Штабелируемая машина
Возможно, этот раздел содержит оригинальные исследования . ( февраль 2016 г. ) |
В информатике , компьютерной инженерии и реализациях языков программирования стековая машина — это компьютерный процессор или виртуальная машина , в которой основным взаимодействием является перемещение кратковременных временных значений в стек и из него . В случае аппаратного процессора аппаратный стек используется . Использование стека существенно уменьшает необходимое количество регистров процессора . Стековые машины расширяют автоматы с выталкиванием вниз дополнительными операциями загрузки/сохранения или несколькими стеками и, следовательно, являются полными по Тьюрингу .
Дизайн [ править ]
Большинство или все инструкции стековой машины предполагают, что операнды будут из стека, а результаты помещены в стек. Стек легко вмещает более двух входных данных или более одного результата, поэтому можно вычислить богатый набор операций. В стековом машинном коде (иногда называемом p-кодом ) инструкции часто имеют только код операции , управляющий операцией, без дополнительных полей, идентифицирующих константу, регистр или ячейку памяти, что известно как формат нулевого адреса . [1] Говорят, что компьютер, который работает таким образом, что большинство его инструкций не содержит явных адресов, использует инструкции с нулевым адресом. [2] Это значительно упрощает декодирование инструкций. Ветви, немедленная загрузка и инструкции загрузки/сохранения требуют поля аргумента, но стековые машины часто устраивают так, что частые случаи из них по-прежнему помещаются вместе с кодом операции в компактную группу битов . Выбор операндов из предыдущих результатов осуществляется неявно путем упорядочивания инструкций. Некоторые наборы команд стековой машины предназначены для интерпретирующего выполнения виртуальной машины, а не для непосредственного управления оборудованием.
Целочисленные константные операнды передаются Push или Load Immediate инструкции. Доступ к памяти часто осуществляется отдельными Load или Store инструкции, содержащие адрес памяти или вычисляющие адрес из значений в стеке. Все практические стековые машины имеют варианты кодов операций загрузки-сохранения для доступа к локальным переменным и формальным параметрам без явного вычисления адреса. Это может быть смещение от текущего адреса вершины стека или смещение от стабильного базового регистра кадра.
Набор команд выполняет большинство действий ALU с помощью постфиксных операций ( обратной польской записи ), которые работают только со стеком выражений, а не с регистрами данных или ячейками основной памяти. Это может быть очень удобно для выполнения языков высокого уровня, поскольку большинство арифметических выражений можно легко перевести в постфиксную нотацию.
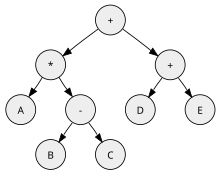
Например, рассмотрим выражение A *( B - C )+( D + E ), записанное в обратной польской записи как A B C - * D E + +. Компиляция и запуск этого на простой воображаемой стековой машине будет выглядеть так:
# stack contents (leftmost = top = most recent): push A # A push B # B A push C # C B A subtract # B-C A multiply # A*(B-C) push D # D A*(B-C) push E # E D A*(B-C) add # D+E A*(B-C) add # A*(B-C)+(D+E)
Арифметические операции «вычитание», «умножение» и «сложение» действуют на два верхних операнда стека. Компьютер берет оба операнда из самых верхних (самых последних) значений стека. Компьютер заменяет эти два значения рассчитанной разницей, суммой или произведением. Другими словами, операнды инструкции «вытаскиваются» из стека, а ее результат(ы) затем «заталкиваются» обратно в стек, готовый к следующей инструкции.
Стековые машины могут иметь стек выражений и стек возврата вызовов отдельно или представлять собой одну интегрированную структуру. Если они разделены, инструкции стековой машины можно будет конвейеризировать с меньшим количеством взаимодействий и меньшей сложностью конструкции, поэтому обычно они будут выполняться быстрее.
Оптимизация скомпилированного кода стека вполне возможна. Было продемонстрировано, что внутренняя оптимизация вывода компилятора значительно улучшает код. [3] [4] и потенциально производительность, в то время как глобальная оптимизация внутри самого компилятора обеспечивает дальнейший выигрыш. [5]
Хранилище стека [ править ]
Некоторые стековые машины имеют стек ограниченного размера, реализованный в виде регистрового файла. ALU получит доступ к этому с помощью индекса. В большом файле регистров используется много транзисторов, поэтому этот метод подходит только для небольших систем. Некоторые машины имеют в памяти как стек выражений, так и отдельный стек регистров. В этом случае программное обеспечение или прерывание могут перемещать данные между ними. Некоторые машины имеют стек неограниченного размера, реализованный в виде массива в оперативной памяти, который кэшируется некоторым количеством адресных регистров «верхушки стека» для уменьшения доступа к памяти. За исключением явных инструкций «загрузки из памяти», порядок использования операндов идентичен порядку операндов в стеке данных, поэтому можно легко выполнить превосходную предварительную выборку.
Учитывать X+1. Он компилируется в Load X; Load 1; Add. Когда стек полностью хранится в оперативной памяти, это выполняет неявную запись и чтение стека в памяти:
- Загрузите X, нажмите в память
- Загрузите 1, нажмите в память
- Извлечь 2 значения из памяти, добавить и отправить результат в память
всего 5 ссылок на кэш данных.
