Детерминированный конечный автомат
В теории вычислений , разделе теоретической информатики , детерминированный конечный автомат ( DFA ) — также известный как детерминированный конечный акцептор ( DFA ), детерминированный конечный автомат ( DFSM ) или детерминированный конечный автомат ( DFSA ) — — это конечный автомат , который принимает или отклоняет заданную строку символов, проходя через последовательность состояний, однозначно определяемую этой строкой. [1] Детерминированный означает уникальность выполнения вычислений. В поисках простейших моделей для описания конечных автоматов Уоррен Маккалок и Уолтер Питтс были одними из первых исследователей, представивших в 1943 году концепцию, подобную конечным автоматам. [2] [3]
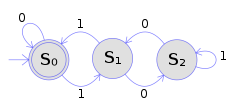
На рисунке показан детерминированный конечный автомат с использованием диаграммы состояний . В этом примере автомата имеется три состояния: S 0 , S 1 и S 2 (обозначены графически кружками). Автомат принимает на вход конечную последовательность нулей и единиц. Для каждого состояния имеется стрелка перехода, ведущая к следующему состоянию как для 0, так и для 1. После считывания символа DFA детерминированно переходит из одного состояния в другое, следуя стрелке перехода. Например, если автомат в данный момент находится в состоянии S 0 и текущий входной символ равен 1, то он детерминированно переходит в состояние S 1 . У DFA есть начальное состояние (графически обозначенное стрелкой, появляющейся из ниоткуда), в котором начинаются вычисления, и набор состояний принятия (графически обозначенных двойным кружком), которые помогают определить, когда вычисление является успешным.
DFA определяется как абстрактная математическая концепция, но часто реализуется в аппаратном и программном обеспечении для решения различных конкретных задач, таких как лексический анализ и сопоставление с образцом . Например, DFA может моделировать программное обеспечение, которое решает, являются ли вводимые пользователем данные онлайн, такие как адреса электронной почты, синтаксически допустимыми. [4]
DFA были обобщены на недетерминированные конечные автоматы (NFA) , которые могут иметь несколько стрелок с одной и той же меткой, начинающихся из состояния. Используя метод построения powerset , каждый NFA можно перевести в DFA, распознающий тот же язык. DFA, а также NFA распознают именно набор обычных языков . [1]
Формальное определение
[ редактировать ]Детерминированный конечный автомат M 5- ( представляет собой Q , Σ, δ , q0 , кортеж F ) , состоящий из
- конечное множество состояний Q
- конечный набор входных символов, называемый алфавитом Σ
- перехода функция δ : Q × Σ → Q
- начальное или начальное состояние
- набор состояний принятия


Пусть w = a 1 a 2 ... an — строка в алфавите Σ . Автомат M принимает строку w, последовательность состояний r 0 , r 1 , ..., r n существует если в Q со следующими условиями:
- р 0 = д 0
- r i +1 = δ ( r i , a i +1 ) , for i = 0, ..., n − 1
- .

