Иерархия кэша
Иерархия кэша, или многоуровневый кэш , — это архитектура памяти, в которой используется иерархия хранилищ памяти, основанная на различной скорости доступа к данным кэша. Очень запрашиваемые данные кэшируются в хранилищах памяти с высокоскоростным доступом, что обеспечивает более быстрый доступ к ядрам центрального процессора (ЦП).
Иерархия кэша является формой и частью иерархии памяти и может рассматриваться как форма многоуровневого хранилища . [1] Эта конструкция была предназначена для того, чтобы позволить ядрам ЦП работать быстрее, несмотря на задержку доступа к основной памяти . Доступ к основной памяти может стать узким местом для производительности ядра ЦП , поскольку ЦП ожидает данных, в то время как обеспечение высокой скорости всей основной памяти может быть непомерно дорогим. Высокоскоростные кэши являются компромиссом, обеспечивающим высокоскоростной доступ к данным, наиболее часто используемым процессором, что позволяет увеличить тактовую частоту процессора . [2]

Предыстория [ править ]
В истории разработки компьютеров и электронных микросхем был период, когда увеличение скорости процессора опережало улучшение скорости доступа к памяти. [3] Разрыв между скоростью процессоров и памятью означал, что процессор часто простаивал. [4] Процессоры становились все более способными запускать и выполнять большее количество инструкций за заданное время, но время, необходимое для доступа к данным из основной памяти, не позволяло программам в полной мере воспользоваться этой возможностью. [5] Эта проблема побудила создание моделей памяти с более высокими скоростями доступа, чтобы реализовать потенциал более быстрых процессоров. [6]
Результатом этого стала концепция кэш-памяти , впервые предложенная Морисом Уилксом , британским ученым-компьютерщиком из Кембриджского университета в 1965 году. Он назвал такие модели памяти «ведомой памятью». [7] Примерно между 1970 и 1990 годами в статьях Ананта Агарвала , Алана Джея Смита , Марка Д. Хилла , Томаса Р. Пузака и других обсуждались лучшие конструкции кэш-памяти. В то время были реализованы первые модели кэш-памяти, но даже по мере того, как исследователи проводили исследования и предлагали лучшие конструкции, потребность в более быстрых моделях памяти сохранялась. Эта необходимость возникла из-за того, что, хотя ранние модели кэша улучшали задержку доступа к данным, с учетом стоимости и технических ограничений было невозможно, чтобы кэш компьютерной системы приблизился к размеру основной памяти. Начиная с 1990 года, были предложены такие идеи, как добавление еще одного уровня кэша (второго уровня) в качестве резервной копии кэша первого уровня. Жан-Лу Баер , Вен-Ханн Ван, Эндрю В. Уилсон и другие провели исследование этой модели. Когда несколько симуляций и реализаций продемонстрировали преимущества моделей двухуровневого кэша, концепция многоуровневых кэшей стала новой и, как правило, лучшей моделью кэш-памяти. С 2000 года модели многоуровневого кэша получили широкое распространение и в настоящее время реализованы во многих системах, например, трехуровневые кэши, присутствующие в продуктах Intel Core i7. [8]
Многоуровневый кэш [ править ]
Доступ к основной памяти для выполнения каждой инструкции может привести к медленной обработке, при этом тактовая частота зависит от времени, необходимого для поиска и выборки данных. Чтобы скрыть эту задержку памяти от процессора, используется кэширование данных. [9] Всякий раз, когда данные требуются процессору, они извлекаются из основной памяти и сохраняются в меньшей структуре памяти, называемой кэшем. Если эти данные еще потребуются, сначала выполняется поиск в кеше, а затем в основной памяти. [10] Эта структура расположена ближе к процессору с точки зрения времени, затрачиваемого на поиск и выборку данных по отношению к основной памяти. [11] Преимущества использования кэша можно доказать, рассчитав среднее время доступа (AAT) для иерархии памяти с кэшем и без него. [12]
