Трансляция (параллельная схема)
Широковещательная рассылка — это примитив коллективной связи в параллельном программировании, предназначенный для распространения программных инструкций или данных по узлам кластера. Это обратная операция сокращения. [1] Операция широковещания широко используется в параллельных алгоритмах, таких как умножение матрицы на вектор, [1] Метод исключения Гаусса и кратчайшие пути . [2]
Интерфейс передачи сообщений реализует широковещательную рассылку в MPI_Bcast. [3]
Определение
[ редактировать ]Сообщение длины должны распространяться от одного узла ко всем остальным узлы.
![{\displaystyle M[1..m]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/c3e38b38a48f71cb8c1c43b0011a71a56a376f3b)


это время, необходимое для отправки одного байта.

— это время, необходимое сообщению для перемещения к другому узлу, независимо от его длины.

Следовательно, время отправки пакета с одного узла на другой равно . [1]

количество узлов и количество процессоров.

Трансляция биномиального дерева
[ редактировать ]
При использовании биномиального дерева вещания все сообщение отправляется сразу. Каждый узел, уже получивший сообщение, отправляет его дальше. Это растет экспоненциально, поскольку на каждом временном шаге количество отправляющих узлов удваивается. Алгоритм идеален для коротких сообщений, но не справляется с более длинными, поскольку во время первой передачи занят только один узел.
Отправка сообщения всем узлам занимает время, что приводит к времени выполнения


Message M
id := node number
p := number of nodes
if id > 0
blocking_receive M
for (i := ceil(log_2(p)) - 1; i >= 0; i--)
if (id % 2^(i+1) == 0 && id + 2^i <= p)
send M to node id + 2^i
Линейное конвейерное вещание
[ редактировать ]
Сообщение разбито на пакеты и отправлять по частям с узла узел . Время, необходимое для распространения первой части сообщения, равно посредством чего — это время, необходимое для отправки пакета с одного процессора на другой.





Отправка всего сообщения занимает .

Оптимально выбрать в результате время выполнения составляет примерно


Время выполнения зависит не только от длины сообщения, но и от количества процессоров, которые играют роли. Этот подход эффективен, когда длина сообщения намного превышает количество процессоров.
Message M := [m_1, m_2, ..., m_n]
id = node number
for (i := 1; i <= n; i++) in parallel
if (id != 0)
blocking_receive m_i
if (id != n)
send m_i to node id + 1
Конвейерная трансляция двоичного дерева
[ редактировать ]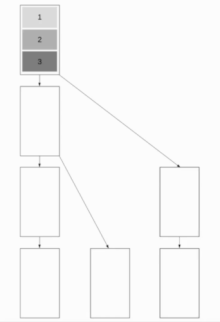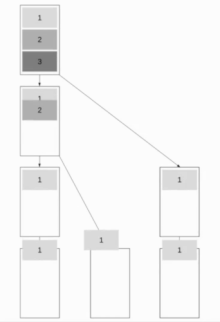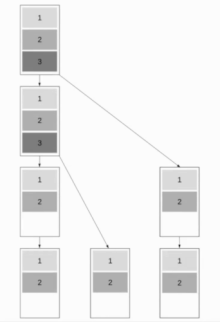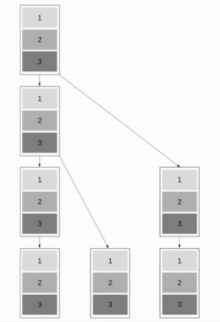
Этот алгоритм сочетает в себе трансляцию биномиального дерева и линейную конвейерную трансляцию, что позволяет алгоритму хорошо работать как с короткими, так и с длинными сообщениями. Цель состоит в том, чтобы заставить работать как можно больше узлов, сохраняя при этом возможность быстрой отправки коротких сообщений. Хороший подход — использовать деревья Фибоначчи для разделения дерева, что является хорошим выбором, поскольку сообщение не может быть отправлено обоим дочерним элементам одновременно. В результате получается двоичная древовидная структура.
В дальнейшем мы будем предполагать, что связь является полнодуплексной . Древовидная структура Фибоначчи имеет глубину около посредством чего золотое сечение .


Полученное время выполнения . Оптимально .


Это приводит к времени выполнения .

Message M := [m_1, m_2, ..., m_k]
for i = 1 to k
if (hasParent())
blocking_receive m_i
if (hasChild(left_child))
send m_i to left_child
if (hasChild(right_child))
send m_i to right_child
Трансляция двух деревьев (23-трансляция)
[ редактировать ]
Определение
[ редактировать ]Этот алгоритм направлен на устранение некоторых недостатков моделей древовидной структуры с конвейерами. Обычно в моделях древовидной структуры с конвейерами (см. методы выше) листья получают только свои данные и не могут участвовать в отправке и распространении данных.
Алгоритм одновременно использует два двоичных дерева для связи. Эти деревья будут называться деревом A и B. Структурно в бинарных деревьях выходных узлов относительно больше, чем внутренних. Основная идея этого алгоритма состоит в том, чтобы сделать листовой узел дерева A внутренним узлом дерева B. Он также имеет ту же техническую функцию на противоположной стороне от дерева B к дереву A. Это означает, что два пакета отправляются и принимаются внутренними узлами и отправляются на разных этапах.
Строительство деревьев
[ редактировать ]
Количество шагов, необходимых для построения двух параллельно работающих двоичных деревьев, зависит от количества процессоров. Как и в других структурах, один процессор может быть корневым узлом, который отправляет сообщения двум деревьям. Нет необходимости задавать корневой узел, поскольку нетрудно понять, что направление отправки сообщений в двоичном дереве обычно сверху вниз. Нет ограничений на количество процессоров для построения двух двоичных деревьев . Пусть высота объединенного дерева равна h = ⌈log( p + 2)⌉ . Деревья A и B могут иметь высоту . Особенно, если количество процессоров соответствует , мы можем создать деревья с обеих сторон и корневой узел.


