Анализ главных компонентов
| Часть серии о |
| Машинное обучение и интеллектуальный анализ данных |
|---|
Анализ главных компонентов ( PCA ) — это метод уменьшения линейной размерности , который применяется в исследовательском анализе данных , визуализации и предварительной обработке данных .
Данные линейно преобразуются в новую систему координат, так что можно легко определить направления (главные компоненты), отражающие наибольшее изменение данных.
Главными компонентами набора точек в реальном координатном пространстве являются последовательность единичные векторы , где -th вектор — это направление линии, которое лучше всего соответствует данным, будучи ортогональным первому. векторы. Здесь наиболее подходящая линия определяется как линия, которая минимизирует средний квадрат перпендикулярного расстояния от точек до линии . Эти направления (т.е. главные компоненты) составляют ортонормированный базис , в котором различные отдельные измерения данных линейно некоррелированы . Во многих исследованиях первые два основных компонента используются для отображения данных в двух измерениях и визуальной идентификации кластеров тесно связанных точек данных. [ 1 ]




Анализ главных компонентов находит применение во многих областях, таких как популяционная генетика , исследования микробиома и наука об атмосфере .
Обзор
[ редактировать ]При выполнении PCA первый главный компонент набора переменные — это производная переменная, сформированная как линейная комбинация исходных переменных, которая объясняет наибольшую дисперсию. Второй главный компонент объясняет наибольшую дисперсию того, что остается после устранения эффекта первого компонента, и мы можем продолжить итераций до тех пор, пока не будут объяснены все отклонения. PCA чаще всего используется, когда многие переменные сильно коррелируют друг с другом и желательно сократить их количество до независимого набора. Первый главный компонент эквивалентно можно определить как направление, которое максимизирует дисперсию прогнозируемых данных. -ю главную компоненту можно принять как направление, ортогональное первой основные компоненты, которые максимизируют дисперсию прогнозируемых данных.
Для любой цели можно показать, что главные компоненты являются собственными векторами данных ковариационной матрицы . Таким образом, главные компоненты часто вычисляются путем собственного разложения матрицы ковариации данных или по сингулярным значениям разложения матрицы данных . PCA — это самый простой из настоящих многомерных анализов на основе собственных векторов, который тесно связан с факторным анализом . Факторный анализ обычно включает в себя более специфичные для предметной области предположения о базовой структуре и решает собственные векторы немного другой матрицы. PCA также связан с каноническим корреляционным анализом (CCA) . CCA определяет системы координат, которые оптимально описывают взаимную ковариацию между двумя наборами данных, а PCA определяет новую ортогональную систему координат , которая оптимально описывает дисперсию в одном наборе данных. [ 2 ] [ 3 ] [ 4 ] [ 5 ] надежные варианты стандартного PCA , основанные на норме L1 . Также были предложены [ 6 ] [ 7 ] [ 8 ] [ 5 ]
История
[ редактировать ]PCA был изобретен в 1901 году Карлом Пирсоном . [ 9 ] как аналог теоремы о главной оси в механике; Позже он был независимо разработан и назван Гарольдом Хотеллингом в 1930-х годах. [ 10 ] В зависимости от области применения его также называют дискретным преобразованием Карунена-Лоэва (KLT) в обработке сигналов , преобразованием Хотеллинга в многомерном контроле качества, собственным ортогональным разложением (POD) в машиностроении, разложением по сингулярным значениям (SVD) X (изобретен в последней четверти XIX века [ 11 ] ), разложение по собственным значениям (EVD) X Т X в линейной алгебре, факторный анализ (обсуждение различий между PCA и факторным анализом см. в главе 7 « Анализ главных компонентов» Джоллиффа ), [ 12 ] Теорема Эккарта-Янга (Харман, 1960), или эмпирические ортогональные функции (ЭОФ) в метеорологии (Лоренц, 1956), эмпирическое разложение собственных функций (Сирович, 1987), квазигармонические моды (Брукс и др., 1988), спектральное разложение в шуме и вибрация, а также эмпирический модальный анализ в динамике конструкций.
Интуиция
[ редактировать ]PCA можно рассматривать как подгонку p -мерного эллипсоида к данным, где каждая ось эллипсоида представляет собой главный компонент. Если какая-то ось эллипсоида мала, то и дисперсия вдоль этой оси также мала.
Чтобы найти оси эллипсоида, мы должны сначала центрировать значения каждой переменной в наборе данных на 0, вычитая среднее значение наблюдаемых значений переменной из каждого из этих значений. Эти преобразованные значения используются вместо исходных наблюдаемых значений для каждой из переменных. Затем мы вычисляем ковариационную матрицу данных и вычисляем собственные значения и соответствующие собственные векторы этой ковариационной матрицы. Затем мы должны нормализовать каждый из ортогональных собственных векторов, чтобы превратить их в единичные векторы. Как только это будет сделано, каждый из взаимно ортогональных единичных собственных векторов можно будет интерпретировать как ось эллипсоида, подобранного к данным. Этот выбор базиса преобразует ковариационную матрицу в диагональную форму, в которой диагональные элементы представляют дисперсию каждой оси. Доля дисперсии, которую представляет каждый собственный вектор, можно рассчитать путем деления собственного значения, соответствующего этому собственному вектору, на сумму всех собственных значений.
Биплоты и графики осыпей (степень объясненной дисперсии ) используются для интерпретации результатов PCA.

Подробности
[ редактировать ]PCA определяется как ортогональное линейное преобразование в реальном внутреннем пространстве продукта , которое преобразует данные в новую систему координат так, что наибольшая дисперсия некоторой скалярной проекции данных приходится на первую координату (называемую первым главным компонентом), второе по величине отклонение второй координаты и так далее. [ 12 ]
Рассмотрим данных матрица X n по столбцам с нулевым эмпирическим средним значением (выборочное среднее каждого столбца было сдвинуто к нулю), где каждая из строк представляет собой различное повторение эксперимента, а каждый из p столбцов дает определенный вид функции (скажем, результаты работы определенного датчика).

Математически преобразование определяется набором размеров -мерных p векторов весов или коэффициентов которые отображают каждый вектор-строку X в новый вектор оценок главных компонентов , заданный





таким образом, чтобы отдельные переменные t, рассматриваемые в наборе данных, последовательно наследуют максимально возможную дисперсию от X , при этом каждый вектор коэффициентов w ограничен единичным вектором (где обычно выбирается строго меньше, чем уменьшить размерность).

Вышеуказанное можно эквивалентно записать в матричной форме как

где , , и .



Первый компонент
[ редактировать ]Таким образом , чтобы максимизировать дисперсию, первый весовой вектор w (1) должен удовлетворять

Аналогично, запись этого в матричной форме дает

Поскольку w (1) был определен как единичный вектор, он эквивалентно также удовлетворяет

Величину, которую необходимо максимизировать, можно определить как коэффициент Рэлея . Стандартный результат для положительной полуопределенной матрицы, такой как X Т X заключается в том, что максимально возможное значение фактора является наибольшим собственным значением матрицы, которое возникает, когда w является соответствующим собственным вектором .
Найдя w (1) , первый главный компонент вектора данных x ( i ) можно затем представить как оценку t 1( i ) = x ( i ) ⋅ w (1) в преобразованных координатах или как соответствующий вектор в исходных переменных, { x ( i ) ⋅ w (1) } w (1) .
Дополнительные компоненты
[ редактировать ]-й компонент k можно найти, вычитая первые k - 1 главных компонент из X :

а затем найти вектор весов, который извлекает максимальную дисперсию из этой новой матрицы данных

Оказывается, это дает остальным собственным векторам X Т X , где максимальные значения величины в скобках заданы соответствующими собственными значениями. Таким образом, весовые векторы являются собственными векторами X Т Х.
Таким образом, k -й главный компонент вектора данных x ( i ) может быть задан как оценка t k ( i ) = x ( i ) ⋅ w ( k ) в преобразованных координатах или как соответствующий вектор в пространстве исходные переменные, { x ( i ) ⋅ w ( k ) } w ( k ) , где w ( k ) - k -й собственный вектор X Т Х.
Таким образом, полное разложение X на главные компоненты можно представить как
где W — p - x- p матрица весов , столбцы которой являются собственными векторами X Т Х. Транспонирование W иногда называют преобразованием отбеливания или сферирования . Столбцы W, умноженные на квадратный корень из соответствующих собственных значений, то есть собственных векторов, увеличенных за счет дисперсий, называются нагрузками в PCA или в факторном анализе.
Ковариации
[ редактировать ]Х Т Сам X можно признать пропорциональным ковариационной матрице эмпирической выборки набора данных X. Т . [ 12 ] : 30–31
Выборочная ковариация Q между двумя различными главными компонентами набора данных определяется следующим образом:

где свойство собственных значений w ( k ) использовалось для перехода от строки 2 к строке 3. Однако собственные векторы w ( j ) и w ( k ), соответствующие собственным значениям симметричной матрицы, ортогональны (если собственные значения различны), или могут быть ортогональными (если векторы имеют одинаковое повторяющееся значение). Таким образом, произведение в последней строке равно нулю; в наборе данных нет выборочной ковариации между различными главными компонентами.
Таким образом, другой способ охарактеризовать преобразование главных компонентов - это преобразование в координаты, которые диагонализуют ковариационную матрицу эмпирической выборки.
В матричной форме эмпирическую ковариационную матрицу исходных переменных можно записать

Эмпирическая ковариационная матрица между главными компонентами принимает вид

где Λ — диагональная матрица собственных значений λ ( k ) оператора X Т Х. λ ( k ) равно сумме квадратов по набору данных, связанному с каждым компонентом k , то есть λ ( k ) = Σ i t k 2 ( я ) знак равно Σ я ( Икс ( я ) ⋅ ш ( k ) ) 2 .
Уменьшение размерности
[ редактировать ]Преобразование T = X W отображает вектор данных x ( i ) из исходного пространства p переменных в новое пространство p переменных, которые не коррелируют в наборе данных. Однако не все основные компоненты должны быть сохранены. Сохранение только первых L главных компонентов, полученных с использованием только первых L собственных векторов, дает усеченное преобразование

где матрица T L теперь имеет n строк, но только L столбцов. Другими словами, PCA изучает линейное преобразование. где столбцы p × L матрицы образуют ортогональную основу для L признаков (компонентов представления t ), которые декоррелированы. [ 13 ] По построению из всех преобразованных матриц данных, содержащих только L столбцов, эта оценочная матрица максимизирует дисперсию сохраненных исходных данных, минимизируя при этом общую квадратичную ошибку реконструкции. или .