Среднее время доступа (AAT) [ править ]
Кэши, будучи небольшими по размеру, могут приводить к частым промахам (когда поиск в кэше не дает искомой информации), что приводит к вызову основной памяти для выборки данных. Следовательно, на AAT влияет частота ошибок каждой структуры, в которой он ищет данные. [13]

AAT для основной памяти определяется временем обращения к основной памяти . AAT для кешей может быть задан как
- времени попадания Кэш частоты промахов + ( кэш × время штрафа за промах, необходимое для перехода в основную память после отсутствия кеша ). [ нужны дальнейшие объяснения ]
Время попадания для кэшей меньше, чем время попадания для основной памяти, поэтому AAT для извлечения данных значительно ниже при доступе к данным через кэш, а не через основную память. [14]
Компромиссы [ править ]
Хотя использование кэша может улучшить задержку памяти, оно не всегда может привести к необходимому улучшению времени, затрачиваемого на выборку данных, из-за способа организации и прохождения кэшей. Например, кэши с прямым отображением одинакового размера обычно имеют более высокий уровень ошибок, чем полностью ассоциативные кэши. Это также может зависеть от производительности компьютера, тестирующего процессор, и от шаблона инструкций. Но использование полностью ассоциативного кеша может привести к большему энергопотреблению, поскольку каждый раз приходится просматривать весь кеш. В связи с этим компромисс между энергопотреблением (и соответствующим выделением тепла) и размером кэша становится критически важным при проектировании кэша. [13]
Эволюция [ править ]

В случае промаха кэша цель использования такой структуры окажется бесполезной, и компьютеру придется обратиться к основной памяти для получения необходимых данных. Однако при использовании многоуровневого кэша , если компьютер пропускает кэш, ближайший к процессору (кэш первого уровня или L1), он будет искать следующий ближайший уровень кэша и переходить к основной памяти, только если они методы не работают. Общая тенденция заключается в том, чтобы кэш L1 оставался небольшим и находился на расстоянии 1–2 тактовых циклов ЦП от процессора, при этом размер кэшей нижних уровней увеличивается для хранения большего количества данных, чем L1, следовательно, они становятся более удаленными, но с меньшими ошибками. ставка. Это приводит к улучшению AAT. [15] Количество уровней кэша может быть спроектировано архитекторами в соответствии с их требованиями после проверки компромисса между стоимостью, AAT и размером. [16] [17]
Прирост производительности [ править ]
Благодаря технологии масштабирования, которая позволила разместить системы памяти на одном кристалле, большинство современных процессоров имеют до трех или четырех уровней кэша. [18] Сокращение AAT можно понять на этом примере, где компьютер проверяет AAT на наличие различных конфигураций вплоть до кэшей L3.
Пример : основная память = 50 нс , L1 = 1 нс с частотой промахов 10 %, L2 = 5 нс с частотой промахов 1 %, L3 = 10 нс с частотой промахов 0,2 %.
- Без кэша, AAT = 50 нс
- Кэш L1, AAT = 1 нс + (0,1 × 50 нс) = 6 нс
- Кэш-память L1–2, AAT = 1 нс + (0,1 × [5 нс + (0,01 × 50 нс)]) = 1,55 нс
- Кэш-память L1–3, AAT = 1 нс + (0,1 × [5 нс + (0,01 × [10 нс + (0,002 × 50 нс)])]) = 1,5101 нс
Недостатки [ править ]
- Кэш-память требует более высоких предельных затрат , чем основная память, и, таким образом, может увеличить стоимость всей системы. [19]
- Кэшированные данные хранятся только до тех пор, пока в кеш подается питание.
