Суперкомпьютер

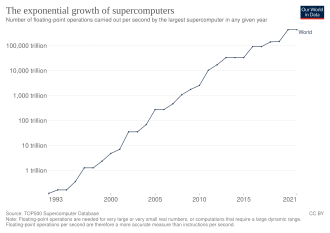
Суперкомпьютер — это тип компьютера с более высоким уровнем производительности по сравнению с компьютером общего назначения. Производительность суперкомпьютера обычно измеряется в с плавающей запятой операциях в секунду ( FLOPS ), а не в миллионах инструкций в секунду (MIPS). С 2017 года существуют суперкомпьютеры, способные выполнять более 10 17 FLOPS (сто квадриллионов FLOPS, 100 петафлопс или 100 PFLOPS). [3] Для сравнения, настольный компьютер имеет производительность в пределах сотен гигафлопс (10 11 ) до десятков терафлопс (10 13 ). [4] [5] С ноября 2017 года все 500 самых быстрых суперкомпьютеров в мире работают на Linux . операционных системах на базе [6] Дополнительные исследования проводятся в США, Европейском Союзе, Тайване, Японии и Китае с целью создания более быстрых, мощных и технологически совершенных экзафлопсных суперкомпьютеров . [7]
Суперкомпьютеры играют важную роль в области вычислительной науки и используются для широкого спектра вычислительно-интенсивных задач в различных областях, включая квантовую механику , прогнозирование погоды , исследования климата , разведку нефти и газа , молекулярное моделирование (вычисление структур и свойств). химических соединений, биологических макромолекул , полимеров и кристаллов) и физическое моделирование (например, моделирование ранних моментов Вселенной, аэродинамики самолетов и космических кораблей , детонации ядерного оружия и ядерного синтеза ). Они сыграли важную роль в области криптоанализа . [8]
Суперкомпьютеры были представлены в 1960-х годах, и в течение нескольких десятилетий самые быстрые из них создавал Сеймур Крей в Control Data Corporation (CDC), Cray Research и последующих компаниях, носящих его имя или монограмму. Первые такие машины представляли собой хорошо настроенные традиционные конструкции, которые работали быстрее, чем их более универсальные современники. В течение десятилетия увеличивалось количество параллелизма от одного до четырех процессоров , обычно . В 1970-е годы стали доминировать векторные процессоры, работающие с большими массивами данных. Ярким примером является очень успешный Cray-1 1976 года. Векторные компьютеры оставались доминирующей конструкцией до 1990-х годов. С тех пор и до сегодняшнего дня массово-параллельные суперкомпьютеры с десятками тысяч готовых процессоров стали нормой. [9] [10]
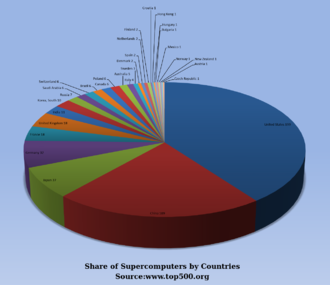
США долгое время были лидером в области суперкомпьютеров, сначала благодаря почти непрерывному доминированию компании Cray в этой области, а затем благодаря множеству технологических компаний. Япония добилась больших успехов в этой области в 1980-х и 90-х годах, при этом Китай становится все более активным в этой области. По состоянию на май 2022 года самым быстрым суперкомпьютером в списке TOP500 является Frontier в США с результатом теста LINPACK 1,102 ExaFlop/s, за ним следует Fugaku . [11] В США пять из десяти крупнейших стран; В Китае их два; По одному имеют Япония, Финляндия и Франция. [12] В июне 2018 года все суперкомпьютеры из списка TOP500 вместе взятые преодолели отметку в 1 экзафлопс . [13]
История [ править ]



В 1960 году UNIVAC построила Ливерморский компьютер атомных исследований (LARC), который сегодня считается одним из первых суперкомпьютеров, для Центра исследований и разработок ВМС США. В нем по-прежнему использовалась высокоскоростная барабанная память , а не недавно появившаяся технология дисковых накопителей . [14] Также среди первых суперкомпьютеров был IBM 7030 Stretch . IBM 7030 был построен IBM для Национальной лаборатории Лос-Аламоса , которая тогда, в 1955 году, запросила компьютер в 100 раз быстрее, чем любой существующий компьютер. В IBM 7030 использовались транзисторы , память на магнитных сердечниках, конвейерные инструкции, предварительная выборка данных через контроллер памяти и новаторские дисковые накопители с произвольным доступом. IBM 7030 был завершен в 1961 году, и, несмотря на то, что он не смог добиться стократного увеличения производительности, он был приобретен Национальной лабораторией Лос-Аламоса. Клиенты в Англии и Франции также купили компьютер, и он стал основой для IBM 7950 Harvest , суперкомпьютера, созданного для криптоанализа . [15]
Третьим новаторским проектом суперкомпьютера в начале 1960-х годов был Атлас в Манчестерском университете , созданный командой под руководством Тома Килберна . Он спроектировал Атлас так, чтобы в памяти могло храниться до миллиона слов по 48 бит, но поскольку магнитное хранилище такой емкости было недоступно, фактическая основная память Атласа составляла всего 16 000 слов, а барабан обеспечивал память еще на 96 000 слов. слова. Atlas Операционная система обменивала данные в виде страниц между магнитным сердечником и барабаном. Операционная система Atlas также ввела в суперкомпьютер разделение времени , так что на суперкомпьютере можно было одновременно выполнять более одной программы. [16] Atlas был совместным предприятием Ферранти и Манчестерского университета и был разработан для работы со скоростью обработки, приближающейся к одной микросекунде на инструкцию, то есть около миллиона инструкций в секунду. [17]
CDC 6600 , разработанный Сеймуром Креем , был закончен в 1964 году и ознаменовал переход от германиевых к кремниевым транзисторам. Кремниевые транзисторы могли работать быстрее, а проблема перегрева была решена за счет внедрения охлаждения в конструкцию суперкомпьютера. [18] Таким образом, CDC6600 стал самым быстрым компьютером в мире. Учитывая, что 6600 превосходил все другие современные компьютеры примерно в 10 раз, его окрестили суперкомпьютером и определили рынок суперкомпьютеров, когда сто компьютеров были проданы по 8 миллионов долларов каждый. [19] [20] [21] [22]
Крей покинул CDC в 1972 году, чтобы основать собственную компанию Cray Research . [20] Через четыре года после ухода из CDC Крей в 1976 году представил Cray-1 с тактовой частотой 80 МГц , который стал одним из самых успешных суперкомпьютеров в истории. [23] [24] Cray -2 был выпущен в 1985 году. Он имел восемь центральных процессоров (ЦП), жидкостное охлаждение , а охлаждающая жидкость для электроники Fluorinert прокачивалась через архитектуру суперкомпьютера . Его производительность достигла 1,9 гигафлопс , что сделало его первым суперкомпьютером, преодолевшим барьер гигафлопс. [25]
Массивно параллельные проекты [ править ]

Единственным компьютером, серьезно бросившим вызов Cray-1 в 1970-х годах, был ILLIAC IV . Эта машина была первым реализованным примером настоящего компьютера с массовым параллелизмом , в котором множество процессоров работали вместе для решения различных частей одной более крупной задачи. В отличие от векторных систем, которые были разработаны для максимально быстрой обработки единого потока данных, в этой концепции компьютер вместо этого передает отдельные части данных совершенно разным процессорам, а затем рекомбинирует результаты. Конструкция ILLIAC была завершена в 1966 году с 256 процессорами и скоростью до 1 GFLOPS по сравнению с пиком Cray-1 1970-х годов, составлявшим 250 MFLOPS. Однако проблемы с разработкой привели к тому, что было построено всего 64 процессора, и система никогда не могла работать быстрее, чем примерно 200 MFLOPS, хотя она была намного больше и сложнее, чем Cray. Другая проблема заключалась в том, что написать программное обеспечение для системы было сложно, а добиться от него максимальной производительности было делом серьезных усилий.