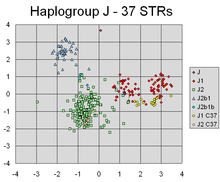
PCA успешно обнаружил линейные комбинации маркеров, которые выделяют разные кластеры, соответствующие разным линиям генетического происхождения Y-хромосомы людей.
Такое уменьшение размерности может быть очень полезным шагом для визуализации и обработки многомерных наборов данных, сохраняя при этом как можно большую дисперсию в наборе данных. Например, если выбрать L = 2 и сохранить только первые два главных компонента, в многомерном наборе данных будет найдена двумерная плоскость, в которой данные наиболее разбросаны, поэтому, если данные содержат кластеры, они тоже могут быть наиболее разбросаны. и поэтому наиболее наглядно их можно изобразить на двухмерной диаграмме; тогда как если два направления данных (или две исходные переменные) выбраны случайным образом, кластеры могут быть гораздо менее разбросаны друг от друга и фактически с гораздо большей вероятностью существенно перекроют друг друга, делая их неразличимыми.
Аналогичным образом, в регрессионном анализе , чем больше допустимое количество объясняющих переменных , тем больше вероятность переобучения модели и получения выводов, которые не могут быть обобщены на другие наборы данных. Один из подходов, особенно когда существуют сильные корреляции между различными возможными объясняющими переменными, состоит в том, чтобы свести их к нескольким главным компонентам, а затем провести против них регрессию, метод, называемый регрессией главных компонентов .
Уменьшение размерности также может быть целесообразным, когда переменные в наборе данных зашумлены. Если каждый столбец набора данных содержит независимый одинаково распределенный гауссовский шум, то столбцы T также будут содержать одинаково одинаково распределенный гауссов шум (такое распределение инвариантно под воздействием матрицы W , которую можно рассматривать как многомерную вращение осей координат). Однако, поскольку большая часть общей дисперсии сосредоточена в первых нескольких главных компонентах по сравнению с той же дисперсией шума, пропорциональное влияние шума меньше — первые несколько компонентов достигают более высокого отношения сигнал/шум . Таким образом, PCA может привести к концентрации большей части сигнала на первых нескольких основных компонентах, которые можно с пользой уловить путем уменьшения размерности; в то время как более поздние основные компоненты могут подвергаться доминированию шума, и поэтому от них можно избавиться без больших потерь. Если набор данных не слишком велик, значимость главных компонентов можно проверить с помощью параметрический бутстрап , чтобы помочь определить, сколько основных компонентов следует сохранить. [ 14 ]
Разложение по сингулярным значениям
[ редактировать ]Преобразование главных компонент также может быть связано с другой матричной факторизацией, разложением по сингулярным значениям (SVD) X ,

Здесь Σ — размером n × p прямоугольная диагональная матрица из положительных чисел σ ( k ) , называемая сингулярными значениями X ; U — n матрица размером × n , столбцы которой представляют собой ортогональные единичные векторы длины n, называемые левыми сингулярными векторами X ; и W — p на матрица размером p , столбцы которой представляют собой ортогональные единичные векторы длины p и называются правыми сингулярными векторами X .
С точки зрения этой факторизации матрица X Т Х можно написать

где - квадратная диагональная матрица с сингулярными значениями X и отрезанными лишними нулями, удовлетворяющая условию . Сравнение с факторизацией собственных векторов X Т X что правые сингулярные векторы W X устанавливает , эквивалентны собственным векторам X Т X сингулярные значения σ ( k ) , а равны квадратному корню из собственных λ ( k ) X значений Т Х.



Используя разложение по сингулярным значениям, матрицу оценок T можно записать

таким образом, каждый столбец T задается одним из левых сингулярных векторов X, умноженным на соответствующее сингулярное значение. Эта форма также является разложением T полярным .
Существуют эффективные алгоритмы для расчета SVD X без необходимости формирования матрицы X. Т X , поэтому вычисление SVD теперь является стандартным способом расчета анализа главных компонентов из матрицы данных, [ 15 ] если только не требуется всего несколько компонентов.
Как и в случае с собственным разложением, усеченная размера n × L матрица оценок T L может быть получена путем рассмотрения только первых L крупнейших сингулярных значений и их сингулярных векторов:

Усечение матрицы M или T с использованием усеченного разложения по сингулярным значениям таким образом дает усеченную матрицу, которая является ближайшей возможной матрицей ранга L к исходной матрице в том смысле, что разница между ними имеет наименьшую возможную норму Фробениуса. , результат, известный как теорема Эккарта – Янга [1936].
Дальнейшие соображения
[ редактировать ]Сингулярные значения (в Σ ) представляют собой квадратные корни из собственных значений матрицы X Т Х. Каждое собственное значение пропорционально части «дисперсии» (точнее, суммы квадратов расстояний точек от их многомерного среднего значения), которая связана с каждым собственным вектором. Сумма всех собственных значений равна сумме квадратов расстояний точек от их многомерного среднего значения. PCA по существу вращает набор точек вокруг их среднего значения, чтобы согласовать его с основными компонентами. Это переместит как можно большую часть дисперсии (с использованием ортогонального преобразования) в первые несколько измерений. Поэтому значения в остальных измерениях имеют тенденцию быть небольшими и могут быть отброшены с минимальной потерей информации (см. ниже ). PCA часто используется таким образом для уменьшения размерности . PCA отличается тем, что является оптимальным ортогональным преобразованием для сохранения подпространства с наибольшей «дисперсией» (как определено выше). Однако это преимущество достигается ценой более высоких вычислительных требований по сравнению, например, и, когда это применимо, с дискретное косинусное преобразование и, в частности, DCT-II, который просто известен как «DCT». Методы нелинейного уменьшения размерности, как правило, требуют больше вычислительных ресурсов, чем PCA.
PCA чувствителен к масштабированию переменных. Если у нас есть только две переменные, и они имеют одинаковую выборочную дисперсию и полностью коррелируют, то PCA повлечет за собой поворот на 45 ° и «веса» (это косинусы вращения) для двух переменных относительно основной компоненты будут равны. Но если мы умножим все значения первой переменной на 100, то первый главный компонент будет почти таким же, как и эта переменная, с небольшим вкладом другой переменной, тогда как второй компонент будет почти совмещен со второй исходной переменной. Это означает, что всякий раз, когда разные переменные имеют разные единицы измерения (например, температура и масса), PCA является несколько произвольным методом анализа. (Другие результаты были бы получены, если бы мы использовали, например, градусы Фаренгейта, а не Цельсия.) Оригинальная статья Пирсона называлась «О линиях и плоскостях, наиболее близких к системам точек в пространстве» - «в пространстве» подразумевает физическое евклидово пространство, где подобные проблемы имеют место. не возникать. Один из способов сделать PCA менее произвольным — использовать переменные, масштабированные так, чтобы иметь единичную дисперсию, путем стандартизации данных и, следовательно, использовать матрицу автокорреляции вместо матрицы автоковариации в качестве основы для PCA. Однако это сжимает (или расширяет) флуктуации во всех измерениях сигнального пространства до единичной дисперсии.
Вычитание среднего значения (также известное как «центрирование среднего») необходимо для выполнения классического PCA, чтобы гарантировать, что первый главный компонент описывает направление максимальной дисперсии. Если вычитание среднего значения не выполняется, вместо этого первый главный компонент может более или менее соответствовать среднему значению данных. Среднее значение нуля необходимо для нахождения базиса, который минимизирует среднеквадратическую ошибку аппроксимации данных. [ 16 ]
Центрирование среднего значения не требуется при выполнении анализа главных компонентов корреляционной матрицы, поскольку данные уже центрированы после расчета корреляций. Корреляции получаются из перекрестного произведения двух стандартных оценок (Z-показателей) или статистических моментов (отсюда и название: корреляция продукта-момента Пирсона ). См. также статью Кромри и Фостера-Джонсона (1998) «Центрирование по среднему в умеренной регрессии: много шума из ничего» . Поскольку ковариации представляют собой корреляции нормализованных переменных ( Z- или стандартных показателей основанный на корреляционной матрице X PCA , равен , основанному на ковариационной матрице Z , стандартизированной версии X. ), PCA ,
PCA — популярный основной метод распознавания образов . Однако он не оптимизирован для разделения классов. [ 17 ] Однако он использовался для количественной оценки расстояния между двумя или более классами путем расчета центра масс для каждого класса в пространстве главных компонентов и определения евклидова расстояния между центрами масс двух или более классов. [ 18 ] Линейный дискриминантный анализ является альтернативой, оптимизированной для разделения классов.
Таблица символов и сокращений
[ редактировать ]| Символ | Значение | Размеры | Индексы |
|---|---|---|---|
| матрица данных, состоящая из набора всех векторов данных, по одному вектору в строке | | ||
| количество векторов-строок в наборе данных | скаляр | ||
| количество элементов в каждом векторе-строке (размерности) | скаляр | ||
| количество измерений в размерно уменьшенном подпространстве, | скаляр | ||
| вектор эмпирических средних , одно среднее значение для каждого столбца j матрицы данных | |||
| вектор эмпирических стандартных отклонений , одно стандартное отклонение для каждого столбца j матрицы данных | |||
| вектор всех единиц | |||
| отклонения от среднего значения каждого столбца j матрицы данных | | ||
| z-показатели , рассчитанные с использованием среднего значения и стандартного отклонения для каждого столбца j матрицы данных. | | ||
| ковариационная матрица | | ||
| корреляционная матрица | | ||
| состоящая из набора всех собственных векторов C матрица , , по одному собственному вектору на столбец | | ||
| диагональная матрица, состоящая из набора всех собственных значений матрицы C вдоль ее главной диагонали и 0 для всех остальных элементов (примечание использовал выше) | | ||
| матрица базисных векторов, по одному вектору на столбец, где каждый базисный вектор является одним из собственных векторов C и где векторы в W являются подмножеством векторов в V | | ||
| матрица, состоящая из n векторов-строк, где каждый вектор является проекцией соответствующего вектора данных из матрицы X содержащиеся в столбцах матрицы W. на базисные векторы , | |
![{\displaystyle \mathbf {X} =[X_{ij}]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/ef4daaf2305609bbd2142de16bbb6cb774218d22)






![{\displaystyle \mathbf {u} =[u_{j}]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/95df093fae62b2ab6dfa4527c69d1cbd3b9d553f)

![{\displaystyle \mathbf {s} =[s_{j}]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/bf19191b22b96e131d03b5b3d1ce7dde1cc877ba)
![{\displaystyle \mathbf {h} =[h_{i}]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/d0ef2db0dd2d098b4893574eca8b44d04fde0653)

![{\displaystyle \mathbf {B} =[B_{ij}]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/1c8b8dd810252420486677821841d9c24c7cf58d)
![{\displaystyle \mathbf {Z} =[Z_{ij}]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/924bacc6ac643a5165b78f62aa36ec85f3e94cd8)
![{\displaystyle \mathbf {C} =[C_{jj'}]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/1652c6b60c22140c190acfa8f49084ccc4ca8f9c)


![{\displaystyle \mathbf {R} =[R_{jj'}]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/0ecc703ef34aa1c05d4b86462435d9eef3dbadde)
![{\displaystyle \mathbf {V} =[V_{jj'}]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/ebedde6d7a291b8a304447f9467f85c6325d4755)
![{\displaystyle \mathbf {D} =[D_{jj'}]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/d5a835ec95447679384c75da973ebdb23fcb0d56)

![{\displaystyle \mathbf {W} =[W_{jl}]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/95c3a7bd748ee5e1b0ebbddc41e61fa6d16d26a5)


![{\displaystyle \mathbf {T} =[T_{il}]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/684b2536b0cdea539fc13d7d4b92b40557727609)

Свойства и ограничения
[ редактировать ]Характеристики
[ редактировать ]Некоторые свойства PCA включают в себя: [ 12 ] [ нужна страница ]
- Свойство 1. Для любого целого числа q , 1 ≤ q ≤ p , рассмотрим ортогональное линейное преобразование
- где является вектором q-элемента и — матрица ( q × p ), и пусть быть дисперсионно - ковариационной матрицей для . Тогда след , обозначенный , максимизируется, если принять , где состоит из первых q столбцов это транспонирование . ( здесь не определено)











- Свойство 2 : снова рассмотрим ортонормированное преобразование
- с и определяется, как и раньше. Затем минимизируется за счет принятия где состоит из последних q столбцов .



Статистический смысл этого свойства заключается в том, что последние несколько ПК не являются просто неструктурированными остатками после удаления важных ПК. Поскольку эти последние ПК имеют дисперсию как можно меньше, они полезны сами по себе. Они могут помочь обнаружить неожиданные почти постоянные линейные связи между элементами x , а также могут быть полезны в регрессии , при выборе подмножества переменных из x и при обнаружении выбросов.
- Свойство 3 : (Спектральное разложение Σ )

Прежде чем мы рассмотрим его использование, мы сначала рассмотрим диагональные элементы,

Тогда, возможно, основным статистическим следствием результата является то, что мы не только можем разложить объединенные дисперсии всех элементов x на уменьшающиеся вклады каждого PC, но мы также можем разложить всю ковариационную матрицу на вклады. с каждого ПК. Хотя и не строго уменьшающиеся, но элементы будет иметь тенденцию уменьшаться по мере увеличивается, так как не увеличивается при увеличении , тогда как элементы имеют тенденцию оставаться примерно одного и того же размера из-за ограничений нормализации: .




