Умножение цепочки матриц
Умножение цепочки матриц (или проблема упорядочивания цепочки матриц [1] ) — это задача оптимизации, касающаяся наиболее эффективного способа умножения заданной последовательности матриц . На самом деле проблема не в том, чтобы выполнить умножения, а просто в том, чтобы определить последовательность соответствующих матричных умножений. Проблему можно решить с помощью динамического программирования .
Вариантов много, поскольку умножение матриц ассоциативно . Другими словами, как бы произведение ни заключалось в скобки , полученный результат останется прежним. Например, для четырех матриц A , B , C и D существует пять возможных вариантов:
- (( AB ) C ) D = ( A ( BC )) D = ( AB )( CD ) = A (( BC ) D ) = A ( B ( CD )).
Хотя это и не влияет на произведение, порядок, в котором члены заключаются в круглые скобки, влияет на количество простых арифметических операций, необходимых для вычисления произведения, то есть на сложность вычислений . Прямое умножение матрицы размера X × Y на матрицу размера Y × Z требует XYZ обычного умножения X ( Y − 1) Z. и обычного сложения В этом контексте типично использовать количество обычных умножений в качестве меры сложности времени выполнения.
Если A — матрица 10 × 30, B — матрица 30 × 5, а C — матрица 5 × 60, то
- вычисления ( AB ) C требуют (10×30×5) + (10×5×60) = 1500 + 3000 = 4500 операций, при этом
- для вычисления A ( BC ) требуется (30×5×60) + (10×30×60) = 9000 + 18000 = 27000 операций.
Очевидно, что первый метод более эффективен. Имея эту информацию, постановку задачи можно уточнить следующим образом: «Как определить оптимальную скобку произведения n матриц?» Количество возможных скобок определяется выражением ( n –1) й Каталонское число , которое равно O (4 н / н 3/2 ), поэтому проверка каждой возможной скобки ( грубая сила ) потребует времени выполнения , экспоненциально зависящего от количества матриц, что очень медленно и непрактично для больших n . Более быстрого решения этой проблемы можно добиться, разбив ее на набор связанных подзадач.
Алгоритм динамического программирования
[ редактировать ]Для начала давайте предположим, что все, что нам действительно нужно знать, — это минимальная стоимость или минимальное количество арифметических операций, необходимых для перемножения матриц. Если мы перемножаем только две матрицы, есть только один способ их перемножить, поэтому минимальная стоимость — это стоимость этого процесса. В общем, мы можем найти минимальную стоимость, используя следующий рекурсивный алгоритм :
- Возьмите последовательность матриц и разделите ее на две подпоследовательности.
- Найдите минимальную стоимость умножения каждой подпоследовательности.
- Сложите эти затраты вместе и добавьте стоимость умножения двух результирующих матриц.
- Сделайте это для каждой возможной позиции, в которой последовательность матриц может быть разделена, и возьмите минимум для всех из них.
Например, если у нас есть четыре матрицы ABCD , мы вычисляем стоимость, необходимую для нахождения каждой из ( A )( BCD ), ( AB )( CD ) и ( ABC )( D ), делая рекурсивные вызовы, чтобы найти минимальную стоимость вычислить ABC , AB , CD и BCD . Затем мы выбираем лучший. Более того, это дает не только минимальные затраты, но и демонстрирует лучший способ умножения: сгруппируйте его так, чтобы получить наименьшие общие затраты, и сделайте то же самое для каждого фактора.
Однако этот алгоритм имеет экспоненциальную сложность во время выполнения, что делает его столь же неэффективным, как и наивный подход с перебором всех перестановок. Причина в том, что алгоритм выполняет много избыточной работы. Например, выше мы сделали рекурсивный вызов, чтобы найти лучшую стоимость для вычисления ABC и AB . Но для того, чтобы найти лучшую стоимость вычисления ABC, необходимо также найти лучшую стоимость для AB . По мере углубления рекурсии происходит все больше и больше ненужных повторений такого типа.
