Изоляционный лес
Судя по всему, основной автор этой статьи тесно связан с ее предметом. ( Октябрь 2023 г. ) |
Isolation Forest — это алгоритм обнаружения аномалий данных , первоначально разработанный Фей Тони Лю в 2008 году. [1] Isolation Forest обнаруживает аномалии с помощью двоичных деревьев . Алгоритм имеет линейную временную сложность и низкие требования к памяти, что хорошо работает с данными большого объема. [2] [3] По сути, для обнаружения аномалий алгоритм опирается на характеристики аномалий, т.е. на то, что их мало и они различны. В алгоритме не выполняется оценка плотности. Алгоритм отличается от алгоритмов дерева решений тем, что для генерации оценки аномалии используется только мера или аппроксимация длины пути, статистика конечных узлов о распределении классов или целевом значении не требуется.
Изоляционный лес работает быстро, поскольку он разбивает пространство данных случайным образом, используя случайно выбранный атрибут и случайно выбранную точку разделения. Оценка аномалии обратно связана с длиной пути, поскольку для изоляции аномалий требуется меньшее количество разделений из-за того, что их мало и они различаются.
История [ править ]
Алгоритм Isolation Forest (iForest) был первоначально предложен Фей Тони Лю, Кай Мин Тином и Чжи-Хуа Чжоу в 2008 году. [2] В 2010 году появилось расширение алгоритма — SCiforest. [4] был разработан для устранения кластерных и параллельно осевых аномалий. В 2012 году [3] те же авторы продемонстрировали, что iForest имеет линейную временную сложность, небольшие требования к памяти и применим к данным большой размерности.
Алгоритм [ править ]
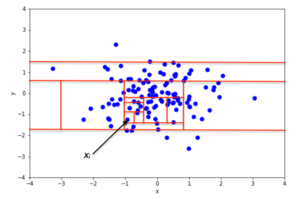
Суть алгоритма «Изолирующий лес» заключается в том, что аномальные точки данных легче отделить от остальной части выборки. Чтобы изолировать точку данных, алгоритм рекурсивно генерирует разделы выборки, случайным образом выбирая атрибут, а затем случайным образом выбирая значение разделения между минимальным и максимальным значениями, разрешенными для этого атрибута.
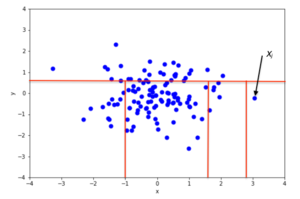
Пример случайного разделения в двумерном наборе данных нормально распределенных точек приведен на рис. 2 для неаномальной точки и на рис. 3 для точки, которая с большей вероятностью является аномальной. На рисунках видно, что аномалии требуют выделения меньшего количества случайных участков по сравнению с нормальными точками.
Рекурсивное секционирование может быть представлено древовидной структурой с именем « Дерево изоляции» , а количество секций, необходимых для изоляции точки, можно интерпретировать как длину пути внутри дерева для достижения конечного узла, начиная с корня. Например, длина пути точки на рис. 2 больше длины пути на рис. 3.


Позволять быть набором d-мерных точек и . Дерево изоляции (iTree) определяется как структура данных со следующими свойствами:


- для каждого узла в Дереве, является либо внешним узлом без дочерних узлов, либо внутренним узлом с одним «тестом» и ровно двумя дочерними узлами ( и )
- тест на узле состоит из атрибута и разделенное значение такой, что тест определяет переход точки данных либо к или .






Чтобы построить iTree, алгоритм рекурсивно делит случайным образом выбрав атрибут и разделенное значение , пока либо

- узел имеет только один экземпляр, или
- все данные в узле имеют одинаковые значения.
Когда iTree полностью вырастет, каждая точка в изолирован на одном из внешних узлов. Интуитивно понятно, что аномальными точками являются точки (следовательно, их легче изолировать) с меньшей длиной пути в дереве, где длина пути точки определяется как количество ребер проходит от корневого узла, чтобы добраться до внешнего узла.



Вероятностное объяснение iTree представлено в оригинальной статье iForest. [2]
Свойства изолирующего леса [ править ]
- Подвыборка : поскольку iForest не требуется изолировать все обычные экземпляры, он часто может игнорировать большую часть обучающей выборки. Как следствие, iForest работает очень хорошо, когда размер выборки остается небольшим, что контрастирует с подавляющим большинством существующих методов, где обычно желателен большой размер выборки. [2] [3]
- Заболачивание : когда нормальные экземпляры расположены слишком близко к аномалиям, количество разделов, необходимых для разделения аномалий, увеличивается. Это явление известно как заболачивание , из-за чего iForest становится сложнее различать аномалии и нормальные точки. Одной из основных причин заболачивания является наличие слишком большого количества данных для обнаружения аномалий, что означает, что одним из возможных решений проблемы является субвыборка. Поскольку он очень хорошо реагирует на подвыборку с точки зрения производительности, уменьшение количества точек в выборке также является хорошим способом уменьшить эффект «заболачивания». [2]
- Маскирование : когда количество аномалий велико, возможно, что некоторые из них объединятся в плотный и большой кластер, что затрудняет разделение отдельных аномалий и, в свою очередь, обнаружение таких точек как аномальных. Подобно заболачиванию, это явление (известное как « маскирование ») также более вероятно, когда количество точек в выборке велико и его можно уменьшить путем субвыборки. [2]
- Высокомерные данные . Одним из основных ограничений стандартных методов, основанных на расстоянии, является их неэффективность при работе с многомерными наборами данных. [5] Основная причина этого в том, что в многомерном пространстве все точки одинаково редки, поэтому использование меры разделения на основе расстояния довольно неэффективно. К сожалению, многомерные данные также влияют на производительность обнаружения iForest, но производительность можно значительно улучшить, добавив тест выбора функций, такой как Kurtosis , для уменьшения размерности выборочного пространства. [2] [4]
- Только нормальные экземпляры : iForest работает хорошо, даже если обучающий набор не содержит аномальных точек. [4] причина в том, что iForest описывает распределение данных таким образом, что высокие значения длины пути соответствуют наличию точек данных. Как следствие, наличие аномалий практически не влияет на эффективность обнаружения iForest.
Обнаружение аномалий с помощью изолирующего леса [ править ]
Обнаружение аномалий с помощью Isolation Forest — это процесс, состоящий из двух основных этапов: [4]
- на первом этапе для построения iTrees используется набор обучающих данных.
- на втором этапе каждый экземпляр в тестовом наборе проходит через эти iTrees, и экземпляру присваивается надлежащая «оценка аномалии».
После того как всем экземплярам в тестовом наборе присвоен показатель аномалии, можно пометить как «аномалию» любую точку, показатель которой превышает заранее определенный порог, который зависит от области, к которой применяется анализ.
Оценка аномалий [ править ]
Алгоритм вычисления оценки аномалии точки данных основан на наблюдении, что структура iTree эквивалентна структуре двоичных деревьев поиска (BST): завершение внешнего узла iTree соответствует неудачному поиску в BST. . [4] В результате оценка среднего для завершения внешнего узла аналогична неудачному поиску в BST, т.е. [6]


где размер тестовых данных, размер выборки и - номер гармоники, который можно оценить по формуле , где — постоянная Эйлера-Машерони .





Значение c(m) выше представляет собой среднее значение данный , поэтому мы можем использовать его для нормализации и получить оценку оценки аномалии для данного экземпляра x:

где это среднее значение из коллекции iTrees. Интересно отметить, что для любого данного случая :


- если близко к затем очень вероятно, что это аномалия
- если меньше, чем затем скорее всего, это нормальное значение
- если для данной выборки всем экземплярам присвоен показатель аномалии около , то можно с уверенностью предположить, что в выборке нет аномалий



Реализации с открытым исходным кодом [ править ]
Первоначальной реализацией авторов статьи был Forest в R. Isolation
Другие реализации (в алфавитном порядке):
- ELKI содержит реализацию Java.
- Isolation Forest — реализация Spark/Scala. [7]
- Isolation Forest от H2O-3 — реализация Python.
- Реализация изолированности в R. пакетов
- Реализация Python с примерами в scikit-learn .
- Spark iForest — распределенная реализация Apache Spark на Scala/Python.
- PyOD IForest — еще одна реализация Python в популярной библиотеке Python Outlier Detection (PyOD) .
Другие варианты реализации алгоритма Isolation Forest:
- Extended Isolation Forest – реализация Extended Isolation Forest. [8]
- Extended Isolation Forest от H2O-3 — реализация Extended Isolation Forest.
- (Python, R, C/C++) Isolation Forest и его варианты — реализация Isolation Forest и его вариаций. [9]
См. также [ править ]
Ссылки [ править ]
- ^ Лю, Фэй Тони. «Первая реализация Isolation Forest на Sourceforge» .
- ^ Jump up to: Перейти обратно: а б с д и ж г Лю, Фэй Тони; Тинг, Кай Мин; Чжоу, Чжи-Хуа (декабрь 2008 г.). «Лес изоляции». 2008 г. Восьмая международная конференция IEEE по интеллектуальному анализу данных . стр. 413–422. дои : 10.1109/ICDM.2008.17 . ISBN 978-0-7695-3502-9 . S2CID 6505449 .
- ^ Jump up to: Перейти обратно: а б с Лю, Фэй Тони; Тинг, Кай Мин; Чжоу, Чжи-Хуа (декабрь 2008 г.). «Обнаружение аномалий на основе изоляции» . Транзакции ACM по извлечению знаний из данных . 6 : 3:1–3:39. дои : 10.1145/2133360.2133363 . S2CID 207193045 .
- ^ Jump up to: Перейти обратно: а б с д и Лю, Фэй Тони; Тинг, Кай Мин; Чжоу, Чжи-Хуа (сентябрь 2010 г.). «Об обнаружении кластерных аномалий с помощью SCiForest» . Объединенная европейская конференция по машинному обучению и обнаружению знаний в базах данных — ECML PKDD 2010: Машинное обучение и обнаружение знаний в базах данных . Конспекты лекций по информатике. 6322 : 274–290. дои : 10.1007/978-3-642-15883-4_18 . ISBN 978-3-642-15882-7 .
- ^ Дилини Талагала, Приянга; Гайндман, Роб Дж.; Смит-Майлз, Кейт (12 августа 2019 г.). «Обнаружение аномалий в многомерных данных». arXiv : 1908.04000 [ stat.ML ].
- ^ Шаффер, Клиффорд А. (2011). Структуры данных и анализ алгоритмов в Java (3-е изд. Дувра). Минеола, Нью-Йорк: Dover Publications. ISBN 9780486485812 . OCLC 721884651 .
- ^ Вербус, Джеймс (13 августа 2019 г.). «Обнаружение и предотвращение злоупотреблений в LinkedIn с помощью изоляционных лесов» . Инженерный блог LinkedIn . Проверено 2 июля 2023 г.
- ^ Харири, Саханд; Добрый, Матиас Карраско; Бруннер, Роберт Дж. (апрель 2021 г.). «Расширенный лес изоляции» . Транзакции IEEE по знаниям и инженерии данных . 33 (4): 1479–1489. arXiv : 1811.02141 . дои : 10.1109/TKDE.2019.2947676 . ISSN 1558-2191 . S2CID 53236735 .
- ^ Кортес, Дэвид (2019). «Аппроксимация расстояния с использованием изоляционных лесов». arXiv : 1910.12362 [ stat.ML ].