Ограничения
[ редактировать ]Как отмечалось выше, результаты PCA зависят от масштабирования переменных. Это можно исправить, масштабируя каждый признак по его стандартному отклонению, так что в итоге мы получаем безразмерные признаки с единичной дисперсией. [ 19 ]
Применимость PCA, как описано выше, ограничена определенными (молчаливыми) предположениями. [ 20 ] сделанный в его выводе. В частности, PCA может фиксировать линейные корреляции между объектами, но терпит неудачу, когда это предположение нарушается (см. Рисунок 6a в ссылке). В некоторых случаях преобразования координат могут восстановить предположение о линейности и затем применить PCA (см. ядро PCA ).
Еще одним ограничением является процесс удаления среднего значения перед построением ковариационной матрицы для PCA. В таких областях, как астрономия, все сигналы неотрицательны, и процесс удаления среднего значения приводит к тому, что среднее значение некоторых астрофизических воздействий становится равным нулю, что, следовательно, создает нефизические отрицательные потоки. [ 21 ] и необходимо выполнить прямое моделирование, чтобы восстановить истинную величину сигналов. [ 22 ] В качестве альтернативного метода можно использовать факторизацию неотрицательных матриц , фокусирующуюся только на неотрицательных элементах матриц, что хорошо подходит для астрофизических наблюдений. [ 23 ] [ 24 ] [ 25 ] Дополнительную информацию см. в разделе «Связь между PCA и факторизацией неотрицательной матрицы» .
PCA находится в невыгодном положении, если данные не были стандартизированы перед применением к ним алгоритма. PCA преобразует исходные данные в данные, соответствующие основным компонентам этих данных, а это означает, что новые переменные данных не могут интерпретироваться так же, как исходные. Они представляют собой линейную интерпретацию исходных переменных. Также при неправильном выполнении PCA существует высокая вероятность потери информации. [ 26 ]
PCA опирается на линейную модель. Если в наборе данных скрыта нелинейная закономерность, то PCA фактически может направить анализ в совершенно противоположном направлении прогресса. [ 27 ] [ нужна страница ] Исследователи из Университета штата Канзас обнаружили, что ошибка выборки в их экспериментах повлияла на погрешность результатов PCA. «Если количество субъектов или блоков меньше 30 и/или исследователя интересуют ПК, выходящие за пределы первого, возможно, лучше сначала внести поправку на серийную корреляцию, прежде чем проводить PCA». [ 28 ] Исследователи из штата Канзас также обнаружили, что PCA может быть «серьезно необъективным, если неправильно обрабатывать автокорреляционную структуру данных». [ 28 ]
PCA и теория информации
[ редактировать ]Уменьшение размерности в целом приводит к потере информации. Уменьшение размерности на основе PCA имеет тенденцию минимизировать потерю информации при определенных моделях сигнала и шума.
В предположении, что

то есть вектор данных представляет собой сумму полезного информационного сигнала и шумовой сигнал можно показать, что PCA может быть оптимальным для уменьшения размерности с точки зрения теории информации.



В частности, Линскер показал, что если является гауссовским и представляет собой гауссов шум с ковариационной матрицей, пропорциональной единичной матрице, PCA максимизирует взаимную информацию между желаемой информацией и выход с уменьшенной размерностью . [ 29 ]


Если шум по-прежнему гауссовский и имеет ковариационную матрицу, пропорциональную единичной матрице (т. е. компоненты вектора являются iid ), но информационный сигнал не является гауссовским (что является распространенным сценарием), PCA по крайней мере минимизирует верхнюю границу потери информации , которая определяется как [ 30 ] [ 31 ]

Оптимальность РСА сохраняется и при условии, что шум является иидным и, по крайней мере, более гауссовым (с точки зрения расхождения Кульбака – Лейблера ), чем информационный сигнал . [ 32 ] В общем, даже если описанная выше модель сигнала верна, PCA теряет свою теоретико-информационную оптимальность, как только шум становится зависимым.
Расчет с использованием ковариационного метода
[ редактировать ]Ниже приводится подробное описание PCA с использованием ковариационного метода. [ 33 ] в отличие от корреляционного метода. [ 34 ]
Цель состоит в том, чтобы преобразовать данный набор данных размерности p в альтернативный набор данных Y меньшего размера L. X Эквивалентно, мы ищем матрицу Y , где Y — преобразование Карунена-Лоэва (KLT) матрицы X :

-
Организуйте набор данных
Предположим, у вас есть данные, содержащие набор наблюдений за p переменными, и вы хотите сократить данные так, чтобы каждое наблюдение можно было описать только с помощью L переменных, L < p . Предположим далее, что данные организованы как набор из n векторов данных. с каждым представляющее одно сгруппированное наблюдение за p- переменными.
- Писать как векторы-строки, каждый из которых имеет p элементов.
- Поместите векторы-строки в одну матрицу X размерностей n × p .
-
Рассчитайте эмпирическое среднее значение
- Найдите эмпирическое среднее значение по каждому столбцу j = 1,..., p .
- Поместите рассчитанные средние значения в эмпирический средний вектор u размеров p × 1.
-
Рассчитаем отклонения от среднего значения
Вычитание среднего значения является неотъемлемой частью решения по поиску базиса главных компонент, который минимизирует среднеквадратическую ошибку аппроксимации данных. [ 35 ] Следовательно, мы продолжим центрирование данных следующим образом:
- Вычтите эмпирический средний вектор из каждой строки матрицы данных X .
- Сохраните данные с вычтенным средним значением в n × p матрице B . где h — вектор-столбец размера n × 1, состоящий из всех единиц:
В некоторых приложениях каждая переменная (столбец B ) также может быть масштабирована так, чтобы иметь дисперсию, равную 1 (см. Z-показатель ). [ 36 ] Этот шаг влияет на рассчитанные главные компоненты, но делает их независимыми от единиц, используемых для измерения различных переменных.
-
Найдите ковариационную матрицу
- Найдите размера p × p эмпирическую ковариационную матрицу C из матрицы B : где — оператор сопряженного транспонирования . Если B полностью состоит из действительных чисел, что имеет место во многих приложениях, «сопряженное транспонирование» совпадает с обычным транспонированием .
- Причиной использования n - 1 вместо n для расчета ковариации является поправка Бесселя .
-
Найдите собственные векторы и собственные значения ковариационной матрицы.
- Вычислите матрицу V собственных векторов , которая диагонализует ковариационную матрицу C : где D — диагональная собственных значений C матрица . Этот шаг обычно включает использование компьютерного алгоритма для вычисления собственных векторов и собственных значений . Эти алгоритмы легко доступны как подкомпоненты большинства систем матричной алгебры , таких как SAS , [ 37 ] Р , МАТЛАБ , [ 38 ] [ 39 ] Математика , [ 40 ] SciPy , IDL ( интерактивный язык данных ) или GNU Octave , а также OpenCV .
- Матрица D примет вид диагональной матрицы размера p × p , где — j - е собственное значение ковариационной матрицы C , и
- Матрица V , также размерности p × p , содержит p вектор-столбцов, каждый из которых имеет длину p , которые представляют p собственных векторов ковариационной C. матрицы
- Собственные значения и собственные векторы упорядочены и спарены. j - е собственное значение соответствует j -му собственному вектору.
- Матрица V обозначает матрицу правых собственных векторов (в отличие от левых собственных векторов). В общем, матрица правых собственных векторов не обязательно должна быть (сопряженной) транспозицией матрицы левых собственных векторов.
-
Переставьте собственные векторы и собственные значения.
- Отсортируйте столбцы матрицы собственных векторов V и матрицы собственных значений D в порядке убывания собственного значения.
- Обязательно соблюдайте правильные пары между столбцами в каждой матрице.
-
Вычислите совокупное содержание энергии для каждого собственного вектора
- Собственные значения представляют собой распределение энергии исходных данных. [ нужны разъяснения ] среди каждого из собственных векторов, где собственные векторы образуют основу для данных. Совокупное содержание энергии g для j -го собственного вектора представляет собой сумму содержания энергии по всем собственным значениям от 1 до j : [ нужна ссылка ]
-
Выберите подмножество собственных векторов в качестве базисных векторов.
- Сохраните первые L столбцов V как p × L матрицу W размера : где
- Используйте вектор g в качестве руководства при выборе подходящего значения для L . Цель состоит в том, чтобы выбрать как можно меньшее значение L , при этом достигая достаточно высокого значения g в процентном отношении. Например, вы можете выбрать L , чтобы совокупная энергия g превышала определенный порог, например 90 процентов. В этом случае выберите наименьшее значение L такое, что
-
Спроецируйте данные на новую основу
- Проецируемые точки данных представляют собой строки матрицы.

















Вывод с использованием ковариационного метода
[ редактировать ]Пусть X — d -мерный случайный вектор, выраженный как вектор-столбец. Без ограничения общности предположим, что X имеет нулевое среднее значение.
Мы хотим найти размера d × d, матрица ортонормированного преобразования P так что PX имеет диагональную ковариационную матрицу (т. е. PX представляет собой случайный вектор, все его отдельные компоненты попарно некоррелированы).

Быстрое вычисление, предполагающее были унитарные доходности:

![{\displaystyle {\begin{aligned}\operatorname{cov}(PX)&=\operatorname{E}[PX~(PX)^{*}]\\&=\operatorname{E}[PX~X^{ *}P^{*}]\\&=P\operatorname{E}[XX^{*}]P^{*}\\&=P\operatorname{cov}(X)P^{-1}\ \\end{выровнено}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/0e4800248eafcc33b2c22c5613f06b0c2455faad)
Следовательно имеет место тогда и только тогда, когда были диагонализуемы .

