Согласованное хеширование
В информатике последовательное хеширование [1] [2] это особый вид метода хеширования , при котором при хеш-таблицы изменяется только изменении размера клавиши необходимо переназначить в среднем там, где количество ключей и это количество слотов. Напротив, в большинстве традиционных хеш-таблиц изменение количества слотов массива приводит к переназначению почти всех ключей, поскольку сопоставление между ключами и слотами определяется модульной операцией .



Согласованное хеширование равномерно распределяет ключи кэша по шардам , даже если некоторые из шардов выходят из строя или становятся недоступными. [3]
История
[ редактировать ]Термин «согласованное хеширование» был введен Дэвидом Каргером и др. в Массачусетском технологическом институте для использования в распределенном кэшировании , особенно для Интернета . [4] В этой научной статье 1997 года на Симпозиуме по теории вычислений был введен термин «согласованное хеширование» как способ распределения запросов среди меняющегося набора веб-серверов. [5] Затем каждый слот представляется сервером в распределенной системе или кластере. Для добавления сервера и удаления сервера (во время масштабирования или простоя) требуется только предметы, которые будут перетасованы при изменении количества слотов (т.е. серверов). Авторы упоминают линейное хеширование и его способность обрабатывать последовательное добавление и удаление серверов, в то время как последовательное хеширование позволяет добавлять и удалять серверы в произвольном порядке. [1] Позже документ был перепрофилирован для решения технической проблемы отслеживания файла в одноранговых сетях, таких как распределенная хеш-таблица . [6] [7]

Teradata использовала этот метод в своей распределенной базе данных, выпущенной в 1986 году, хотя и не использовала этот термин. Teradata до сих пор использует концепцию хеш-таблицы именно для этой цели. Akamai Technologies была основана в 1998 году учёными Дэниелом Льюином и Ф. Томсоном Лейтоном (соавторами статьи о «последовательном хешировании»). В сети доставки контента Akamai [8] согласованное хеширование используется для балансировки нагрузки внутри кластера серверов, а алгоритм стабильного брака используется для балансировки нагрузки между кластерами. [2]
Согласованное хеширование также использовалось для уменьшения влияния частичных сбоев системы в крупных веб-приложениях, чтобы обеспечить надежное кэширование без общесистемных последствий сбоя. [9] Согласованное хеширование также является краеугольным камнем распределенных хеш-таблиц (DHT), которые используют хеш-значения для разделения пространства ключей по распределенному набору узлов, а затем создают наложенную сеть связанных узлов, обеспечивающую эффективный поиск узлов по ключу.
Хеширование рандеву , разработанное в 1996 году, представляет собой более простой и общий метод. [ нужна ссылка ] . Он достигает целей последовательного хеширования, используя совершенно другой алгоритм наибольшего случайного веса (HRW).
Основная техника
[ редактировать ]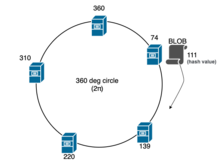

в задаче балансировки нагрузки Например, , когда BLOB-объект должен быть назначен одному из серверов в кластере , можно использовать стандартную хеш-функцию таким образом, чтобы мы вычисляли хэш-значение для этого BLOB, предполагая, что результирующее значение хеш-функции равно , выполняем модульную работу с количеством серверов ( в данном случае), чтобы определить сервер, на котором мы можем разместить BLOB: ; следовательно, BLOB будет помещен на сервер, чей является преемником в этом случае. Однако когда сервер добавляется или удаляется во время простоя или масштабирования (когда изменения), все BLOB-объекты на каждом сервере должны быть переназначены и перемещены из-за перехэширования , но эта операция является дорогостоящей.




Согласованное хеширование было разработано, чтобы избежать проблемы переназначения каждого BLOB-объекта при добавлении или удалении сервера в кластере. Основная идея заключается в использовании хэш-функции, которая отображает как BLOB, так и серверы в единичный круг, обычно радианы. Например, (где — это хэш BLOB-объекта или идентификатора сервера, например IP-адреса или UUID ). Каждый BLOB затем назначается следующему серверу, который появляется в круге по часовой стрелке. Обычно алгоритм двоичного поиска или линейный поиск используются для поиска «пятна» или сервера для размещения этого конкретного BLOB-объекта. или сложности соответственно; и на каждой итерации, которая происходит по часовой стрелке, операция (где — значение сервера в кластере) выполняется для поиска сервера для размещения BLOB. Это обеспечивает равномерное распределение BLOB-объектов по серверам. Но, что еще более важно, если сервер выйдет из строя и будет удален из круга, только те BLOB-объекты, которые были сопоставлены с вышедшим из строя сервером, необходимо будет переназначить следующему серверу по часовой стрелке. Аналогично, если добавляется новый сервер, он добавляется в единичный круг, и переназначать необходимо только BLOB-объекты, сопоставленные с этим сервером.