Одно простое решение называется мемоизацией : каждый раз, когда мы вычисляем минимальную стоимость, необходимую для умножения определенной подпоследовательности, мы сохраняем ее. Если нас когда-нибудь попросят вычислить его еще раз, мы просто дадим сохраненный ответ и не будем его пересчитывать. Поскольку их около n 2 /2 различных подпоследовательностей, где n — количество матриц, пространство, необходимое для этого, является разумным. Можно показать, что этот простой трюк сокращает время выполнения до O( n 3 ) из O(2 н ), что более чем достаточно эффективно для реальных приложений. Это сверху вниз динамическое программирование .
Следующий восходящий подход [2] вычисляет для каждого 2 ≤ k ≤ n минимальные стоимости всех подпоследовательностей длины k, используя уже вычисленные стоимости меньших подпоследовательностей. Он имеет такое же асимптотическое время выполнения и не требует рекурсии.
Псевдокод:
// Matrix A[i] has dimension dims[i-1] x dims[i] for i = 1..n
MatrixChainOrder(int dims[])
{
// length[dims] = n + 1
n = dims.length - 1;
// m[i,j] = Minimum number of scalar multiplications (i.e., cost)
// needed to compute the matrix A[i]A[i+1]...A[j] = A[i..j]
// The cost is zero when multiplying one matrix
for (i = 1; i <= n; i++)
m[i, i] = 0;
for (len = 2; len <= n; len++) { // Subsequence lengths
for (i = 1; i <= n - len + 1; i++) {
j = i + len - 1;
m[i, j] = MAXINT;
for (k = i; k <= j - 1; k++) {
cost = m[i, k] + m[k+1, j] + dims[i-1]*dims[k]*dims[j];
if (cost < m[i, j]) {
m[i, j] = cost;
s[i, j] = k; // Index of the subsequence split that achieved minimal cost
}
}
}
}
}
- Примечание. Первый индекс для dims равен 0, а первый индекс для m и s — 1.
с Реализация Python использованием декоратора мемоизации из стандартной библиотеки:
from functools import cache
def matrixChainOrder(dims: list[int]) -> int:
@cache
def a(i, j):
return min((a(i, k) + dims[i] * dims[k] * dims[j] + a(k, j)
for k in range(i + 1, j)), default=0)
return a(0, len(dims) - 1)
Более эффективные алгоритмы
[ редактировать ]Есть алгоритмы более эффективные, чем O ( n 3 ) алгоритм динамического программирования, хотя они и более сложны.
Ху и Шинг
[ редактировать ]Алгоритм, опубликованный TC Hu и M.-T. Шинг достигает O ( n log n ) вычислительной сложности . [3] [4] [5] Они показали, как задачу умножения цепочки матриц можно преобразовать (или свести ) в задачу триангуляции правильного многоугольника . Многоугольник ориентирован так, что у него есть горизонтальная нижняя сторона, называемая основанием, которая представляет конечный результат. Остальные n сторон многоугольника, по часовой стрелке, представляют собой матрицы. Вершины на каждом конце стороны — это размеры матрицы, представленной этой стороной. С n матрицами в цепочке умножения имеется n −1 бинарных операций и Cn − 1 способов расстановки скобок, где Cn − 1 — ( n −1)-е каталанское число . Алгоритм использует то, что существует также C n −1 возможных триангуляций многоугольника с n +1 сторонами.
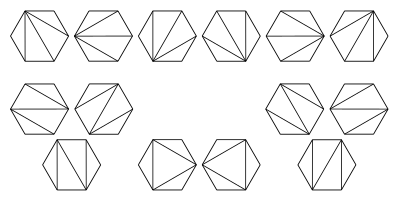
Это изображение иллюстрирует возможные триангуляции правильного шестиугольника . Они соответствуют различным способам расстановки скобок для упорядочивания умножения произведения пяти матриц.
В примере ниже есть четыре стороны: A, B, C и конечный результат ABC. A — матрица 10×30, B — матрица 30×5, C — матрица 5×60, а окончательный результат — матрица 10×60. Правильный многоугольник в этом примере представляет собой 4-угольник, то есть квадрат:

