Алгоритм избегания общения
Алгоритмы, избегающие взаимодействия, минимизируют перемещение данных в иерархии памяти , что позволяет сократить время работы и энергопотребление. Это минимизирует сумму двух затрат (с точки зрения времени и энергии): арифметики и связи. В этом контексте связь означает перемещение данных либо между уровнями памяти, либо между несколькими процессорами по сети. Это гораздо дороже, чем арифметика. [1]
Формальная теория
[ редактировать ]Двухуровневая модель памяти
[ редактировать ]Распространенной вычислительной моделью при анализе алгоритмов предотвращения общения является двухуровневая модель памяти:
- Имеется один процессор и два уровня памяти.
- Память уровня 1 бесконечно велика. Память уровня 0 («кэш») имеет размер .
- Вначале входные данные находятся на уровне 1. В конце концов, выходные данные находятся на уровне 1.
- Процессор может работать только с данными в кэше.
- Цель состоит в том, чтобы минимизировать передачу данных между двумя уровнями памяти.

Умножение матрицы
[ редактировать ][2] Следствие 6.2:
Теорема — Данные матрицы размеров , затем имеет коммуникативную сложность .




Эта нижняя граница достижима путем тайлового умножения матриц .
Более общие результаты для других числовых операций линейной алгебры можно найти в . [3] Следующее доказательство взято из. [4]
Мы можем нарисовать график вычислений как куб точек решетки, каждая точка имеет форму . С , вычисления требует, чтобы процессор имел доступ к каждой точке внутри куба хотя бы один раз. Таким образом, проблема заключается в том, чтобы прикрыть точки решетки с минимальным количеством связей.


![{\displaystyle D[i,k]=\sum _{j}A[i,j]B[j,k]+C[i,k]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/0cac33af611126fc1c4c482c88ffc62682d5cc2a)

Если большой, то мы можем просто загрузить все записи, затем напишите записи. Это неинтересно.


Если мала, то мы можем разделить алгоритм минимальной связи на отдельные сегменты. В течение каждого сегмента он выполняет ровно чтение в кеш и любое количество записей из кеша.
В течение каждого сегмента процессор имеет доступ не более чем к разные точки от .

Позволять — набор точек решетки, охватываемых на этом отрезке. Тогда по неравенству Лумиса–Уитни ,

с ограничением .


По неравенству средних арифметических и геометрических имеем , с экстремумом, достигнутым, когда .


Таким образом, арифметическая интенсивность ограничена сверху величиной где , и поэтому связь ограничена снизу .



Прямые вычисления проверяют, достигает ли алгоритм умножения мозаичной матрицы нижней границы.
Мотивация
[ редактировать ]Рассмотрим следующую модель времени выполнения: [5]
- Мера вычислений = Время на флоп = γ
- Мера связи = количество слов перемещенных данных = β
⇒ Общее время работы = γ·(количество флопов ) + β·(количество слов)
Учитывая тот факт, что β >> γ , измеряемое во времени и энергии, стоимость связи доминирует над стоимостью вычислений. Технологические тенденции [6] указывают на то, что относительная стоимость связи растет на различных платформах, от облачных вычислений до суперкомпьютеров и мобильных устройств. В отчете также прогнозируется, что разрыв между временем доступа к DRAM и количеством операций ввода-вывода увеличится в 100 раз в течение ближайшего десятилетия, чтобы сбалансировать энергопотребление между процессорами и DRAM. [1]
| Коэффициент флопа (γ) | Пропускная способность DRAM (β) | Пропускная способность сети (β) |
|---|---|---|
| 59%/год | 23% / год | 26%/год |