Важно отметить, что при добавлении или удалении сервера подавляющее большинство BLOB-объектов сохраняют свои предыдущие назначения серверов, а добавление сервер вызывает только часть BLOB-объектов для перемещения. Хотя процесс перемещения BLOB-объектов между кэш-серверами в кластере зависит от контекста, обычно вновь добавленный кэш-сервер идентифицирует своего «преемника» и перемещает все BLOB-объекты, сопоставление которых принадлежит этому серверу (т. е. чье хэш-значение меньше этого значения). нового сервера), с него. Однако в случае кэшей веб-страниц в большинстве реализаций перемещение или копирование не требуется, при условии, что кэшированный BLOB-объект достаточно мал. Когда запрос попадает на вновь добавленный кэш-сервер, происходит промах кэша , и выполняется запрос к фактическому веб-серверу , а BLOB-объект кэшируется локально для будущих запросов. Избыточные BLOB-объекты на ранее использовавшихся серверах кэша будут удалены в соответствии с политикой вытеснения кэша . [10]


Выполнение
[ редактировать ]Позволять и — хеш-функции, используемые для BLOB-объекта и уникального идентификатора сервера соответственно. На практике двоичное дерево поиска (BST) используется для динамического поддержания внутри кластера или хэширования, а для поиска преемника или минимума в BST обход дерева используется .


- Вставка в кластер
- Позволять быть хеш-значением BLOB-объекта, таким образом, что где и . Чтобы вставить , найдите преемника в BST с. Если больше, чем все s, BLOB размещается на сервере с наименьшим ценить.
- Удаление из кластера
- Найдите преемника в BST удалите BLOB из возвращенного . Если не имеет преемника, удалите BLOB из наименьшего из с. [11]
- Вставляем сервер в кластер
- Позволять быть хеш-значением идентификатора сервера, таким образом, где и . Переместите все BLOB-объекты, хеш-значение которых меньше , с сервера, чей является преемником . Если является крупнейшим из всех s, переместите соответствующие BLOB-объекты из наименьшего из в . [12]
- Удалить сервер из кластера
- Найдите преемника в BST переместите BLOB-объекты из на его последующий сервер. Если не имеет преемника, переместите BLOB-объекты в самый маленький из с. [13]








Уменьшение дисперсии
[ редактировать ]Чтобы избежать асимметрии нескольких узлов внутри радиана, которая возникает из-за отсутствия равномерного распределения серверов внутри кластера, используются несколько меток. Эти повторяющиеся метки называются «виртуальными узлами», т.е. несколько меток, которые указывают на одну «настоящую» метку или сервер в кластере. Количество виртуальных узлов или повторяющихся меток, используемых для конкретного сервера в кластере, называется «весом» этого конкретного сервера. [14]
Практические расширения
[ редактировать ]Для эффективного использования согласованного хеширования для балансировки нагрузки на практике необходим ряд расширений базового метода. В приведенной выше базовой схеме в случае сбоя сервера все его BLOB-объекты переназначаются следующему серверу по часовой стрелке, что потенциально увеличивает нагрузку на этот сервер вдвое. Это может быть нежелательно. Чтобы обеспечить более равномерное перераспределение BLOB-объектов в случае сбоя сервера, каждый сервер можно хешировать в несколько мест на единичном круге. В случае сбоя сервера BLOB-объекты, назначенные каждой из его реплик в единичном круге, будут переназначены другому серверу по часовой стрелке, что перераспределит BLOB-объекты более равномерно. Другое расширение касается ситуации, когда один BLOB становится «горячим», к нему обращаются большое количество раз и его необходимо разместить на нескольких серверах. В этой ситуации BLOB-объект может быть назначен нескольким смежным серверам путем прохождения единичного круга по часовой стрелке. Более сложное практическое рассмотрение возникает, когда два BLOB-объекта хэшируются рядом друг с другом в единичном круге и оба становятся «горячими» одновременно. В этом случае оба BLOB-объекта будут использовать один и тот же набор смежных серверов в единичном круге. Эту ситуацию можно улучшить, если каждый BLOB выберет другую хэш-функцию для сопоставления серверов с единичным кругом. [2]
Сравнение с рандеву-хешированием и другими альтернативами
[ редактировать ]Хэширование рандеву , разработанное в 1996 году, представляет собой более простой и общий метод, позволяющий полностью распределять соглашения по набору варианты из возможного набора параметры. Фактически можно показать , что согласованное хеширование является частным случаем рандеву-хеширования. Из-за своей простоты и универсальности рандеву-хеширование теперь используется во многих приложениях вместо последовательного хеширования.