Следующим шагом вперед является стековая машина или интерпретатор с одним регистром вершины стека. Затем приведенный выше код выполняет:
- Загрузите X в пустой регистр TOS (если аппаратная машина) или запишите регистр TOS в память, загрузите X в регистр TOS (если интерпретатор)
- Поместите регистр TOS в память, загрузите 1 в регистр TOS.
- Вытащить левый операнд из памяти, добавить в регистр TOS и оставить там
всего 3 ссылки на кэш данных, в худшем случае. Обычно интерпретаторы не отслеживают пустоту, потому что в этом нет необходимости: все, что находится ниже указателя стека, является непустым значением, а регистр кэша TOS всегда остается горячим. Однако типичные интерпретаторы Java не буферизуют верхнюю часть стека таким образом, поскольку программа и стек содержат как короткие, так и широкие значения данных.
Если аппаратно-стековая машина имеет 2 или более регистров верхнего стека или файл регистров, то в этом примере исключается весь доступ к памяти и существует только 1 цикл кэширования данных.
История и реализации [ править ]
Описание такого метода, требующего одновременного хранения в регистрах только двух значений с ограниченным набором заранее определенных операндов, которые можно было расширить путем определения дальнейших операндов, функций и подпрограмм, было впервые представлено на конференции Робертом С. Бартон в 1961 году. [6] [7]
Коммерческие штабелёры [ править ]
Примеры наборов команд стека, непосредственно выполняемых аппаратно, включают:
- Z4 ( 1945) Компьютер Конрада Цузе имел двухуровневый стек. [8] [9]
- ( архитектура больших систем Берроуза с 1961 г.)
- английская электрическая машина KDF9 . Впервые выпущенный в 1964 году, KDF9 имел 19-уровневый стек арифметических регистров с глубоким выталкиванием вниз и 17-уровневый глубокий стек для адресов возврата подпрограмм.
- мини -компьютер Collins Radio Collins Adaptive Processing System (CAPS, с 1969 г.) и Rockwell Collins микропроцессор с усовершенствованной архитектурой (AAMP, с 1981 г.). [10]
- Xerox Dandelion , представленный 27 апреля 1981 года, и Xerox Daybreak использовали стековую архитектуру машины для экономии памяти. [11] [12]
- p-машина UCSD Pascal (как Pascal MicroEngine и многие другие) поддерживала полноценную среду программирования для студентов на ранних 8-битных микропроцессорах с плохим набором команд и небольшим объемом оперативной памяти путем компиляции в машину виртуального стека.
- Серии MU5 и ICL 2900 . Гибридные штабелирующие и аккумуляторные машины. Регистр аккумулятора буферизует верхнее значение данных стека памяти. Варианты кодов операций загрузки и сохранения контролировали, когда этот регистр был перегружен в стек памяти или перезагружен оттуда.
- HP 3000 (классический, не PA-RISC)
- Системы HP 9000 на базе микропроцессора HP FOCUS . [13]
- Тандемные компьютеры Т/16. Как HP 3000, за исключением того, что компиляторы, а не микрокод, контролировали, когда стек регистров перезагружался в стек памяти или пополнялся из стека памяти.
- Atmel MARC4 микроконтроллер [14]
- Несколько «Форт-фишек» [15] такие как RTX2000, RTX2010 , F21 [16] и PSC1000 [17] [18]
- Компьютер Setun Ternary выполнил сбалансированную троичную систему с использованием стека.
- Четырехстековый процессор Бернда Пейсана имеет четыре стека. [19]
- компании Patriot Scientific Стековая машина Ignite , разработанная Чарльзом Х. Муром, занимает лидирующие позиции по функциональной плотности .
- Saab Ericsson Space Thor Радиационно-стойкий микропроцессор [20]
- Инмос Транспьютеры .
- ZPU Физически небольшой ЦП, предназначенный для управления FPGA . системами [21]
- Архитектура F18A 144-процессорного чипа GA144 от GreenArrays, Inc. [22] [23] [24]
- Некоторые технические портативные калькуляторы используют обратную польскую запись в интерфейсе клавиатуры вместо клавиш в скобках. Это разновидность стековой машины. Ключ «Плюс» опирается на то, что два его операнда уже находятся в правильных верхних позициях видимого пользователю стека.
Виртуальные стековые машины [ править ]
Примеры машин виртуального стека, интерпретируемых в программном обеспечении:
- интерпретирующий код Whetstone ALGOL 60 , [25] на котором были основаны некоторые особенности Burroughs B6500
- UCSD Pascal р-машина ; который очень напоминал Берроуза
- машина p-кода Никлауса Вирта
- Смолток
- набор инструкций виртуальной машины Java (обратите внимание, что только абстрактный набор команд основан на стеке, HotSpot, например, виртуальная машина Sun Java, не реализует реальный интерпретатор в программном обеспечении, а представляет собой рукописные заглушки сборки)
- WebAssembly код байт-
- система виртуального выполнения (VES) для Common Intermediate Language набора инструкций (CIL) .NET Framework (ECMA 335)
- , язык программирования Форт особенно встроенная виртуальная машина
- от Adobe PostScript
- Язык программирования Попугай
- Язык программирования SwapDrop компании Sun Microsystems для Sun Ray смарт-карт идентификации
- Виртуальная машина Adobe ActionScript 2 (AVM2)
- Эфириума EVM
- CPython кода байт- интерпретатор
- Ruby кода YARV интерпретатор байт-
- машина Рубиниус виртуальная
- bs (язык программирования) в Unix использует виртуальный стек-машину для обработки команд после предварительного преобразования предоставленной формы языка ввода в обратную шлифовку.