На словах первое условие говорит о том, что машина запускается в стартовом состоянии q 0 . Второе условие гласит, что с учетом каждого символа строки w машина будет переходить из состояния в состояние в соответствии с функцией перехода δ . Последнее условие говорит, что машина принимает w , если последний ввод w приводит к остановке машины в одном из состояний принятия. В противном случае говорят, что автомат отвергает строку. Набор строк, который M, принимает — это язык, распознаваемый M , и этот язык обозначается L ( M ) .
Детерминированный конечный автомат без состояний принятия и без начального состояния известен как система переходов или полуавтомат .
Более полное введение формального определения см. в теории автоматов .
Пример
[ редактировать ]Следующий пример представляет собой DFA M с двоичным алфавитом, который требует, чтобы входные данные содержали четное количество нулей.
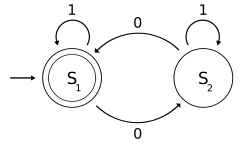
M знак равно ( Q , Σ, δ , q 0 , F ) где
- Q знак равно { S 1 , S 2 }
- Σ = {0, 1}
- q 0 = S 1
- F = { S 1 } и
- δ определяется следующей таблицей переходов состояний :
- 01
SS1 SS2 SS1 SS2 SS1 SS2
Состояние S1 означает , что на данный момент во входных данных было четное количество нулей, а состояние означает S2 нечетное число. 1 на входе не меняет состояние автомата. Когда ввод закончится, состояние покажет, содержало ли вход четное количество нулей или нет. Если входные данные содержали четное количество нулей, M завершит работу в состоянии S 1 , состоянии принятия, поэтому входная строка будет принята.
Язык, распознаваемый M, является регулярным языком, заданным регулярным выражением (1*) (0 (1*) 0 (1*))*, где * это звезда Клини , например, 1* обозначает любое количество (возможно, ноль) последовательных единиц.
Вариации
[ редактировать ]Полный и неполный
[ редактировать ]Согласно приведенному выше определению, детерминированные конечные автоматы всегда полны : они определяют из каждого состояния переход для каждого входного символа.
Хотя это наиболее распространенное определение, некоторые авторы используют термин «детерминированный конечный автомат» для немного другого понятия: автомат, который определяет не более одного перехода для каждого состояния и каждого входного символа; функция перехода может быть частичной . [5] Если переход не определен, такой автомат останавливается.
Локальные автоматы
[ редактировать ]Локальный автомат — это ДКА, не обязательно полный, у которого все ребра с одинаковой меткой ведут в одну вершину. Локальные автоматы принимают класс локальных языков , для которых принадлежность слова к языку определяется «скользящим окном» длины два на слове. [6] [7]
Граф Майхилла над алфавитом A — это ориентированный граф с множеством вершин A и подмножествами вершин, помеченными «начало» и «конец». Язык, принятый графом Майхилла, представляет собой набор направленных путей от начальной вершины до конечной вершины: таким образом, граф действует как автомат. [6] Класс языков, принимаемый графами Майхилла, — это класс локальных языков. [8]
Случайность
[ редактировать ]Когда начальное состояние и состояния принятия игнорируются, DFA из n состояний и алфавита размера k можно рассматривать как орграф из n вершин, в котором все вершины имеют k исходящих дуг, помеченных 1, ..., k ( ak -внешний диграф). Известно, что когда k ≥ 2 — фиксированное целое число, с большой вероятностью наибольшая сильно связная компонента (SCC) в таком равномерно выбранном наугад k -out орграфе имеет линейный размер и достижима всеми вершинами. [9] Также было доказано, что если k разрешено увеличиваться с увеличением n , то весь орграф имеет фазовый переход для сильной связности, аналогичный модели Эрдеша – Реньи для связности. [10]
В случайном DFA максимальное количество вершин, достижимых из одной вершины, с высокой вероятностью очень близко к количеству вершин в наибольшем SCC . [9] [11] Это также верно для наибольшего индуцированного подграфа минимальной степени, который можно рассматривать как направленную версию 1 -core . [10]
Свойства замыкания
[ редактировать ]
Если DFA распознают языки, полученные в результате применения операции к распознаваемым DFA языкам, то говорят, что DFA закрыты в рамках этой операции. ДФА закрываются при следующих операциях.
была определена оптимальная конструкция по числу состояний Для каждой операции в ходе исследования сложности состояний .Поскольку ДКА эквивалентны недетерминированным конечным автоматам (НКА), эти замыкания также можно доказать, используя свойства замыкания НКА.
Как переходный моноид
[ редактировать ]Выполнение данного ДКА можно рассматривать как последовательность композиций очень общей формулировки функции перехода с самой собой. Здесь мы создаем эту функцию.
Для данного входного символа , можно построить функцию перехода определяя для всех . (Этот трюк называется каррирование .) С этой точки зрения «воздействует» на состояние в Q, создавая другое состояние. Затем можно рассмотреть результат композиции функций, многократно примененный к различным функциям. , , и так далее. Дана пара букв , можно определить новую функцию , где обозначает композицию функций.