Но частичный успех ILLIAC IV был воспринят многими как указание пути в будущее суперкомпьютеров. Крей возражал против этого, пошутив: «Если бы вы пахали поле, что бы вы предпочли использовать? Двух сильных волов или 1024 курицы?» [26] Но к началу 1980-х годов несколько команд работали над параллельными разработками с тысячами процессоров, в частности над Connection Machine (CM), разработанной в результате исследований в Массачусетском технологическом институте . В CM-1 использовалось 65 536 упрощенных специализированных микропроцессоров, соединенных в сеть для обмена данными. Затем последовало несколько обновленных версий; Суперкомпьютер CM-5 — это компьютер с массивной параллельной обработкой, способный выполнять многие миллиарды арифметических операций в секунду. [27]
В 1982 году Осаки Университета в системе компьютерной графики LINKS-1 использовалась архитектура массово-параллельной обработки с 514 микропроцессорами , включая 257 Zilog Z8001 процессоров управления и 257 процессоров iAPX 86/20 с плавающей запятой . В основном он использовался для рендеринга реалистичной компьютерной 3D-графики . [28] Fujitsu VPP500 1992 года необычен, поскольку для достижения более высоких скоростей в его процессорах использовался GaAs , материал, который обычно используется в микроволновых приложениях из-за его токсичности. [29] Fujitsu компании Суперкомпьютер Numerical Wind Tunnel использовал 166 векторных процессоров, чтобы занять первое место в 1994 году с пиковой скоростью 1,7 гигафлопс (GFLOPS) на процессор. [30] [31] В 1996 году Hitachi SR2201 достиг пиковой производительности 600 гигафлопс за счет использования 2048 процессоров, соединенных через быструю трехмерную перекрестную сеть. [32] [33] [34] Intel Paragon мог иметь от 1000 до 4000 процессоров Intel i860 в различных конфигурациях и в 1993 году был признан самым быстрым в мире. Paragon представлял собой машину MIMD , которая соединяла процессоры через высокоскоростную двумерную сетку, позволяя процессам выполняться на отдельных узлах. , общаясь через интерфейс передачи сообщений . [35]
Разработка программного обеспечения оставалась проблемой, но серия CM послужила толчком для серьезных исследований по этому вопросу. Подобные конструкции с использованием специального оборудования создавались многими компаниями, включая Evans & Sutherland ES-1 , MasPar , nCUBE , Intel iPSC и Goodyear MPP . Но к середине 1990-х годов производительность процессоров общего назначения настолько возросла, что суперкомпьютер можно было построить, используя их в качестве отдельных процессоров вместо использования специальных микросхем. На рубеже 21-го века конструкции с десятками тысяч обычных процессоров стали нормой, а более поздние машины добавили графические модули . к этому набору [9] [10]
В 1998 году Дэвид Бейдер разработал первый суперкомпьютер Linux, используя стандартные детали. [36] Во время учебы в Университете Нью-Мексико Бадер стремился построить суперкомпьютер под управлением Linux, используя готовые потребительские компоненты и высокоскоростную межсетевую сеть с малой задержкой. В прототипе использовался Alta Technologies «AltaCluster» из восьми двойных компьютеров Intel Pentium II с тактовой частотой 333 МГц, работающих под управлением модифицированного ядра Linux. Бадер портировал значительное количество программного обеспечения для обеспечения поддержки необходимых компонентов Linux, а также код членов Национального альянса вычислительных наук (NCSA) для обеспечения совместимости, поскольку ни одно из них ранее не запускалось в Linux. [37] Используя успешный дизайн прототипа, он возглавил разработку RoadRunner, первого суперкомпьютера Linux для открытого использования национальным научным и инженерным сообществом через Национальную технологическую сеть Национального научного фонда. RoadRunner был введен в эксплуатацию в апреле 1999 года. На момент запуска он считался одним из 100 самых быстрых суперкомпьютеров в мире. [37] [38] Хотя кластеры на базе Linux с использованием компонентов потребительского уровня, такие как Beowulf , существовали до разработки прототипа Бадера и RoadRunner, им не хватало масштабируемости, пропускной способности и возможностей параллельных вычислений, чтобы считаться «настоящими» суперкомпьютерами. [37]
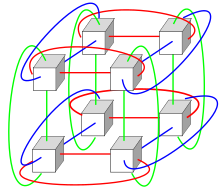
Системы с огромным количеством процессоров обычно идут по одному из двух путей. В рамках подхода грид-вычислений вычислительная мощность многих компьютеров, организованных как распределенные, разнообразные административные домены, используется оппортунистически всякий раз, когда компьютер доступен. [39] В другом подходе множество процессоров используются близко друг к другу, например, в компьютерном кластере . В такой централизованной системе с массовым параллелизмом скорость и гибкость Межсоединение становится очень важным, и в современных суперкомпьютерах используются различные подходы, начиная от усовершенствованных систем Infiniband и заканчивая трехмерными торическими межсоединениями . [40] [41] Использование многоядерных процессоров в сочетании с централизацией является новым направлением, например, как в системе Cyclops64 . [42] [43]
Поскольку цена, производительность и энергоэффективность графических процессоров общего назначения (GPGPU) улучшились, ряд петафлопс- суперкомпьютеров, таких как Tianhe-I и Nebulae, начали полагаться на них. [44] Однако другие системы, такие как компьютер K, продолжают использовать традиционные процессоры, такие как конструкции на основе SPARC , и общая применимость GPGPU в высокопроизводительных вычислительных приложениях общего назначения была предметом споров, поскольку GPGPU можно настраивать Чтобы получить хорошие результаты в конкретных тестах, его общая применимость к повседневным алгоритмам может быть ограничена, если не будут затрачены значительные усилия на настройку приложения под него. [45] Однако графические процессоры набирают популярность, и в 2012 году суперкомпьютер Jaguar был преобразован в Titan путем модернизации процессоров с помощью графических процессоров. [46] [47] [48]
Ожидаемый жизненный цикл высокопроизводительных компьютеров составляет около трех лет, прежде чем потребуется обновление. [49] Суперкомпьютер Gyoukou уникален тем, что в нем используется как массивно-параллельная конструкция, так и жидкостное иммерсионное охлаждение .
Суперкомпьютеры специального назначения [ править ]
Был разработан ряд систем специального назначения, посвященных одной проблеме. Это позволяет использовать специально запрограммированные микросхемы FPGA или даже специальные ASIC , обеспечивая лучшее соотношение цены и производительности за счет принесения в жертву универсальности. Примеры суперкомпьютеров специального назначения включают Belle , [50] Темно-синий , [51] и Гидра [52] для игры в шахматы , Гравитационная труба для астрофизики, [53] MDGRAPE-3 для прогнозирования структуры белков и молекулярной динамики, [54] и Deep Crack для взлома DES шифра . [55]
энергии и управление Использование теплом

На протяжении десятилетий управление плотностью тепла оставалось ключевым вопросом для большинства централизованных суперкомпьютеров. [58] [59] [60] Большое количество тепла, выделяемого системой, может иметь и другие последствия, например, сокращение срока службы других компонентов системы. [61] Существовали различные подходы к управлению теплом: от прокачки фторинерта через систему до гибридной системы жидкостно-воздушного охлаждения или воздушного охлаждения с нормальной температурой кондиционирования воздуха . [62] [63] Типичный суперкомпьютер потребляет большое количество электроэнергии, почти вся из которой преобразуется в тепло, требующее охлаждения. Например, Тяньхэ-1А потребляет 4,04 мегаватта (МВт) электроэнергии. [64] Затраты на электроснабжение и охлаждение системы могут быть значительными, например, 4 МВт при цене 0,10 доллара США за кВтч составляют 400 долларов США в час или около 3,5 миллионов долларов США в год.