- Lua (язык программирования) C API
- машина Uxn виртуальная
- виртуальная машина TON (TVM) для Open Network смарт-контрактов
Гибридные машины [ править ]
Машины с чистым стеком совершенно неэффективны для процедур, которые обращаются к нескольким полям одного и того же объекта. Машинный код стека должен перезагрузить указатель объекта для каждого вычисления указателя + смещения. Распространенным решением этой проблемы является добавление в стековую машину некоторых функций регистровой машины: видимого регистрового файла, предназначенного для хранения адресов, и инструкций в стиле регистра для выполнения загрузки и простых вычислений адресов. Регистры полностью общего назначения встречаются редко, потому что тогда нет веской причины иметь стек выражений и постфиксные инструкции.
Другой распространенный гибрид — начать с архитектуры регистровой машины и добавить еще один режим адреса памяти, который имитирует операции push или pop стековых машин: 'memaddress = reg; reg += instr.displ'. Впервые он был использован в DEC компании миникомпьютере PDP-11 . [26] Эта функция была реализована в компьютерах VAX и микропроцессорах Motorola 6800 и M68000 . Это позволило использовать более простые методы стека в ранних компиляторах. Он также эффективно поддерживал виртуальные машины с использованием интерпретаторов стека или многопоточного кода . Однако эта функция не помогла собственному коду регистровой машины стать таким же компактным, как чистый машинный код стека. Также скорость выполнения была меньше, чем при хорошей компиляции в регистровую архитектуру. Быстрее изменять указатель вершины стека лишь изредка (один раз за вызов или возврат), чем постоянно перемещать его вверх и вниз в каждом операторе программы, и еще быстрее полностью избегать обращений к памяти.
Совсем недавно так называемые стековые машины второго поколения приняли специальный набор регистров в качестве адресных регистров, разгружая задачу адресации памяти со стека данных. Например, MuP21 использует регистр под названием «A», тогда как более поздние процессоры GreenArrays используют два регистра: A и B. [23]
Семейство микропроцессоров Intel x86 имеет набор инструкций в стиле регистра (аккумулятора) для большинства операций, но для x87 использует инструкции стека , арифметику с плавающей запятой Intel 8087 , восходящую к сопроцессору iAPX87 (8087) для 8086 и 8088. То есть, нет доступных для программиста регистров с плавающей запятой, а есть только 80-битный 8-уровневый стек. Процессор x87 в значительной степени зависит от процессора x86 при выполнении своих операций.
использующие стеки вызовов и фреймы стека , Компьютеры
Большинство современных компьютеров (с любым стилем набора команд) и большинство компиляторов используют большой стек вызовов-возвратов в памяти для организации кратковременных локальных переменных и ссылок возврата для всех активных в данный момент процедур или функций. Каждый вложенный вызов создает в памяти новый кадр стека , который сохраняется до завершения вызова. Этот стек вызовов-возвратов может полностью управляться аппаратным обеспечением через специализированные адресные регистры и специальные режимы адреса в инструкциях. Или это может быть просто набор соглашений, которым следуют компиляторы, используя общие регистры и режимы адреса регистр + смещение. Или это может быть что-то среднее.
Поскольку этот метод теперь почти универсален, даже на регистровых машинах, бесполезно называть все эти машины стековыми машинами. Этот термин обычно используется для машин, которые также используют стек выражений и арифметические инструкции, состоящие только из стека, для вычисления частей одного оператора.
программы Компьютеры обычно обеспечивают прямой и эффективный доступ к глобальным переменным и к локальным переменным только текущей самой внутренней процедуры или функции, самого верхнего кадра стека. Адресация «верхнего уровня» содержимого кадров стека вызывающих абонентов обычно не требуется и не поддерживается напрямую аппаратным обеспечением. При необходимости компиляторы поддерживают это, передавая указатели кадров в качестве дополнительных скрытых параметров.
Некоторые стековые машины Burroughs поддерживают ссылки верхнего уровня непосредственно в аппаратном обеспечении со специализированными режимами адреса и специальным файлом регистров «отображения», содержащим адреса кадров всех внешних областей. На данный момент только в МЦСТ « Эльбрус» аппаратно это реализовано . Когда Никлаус Вирт разработал первый компилятор Паскаля для CDC 6000 , он обнаружил, что в целом быстрее передавать указатели кадров в виде цепочки, чем постоянно обновлять полные массивы указателей кадров. Этот программный метод также не добавляет накладных расходов для распространенных языков, таких как C, в которых отсутствуют ссылки верхнего уровня.
Те же самые машины Берроуза также поддерживали вложенность задач или потоков. Задача и ее создатель используют общие кадры стека, существовавшие на момент создания задачи, но не последующие кадры создателя и собственные кадры задачи. Его поддерживала стопка кактусов , схема расположения которой напоминала ствол и ветви кактуса Сагуаро . Каждая задача имела свой собственный сегмент памяти, в котором хранился ее стек и принадлежащие ей кадры. Основание этого стека связано с серединой стека его создателя. В машинах с обычным плоским адресным пространством стек создателя и стеки задач будут отдельными объектами-кучей в одной куче.