- Увеличенная площадь кристалла, необходимая для системы памяти. [20]
- Преимущества могут быть сведены к минимуму или устранены в случае больших программ с плохой временной локальностью , которые часто обращаются к основной памяти. [21]
Свойства [ править ]
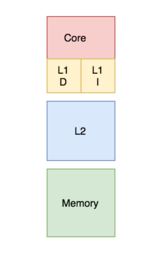
Банковские против унифицированных [ править ]
В банковском кеше кеш разделен на кеш, предназначенный для хранения инструкций , и кеш, предназначенный для данных. Напротив, унифицированный кеш содержит как инструкции, так и данные в одном кеше. [22] Во время процесса процессор обращается к кэшу L1 (или к кэшу большей части верхнего уровня в зависимости от его подключения к процессору) для получения как инструкций, так и данных. Требование одновременного выполнения обоих действий требует наличия нескольких портов и большего времени доступа к единому кэшу. Наличие нескольких портов требует дополнительного оборудования и проводки, что приводит к значительной структуре между кэшами и процессорами. [23] Чтобы избежать этого, кэш L1 часто организуется в виде банковского кэша, что приводит к меньшему количеству портов, меньшему количеству аппаратного обеспечения и, как правило, к меньшему времени доступа. [13]
Современные процессоры имеют разделенный кэш, а в системах с многоуровневым кэшем кэши более высокого уровня могут быть объединены, а кэши нижних уровней разделены. [24]
Политика включения [ править ]

Может ли блок, присутствующий на верхнем уровне кэша, также присутствовать на нижнем уровне кэша, определяется политикой включения системы памяти , которая может быть инклюзивной, эксклюзивной или неинклюзивной-неэксклюзивной (NINE). [ нужна ссылка ]
При использовании инклюзивной политики все блоки, присутствующие в кеше верхнего уровня, должны также присутствовать и в кеше нижнего уровня. Каждый компонент кэша верхнего уровня является подмножеством компонента кэша нижнего уровня. В этом случае, поскольку происходит дублирование блоков, происходит некоторая потеря памяти. Однако проверка происходит быстрее. [ нужна ссылка ]
В соответствии с политикой эксклюзивности все компоненты иерархии кэша являются полностью эксклюзивными, так что любой элемент кэша верхнего уровня не будет присутствовать ни в одном из компонентов кэша нижнего уровня. Это позволяет полностью использовать кэш-память. Однако существует высокая задержка доступа к памяти. [25]
Вышеуказанные политики требуют соблюдения ряда правил для их реализации. Если ни один из них не является обязательным, результирующая политика включения называется неинклюзивной неэксклюзивной (NINE). Это означает, что кэш верхнего уровня может присутствовать или отсутствовать в кеше нижнего уровня. [21]
Написать политику [ править ]
Существует две политики, определяющие способ обновления измененного блока кэша в основной памяти: сквозная запись и обратная запись. [ нужна ссылка ]
В случае политики сквозной записи всякий раз, когда значение блока кэша изменяется, оно также модифицируется в иерархии памяти нижнего уровня. [26] Эта политика гарантирует безопасное хранение данных при их записи по всей иерархии.
Однако в случае политики обратной записи измененный блок кэша будет обновлен в иерархии нижнего уровня только тогда, когда блок кэша будет удален. «Грязный бит» прикрепляется к каждому блоку кэша и устанавливается при каждом изменении блока кэша. [27] Во время вытеснения блоки с установленным грязным битом будут записаны в иерархию нижнего уровня. В соответствии с этой политикой существует риск потери данных, поскольку последняя измененная копия данных хранится только в кэше, и поэтому необходимо соблюдать некоторые методы исправления.
В случае записи, когда байт отсутствует в блоке кэша, байт может быть перенесен в кэш, как это определено политикой выделения записи или запрета записи. [28] Политика распределения записи гласит, что в случае промаха записи блок извлекается из основной памяти и помещается в кеш перед записью. [29] В политике записи без выделения, если блок пропущен в кеше, он будет записывать в иерархию памяти нижнего уровня без извлечения блока в кеш. [30]
Обычными комбинациями политик являются «блокировка записи», «выделение записи» и «запись через запись без выделения» .