Это очень конструктивно, поскольку cov( X ) гарантированно будет неотрицательно определенной матрицей и, таким образом, гарантированно будет диагонализируемой некоторой унитарной матрицей.
Вычисление без ковариации
[ редактировать ]В практических реализациях, особенно с данными большой размерности (большие p ), метод наивной ковариации используется редко, поскольку он неэффективен из-за высоких затрат вычислений и памяти для явного определения ковариационной матрицы. Безковариационный подход позволяет избежать np 2 операции явного вычисления и хранения ковариационной матрицы X Т X , используя вместо этого один из безматричных методов , например, на основе функции, оценивающей продукт X Т (X r) ценой 2 np операций.
Итеративные вычисления
[ редактировать ]Один из способов эффективного вычисления первого главного компонента [ 41 ] показано в следующем псевдокоде для матрицы данных X с нулевым средним значением без вычисления ее ковариационной матрицы.
r = a random vector of length p r = r / norm(r) do c times: s = 0 (a vector of length p) for each row x in X s = s + (x ⋅ r) x λ = rTs // λ is the eigenvalue error = |λ ⋅ r − s| r = s / norm(s) exit if error < tolerance return λ, r
Этот алгоритм итерации мощности просто вычисляет вектор X Т (X r) нормализует и помещает результат обратно в r . Собственное значение аппроксимируется r Т (Х Т X) r , который является фактором Рэлея на единичном векторе r для ковариационной матрицы X Т Х. Если наибольшее сингулярное значение хорошо отделено от следующего по величине, вектор r приближается к первому главному компоненту X за количество итераций c , которое мало по сравнению с p , с общей стоимостью 2cnp . Сходимость степенных итераций можно ускорить, не жертвуя заметно небольшими затратами на итерацию, используя более совершенные безматричные методы , такие как алгоритм Ланцоша или метод локально оптимального блочного предварительно обусловленного сопряженного градиента ( LOBPCG ).
Последующие главные компоненты могут рассчитываться один за другим путем дефлятирования или одновременно в виде блока. В первом подходе неточности в уже вычисленных приближенных главных компонентах аддитивно влияют на точность вычисленных впоследствии главных компонент, тем самым увеличивая ошибку с каждым новым вычислением. Последний подход в блочном степенном методе заменяет одиночные векторы r и s блочными векторами, R и S. матрицами Каждый столбец R аппроксимирует один из ведущих главных компонентов, при этом все столбцы повторяются одновременно. Основной расчет – оценка продукта X Т (ХР) . Реализованная, например, в LOBPCG , эффективная блокировка устраняет накопление ошибок, позволяет использовать высокоуровневые матрично-матричные функции произведения BLAS и обычно приводит к более быстрой сходимости по сравнению с одновекторным методом «один за другим».
Метод НИПАЛС
[ редактировать ]Нелинейный итеративный метод частичных наименьших квадратов (NIPALS) — это вариант классической степенной итерации с дефляцией матрицы путем вычитания, реализованный для вычисления первых нескольких компонентов в анализе главного компонента или частичного метода наименьших квадратов . Для наборов данных очень большой размерности, например, созданных в области *омики (например, геномики , метаболомики ), обычно необходимо вычислить только первые несколько компьютеров. Нелинейный итеративный алгоритм частичных наименьших квадратов (NIPALS) обновляет итеративные аппроксимации ведущих оценок и нагрузок t 1 и r 1 Т путем умножения степенной итерации на каждой итерации на X слева и справа, то есть избегается вычисление ковариационной матрицы, так же, как и в безматричной реализации степенных итераций до X Т X , на основе функции оценки продукта X Т (Х г) = ((Х г) Т Х) Т .
Матричное дефлятирование вычитанием выполняется путем вычитания внешнего произведения t 1 r 1 Т от X остается сдутая остаточная матрица, используемая для расчета последующих ведущих ПК. [ 42 ] Для больших матриц данных или матриц с высокой степенью коллинеарности столбцов NIPALS страдает от потери ортогональности ПК из- за ошибок машинного округления, накапливающихся на каждой итерации, и дефляции матрицы путем вычитания. [ 43 ] ортогональности . Алгоритм реортогонализации Грама – Шмидта применяется как к оценкам, так и к нагрузкам на каждом шаге итерации, чтобы устранить эту потерю [ 44 ] Зависимость NIPALS от одновекторных умножений не позволяет использовать преимущества BLAS высокого уровня и приводит к медленной сходимости для кластеризованных ведущих сингулярных значений - оба этих недостатка устраняются в более сложных безматрицных решателях блоков, таких как локально оптимальный блочный предварительно обусловленный сопряженный градиент ( LOBPCG ) метод.
Онлайн/последовательная оценка
[ редактировать ]В «онлайн» или «потоковой» ситуации, когда данные поступают по частям, а не хранятся в одном пакете, полезно сделать оценку прогноза PCA, который может обновляться последовательно. Это можно сделать эффективно, но требуются другие алгоритмы. [ 45 ]
Качественные переменные
[ редактировать ]В PCA обычно мы хотим ввести качественные переменные в качестве дополнительных элементов. Например, на растениях были измерены многие количественные переменные. Для этих растений доступны некоторые качественные переменные, например, вид, к которому принадлежит растение. Эти данные были подвергнуты PCA для количественных переменных. При анализе результатов естественно связать главные компоненты с качественными переменными видами . Для этого получаются следующие результаты.
- Идентификация на факториальных плоскостях разных видов, например, с использованием разных цветов.
- Представление на факториальных плоскостях центров тяжести растений одного вида.
- Для каждого центра тяжести и каждой оси значение p позволяет оценить значимость разницы между центром тяжести и началом координат.
Эти результаты представляют собой то, что называется введением качественной переменной в качестве дополнительного элемента . Эта процедура подробно описана в Husson, Lê & Pages 2009 и Pages 2013. Немногие программы предлагают эту опцию «автоматически». Так обстоит дело со SPAD, который исторически, следуя за работами Людовика Лебарта , первым предложил этот вариант, и с пакетом R FactoMineR .
Приложения
[ редактировать ]Интеллект
[ редактировать ]Самое раннее применение факторного анализа заключалось в обнаружении и измерении компонентов человеческого интеллекта. Считалось, что интеллект имеет различные некоррелированные компоненты, такие как пространственный интеллект, вербальный интеллект, индукция, дедукция и т. д., и что оценки по ним можно получить с помощью факторного анализа результатов различных тестов, чтобы получить единый индекс, известный как коэффициент интеллекта (IQ). ). Психолог-новатор Спирмен фактически разработал факторный анализ в 1904 году для своей двухфакторной теории интеллекта, добавив формальный метод к науке психометрии . В 1924 году Терстоун выявил 56 факторов интеллекта, разработав понятие умственного возраста. Сегодняшние стандартные тесты IQ основаны на этой ранней работе. [ 46 ]
Жилая дифференциация
[ редактировать ]В 1949 году Шевки и Уильямс представили теорию факторной экологии , которая доминировала в исследованиях жилищной дифференциации с 1950-х по 1970-е годы. [ 47 ] Районы в городе были узнаваемы или отличались друг от друга по различным характеристикам, которые с помощью факторного анализа можно было свести к трем. Они были известны как «социальный ранг» (индекс профессионального статуса), «семейство» или размер семьи и «этническая принадлежность»; Затем можно применить кластерный анализ для разделения города на кластеры или районы в соответствии со значениями трех ключевых факторных переменных. По факториальной экологии в городской географии сложилась обширная литература, но этот подход вышел из моды после 1980 года как методологически примитивный и имеющий мало места в постмодернистских географических парадигмах.
Одной из проблем факторного анализа всегда был поиск убедительных названий различных искусственных факторов. В 2000 году Флуд возродил подход факторной экологии, чтобы показать, что анализ главных компонентов фактически дает значимые ответы напрямую, не прибегая к ротации факторов. Основными компонентами на самом деле были двойные переменные или теневые цены «сил», сталкивающих людей вместе или друг от друга в городах. Первым компонентом была «доступность», классический компромисс между спросом на путешествия и спросом на пространство, на котором базируется классическая городская экономика. Следующими двумя компонентами были «недостаток», который удерживает людей с одинаковым статусом в отдельных кварталах (опосредованно планированием), и этническая принадлежность, где люди схожего этнического происхождения пытаются жить вместе. [ 48 ]
Примерно в то же время Австралийское статистическое бюро определило отдельные индексы преимуществ и недостатков, взяв первый главный компонент наборов ключевых переменных, которые считались важными. Эти индексы SEIFA регулярно публикуются для различных юрисдикций и часто используются в пространственном анализе. [ 49 ]
Индексы развития
[ редактировать ]PCA был единственным формальным методом, доступным для разработки индексов, которые в противном случае представляли бы собой случайную задачу .
Индекс развития города был разработан PCA на основе примерно 200 показателей состояния городов в ходе исследования 1996 года, проведенного в 254 городах мира. Первый главный компонент подвергался итеративной регрессии с добавлением исходных переменных по отдельности до тех пор, пока не было учтено около 90% его вариаций. В конечном итоге в индексе использовалось около 15 индикаторов, но он был хорошим предсказателем многих других переменных. Его сравнительная ценность очень хорошо согласовывалась с субъективной оценкой состояния каждого города. Коэффициенты по объектам инфраструктуры были примерно пропорциональны средним затратам на предоставление основных услуг, что позволяет предположить, что Индекс на самом деле является мерой эффективных физических и социальных инвестиций в город.
на уровне страны Индекс человеческого развития (ИЧР) , разработанный ПРООН , который публикуется с 1990 года и очень широко используется в исследованиях развития. [ 50 ] имеет очень похожие коэффициенты по схожим показателям, что позволяет предположить, что изначально он был построен с использованием PCA.
Популяционная генетика
[ редактировать ]В 1978 году Кавалли-Сфорца и другие впервые применили анализ главных компонентов (PCA) для обобщения данных о вариациях частот человеческих генов в разных регионах. Компоненты демонстрировали характерные закономерности, включая градиенты и синусоидальные волны. Они интерпретировали эти закономерности как результат конкретных древних миграционных событий.
С тех пор PCA повсеместно используется в популяционной генетике: тысячи статей используют PCA в качестве механизма отображения. Генетика во многом зависит от близости, поэтому первые два основных компонента фактически отражают пространственное распределение и могут использоваться для картирования относительного географического положения различных групп населения, тем самым показывая людей, которые покинули свое первоначальное местонахождение. [ 51 ]
PCA в генетике был технически спорным, поскольку этот метод применялся к дискретным ненормальным переменным и часто к бинарным аллельным маркерам. Отсутствие каких-либо мер стандартной ошибки в PCA также является препятствием для более последовательного использования. В августе 2022 года молекулярный биолог Эран Эльхайк теоретическую статью, опубликовал в журнале Scientific Reports в которой анализируется 12 применений PCA. Он пришел к выводу, что этим методом легко манипулировать, что, по его мнению, приводит к «ошибочным, противоречивым и абсурдным» результатам. В частности, утверждал он, результаты, достигнутые в популяционной генетике, характеризуются избирательностью и круговым рассуждением . [ 52 ]
Исследования рынка и индексы отношения
[ редактировать ]Исследования рынка активно используют PCA. Он используется для определения показателей удовлетворенности или лояльности клиентов для продуктов, а вместе с кластеризацией — для разработки сегментов рынка, на которые можно ориентироваться с помощью рекламных кампаний, во многом так же, как факторная экология позволяет определять географические области со схожими характеристиками. [ 53 ]
PCA быстро преобразует большие объемы данных в более мелкие и простые для понимания переменные, которые можно быстрее и проще анализировать. В любом потребительском опроснике есть ряд вопросов, призванных выявить потребительское отношение, а основные компоненты выявляют скрытые переменные, лежащие в основе этого отношения. Например, в ходе Оксфордского интернет-опроса в 2013 году 2000 человек опросили об их взглядах и убеждениях, и из этих опросов аналитики выделили четыре основных компонента, которые они определили как «побег», «социальные сети», «эффективность» и «создание проблем». . [ 54 ]
Другой пример, приведенный Джо Флудом в 2008 году, позволил получить индекс отношения к жилью из 28 вопросов об отношении в национальном опросе 2697 домохозяйств в Австралии. Первый главный компонент представлял собой общее отношение к собственности и домовладению. Индекс или вопросы отношения, которые он воплощает, могут быть включены в общую линейную модель выбора владения. Самым сильным фактором, определяющим частную аренду, безусловно, был индекс отношения, а не доход, семейное положение или тип домохозяйства. [ 55 ]
Количественные финансы
[ редактировать ]В количественных финансах используется PCA. [ 56 ] в управлении финансовыми рисками и применялся к другим проблемам, таким как оптимизация портфеля .
PCA обычно используется в задачах, связанных с с фиксированным доходом ценными бумагами и портфелями , а также процентными деривативами . Оценки здесь зависят от всей кривой доходности , состоящей из множества сильно коррелированных инструментов, а PCA используется для определения набора компонентов или факторов, которые объясняют движения ставок. [ 57 ] тем самым облегчая моделирование. Одним из распространенных приложений управления рисками является расчет стоимости риска , VaR, с применением PCA к моделированию Монте-Карло . [ 58 ] Здесь для каждой выборки моделирования компоненты подвергаются стрессу, а ставки и, в свою очередь, значения вариантов затем восстанавливаются ; и, наконец, VaR рассчитывается на протяжении всего периода. PCA также используется для хеджирования процентного риска , учитывая неполную дюрацию и другие чувствительные факторы. [ 57 ] В обоих случаях интерес обычно представляют первые три основных компонента системы ( представляющие «сдвиг», «поворот» и «искривление»). Эти основные компоненты получаются в результате собственного разложения ковариационной матрицы доходности ; при заранее определенных сроках погашения [ 59 ] и где дисперсия каждого компонента является его собственным значением (а поскольку компоненты ортогональны , в последующем моделировании не требуется учитывать корреляцию).
Для акций оптимальным портфелем является портфель, в котором ожидаемая доходность максимизируется при заданном уровне риска или, альтернативно, где риск минимизируется при заданном доходе; см. обсуждение модели Марковица . Таким образом, один из подходов заключается в снижении портфельного риска, когда стратегии распределения применяются к «основным портфелям», а не к базовым акциям . Второй подход заключается в повышении доходности портфеля путем использования основных компонентов для выбора акций компаний с потенциалом роста. [ 60 ] [ 61 ] PCA также использовался для понимания отношений [ 56 ] между международными рынками акций и внутри рынков между группами компаний в отраслях или секторах .
PCA также может применяться для стресс-тестирования . [ 62 ] по сути, это анализ способности банка выдержать гипотетический неблагоприятный экономический сценарий . Его полезность заключается в «преобразовании информации, содержащейся в [нескольких] макроэкономических переменных , в более управляемый набор данных, который затем можно [использовать] для анализа». [ 62 ] фактора Здесь результирующие факторы связаны, например, с процентными ставками – на основе крупнейших элементов собственного вектора – и затем наблюдается, как «шок» каждого из факторов влияет на подразумеваемые активы каждого из банков.
Нейронаука
[ редактировать ]Вариант анализа главных компонентов используется в нейробиологии для выявления специфических свойств стимула, повышающих потенциала вероятность генерации нейроном действия . [ 63 ] [ 64 ] Этот метод известен как ковариационный анализ, запускаемый пиками . В типичном приложении экспериментатор представляет процесс белого шума в качестве стимула (обычно либо как сенсорный входной сигнал для испытуемого, либо как ток, подаваемый непосредственно в нейрон) и записывает последовательность потенциалов действия или импульсов, создаваемых испытуемым. в результате нейрон. Предположительно, определенные особенности стимула повышают вероятность возникновения импульса у нейрона. Чтобы извлечь эти особенности, экспериментатор вычисляет ковариационную матрицу ансамбля , инициированного спайком , набора всех стимулов (определенных и дискретизированных в течение конечного временного окна, обычно порядка 100 мс), которые непосредственно предшествовали спайку. Собственные векторы разности между ковариационной матрицей, инициированной спайком, и ковариационной матрицей предшествующего ансамбля стимулов (набор всех стимулов, определенных в течение одного и того же временного окна) затем указывают направления в пространстве стимулов , вдоль которых дисперсия ансамбль, запускаемый спайком, больше всего отличался от ансамбля предшествующего стимула. В частности, собственные векторы с наибольшими положительными собственными значениями соответствуют направлениям, вдоль которых дисперсия ансамбля, запускаемого шипами, показала наибольшее положительное изменение по сравнению с дисперсией предыдущего. Поскольку это были направления, в которых изменение стимула приводило к всплеску, они часто являются хорошим приближением к искомым соответствующим характеристикам стимула.
В нейробиологии PCA также используется для определения личности нейрона по форме его потенциала действия. Сортировка спайков — важная процедура, поскольку методы внеклеточной регистрации часто улавливают сигналы от более чем одного нейрона. При сортировке спайков сначала используется PCA, чтобы уменьшить размерность пространства форм сигналов потенциала действия, а затем выполняется кластерный анализ, чтобы связать конкретные потенциалы действия с отдельными нейронами.
PCA как метод уменьшения размерности особенно подходит для обнаружения скоординированной деятельности больших ансамблей нейронов. Он использовался для определения коллективных переменных, то есть параметров порядка , во время фазовых переходов в мозге. [ 65 ]
Связь с другими методами
[ редактировать ]Анализ корреспонденции
[ редактировать ]Анализ соответствия (СА) был разработан Жан-Полем Бензекри. [ 66 ] и концептуально похож на PCA, но масштабирует данные (которые должны быть неотрицательными), чтобы строки и столбцы обрабатывались одинаково. Традиционно он применяется к таблицам непредвиденных обстоятельств . CA разлагает статистику хи-квадрат, связанную с этой таблицей, на ортогональные факторы. [ 67 ] Поскольку CA является описательным методом, его можно применять к таблицам, для которых статистика хи-квадрат подходит или нет. Доступно несколько вариантов CA, включая анализ соответствия без тренда и анализ канонического соответствия . Одним из специальных расширений является анализ множественных соответствий , который можно рассматривать как аналог анализа главных компонентов для категориальных данных. [ 68 ]
Факторный анализ
[ редактировать ]
Анализ главных компонентов создает переменные, которые являются линейными комбинациями исходных переменных. Новые переменные обладают тем свойством, что все переменные ортогональны. Преобразование PCA может быть полезно в качестве этапа предварительной обработки перед кластеризацией. PCA — это подход, ориентированный на дисперсию, направленный на воспроизведение общей дисперсии переменной, в котором компоненты отражают как общую, так и уникальную дисперсию переменной. PCA обычно предпочтительнее для целей сокращения данных (то есть перевода пространства переменных в оптимальное пространство факторов), но не тогда, когда целью является обнаружение скрытой конструкции или факторов.
Факторный анализ похож на анализ главных компонентов, поскольку факторный анализ также включает в себя линейные комбинации переменных. В отличие от PCA, факторный анализ представляет собой подход, ориентированный на корреляцию, стремящийся воспроизвести взаимные корреляции между переменными, в котором факторы «представляют собой общую дисперсию переменных, исключая уникальную дисперсию». [ 69 ] С точки зрения корреляционной матрицы это соответствует объяснению недиагональных терминов (то есть общей ковариации), тогда как PCA фокусируется на объяснении терминов, расположенных по диагонали. Однако, как побочный результат, при попытке воспроизвести диагональные члены PCA также имеет тенденцию относительно хорошо соответствовать недиагональным корреляциям. [ 12 ] : 158 Результаты, полученные с помощью PCA и факторного анализа, в большинстве ситуаций очень похожи, но это не всегда так, и есть некоторые проблемы, в которых результаты существенно различаются. Факторный анализ обычно используется, когда целью исследования является обнаружение структуры данных (то есть скрытых конструкций или факторов) или причинно-следственное моделирование . Если факторная модель сформулирована неправильно или предположения не выполняются, то факторный анализ даст ошибочные результаты. [ 70 ]
K - означает кластеризацию
[ редактировать ]Утверждалось, что расслабленное решение k кластеризации -средних , заданное индикаторами кластера, задается главными компонентами, а подпространство PCA, охватываемое основными направлениями, идентично подпространству центроида кластера. [ 71 ] [ 72 ] Однако тот факт, что PCA является полезным ослаблением кластеризации k -средних, не был новым результатом. [ 73 ] и легко найти контрпримеры к утверждению, что подпространство центроида кластера натянуто на главные направления. [ 74 ]
Неотрицательная матричная факторизация
[ редактировать ]
Неотрицательная матричная факторизация (NMF) - это метод уменьшения размерности, при котором в матрицах используются только неотрицательные элементы, что, следовательно, является многообещающим методом в астрономии. [ 23 ] [ 24 ] [ 25 ] в том смысле, что астрофизические сигналы неотрицательны. Компоненты PCA ортогональны друг другу, тогда как все компоненты NMF неотрицательны и, следовательно, создают неортогональный базис.
В PCA вклад каждого компонента ранжируется на основе величины его соответствующего собственного значения, которое эквивалентно дробной остаточной дисперсии (FRV) при анализе эмпирических данных. [ 21 ] Для NMF его компоненты ранжируются только на основе эмпирических кривых FRV. [ 25 ] Графики остаточных дробных собственных значений, то есть как функция номера компонента учитывая в общей сложности компоненты, поскольку PCA имеют плоское плато, где не собираются данные для удаления квазистатического шума, затем кривые быстро падают, что указывает на переобучение (случайный шум). [ 21 ] Кривые FRV для NMF постоянно уменьшаются. [ 25 ] когда компоненты NMF строятся последовательно , [ 24 ] индикация непрерывного улавливания квазистатического шума; затем сходятся к более высоким уровням, чем PCA, [ 25 ] что указывает на меньшее свойство переобучения NMF.