Управление теплом является серьезной проблемой в сложных электронных устройствах и по-разному влияет на мощные компьютерные системы. [65] Проблемы теплового расчета и рассеивания мощности процессора в суперкомпьютерах превосходят проблемы традиционных технологий охлаждения компьютеров . Награды за суперкомпьютеры за «зеленые» вычисления отражают эту проблему. [66] [67] [68]
Объединение тысяч процессоров вместе неизбежно приводит к значительному выделению тепла , с которым необходимо бороться. Cray -2 имел жидкостное охлаждение и использовал «охлаждающий водопад» Fluorinert , который проталкивался через модули под давлением. [62] Однако подход погружного жидкостного охлаждения оказался непрактичным для многокабинетных систем на базе готовых процессоров, и в System X совместно с компанией Liebert была разработана специальная система охлаждения, сочетающая кондиционирование воздуха с жидкостным охлаждением . [63]
В системе Blue Gene IBM намеренно использовала процессоры с низким энергопотреблением, чтобы справиться с плотностью тепла. [69] IBM Power 775 , выпущенный в 2011 году, имеет плотно упакованные элементы, требующие водяного охлаждения. [70] В системе IBM Aquasar для достижения энергоэффективности используется охлаждение горячей водой, причем вода также используется для обогрева зданий. [71] [72]
Энергоэффективность компьютерных систем обычно измеряется в единицах « флопс на ватт ». В 2008 году Roadrunner от IBM работал со скоростью 376 MFLOPS/Вт . [73] [74] В ноябре 2010 года производительность Blue Gene/Q достигла 1684 MFLOPS/Вт. [75] [76] а в июне 2011 года два верхних места в списке Green 500 заняли машины Blue Gene в Нью-Йорке (одна из них достигла 2097 MFLOPS/Вт), а кластер DEGIMA в Нагасаки занял третье место с 1375 MFLOPS/Вт. [77]
Поскольку медные провода могут передавать энергию в суперкомпьютер с гораздо более высокой плотностью мощности, чем принудительная подача воздуха или циркулирующие хладагенты могут отводить отработанное тепло . [78] способность систем охлаждения отводить отработанное тепло является ограничивающим фактором. [79] [80] По состоянию на 2015 год [update]Многие существующие суперкомпьютеры имеют большую мощность инфраструктуры, чем фактическая пиковая потребность машины – проектировщики обычно консервативно проектируют инфраструктуру электропитания и охлаждения так, чтобы она могла выдерживать мощность, превышающую теоретическую пиковую электрическую мощность, потребляемую суперкомпьютером. Конструкции будущих суперкомпьютеров ограничены по мощности: расчетная тепловая мощность суперкомпьютера в целом, то есть количество, которое может выдержать инфраструктура электропитания и охлаждения, несколько превышает ожидаемое нормальное энергопотребление, но меньше теоретического пикового энергопотребления. электронное оборудование. [81]
Программное обеспечение и управление системой [ править ]
Операционные системы [ править ]
С конца 20-го века операционные системы суперкомпьютеров претерпели серьезные преобразования, основанные на изменениях в архитектуре суперкомпьютеров . [82] В то время как ранние операционные системы были специально адаптированы для каждого суперкомпьютера для увеличения скорости, тенденция заключалась в переходе от собственных операционных систем к адаптации общего программного обеспечения, такого как Linux . [83]
Поскольку современные суперкомпьютеры с массовым параллелизмом обычно отделяют вычисления от других служб с помощью узлов нескольких типов , они обычно используют разные операционные системы на разных узлах, например, используя небольшое и эффективное легкое ядро , такое как CNK или CNL, на вычислительных узлах, но более крупную систему, такую как как производная от Linux на сервере и узлах ввода-вывода . [84] [85] [86]
В то время как в традиционной многопользовательской компьютерной системе планирование заданий , по сути, является проблемой постановки задач для обработки и периферийных ресурсов, в системе с массовым параллелизмом система управления заданиями должна управлять распределением как вычислительных, так и коммуникационных ресурсов, а также корректно справляться с неизбежными аппаратными сбоями при наличии десятков тысяч процессоров. [87]
Хотя большинство современных суперкомпьютеров используют операционные системы на базе Linux , у каждого производителя есть своя собственная производная от Linux, и отраслевого стандарта не существует, отчасти из-за того, что различия в аппаратных архитектурах требуют изменений для оптимизации операционной системы для каждой аппаратной конструкции. [82] [88]
Программные инструменты передача сообщений и

Параллельная архитектура суперкомпьютеров часто требует использования специальных методов программирования для использования их скорости. Программные инструменты для распределенной обработки включают стандартные API, такие как MPI. [90] а также PVM , VTL и программное обеспечение с открытым исходным кодом, такое как Beowulf .
В наиболее распространенном сценарии такие среды, как PVM и MPI для слабосвязанных кластеров и OpenMP используются для тесно скоординированных машин с общей памятью. Требуются значительные усилия для оптимизации алгоритма с учетом характеристик межсоединения машины, на которой он будет работать; цель состоит в том, чтобы не допустить, чтобы какой-либо из процессоров тратил время на ожидание данных от других узлов. GPGPU имеют сотни процессорных ядер и программируются с использованием таких моделей программирования, как CUDA или OpenCL .
Более того, отлаживать и тестировать параллельные программы довольно сложно. специальные методы Для тестирования и отладки таких приложений необходимо использовать .
суперкомпьютеры Распределенные
подходы Оппортунистические
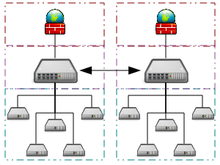
Оппортунистические суперкомпьютеры — это форма сетевых распределенных вычислений , при которой «супервиртуальный компьютер», состоящий из множества слабосвязанных вычислительных машин-добровольцев, выполняет очень большие вычислительные задачи. Грид-вычисления применялись для решения ряда крупномасштабных задач с ошеломляющим параллелизмом , требующих масштабов производительности суперкомпьютеров. Однако базовые подходы к грид- и облачным вычислениям , основанные на добровольных вычислениях, не могут справиться с традиционными суперкомпьютерными задачами, такими как гидродинамическое моделирование. [91]
Самая быстрая система грид-вычислений — это волонтерский вычислительный проект Folding@home (F@h). По состоянию на апрель 2020 г. [update] 2,5 экзафлопс , F@h сообщил о производительности процессора x86 . Из них более 100 PFLOPS приходится на клиенты, работающие на различных графических процессорах, а остальную часть — на различные системы ЦП. [92]
Платформа открытой инфраструктуры сетевых вычислений Беркли (BOINC) размещает ряд добровольных вычислительных проектов. По состоянию на февраль 2017 г. [update]BOINC зафиксировал вычислительную мощность более 166 петафлопс на более чем 762 тысячах активных компьютеров (хостов) в сети. [93]
По состоянию на октябрь 2016 г. [update] Prime Great Internet Mersenne Prime Search компании Распределенный поиск Мерсенна Search (GIMPS) достиг скорости около 0,313 PFLOPS на более чем 1,3 миллионах компьютеров. [94] Сервер PrimeNet поддерживает подход GIMPS к грид-вычислениям, одному из первых добровольных вычислительных проектов, начиная с 1997 года.
Квазиоппортунистические подходы [ править ]
Квазиоппортунистические суперкомпьютеры — это форма распределенных вычислений , при которой «супервиртуальный компьютер» из множества географически разбросанных по сети компьютеров выполняет вычислительные задачи, требующие огромной вычислительной мощности. [95] Квазиоппортунистические суперкомпьютеры направлены на обеспечение более высокого качества обслуживания, чем оппортунистические грид-вычисления, за счет достижения большего контроля над назначением задач распределенным ресурсам и использования информации о доступности и надежности отдельных систем в суперкомпьютерной сети. Однако квазиоппортунистическое распределенное выполнение требовательного программного обеспечения для параллельных вычислений в гридах должно быть достигнуто за счет реализации соглашений о распределении по сетке, подсистем совместного распределения, механизмов распределения с учетом топологии связи, отказоустойчивых библиотек передачи сообщений и предварительной подготовки данных. [95]
Облака высокопроизводительных вычислений [ править ]
Облачные вычисления с их недавним быстрым расширением и развитием в последние годы привлекли внимание пользователей и разработчиков высокопроизводительных вычислений (HPC). Облачные вычисления пытаются предоставить HPC как услугу точно так же, как и другие формы услуг, доступных в облаке, такие как программное обеспечение как услуга , платформа как услуга и инфраструктура как услуга . Пользователи высокопроизводительных вычислений могут получить выгоду от облака с разных точек зрения, например, благодаря масштабируемости, доступности ресурсов по требованию, скорости и дешевизне. С другой стороны, перемещение приложений HPC также сопряжено с рядом проблем. Хорошими примерами таких проблем являются накладные расходы на виртуализацию в облаке, мультиарендность ресурсов и проблемы с задержками в сети. В настоящее время проводится много исследований, чтобы преодолеть эти проблемы и сделать высокопроизводительные вычисления в облаке более реалистичными. [96] [97] [98] [99]
Penguin Computing, Parallel Works, R-HPC, Amazon Web Services , Univa , Silicon Graphics International , Rescale высокопроизводительные вычисления начали предлагать В 2016 году облачные , Sabalcore и Gomput . Облако Penguin On Demand (POD) представляет собой «голую» вычислительную модель для выполнения кода, но каждому пользователю предоставляется виртуальный узел входа в систему. Вычислительные узлы POD подключаются через невиртуализированные 10 Гбит/с Ethernet или QDR InfiniBand сети POD . Скорость подключения пользователей к дата-центру варьируется от 50 Мбит/с до 1 Гбит/с. [100] Ссылаясь на Amazon EC2 Elastic Compute Cloud, Penguin Computing утверждает, что виртуализация вычислительных узлов не подходит для HPC. Компания Penguin Computing также раскритиковала то, что облака HPC могут выделять вычислительные узлы клиентам, находящимся далеко друг от друга, что приводит к задержке, которая снижает производительность некоторых приложений HPC. [101]
Измерение производительности [ править ]
Возможности и возможности [ править ]
Суперкомпьютеры обычно стремятся к максимальным вычислительным возможностям, а не к вычислительной мощности. Под вычислением возможностей обычно понимают использование максимальной вычислительной мощности для решения одной большой проблемы за кратчайший промежуток времени. Часто система возможностей способна решить проблему такого размера или сложности, которую не может решить ни один другой компьютер, например, очень сложное приложение для моделирования погоды . [102]
Напротив, емкостные вычисления обычно рассматриваются как использование эффективных и экономичных вычислительных мощностей для решения нескольких довольно крупных проблем или множества небольших проблем. [102] Архитектуры, которые позволяют поддерживать множество пользователей при выполнении рутинных повседневных задач, могут иметь большую мощность, но обычно не считаются суперкомпьютерами, поскольку они не решают ни одной очень сложной проблемы. [102]
Показатели производительности [ править ]
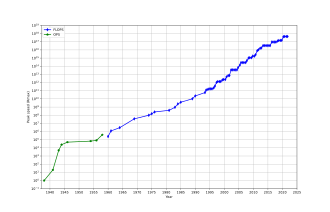
В общем, скорость суперкомпьютеров измеряется и оценивается в FLOPS (операциях с плавающей запятой в секунду), а не в MIPS (миллионе инструкций в секунду), как в случае с компьютерами общего назначения. [103] Эти измерения обычно используются с префиксом SI, например, тера- , объединенным в сокращенное обозначение TFLOPS (10 12 FLOPS, произносится как терафлопс ), или пета- , в сочетании с сокращением PFLOPS (10 15 ФЛОПС, ярко выраженные петафлопы .) Суперкомпьютеры петафлопа могут обрабатывать один квадриллион (10 15 ) (1000 триллионов) ФЛОПС. Эксафлопс — это вычислительная производительность в диапазоне экзафлопс (EFLOPS). ЭФЛОПС — это один квинтиллион (10 18 ) FLOPS (миллион терафлопс). Однако, как упоминали Брем и Брювилер (2015), на производительность суперкомпьютера могут серьезно повлиять колебания, вызванные такими элементами, как загрузка системы, сетевой трафик и параллельные процессы. [104]
Ни одно число не может отразить общую производительность компьютерной системы, однако цель теста Linpack — приблизительно оценить, насколько быстро компьютер решает числовые задачи, и он широко используется в отрасли. [105] Измерение FLOPS указывается либо на основе теоретической производительности процессора с плавающей запятой (полученной из спецификаций процессора производителя и обозначенной как «Rpeak» в списках TOP500), что обычно недостижимо при выполнении реальных рабочих нагрузок, либо на достижимой пропускной способности, полученной из в тестах LINPACK и отображается как «Rmax» в списке TOP500. [106] Тест LINPACK обычно выполняет LU-разложение большой матрицы. [107] Производительность LINPACK дает некоторое представление о производительности для некоторых реальных задач, но не обязательно соответствует требованиям к обработке многих других рабочих нагрузок суперкомпьютера, которые, например, могут требовать большей пропускной способности памяти, или могут требовать более высокой производительности целочисленных вычислений, или могут нуждаться в более высокой производительности целочисленных вычислений. высокопроизводительная система ввода-вывода для достижения высокого уровня производительности. [105]
Список ТОП500 [ править ]

С 1993 года самые быстрые суперкомпьютеры входят в список TOP500 по результатам тестов LINPACK . Список не претендует на беспристрастность или окончательность, но это широко цитируемое современное определение «самого быстрого» суперкомпьютера, доступного в любой момент времени.