Очевидно, что этот процесс можно рекурсивно продолжить, дав следующее рекурсивное определение :

- , где пустая строка и
- , где и .




определено для всех слов . Прогон DFA представляет собой последовательность композиций с самим собой.


Повторяющаяся композиция функций образует моноид . Для функций перехода этот моноид известен как моноид перехода или иногда полугруппа преобразований . Построение может быть и обратным: учитывая , можно восстановить , и поэтому два описания эквивалентны.

Преимущества и недостатки
[ редактировать ]DFA являются одной из наиболее практичных моделей вычислений, поскольку существует тривиальный онлайн-алгоритм с линейным временем и постоянным пространством для моделирования DFA в потоке входных данных. Кроме того, существуют эффективные алгоритмы поиска DFA, распознающие:
- дополнение языка, распознаваемое данным DFA.
- объединение/пересечение языков, признаваемых двумя данными DFA.
Поскольку ДКА можно привести к канонической форме ( минимальные ДКА ), существуют также эффективные алгоритмы для определения:
- принимает ли DFA какие-либо строки (проблема пустоты)
- принимает ли DFA все строки (проблема универсальности)
- признают ли два DFA один и тот же язык (проблема равенства)
- включен ли язык, распознаваемый DFA, в язык, распознаваемый вторым DFA (проблема включения)
- ДКА с минимальным количеством состояний для конкретного регулярного языка (задача минимизации)
DFA эквивалентны по вычислительной мощности недетерминированным конечным автоматам (NFA). Это связано с тем, что, во-первых, любой DFA также является NFA, поэтому NFA может делать то же, что и DFA. Кроме того, учитывая NFA, используя конструкцию powerset, можно построить DFA, который распознает тот же язык, что и NFA, хотя DFA может иметь экспоненциально большее количество состояний, чем NFA. [15] [16] Однако, несмотря на то, что NFA вычислительно эквивалентны DFA, вышеупомянутые проблемы не обязательно решаются эффективно и для NFA. Проблема неуниверсальности NFA является PSPACE-полной , поскольку существуют небольшие NFA с кратчайшим отклоняющим словом экспоненциального размера. DFA является универсальным тогда и только тогда, когда все состояния являются конечными состояниями, но это не относится к NFA. Проблемы равенства, включения и минимизации также являются PSPACE полными, поскольку они требуют формирования дополнения к NFA, что приводит к экспоненциальному увеличению размера. [17]
С другой стороны, автоматы с конечным числом состояний имеют строго ограниченную мощность на языках, которые они могут распознавать; многие простые языки, включая любую проблему, для решения которой требуется больше, чем постоянное пространство, не могут быть распознаны DFA. Классическим примером просто описанного языка, который не может распознать ни один DFA, является скобочный язык или язык Дика , т. е. язык, который состоит из правильно парных скобок, таких как слово «(()())». Интуитивно понятно, что ни один DFA не может распознать язык Дика, потому что DFA не способен считать: автомату, подобному DFA, необходимо иметь состояние для представления любого возможного количества «открытых в данный момент» круглых скобок, а это означает, что ему потребуется неограниченное количество состояний. Другой более простой пример — язык, состоящий из строк вида a н б н но произвольного числа a для некоторого конечного , количество b , за которым следует такое же . [18]
Идентификация DFA по помеченным словам
[ редактировать ]Дан набор позитивных слов и набор негативных слов можно построить ДКА, который принимает все слова из и отвергает все слова из : эта проблема называется DFA-идентификация (синтез, обучение).Хотя некоторые ДКА могут быть построены за линейное время, проблема идентификации ДКА с минимальным числом состояний является NP-полной. [19] Первый алгоритм минимальной идентификации DFA был предложен Трахтенбротом и Барздином. [20] и называется ТБ-алгоритмом .Однако TB-алгоритм предполагает, что все слова из до заданной длины содержатся либо в .