Иконография корреляций
[ редактировать ]Часто бывает трудно интерпретировать основные компоненты, когда данные включают множество переменных различного происхождения или когда некоторые переменные являются качественными. Это приводит пользователя PCA к деликатному исключению нескольких переменных. Если наблюдения или переменные оказывают чрезмерное влияние на направление осей, их следует удалить, а затем спроецировать как дополнительные элементы. Кроме того, необходимо избегать интерпретации близости между точками, близкими к центру факториальной плоскости.
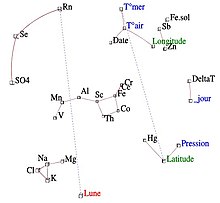
Иконография корреляций , напротив, не являющаяся проекцией на систему осей, не имеет этих недостатков. Таким образом, мы можем сохранить все переменные.
Принцип диаграммы состоит в том, чтобы подчеркнуть «замечательные» корреляции корреляционной матрицы сплошной линией (положительная корреляция) или пунктирной линией (отрицательная корреляция).
Сильная корреляция не является «примечательной», если она не является прямой, а вызвана влиянием третьей переменной. И наоборот, слабые корреляции могут быть «замечательными». Например, если переменная Y зависит от нескольких независимых переменных, корреляции Y с каждой из них слабы, но «замечательны».
Обобщения
[ редактировать ]Разреженный PCA
[ редактировать ]Особым недостатком PCA является то, что основные компоненты обычно представляют собой линейные комбинации всех входных переменных. Разреженный PCA преодолевает этот недостаток, находя линейные комбинации, содержащие всего несколько входных переменных. Он расширяет классический метод анализа главных компонентов (PCA) для уменьшения размерности данных путем добавления ограничения разреженности входных переменных. Было предложено несколько подходов, в том числе
- модель регрессии, [ 75 ]
- структура выпуклого релаксации/полуопределенного программирования, [ 76 ]
- структура обобщенного степенного метода [ 77 ]
- альтернативная структура максимизации [ 78 ]
- жадный поиск вперед-назад и точные методы с использованием методов ветвей и границ, [ 79 ]
- Байесовская формулировка. [ 80 ]
Методологические и теоретические разработки Sparse PCA, а также его применение в научных исследованиях были недавно рассмотрены в обзорной статье. [ 81 ]
Нелинейный PCA
[ редактировать ]
Большинство современных методов нелинейного уменьшения размерности уходят своими теоретическими и алгоритмическими корнями в PCA или K-средние. Первоначальная идея Пирсона заключалась в том, чтобы взять прямую линию (или плоскость), которая будет «наилучшим образом соответствовать» набору точек данных. Тревор Хэсти расширил эту концепцию, предложив основные кривые. [ 85 ] как естественное расширение геометрической интерпретации PCA, которое явно строит многообразие для аппроксимации данных с последующим проецированием на него точек. См. также алгоритм упругой карты и основной геодезический анализ . [ 86 ] Другое популярное обобщение — ядро PCA , которое соответствует PCA, выполняемому в воспроизводящем ядерном гильбертовом пространстве, связанном с положительно определенным ядром.
В полилинейном обучении подпространства [ 87 ] [ 88 ] [ 89 ] PCA обобщается до мультилинейного PCA (MPCA), который извлекает признаки непосредственно из тензорных представлений. MPCA решается путем итеративного выполнения PCA в каждом режиме тензора. MPCA применялся для распознавания лиц, распознавания походки и т. д. MPCA в дальнейшем расширяется до некоррелированного MPCA, неотрицательного MPCA и устойчивого MPCA.
N -факторный анализ главных компонент может быть выполнен с использованием таких моделей, как разложение Такера , PARAFAC , многофакторный анализ, коинерционный анализ, STATIS и DISTATIS.
Прочный PCA
[ редактировать ]Хотя PCA находит математически оптимальный метод (как и при минимизации квадратичной ошибки), он по-прежнему чувствителен к выбросам в данных, которые приводят к большим ошибкам, чего метод пытается избежать в первую очередь. Поэтому обычной практикой является удаление выбросов перед вычислением PCA. Однако в некоторых контекстах выбросы бывает сложно выявить. Например, в интеллектуального анализа данных алгоритмах , таких как корреляционная кластеризация , назначение точек кластерам и выбросам заранее не известно. Недавно предложенное обобщение PCA [ 90 ] на основе взвешенного PCA повышает надежность за счет присвоения объектам данных разных весов на основе их предполагаемой релевантности.
Также были предложены устойчивые к выбросам варианты PCA, основанные на формулировках L1-нормы ( L1-PCA ). [ 6 ] [ 4 ]
Надежный анализ главных компонент (RPCA) посредством разложения в низкоранговых и разреженных матрицах представляет собой модификацию PCA, которая хорошо работает в отношении сильно искаженных наблюдений. [ 91 ] [ 92 ] [ 93 ]
Подобные методы
[ редактировать ]Независимый анализ компонентов
[ редактировать ]Анализ независимых компонентов (ICA) направлен на решение тех же задач, что и анализ главных компонентов, но находит аддитивно разделяемые компоненты, а не последовательные приближения.
Анализ сетевых компонентов
[ редактировать ]Дана матрица , он пытается разложить его на две матрицы так, что . Ключевое отличие от таких методов, как PCA и ICA, заключается в том, что некоторые записи ограничены равными 0. Здесь называется регуляторным слоем. Хотя в целом такое разложение может иметь несколько решений, они доказывают, что при выполнении следующих условий:



- имеет полный ранг столбца
- Каждый столбец должен иметь по крайней мере нули где количество столбцов (или, альтернативно, количество строк ). Обоснованием этого критерия является то, что если узел удален из регулятивного уровня вместе со всеми подключенными к нему выходными узлами, результат все равно должен характеризоваться матрицей связности с полным рангом столбца.
- должен иметь полный ранг строки.