[ править ]

Частный кэш назначается одному конкретному ядру процессора и не может быть доступен другим ядрам. В некоторых архитектурах каждое ядро имеет свой собственный кэш; это создает риск дублирования блоков в архитектуре системного кэша, что приводит к снижению использования емкости. Однако этот тип выбора конструкции в архитектуре многоуровневого кэша также может быть полезен для снижения задержки доступа к данным. [28] [31] [32]
Общий кеш — это кеш, к которому могут получить доступ несколько ядер. [33] Поскольку он является общим, каждый блок в кеше уникален и, следовательно, имеет большую вероятность попадания, поскольку не будет повторяющихся блоков. Однако задержка доступа к данным может увеличиться, поскольку несколько ядер пытаются получить доступ к одному и тому же кэшу. [34]
В многоядерных процессорах выбор конструкции: общий или частный кэш влияет на производительность процессора. [35] На практике кэш верхнего уровня L1 (или иногда L2) [36] [37] реализован как частный, а кэши нижнего уровня реализованы как общие. Такая конструкция обеспечивает высокую скорость доступа к кэшам высокого уровня и низкую частоту ошибок для кэшей нижнего уровня. [35]
Последние модели реализации [ править ]

Intel Xeon Emerald Rapids ( 2024 г. )
До 64 ядер:
- Кэш L1 — 80 КБ на ядро
- Кэш L2 — 2 МБ на ядро
- Кэш L3 — 5 МБ до 320 МБ ) на ядро (т.е. всего
Intel i5 Raptor Lake-HX ( 2024 г. )
6 ядер (производительность | эффективность):
- Кэш L1 — 128 КБ на ядро
- Кэш L2 — 2 МБ на ядро | 4–8 МБ, полуразделенный
- Кэш L3 — 20–24 МБ общий
AMD EPYC 9684X (2023 г.) [ править ]
96 ядер:
- Кэш L1 — 64 КБ на ядро
- Кэш L2 — 1 МБ на ядро
- Кэш L3 — 1152 МБ общий
Apple M1 Ultra (2022 г.) [ править ]
20 ядер (ядро «производительность» 4:1 | ядро «эффективность»):
- Кэш L1 — 320|192 КБ на ядро
- Кэш L2 — 52 МБ , полуобщий
- Кэш L3 — 96 МБ общий
AMD Ryzen 7000 (2022 г.) [ править ]
От 6 до 16 ядер:
- Кэш L1 — 64 КБ на ядро
- Кэш L2 — 1 МБ на ядро
- Кэш L3 — от 32 до 128 МБ общий
Микроархитектура AMD Zen 2 (2019 г.) [ править ]
- Кэш L1 — 32 КБ данных и 32 КБ инструкций на ядро, 8-поточный
- Кэш L2 — 512 КБ на ядро, 8-поточный включительно
- Кэш-память L3 — 16 МБ локально на 4-ядерный CCX, 2 CCX на чиплет, 16-канальный невключительно. До 64 МБ на настольных процессорах и 256 МБ на серверных процессорах
Микроархитектура AMD Zen (2017 г.) [ править ]
- Кэш L1 — 32 КБ данных и 64 КБ инструкций на ядро, 4-сторонний
- Кэш L2 — 512 КБ на ядро, 4-поточный включительно
- Кэш L3 — 4 МБ локального и удаленного на 4-ядерный CCX, 2 CCX на чиплет, 16-канальный невключительно. До 16 МБ на настольных процессорах и 64 МБ на серверных процессорах
Intel Kaby Lake microarchitecture (2016) [ edit ]
- Кэш L1 (инструкции и данные) – 64 КБ на ядро
- Кэш L2 — 256 КБ на ядро
- Кэш L3 — общий от 2 МБ до 8 МБ [37]
Intel Broadwell (2014 Микроархитектура ) г.