Это недавний список компьютеров, которые оказались на вершине списка TOP500 . [108] а «Пиковая скорость» указывается как рейтинг «Rmax». В 2018 году Lenovo стала крупнейшим в мире поставщиком суперкомпьютеров из ТОП-500, выпустив 117 единиц. [109]
| Ранг (предыдущий) | Рмакс Рпик (Пета ФЛОПС ) | Имя | Модель | Ядра процессора | Ядра ускорителя (например, графического процессора) | Межсоединение | Производитель | Сайт страна | Год | Операционная система |
|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 1,102.00 1,685.65 | Граница | HPE Cray EX235a | 591,872 (9248 × 64-ядерный оптимизированный EPYC 64C 3-го поколения с частотой 2,0 ГГц) | 36 992 × 220 AMD Instinct MI250X | Рогатка-11 | HPE | Окриджская национальная лаборатория | 2022 | Linux ( ОС HPE Cray ) |
| 2 | 442.010 537.212 | Фугаку | Суперкомпьютер Фугаку | 7,630,848 (158 976 × 48-ядерный Fujitsu A64FX @ 2,2 ГГц) | 0 | Тофу межсоединение D | Фуджицу | Центр вычислительных наук RIKEN | 2020 | Линукс ( RHEL ) |
| 3 | 309.10 428.70 | КОМНАТА | HPE Cray EX235a | 150,528 (2352 × 64-ядерный оптимизированный EPYC 64C 3-го поколения с частотой 2,0 ГГц) | 9408 × 220 AMD Instinct MI250X | Рогатка-11 | HPE | EuroHPC Ю Каяани | 2022 | Linux ( ОС HPE Cray ) |
| 4 | 174.70 255.75 | Леонардо | БуллСеквана XH2000 | 110,592 (3456 × 32-ядерный процессор Xeon Platinum 8358 @ 2,6 ГГц) | 13 824 × 108 Nvidia Ampere A100 | NVIDIA HDR100 Infiniband | Действия | EuroHPC JU Болонья | 2022 | Линукс |
| 5 | 148.60 200.795 | Саммит | IBM Power System AC922 | 202,752 (9216 × 22-ядерный IBM POWER9 @ 3,07 ГГц) | 27 648 × 80 NVIDIA Tesla V100 | InfiniBand EDR | ИБМ | Окриджская национальная лаборатория | 2018 | Linux ( RHEL 7.4) |
| 6 | 94.640 125.712 | Сьерра | IBM Power System S922LC | 190,080 (8640 × 22-ядерный IBM POWER9 @ 3,1 ГГц) | 17 280 × 80 NVIDIA Tesla V100 | InfiniBand EDR | ИБМ | Ливерморская национальная лаборатория Лоуренса | 2018 | Линукс ( RHEL ) |
| 7 | 93.015 125.436 | SunwayТайхуСвет | Санвей МПП | 10,649,600 (40 960 × 260 ядер Sunway SW26010 @ 1,45 ГГц) | 0 | Санвей [111] | НРКПК | Национальный суперкомпьютерный центр в Уси | 2016 | Linux (RaiseOS 2.0.5) |
| 8 | 70.87 93.75 | Перлмуттер | HPE Cray EX235n | ? × ?-ядерный AMD Epyc 7763, 64 ядра, 2,45 ГГц | ? × 108 NVIDIA Ампер А100 | Рогатка-10 | HPE | НЕРСК | 2021 | Linux ( ОС HPE Cray ) |
| 9 | 63.460 79.215 | Селена | Нвидиа | 71,680 (1120 × 64-ядерный процессор AMD Epyc 7742 @ 2,25 ГГц) | 4480 × 108 Nvidia Ampere A100 | Mellanox HDR Infiniband | Нвидиа | Нвидиа | 2020 | Linux ( Убунту 20.04.1 ) |
| 10 | 61.445 100.679 | Тяньхэ-2 А | TH-IVB-FEP | 427,008 (35 584 × 12-ядерный процессор Intel Xeon E5–2692 v2 @ 2,2 ГГц) | 35 584 × Матрица-2000 [112] 128-ядерный | ТД Экспресс-2 | НУДТ | Национальный суперкомпьютерный центр в Гуанчжоу | 2018 [113] | Линукс ( Килин ) |
Приложения [ править ]
Этот раздел нуждается в расширении . Вы можете помочь, добавив к нему . ( январь 2020 г. ) |
Этапы применения суперкомпьютера можно резюмировать в следующей таблице:
| Десятилетие | Использование и использование компьютера |
|---|---|
| 1970-е годы | Прогноз погоды, аэродинамические исследования ( Крей-1 ). [114] |
| 1980-е годы | Вероятностный анализ, [115] моделирование радиационной защиты [116] ( ЦКЗ Сайбер ). |
| 1990-е годы | Взлом кода методом грубой силы ( взломщик EFF DES ). [117] |
| 2000-е | Трехмерное моделирование ядерных испытаний как замена законному поведению Договор о нераспространении ядерного оружия ( ASCI Q ). [118] |
| 2010-е годы | Моделирование молекулярной динамики ( Тяньхэ-1А ) [119] |
| 2020-е годы | Научные исследования для предотвращения вспышек заболеваний/Исследование электрохимических реакций [120] |
Компьютер IBM Blue Gene /P использовался для моделирования количества искусственных нейронов, эквивалентного примерно одному проценту коры головного мозга человека, содержащего 1,6 миллиарда нейронов с примерно 9 триллионами связей. Той же исследовательской группе также удалось с помощью суперкомпьютера смоделировать количество искусственных нейронов, эквивалентное всему мозгу крысы. [121]
Современное прогнозирование погоды также опирается на суперкомпьютеры. Национальное управление океанических и атмосферных исследований использует суперкомпьютеры для обработки сотен миллионов наблюдений, чтобы сделать прогнозы погоды более точными. [122]
В 2011 году проблемы и трудности в развитии суперкомпьютеров были подчеркнуты петамасштабного отказом IBM от проекта Blue Waters . [123]
Программа расширенного моделирования и вычислений в настоящее время использует суперкомпьютеры для обслуживания и моделирования ядерного арсенала Соединенных Штатов. [124]
В начале 2020 года COVID-19 был в центре внимания в мире. Суперкомпьютеры использовали различные методы моделирования, чтобы найти соединения, которые потенциально могли бы остановить распространение. Эти компьютеры работают десятки часов, используя несколько параллельно работающих процессоров для моделирования различных процессов. [125] [126] [127]

и Развитие тенденции
В 2010-х годах Китай, США, Европейский Союз и другие страны боролись за право первыми создать 1 экзафлопс (10 18 или один квинтиллион ФЛОПС) суперкомпьютера. [128] Эрик П. ДеБенедиктис из Sandia National Laboratories предположил, что зеттафлопс (10 21 или один секстиллион ФЛОПС) требуется компьютер для выполнения полного моделирования погоды , которое может точно охватить двухнедельный период времени. [129] [130] [131] Такие системы могут быть построены примерно к 2030 году. [132]
Во многих симуляциях Монте-Карло используется один и тот же алгоритм для обработки случайно сгенерированного набора данных; в частности, интегро-дифференциальные уравнения, описывающие физические процессы переноса , случайные пути , столкновения, а также выделение энергии и импульса нейтронов, фотонов, ионов, электронов и т. д. Следующим шагом для микропроцессоров может стать переход в третье измерение ; а благодаря специализации Монте-Карло многие слои могут быть идентичными, что упрощает процесс проектирования и производства. [133]