Матричное произведение AB представляет собой матрицу 10x5, а BC — матрицу 30x60. В этом примере возможны две триангуляции:
-
 Многоугольное представление (AB)C
Многоугольное представление (AB)C -
 Многоугольное представление A(BC)
Многоугольное представление A(BC)


Стоимость одного треугольника с точки зрения количества необходимых умножений равна произведению его вершин. Общая стоимость конкретной триангуляции многоугольника равна сумме стоимостей всех его треугольников:
- ( AB ) C : (10×30×5) + (10×5×60) = 1500 + 3000 = 4500 умножений
- A ( BC ): (30×5×60) + (10×30×60) = 9000 + 18000 = 27000 умножений
Ху и Шинг разработали алгоритм, который находит оптимальное решение задачи разделения минимальной стоимости за время O ( n log n ). Их доказательство правильности алгоритма основано на «лемме 1», доказанной в техническом отчете 1981 года и исключенной из опубликованной статьи. [6] [4] Доказательство леммы в техническом отчете неверно, но Шинг представил исправленное доказательство. [1]
Другие O ( n log n ) алгоритмы
[ редактировать ]Ван, Чжу и Тиан опубликовали упрощенный алгоритм O ( n log m ), где n — количество матриц в цепочке, а m — количество локальных минимумов в размерной последовательности данной цепочки матриц. [7]
Нимбарк, Гохель и Доши опубликовали жадный алгоритм O ( n log n ), [8] но их доказательство оптимальности неверно, и их алгоритм не может обеспечить наиболее эффективное назначение скобок для некоторых цепочек матриц. [1]
Приближенное решение Чин-Ху-Шинга
[ редактировать ]Алгоритм, созданный независимо Чином. [9] и Ху и Шинг [10] работает за O( n ) и создает скобки, которые не более чем на 15,47% хуже оптимального выбора. В большинстве случаев алгоритм дает оптимальное решение или решение, которое хуже оптимального всего на 1–2 процента. [5]
Алгоритм начинается с перевода проблемы в задачу разделения многоугольников. Каждой вершине V многоугольника сопоставлен вес w . Предположим, у нас есть три последовательные вершины , и это вершина с минимальным весом . Смотрим на четырёхугольник с вершинами (по часовой стрелке). Мы можем триангулировать его двумя способами:




- и , со стоимостью
- и со стоимостью .






Следовательно, если

или эквивалентно

мы удаляем вершину от многоугольника и добавьте сторону к триангуляции. Повторяем этот процесс до тех пор, пока не удовлетворяет условию выше. Для всех остальных вершин , добавляем сторону к триангуляции. Это дает нам почти оптимальную триангуляцию.