Позднее К. Ланг предложил расширение ТБ-алгоритма, не использующее никаких предположений о и , алгоритм Traxbar . [21] Однако Traxbar не гарантирует минимальность построенного DFA.В своей работе [19] EM Gold также предложил эвристический алгоритм для минимальной идентификации DFA.Алгоритм Голда предполагает, что и содержать характерный набор регулярного языка; в противном случае построенный DFA будет несовместим либо с или .Другие известные алгоритмы идентификации DFA включают алгоритм RPNI, [22] основанный на доказательствах алгоритм объединения состояний Blue-Fringe, [23] и оконный-EDSM. [24] Еще одним направлением исследований является применение эволюционных алгоритмов : эволюционный алгоритм интеллектуальной маркировки состояний. [25] позволило решить модифицированную задачу идентификации DFA, в которой обучающие данные (наборы и ) зашумлен в том смысле, что некоторые слова относятся к неправильным классам.
Еще один шаг вперед был сделан благодаря использованию SAT решателей Марджином Дж. Хойле и С. Вервером: минимальная задача идентификации DFA сведена к определению выполнимости булевой формулы. [26] Основная идея состоит в том, чтобы построить акцептор расширенного префиксного дерева ( дерево, содержащее все входные слова с соответствующими метками) на основе входных наборов и уменьшить проблему поиска DFA с указывает на раскраску вершин дерева с помощью состояния таким образом, что при объединении вершин одного цвета в одно состояние сгенерированный автомат является детерминированным и соответствует и .Хотя этот подход позволяет найти минимальный DFA, он страдает от экспоненциального увеличения времени выполнения при увеличении размера входных данных.Поэтому первоначальный алгоритм Хойле и Вервера позже был дополнен несколькими шагами алгоритма EDSM перед выполнением решателя SAT: алгоритмом DFASAT. [27] Это позволяет сократить пространство поиска задачи, но приводит к потере гарантии минимальности.Другой способ сокращения пространства поиска был предложен Ульянцевым и др. [28] с помощью новых предикатов нарушения симметрии, основанных на алгоритме поиска в ширину :искомые состояния DFA ограничены нумерацией в соответствии с алгоритмом BFS, запускаемым из исходного состояния. Этот подход уменьшает пространство поиска на путем исключения изоморфных автоматов.


Эквивалентные модели
[ редактировать ]Правосторонние машины Тьюринга только для чтения
[ редактировать ]Машины Тьюринга, движущиеся вправо только для чтения, представляют собой особый тип машины Тьюринга , которая движется только вправо; этипочти точно эквивалентны DFA. [29] Определение, основанное на единственной бесконечной ленте, представляет собой семикортеж

где
- — конечное множество состояний ;
- — конечное множество ленточных алфавитов/символов ;
- — пустой символ (единственный символ, который может появляться на ленте бесконечно часто на любом этапе вычислений);
- , подмножество не включая b , — набор входных символов ;
- – функция, называемая функцией перехода , R – движение вправо (сдвиг вправо);
- — исходное состояние ;
- — это набор конечных или принимающих состояний .




Машина всегда принимает обычный язык. Должен существовать хотя бы один элемент множества F ( состояние HALT ), чтобы язык был непустым.
Пример машины Тьюринга с 3 состояниями и 2 символами только для чтения
[ редактировать ]| Текущее состояние А | Текущее состояние Б | Текущее состояние C | |||||||
| символ ленты | Написать символ | Переместить ленту | Следующее состояние | Написать символ | Переместить ленту | Следующее состояние | Написать символ | Переместить ленту | Следующее состояние |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | Р | Б | 1 | Р | А | 1 | Р | Б |
| 1 | 1 | Р | С | 1 | Р | Б | 1 | Н | ОСТАНОВКА |
- , "пустой";
- , пустой набор;
- см. таблицу состояний выше;
- , исходное состояние;
- одноэлементный набор конечных состояний: .