В некоторых языках программирования внешние среды данных не всегда вложены во времени. Эти языки организуют свои «записи активации» процедур как отдельные объекты кучи, а не как кадры стека, добавленные в линейный стек.
В простых языках, таких как Форт , в которых отсутствуют локальные переменные и именование параметров, кадры стека не будут содержать ничего, кроме адресов ответвлений и накладных расходов на управление кадрами. Таким образом, их стек возврата содержит голые адреса возврата, а не кадры. Стек возврата отделен от стека значений данных, чтобы улучшить поток настройки вызовов и возвратов.
Сравнение с регистровыми машинами [ править ]
Этот раздел нуждается в дополнительных цитатах для проверки . ( Май 2023 г. ) |
Стековые машины часто сравнивают с регистровыми машинами, которые хранят значения в массиве регистров . Регистровые машины могут хранить в этом массиве структуры, подобные стеку, но у регистровых машин есть инструкции, которые обходят интерфейс стека. Регистровые машины обычно превосходят по производительности стековые машины, [27] а стековые машины остались нишевым игроком в аппаратных системах. Но стековые машины часто используются при реализации виртуальных машин из-за их простоты и легкости реализации. [28]
Инструкция [ править ]
Стековые машины имеют более высокую плотность кода . В отличие от обычных стековых машинных инструкций, которые легко умещаются в 6 бит или меньше, регистровым машинам для выбора операндов требуется два или три поля номера регистра на инструкцию ALU; машины с самыми плотными регистрами имеют в среднем около 16 бит на инструкцию плюс операнды. Регистровые машины также используют более широкое поле смещения для кодов операций загрузки и сохранения. Компактный код стековой машины естественным образом помещает в кэш больше инструкций и, следовательно, может обеспечить более высокую эффективность кэша , снижая затраты на память или позволяя использовать более быстрые системы памяти при заданной стоимости. Кроме того, большинство инструкций стековой машины очень просты и состоят только из одного поля кода операции или одного поля операнда. Таким образом, стековым машинам требуется очень мало электронных ресурсов для декодирования каждой инструкции.
Программа должна выполнить больше инструкций при компиляции в стековую машину, чем при компиляции в регистровую машину или машину памяти-памяти. Для каждой загрузки переменной или константы требуется собственная отдельная инструкция загрузки, а не объединение в инструкцию, которая использует это значение. Отдельные инструкции могут выполняться проще и быстрее, но общее количество инструкций все равно выше.
Большинство интерпретаторов регистров указывают свои регистры по номерам. Но к регистрам хост-машины нельзя получить доступ в индексированном массиве, поэтому для виртуальных регистров выделяется массив памяти. Следовательно, инструкции интерпретатора регистров должны использовать память для передачи сгенерированных данных следующей инструкции. Это заставляет интерпретаторы регистров работать намного медленнее на микропроцессорах, созданных с использованием правил точного процесса (т. е. более быстрых транзисторов без увеличения скорости схемы, таких как Haswell x86). Им требуется несколько тактов для доступа к памяти, но только один такт для доступа к регистру. В случае стековой машины со схемой пересылки данных вместо файла регистров интерпретаторы стека могут выделять регистры главной машины для нескольких верхних операндов стека вместо памяти главной машины.
В стековой машине операнды, используемые в инструкциях, всегда находятся по известному смещению (заданному в указателе стека), от фиксированного места (дна стека, которое в аппаратной конструкции всегда может находиться в нулевой ячейке памяти), экономия драгоценного кэша или памяти ЦП от использования для хранения большого количества адресов памяти или индексных номеров. Это может сохранить такие регистры и кэш для использования в непотоковых вычислениях. [ нужна ссылка ]
Временные/локальные значения [ править ]
Некоторые представители отрасли полагают, что стековые машины выполняют больше циклов кэширования данных для временных значений и локальных переменных, чем регистровые машины. [29]
На стековых машинах временные значения часто попадают в память, тогда как на машинах с большим количеством регистров эти временные значения обычно остаются в регистрах. (Однако эти значения часто необходимо помещать в «кадры активации» в конце определения процедуры, в базовый блок или, по крайней мере, в буфер памяти во время обработки прерывания). Значения, попадающие в память, добавляют больше циклов кэширования. Этот эффект распределения зависит от количества скрытых регистров, используемых для буферизации значений вершины стека, от частоты вызовов вложенных процедур и от скорости обработки прерываний главного компьютера.
На регистровых машинах, использующих оптимизирующие компиляторы, наиболее часто используемые локальные переменные остаются в регистрах, а не в ячейках памяти кадра стека. Это исключает большинство циклов кэширования данных для чтения и записи этих значений. Разработка «стекового планирования» для выполнения анализа переменных в реальном времени и, таким образом, сохранения ключевых переменных в стеке в течение продолжительных периодов времени помогает решить эту проблему. [3] [4] [5]
С другой стороны, регистровые машины должны передавать многие из своих регистров в память при вызовах вложенных процедур. Решение о том, какие регистры следует разгружать и когда, принимается статически во время компиляции, а не на основе динамической глубины вызовов. Это может привести к увеличению трафика кэша данных, чем при реализации расширенной стековой машины.