тогда разложение однозначно с точностью до умножения на скаляр. [ 94 ]
Дискриминантный анализ главных компонентов
[ редактировать ]Дискриминантный анализ главных компонентов (DAPC) — это многомерный метод, используемый для идентификации и описания кластеров генетически связанных людей. Генетическая изменчивость разделена на два компонента: вариации между группами и внутри групп, и она максимизирует первую. Линейные дискриминанты — это линейные комбинации аллелей, которые лучше всего разделяют кластеры. Таким образом, аллели, которые больше всего способствуют этой дискриминации, — это те, которые наиболее заметно различаются между группами. Вклад аллелей в группы, идентифицированные с помощью DAPC, может позволить идентифицировать области генома, вызывающие генетическую дивергенцию между группами. [ 95 ] В DAPC данные сначала преобразуются с использованием анализа главных компонентов (PCA), а затем кластеры идентифицируются с помощью дискриминантного анализа (DA).
DAPC можно реализовать на R с помощью пакета Adegenet. (подробнее: adegenet в Интернете )
Анализ направленных компонентов
[ редактировать ]Анализ направленных компонентов (DCA) — это метод, используемый в науках об атмосфере для анализа многомерных наборов данных. [ 96 ] Как и PCA, он позволяет уменьшить размерность, улучшить визуализацию и улучшить интерпретируемость больших наборов данных. Как и PCA, он основан на ковариационной матрице, полученной из входного набора данных. Разница между PCA и DCA заключается в том, что DCA дополнительно требует ввода направления вектора, называемого воздействием. В то время как PCA максимизирует объясненную дисперсию, DCA максимизирует плотность вероятности с учетом воздействия. Мотивацией для DCA является поиск компонентов многомерного набора данных, которые одновременно вероятны (измеряются с использованием плотности вероятности) и важны (измеряются с использованием воздействия). DCA использовался для поиска наиболее вероятных и наиболее серьезных моделей волн тепла в ансамблях прогнозов погоды. , [ 97 ] и наиболее вероятные и наиболее важные изменения количества осадков из-за изменения климата. . [ 98 ]
Программное обеспечение/исходный код
[ редактировать ]- ALGLIB — библиотека C++ и C#, реализующая PCA и усеченный PCA.
- Analytica – встроенная функция EigenDecomp вычисляет главные компоненты.
- ELKI — включает PCA для проецирования, включая надежные варианты PCA, а также алгоритмы кластеризации на основе PCA .
- Gretl – анализ главных компонент может быть выполнен либо через
pcaкомандой или черезprincomp()функция. - Джулия – поддерживает PCA с
pcaфункция в пакете MultivariateStats - KNIME — программное обеспечение для анализа узлов на основе Java, в котором узлы, называемые PCA, PCA Computing, PCA Apply, PCA Inverse, упрощают задачу.
- Maple (программное обеспечение) — команда PCA используется для выполнения анализа главных компонентов набора данных.
- Mathematica – реализует анализ главных компонентов с помощью команды PrincipalComponents, используя методы ковариации и корреляции.
- MathPHP — математическая библиотека PHP с поддержкой PCA.
- MATLAB – Функция SVD является частью базовой системы. В панели инструментов статистики функции
princompиpca(R2012b) дают главные компоненты, а функцияpcaresдает остатки и восстановленную матрицу для приближения PCA низкого ранга. - Matplotlib — библиотека Python имеет пакет PCA в модуле .mlab.
- mlpack — обеспечивает реализацию анализа главных компонентов на C++ .
- mrmath — высокопроизводительная математическая библиотека для Delphi и FreePascal, способная выполнять PCA; включая надежные варианты.
- Библиотека NAG . Анализ основных компонентов осуществляется через
g03aaподпрограмма (доступна в обеих версиях библиотеки для Фортрана). - NMath — собственная числовая библиотека, содержащая PCA для .NET Framework .
- GNU Octave - вычислительная среда с бесплатным программным обеспечением, в основном совместимая с MATLAB, функция
princompдает главную компоненту. - OpenCV
- База данных Oracle 12c – реализована через
DBMS_DATA_MINING.SVDS_SCORING_MODEуказав значение настройкиSVDS_SCORING_PCA - Orange (программное обеспечение) – интегрирует PCA в среду визуального программирования. PCA отображает график осыпи (степень объясненной дисперсии), где пользователь может в интерактивном режиме выбрать количество основных компонентов.
- Origin – содержит PCA в версии Pro.
- Qlucore — коммерческое программное обеспечение для анализа многомерных данных с мгновенным ответом с использованием PCA.
- R – Бесплатный статистический пакет, функции
princompиprcompможет использоваться для анализа главных компонент;prcompиспользует разложение по сингулярным значениям , что обычно дает лучшую числовую точность. Некоторые пакеты, реализующие PCA в R, включают, помимо прочего:ade4,vegan,ExPosition,dimRed, иFactoMineR. - SAS – Собственное программное обеспечение; например, см. [ 99 ]
- scikit-learn — библиотека Python для машинного обучения, которая содержит PCA, Probabilistic PCA, Kernel PCA, Sparse PCA и другие методы в модуле декомпозиции.
- Scilab - бесплатный кроссплатформенный пакет численных вычислений с открытым исходным кодом, функция
princompвычисляет анализ главных компонент, функцияpcaвычисляет анализ главных компонентов со стандартизированными переменными. - SPSS — фирменное программное обеспечение, наиболее часто используемое социологами для PCA, факторного анализа и связанного с ним кластерного анализа.
- Weka — Java-библиотека для машинного обучения, содержащая модули для вычисления основных компонентов.
См. также
[ редактировать ]- Анализ соответствия (для таблиц сопряженности)
- Анализ множественных соответствий (для качественных переменных)
- Факторный анализ смешанных данных (для количественных и качественных переменных)
- Каноническая корреляция
- Аппроксимация матрицы CUR (может заменить аппроксимацию SVD низкого ранга)
- Анализ соответствия без тренда
- Анализ направленных компонентов
- Динамическое модовое разложение
- Эйгенфейс
- Алгоритм ожидания-максимизации
- Исследовательский факторный анализ (Викиверситет)
- Факториальный код
- Функциональный анализ главных компонентов
- Анализ геометрических данных
- Независимый анализ компонентов
- Ядро PCA
- Анализ главных компонент L1-нормы
- Низкоранговое приближение
- Разложение матрицы
- Неотрицательная матричная факторизация
- Нелинейное уменьшение размерности
- Правило Оджи
- Модель распределения точек (PCA применяется к морфометрии и компьютерному зрению)
- Анализ главных компонентов (Викибуки)
- Регрессия главных компонентов
- Анализ сингулярного спектра
- Разложение по сингулярным значениям
- Разреженный PCA
- Преобразование кодирования
- Взвешенные наименьшие квадраты
Ссылки
[ редактировать ]- ^ Джоллифф, Ян Т.; Кадима, Хорхе (13 апреля 2016 г.). «Анализ главных компонентов: обзор и последние разработки» . Философские труды Королевского общества A: Математические, физические и технические науки . 374 (2065): 20150202. Бибкод : 2016RSPTA.37450202J . дои : 10.1098/rsta.2015.0202 . ПМЦ 4792409 . ПМИД 26953178 .
- ^ Барнетт, Т.П. и Р. Прейзендорфер. (1987). «Происхождение и уровни ежемесячных и сезонных прогнозов температуры приземного воздуха в США, определенные с помощью канонического корреляционного анализа» . Ежемесячный обзор погоды . 115 (9): 1825. Бибкод : 1987MWRv..115.1825B . doi : 10.1175/1520-0493(1987)115<1825:oaloma>2.0.co;2 .
- ^ Сюй, Дэниел; Какаде, Шам М.; Чжан, Тонг (2008). Спектральный алгоритм обучения скрытых марковских моделей . arXiv : 0811.4413 . Бибкод : 2008arXiv0811.4413H .
- ^ Jump up to: а б Маркопулос, Панос П.; Кунду, Сандипан; Чамадия, Шубхам; Падос, Димитрис А. (15 августа 2017 г.). «Эффективный анализ главных компонентов L1-нормы посредством переворота битов». Транзакции IEEE по обработке сигналов . 65 (16): 4252–4264. arXiv : 1610.01959 . Бибкод : 2017ИТСП...65.4252М . дои : 10.1109/TSP.2017.2708023 . S2CID 7931130 .
- ^ Jump up to: а б Чачлакис, Димитрис Г.; Пратер-Беннетт, Эшли; Маркопулос, Панос П. (22 ноября 2019 г.). «Разложение тензора Такера по норме L1» . Доступ IEEE . 7 : 178454–178465. arXiv : 1904.06455 . дои : 10.1109/ACCESS.2019.2955134 .
- ^ Jump up to: а б Маркопулос, Панос П.; Каристинос, Джордж Н.; Падос, Димитрис А. (октябрь 2014 г.). «Оптимальные алгоритмы обработки сигналов в L1-подпространстве». Транзакции IEEE по обработке сигналов . 62 (19): 5046–5058. arXiv : 1405.6785 . Бибкод : 2014ITSP...62.5046M . дои : 10.1109/TSP.2014.2338077 . S2CID 1494171 .
- ^ Жан, Дж.; Васвани, Н. (2015). «Надежный PCA с частичным знанием подпространства» . Транзакции IEEE по обработке сигналов . 63 (13): 3332–3347. arXiv : 1403.1591 . Бибкод : 2015ITSP...63.3332Z . дои : 10.1109/tsp.2015.2421485 . S2CID 1516440 .
- ^ Канаде, Т.; Ке, Цифа (июнь 2005 г.). «Надежная факторизация нормы L₁ при наличии выбросов и отсутствующих данных с помощью альтернативного выпуклого программирования». 2005 Конференция IEEE Computer Society по компьютерному зрению и распознаванию образов (CVPR'05) . Том. 1. ИИЭР. стр. 739–746. CiteSeerX 10.1.1.63.4605 . дои : 10.1109/CVPR.2005.309 . ISBN 978-0-7695-2372-9 . S2CID 17144854 .
- ^ Пирсон, К. (1901). «О прямых и плоскостях, наиболее близких к системам точек пространства» . Философский журнал . 2 (11): 559–572. дои : 10.1080/14786440109462720 . S2CID 125037489 .
- ^ Хотеллинг, Х. (1933). Анализ комплекса статистических переменных на главные компоненты. Журнал педагогической психологии , 24 , 417–441 и 498–520.