- Кэш L1 (инструкции и данные) – 64 КБ на ядро
- Кэш L2 — 256 КБ на ядро
- Кэш L3 — общий от 2 МБ до 6 МБ
- Кэш L4 — 128 МБ eDRAM (только модели Iris Pro) [36]
IBM POWER7 (2010) [ править ]
- Кэш L1 (инструкции и данные) – каждый 64-банковый, каждый банк имеет 2 порта + 1 WR, 32 КБ, 8-канальный ассоциативный, блок 128 байт, сквозная запись
- Кэш L2 — 256 КБ, 8-поточный, блок 128 байт, обратная запись, включая L1, задержка доступа 2 нс
- Кэш L3 — 8 областей по 4 МБ (всего 32 МБ), локальная область 6 нс, удаленная 30 нс, каждая область 8-сторонняя ассоциативность, массив данных DRAM, массив тегов SRAM [39]
См. также [ править ]
- POWER7
- Микроархитектура Intel Broadwell
- Intel Kaby Lake Microarchitecture
- Кэш процессора
- Иерархия памяти
- Задержка CAS
- Кэш (вычисления)
Ссылки [ править ]
- ^ Хеннесси, Джон Л; Паттерсон, Дэвид А; Асанович, Крсте ; Бакос, Джейсон Д; Колвелл, Роберт П.; Бхаттачарджи, Абхишек; Конте, Томас М; Дуато, Хосе; Франклин, Диана; Гольдберг, Дэвид; Жуппи, Норман П; Ли, Шэн; Муралиманохар, Навин; Петерсон, Грегори Д.; Пинкстон, Тимоти Марк; Ранганатан, Пракаш; Вуд, Дэвид Аллен; Янг, Клиффорд; Заки, Амр (2011). Компьютерная архитектура: количественный подход (Шестое изд.). Эльзевир Наука. ISBN 978-0128119051 . OCLC 983459758 .
- ^ «Кэш: зачем выравнивать» (PDF) .
- ^ Рональд Д. Миллер; Ларс И. Эрикссон; Ли А. Флейшер, 2014. Электронная книга Миллера по анестезии. Elsevier Науки о здоровье. п. 75. ISBN 978-0-323-28011-2 .
- ^ Альберт Ю. Зомайя, 2006. Справочник по природным и инновационным вычислениям: интеграция классических моделей с новыми технологиями. Springer Science & Business Media. п. 298. ISBN 978-0-387-40532-2 .
- ^ Ричард К. Дорф, 2018. Датчики, нанонаука, биомедицинская инженерия и инструменты: датчики, нанонаука, биомедицинская инженерия. ЦРК Пресс. п. 4. ISBN 978-1-4200-0316-1 .
- ^ Дэвид А. Паттерсон; Джон Л. Хеннесси, 2004. Компьютерная организация и дизайн: интерфейс аппаратного и программного обеспечения, третье издание. Эльзевир. п. 552. ISBN 978-0-08-050257-1 .
- ^ «Сэр Морис Винсент Уилкс | Британский ученый-компьютерщик» . Британская энциклопедия . Проверено 11 декабря 2016 г.
- ^ Беркли, Джон Л. Хеннесси, Стэнфордский университет, и Дэвид А. Паттерсон, Калифорнийский университет. «Проектирование иерархии памяти. Часть 6. Intel Core i7, заблуждения и подводные камни» . ЭДН . Проверено 13 октября 2022 г.
{{cite news}}: CS1 maint: несколько имен: список авторов ( ссылка ) - ^ Шейн Кук, 2012. Программирование CUDA: Руководство разработчика по параллельным вычислениям на графических процессорах. Ньюнес. стр. 107–109. ISBN 978-0-12-415988-4 .
- ^ Брюс Хеллингсворт; Патрик Холл; Говард Андерсон; 2001. Высшая национальная вычислительная техника. Рутледж. стр. 30–31. ISBN 978-0-7506-5230-8 .
- ^ Рита Саху, Гаган Саху. Инфоматические практики. Saraswati House Pvt Ltd., стр. 1–. ISBN 978-93-5199-433-6 .
- ^ Филип А. Лапланте; Сеппо Дж. Оваска; 2011. Проектирование и анализ систем реального времени: инструменты для практика. Джон Уайли и сыновья. стр. 94–95. ISBN 978-1-118-13659-1 .
- ^ Jump up to: Перейти обратно: а б с Хеннесси и Паттерсон. Компьютерная архитектура: количественный подход . Морган Кауфманн . ISBN 9780123704900 .
- ^ Четин Кая Коч, 2008. Криптографическая инженерия. Springer Science & Business Media. стр. 479–480. ISBN 978-0-387-71817-0 .
- ^ Дэвид А. Паттерсон; Джон Л. Хеннесси; 2008. Организация и дизайн компьютера: аппаратно-программный интерфейс. Морган Кауфманн. стр. 489–492. ISBN 978-0-08-092281-2 .
- ^ Харви Г. Крагон, 2000. Компьютерная архитектура и реализация. Издательство Кембриджского университета. стр. 95–97. ISBN 978-0-521-65168-4 .