Стоимость эксплуатации высокопроизводительных суперкомпьютеров выросла, в основном из-за увеличения энергопотребления. В середине 1990-х годов 10 лучших суперкомпьютеров требовали мощность в пределах 100 киловатт, а в 2010 году 10 лучших суперкомпьютеров требовали от 1 до 2 мегаватт. [134] Исследование 2010 года, проведенное по заказу DARPA, определило энергопотребление как наиболее распространенную проблему на пути к достижению экзафлопсных вычислений . [135] В то время мегаватт энергопотребления в год стоил около 1 миллиона долларов. Суперкомпьютерные мощности были построены для эффективного отвода растущего количества тепла, выделяемого современными многоядерными центральными процессорами . Судя по энергопотреблению суперкомпьютеров из списка Green 500 в период с 2007 по 2011 год, суперкомпьютер с производительностью 1 экзафлопс в 2011 году потребовал бы почти 500 мегаватт. Операционные системы были разработаны для существующего оборудования, чтобы по возможности экономить энергию. [136] Ядра ЦП, не используемые во время выполнения параллельного приложения, были переведены в режим пониженного энергопотребления, что привело к экономии энергии для некоторых суперкомпьютерных приложений. [137]
Растущая стоимость эксплуатации суперкомпьютеров стала движущим фактором тенденции к объединению ресурсов через распределенную суперкомпьютерную инфраструктуру. Национальные суперкомпьютерные центры сначала появились в США, затем в Германии и Японии. Европейский Союз запустил Партнерство по передовым вычислениям в Европе (PRACE) с целью создания постоянной общеевропейской суперкомпьютерной инфраструктуры с услугами для поддержки ученых по всему Европейскому Союзу в портировании, масштабировании и оптимизации суперкомпьютерных приложений. [134] Исландия построила первый в мире суперкомпьютер с нулевым уровнем выбросов. Этот суперкомпьютер, расположенный в центре обработки данных Thor в Рейкьявике , Исландия, использует полностью возобновляемые источники энергии, а не ископаемое топливо. Более холодный климат также снижает потребность в активном охлаждении, что делает его одним из самых экологически чистых предприятий в мире компьютеров. [138]
Финансирование суперкомпьютерного оборудования также становилось все труднее. В середине 1990-х годов 10 лучших суперкомпьютеров стоили около 10 миллионов евро, а в 2010 году 10 лучших суперкомпьютеров требовали инвестиций в размере от 40 до 50 миллионов евро. [134] В 2000-х годах национальные правительства разработали различные стратегии финансирования суперкомпьютеров. В Великобритании национальное правительство полностью финансировало суперкомпьютеры, а высокопроизводительные вычисления были поставлены под контроль национального финансового агентства. Германия разработала смешанную модель финансирования, объединяющую местное государственное финансирование и федеральное финансирование. [134]
В художественной литературе [ править ]
Примеры суперкомпьютеров в художественной литературе включают HAL 9000 , Multivac , The Machine Stops , GLaDOS , The Evitable Conflict , Vulcan's Hammer , Colossus , WOPR , AM и Deep Thought . Cray X-MP упоминался как суперкомпьютер, используемый для секвенирования ДНК, извлеченной из сохранившихся паразитов в сериале «Парк Юрского периода» .
См. также [ править ]
- Конференция по суперкомпьютерам ACM/IEEE
- ACM SIGHPC
- Высокопроизводительные вычисления
- Высокопроизводительные технические вычисления
- Джунглевые вычисления
- Персональный суперкомпьютер Nvidia Tesla
- Параллельные вычисления
- Суперкомпьютеры в Китае
- Суперкомпьютеры в Европе
- Суперкомпьютеры в Индии
- Суперкомпьютеры в Японии
- Тестирование высокопроизводительных вычислительных приложений
- Ультра сетевые технологии
- Квантовые вычисления
Ссылки [ править ]
- ^ «Анонс IBM Blue Gene» . 03.ibm.com. 26 июня 2007 года . Проверено 9 июня 2012 года .
- ^ «Бесстрашный» . Аргоннский вычислительный центр для руководителей . Аргоннская национальная лаборатория . Архивировано из оригинала 7 мая 2013 года . Проверено 26 марта 2020 г. .
- ^ «Список: июнь 2018» . Топ 500 . Проверено 25 июня 2018 г.
- ^ «Характеристики графического процессора AMD Playstation 5» . TechPowerUp . Проверено 11 сентября 2021 г.
- ^ «Характеристики NVIDIA GeForce GT 730» . TechPowerUp . Проверено 11 сентября 2021 г.
- ^ «Семейство операционных систем/Linux» . TOP500.org . Проверено 30 ноября 2017 г.
- ↑ Андерсон, Марк (21 июня 2017 г.). «Глобальная гонка за экзафлопсом приведет к массовому распространению суперкомпьютеров и искусственного интеллекта». Spectrum.IEEE.org . Проверено 20 января 2019 г.
- ^ Лемке, Тим (8 мая 2013 г.). «АНБ прокладывает путь к созданию массивного вычислительного центра» . Проверено 11 декабря 2013 г.
- ↑ Перейти обратно: Перейти обратно: а б Хоффман, Аллан Р.; и др. (1990). Суперкомпьютеры: направления в технологиях и приложениях . Национальные академии. стр. 35–47. ISBN 978-0-309-04088-4 .
- ↑ Перейти обратно: Перейти обратно: а б Хилл, Марк Дональд; Жуппи, Норман Пол ; Сохи, Гуриндар (1999). Чтения по компьютерной архитектуре . Галф Профессионал. стр. 40–49. ISBN 978-1-55860-539-8 .
- ^ Пол Алкорн (30 мая 2022 г.). «Суперкомпьютер Frontier на базе AMD преодолевает экзафлопсный барьер и теперь является самым быстрым в мире» . Аппаратное обеспечение Тома . Проверено 30 мая 2022 г.
- ^ «Япония завоевала корону TOP500 с помощью суперкомпьютера на базе ручного привода — веб-сайт TOP500» . www.top500.org .
- ^ «Развитие производительности» . www.top500.org . Проверено 27 октября 2022 г.
- ^ Эрик Г. Сведин; Дэвид Л. Ферро (2007). Компьютеры: история жизни технологии . Джу Пресс. п. 57. ИСБН 9780801887741 .
- ^ Эрик Г. Сведин; Дэвид Л. Ферро (2007). Компьютеры: история жизни технологии . Джу Пресс. п. 56. ИСБН 9780801887741 .
- ^ Эрик Г. Сведин; Дэвид Л. Ферро (2007). Компьютеры: история жизни технологии . Джу Пресс. п. 58. ИСБН 9780801887741 .
- ^ Атлас , Манчестерский университет, заархивировано из оригинала 28 июля 2012 года , получено 21 сентября 2010 года.
- ^ Супермены , Чарльз Мюррей, Wiley & Sons, 1997.
- ^ Пол Э. Серуцци (2003). История современных вычислений . МТИ Пресс. п. 161 . ISBN 978-0-262-53203-7 .
- ↑ Перейти обратно: Перейти обратно: а б Ханнан, Кэрин (2008). Биографический словарь Висконсина . Государственные исторические публикации. стр. 83–84. ISBN 978-1-878592-63-7 .
- ^ Джон Импальяццо; Джон А.Н. Ли (2004). История информатики в образовании . Springer Science & Business Media. п. 172 . ISBN 978-1-4020-8135-4 .
- ^ Эндрю Р.Л. Кейтон; Ричард Сиссон; Крис Захер (2006). Средний Запад Америки: Интерпретационная энциклопедия . Издательство Университета Индианы. п. 1489. ИСБН 978-0-253-00349-2 .
