Полнотекстовый поиск
Эта статья нуждается в дополнительных цитатах для проверки . ( август 2012 г. ) |
В текстовом поиске полнотекстовый поиск относится к методам поиска отдельного на компьютере хранящегося документа, , или коллекции в полнотекстовой базе данных . Полнотекстовый поиск отличается от поиска, основанного на метаданных или частях исходного текста, представленных в базах данных (например, названиях, рефератах, выбранных разделах или библиографических ссылках).
При полнотекстовом поиске поисковая система проверяет все слова в каждом сохраненном документе, пытаясь соответствовать критериям поиска (например, тексту, указанному пользователем). Методы полнотекстового поиска появились в 1960-х годах, например, IBM STAIRS с 1969 года, и стали обычным явлением в онлайн -библиографических базах данных в 1990-х годах. [ нужна проверка ] Многие веб-сайты и прикладные программы (например, текстовые редакторы ) предоставляют возможности полнотекстового поиска. Некоторые поисковые системы, такие как бывшая AltaVista , используют методы полнотекстового поиска, в то время как другие индексируют только часть веб-страниц, проверенных их системами индексирования. [1]
Индексирование
[ редактировать ]При работе с небольшим количеством документов система полнотекстового поиска может напрямую сканировать содержимое документов при каждом запросе . Такая стратегия называется « последовательным сканированием ». Это то, что делают некоторые инструменты, такие как grep , при поиске.
Однако, когда количество документов для поиска потенциально велико или количество выполняемых поисковых запросов существенно, задача полнотекстового поиска часто разделяется на две задачи: индексирование и поиск. На этапе индексирования сканируется текст всех документов и строится список поисковых запросов (часто называемый индексом , но правильнее называть согласованием ). На этапе поиска при выполнении конкретного запроса используется только индекс, а не текст исходных документов. [2]
Индексатор сделает запись в указателе для каждого термина или слова, найденного в документе, и, возможно, отметит его относительное положение в документе. Обычно индексатор игнорирует стоп-слова (такие как «the» и «and»), которые являются общими и недостаточно значимыми, чтобы их можно было использовать при поиске. Некоторые индексаторы также используют специфическую для языка основу индексируемых слов. Например, слова «ездит», «возил» и «ехал» будут записаны в указателе под одним понятийным словом «драйв».
Компромисс между точностью и полнотой
[ редактировать ]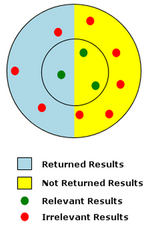
Напомним, что измеряется количество релевантных результатов, полученных в результате поиска, а точность — это мера качества возвращаемых результатов. Напомним, это отношение возвращаемых релевантных результатов ко всем релевантным результатам. Точность — это отношение количества возвращенных релевантных результатов к общему количеству возвращенных результатов.
Диаграмма справа представляет поиск с низкой точностью и малой запоминаемостью. На диаграмме красные и зеленые точки обозначают общую совокупность потенциальных результатов поиска для данного поиска. Красные точки представляют собой нерелевантные результаты, а зеленые точки — значимые результаты. Релевантность определяется близостью результатов поиска к центру внутреннего круга. Из всех возможных результатов те, которые действительно были получены в результате поиска, показаны на голубом фоне. В примере был возвращен только 1 релевантный результат из 3 возможных релевантных результатов, поэтому коэффициент отзыва очень низкий — 1/3, или 33%. Точность для примера составляет очень низкую 1/4, или 25%, поскольку только 1 из 4 возвращенных результатов был релевантным. [3]
Из-за неоднозначности естественного языка системы полнотекстового поиска обычно включают в себя такие опции, как фильтрация для повышения точности и стемминг для увеличения запоминаемости. Поиск по контролируемому словарю также помогает устранить проблемы с низкой точностью, помечая документы таким образом, чтобы исключить двусмысленность. Компромисс между точностью и полнотой прост: повышение точности может снизить общую полноту, а увеличение полноты снижает точность. [4]
Ложноположительная проблема
[ редактировать ]Полнотекстовый поиск, скорее всего, приведет к получению большого количества документов, которые не имеют отношения к заданному вопросу поиска. Такие документы называются ложными срабатываниями (см. ошибку I рода ). Поиск ненужных документов часто вызван присущей естественному языку двусмысленностью . На примере диаграммы справа ложноположительные результаты представлены нерелевантными результатами (красные точки), которые были возвращены поиском (на голубом фоне).
Методы кластеризации, основанные на байесовских алгоритмах, могут помочь уменьшить количество ложных срабатываний. По поисковому запросу «банк» можно использовать кластеризацию для категоризации совокупности документов/данных на «финансовое учреждение», «место для сидения», «место для хранения» и т. д. В зависимости от встречаемости слов, соответствующих категориям, Условия поиска или результаты поиска могут быть помещены в одну или несколько категорий. Этот метод широко применяется в сфере электронного обнаружения . [ нужны разъяснения ]
Улучшения производительности
[ редактировать ]Недостатки полнотекстового поиска были устранены двумя способами: путем предоставления пользователям инструментов, которые позволяют им более точно формулировать свои поисковые вопросы, и путем разработки новых алгоритмов поиска, которые повышают точность поиска.
Улучшенные инструменты запросов
[ редактировать ]- Ключевые слова . Создателям документов (или обученным индексаторам) предлагается предоставить список слов, описывающих тему текста, включая синонимы слов, описывающих эту тему. Ключевые слова улучшают запоминаемость, особенно если список ключевых слов включает в себя искомое слово, которого нет в тексте документа.
- Поиск с ограничением по полю . Некоторые поисковые системы позволяют пользователям ограничивать полнотекстовый поиск определенным полем в сохраненной записи данных , например «Название» или «Автор».
