Левая рекурсия
Эта статья может быть слишком технической для понимания большинства читателей . ( Ноябрь 2015 г. ) |
В теории языка информатики , формальной левая рекурсия — это частный случай рекурсии когда строка распознается как часть языка на основании того факта, что она разлагается на строку того же языка (слева) и суффикс (слева). право). Например, можно признать суммой, поскольку ее можно разбить на , также сумма, и , подходящий суффикс.



С точки зрения контекстно-свободной грамматики , нетерминал является леворекурсивным, если крайний левый символ в одном из его произведений является самим собой (в случае прямой левой рекурсии) или может быть создан некоторой последовательностью подстановок (в случае косвенной грамматики). левая рекурсия).
Определение
[ редактировать ]Грамматика является леворекурсивной тогда и только тогда, когда существует нетерминальный символ. который может привести к форме предложения , где он будет самым левым символом. [1] Символически,

- ,

где указывает операцию выполнения одной или нескольких замен, и — любая последовательность терминальных и нетерминальных символов.


Прямая левая рекурсия
[ редактировать ]Прямая левая рекурсия возникает, когда определение может быть удовлетворено только одной заменой. Требуется правило вида

где представляет собой последовательность нетерминалов и терминалов. Например, правило

является непосредственно леворекурсивным. слева направо Анализатор рекурсивного спуска для этого правила может выглядеть так:
void Expression() {
Expression();
match('+');
Term();
}
и такой код при выполнении впадет в бесконечную рекурсию.
Косвенная левая рекурсия
[ редактировать ]Косвенная левая рекурсия возникает, когда определение левой рекурсии удовлетворяется посредством нескольких замен. Это влечет за собой набор правил, следующих шаблону




где представляют собой последовательности, каждая из которых может дать пустую строку , а могут быть любые последовательности терминальных и нетерминальных символов. Обратите внимание, что эти последовательности могут быть пустыми. Вывод



затем дает как крайний левый в его окончательной форме предложения.

Использование
[ редактировать ]Левая рекурсия обычно используется как идиома для создания левоассоциативных операций : выражение a+b-c-d+e оценивается как (((a+b)-c)-d)+e. В этом случае этот порядок вычислений может быть достигнут с помощью синтаксиса с помощью трех грамматических правил.


Они позволяют только анализировать a+b-c-d+e как состоящий из a+b-c-d и e, где a+b-c-d в свою очередь состоит из a+b-c и d, пока a+b-c состоит из a+b и c, и т. д.


Удаление левой рекурсии
[ редактировать ]Левая рекурсия часто создает проблемы для парсеров, либо потому, что она приводит их к бесконечной рекурсии (как в случае большинства нисходящих парсеров ), либо потому, что они ожидают правил в нормальной форме, которые запрещают это (как в случае многих восходящих парсеров). парсеры [ нужны разъяснения ] ). Поэтому грамматика часто подвергается предварительной обработке для устранения левой рекурсии.
Удаление прямой левой рекурсии
[ редактировать ]Общий алгоритм удаления прямой левой рекурсии следующий. В этот метод было внесено несколько усовершенствований. [2] Для леворекурсивного нетерминала , отбросьте все правила вида и рассмотрим те, что остались:


где:
- каждый представляет собой непустую последовательность нетерминалов и терминалов, и
- каждый представляет собой последовательность нетерминалов и терминалов, которая не начинается с .

Замените их двумя наборами произведений, один набор для :

и еще набор для свежего нетерминала (часто называемый «хвостом» или «остатком»):


Повторяйте этот процесс до тех пор, пока не останется прямой левой рекурсии.
В качестве примера рассмотрим набор правил

Это можно переписать, чтобы избежать левой рекурсии, как


Удаление всей левой рекурсии
[ редактировать ]Вышеописанный процесс можно расширить, чтобы исключить всю левую рекурсию, сначала преобразуя косвенную левую рекурсию в прямую левую рекурсию на нетерминале с наибольшим номером в цикле.
- Входные данные Грамматика: набор нетерминалов и их продукция
- Выходные данные Модифицированная грамматика, генерирующая тот же язык, но без левой рекурсии.
- Для каждого нетерминала :
- Повторяйте до тех пор, пока итерация не оставит грамматику неизменной:
- Для каждого правила , представляет собой последовательность терминалов и нетерминалов:
- Если начинается с нетерминала и :
- Позволять быть без его ведущего .
- Удалить правило .
- Для каждого правила :
- Добавить правило .
- Если начинается с нетерминала и :
- Для каждого правила , представляет собой последовательность терминалов и нетерминалов:
- Удалить прямую левую рекурсию для как описано выше.
- Повторяйте до тех пор, пока итерация не оставит грамматику неизменной:
- Для каждого нетерминала :









Шаг 1.1.1 представляет собой расширение исходного нетерминального в правой части некоторого правила , но только если . Если был одним шагом в цикле продукций, приводящим к левой рекурсии, то это сократило этот цикл на один шаг, но часто за счет увеличения количества правил.

Алгоритм можно рассматривать как установление топологического порядка на нетерминалах: после этого может быть только правило если . Обратите внимание, что этот алгоритм очень чувствителен к нетерминальному упорядочению; оптимизации часто фокусируются на правильном выборе этого порядка.