- ^ Чтения по компьютерной архитектуре Марка Дональда Хилла, Нормана Пола Джуппи, Гуриндара Сохи, 1999 г. ISBN 978-1-55860-539-8 стр. 41-48
- ^ Вехи в области информатики и информационных технологий Эдвина Д. Рейли, 2003 г. ISBN 1-57356-521-0 стр. 65
- ↑ Из-за советской пропаганды иногда можно прочитать, что советский суперкомпьютер М13 первым достиг барьера гигафлопс. Вообще-то строительство М13 началось в 1984 году, но до 1986 года оно не вводилось в эксплуатацию. Рогачев Юрий Васильевич, Русский Виртуальный Компьютерный Музей
- ^ «Цитаты Сеймура Крея» . BrainyЦитата .
- ^ Стив Нельсон (3 октября 2014 г.). «ComputerGK.com: Суперкомпьютеры» .
- ^ «Система компьютерной графики LINKS-1-Компьютерный музей» . Museum.ipsj.or.jp .
- ^ «VPP500 (1992 г.) — Fujitsu Global» .
- ^ «Годовой отчет ТОП500 за 1994 год» . Netlib.org. 1 октября 1996 года . Проверено 9 июня 2012 года .
- ^ Н. Хиросе и М. Фукуда (1997). «Численная аэродинамическая труба (СЗТ) и исследования CFD в Национальной аэрокосмической лаборатории». Труды Высокопроизводительные вычисления на информационной супермагистрали. HPC Азия '97 . Труды HPC-Азия '97. Страницы компьютерного общества IEEE. стр. 99–103. дои : 10.1109/HPC.1997.592130 . ISBN 0-8186-7901-8 .
- ^ Х. Фуджи, Ю. Ясуда, Х. Акаши, Ю. Инагами, М. Кога, О. Исихара, М. Сьязван, Х. Вада, Т. Сумимото, Архитектура и производительность массивно-параллельной процессорной системы Hitachi SR2201 , Материалы 11-го Международного симпозиума по параллельной обработке, апрель 1997 г., страницы 233–241.
- ^ Ю. Ивасаки, Проект CP-PACS, Ядерная физика B: Дополнения к материалам, том 60, выпуски 1–2, январь 1998 г., страницы 246–254.
- ^ Эй Джей ван дер Стин, Обзор новейших суперкомпьютеров , Публикация NCF, Stichting Nationale Computer Estates, Нидерланды, январь 1997 г.
- ^ Масштабируемый ввод/вывод: достижение баланса системы Дэниел А. Рид, 2003 г. ISBN 978-0-262-68142-1 стр. 182
- ^ «Дэвид Бейдер выбран лауреатом премии Сидни Фернбаха от компьютерного общества IEEE 2021 года» . Компьютерное общество IEEE. 22 сентября 2021 г. Проверено 12 октября 2023 г.
- ↑ Перейти обратно: Перейти обратно: а б с Бадер, Дэвид А. (2021). «Linux и суперкомпьютеры: как моя страсть к созданию COTS-систем привела к революции высокопроизводительных вычислений» . IEEE Анналы истории вычислений . 43 (3): 73–80. дои : 10.1109/MAHC.2021.3101415 . S2CID 237318907 .
- ^ Флек, Джон (8 апреля 1999 г.). «UNM сегодня запустит суперкомпьютер стоимостью 400 000 долларов» . Журнал Альбукерке . п. Д1.
- ^ Продан, Раду; Фарингер, Томас (2007). Грид-вычисления: управление экспериментами, интеграция инструментов и научные рабочие процессы . Спрингер. стр. 1–4 . ISBN 978-3-540-69261-4 .
- ^ Найт, Уилл: « IBM создает самый мощный компьютер в мире », служба новостей NewScientist.com , июнь 2007 г.
- ^ Н.Р. Агида; и др. (2005). «Сеть межсоединений Blue Gene/L Torus | Журнал исследований и разработок IBM» (PDF) . Сеть межсоединений тора . п. 265. Архивировано из оригинала (PDF) 15 августа 2011 года.
- ^ Ню, Янвэй; Ху, Цзян; Барнер, Кеннет ; Гао, Гуан Р. (2005). «Моделирование производительности и оптимизация доступа к памяти на клеточной компьютерной архитектуре Cyclops64» (PDF) . Сетевые и параллельные вычисления . Конспекты лекций по информатике. Том. 3779. стр. 132–143. дои : 10.1007/11577188_18 . ISBN 978-3-540-29810-6 . Архивировано (PDF) из оригинала 9 октября 2022 года.
- ^ Анализ и результаты производительности вычислений по принципу централизации посредничества на IBM Cyclops64 , авторы Гуанмин Тан, Вугранам К. Сридхар и Гуан Р. Гао. Журнал суперкомпьютеров , том 56, номер 1, 1–24 сентября 2011 г.
- ^ Прикетт, Тимоти (31 мая 2010 г.). «500 лучших супергероев – Рассвет графических процессоров» . Thereregister.co.uk.
- ^ Ганс Хакер; Карстен Тринитис; Йозеф Вайдендорфер; Матиас Брем (2010). «Рассмотрение GPGPU для центров высокопроизводительных вычислений: стоит ли оно усилий?» . У Райнера Келлера; Дэвид Крамер; Ян-Филипп Вайс (ред.). Решение проблемы многоядерности: аспекты новых парадигм и технологий в параллельных вычислениях . Springer Science & Business Media. стр. 118–121. ISBN 978-3-642-16232-9 .
- ^ Дэймон Потер (11 октября 2011 г.). «Суперкомпьютер Titan компании Cray для ORNL может быть самым быстрым в мире» . Pcmag.com.
- ^ Фельдман, Майкл (11 октября 2011 г.). «Графические процессоры превратят Jaguar от ORNL в Titan с производительностью 20 петафлопс» . Hpcwire.com.
- ^ Тимоти Прикетт Морган (11 октября 2011 г.). «Ок-Ридж меняет акцент Jaguar с центральных процессоров на графические процессоры» . Thereregister.co.uk.
- ^ «Суперкомпьютер NETL». Архивировано 4 сентября 2015 года в Wayback Machine .страница 2.
- ^ Кондон, Дж. Х. и К. Томпсон, « Оборудование Belle Chess », « Достижения в компьютерных шахматах 3 » (изд.MRBClarke), Pergamon Press, 1982.
- ^ Сюй, Фэн-сюн (2002). За Deep Blue: создание компьютера, который победил чемпиона мира по шахматам . Издательство Принстонского университета . ISBN 978-0-691-09065-8 .
- ^ К. Доннингер, У. Лоренц. Шахматный монстр Гидра. Учеб. 14-й Международной конференции по программируемой логике и приложениям (FPL), 2004 г., Антверпен, Бельгия, LNCS 3203, стр. 927–932.
- ^ Дж. Макино и М. Тайджи, Научное моделирование с помощью компьютеров специального назначения: системы GRAPE , Wiley. 1998.
- ^ Пресс-релиз RIKEN, Завершение создания компьютерной системы производительностью один петафлопс для моделирования молекулярной динамики. Архивировано 2 декабря 2012 г. в Wayback Machine.
- ^ Фонд электронных границ (1998). Взлом DES – секреты исследования шифрования, политики прослушивания телефонных разговоров и проектирования чипов . Oreilly & Associates Inc. ISBN 978-1-56592-520-5 .
- ^ Лор, Стив (8 июня 2018 г.). «Подвинься, Китай: США снова стали домом для самого быстрого суперкомпьютера в мире» . Нью-Йорк Таймс . Проверено 19 июля 2018 г.
- ^ «Список Green500 – ноябрь 2018» . ТОП500 . Проверено 19 июля 2018 г.
- ^ Сюэ-Джун Ян; Сян-Ке Ляо; и др. (2011). «Суперкомпьютер TianHe-1A: аппаратное и программное обеспечение». Журнал компьютерных наук и технологий . 26 (3): 344–351. дои : 10.1007/s02011-011-1137-8 . S2CID 1389468 .
- ^ Супермены: История Сеймура Крея и технических волшебников за суперкомпьютером Чарльза Дж. Мюррея 1997, ISBN 0-471-04885-2 , страницы 133–135.
- ^ Параллельная вычислительная динамика жидкости; Последние достижения и будущие направления под редакцией Рупака Бисваса, 2010 г. ISBN 1-60595-022-X стр. 401
- ^ Достижения в области суперкомпьютерных исследований , Юнге Хуанг, 2008 г., ISBN 1-60456-186-6 , страницы 313–314.
- ↑ Перейти обратно: Перейти обратно: а б Параллельные вычисления для обработки сигналов и управления в реальном времени , М.О. Тохи, Мохаммад Аламгир Хоссейн, 2003 г., ISBN 978-1-85233-599-1 , страницы 201–202.
- ↑ Перейти обратно: Перейти обратно: а б Вычислительная наука - ICCS 2005: 5-я международная конференция под редакцией Вайди С. Сундерам 2005, ISBN 3-540-26043-9 , страницы 60–67.
- ^ «Графические процессоры NVIDIA Tesla питают самый быстрый суперкомпьютер в мире» (пресс-релиз). Нвидиа. 29 октября 2010 г. Архивировано из оригинала 2 марта 2014 г. Проверено 21 февраля 2011 г.