Обобщения
[ редактировать ]Задача умножения цепочки матриц обобщается до решения более абстрактной задачи: дана линейная последовательность объектов, ассоциативная бинарная операция над этими объектами и способ вычисления стоимости выполнения этой операции над любыми двумя заданными объектами (а также всеми частичными объектами). результаты), вычислите способ группировки объектов с минимальной стоимостью, чтобы применить операцию к последовательности. [11] Одним из несколько надуманных частных случаев является объединение строк списка строк. В C , например, стоимость объединения двух строк длины m и n с помощью strcat равна O( m + n ), поскольку нам нужно время O( m ), чтобы найти конец первой строки, и O( n время ), чтобы найти конец первой строки. скопируйте вторую строку в ее конец. Используя эту функцию стоимости, мы можем написать алгоритм динамического программирования, чтобы найти самый быстрый способ объединения последовательности строк. Однако эта оптимизация довольно бесполезна, поскольку мы можем напрямую объединить строки за время, пропорциональное сумме их длин. Аналогичная проблема существует и для односвязных списков .
Другое обобщение заключается в решении проблемы при наличии параллельных процессоров. В этом случае вместо того, чтобы складывать затраты на вычисление каждого фактора матричного произведения, мы берем максимум, поскольку можем выполнять их одновременно. Это может существенно повлиять как на минимальную стоимость, так и на окончательную оптимальную группировку; Предпочтение отдается более «сбалансированным» группировкам, при которых все процессоры будут заняты. Есть еще более изощренные подходы. [12]
См. также
[ редактировать ]Ссылки
[ редактировать ]- ^ Перейти обратно: а б с Шварц, Одед; Вайс, Элад (январь 2019 г.). «Возвращаясь к «Вычислению продуктов матричной цепочки ». SIAM Journal on Computing . 48 (5): 1481–1486. doi : 10.1137/18m1195401 . S2CID 203009883 .
- ^ Кормен, Томас Х ; Лейзерсон, Чарльз Э ; Ривест, Рональд Л .; Штейн, Клиффорд (2001). «15.2: Матрично-цепочное умножение». Введение в алгоритмы . Том. Второе издание. MIT Press и McGraw-Hill. стр. 331–338. ISBN 978-0-262-03293-3 .
- ^ Ху, ТЦ ; Шинг, М.-Т. (1982). «Расчет произведений матричной цепочки, часть I» (PDF) . SIAM Journal по вычислительной технике . 11 (2): 362–373. CiteSeerX 10.1.1.695.2923 . дои : 10.1137/0211028 . ISSN 0097-5397 .
- ^ Перейти обратно: а б Ху, ТЦ ; Шинг, М.-Т. (1984). «Расчет произведений матричной цепочки, часть II» (PDF) . SIAM Journal по вычислительной технике . 13 (2): 228–251. CiteSeerX 10.1.1.695.4875 . дои : 10.1137/0213017 . ISSN 0097-5397 .
- ^ Перейти обратно: а б Артур, Чумай (1996). «Очень быстрое приближение задачи о произведении матричной цепочки» (PDF) . Журнал алгоритмов . 21 : 71–79. CiteSeerX 10.1.1.218.8168 . дои : 10.1006/jagm.1996.0037 . S2CID 2818053 . Архивировано из оригинала (PDF) 27 июля 2018 г.
- ^ Ху, ТК; Шинг, Монтана (1981). Расчет произведений матричной цепочки, Часть I, Часть II (PDF) (Технический отчет). Стэнфордский университет, факультет компьютерных наук. Часть II, стр. 3. STAN-CS-TR-81-875.
- ^ Ван, Сяодун; Чжу, Даксин; Тиан, Цзюнь (апрель 2013 г.). «Эффективное вычисление матричной цепочки». 2013 8-я Международная конференция по информатике и образованию . стр. 703–707. дои : 10.1109/ICCSE.2013.6553999 . ISBN 978-1-4673-4463-0 . S2CID 17303326 .
- ^ Нимбарк, Хитеш; Гоэль, Шобхен; Доши, Нишант (2011). «Новый подход к умножению цепочки матриц с использованием жадного метода обработки пакетов». Компьютерные сети и информационные технологии . Коммуникации в компьютерной и информатике. Том. 142. стр. 318–321. дои : 10.1007/978-3-642-19542-6_58 . ISBN 978-3-642-19541-9 .
- ^ Чин, Фрэнсис Ю. (июль 1978 г.). «Алгоритм O (n) для определения почти оптимального порядка вычислений продуктов матричной цепочки» . Коммуникации АКМ . 21 (7): 544–549. дои : 10.1145/359545.359556 .
- ^ Ху, ТК; Шинг, Монтана (июнь 1981 г.). «Алгоритм O (n) для поиска почти оптимального разбиения выпуклого многоугольника». Журнал алгоритмов . 2 (2): 122–138. дои : 10.1016/0196-6774(81)90014-6 .
- ^ Г. Баумгартнер, Д. Бернхольдт, Д. Кочорва, Р. Харрисон, М. Нуойен, Дж. Рамануджам и П. Садаяппан. Платформа оптимизации производительности для компиляции выражений тензорного сжатия в параллельные программы. 7-й международный семинар по моделям параллельного программирования высокого уровня и вспомогательным средам (HIPS '02). Форт-Лодердейл, Флорида. 2002 г. доступно по адресу http://citeseer.ist.psu.edu/610463.html и http://www.csc.lsu.edu/~gb/TCE/Publications/OptFramework-HIPS02.pdf.
- ^ Хиджо Ли, Чон Ким, Сунгдже Хон и Сунгу Ли. Распределение процессоров и планирование задач для продуктов матричных цепочек в параллельных системах. Архивировано 22 июля 2011 г. в Wayback Machine . IEEE Транс. по параллельным и распределенным системам, Vol. 14, № 4, стр. 394–407, апрель 2003 г.