Общие подвыражения [ править ]
В регистровых машинах общее подвыражение (подвыражение, которое используется несколько раз с одним и тем же значением результата) может быть вычислено только один раз, а его результат сохранен в быстром регистре. Последующие повторные использования не требуют затрат времени или кода, а только ссылку на регистр. Эта оптимизация ускоряет простые выражения (например, загрузку переменной X или указателя P), а также менее распространенные сложные выражения.
Напротив, в стековых машинах результаты могут сохраняться одним из двух способов. Во-первых, результаты можно сохранить с помощью временной переменной в памяти. Хранение и последующее извлечение требуют дополнительных инструкций и дополнительных циклов кэширования данных. Это будет выигрышем только в том случае, если вычисление подвыражения требует больше времени, чем выборка из памяти, что в большинстве процессоров со стеком происходит почти всегда. Это никогда не имеет смысла для простых переменных и выборок указателей, потому что они уже имеют одинаковую стоимость одного цикла кэширования данных за доступ. Это имеет лишь незначительное значение для таких выражений, как X+1. Эти более простые выражения составляют большинство избыточных, оптимизируемых выражений в программах, написанных на языках, отличных от конкатенативных языков . Оптимизирующий компилятор может выиграть только от избыточности, которой программист мог бы избежать в исходном коде. [ нужна ссылка ]
Второй способ оставляет вычисленное значение в стеке данных, дублируя его по мере необходимости. При этом используются операции для копирования записей стека. Стек должен иметь достаточную глубину для доступных инструкций копирования ЦП. Написанный вручную стек-код часто использует этот подход и достигает скорости, сравнимой с регистровыми машинами общего назначения. [30] [9] К сожалению, алгоритмы оптимального «стекового планирования» не получили широкого распространения в языках программирования.
Конвейерная обработка [ править ]
В современных машинах время выборки переменной из кэша данных часто в несколько раз превышает время, необходимое для основных операций ALU. Программа работает быстрее без зависаний, если загрузка ее памяти может быть запущена за несколько циклов до команды, которой нужна эта переменная. Сложные машины могут сделать это с помощью глубокого конвейера и «выполнения вне очереди», который проверяет и выполняет множество инструкций одновременно. Регистровые машины могут сделать это даже с помощью гораздо более простого «исправного» оборудования, мелкого конвейера и немного более умных компиляторов. Шаг загрузки становится отдельной инструкцией, и эта инструкция статически запланирована гораздо раньше в последовательности кода. Компилятор помещает между ними независимые шаги.
Для планирования доступа к памяти требуются явные резервные регистры. На стековых машинах это невозможно без раскрытия программисту некоторых аспектов микроархитектуры. Для выражения AB - B должно быть вычислено и введено непосредственно перед шагом «Минус». Без перестановки стека или аппаратной многопоточности во время ожидания завершения загрузки B между ними можно разместить относительно мало полезного кода. Стековые машины могут обойти задержку памяти, либо используя глубокий конвейер выполнения вне порядка, охватывающий множество инструкций одновременно, либо, что более вероятно, они могут переставить стек так, чтобы они могли работать над другими рабочими нагрузками, пока загрузка завершается, или они может чередовать выполнение разных потоков программы, как в системе Unisys A9. [31] Однако сегодняшние все более параллельные вычислительные нагрузки позволяют предположить, что это, возможно, не тот недостаток, которым его считали в прошлом.
Стековые машины могут пропускать этап выборки операндов в регистровой машине. [30] Например, в микропроцессоре Java Optimized Processor (JOP) два верхних операнда стека напрямую входят в схему пересылки данных, которая работает быстрее, чем файл регистров. [32]
Исполнение вне очереди [ править ]
Алгоритм Томасуло находит параллелизм на уровне инструкций, выдавая инструкции по мере того, как их данные становятся доступными. Концептуально адреса позиций в стеке ничем не отличаются от индексов регистров файла регистров. Это представление позволяет использовать внеочередное выполнение алгоритма Томасуло со стековыми машинами.
Выполнение вне очереди в стековых машинах, по-видимому, уменьшает или позволяет избежать многих теоретических и практических трудностей. [33] Приведенное исследование показывает, что такая стековая машина может использовать параллелизм на уровне инструкций, и полученное оборудование должно кэшировать данные для инструкций. Такие машины эффективно обходят большинство обращений к памяти к стеку. В результате достигается пропускная способность (количество инструкций за такт ), сравнимая с машинами с архитектурой загрузки-хранения , с гораздо более высокой плотностью кода (поскольку адреса операндов неявны).
Одна из проблем, поднятая в исследовании, заключалась в том, что для выполнения работы одной инструкции на машине с архитектурой загрузки и хранения требуется около 1,88 машинных инструкций стека. [ нужна ссылка ] Таким образом, конкурирующие машины с вышедшим из строя штабелем требуют примерно вдвое больше электронных ресурсов для отслеживания инструкций («станций выдачи»). Это может быть компенсировано экономией в кэше инструкций и памяти, а также за счет схем декодирования инструкций.