- ^ Баландин, Александр А. (октябрь 2009 г.). «Улучшение вычислений благодаря охлаждению процессора» . Spectrum.ieee.org.
- ^ «Зеленые 500» . Green500.org. Архивировано из оригинала 26 августа 2016 года . Проверено 14 августа 2011 г.
- ^ «Зеленый список 500» включает суперкомпьютеры» . iTnews Австралия . Архивировано из оригинала 22 октября 2008 года.
- ^ У-чунь Фэн (2003). «Обоснование эффективности суперкомпьютеров | Журнал ACM Queue, том 1, выпуск 7, 10 января 2003 г., doi 10.1145/957717.957772» . Очередь . 1 (7): 54. дои : 10.1145/957717.957772 . S2CID 11283177 .
- ^ «IBM раскрывает 20 петафлопс BlueGene/Q super» . Регистр . 22 ноября 2010 года . Проверено 25 ноября 2010 г.
- ^ Прикетт, Тимоти (15 июля 2011 г.). « The Register : Суперузел IBM «Blue Waters» выброшен на берег в августе» . Thereregister.co.uk . Проверено 9 июня 2012 года .
- ^ «Суперкомпьютер IBM с водяным охлаждением запускается в ETH Zurich» . Отдел новостей IBM . 2 июля 2010 года. Архивировано из оригинала 10 января 2011 года . Проверено 16 марта 2020 г.
- ^ Мартин ЛаМоника (10 мая 2010 г.). «CNet, 10 мая 2010 г.» . News.cnet.com. Архивировано из оригинала 1 ноября 2013 года . Проверено 9 июня 2012 года .
- ^ «Правительство представляет самый быстрый компьютер в мире» . CNN . Архивировано из оригинала 10 июня 2008 года.
Выполняет 376 миллионов вычислений на каждый ватт использованной электроэнергии.
- ^ «IBM Roadrunner берет золото в гонке петафлопов» . Архивировано из оригинала 17 декабря 2008 года . Проверено 16 марта 2020 г.
- ^ «Список суперкомпьютеров Top500 раскрывает тенденции в области вычислений» . 20 июля 2010 г.
IBM... Система BlueGene/Q... установила рекорд энергоэффективности со значением 1680 MFLOPS/Вт, что более чем в два раза превышает показатель следующей лучшей системы.
- ^ «IBM Research — явный победитель в рейтинге Green 500» . 18 ноября 2010 г.
- ^ «Зеленый список 500» . Green500.org. Архивировано из оригинала 3 июля 2011 года . Проверено 16 марта 2020 г.
- ^ Саед Г. Юнис. «Асимптотически нулевые вычисления с использованием логики восстановления заряда с разделением уровней» .1994.страница 14.
- ^ «Горячая тема — проблема охлаждения суперкомпьютеров». Архивировано 18 января 2015 года в Wayback Machine .
- ^ Ананд Лал Шимпи. «Внутри суперкомпьютера Titan: 299 тысяч ядер AMD x86 и 18,6 тысяч графических процессоров NVIDIA» .2012.
- ^ Кертис Сторли; Джо Секстон; Скотт Пэкин; Майкл Лэнг; Брайан Райх; Уильям Раст. «Моделирование и прогнозирование энергопотребления высокопроизводительных вычислений» .2014.
- ↑ Перейти обратно: Перейти обратно: а б Энциклопедия параллельных вычислений Дэвида Падуа, 2011 г. ISBN 0-387-09765-1 страницы 426–429
- ^ Познание машин: очерки технических изменений Дональда Маккензи, 1998 г. ISBN 0-262-63188-1 стр. 149-151
- ^ Параллельная обработка Euro-Par 2004: 10-я Международная конференция Euro-Par 2004, Марко Данелутто, Марко Ваннески и Доменико Лафоренца, ISBN 3-540-22924-8 , стр. 835.
- ^ Параллельная обработка Euro-Par 2006: 12-я Международная конференция Euro-Par , 2006 г., Вольфганг Э. Нагель, Вольфганг В. Вальтер и Вольфганг Ленер ISBN 3-540-37783-2 стр.
- ^ Оценка Национальной лаборатории Ок-Ридж Cray XT3, проведенная Садафом Р. Аламом и др. Международный журнал приложений для высокопроизводительных вычислений, февраль 2008 г., том. 22 нет. 1 52–80
- ^ Открытая архитектура управления заданиями для суперкомпьютера Blue Gene/L, автор Ярив Аридор и др. в книге «Стратегии планирования заданий для параллельной обработки» , Дрор Г. Фейтельсон, 2005 г. ISBN 978-3-540-31024-2 страницы 95–101
- ^ «Топ500 чарт ОС» . Топ500.org. Архивировано из оригинала 5 марта 2012 года . Проверено 31 октября 2010 г.
- ^ «Широкоугольный вид коррелятора АЛМА» . Пресс-релиз ESO . Проверено 13 февраля 2013 г.
- ^ Нильсен, Франк (2016). Введение в HPC с MPI для науки о данных . Спрингер. стр. 185–221. ISBN 978-3-319-21903-5 .
- ^ Рахат, Назмул. «Глава 03 Программное обеспечение и управление системой» .
- ^ Лаборатория Панде. «Статистика клиентов по ОС» . Складной@дома . Стэнфордский университет . Проверено 10 апреля 2020 г.
- ^ «БОИНК Комбинированный» . BOINCстатистика . БОИНК . Архивировано из оригинала 19 сентября 2010 года . Проверено 30 октября 2016 г. Обратите внимание, что по этой ссылке будет представлена текущая статистика, а не статистика на дату последнего доступа.
{{cite web}}: CS1 maint: постскриптум ( ссылка ) - ^ «Технология распределенных вычислений Internet PrimeNet Server для эффективного поиска простых чисел Мерсенна в Интернете» . ГИМПЫ . Проверено 6 июня 2011 г.
- ↑ Перейти обратно: Перейти обратно: а б Кравцов, Валентин; Кармели, Дэвид; Дубицкий, Вернер; Орда, Ариэль; Шустер, Ассаф ; Йошпа, Бенни. «Квазиоппортунистические суперкомпьютеры в сетках, актуальная тема (2007)» . Международный симпозиум IEEE по высокопроизводительным распределенным вычислениям . IEEE. CiteSeerX 10.1.1.135.8993 . Проверено 4 августа 2011 г.
{{cite web}}: CS1 maint: несколько имен: список авторов ( ссылка ) - ^ Джамалян, С.; Раджаи, Х. (1 марта 2015 г.). «ASETS: система планирования задач на базе SDN для HPCaaS в облаке». Международная конференция IEEE 2015 по облачной инженерии . стр. 329–334. дои : 10.1109/IC2E.2015.56 . ISBN 978-1-4799-8218-9 . S2CID 10974077 .
- ^ Джамалян, С.; Раджаи, Х. (1 июня 2015 г.). «Планирование задач HPC с интенсивным использованием данных с помощью SDN для реализации HPC как услуги». 2015 8-я Международная конференция IEEE по облачным вычислениям . стр. 596–603. дои : 10.1109/ОБЛАКО.2015.85 . ISBN 978-1-4673-7287-9 . S2CID 10141367 .
- ^ Гупта, А.; Миложич, Д. (1 октября 2011 г.). «Оценка приложений HPC в облаке». 2011 Шестой открытый саммит Cirrus . стр. 22–26. CiteSeerX 10.1.1.294.3936 . дои : 10.1109/OCS.2011.10 . ISBN 978-0-7695-4650-6 . S2CID 9405724 .
- ^ Ким, Х.; эль-Хамра, Ю.; Джа, С.; Парашар, М. (1 декабря 2009 г.). «Автономный подход к интегрированному использованию высокопроизводительных сетей и облаков». 2009 Пятая Международная конференция IEEE по электронной науке . стр. 366–373. CiteSeerX 10.1.1.455.7000 . doi : 10.1109/e-Science.2009.58 . ISBN 978-1-4244-5340-5 . S2CID 11502126 .
- ^ Идлайн, Дуглас. «Перенос HPC в облако» . Журнал Админ . Проверено 30 марта 2019 г.
- ^ Николаи, Джеймс (11 августа 2009 г.). «Penguin переносит высокопроизводительные вычисления в облако» . ПКМир . IDG для потребителей и малого и среднего бизнеса . Проверено 6 июня 2016 г.
- ↑ Перейти обратно: Перейти обратно: а б с Потенциальное влияние высокопроизводительных вычислений на четыре показательные области науки и техники, проведенное Комитетом по потенциальному влиянию высокопроизводительных вычислений на показательные области науки и техники и Национальным исследовательским советом (28 октября 2008 г.) ISBN 0-309-12485-9 стр. 9
- ^ Синфу Ву (1999). Оценка производительности, прогнозирование и визуализация параллельных систем . Springer Science & Business Media. стр. 114–117. ISBN 978-0-7923-8462-5 .