Подводные камни
[ редактировать ]Хотя приведенные выше преобразования сохраняют язык, созданный грамматикой, они могут изменить деревья синтаксического анализа , которые свидетельствуют о распознавании строк. При соответствующем учете переписывание деревьев может восстановить оригиналы, но если этот шаг пропустить, различия могут изменить семантику анализа.
Ассоциативность особенно уязвима; В новой грамматике левоассоциативные операторы обычно появляются в форме правоассоциативной структуры. Например, начиная с этой грамматики:



стандартные преобразования для удаления левой рекурсии дают следующее:




Разбор строки «1 — 2 — 3» с помощью первой грамматики в анализаторе LALR (который может обрабатывать леворекурсивные грамматики) привел бы к получению дерева разбора:
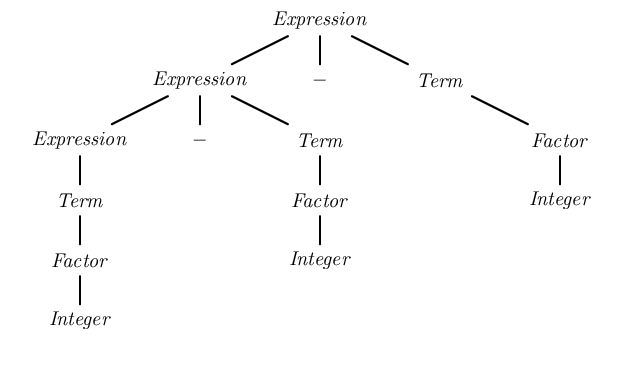
Это дерево разбора группирует термины слева, давая правильную семантику (1 - 2) - 3 .
Разбор со второй грамматикой дает

что при правильной интерпретации означает 1 + (-2 + (-3)) , что также правильно, но менее точно соответствует входным данным и гораздо сложнее реализовать для некоторых операторов. Обратите внимание, как члены справа появляются глубже в дереве, подобно тому, как праворекурсивная грамматика расположила бы их для 1 - (2 - 3) .
Учет левой рекурсии при синтаксическом анализе сверху вниз
[ редактировать ], Формальная грамматика содержащая левую рекурсию, не может быть проанализирована LL (k)-анализатором или другим анализатором наивного рекурсивного спуска , если она не преобразована в слабо эквивалентную праворекурсивную форму. Напротив, левая рекурсия предпочтительнее для анализаторов LALR , поскольку она приводит к меньшему использованию стека, чем правая рекурсия . Однако более сложные нисходящие синтаксические анализаторы могут реализовать общие контекстно-свободные грамматики за счет сокращения. В 2006 году Фрост и Хафиз описали алгоритм, который учитывает неоднозначные грамматики с помощью прямых леворекурсивных правил производства . [3] Этот алгоритм был расширен до полного алгоритма синтаксического анализа , чтобы обеспечить как косвенную, так и прямую левую рекурсию за полиномиальное время, а также генерировать компактные представления полиномиального размера потенциально экспоненциального числа деревьев синтаксического анализа для весьма неоднозначных грамматик Фростом, Хафизом и Каллаганом в 2007 году. . [4] Затем авторы реализовали алгоритм в виде набора комбинаторов парсеров, написанных на языке программирования Haskell . [5]
См. также
[ редактировать ]Ссылки
[ редактировать ]- ^ Заметки по теории формального языка и синтаксическому анализу в Wayback Machine (архивировано 27 ноября 2007 г.). Джеймс Пауэр, факультет компьютерных наук Национального университета Ирландии, Мейнут Мейнут, графство Килдэр, Ирландия. JPR02
- ^ Мур, Роберт К. (май 2000 г.). «Удаление левой рекурсии из контекстно-свободных грамматик» (PDF) . 6-я конференция по прикладной обработке естественного языка : 249–255.
- ^ Фрост, Р.; Р. Хафиз (2006). «Новый алгоритм синтаксического анализа сверху вниз для устранения неоднозначности и левой рекурсии за полиномиальное время» . Уведомления ACM SIGPLAN . 41 (5): 46–54. дои : 10.1145/1149982.1149988 . S2CID 8006549 . , доступно у автора по адресу http://hafiz.myweb.cs.uwindsor.ca/pub/p46-frost.pdf. Архивировано 8 января 2015 г. на Wayback Machine.
- ^ Фрост, Р.; Р. Хафиз; П. Каллаган (июнь 2007 г.). «Модульный и эффективный нисходящий анализ неоднозначных леворекурсивных грамматик» (PDF) . 10-й международный семинар по технологиям синтаксического анализа (IWPT), ACL-SIGPARSE : 109–120. Архивировано из оригинала (PDF) 27 мая 2011 г.
- ^ Фрост, Р.; Р. Хафиз; П. Каллаган (январь 2008 г.). «Парсер-комбинаторы неоднозначных леворекурсивных грамматик». Практические аспекты декларативных языков (PDF) . Конспекты лекций по информатике. Том. 4902. стр. 167–181. дои : 10.1007/978-3-540-77442-6_12 . ISBN 978-3-540-77441-9 .