Если значения ключей всегда будут монотонно увеличиваться , альтернативный подход с использованием хеш-таблицы с монотонными ключами может оказаться более подходящим, чем последовательное хеширование. [ нужна ссылка ]
Сложность
[ редактировать ]| Классическая хеш-таблица | Согласованное хеширование | |
|---|---|---|
| добавить узел | ||
| удалить узел | ||
| найти ключ | ||
| добавить ключ | ||
| удалить ключ |





The — это средние затраты на перераспределение ключей и Сложность последовательного хеширования связана с тем, что двоичный поиск среди углов узлов. для поиска следующего узла на кольце требуется [ нужна ссылка ]

Примеры
[ редактировать ]Известные примеры использования последовательного хеширования включают:
- Couchbase Автоматическое разделение данных [15]
- Служба объектного хранилища OpenStack Swift [16]
- Компонент секционирования системы хранения данных Amazon Dynamo [17]
- Разделение данных в Apache Cassandra [18]
- Разделение данных в ScyllaDB [19]
- Разделение данных в Волдеморте [20]
- Akka Маршрутизатор последовательного хеширования [21]
- Riak , распределенная база данных «ключ-значение» [22]
- Gluster — сетевая файловая система хранения данных. [23]
- Akamai Сеть доставки контента [24]
- в Discord Приложение для общения [25]
- Балансировка нагрузки запросов gRPC в распределенный кеш в SpiceDB [26]
- аккордов Алгоритм [27]
- MinIO Система объектного хранения [28]
Ссылки
[ редактировать ]- ^ Jump up to: Перейти обратно: а б Каргер, Д.; Леман, Э.; Лейтон, Т .; Паниграхи, Р.; Левин, М.; Левин, Д. (1997). Согласованное хеширование и случайные деревья: протоколы распределенного кэширования для устранения «горячих точек» во Всемирной паутине . Труды двадцать девятого ежегодного симпозиума ACM по теории вычислений . ACM Press Нью-Йорк, Нью-Йорк, США. стр. 654–663. дои : 10.1145/258533.258660 .
- ^ Jump up to: Перейти обратно: а б с Брюс Мэггс и Рамеш Ситараман (2015). «Алгоритмические самородки в доставке контента» (PDF) . Обзор компьютерных коммуникаций ACM SIGCOMM . 45 (3).
- ^ Проектирование шаблонов и парадигм распределенных систем для масштабируемых и надежных сервисов . О'Рейли Медиа. 2018. ISBN 9781491983607 .
- ^ Roughgarden & Valiant 2021 , с. 2.
- ^ Roughgarden & Valiant 2021 , с. 7.
- ^ Roughgarden & Valiant 2021 , с. 8.
- ^ И. Стойка и др., «Chord: масштабируемый протокол однорангового поиска для интернет-приложений», в IEEE/ACM Transactions on Networking, vol. 11, нет. 1, стр. 17–32, февраль 2003 г., doi: 10.1109/TNET.2002.808407.
- ^ Нигрен., Э.; Ситараман Р.К.; Сан, Дж. (2010). «Сеть Akamai: платформа для высокопроизводительных интернет-приложений» (PDF) . Обзор операционных систем ACM SIGOPS . 44 (3): 2–19. дои : 10.1145/1842733.1842736 . S2CID 207181702 . Архивировано (PDF) из оригинала 30 ноября 2022 г. Проверено 29 августа 2023 г.
- ^ Каргер, Д.; Шерман, А.; Беркхаймер, А.; Богстад, Б.; Данидина, Р.; Ивамото, К.; Ким, Б.; Маткинс, Л.; Йерушалми, Ю. (1999). «Веб-кэширование с последовательным хешированием» . Компьютерные сети . 31 (11): 1203–1213. дои : 10.1016/S1389-1286(99)00055-9 . Архивировано из оригинала 21 июля 2008 г. Проверено 5 февраля 2008 г.