Потребление энергии увеличивается на порядки по мере того, как мы поднимаемся выше в иерархии памяти. [7]
Президент США Барак Обама упомянул алгоритмы, избегающие общения, в бюджетном запросе Министерства энергетики Конгрессу на 2012 финансовый год: [1]
Новый алгоритм повышает производительность и точность вычислительных систем экстремального масштаба. В современных компьютерных архитектурах связь между процессорами занимает больше времени, чем выполнение арифметической операции с плавающей запятой данным процессором. Исследователи ASCR разработали новый метод, основанный на широко используемых методах линейной алгебры, позволяющий минимизировать взаимодействие между процессорами и иерархией памяти путем переформулирования шаблонов взаимодействия, указанных в алгоритме. Этот метод был реализован в среде TRILINOS, высоко оцененном пакете программного обеспечения, который предоставляет исследователям по всему миру функциональные возможности для решения крупномасштабных и сложных мультифизических задач.
Цели
[ редактировать ]Алгоритмы избегания общения разработаны со следующими целями:
- Реорганизуйте алгоритмы, чтобы уменьшить взаимодействие во всех иерархиях памяти.
- По возможности достигайте нижнего предела общения.
Следующий простой пример [1] показывает, как они достигаются.
Пример умножения матрицы
[ редактировать ]Пусть A, B и C — квадратные матрицы порядка n × n . Следующий простой алгоритм реализует C = C + A * B:

for i = 1 to n
for j = 1 to n
for k = 1 to n
C(i,j) = C(i,j) + A(i,k) * B(k,j)
Арифметическая стоимость (временная сложность): n 2 (2 n − 1) для достаточно больших n или O( n 3 ).
Переписывание этого алгоритма с указанием стоимости связи на каждом этапе.
for i = 1 to n
{read row i of A into fast memory} - n2 reads
for j = 1 to n
{read C(i,j) into fast memory} - n2 reads
{read column j of B into fast memory} - n3 reads
for k = 1 to n
C(i,j) = C(i,j) + A(i,k) * B(k,j)
{write C(i,j) back to slow memory} - n2 writes
Быстрая память может быть определена как память локального процессора ( кэш ЦП ) размера M, а медленная память может быть определена как DRAM.
Стоимость связи (чтение/запись): n 3 + 3н 2 или O( n 3 )
Поскольку общее время работы = γ ·O( n 3 ) + β ·O( n 3 ) и β >> γ стоимость связи является доминирующей. Алгоритм умножения блочной (плиточной) матрицы [1] уменьшает этот доминирующий термин:
Умножение блочной (плиточной) матрицы
[ редактировать ]Считайте, что A, B и C представляют собой n / b размером - на n / b матрицы размером b - на b из подблоков три блока b -by- b , где b называется размером блока; предположим, что в быстрой памяти помещаются .
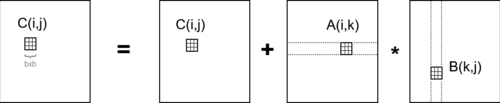
for i = 1 to n/b
for j = 1 to n/b
{read block C(i,j) into fast memory} - b2 × (n/b)2 = n2 reads
for k = 1 to n/b
{read block A(i,k) into fast memory} - b2 × (n/b)3 = n3/b reads
{read block B(k,j) into fast memory} - b2 × (n/b)3 = n3/b reads
C(i,j) = C(i,j) + A(i,k) * B(k,j) - {do a matrix multiply on blocks}
{write block C(i,j) back to slow memory} - b2 × (n/b)2 = n2 writes
Стоимость связи: 2 н. 3 / б + 2н 2 читает/пишет << 2 n 3 арифметическая стоимость
Делаем b максимально большим:
- 3 б 2 ≤ М
мы достигаем следующей нижней границы связи:
- 3 1/2 н 3 / М 1/2 + 2н 2 или Ω (количество FLOP/ M 1/2 )
Предыдущие подходы к сокращению общения
[ редактировать ]Большинство подходов, исследованных в прошлом для решения этой проблемы, основаны на методах планирования или настройки, целью которых является перекрытие связи с вычислениями. Однако этот подход может привести к улучшению максимум в два раза. Ghosting — это другой метод сокращения обмена данными, при котором процессор сохраняет и избыточно обрабатывает данные соседних процессоров для будущих вычислений. Алгоритмы, не учитывающие кэш, представляют собой другой подход, представленный в 1999 году для быстрых преобразований Фурье . [8] а затем распространились на графовые алгоритмы, динамическое программирование и т. д. Они также применялись к нескольким операциям в линейной алгебре. [9] [10] [11] как плотные LU- и QR-факторизации. Разработка алгоритмов, специфичных для конкретной архитектуры, — это еще один подход, который можно использовать для сокращения обмена данными в параллельных алгоритмах, и в литературе есть много примеров алгоритмов, адаптированных к заданной топологии связи. [12]
См. также
[ редактировать ]Ссылки
[ редактировать ]- ^ Jump up to: а б с д и Деммель, Джим. «Алгоритмы избежания общения». 2012 SC Companion: Высокопроизводительные вычисления, сетевое хранилище и анализ. ИИЭР, 2012.
- ^ Цзя-Вэй, Хун; Кунг, ХТ (1981). «Сложность ввода-вывода» . Материалы тринадцатого ежегодного симпозиума ACM по теории вычислений - STOC '81 . Нью-Йорк, Нью-Йорк, США: ACM Press. стр. 326–333. дои : 10.1145/800076.802486 . S2CID 8410593 .
- ^ Баллард, Г.; Карсон, Э.; Деммель, Дж.; Хёммен, М.; Найт, Н.; Шварц, О. (май 2014 г.). «Коммуникационные нижние оценки и оптимальные алгоритмы численной линейной алгебры» . Акта Нумерика . 23 : 1–155. дои : 10.1017/s0962492914000038 . ISSN 0962-4929 . S2CID 122513943 .
- ^ Деммель, Джеймс; Динь, Грейс (24 апреля 2018 г.). «Оптимальные для связи сверточные нейронные сети». arXiv : 1802.06905 [ cs.DS ].
- ^ Деммель, Джеймс и Кэти Йелик. «Избегание общения (CA) и другие инновационные алгоритмы». Лаборатория Беркли Par Lab: Прогресс в области параллельных вычислений: 243–250.
- ^ Бергман, Керен и др. « Исследование экзафлопсных вычислений: технологические проблемы в экзафлопсных вычислительных системах ». Агентства перспективных исследовательских проектов Министерства обороны Управление технологий обработки информации (DARPA IPTO), техн. Реп 15 (2008).
- ^ Шальф, Джон, Судип Досандж и Джон Моррисон. «Проблемы экзафлопсных вычислительных технологий». Высокопроизводительные вычисления для вычислительной науки – VECPAR 2010. Springer Berlin Heidelberg, 2011. 1–25.
- ^ М. Фриго, CE Лейзерсон, Х. Прокоп и С. Рамачандран, «Алгоритмы Cacheoblivious», в FOCS '99: Материалы 40-го ежегодного симпозиума по основам информатики, 1999. Компьютерное общество IEEE.
- ^ С. Толедо, « Локальность отсчета в LU-разложении с частичным поворотом », SIAM J. Matrix Anal. Приложение, вып. 18, нет. 4, 1997.
- ^ Ф. Густавсон, «Рекурсия приводит к автоматической блокировке переменных для алгоритмов плотной линейной алгебры», IBM Journal of Research and Development, vol. 41, нет. 6, стр. 737–755, 1997.
- ^ Э. Элмрот, Ф. Густавсон, И. Йонссон и Б. Кагстром, « Рекурсивные блокированные алгоритмы и гибридные структуры данных для программного обеспечения библиотеки плотных матриц », SIAM Review, vol. 46, нет. 1, стр. 3–45, 2004.
- ^ Григори, Лаура . « Введение в коммуникацию без использования алгоритмов линейной алгебры в высокопроизводительных вычислениях» .