Ближайший сосед с большой маржой
Ближайший сосед с большим запасом ( LMNN ) [1] Классификация — это статистический машинного обучения алгоритм для метрического обучения . Он изучает псевдометрику, предназначенную для классификации k-ближайших соседей . Алгоритм основан на полуопределенном программировании , подклассе выпуклой оптимизации .
Цель обучения с учителем (точнее, классификации) — изучить правило принятия решения, которое может классифицировать экземпляры данных по заранее определенным классам. Правило k-ближайшего соседа предполагает набор обучающих данных из помеченных экземпляров (т. е. классы известны). Он классифицирует новый экземпляр данных по классу, полученному большинством голосов k ближайших (помеченных) обучающих экземпляров. Близость измеряется с помощью заранее определенной метрики . Ближайшие соседи с большим запасом — это алгоритм, который изучает эту глобальную (псевдо)метрику контролируемым образом, чтобы повысить точность классификации правила k-ближайшего соседа.
Настраивать
[ редактировать ]Основная идея LMNN заключается в изучении псевдометрики, согласно которой все экземпляры данных в обучающем наборе окружены как минимум k экземплярами, имеющими одну и ту же метку класса. Если это достигнуто, ошибка исключения одного (особый случай перекрестной проверки ) сводится к минимуму. Пусть обучающие данные состоят из набора данных , где набор возможных категорий классов равен .


Алгоритм изучает псевдометрику типа
- .

Для чтобы быть четко определенным, матрица должно быть положительно полуопределенным . Евклидова метрика является частным случаем, когда является единичной матрицей. Это обобщение часто (ошибочно) [ нужна ссылка ] ), называемую метрикой Махаланобиса .


Рисунок 1 иллюстрирует влияние метрики при изменении . Два круга показывают набор точек на равном расстоянии от центра. . В евклидовом случае это множество представляет собой круг, тогда как в модифицированной метрике (Махаланобиса) оно становится эллипсоидом .

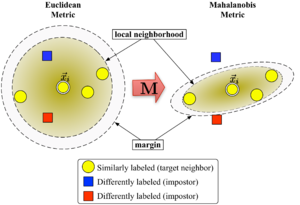
Алгоритм различает два типа особых точек данных: целевые соседи и самозванцы .
Целевые соседи
[ редактировать ]Целевые соседи выбираются перед обучением. Каждый экземпляр имеет точно разные целевые соседи внутри , которые имеют одну и ту же метку класса . Целевые соседи — это точки данных, которые должны стать ближайшими соседями по изученной метрике . Обозначим набор целевых соседей для точки данных как .




Самозванцы
[ редактировать ]Самозванец точки данных это еще одна точка данных с другой меткой класса (т.е. ), который является одним из ближайших соседей . Во время обучения алгоритм пытается минимизировать количество самозванцев для всех экземпляров данных в обучающем наборе.


Алгоритм
[ редактировать ]Большой запас ближайших соседей оптимизирует матрицу с помощью полуопределенного программирования . Цель двоякая: для каждой точки данных целевые соседи должны быть близко , а самозванцы должны быть далеко . На рисунке 1 показан эффект такой оптимизации на наглядном примере. Изученная метрика приводит к тому, что входной вектор быть окружен обучающими экземплярами одного и того же класса. Если бы это была контрольная точка, она была бы правильно отнесена к категории правило ближайшего соседа.

Первая цель оптимизации достигается за счет минимизации среднего расстояния между экземплярами и их целевыми соседями.
- .

Вторая цель достигается за счет штрафных санкций за расстояние до самозванцев. которые находятся менее чем на одну единицу дальше, чем целевые соседи (и, следовательно, выталкивая их из местного района ). Результирующее значение, которое необходимо минимизировать, можно записать как:

![{\displaystyle \sum _{i,j\in N_{i},l,y_{l}\neq y_{i}}[d({\vec {x}}_{i},{\vec {x }}_{j})+1-d({\vec {x}}_{i},{\vec {x}}_{l})]_{+}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/610f792bc1112ce305344bf3096730af8c5a066a)
С потери шарнира функцией , что гарантирует, что близость самозванца не будет наказываться за пределами поля. Запас ровно в одну единицу фиксирует масштаб матрицы. . Любой альтернативный выбор приведет к изменению масштаба в разы .
![{\textstyle [\cdot ]_ {+}=\max(\cdot,0)}](https://wikimedia.org/api/rest_v1/media/math/render/svg/18812591e56f8034ee8c8497c0f85caaf16818fc)



Окончательная задача оптимизации выглядит следующим образом:





Гиперпараметр — некоторая положительная константа (обычно устанавливается посредством перекрестной проверки). Здесь переменные (вместе с двумя типами ограничений) заменяет член в функции стоимости. Они играют роль, аналогичную резервным переменным, поглощая степень нарушений ограничений самозванца. Последнее ограничение гарантирует, что является положительно полуопределенным. Задача оптимизации является примером полуопределенного программирования (SDP). Хотя SDP, как правило, страдают от высокой вычислительной сложности, этот конкретный экземпляр SDP может быть решен очень эффективно благодаря основным геометрическим свойствам проблемы. В частности, большинство ограничений-самозванцев естественным образом удовлетворяются и их не нужно применять во время выполнения (т. е. набор переменных является редким). Особенно хорошо подходящим методом решателя является метод рабочего набора , который сохраняет небольшой набор активно применяемых ограничений и лишь изредка отслеживает оставшиеся (вероятно удовлетворяемые) ограничения, чтобы гарантировать правильность.


Расширения и эффективные решатели
[ редактировать ]В статье 2008 года LMNN был расширен на несколько локальных показателей. [2] Это расширение значительно уменьшает ошибку классификации, но требует более дорогостоящей задачи оптимизации. В своей публикации 2009 года в Журнале исследований машинного обучения [3] Вайнбергер и Сол нашли эффективный решатель для полуопределенной программы. Он может изучить метрику для набора рукописных цифр MNIST за несколько часов, включая миллиарды парных ограничений. Реализация с открытым исходным кодом Matlab находится в свободном доступе на веб-странице авторов .
Кумаль и др. [4] расширил алгоритм, включив локальные инварианты в многомерные полиномиальные преобразования и улучшенную регуляризацию.
См. также
[ редактировать ]- Обучение по сходству
- Линейный дискриминантный анализ
- Обучение векторному квантованию
- Псевдометрическое пространство
- Поиск ближайшего соседа
- Кластерный анализ
- Классификация данных
- Интеллектуальный анализ данных
- Машинное обучение
- Распознавание образов
- Прогнозная аналитика
- Уменьшение размеров
- Анализ компонентов соседства
Ссылки
[ редактировать ]- ^ Вайнбергер, КК; Блитцер Дж.К.; Саул Л.К. (2006). «Дистанционное метрическое обучение для классификации ближайших соседей с большим запасом» . Достижения в области нейронных систем обработки информации . 18 : 1473–1480.
- ^ Вайнбергер, КК; Саул Л.К. (2008). «Быстрые решатели и эффективные реализации дистанционного обучения метрикам» (PDF) . Материалы международной конференции по машинному обучению : 1160–1167. Архивировано из оригинала (PDF) 24 июля 2011 г. Проверено 14 июля 2010 г.
- ^ Вайнбергер, КК; Саул Л.К. (2009). «Дистанционное метрическое обучение для классификации с большой маржой» (PDF) . Журнал исследований машинного обучения . 10 : 207–244.
- ^ Кумар, член парламента; Торр PHS; Зиссерман А. (2007). «Инвариантный классификатор ближайших соседей с большим запасом». 2007 г. 11-я Международная конференция IEEE по компьютерному зрению . стр. 1–8. дои : 10.1109/ICCV.2007.4409041 . ISBN 978-1-4244-1630-1 . S2CID 1326101 .