- ^ Бейкер Мохаммад, 2013. Проектирование встроенной памяти для многоядерных и систем на кристалле. Springer Science & Business Media. стр. 11–14. ISBN 978-1-4614-8881-1 .
- ^ Гайд, Уильям. «Как проектируются и создаются процессоры» . Техспот . Проверено 17 августа 2019 г.
- ^ Вожин Г. Оклобдзия, 2017. Цифровой дизайн и производство. ЦРК Пресс. п. 4. ISBN 978-0-8493-8604-6 .
- ^ «Иерархия памяти» .
- ^ Jump up to: Перейти обратно: а б Солихин, Ян (2016). Основы параллельной многоядерной архитектуры . Чепмен и Холл. стр. Глава 5: Введение в организацию иерархии памяти. ISBN 9781482211184 .
- ^ Ян Солихин, 2015. Основы параллельной многоядерной архитектуры. ЦРК Пресс. п. 150. ISBN 978-1-4822-1119-1 .
- ^ Стив Хит, 2002. Проектирование встраиваемых систем. Эльзевир. п. 106. ISBN 978-0-08-047756-5 .
- ^ Алан Клементс, 2013. Компьютерная организация и архитектура: темы и вариации. Cengage Обучение. п. 588. ISBN 1-285-41542-6 .
- ^ «Оценка производительности эксклюзивных иерархий кэша» (PDF) . Архивировано из оригинала (PDF) 13 августа 2012 г. Проверено 19 октября 2016 г.
- ^ Дэвид А. Паттерсон; Джон Л. Хеннесси; 2017. Компьютерная организация и дизайн RISC-V Edition: Аппаратно-программный интерфейс. Эльзевир Наука. стр. 386–387. ISBN 978-0-12-812276-1 .
- ^ Стефан Гедекер; Адольфи Хойзи; 2001. Оптимизация производительности числовых кодов. СИАМ. п. 11. ISBN 978-0-89871-484-5 .
- ^ Jump up to: Перейти обратно: а б Солихин, Ян (2009). Основы архитектуры параллельного компьютера . Издательство Солихин. стр. Глава 6: Введение в организацию иерархии памяти. ISBN 9780984163007 .
- ^ Харви Г. Крагон, 1996. Системы памяти и конвейерные процессоры. Джонс и Бартлетт Обучение. п. 47. ISBN 978-0-86720-474-2 .
- ^ Дэвид А. Паттерсон; Джон Л. Хеннесси; 2007. Компьютерная организация и дизайн, обновленная печать, третье издание: Аппаратно-программный интерфейс. Эльзевир. п. 484. ISBN 978-0-08-055033-6 .
- ^ «Программные методы для многоядерных систем с общим кэшем» . 24 мая 2018 г.
- ^ «Адаптивная схема разделения общего/частного кэша NUCA для мультипроцессоров» (PDF) . Архивировано из оригинала (PDF) 19 октября 2016 г.
- ^ Аканкша Джайн; Кэлвин Лин; 2019. Политика замены кэша. Издательство Морган и Клейпул. п. 45. ISBN 978-1-68173-577-1 .
- ^ Дэвид Каллер; Джасвиндер Пал Сингх; Ануп Гупта; 1999. Параллельная компьютерная архитектура: аппаратно-программный подход. Профессиональное издательство Персидского залива. п. 436. ISBN 978-1-55860-343-1 .
- ^ Jump up to: Перейти обратно: а б Стивен В. Кеклер; Кунле Олукотун; Х. Питер Хофсти; 2009. Многоядерные процессоры и системы. Springer Science & Business Media. п. 182. ISBN 978-1-4419-0263-4 .
- ^ Jump up to: Перейти обратно: а б «Микроархитектура Intel Broadwell» .
- ^ Jump up to: Перейти обратно: а б «Микроархитектура Intel Kaby Lake» .
- ^ «Архитектура процессора Nehalem и платформ Nehalem-EP SMP» (PDF) . Архивировано из оригинала (PDF) 11 августа 2014 г.
- ^ «ИБМ Power7» .