Чередованная память
Эта статья включает список общих ссылок , но в ней отсутствуют достаточные соответствующие встроенные цитаты . ( Октябрь 2012 г. ) |
В вычислительной технике чередующаяся память — это конструкция, которая компенсирует относительно низкую скорость динамической памяти с произвольным доступом (DRAM) или основной памяти путем равномерного распределения адресов памяти по банкам памяти . Таким образом, последовательные операции чтения и записи памяти используют каждый банк памяти по очереди, что приводит к повышению пропускной способности памяти за счет сокращения времени ожидания готовности банков памяти к операциям.
Она отличается от многоканальных архитектур памяти , прежде всего тем, что чередующаяся память не добавляет больше каналов между основной памятью и контроллером памяти . Однако чередование каналов также возможно, например, в процессорах Freescale i.MX 6, которые позволяют выполнять чередование между двумя каналами. [ нужна ссылка ]
Обзор
[ редактировать ]При чередовании памяти адреса памяти выделяются каждому банку памяти по очереди. Например, в чередующейся системе с двумя банками памяти (при условии, что память имеет пословную адресацию ), если логический адрес 32 принадлежит банку 0, то логический адрес 33 будет принадлежать банку 1, логический адрес 34 будет принадлежать банку 0 и т. д. . Говорят, что чередующаяся память имеет n-стороннее чередование, если имеется n банков и ячейка памяти i находится в банке i mod n .
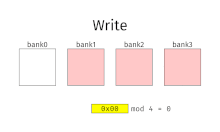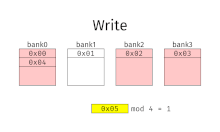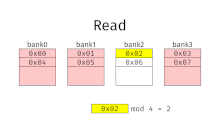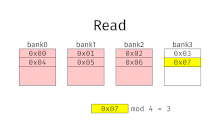
Чередование памяти приводит к непрерывному чтению (которое часто встречается как в мультимедиа, так и при выполнении программ) и непрерывной записи (которое часто используется при заполнении буферов хранения или связи), фактически используя каждый банк памяти по очереди, вместо многократного использования одного и того же. Это приводит к значительно более высокой пропускной способности памяти, поскольку каждый банк имеет минимальное время ожидания между чтением и записью.
Чередованная DRAM
[ редактировать ]Основная память ( оперативное запоминающее устройство , ОЗУ) обычно состоит из набора микросхем памяти DRAM , где несколько микросхем могут быть сгруппированы вместе, чтобы сформировать банк памяти. Тогда с помощью контроллера памяти, поддерживающего чередование, можно расположить эти банки памяти так, чтобы банки памяти чередовались.
Данные в DRAM хранятся в страницах. Каждый банк DRAM имеет буфер строк, который служит кэшем для доступа к любой странице в банке. Прежде чем страница в банке DRAM будет прочитана, она сначала загружается в буфер строк . Если страница немедленно считывается из буфера строк (или при попадании в буфер строк), она имеет наименьшую задержку доступа к памяти за один цикл памяти. Если это промах буфера строк, который также называется конфликтом буфера строк, это происходит медленнее, поскольку новая страница должна быть загружена в буфер строк, прежде чем она будет прочитана. Промахи в буфере строк происходят, когда обслуживаются запросы доступа к разным страницам памяти в одном банке. Конфликт строк и буферов приводит к существенной задержке доступа к памяти. Напротив, доступ к памяти к различным банкам может осуществляться параллельно с высокой пропускной способностью.
Проблема конфликтов буферов строк хорошо изучена и имеет эффективное решение. [1] Размер буфера строк обычно равен размеру страницы памяти, управляемой операционной системой. Конфликты или промахи буфера строк возникают в результате последовательности обращений к разным страницам в одном и том же банке памяти. Изучение [1] показывает, что традиционный метод чередования памяти будет распространять конфликты отображения адресов на уровне кэша в адресное пространство памяти, вызывая промахи в буфере строк в банке памяти. Метод чередующейся памяти на основе перестановок решил проблему с тривиальными затратами на микроархитектуру. [1] Компания Sun Microsystems быстро внедрила этот метод перестановочного чередования в свои продукты. [2] Этот незапатентованный метод можно найти во многих коммерческих микропроцессорах, таких как AMD, Intel и NVIDIA , для встраиваемых систем, ноутбуков, настольных компьютеров и корпоративных серверов. [3]
В традиционных (плоских) схемах банкам памяти может быть выделен непрерывный блок адресов памяти, что очень просто для контроллера памяти и обеспечивает одинаковую производительность в сценариях полностью произвольного доступа по сравнению с уровнями производительности, достигаемыми за счет чередования. Однако в действительности операции чтения из памяти редко бывают случайными из-за локальности ссылок , а оптимизация для доступа близко друг к другу дает гораздо лучшую производительность в чередующихся макетах.
Способ обращения к памяти не влияет на время доступа к ячейкам памяти, которые уже кэшированы , а влияет только на те ячейки памяти, которые необходимо извлечь из DRAM.
История
[ редактировать ]Ранние исследования чередующейся памяти проводились в IBM в 60-х и 70-х годах применительно к компьютеру IBM 7030 Stretch . [4] но разработка продолжалась десятилетиями, улучшая дизайн, гибкость и производительность для создания современных реализаций.
См. также
[ редактировать ]Ссылки
[ редактировать ]- ^ Jump up to: а б с Чжао Чжан, Чжичунь Чжу и Сяодун Чжан (2000). Схема чередования страниц на основе перестановок для уменьшения конфликтов между строками и буфером и использования локальности данных . МИКРО' 33.
{{cite conference}}: CS1 maint: несколько имен: список авторов ( ссылка ) - ^ «Сан-письмо директору отдела трансфера технологий Колледжа Уильяма и Мэри» (PDF) . 15 июля 2005 г.
- ^ «Профессор Сяодун Чжан получил награду ACM «Испытание времени в области микроархитектуры 2020 года»» . Департамент компьютерных наук и инженерии Инженерного колледжа Университета штата Огайо . 19 января 2021 г.
- ^ Марк Смотерман (июль 2010 г.). «IBM Stretch (7030) — агрессивный однопроцессорный параллелизм» . Клемсон.edu . Проверено 7 декабря 2013 г.