Скрывает внутри более быструю регистрационную машину [ править ]
Некоторые простые стековые машины имеют конструкцию микросхемы, которая полностью настраивается вплоть до уровня отдельных регистров. Верхний адресный регистр стека и N верхних буферов данных стека построены из отдельных отдельных цепей регистров с отдельными сумматорами и специальными соединениями.
Однако большинство стековых машин построены из более крупных схемных компонентов, в которых N буферов данных хранятся вместе в файле регистров и используют общие шины чтения/записи. Декодированные инструкции стека отображаются в одно или несколько последовательных действий в этом скрытом файле регистров. Загрузки и операции ALU действуют на несколько самых верхних регистров, а неявные сбросы и заполнения действуют на самые нижние регистры. Декодер позволяет сделать поток команд компактным. Но если бы поток кода вместо этого имел явные поля выбора регистра, которые напрямую управляли бы базовым файлом регистров, компилятор мог бы лучше использовать все регистры, и программа работала бы быстрее.
Микропрограммированные стековые машины являются примером этого. Внутренний механизм микрокода представляет собой своего рода регистровую машину типа RISC или машину типа VLIW , использующую несколько файлов регистров. При непосредственном управлении микрокодом, специфичным для задачи, этот механизм выполняет гораздо больше работы за цикл, чем при косвенном управлении эквивалентным кодом стека для той же задачи.
Еще одним примером являются трансляторы объектного кода для HP 3000 и Tandem T/16. [34] [35] Они перевели последовательности стекового кода в эквивалентные последовательности RISC-кода. Незначительные «локальные» оптимизации устранили большую часть накладных расходов стековой архитектуры. Запасные регистры использовались для исключения повторяющихся вычислений адреса. Переведенный код по-прежнему содержал много накладных расходов на эмуляцию из-за несоответствия между исходной и целевой машинами. Несмотря на это бремя, эффективность цикла транслируемого кода соответствовала эффективности цикла исходного кода стека. А когда исходный код перекомпилировался напрямую в регистровую машину с помощью оптимизирующих компиляторов, эффективность возросла вдвое. Это показывает, что стековая архитектура и ее неоптимизирующие компиляторы тратили более половины мощности базового оборудования.
Файлы регистров являются хорошими инструментами для вычислений, поскольку они имеют высокую пропускную способность и очень низкую задержку по сравнению с обращениями к памяти через кэши данных. В простой машине файл регистров позволяет читать два независимых регистра и записывать третий, и все это за один цикл ALU с задержкой в один цикл или меньше. В то время как соответствующий кэш данных может запускать только одно чтение или одну запись (не обе) за цикл, а задержка чтения обычно составляет два цикла ALU. Это одна треть пропускной способности при удвоенной задержке конвейера. В сложной машине, такой как Athlon , которая выполняет две или более инструкций за цикл, файл регистров позволяет считывать четыре или более независимых регистров и записывать два других, и все это за один цикл ALU с задержкой в один цикл. В то время как соответствующий двухпортовый кэш данных может запускать только два чтения или записи за цикл с несколькими циклами задержки. Опять же, это треть пропускной способности регистров. Создание кэша с дополнительными портами обходится очень дорого.
Поскольку стек является компонентом большинства программ, даже если используемое программное обеспечение не является строго стековой машиной, аппаратная стековая машина может более точно имитировать внутреннюю работу своих программ. Регистры процессора имеют высокие тепловые затраты, а стековая машина может требовать более высокой энергоэффективности. [22]
Прерывания [ править ]
Реакция на прерывание включает сохранение регистров в стек, а затем переход к коду обработчика прерывания. Часто стековые машины быстрее реагируют на прерывания, поскольку большинство параметров уже находятся в стеке и помещать их туда нет необходимости. Некоторые регистровые машины решают эту проблему, имея несколько файлов регистров, которые можно мгновенно поменять местами. [36] но это увеличивает затраты и замедляет работу файла реестра.
Переводчики [ править ]
Интерпретаторы для виртуальных стековых машин создать проще, чем интерпретаторы для регистровых машин; логика обработки режимов адреса памяти находится только в одном месте, а не повторяется во многих инструкциях. Стековые машины также имеют меньше вариантов кода операции; один обобщенный код операции будет обрабатывать как частые случаи, так и неясные случаи обращения к памяти или настройки вызова функции. (Однако плотность кода часто улучшается добавлением коротких и длинных форм для одной и той же операции.)
Интерпретаторы для виртуальных стековых машин часто работают медленнее, чем интерпретаторы для других стилей виртуальных машин. [37] Это замедление наиболее сильно проявляется при работе на хост-компьютерах с глубокими конвейерами выполнения, таких как современные чипы x86.