- ^ Брем, М. и Брювилер,DL (2015) «Рабочие характеристики ускорения плазменного вейкфилда, вызванного сгустками протонов». Физический журнал: серия конференций
- ↑ Перейти обратно: Перейти обратно: а б Донгарра, Джек Дж.; Лущек, Петр; Петите, Антуан (2003), «Бенчмарк LINPACK: прошлое, настоящее и будущее» (PDF) , Параллелизм и вычисления: практика и опыт , 15 (9): 803–820, doi : 10.1002/cpe.728 , S2CID 1900724
- ^ «Понимание показателей производительности суперкомпьютера и емкости системы хранения» . Университет Индианы . Проверено 3 декабря 2017 г.
- ^ «Часто задаваемые вопросы» . TOP500.org . Проверено 3 декабря 2017 г.
- ^ Брошюра Intel – 11/91. «Страница каталога списков Top500. Результаты по каждому списку с июня 1993 года» . Топ500.org. Архивировано из оригинала 18 декабря 2010 года . Проверено 31 октября 2010 г.
{{cite web}}: CS1 maint: числовые имена: список авторов ( ссылка ) - ^ «Lenovo завоевала статус крупнейшего мирового поставщика суперкомпьютеров из ТОП-500» . Деловой провод . 25 июня 2018 г.
- ^ «Ноябрь 2022 | ТОП500» . www.top500.org . Проверено 7 декабря 2022 г.
- ↑ Перейти обратно: Перейти обратно: а б «Китай возглавил рейтинг суперкомпьютеров с новой машиной с производительностью 93 петафлопс | TOP500» . www.top500.org .
- ^ «Матрица-2000 — НУДТ — WikiChip» . ru.wikichip.org . Проверено 19 июля 2019 г.
- ^ «Тяньхэ-2А — Кластер TH-IVB-FEP, Intel Xeon E5-2692v2 12C 2,2 ГГц, TH Express-2, Matrix-2000 | ТОП500 сайтов суперкомпьютеров» . www.top500.org . Проверено 16 ноября 2022 г.
- ^ «Компьютерная система Cray-1» (PDF) . Cray Research, Inc. Архивировано (PDF) оригиналом 9 октября 2022 года . Проверено 25 мая 2011 г.
- ^ Джоши, Раджани Р. (9 июня 1998 г.). «Новый эвристический алгоритм вероятностной оптимизации». Компьютеры и исследования операций . 24 (7): 687–697. дои : 10.1016/S0305-0548(96)00056-1 .
- ^ «Реферат по SAMSY - Модульная система анализа экранирования» . Агентство по ядерной энергии ОЭСР, Исси-ле-Мулино, Франция . Проверено 25 мая 2011 г.
- ^ «Исходный код EFF DES Cracker» . Cosic.esat.kuleuven.be . Проверено 8 июля 2011 г.
- ^ «Дипломатия разоружения: Программа суперкомпьютеров и моделирования испытаний Министерства энергетики США» . Acronym.org.uk. 22 августа 2000 года. Архивировано из оригинала 16 мая 2013 года . Проверено 8 июля 2011 г.
- ^ «Инвестиции Китая в суперкомпьютеры на графических процессорах начинают окупаться!» . Блоги.nvidia.com. Архивировано из оригинала 5 июля 2011 года . Проверено 8 июля 2011 г.
- ^ Эндрю, Скотти (19 марта 2020 г.). «Самый быстрый в мире суперкомпьютер определил химические вещества, которые могут остановить распространение коронавируса, что является важным шагом на пути к лечению» . CNN . Проверено 12 мая 2020 г.
- ^ Каку, Мичио. Физика будущего (Нью-Йорк: Doubleday, 2011), 65.
- ^ «Более быстрые суперкомпьютеры помогают прогнозировать погоду» . Новости.nationalgeographic.com. 28 октября 2010 г. Архивировано из оригинала 5 сентября 2005 г. Проверено 8 июля 2011 г.
- ^ «IBM отказывается от проекта суперкомпьютера Blue Waters» . Интернэшнл Бизнес Таймс . 9 августа 2011 года . Проверено 14 декабря 2018 г. – через EBSCO (требуется подписка)
- ^ «Суперкомпьютеры» . Министерство энергетики США . Архивировано из оригинала 7 марта 2017 года . Проверено 7 марта 2017 г.
- ^ «Суперкомпьютерное моделирование помогает продвигать исследования электрохимических реакций» . ucsdnews.ucsd.edu . Проверено 12 мая 2020 г.
- ^ «Саммит IBM — суперкомпьютеры борются с коронавирусом» . Электронный журнал MedicalExpo . 16 апреля 2020 г. Проверено 12 мая 2020 г.
- ^ «OSTP финансирует суперкомпьютерные исследования для борьбы с COVID-19 – MeriTalk» . Проверено 12 мая 2020 г.
- ^ «Проект суперкомпьютера стоимостью 1,2 ЕС для нескольких 10-100 компьютеров PetaFLOP к 2020 году и exaFLOP к 2022 году | NextBigFuture.com» . NextBigFuture.com . 4 февраля 2018 года . Проверено 21 мая 2018 г.
- ^ ДеБенедиктис, Эрик П. (2004). «Путь к экстремальным вычислениям» (PDF) . Зеттафлопс . Сандианские национальные лаборатории. Архивировано из оригинала (PDF) 3 августа 2007 года . Проверено 9 сентября 2020 г.
- ^ Коэн, Реувен (28 ноября 2013 г.). «Глобальная вычислительная мощность биткойнов теперь в 256 раз быстрее, чем у 500 лучших суперкомпьютеров вместе взятых!» . Форбс . Проверено 1 декабря 2017 г.
- ^ ДеБенедиктис, Эрик П. (2005). «Обратимая логика для суперкомпьютеров» . Материалы 2-й конференции по передовым технологиям . АКМ Пресс. стр. 391–402. ISBN 978-1-59593-019-4 .
- ^ «IDF: Intel заявляет, что закон Мура будет действовать до 2029 года» . Хейзе онлайн . 4 апреля 2008 г. Архивировано из оригинала 8 декабря 2013 г.
- ^ Солем, Дж. К. (1985). «MECA: концепция мультипроцессора, специализированная для Монте-Карло» . Методы Монте-Карло и их приложения в нейтронике, фотонике и статистической физике . Конспект лекций по физике. Том. 240. Материалы совместной встречи Лос-Аламосской национальной лаборатории и Комиссариата по атомной энергии, состоявшейся в замке Кадараш, Прованс, Франция, 22–26 апреля 1985 г.; Методы Монте-Карло и их применения в нейтронике, фотонике и статистической физике, Алькуфф, Р.; Дотрей, Р.; Форстер, А.; Форстер, Г.; Мерсье, Б.; Ред. (Springer Verlag, Берлин). стр. 184–195. Бибкод : 1985ЛНП...240..184С . дои : 10.1007/BFb0049047 . ISBN 978-3-540-16070-0 . ОСТИ 5689714 .
- ↑ Перейти обратно: Перейти обратно: а б с д Яннис Котронис; Энтони Даналис; Димитрис Николопулос; Джек Донгарра (2011). Последние достижения в интерфейсе передачи сообщений: 18-е собрание европейской группы пользователей MPI, EuroMPI 2011, Санторини, Греция, 18-21 сентября 2011 г. Материалы . Springer Science & Business Media. ISBN 9783642244483 .
- ^ Джеймс Х. Ларос III; Кевин Педретти; Сюзанна М. Келли; Вэй Шу; Курт Феррейра; Джон Ван Дайк; Кортни Вон (2012). Энергоэффективные высокопроизводительные вычисления: измерение и настройка . Springer Science & Business Media. п. 1 . ISBN 9781447144922 .
- ^ Джеймс Х. Ларос III; Кевин Педретти; Сюзанна М. Келли; Вэй Шу; Курт Феррейра; Джон Ван Дайк; Кортни Вон (2012). Энергоэффективные высокопроизводительные вычисления: измерение и настройка . Springer Science & Business Media. п. 2 . ISBN 9781447144922 .
- ^ Джеймс Х. Ларос III; Кевин Педретти; Сюзанна М. Келли; Вэй Шу; Курт Феррейра; Джон Ван Дайк; Кортни Вон (2012). Энергоэффективные высокопроизводительные вычисления: измерение и настройка . Springer Science & Business Media. п. 3 . ISBN 9781447144922 .
- ^ «Зеленый суперкомпьютер обрабатывает большие данные в Исландии» . intelfreepress.com . 21 мая 2015 года. Архивировано из оригинала 20 мая 2015 года . Проверено 18 мая 2015 г.
Внешние ссылки [ править ]
- Макдоннелл, Маршалл Т. (2013). «Проектирование суперкомпьютера: первоначальная попытка учесть экологические, экономические и социальные последствия» . Публикации по химической и биомолекулярной инженерии и другие работы.
компьютеров Размеры и классы |
|---|