Чтобы эффективно и легко построить эту модель с полностью построенным деревом, мы можем использовать два метода, называемые «Сдвиг» и «Зеркалирование», для получения второго дерева. Предположим, что дерево A уже смоделировано, а дерево B должно быть построено на основе дерева A. Предположим, что у нас есть процессоры упорядочены от 0 до .
Переключение
[ редактировать ]
Метод «Сдвиг» сначала копирует дерево A и перемещает каждый узел на одну позицию влево, чтобы получить дерево B. Узел, который будет расположен в -1, становится дочерним элементом процессора. .

Зеркальное отображение
[ редактировать ]
«Зеркалирование» идеально подходит для четного числа процессоров. С помощью этого метода дерево B легче построить из дерева A, поскольку для создания нового дерева не требуется структурных преобразований. Кроме того, симметричный процесс упрощает этот подход. Этот метод также может обрабатывать нечетное количество процессоров, в этом случае мы можем установить процессор в качестве корневого узла для обоих деревьев. Для остальных процессоров можно использовать «Зеркалирование».
Раскраска
[ редактировать ]Нам нужно найти расписание, чтобы гарантировать, что ни одному процессору не придется отправлять или получать два сообщения от двух деревьев за шаг. Край — это коммуникационное соединение для соединения двух узлов, которое может быть помечено как 0 или 1, чтобы гарантировать, что каждый процессор может переключаться между ребрами, помеченными 0 и 1. Края A и B можно раскрасить в два цвета (0 и 1) так, что
- ни один процессор не соединен со своими родительскими узлами в A и B, используя ребра одного цвета.
- ни один процессор не соединен со своими дочерними узлами в A или B, используя ребра одного цвета. [7]
На каждом четном шаге активируются ребра с 0, а на каждом нечетном шаге активируются ребра с 1.
Временная сложность
[ редактировать ]В этом случае количество пакетов k делится пополам для каждого дерева. Оба дерева совместно работают над общим количеством пакетов. (верхнее дерево + нижнее дерево)

В каждом двоичном дереве отправка сообщения другим узлам занимает шагов до тех пор, пока процессор не получит хотя бы пакет в шаге . Следовательно, мы можем рассчитать все шаги как .



Итоговое время выполнения . (Оптимальный )


Это приводит к тому, что время выполнения .

ESBT-Broadcasting (непересекающиеся по краям остовные биномиальные деревья)
[ редактировать ]В этом разделе будет представлен другой алгоритм широковещания, лежащий в основе модели телефонной связи. Гиперкуб с создает сетевую систему . Каждый узел представлен двоичным в зависимости от количества измерений. По сути, ESBT (непересекающиеся по краям остовные биномиальные деревья) основаны на графах гиперкубов , конвейерной обработке( сообщения делятся по пакеты) и биномиальные деревья . Процессор циклически распределяет пакеты по корням ESBT. Корни ESBT передают данные в виде биномиального дерева. Оставить все от , шаги необходимы, поскольку все пакеты распределяются по . Требуется еще d шагов, пока последний листовой узел не получит пакет. Всего необходимы шаги для трансляции сообщение через ESBT.





Итоговое время выполнения . .


Это приводит к тому, что время выполнения .

См. также
[ редактировать ]Ссылки
[ редактировать ]- ^ Jump up to: а б с Кумар, Випин (2002). Введение в параллельные вычисления (2-е изд.). Бостон, Массачусетс, США: Addison-Wesley Longman Publishing Co., Inc., стр. 185, 151, 66. ISBN. 9780201648652 .
- ^ Jump up to: а б Брук, Дж.; Сайфер, Р.; Эй, Коннектикут. (1992). «Множественная передача сообщений с обобщенными деревьями Фибоначчи». [1992] Материалы четвертого симпозиума IEEE по параллельной и распределенной обработке . стр. 424–431. дои : 10.1109/SPDP.1992.242714 . ISBN 0-8186-3200-3 . S2CID 2846661 .
- ^ MPI: Стандартный интерфейс передачи сообщений, версия 3.0 , Форум интерфейса передачи сообщений, стр. 148, 2012 г.
- ^ Jump up to: а б с Михаэль Иккерт, Т. Кириц, П. Сандерс Алгоритм Парралеле - сценарий (немецкий), Технологический институт Карлсруэ, стр. 29-32, 2009 г.
- ^ Майкл Иккерт, Т. Кириц, Алгоритм Парралеле П. Сандерса - сценарий (немецкий), Технологический институт Карлсруэ, стр. 33-37, 2009 г.
- ^ П. Сандерс [1] (немецкий), Технологический институт Карлсруэ, стр. 82-96, 2018 г.
- ^ Jump up to: а б Сандерс, Питер; Спек, Йохен; Трефф, Йеспер Ларссон (2009). «Двухдеревьевые алгоритмы для широкополосного вещания, сокращения и сканирования». Параллельные вычисления . 35 (12): 581–594. дои : 10.1016/j.parco.2009.09.001 . ISSN 0167-8191 .
- ^ Майкл Иккерт, Т. Кириц, Алгоритм Парралеле П. Сандерса - сценарий (немецкий), Технологический институт Карлсруэ, стр. 40-42, 2009 г.
- ^ П. Сандерс [2] (немецкий), Технологический институт Карлсруэ, стр. 101-104, 2018 г.