См. также
[ редактировать ]Примечания
[ редактировать ]- ^ Перейти обратно: а б Хопкрофт 2001 г.
- ^ Маккалок и Питтс (1943)
- ^ Рабин и Скотт (1959)
- ^ Бай, Джина Р.; Кли, Брайан; Шреста, Нишал; Чепмен, Карл; Райт, Симоне; Столи, Кэтрин Т. (2019). «Изучение инструментов и стратегий, используемых при выполнении задач по составлению регулярных выражений» . В Геэнеке — Янн-Гаэль; Хомх, Фаутс; Сарро, Федерика (ред.). Материалы 27-й Международной конференции по программированию, ICPC 2019, Монреаль, Квебек, Канада, 25-31 мая 2019 г. IEEE/АКМ. стр. 197–208. дои : 10.1109/ICPC.2019.00039 .
- ^ Могенсен, Торбен Эгидиус (2011). «Лексический анализ». Введение в проектирование компилятора . Темы бакалавриата по информатике. Лондон: Спрингер. п. 12. дои : 10.1007/978-0-85729-829-4_1 . ISBN 978-0-85729-828-7 .
- ^ Перейти обратно: а б Лоусон (2004) стр.129
- ^ Сакарович (2009) стр.228
- ^ Лоусон (2004) стр.128
- ^ Перейти обратно: а б Грушо, А.А. (1973). «Предельные распределения некоторых характеристик случайных автоматных графов». Математические записки Академии наук СССР . 4 : 633–637. дои : 10.1007/BF01095785 . S2CID 121723743 .
- ^ Перейти обратно: а б Цай, Син Ши; Деврой, Люк (октябрь 2017 г.). «Структура графа случайно выбранного детерминированного автомата». Случайные структуры и алгоритмы . 51 (3): 428–458. arXiv : 1504.06238 . дои : 10.1002/rsa.20707 . S2CID 13013344 .
- ^ Карайоль, Арно; Нико, Сирил (февраль 2012 г.). Распределение числа доступных состояний в случайном детерминированном автомате . STACS'12 (29-й симпозиум по теоретическим аспектам информатики). Том. 14. Париж, Франция. стр. 194–205.
- ^ Джон Э. Хопкрофт и Джеффри Д. Ульман (1979). Введение в теорию автоматов, языки и вычисления . Ридинг/Массачусетс: Аддисон-Уэсли. ISBN 0-201-02988-Х .
- ^ Перейти обратно: а б с Роуз, Джин Ф. (1968). «Замыкания, сохраняющие конечность в семьях языков». Журнал компьютерных и системных наук . 2 (2): 148–168. дои : 10.1016/S0022-0000(68)80029-7 .
- ^ Перейти обратно: а б Спаниер, Э. (1969). «Грамматики и языки». Американский математический ежемесячник . 76 : 335–342. дои : 10.1080/00029890.1969.12000214 . JSTOR 2316423 . МР 0241205 .
- ^ Сакарович (2009) стр.105
- ^ Лоусон (2004) стр.63
- ^ Эспарса Эстаун, Франсиско Хавьер; Сикерт, Саломон; Блонден, Майкл (16 ноября 2016 г.). «Операции и тесты на множествах: реализация на DFA» (PDF) . Автоматы и формальные языки 2017/18 . Архивировано из оригинала (PDF) 8 августа 2018 года.
- ^ Лоусон (2004) стр.46
- ^ Перейти обратно: а б Золото, ЕМ (1978). «Сложность идентификации автоматов по заданным данным». Информация и контроль . 37 (3): 302–320. дои : 10.1016/S0019-9958(78)90562-4 .
- ^ Де Врис, А. (28 июня 2014 г.). Конечные автоматы: поведение и синтез . Эльзевир. ISBN 9781483297293 .
- ^ Ланг, Кевин Дж. (1992). «Случайные DFA можно приблизительно узнать из редких однородных примеров». Материалы пятого ежегодного семинара по теории вычислительного обучения - COLT '92 . стр. 45–52. дои : 10.1145/130385.130390 . ISBN 089791497X . S2CID 7480497 .
- ^ Ончина, Дж.; Гарсия, П. (1992). «Вывод регулярных языков за полиномиальное время обновления». Распознавание образов и анализ изображений . Серия «Машинное восприятие и искусственный интеллект». Том. 1. С. 49–61. дои : 10.1142/9789812797902_0004 . ISBN 978-981-02-0881-3 .