В некоторых интерпретаторах интерпретатор должен выполнить переход по N-стороннему переключателю, чтобы декодировать следующий код операции и перейти к его шагам для этого конкретного кода операции. Другой метод выбора опкодов — потоковый код . Механизмы предварительной выборки хост-машины не могут предсказать и получить цель этого индексированного или косвенного перехода. Таким образом, конвейер выполнения хост-машины должен перезапускаться каждый раз, когда размещенный интерпретатор декодирует другую виртуальную инструкцию. Это происходит чаще с виртуальными стековыми машинами, чем с другими типами виртуальных машин. [38]
Одним из примеров является язык программирования Java . Его каноническая виртуальная машина указана как 8-битная стековая машина. Однако виртуальная машина Dalvik для Java, используемая на Android смартфонах , представляет собой 16-битную машину с виртуальным регистром — выбор сделан по соображениям эффективности. Арифметические инструкции напрямую извлекают или сохраняют локальные переменные через 4-битные (или более) поля инструкций. [39] Аналогичным образом, версия 5.0 Lua заменила виртуальную машину стека более быстрой машиной виртуальных регистров. [40] [41]
С тех пор, как виртуальная машина Java стала популярной, микропроцессоры стали использовать усовершенствованные средства прогнозирования ветвей для непрямых переходов. [42] Это усовершенствование позволяет избежать большинства перезапусков конвейера из-за N-путевых переходов и устраняет большую часть затрат на подсчет команд, которые влияют на интерпретаторы стека.
См. также [ править ]
- Стек-ориентированный язык программирования
- Конкатенативный язык программирования
- Сравнение виртуальных машин приложений
- SECD-машина
- Аккумуляторная машина
- Ленточная машина
- Машина произвольного доступа
Ссылки [ править ]
- ^ Борода, Боб (осень 1997 г.). «Компьютер KDF9 — 30 лет спустя» . Компьютерное ВОСКРЕСЕНИЕ .
- ^ Хейс, Джон П. (1978). Компьютерная архитектура и организация . Международная книжная компания McGraw-Hill. п. 164. ИСБН 0-07-027363-4 .
- ↑ Перейти обратно: Перейти обратно: а б Купман-младший, Филип Джон (1994). «Предварительное исследование оптимизированной генерации стекового кода» (PDF) . Журнал Форт-приложений и исследований . 6 (3).
- ↑ Перейти обратно: Перейти обратно: а б Бейли, Крис (2000). «Межграничное планирование операндов стека: предварительное исследование» (PDF) . Материалы конференции Euroforth 2000 .
- ↑ Перейти обратно: Перейти обратно: а б Шеннон, Марк; Бейли, Крис (2006). «Глобальное распределение стека: распределение регистров для стековых машин» (PDF) . Материалы конференции Euroforth 2006 .
- ^ Бартон, Роберт С. (9 мая 1961 г.). «Новый подход к функциональному проектированию цифрового компьютера» . Доклады, представленные на Западной совместной компьютерной конференции IRE-AIEE-ACM 9–11 мая 1961 г. 1961 Западная совместная компьютерная конференция IRE-AIEE-ACM. стр. 393–396. дои : 10.1145/1460690.1460736 . ISBN 978-1-45037872-7 . S2CID 29044652 .
- ^ Бартон, Роберт С. (1987). «Новый подход к функциональному проектированию цифрового компьютера» . IEEE Анналы истории вычислений . 9 :11–15. дои : 10.1109/MAHC.1987.10002 .
- ^ Блаау, Геррит Энн ; Брукс-младший, Фредерик Филлипс (1997). Компьютерная архитектура: концепции и эволюция . Бостон, Массачусетс, США: Addison-Wesley Longman Publishing Co., Inc.
- ↑ Перейти обратно: Перейти обратно: а б ЛаФорест, Чарльз Эрик (апрель 2007 г.). «2.1 Лукасевич и первое поколение: 2.1.2 Германия: Конрад Цузе (1910–1995); 2.2 Первое поколение стековых компьютеров: 2.2.1 Zuse Z4». Стековая компьютерная архитектура второго поколения (PDF) (диссертация). Ватерлоо, Канада: Университет Ватерлоо . п. 8, 11 и т. д. Архивировано (PDF) из оригинала 20 января 2022 г. Проверено 2 июля 2022 г. (178 страниц) [1]
- ^ Греве, Дэвид А.; Уайлдинг, Мэтью М. (12 января 1998 г.). «Первый в мире Java-процессор» . Время электронной инженерии .
- ^ «Принципы работы процессора Mesa» . Компьютерный музей DigiBarn . Ксерокс. Архивировано из оригинала 14 мая 2024 г. Проверено 20 сентября 2023 г.
- ^ «DigiBarn: Xerox Star 8010 «Одуванчик» » . Компьютерный музей DigiBarn. Архивировано из оригинала 3 мая 2024 г. Проверено 20 сентября 2023 г.
- ^ «Набор команд для однокристального 32-битного процессора» . Журнал Hewlett-Packard . 34 (8). Хьюлетт-Паккард. Август 1983 года . Проверено 5 февраля 2024 г.
- ^ Руководство программиста 4-битных микроконтроллеров MARC4 (PDF) . Атмел .
- ^ «Форт фишки» . Colorforth.com . Архивировано из оригинала 15 февраля 2006 г. Проверено 8 октября 2017 г.
- ^ «Обзор микропроцессора F21» . Ультратехнология.com . Проверено 8 октября 2017 г.
- ^ «ФортФрик вики» . GitHub.com . 25 августа 2017 г. Проверено 8 октября 2017 г.
- ^ «Чип Java доступен — прямо сейчас!» . Разработчик.com . 8 апреля 1999 г. Проверено 7 июля 2022 г.
- ^ «4-стековый процессор» . bernd-paysan.de . Проверено 8 октября 2017 г.
- ^ «Портирование компилятора GNU C на микропроцессор Thor» (PDF) . 04.12.1995. Архивировано из оригинала (PDF) 20 августа 2011 г. Проверено 30 марта 2011 г.