Хотеллинг, Х (1936). «Отношения между двумя наборами переменных». Биометрика . 28 (3/4): 321–377. дои : 10.2307/2333955 . JSTOR 2333955 . - ^ Стюарт, GW (1993). «О ранней истории разложения по сингулярным значениям» . Обзор СИАМ . 35 (4): 551–566. дои : 10.1137/1035134 . HDL : 1903/566 .
- ^ Jump up to: а б с д и Джоллифф, IT (2002). Анализ главных компонентов . Серия Спрингера по статистике. Нью-Йорк: Springer-Verlag. дои : 10.1007/b98835 . ISBN 978-0-387-95442-4 .
- ^ Бенджио, Ю.; и др. (2013). «Обучение репрезентации: обзор и новые перспективы». Транзакции IEEE по анализу шаблонов и машинному интеллекту . 35 (8): 1798–1828. arXiv : 1206.5538 . дои : 10.1109/TPAMI.2013.50 . ПМИД 23787338 . S2CID 393948 .
- ^ Форкман Дж., Хосс Дж., Пьефо, Х.П. (2019). «Проверка гипотез для анализа главных компонент при стандартизации переменных» . Журнал сельскохозяйственной, биологической и экологической статистики . 24 (2): 289–308. дои : 10.1007/s13253-019-00355-5 .
{{cite journal}}: CS1 maint: несколько имен: список авторов ( ссылка ) - ^ Бойд, Стивен; Ванденберге, Ливен (8 марта 2004 г.). Выпуклая оптимизация . Издательство Кембриджского университета. дои : 10.1017/cbo9780511804441 . ISBN 978-0-521-83378-3 .
- ^ А. А. Миранда, Ю. А. Ле Борнь и Г. Бонтемпи. Новые маршруты от минимальной ошибки аппроксимации к главным компонентам , том 27, номер 3 / июнь 2008 г., письма о нейронной обработке, Springer
- ^ Фукунага, Кейносукэ (1990). Введение в статистическое распознавание образов . Эльзевир. ISBN 978-0-12-269851-4 .
- ^ Ализаде, Элахе; Лайонс, Саманта М; Касл, Джордан М; Прасад, Ашок (2016). «Измерение систематических изменений формы инвазивных раковых клеток с использованием моментов Цернике» . Интегративная биология . 8 (11): 1183–1193. дои : 10.1039/C6IB00100A . ПМИД 27735002 .
- ^ Лезник, М; Тофаллис, К. 2005 Оценка инвариантных главных компонентов с использованием диагональной регрессии.
- ^ Джонатон Шленс, Учебное пособие по анализу главных компонентов.
- ^ Jump up to: а б с Саммер, Реми; Пуэйо, Лоран; Ларкин, Джеймс (2012). «Обнаружение и характеристика экзопланет и дисков с использованием проекций на собственных изображениях Карунена-Лоэва». Письма астрофизического журнала . 755 (2): Л28. arXiv : 1207.4197 . Бибкод : 2012ApJ...755L..28S . дои : 10.1088/2041-8205/755/2/L28 . S2CID 51088743 .
- ^ Пуэйо, Лоран (2016). «Обнаружение и характеристика экзопланет с использованием проекций на собственных изображениях Кархунен-Лёве: перспективное моделирование» . Астрофизический журнал . 824 (2): 117. arXiv : 1604.06097 . Бибкод : 2016ApJ...824..117P . дои : 10.3847/0004-637X/824/2/117 . S2CID 118349503 .
- ^ Jump up to: а б Блэнтон, Майкл Р.; Роуэйс, Сэм (2007). «К-коррекции и преобразования фильтров в ультрафиолетовом, оптическом и ближнем инфракрасном диапазонах». Астрономический журнал . 133 (2): 734–754. arXiv : astro-ph/0606170 . Бибкод : 2007AJ....133..734B . дои : 10.1086/510127 . S2CID 18561804 .
- ^ Jump up to: а б с Чжу, Гуантунь Б. (19 декабря 2016 г.). «Неотрицательная матричная факторизация (NMF) с гетероскедастическими неопределенностями и отсутствующими данными». arXiv : 1612.06037 [ astro-ph.IM ].
- ^ Jump up to: а б с д и ж Рен, Бин; Пуэйо, Лоран; Чжу, Гуантунь Б.; Дюшен, Гаспар (2018). «Неотрицательная матричная факторизация: надежное извлечение расширенных структур» . Астрофизический журнал . 852 (2): 104. arXiv : 1712.10317 . Бибкод : 2018ApJ...852..104R . дои : 10.3847/1538-4357/aaa1f2 . S2CID 3966513 .
- ^ «Каковы плюсы и минусы PCA?» . i2tutorials . 1 сентября 2019 года . Проверено 4 июня 2021 г.
- ^ Эбботт, Дин (май 2014 г.). Прикладная прогнозная аналитика . Уайли. ISBN 9781118727966 .
- ^ Jump up to: а б Цзян, Хун; Эскридж, Кент М. (2000). «Смещение в анализе главных компонентов из-за коррелирующих наблюдений» . Конференция по прикладной статистике в сельском хозяйстве . дои : 10.4148/2475-7772.1247 . ISSN 2475-7772 .
- ^ Линскер, Ральф (март 1988 г.). «Самоорганизация в перцептивной сети». IEEE-компьютер . 21 (3): 105–117. дои : 10.1109/2.36 . S2CID 1527671 .
- ^ Деко и Обрадович (1996). Теоретико-информационный подход к нейронным вычислениям . Нью-Йорк, штат Нью-Йорк: Спрингер. ISBN 9781461240167 .
- ^ Пламбли, Марк (1991). Теория информации и неконтролируемые нейронные сети . Техническая записка
- ^ Гейгер, Бернхард; Кубин, Гернот (январь 2013 г.). «Усиление сигнала как минимизация потери соответствующей информации». Учеб. Конференция ITG. О системах, коммуникации и кодировании . arXiv : 1205.6935 . Бибкод : 2012arXiv1205.6935G .
- ^ См. также руководство здесь.
- ^ «Справочник по инженерной статистике, раздел 6.5.5.2» . Проверено 19 января 2015 г.
- ^ А.А. Миранда, Ю.-А. Ле Борнь и Ж. Бонтемпи. Новые маршруты от минимальной ошибки аппроксимации к главным компонентам , том 27, номер 3 / июнь 2008 г., письма о нейронной обработке, Springer
- ^ Абди. Х. и Уильямс, ЖЖ (2010). «Анализ главных компонент». Междисциплинарные обзоры Wiley: вычислительная статистика . 2 (4): 433–459. arXiv : 1108.4372 . дои : 10.1002/wics.101 . S2CID 122379222 .
- ^ «Руководство пользователя SAS/STAT(R) 9.3» .
- ^ eig функция Документация Matlab
- ^ «Система распознавания лиц на основе PCA» . www.mathworks.com . 19 июня 2023 г.
- ^ Функция собственных значений Документация Mathematica
- ^ Роуэйс, Сэм. «ЭМ-алгоритмы для PCA и SPCA». Достижения в области нейронных систем обработки информации. Эд. Майкл И. Джордан, Майкл Дж. Кернс и Сара А. Солла, MIT Press, 1998.
- ^ Гелади, Пол; Ковальски, Брюс (1986). «Регрессия частичных наименьших квадратов: Учебное пособие». Аналитика Химика Акта . 185 : 1–17. дои : 10.1016/0003-2670(86)80028-9 .
- ^ Крамер, Р. (1998). Хемометрические методы количественного анализа . Нью-Йорк: CRC Press. ISBN 9780203909805 .
- ^ Андрекут, М. (2009). «Параллельная реализация итеративных алгоритмов PCA на графическом процессоре». Журнал вычислительной биологии . 16 (11): 1593–1599. arXiv : 0811.1081 . дои : 10.1089/cmb.2008.0221 . ПМИД 19772385 . S2CID 1362603 .
- ^ Вармут, МК; Кузьмин, Д. (2008). «Рандомизированные онлайн-алгоритмы PCA с логарифмическими границами сожаления» (PDF) . Журнал исследований машинного обучения . 9 : 2287–2320.
- ^ Каплан, Р.М., и Саккуццо, Д.П. (2010). Психологическое тестирование: принципы, применение и проблемы. (8-е изд.). Бельмонт, Калифорния: Уодсворт, Cengage Learning.
- ^ Шевки, Эшреф; Уильямс, Мэрилин (1949). Социальные районы Лос-Анджелеса: анализ и типология . Издательство Калифорнийского университета.
- ^ Флад, Дж (2000). Сидней разделен: новый взгляд на факториальную экологию. Документ для конференции APA 2000 г., Мельбурн, ноябрь, и для 24-й конференции ANZRSAI, Хобарт, декабрь 2000 г. [1]
- ^ «Социально-экономические показатели территорий» . Австралийское статистическое бюро . 2011 . Проверено 5 мая 2022 г.
- ^ Отчеты о человеческом развитии. «Индекс человеческого развития» . Программа развития ООН . Проверено 6 мая 2022 г.
- ^ Новембре, Джон; Стивенс, Мэтью (2008). «Интерпретация анализа главных компонентов пространственной популяционной генетической изменчивости» . Нат Жене . 40 (5): 646–49. дои : 10.1038/ng.139 . ПМЦ 3989108 . ПМИД 18425127 .
- ^ Эльхайк, Эран (2022). «Результаты популяционно-генетических исследований, основанные на анализе главных компонентов (PCA), сильно необъективны и должны быть переоценены» . Научные отчеты . 12 (1). 14683. Бибкод : 2022NatSR..1214683E . дои : 10.1038/s41598-022-14395-4 . ПМЦ 9424212 . ПМИД 36038559 . S2CID 251932226 .
- ^ ДеСарбо, Уэйн; Хаусманн, Роберт; Кукиц, Джеффри (2007). «Ограниченный анализ главных компонентов для маркетинговых исследований» . Журнал маркетинга в менеджменте . 2 : 305–328 – через Researchgate.
- ^ Даттон, Уильям Х; Бланк, Грант (2013). Культуры Интернета: Интернет в Великобритании (PDF) . Оксфордский Интернет-институт. п. 6.
- ^ Флуд, Джо (2008). «Мультиномиальный анализ обследования жилищной карьеры» . Доклад для конференции Европейской сети жилищных исследований, Дублин . Проверено 6 мая 2022 г.
- ^ Jump up to: а б См. гл. 9 в Майкле Б. Миллере (2013). Математика и статистика для управления финансовыми рисками , 2-е издание. Уайли ISBN 978-1-118-75029-2
- ^ Jump up to: а б §9.7 в книге Джона Халла (2018). Управление рисками и финансовые институты, 5-е издание. Уайли. ISBN 1119448115
- ^ §III.A.3.7.2 в книге Кэрол Александер и Элизабет Шиди, ред. (2004). Справочник профессиональных риск-менеджеров . ПРМИЯ . ISBN 978-0976609704
- ^ пример разложения , Джон Халл
- ^ Либинь Ян. Применение анализа главных компонентов для управления портфелем акций . Факультет экономики и финансов Кентерберийского университета , январь 2015 г.
- ^ Джорджия Пасини (2017); Анализ главных компонентов для управления портфелем акций . Международный журнал чистой и прикладной математики . Том 115 № 1 2017, 153–167
- ^ Jump up to: а б См. гл. 25 § «Тестирование сценариев с использованием анализа главных компонент» в Ли Онге (2014). «Руководство по методам и моделям стресс-тестирования МВФ» , Международный валютный фонд.
- ^ Чапин, Джон; Николелис, Мигель (1999). «Анализ главных компонентов активности ансамбля нейронов выявляет многомерные соматосенсорные представления». Журнал методов нейробиологии . 94 (1): 121–140. дои : 10.1016/S0165-0270(99)00130-2 . ПМИД 10638820 . S2CID 17786731 .
- ^ Бреннер Н., Бялек В. и де Рюйтер ван Стивенинк Р.Р. (2000).
