Коэффициент получения информации
В этой статье есть несколько проблем. Пожалуйста, помогите улучшить его или обсудите эти проблемы на странице обсуждения . ( Узнайте, как и когда удалять эти шаблонные сообщения )
|
В обучении дерева решений коэффициент прироста информации — это отношение прироста информации к внутренней информации. Его предложил Росс Куинлан . [1] уменьшить перекос в сторону многозначных атрибутов, принимая во внимание количество и размер ветвей при выбореатрибут. [2]
Получение информации также известно как взаимная информация . [3]
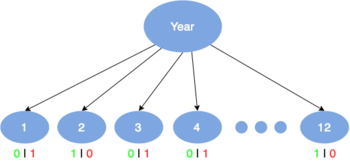
Расчет получения информации
[ редактировать ]Прирост информации — это уменьшение энтропии, возникающее в результате разделения набора по атрибутам. и находим оптимального кандидата, который дает наибольшее значение:


где является случайной величиной и это энтропия учитывая значение атрибута .


Прирост информации равен общей энтропии атрибута, если для каждого значения атрибута можно провести уникальную классификацию результирующего атрибута. В этом случае относительная энтропия, вычтенная из общей энтропии, равна 0.
Расчет разделенной информации
[ редактировать ]Значение разделенной информации для теста определяется следующим образом:

где — дискретная случайная величина с возможными значениями и количество раз, которое происходит, разделенное на общее количество событий где это совокупность событий.






Значение информации о разделении — это положительное число, которое описывает потенциальную ценность отделения ветви от узла. Это, в свою очередь, является внутренней ценностью, которой обладает случайная величина и которая будет использоваться для устранения систематической ошибки при расчете коэффициента прироста информации.
Расчет коэффициента прироста информации
[ редактировать ]Коэффициент прироста информации — это соотношение между приростом информации и значением разделенной информации:


Пример
[ редактировать ]Используя данные о погоде, опубликованные Университетом Фордхэма, [4] таблица была создана ниже:
| Перспективы | Температура | Влажность | Ветер | Играть |
|---|---|---|---|---|
| Солнечно | Горячий | Высокий | ЛОЖЬ | Нет |
| Солнечно | Горячий | Высокий | Истинный | Нет |
| Пасмурно | Горячий | Высокий | ЛОЖЬ | Да |
| Дождливый | Мягкий | Высокий | ЛОЖЬ | Да |
| Дождливый | Прохладный | Нормальный | ЛОЖЬ | Да |
| Дождливый | Прохладный | Нормальный | Истинный | Нет |
| Пасмурно | Прохладный | Нормальный | Истинный | Да |
| Солнечно | Мягкий | Высокий | ЛОЖЬ | Нет |
| Солнечно | Прохладный | Нормальный | ЛОЖЬ | Да |
| Дождливый | Мягкий | Нормальный | ЛОЖЬ | Да |
| Солнечно | Мягкий | Нормальный | ЛОЖЬ | Да |
| Пасмурно | Мягкий | Высокий | Истинный | Да |
| Пасмурно | Горячий | Нормальный | ЛОЖЬ | Да |
| Дождливый | Мягкий | Высокий | Истинный | Нет |
Используя приведенную выше таблицу, можно найти энтропию, прирост информации, разделение информации и коэффициент прироста информации для каждой переменной (прогноз, температура, влажность и ветер). Эти расчеты показаны в таблицах ниже:
|
|
|
|
Используя приведенные выше таблицы, можно сделать вывод, что Outlook имеет самый высокий коэффициент получения информации. Далее необходимо найти статистику для подгрупп переменной Outlook (солнечно, пасмурно и дождливо), для этого примера будет построена только солнечная ветка (как показано в таблице ниже):
| Перспективы | Температура | Влажность | Ветер | Играть |
|---|---|---|---|---|
| Солнечно | Горячий | Высокий | ЛОЖЬ | Нет |
| Солнечно | Горячий | Высокий | Истинный | Нет |
| Солнечно | Мягкий | Высокий | ЛОЖЬ | Нет |
| Солнечно | Прохладный | Нормальный | ЛОЖЬ | Да |
| Солнечно | Мягкий | Нормальный | Истинный | Да |
Можно найти следующую статистику для других переменных (температура, влажность и ветер), чтобы увидеть, какие из них оказывают наибольшее влияние на солнечный элемент переменной прогноза:
|
|
|
Было обнаружено, что влажность имеет самый высокий коэффициент получения информации. Повторим те же шаги, что и раньше, и найдем статистику событий переменной Влажность (высокая и нормальная):
|
|
Поскольку игровые значения либо «Нет», либо «Да», значение коэффициента прироста информации будет равно 1. Кроме того, теперь, когда мы достигли конца цепочки переменных, где Wind является последней оставшейся переменной, они могут построить вся ветвь от корня к конечному узлу дерева решений.
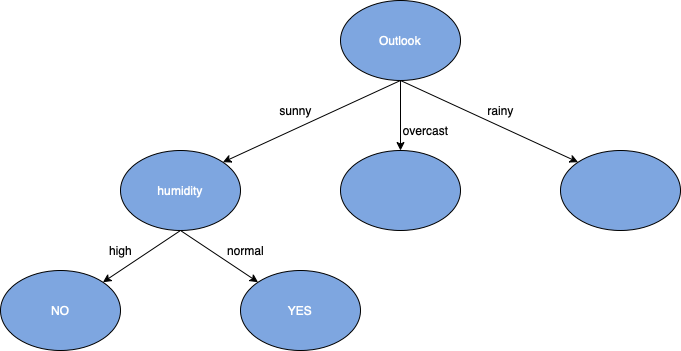
После достижения этого листового узла можно будет выполнить ту же процедуру для остальных элементов, которые еще не были разделены в дереве решений. Этот набор данных был относительно небольшим, однако, если использовался больший набор, преимущества использования коэффициента прироста информации в качестве коэффициента разделения дерева решений можно было увидеть больше.
Преимущества
[ редактировать ]Коэффициент прироста информации искажает дерево решений , не позволяя учитывать атрибуты с большим количеством различных значений.
Например, предположим, что мы строим дерево решений для некоторых данных, описывающих клиентов компании. Коэффициент прироста информации используется для принятия решения о том, какие из атрибутов являются наиболее релевантными. Они будут проверены возле корня дерева. клиента Одним из входных атрибутов может быть номер телефона . Этот атрибут имеет высокую информационную ценность, поскольку он однозначно идентифицирует каждого клиента. Из-за большого количества различных значений он не будет выбран для проверки вблизи корня.
Недостатки
[ редактировать ]Хотя коэффициент прироста информации решает ключевую проблему прироста информации, он создает еще одну проблему. Если рассматривать количество атрибутов, имеющих большое количество различных значений, оно никогда не будет больше атрибута с меньшим количеством различных значений.
Отличие от получения информации
[ редактировать ]- Недостаток прироста информации возникает из-за отсутствия численной разницы между атрибутами с высокими отличными значениями и атрибутами с меньшими значениями.
- Пример: предположим, что мы строим дерево решений для некоторых данных, описывающих клиентов компании. Полученная информация часто используется для принятия решения о том, какие из атрибутов являются наиболее релевантными, поэтому их можно проверить вблизи корня дерева. клиента Одним из входных атрибутов может быть номер кредитной карты . Этот атрибут дает высокую информационную выгоду, поскольку он уникально идентифицирует каждого клиента, но мы не хотим включать его в дерево решений: решение о том, как обращаться с клиентом на основе номера его кредитной карты, вряд ли будет распространяться на клиентов, которых у нас нет. видел раньше.
- Сильная сторона коэффициента прироста информации заключается в том, что он имеет уклон в сторону атрибутов с меньшим количеством различных значений.
- Ниже приведена таблица, описывающая различия в приросте информации и коэффициенте прироста информации в определенных сценариях.
| Получение информации | Коэффициент получения информации |
|---|---|
| Не будет отдавать предпочтение каким-либо атрибутам по количеству различных значений. | Предпочитает атрибут с меньшим количеством различных значений. |
| При применении к атрибутам, которые могут принимать большое количество различных значений, этот метод может изучить обучающий набор. слишком хорошо | Пользователю будет сложно найти атрибуты, требующие большого количества различных значений. |
См. также
[ редактировать ]Ссылки
[ редактировать ]- ^ Куинлан, младший (1986). «Индукция деревьев решений» . Машинное обучение . 1 : 81–106. дои : 10.1007/BF00116251 .
- ^ http://www.ke.tu-darmstadt.de/lehre/archiv/ws0809/mldm/dt.pdf . Архивировано 28 декабря 2014 г. в Wayback Machine. [ пустой URL PDF ]
- ^ «Получение информации, взаимное информирование и связанные с этим меры» .
- ^ https://storm.cis.fordham.edu/~gweiss/data-mining/weka-data/weather.nominal.arff