- ^ Ланг, Кевин Дж.; Перлмуттер, Барак А.; Прайс, Родни А. (1998). «Результаты конкурса обучения Abbadingo one DFA и новый алгоритм слияния состояний, основанный на фактических данных». Грамматический вывод (PDF) . Конспекты лекций по информатике. Том. 1433. стр. 1–12. дои : 10.1007/BFb0054059 . ISBN 978-3-540-64776-8 .
- ^ За пределами ЭДСМ | Материалы 6-го Международного коллоквиума по грамматическому выводу: алгоритмы и приложения . 23 сентября 2002 г. стр. 37–48. ISBN 9783540442394 .
- ^ Лукас, С.М.; Рейнольдс, Ти Джей (2005). «Изучение детерминированных конечных автоматов с помощью интеллектуального эволюционного алгоритма разметки состояний». Транзакции IEEE по анализу шаблонов и машинному интеллекту . 27 (7): 1063–1074. дои : 10.1109/TPAMI.2005.143 . ПМИД 16013754 . S2CID 14062047 .
- ^ Хойле, MJH (2010). «Точная идентификация DFA с использованием решателей SAT». Грамматический вывод: теоретические результаты и приложения . Грамматический вывод: теоретические результаты и приложения. ICGI 2010. Конспекты лекций по информатике. Конспекты лекций по информатике. Том. 6339. стр. 66–79. дои : 10.1007/978-3-642-15488-1_7 . ISBN 978-3-642-15487-4 .
- ^ Хойле, Марин Дж. Х .; Вервер, Сикко (2013). «Программный синтез модели с использованием решателей выполнимости» . Эмпирическая программная инженерия . 18 (4): 825–856. дои : 10.1007/s10664-012-9222-z . hdl : 2066/103766 . S2CID 17865020 .
- ^ Ульянцев Владимир; Закирзянов Илья; Шалыто, Анатолий (2015). «Предикаты нарушения симметрии на основе BFS для идентификации DFA». Теория и приложения языка и автоматов . Конспекты лекций по информатике. Том. 8977. стр. 611–622. дои : 10.1007/978-3-319-15579-1_48 . ISBN 978-3-319-15578-4 .
- ^ Дэвис, Мартин; Рон Сигал; Элейн Дж. Вейкер (1994). Второе издание: Вычислимость, сложность, языки и логика: основы теоретической информатики (2-е изд.). Сан-Диего: Academic Press, Harcourt, Brace & Company. ISBN 0-12-206382-1 .
Ссылки
[ редактировать ]- Хопкрофт, Джон Э .; Мотвани, Раджив ; Уллман, Джеффри Д. (2001). Введение в теорию автоматов, языки и вычисления (2-е изд.). Бостон: Эддисон Уэсли . ISBN 0-201-44124-1 .
- Лоусон, Марк В. (2004). Конечные автоматы . Чепмен и Холл/CRC. ISBN 1-58488-255-7 . Збл 1086.68074 .
- Маккалок, штат Вашингтон; Питтс, В. (1943). «Логическое исчисление идей, имманентных нервной деятельности». Вестник математической биофизики . 5 (4): 115–133. дои : 10.1007/BF02478259 . ПМИД 2185863 .
- Рабин, Миссури; Скотт, Д. (1959). «Конечные автоматы и проблемы их решения» . IBM J. Res. Дев . 3 (2): 114–125. дои : 10.1147/рд.32.0114 .
- Сакарович, Жак (2009). Элементы теории автоматов . Перевод с французского Рубена Томаса. Кембридж: Издательство Кембриджского университета . ISBN 978-0-521-84425-3 . Збл 1188.68177 .
- Сипсер, Майкл (1997). Введение в теорию вычислений . Бостон: PWS. ISBN 0-534-94728-Х . . Раздел 1.1: Конечные автоматы, стр. 31–47. Подраздел «Разрешимые проблемы, касающиеся регулярных языков» раздела 4.1: Разрешимые языки, стр. 152–155.4.4 DFA может принимать только обычный язык.