- Булевы запросы . Поиски, в которых используются логические операторы (например, «энциклопедия» И «онлайн», а НЕ «Энкарта» ) могут значительно повысить точность полнотекстового поиска. Оператор AND фактически говорит: «Не извлекайте документ, если он не содержит оба этих термина». Оператор NOT фактически говорит: «Не получать ни одного документа, содержащего это слово». Если список поиска извлекает слишком мало документов, Оператор OR можно использовать для увеличения отзыва ; рассмотрим, например, «энциклопедия» И «онлайн» ИЛИ «Интернет», НЕ «Энкарта» . В результате поиска будут найдены документы об онлайн-энциклопедиях, в которых используется термин «Интернет» вместо «онлайн». Такое увеличение точности очень часто бывает контрпродуктивным, поскольку обычно сопровождается резкой потерей памяти. [5]
- Поиск фраз . Поиск по фразе находит только те документы, которые содержат указанную фразу, например: «Arc.Ask3.Ru, свободная энциклопедия».
- Поиск концепции . Поиск, основанный на понятиях, состоящих из нескольких слов, например, «Обработка составных терминов» . Этот тип поиска становится популярным во многих решениях для обнаружения электронных данных.
- Поиск соответствия . Поиск по соответствию создает алфавитный список всех основных слов, встречающихся в тексте, с их непосредственным контекстом.
- Поиск близости . Фразовый поиск находит только те документы, которые содержат два или более слов, разделенных указанным количеством слов; поиск «Arc.Ask3.Ru» ВНУТРИ2 «бесплатно» будет извлекать только те документы, в которых слова «Arc.Ask3.Ru» и «бесплатно» встречаются в двух словах друг от друга.
- Регулярное выражение . Регулярное выражение использует сложный, но мощный синтаксис запросов , который можно использовать для точного указания условий извлечения.
- Нечеткий поиск будет искать документ, который соответствует заданным терминам и некоторым вариациям вокруг них (например, с использованием расстояния редактирования для ограничения множественных вариантов).
- Поиск по шаблону . Поиск, при котором один или несколько символов в поисковом запросе заменяются подстановочным знаком, например звездочкой . Например, использование звездочки в поисковом запросе «s*n» найдет в тексте слова «грех», «сын», «солнце» и т. д.
Улучшенные алгоритмы поиска
[ редактировать ]Алгоритм PageRank , разработанный Google, придает больше внимания документам, на которые другие веб-страницы . ссылаются [6] см . в разделе Поисковая система Дополнительные примеры .
Программное обеспечение
[ редактировать ]Ниже приведен неполный список доступных программных продуктов, основной целью которых является полнотекстовое индексирование и поиск. Некоторые из них сопровождаются подробным описанием теории работы или внутренних алгоритмов, что может дать дополнительное представление о том, как можно осуществлять полнотекстовый поиск.
Бесплатное программное обеспечение с открытым исходным кодом
[ редактировать ]Собственное программное обеспечение
[ редактировать ]- Алголия
- Автономная корпорация
- Поиск Azure
- Проект Бар-Илан Респонса
- Базовая база данных
- Мозговое ПО
- БРС/Поиск
- Концепция поиска ограничена
- Дизельпойнт
- dtSearch
- Эластичный поиск
- Эндека
- Эксалид
- Быстрый поиск и передача
- Инктоми
- Осознанное воображение
- МаркЛогик
- SAP Хана [7]
- Свифтайп
- ООО «Тандерстоун Софтвер».
- Вершинный AI-поиск [8]
- Веспа
- очень яркий
Ссылки
[ редактировать ]- ^ На практике может быть сложно определить, как работает конкретная поисковая система. Алгоритмы поиска, фактически используемые службами веб-поиска, редко полностью раскрываются из-за опасений, что веб-предприниматели будут использовать методы поисковой оптимизации для повышения своей известности в списках поиска.
- ^ «Возможности системы полнотекстового поиска» . Архивировано из оригинала 23 декабря 2010 года.
- ^ Коулз, Майкл (2008). Полнотекстовый поиск Pro в SQL Server 2008 (изд. версии 1). Издательская компания «Апресс» . ISBN 978-1-4302-1594-3 .
- ^ Б., Ювоно; Ли, Д.Л. (1996). Алгоритмы поиска и ранжирования для размещения ресурсов во Всемирной паутине . 12-я Международная конференция по инженерии данных (ICDE'96). п. 164.
- ^ Экспериментальное сравнение схем интерпретации логических запросов
- ^ США 6285999 , Пейдж, Лоуренс, «Метод ранжирования узлов в связанной базе данных», опубликовано 9 января 1998 г., выдано 4 сентября 2001 г. «Метод присваивает ранги важности узлам в связанной базе данных, такой как любая база данных документов, содержащих цитаты, всемирная паутина или любая другая база данных гипермедиа. Ранг, присвоенный документу, рассчитывается на основе рангов документов, цитирующих его. Кроме того, , ранг документа..."
- ^ «SAP добавляет пакеты программного обеспечения на основе HANA в портфель IoT | MarTech Advisor» . www.martechadvisor.com .
- ^ «Поиск вершин ИИ» . cloud.google.com/enterprise-search .
См. также
[ редактировать ]- Сопоставление шаблонов и сопоставление строк
- Обработка сложных терминов
- Корпоративный поиск
- Извлечение информации
- Поиск информации
- Фасетный поиск
- WebCrawler , первый движок FTS
- Индексирование поисковыми системами : как поисковые системы генерируют индексы для поддержки полнотекстового поиска.
| Базы данных органов управления : Национальные |
|---|