- ^ «ZPU — самый маленький в мире 32-битный процессор с набором инструментов GCC: обзор» . opencores.org . Проверено 7 февраля 2015 г.
- ↑ Перейти обратно: Перейти обратно: а б «Документы» . ГринАррайс, Инк . Технология F18A . Проверено 7 июля 2022 г.
- ↑ Перейти обратно: Перейти обратно: а б «Инструкции colorForth» . Colorforth.com . Архивировано из оригинала 10 марта 2016 г. Проверено 8 октября 2017 г. (Набор инструкций ядер F18A, по историческим причинам названный colorForth.)
- ^ «ГринАррайс, Инк» . Greenarraychips.com . Проверено 8 октября 2017 г.
- ^ Рэнделл, Брайан ; Рассел, Лоуфорд Джон (1964). Реализация Алгола 60 (PDF) . Лондон, Великобритания: Academic Press . ISBN 0-12-578150-4 .
- ^ Дункан, Фрейзер Джордж (1 мая 1977 г.). «Разработка стековых машин: Австралия, Великобритания и Европа» (PDF) . Компьютер . Том. 10, нет. 5. Бристольский университет, Бристоль, Вирджиния, США. стр. 50–52. дои : 10.1109/MC.1977.315873 . eISSN 1558-0814 . ISSN 0018-9162 . S2CID 17013010 . КОДЕН CPTRB4 . Архивировано из оригинала (PDF) 15 октября 2023 г. Проверено 15 октября 2023 г. (3 страницы)
- ^ Ши, Юнхэ; Грегг, Дэвид; Битти, Эндрю; Эртл, М. Антон (2005). «Разборка виртуальных машин: стек против регистров». Материалы 1-й международной конференции ACM/USENIX по виртуальным средам исполнения . стр. 153–163. дои : 10.1145/1064979.1065001 . ISBN 1595930477 . S2CID 811512 .
- ^ Хайд, Рэндалл (2004). Напишите отличный код, Том. 2. Мышление на низком уровне, письмо на высоком уровне . Том. 2. Пресс без крахмала . п. 391. ИСБН 978-1-59327-065-0 . Проверено 30 июня 2021 г.
- ^ «Компьютерная архитектура: количественный подход», Джон Л. Хеннесси , Дэвид Эндрю Паттерсон ; См. обсуждение стековых машин.
- ↑ Перейти обратно: Перейти обратно: а б Купман-младший, Филип Джон. «Стековые компьютеры: новая волна» . Ece.cmu.edu . Проверено 8 октября 2017 г.
- ^ Введение в системы серии A (PDF) . Корпорация Берроуз . Апрель 1986 года . Проверено 20 сентября 2023 г.
- ^ «Проектирование и внедрение эффективной штабелёрной машины» (PDF) . Jopdesign.com . Проверено 8 октября 2017 г.
- ^ Синха, Стив; Чаттерджи, Сатраджит; Равиндран, Кошик. «BOOST: Неисправный стек в Беркли» . Исследовательские ворота . Проверено 11 ноября 2023 г.
- ^ Берг, Арндт; Кейлман, Кейт; Магенхаймер, Дэниел; Миллер, Джеймс (декабрь 1987 г.). «Эмуляция HP3000 на компьютерах HP Precision Architecture» (PDF) . Журнал Hewlett-Packard . Хьюлетт-Паккард : 87–89 . Проверено 20 сентября 2023 г.
- ^ Кристи Эндрюс; Дуэйн Сэнд (октябрь 1992 г.). «Миграция семейства компьютеров CISC на RISC посредством трансляции объектного кода». Труды АСПЛОС-V .
- ^ Руководство по процессору 8051, Intel, 1980 г.
- ^ Ши, Юнхэ; Грегг, Дэвид; Битти, Эндрю; Эртле, М. Антон. «Разборка виртуальных машин: стек против регистровой машины» (PDF) . Usenix.org . Проверено 8 октября 2017 г.
- ^ Дэвис, Брайан; Битти, Эндрю; Кейси, Кевин; Грегг, Дэвид; Уолдрон, Джон. «Аргументы в пользу машин с виртуальными регистрами» (PDF) . Scss.tcd.ie. Проверено 20 сентября 2023 г.
- ^ Борнштейн, Дэн (29 мая 2008 г.). «Презентация внутренних компонентов Dalvik VM» (PDF) . п. 22 . Проверено 16 августа 2010 г.
- ^ «Реализация Lua 5.0» (PDF) . Луа.орг . Проверено 8 октября 2017 г.
- ^ «Виртуальная машина Lua 5.0» (PDF) . Инф.puc-rio.br . Проверено 8 октября 2017 г.
- ^ «Прогнозирование ветвей и работа переводчиков - не доверяйте фольклору» . Hal.inria.fr . Проверено 20 сентября 2023 г.
Внешние ссылки [ править ]
- Домашний процессор в FPGA - самодельная стековая машина с использованием FPGA
- Компьютер Mark 1 FORTH — самодельная стековая машина, использующая дискретные логические схемы.
- Компьютер Mark 2 FORTH — самодельная стековая машина, использующая bitslice/PLD
- Стековая компьютерная архитектура второго поколения — диссертация об истории и конструкции стековых машин.