- ^ Йирса, Виктор; Фридрих, Р; Хакен, Герман; Келсо, Скотт (1994). «Теоретическая модель фазовых переходов в мозге человека». Биологическая кибернетика . 71 (1): 27–35. дои : 10.1007/bf00198909 . ПМИД 8054384 . S2CID 5155075 .
- ^ Бенсекри, Ж.-П. (1973). Анализ данных. Том II. Анализ корреспонденции . Париж, Франция: Дюно.
- ^ Гринакр, Майкл (1983). Теория и приложения анализа соответствий . Лондон: Академическая пресса. ISBN 978-0-12-299050-2 .
- ^ Ле Ру; Бриджит и Анри Руане (2004). Геометрический анализ данных: от анализа соответствий к анализу структурированных данных . Дордрехт: Клювер. ISBN 9781402022357 .
- ^ Тимоти А. Браун. Подтверждающий факторный анализ для прикладной методологии исследований в социальных науках . Гилфорд Пресс, 2006 г.
- ^ Меглен, Р.Р. (1991). «Исследование больших баз данных: хемометрический подход с использованием анализа главных компонентов». Журнал хемометрики . 5 (3): 163–179. дои : 10.1002/cem.1180050305 . S2CID 120886184 .
- ^ Х. Жа; К. Дин; М. Гу; X. Он; HD Саймон (декабрь 2001 г.). «Спектральная релаксация для кластеризации K-средних» (PDF) . Нейронные системы обработки информации, том 14 (NIPS 2001) : 1057–1064.
- ^ Крис Дин; Сяофэн Хэ (июль 2004 г.). «Кластеризация K-средних посредством анализа главных компонентов» (PDF) . Учеб. Международной конференции. Машинное обучение (ICML 2004) : 225–232.
- ^ Дриней, П.; А. Фриз; Р. Каннан; С. Вемпала; В. Винай (2004). «Кластеризация больших графов с помощью разложения по сингулярным значениям» (PDF) . Машинное обучение . 56 (1–3): 9–33. дои : 10.1023/b:mach.0000033113.59016.96 . S2CID 5892850 . Проверено 2 августа 2012 г.
- ^ Коэн, М.; С. Элдер; К. Муско; К. Муско; М. Персу (2014). Уменьшение размерности для кластеризации k-средних и аппроксимации низкого ранга (Приложение B) . arXiv : 1410.6801 . Бибкод : 2014arXiv1410.6801C .
- ^ Хуэй Цзоу; Тревор Хэсти; Роберт Тибширани (2006). «Анализ разреженных главных компонентов» (PDF) . Журнал вычислительной и графической статистики . 15 (2): 262–286. CiteSeerX 10.1.1.62.580 . дои : 10.1198/106186006x113430 . S2CID 5730904 .
- ^ Александр д'Аспремон; Лоран Эль Гауи; Майкл И. Джордан; Герт Р.Г. Ланкриет (2007). «Прямая формулировка разреженного PCA с использованием полуопределенного программирования» (PDF) . Обзор СИАМ . 49 (3): 434–448. arXiv : cs/0406021 . дои : 10.1137/050645506 . S2CID 5490061 .
- ^ Мишель Журне; Юрий Нестеров; Питер Рихтарик; Родольф Гробница (2010). «Обобщенный степенной метод для анализа разреженных главных компонентов» (PDF) . Журнал исследований машинного обучения . 11 : 517–553. arXiv : 0811.4724 . Бибкод : 2008arXiv0811.4724J . CORE Дискуссионный документ 2008/70.
- ^ Питер Рихтарик; Мартин Такач; С. Дамла Ахипасаоглу (2012). «Попеременная максимизация: унификация структуры для 8 разреженных формулировок PCA и эффективных параллельных кодов». arXiv : 1212.4137 [ stat.ML ].
- ^ Бабак Могаддам; Яир Вайс; Шай Авидан (2005). «Спектральные границы для разреженного PCA: точные и жадные алгоритмы» (PDF) . Достижения в области нейронных систем обработки информации . Том. 18. МИТ Пресс.
- ^ Юэ Гуань; Дженнифер Дай (2009). «Разреженный вероятностный анализ главных компонентов» (PDF) . Журнал семинаров по исследованиям в области машинного обучения и материалы конференций . 5 : 185.
- ^ Хуэй Цзоу; Линчжоу Сюэ (2018). «Выборочный обзор анализа разреженных главных компонентов» . Труды IEEE . 106 (8): 1311–1320. дои : 10.1109/JPROC.2018.2846588 .
- ^ А. Н. Горбань , А. Ю. Зиновьев, «Основные графы и многообразия» , В: Справочник по исследованиям приложений и тенденций машинного обучения: алгоритмы, методы и методы , Оливас ES и др. Eds. Справочник по информатике, IGI Global: Херши, Пенсильвания, США, 2009. 28–59.
- ^ Ван, Ю.; Кляйн, Дж.Г.; Чжан, Ю.; Зивертс, AM; Смотри, депутат; Ян, Ф.; Талантов Д.; Тиммерманс, М.; Мейер-ван Гелдер, Мэн; Ю, Дж.; и др. (2005). «Профили экспрессии генов для прогнозирования отдаленных метастазов первичного рака молочной железы с отрицательным поражением лимфатических узлов». Ланцет . 365 (9460): 671–679. дои : 10.1016/S0140-6736(05)17947-1 . ПМИД 15721472 . S2CID 16358549 . Онлайн-данные
- ^ Зиновьев А. «ВиДаЭксперт – инструмент многомерной визуализации данных» . Институт Кюри . Париж. (бесплатно для некоммерческого использования)
- ^ Хасти, Т .; Штютцле, В. (июнь 1989 г.). «Основные кривые» (PDF) . Журнал Американской статистической ассоциации . 84 (406): 502–506. дои : 10.1080/01621459.1989.10478797 .
- ^ А. Н. Горбань, Б. Кегль, Д. К. Вунш, А. Зиновьев (ред.), Основные многообразия для визуализации данных и уменьшения размерности , LNCSE 58, Шпрингер, Берлин – Гейдельберг – Нью-Йорк, 2007 г. ISBN 978-3-540-73749-0
- ^ Василеску, МАО; Терзопулос, Д. (2003). Полилинейный подпространственный анализ ансамблей изображений (PDF) . Материалы конференции IEEE по компьютерному зрению и распознаванию образов (CVPR'03). Мэдисон, Висконсин.
- ^ Василеску, МАО; Терзопулос, Д. (2002). Полилинейный анализ ансамблей изображений: TensorFaces (PDF) . Конспекты лекций по информатике 2350; (Представлено на 7-й Европейской конференции по компьютерному зрению (ECCV'02), Копенгаген, Дания). Шпрингер, Берлин, Гейдельберг. дои : 10.1007/3-540-47969-4_30 . ISBN 978-3-540-43745-1 .
- ^ Василеску, МАО; Терзопулос, Д. (июнь 2005 г.). Многолинейный анализ независимых компонентов (PDF) . Материалы конференции IEEE по компьютерному зрению и распознаванию образов (CVPR'05). Том. 1. Сан-Диего, Калифорния. стр. 547–553.
- ^ Кригель, HP; Крегер, П.; Шуберт, Э.; Зимек, А. (2008). «Общая основа повышения устойчивости алгоритмов корреляционной кластеризации на основе PCA». Управление научно-статистическими базами данных . Конспекты лекций по информатике. Том. 5069. стр. 418–435. CiteSeerX 10.1.1.144.4864 . дои : 10.1007/978-3-540-69497-7_27 . ISBN 978-3-540-69476-2 .
- ^ Эммануэль Дж. Кандес; Сяодун Ли; Йи Ма; Джон Райт (2011). «Надежный анализ главных компонентов?». Журнал АКМ . 58 (3): 11. arXiv : 0912.3599 . дои : 10.1145/1970392.1970395 . S2CID 7128002 .
- ^ Т. Бауманс; Э. Заза (2014). «Надежный PCA через поиск основных компонентов: обзор сравнительной оценки в области видеонаблюдения». Компьютерное зрение и понимание изображений . 122 : 22–34. дои : 10.1016/j.cviu.2013.11.009 .
- ^ Т. Бауманс; А. Собрал; С. Джавед; С. Юнг; Э. Заза (2015). «Разложение на низкоранговые плюс аддитивные матрицы для разделения фона и переднего плана: обзор сравнительной оценки с крупномасштабным набором данных». Обзор компьютерных наук . 23 : 1–71. arXiv : 1511.01245 . Бибкод : 2015arXiv151101245B . дои : 10.1016/j.cosrev.2016.11.001 . S2CID 10420698 .
- ^ Ляо, JC; Босколо, Р.; Ян, Ю.-Л.; Тран, Л.М.; Сабатти, К. ; Ройчоудхури, вице-президент (2003 г.). «Сетевой компонентный анализ: Реконструкция регуляторных сигналов в биологических системах» . Труды Национальной академии наук . 100 (26): 15522–15527. Бибкод : 2003PNAS..10015522L . дои : 10.1073/pnas.2136632100 . ПМК 307600 . ПМИД 14673099 .
- ^ Ляо, Т.; Жомбар, С.; Девильяр, Ф.; Балу (2010). «Дискриминантный анализ главных компонентов: новый метод анализа генетически структурированных популяций» . БМК Генетика . 11:11:94 . дои : 10.1186/1471-2156-11-94 . ПМЦ 2973851 . ПМИД 20950446 .
- ^ Джусон, С. (2020). «Альтернатива PCA для оценки доминирующих моделей изменчивости климата и экстремальных явлений с применением к сезонным осадкам в США и Китае» . Атмосфера . 11 (4): 354. Бибкод : 2020Атмос..11..354J . дои : 10.3390/atmos11040354 .
- ^ Шер, С.; Джусон, С.; Мессори, Г. (2021). «Надежные наихудшие сценарии на основе ансамблевых прогнозов» . Погода и прогнозирование . 36 (4): 1357–1373. Бибкод : 2021WtFor..36.1357S . дои : 10.1175/WAF-D-20-0219.1 . S2CID 236300040 .
- ^ Джусон, С.; Мессори, Г.; Барбато, Г.; Меркольяно, П.; Мысиак, Дж.; Сасси, М. (2022). «Разработка репрезентативных сценариев воздействия на основе ансамблей климатических проекций с применением к UKCP18 и осадкам EURO-CORDEX» . Журнал достижений в моделировании систем Земли . 15 (1). дои : 10.1029/2022MS003038 . S2CID 254965361 .
- ^ «Анализ главных компонентов» . Институт цифровых исследований и образования . Калифорнийский университет в Лос-Анджелесе . Проверено 29 мая 2018 г.
Дальнейшее чтение
[ редактировать ]- Джексон, Дж. Э. (1991). Руководство пользователя по основным компонентам (Wiley).
- Джоллифф, IT (1986). Анализ главных компонентов . Серия Спрингера по статистике. Спрингер-Верлаг. стр. 487 . CiteSeerX 10.1.1.149.8828 . дои : 10.1007/b98835 . ISBN 978-0-387-95442-4 .
- Джоллифф, IT (2002). Анализ главных компонентов . Серия Спрингера по статистике. Нью-Йорк: Springer-Verlag. дои : 10.1007/b98835 . ISBN 978-0-387-95442-4 .
- Юссон Франсуа, Ле Себастьян и Паж Жером (2009). Исследовательский многомерный анализ на примере использования R. Чепмен и Холл/CRC The R Series, Лондон. 224стр. ISBN 978-2-7535-0938-2
- Пажес Жером (2014). Многофакторный анализ на примере использования R. Чепмен и Холл / CRC The R Series, Лондон, 272 стр.
Внешние ссылки
[ редактировать ]- Видео Копенгагенского университета Расмуса Бро на YouTube
- Видео Стэнфордского университета Эндрю Нг на YouTube
- Учебное пособие по анализу главных компонентов
- Введение в анализ главных компонентов для непрофессионала на YouTube (видео продолжительностью менее 100 секунд).
- StatQuest: StatQuest: Анализ главных компонентов (PCA), шаг за шагом на YouTube
- См. также список реализаций программного обеспечения.
| Базы данных органов управления : Национальные |
|---|