- ^ Roughgarden & Valiant 2021 , с. 6.
- ^ Мойтра 2016 , с. 2.
- ^ Мойтра 2016 , с. 2–3.
- ^ Мойтра 2016 , с. 3.
- ^ Roughgarden & Valiant 2021 , с. 6–7.
- ^ «Что такое мембаза?» . 16 декабря 2014 года . Проверено 29 октября 2020 г.
- ^ Холт, Грег (февраль 2011 г.). «Создание согласованного кольца хеширования» . сайт openstack.org . Проверено 17 ноября 2019 г.
- ^ ДеКандиа, Дж.; Хасторун, Д.; Джампани, М.; Какулапати, Г.; Лакшман, А.; Пильчин А.; Сивасубраманиан, С.; Восшалл, П.; Фогельс, Вернер (2007). «Динамо» (PDF) . Обзор операционных систем ACM Sigops . 41 (6): 205–220. дои : 10.1145/1323293.1294281 . Проверено 7 июня 2018 г.
- ^ Лакшман, Авинаш; Малик, Прашант (2010). «Кассандра: децентрализованная структурированная система хранения». Обзор операционных систем ACM SIGOPS . 44 (2): 35–40. дои : 10.1145/1773912.1773922 . S2CID 916681 .
- ^ «Сравнение NoSQL: MongoDB и ScyllaDB» . benchant.com . Проверено 21 марта 2024 г.
- ^ «Дизайн — Волдеморт» . www.project-voldemort.com/ . Архивировано из оригинала 9 февраля 2015 года . Проверено 9 февраля 2015 г.
Согласованное хеширование — это метод, который позволяет избежать этих проблем, и мы используем его для вычисления местоположения каждого ключа в кластере.
- ^ «Акка Роутинг» . akka.io. Проверено 16 ноября 2019 г.
- ^ «Концепции Риак» . Архивировано из оригинала 19 сентября 2015 г. Проверено 6 декабря 2016 г.
- ^ «Алгоритмы GlusterFS: Распространение» . gluster.org . 01.03.2012 . Проверено 16 ноября 2019 г.
- ^ Рафгарден, Тим; Валиант, Грегори (28 марта 2016 г.). «Современный набор инструментов для алгоритмов» (PDF) . Стэнфорд.edu . Проверено 17 ноября 2019 г.
- ^ Вишневский, Станислав (06.07.2017). «Как Discord увеличил число одновременных пользователей Elixir до 5 000 000» . Проверено 16 августа 2022 г.
- ^ «Последовательная балансировка хэш-нагрузки для gRPC» . 24 ноября 2021 г. Проверено 4 сентября 2023 г.
- ^ Стойка, И .; Моррис, Р.; Либен-Ноуэлл, Д.; Каргер, Д.; Каашук, МФ; Дабек, Ф.; Балакришнан, Х. (25 февраля 2003 г.). «Chord: масштабируемый протокол однорангового поиска для интернет-приложений». Транзакции IEEE/ACM в сети . 11 (1): 17–32. дои : 10.1109/TNET.2002.808407 . S2CID 221276912 .
- ^ «Управление версиями MinIO, метаданные и хранилище» . Проверено 24 октября 2023 г.
Цитируемые работы
[ редактировать ]- Мойтра, Анкур (10 февраля 2016 г.). «Расширенные алгоритмы, 6.854» (PDF) . Массачусетский технологический институт . Архивировано (PDF) из оригинала 13 апреля 2021 года . Проверено 8 октября 2021 г.
- Рафгарден, Тим; Валиант, Грегори (28 марта 2021 г.). «Современный набор алгоритмических инструментов, введение в последовательное хеширование» (PDF) . Стэнфордский университет . Архивировано (PDF) из оригинала 25 июля 2021 года . Проверено 7 октября 2021 г.
Внешние ссылки
[ редактировать ]- Понимание последовательного хеширования
- Последовательное хеширование Майкла Нильсена, 3 июня 2009 г.
- Последовательное хеширование, Дэнни Левин и создание Akamai
- Согласованное хеширование с переходом: быстрый, последовательный алгоритм хеширования с минимальным объемом памяти
- Хеширование рандеву: альтернатива последовательному хешированию
- Реализации на разных языках: