Политики замены кэша
В вычислительной технике политики замены кэша (также известные как алгоритмы замены кэша или алгоритмы кэша ) представляют собой оптимизирующие инструкции или алгоритмы , которые компьютерная программа или структура, поддерживаемая аппаратным обеспечением, могут использовать для управления кэшем информации. Кэширование повышает производительность за счет хранения последних или часто используемых элементов данных в ячейках памяти, доступ к которым осуществляется быстрее или с вычислительной точки зрения дешевле, чем к обычным хранилищам памяти. Когда кеш заполнен, алгоритм должен выбрать, какие элементы отбросить, чтобы освободить место для новых данных.
Обзор
[ редактировать ]Среднее время обращения к памяти составляет [1]

где
- = коэффициент промахов = 1 - (коэффициент попаданий)
- = время доступа к основной памяти в случае промаха (или, в случае многоуровневого кеша, среднее время обращения к памяти для следующего нижнего кеша)
- = задержка: время обращения к кешу (должно быть одинаковым для попаданий и промахов)
- = вторичные эффекты, такие как эффекты массового обслуживания в многопроцессорных системах




Кэш имеет два основных показателя качества: задержка и коэффициент попаданий. На производительность кэша также влияет ряд второстепенных факторов. [1]
Коэффициент попадания в кэш описывает, как часто находится искомый элемент. Более эффективные политики замены отслеживают больше информации об использовании, чтобы повысить частоту попаданий для заданного размера кэша. Задержка кэша описывает, как долго после запроса желаемого элемента кэш может вернуть этот элемент при попадании. Стратегии более быстрой замены обычно отслеживают меньше информации об использовании (или, при использовании кэша с прямым отображением, отсутствие информации), чтобы сократить время, необходимое для обновления информации. Каждая стратегия замены представляет собой компромисс между частотой попаданий и задержкой.
Измерения частоты попаданий обычно выполняются в тестовых приложениях, а коэффициент попаданий варьируется в зависимости от приложения. Приложения потоковой передачи видео и аудио часто имеют коэффициент попадания, близкий к нулю, поскольку каждый бит данных в потоке считывается один раз (обязательный промах), используется, а затем никогда не читается и не записывается снова. Многие алгоритмы кэширования (в частности, LRU ) позволяют потоковым данным заполнять кэш, выталкивая информацию, которая вскоре будет использоваться снова ( загрязнение кэша ). [2] Другими факторами могут быть размер, продолжительность получения и срок действия. В зависимости от размера кэша дополнительный алгоритм кэширования для удаления элементов может не потребоваться. Алгоритмы также поддерживают согласованность кэша , когда несколько кэшей используются для одних и тех же данных, например, когда несколько серверов баз данных обновляют общий файл данных.
Политика
[ редактировать ]Аномалия Белади в алгоритмах замены страниц
[ редактировать ]Наиболее эффективным алгоритмом кэширования было бы удаление информации, которая не понадобится в течение длительного времени; это известно как оптимальный алгоритм Белади , оптимальная политика замены или алгоритм ясновидения . Поскольку, как правило, невозможно предсказать, как далеко в будущем понадобится информация, на практике это неосуществимо. Практический минимум можно рассчитать после экспериментов и сравнить эффективность выбранного алгоритма кэширования.
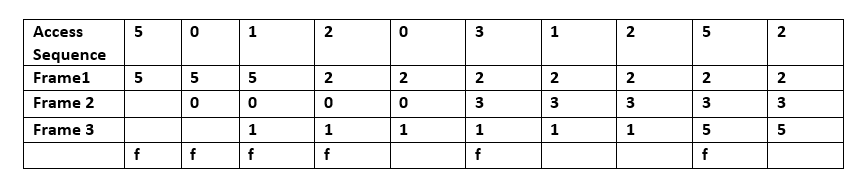
При возникновении ошибки страницы в памяти находится набор страниц. В этом примере доступ к последовательности 5, 0, 1 осуществляется в Кадре 1, Кадре 2 и Кадре 3 соответственно. Когда осуществляется доступ к 2, оно заменяет значение 5 (которое находится в кадре 1, предсказывая, что значение 5 не будет доступно в ближайшем будущем. Поскольку операционная система общего назначения не может предсказать, когда будет осуществлен доступ к 5, алгоритм Белади не может быть реализован там .
Случайная замена (RR)
[ редактировать ]Случайная замена выбирает элемент и отбрасывает его, чтобы освободить место при необходимости. Этот алгоритм не требует сохранения истории доступа. Он использовался в процессорах ARM из-за своей простоты. [3] и это позволяет эффективно стохастическое моделирование. [4]
Простые политики на основе очередей
[ редактировать ]«Первым пришел — первым обслужен» (FIFO)
[ редактировать ]При использовании этого алгоритма кэш ведет себя как очередь FIFO ; он удаляет блоки в том порядке, в котором они были добавлены, независимо от того, как часто и сколько раз к ним обращались раньше.
«Последним пришел — первым ушел» (LIFO) или «Первым пришел — последним ушел» (FILO)
[ редактировать ]Кэш ведет себя как стек и в отличие от очереди FIFO. Кэш сначала удаляет блок, добавленный последним, независимо от того, как часто и сколько раз к нему обращались раньше.
СИТО
[ редактировать ]SIEVE — это простой алгоритм вытеснения, разработанный специально для веб-кешей, таких как кеши «ключ-значение» и сети доставки контента. Он использует идею ленивого продвижения по службе и быстрого понижения в должности. [5] Таким образом, SIEVE не обновляет глобальную структуру данных при попадании в кэш и откладывает обновление до времени вытеснения; в то же время он быстро удаляет вновь вставленные объекты, поскольку рабочие нагрузки кэша имеют тенденцию показывать высокий коэффициент «одного попадания», и большинство новых объектов не имеют смысла хранить в кэше. SIEVE использует единую очередь FIFO и использует движущуюся руку для выбора объектов для выселения. Объекты в кэше имеют один бит метаданных, указывающий, был ли объект запрошен после того, как его допустили в кэш. Стрелка выселения указывает на хвост очереди в начале и со временем перемещается к ее началу. По сравнению с алгоритмом выселения CLOCK, сохраненные объекты в SIEVE остаются в старом положении. Поэтому новые объекты всегда находятся в начале, а старые — в хвосте. Когда рука движется к голове, новые объекты быстро вытесняются (быстрое понижение в должности), что является ключом к высокой эффективности алгоритма вытеснения SIEVE. SIEVE проще, чем LRU, но обеспечивает удивительно меньший коэффициент ошибок, чем LRU, наравне с современными алгоритмами вытеснения. Более того, при стационарных неравномерных нагрузках SIEVE лучше, чем существующие известные алгоритмы, включая LFU. [6]
Простые политики на основе давности
[ редактировать ]Наименее недавно использованный (LRU)
[ редактировать ]Сначала выбрасывайте наименее использованные предметы. Этот алгоритм требует отслеживания того, что и когда использовалось, что является обременительным. Он требует «биты возраста» для строк кэша и на их основе отслеживает наименее использованную строку кэша. Когда используется строка кэша, возраст других строк кэша изменяется. LRU — семейство алгоритмов кэширования , в которое входит 2Q Теодора Джонсона и Денниса Шаши. [7] и LRU/K Пэт О'Нил, Бетти О'Нил и Герхарда Вейкума. [8] Последовательность доступа для примера — ABCDEDF:

Когда ABCD установлен в блоках с порядковыми номерами (приращение 1 для каждого нового доступа) и осуществляется доступ к E, это промах и его необходимо установить в блок. В алгоритме LRU E заменит A, поскольку A имеет самый низкий ранг (A(0)). На предпоследнем этапе осуществляется доступ к D и обновляется порядковый номер. Затем осуществляется доступ к F, заменяющему B, который имел самый низкий ранг (B (1)).
С учетом времени, использовался реже всего
[ редактировать ]С учетом времени, реже всего использовавшийся (TLRU) [9] — это вариант LRU, предназначенный для случаев, когда содержимое кэша имеет допустимый срок службы. Алгоритм подходит для приложений сетевого кэширования, таких как информационно-ориентированные сети (ICN), сети доставки контента (CDN) и распределенные сети в целом. TLRU вводит термин: TTU (время использования), временную метку контента (или страницы), которая определяет время использования контента в зависимости от его местоположения и издателя контента. TTU предоставляет локальному администратору больше возможностей для управления сетевым хранилищем.
Когда поступает контент, на который распространяется действие TLRU, узел кэша вычисляет локальный TTU на основе TTU, назначенного издателем контента. Локальное значение TTU рассчитывается с помощью локально определенной функции. Когда вычисляется локальное значение TTU, замена контента выполняется для подмножества общего контента узла кэша. TLRU гарантирует, что менее популярный и недолговечный контент будет заменен входящим контентом.
Последние использованные (MRU)
[ редактировать ]В отличие от LRU, MRU сначала отбрасывает самые недавно использованные элементы. На 11-й конференции VLDB Чоу и ДеВитт заявили: «Когда файл многократно сканируется в [циклически последовательном] эталонном шаблоне, MRU является лучшим алгоритмом замены ». [10] Исследователи, выступавшие на 22-й конференции VLDB, отметили, что для шаблонов произвольного доступа и повторного сканирования больших наборов данных (также известных как шаблоны циклического доступа) алгоритмы кэширования MRU имеют больше совпадений, чем LRU, из-за их склонности сохранять более старые данные. [11] Алгоритмы MRU наиболее полезны в ситуациях, когда чем старше элемент, тем выше вероятность доступа к нему. Последовательность доступа для примера: ABCDECDB:
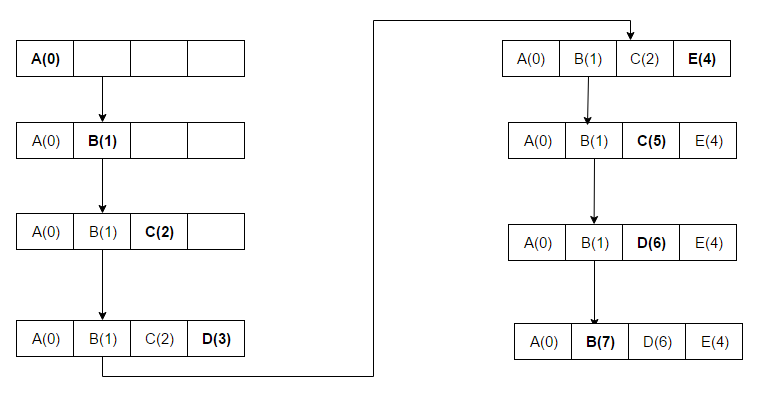
ABCD помещаются в кэш, поскольку там есть свободное место. При пятом доступе (E) блок, в котором содержался D, заменяется на E, поскольку этот блок использовался последним. При следующем доступе (к D) C заменяется, поскольку доступ к этому блоку был непосредственно перед D.
Сегментированный LRU (SLRU)
[ редактировать ]Кэш SLRU разделен на два сегмента: испытательный и защищенный. Строки в каждом сегменте упорядочены от наиболее частого к наименее последнему доступу. Данные о промахах добавляются в кэш в конце испытательного сегмента, к которому обращались в последний раз. Обращения удаляются из того места, где они находятся, и добавляются в конец защищенного сегмента, к которому обращались в последний раз; к линиям в защищенном сегменте обращались как минимум дважды. Защищенный сегмент конечен; миграция линии из испытательного сегмента в защищенный сегмент может вызвать миграцию линии LRU в защищенном сегменте на последний использованный конец испытательного сегмента, давая этой линии еще один шанс получить доступ перед ее заменой. Ограничение размера защищенного сегмента — это параметр SLRU, который варьируется в зависимости от шаблонов рабочей нагрузки ввода-вывода . Когда данные необходимо удалить из кэша, строки получаются из конца LRU испытательного сегмента. [12]
LRU-приближения
[ редактировать ]LRU может быть дорогим в кэшах с более высокой ассоциативностью . Практическое оборудование обычно использует приближение для достижения аналогичной производительности при более низкой стоимости оборудования.
Псевдо-LRU (PLRU)
[ редактировать ]Для кэшей ЦП с большой ассоциативностью (обычно > четырех способов) стоимость реализации LRU становится непомерно высокой. Во многих кэшах ЦП достаточно алгоритма, который почти всегда отбрасывает один из наименее используемых элементов; многие разработчики ЦП выбирают алгоритм PLRU, для работы которого требуется только один бит на элемент кэша. PLRU обычно имеет немного худший коэффициент промахов, немного лучшую задержку , потребляет немного меньше энергии, чем LRU, и имеет меньшие накладные расходы , чем LRU.
Биты работают как двоичное дерево однобитовых указателей, которые указывают на поддерево, которое использовалось реже. Следование по цепочке указателей до конечного узла идентифицирует кандидата на замену. При доступе все указатели в цепочке от листового узла пути доступа до корневого узла устанавливаются так, чтобы указывать на поддерево, которое не содержит путь доступа. Последовательность доступа в примере — ABCDE:
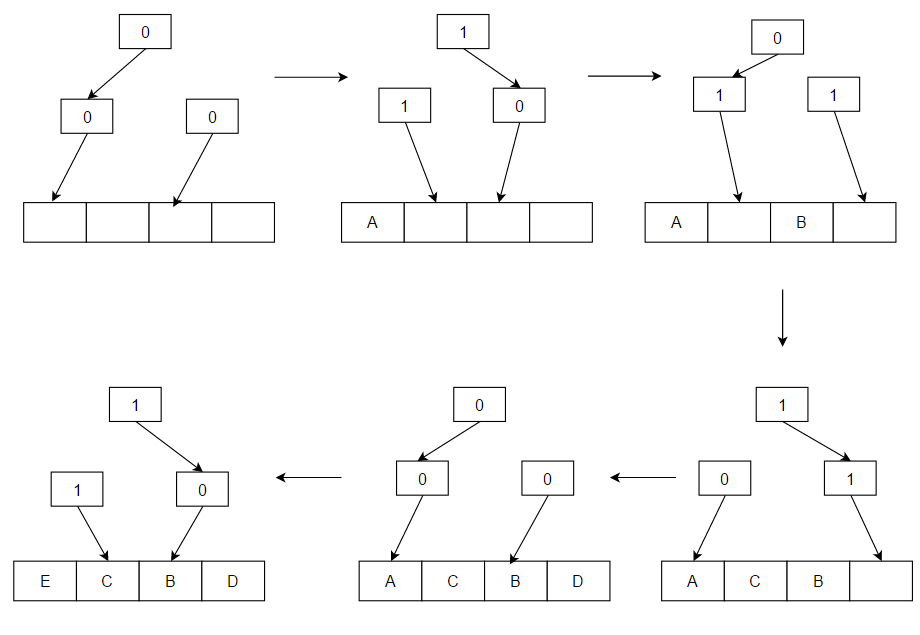
Когда есть доступ к значению (например, A) и его нет в кеше, оно загружается из памяти и помещается в блок, куда указывают стрелки в примере. После того, как этот блок установлен, стрелки переворачиваются в противоположном направлении. Размещаются A, B, C и D; E заменяет A по мере заполнения кэша, потому что именно туда указывали стрелки, а стрелки, ведущие к A, переворачиваются и указывают в противоположном направлении (к B, блоку, который будет заменен при следующем промахе кэша).
Часы-Про
[ редактировать ]Алгоритм LRU не может быть реализован на критическом пути компьютерных систем, таких как операционные системы , из-за его высоких накладных расходов; Вместо этого обычно используется Clock , приближенная версия LRU. Clock-Pro — это аппроксимация LIRS для недорогой реализации в системах. [13] Clock-Pro имеет базовую структуру Clock с тремя преимуществами. Он имеет три «стрелки часов» (в отличие от единственной «стрелки» Clock) и может приблизительно измерять расстояние повторного использования доступа к данным. с однократным доступом или низкой локальностью Как и LIRS, он может быстро удалять элементы данных . Clock-Pro так же сложен, как и Clock, и его легко внедрить при небольших затратах. Реализация замены буферного кэша в версии Linux 2017 сочетает в себе LRU и Clock-Pro. [14] [15]
Простые политики на основе частоты
[ редактировать ]Наименее часто используемый (LFU)
[ редактировать ]Алгоритм LFU подсчитывает, как часто нужен предмет; те, которые используются реже, выбрасываются в первую очередь. Это похоже на LRU, за исключением того, что сохраняется количество обращений к блоку, а не то, как недавно. При выполнении последовательности доступа блок, который использовался меньше всего раз, будет удален из кэша.
Наименее часто использовавшийся в последнее время (LFRU)
[ редактировать ]Наименее часто используемый в последнее время (LFRU) [16] Алгоритм сочетает в себе преимущества LFU и LRU. LFRU подходит для приложений сетевого кэша, таких как ICN , CDN и распределенных сетей в целом. В LFRU кеш разделен на два раздела: привилегированный и непривилегированный. Привилегированный раздел защищен, и, если контент популярен, он помещается в привилегированный раздел. При замене привилегированного раздела LFRU удаляет содержимое из непривилегированного раздела; перемещает содержимое из привилегированного раздела в непривилегированный раздел и вставляет новое содержимое в привилегированный раздел. LRU используется для привилегированного раздела и приближенный алгоритм LFU (ALFU) для непривилегированного раздела.
LFU с динамическим старением (LFUDA)
[ редактировать ]Вариант LFU с динамическим старением (LFUDA) использует динамическое старение для учета изменений в наборе популярных объектов; он добавляет коэффициент возраста кэша к счетчику ссылок, когда новый объект добавляется в кэш или при повторной ссылке на существующий объект. LFUDA увеличивает возраст кэша при удалении блоков, устанавливая для него значение ключа вытесненного объекта, а возраст кэша всегда меньше или равен минимальному значению ключа в кэше. [17] Если к объекту в прошлом часто обращались и он стал непопулярным, он останется в кеше в течение длительного времени (предотвращая замену его новыми или менее популярными объектами). Динамическое старение уменьшает количество таких объектов, делая их пригодными для замены, а LFUDA уменьшает загрязнение кэша, вызванное LFU, когда кэш мал.
S3-ФИФО
[ редактировать ]Это новый алгоритм вытеснения, разработанный в 2023 году. По сравнению с существующими алгоритмами, которые в основном основаны на LRU (наименее использованном в последнее время), S3-FIFO использует только три очереди FIFO: небольшую очередь, занимающую 10% пространства кэша, основную очередь. который использует 90% пространства кэша, и призрачную очередь, в которой хранятся только метаданные объекта. Небольшая очередь используется для фильтрации «чудес с одним попаданием» (объектов, доступ к которым осуществляется только один раз за короткий промежуток времени); основная очередь используется для хранения популярных объектов и использует повторную вставку для сохранения их в кеше; а призрачная очередь используется для перехвата потенциально популярных объектов, которые исключаются из небольшой очереди. Объекты сначала вставляются в малую очередь (если они не найдены в призрачной очереди, в противном случае вставляются в основную очередь); при исключении из малой очереди, если объект был запрошен, он снова вставляется в основную очередь, в противном случае он вытесняется, а метаданные отслеживаются в призрачной очереди. [18]
S3-FIFO демонстрирует, что очередей FIFO достаточно для разработки эффективных и масштабируемых алгоритмов вытеснения. По сравнению с алгоритмами LRU и LRU, S3-FIFO может обеспечить в 6 раз более высокую пропускную способность. Кроме того, при рабочих нагрузках веб-кэша S3-FIFO достигает самого низкого коэффициента ошибок среди 11 современных алгоритмов, с которыми сравнивали авторы. [19]
Политика в стиле RRIP
[ редактировать ]Политики в стиле RRIP являются основой для других политик замены кэша, включая Hawkeye. [20]
Прогнозирование интервала повторного отсчета (RRIP)
[ редактировать ]ремень [21] — это гибкая политика, предложенная Intel , которая пытается обеспечить хорошую устойчивость к сканированию, позволяя при этом удалять старые строки кэша, которые не использовались повторно. Все строки кэша имеют значение прогнозирования, RRPV (значение прогнозирования повторной ссылки), которое должно коррелировать с тем, когда ожидается повторное использование строки. RRPV обычно бывает высоким при введении; если строка в ближайшее время не будет повторно использована, она будет удалена, чтобы предотвратить заполнение кэша при сканировании (большие объемы данных используются только один раз). Когда строка кэша используется повторно, RRPV устанавливается на ноль, указывая, что строка была повторно использована один раз и, вероятно, будет повторно использована снова.
При промахе в кэше строка с RRPV, равным максимально возможному RRPV, вытесняется; с 3-битными значениями, строка с RRPV, равным 2 3 - 1 = 7 выселено. Если ни одна строка не имеет этого значения, все RRPV в наборе увеличиваются на 1, пока одна из них не достигнет этого значения. Нужен тай-брейк, и обычно это первая линия слева. Увеличение необходимо для того, чтобы гарантировать, что старые линии устарели должным образом и будут выселены, если они не будут использоваться повторно.
Статический РРИП (СРРИП)
[ редактировать ]SRRIP вставляет строки со значением RRPV maxRRPV; только что вставленная строка с наибольшей вероятностью будет удалена из-за промаха в кэше.
Бимодальный РРИП (БРРИП)
[ редактировать ]SRRIP обычно работает хорошо, но ухудшается, когда рабочий набор намного превышает размер кэша, и вызывает перегрузку кэша . Это исправляется путем вставки строк со значением RRPV maxRRPV большую часть времени, а также вставкой строк со значением RRPV maxRRPV - 1 случайным образом с низкой вероятностью. Это приводит к тому, что некоторые строки «застревают» в кеше и помогают предотвратить перегрузку. Однако BRRIP снижает производительность при доступе без перегрузки. SRRIP работает лучше всего, когда рабочий набор меньше кэша, а BRRIP работает лучше всего, когда рабочий набор больше кэша.
Динамический RRIP (DRRIP)
[ редактировать ]ДРРИП [21] использует набор дуэлей [22] чтобы выбрать, использовать ли SRRIP или BRRIP. Он выделяет несколько наборов (обычно 32) для использования SRRIP и еще несколько для использования BRRIP, а также использует счетчик политик, который отслеживает производительность набора, чтобы определить, какая политика будет использоваться остальной частью кэша.
Политики, аппроксимирующие алгоритм Белади
[ редактировать ]Алгоритм Белади является оптимальной политикой замены кэша, но он требует знания будущего, чтобы исключить строки, которые будут повторно использоваться в будущем. Был предложен ряд политик замены, которые пытаются предсказать будущие расстояния повторного использования на основе прошлых моделей доступа. [23] позволяя им приблизиться к оптимальной политике замены. Некоторые из наиболее эффективных политик замены кэша пытаются имитировать алгоритм Белади.
Соколиный глаз
[ редактировать ]Соколиный глаз [20] пытается эмулировать алгоритм Белади, используя прошлые обращения к ПК, чтобы предсказать, будут ли производимые им доступы генерировать дружественные к кешу (используются позже) или нежелательные к кешу доступы (не используются позже). Он выбирает несколько наборов невыровненных кэшей, использует историю длины и эмулирует алгоритм Белади при этих доступах. Это позволяет политике определять, какие строки следует кэшировать, а какие нет, предсказывая, является ли инструкция благоприятной для кэширования или нежелательной. Эти данные затем передаются в RRIP; доступ из инструкций, дружественных к кэшу, имеет более низкое значение RRPV (вероятно, будет исключен позже), а доступ из инструкций, не относящихся к кэшу, имеет более высокое значение RRPV (вероятно, будет исключен раньше). Серверная часть RRIP принимает решения о выселении. Выборочный кеш и генератор OPT устанавливают начальное значение RRPV для вставленных строк кэша. Hawkeye выиграл чемпионат по кэшированию CRC2 в 2017 году. [24] и Гармония [25] является расширением Hawkeye, которое повышает производительность предварительной выборки.

Сойка-пересмешница
[ редактировать ]Сойка-пересмешница [26] пытается улучшить Соколиного Глаза несколькими способами. Он отбрасывает двоичное предсказание, позволяя принимать более детальные решения о том, какие строки кэша следует вытеснить, и оставляет решение о том, какую строку кэша вытеснить, когда будет доступно больше информации.
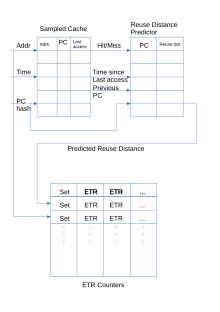
Сойка-пересмешница хранит выборочный кеш уникальных обращений, компьютеров, которые их произвели, и их временных меток. При повторном доступе к строке в выборочном кэше разница во времени будет отправлена в предиктор расстояния повторного использования. RDP использует обучение временной разнице, [27] где новое значение RDP будет увеличено или уменьшено на небольшое число, чтобы компенсировать выбросы; число рассчитывается как . Если значение не было инициализировано, наблюдаемое расстояние повторного использования вставляется напрямую. Если выборочный кеш заполнен и строку необходимо отбросить, RDP получает указание, что компьютер, который последним обращался к нему, осуществляет потоковый доступ.

При доступе или вставке расчетное время повторного использования (ETR) для этой линии обновляется, чтобы отразить прогнозируемое расстояние повторного использования. При промахе в кэше строка с наибольшим значением ETR удаляется. Сойка-пересмешница имеет результаты, близкие к оптимальному алгоритму Белади.
Политика машинного обучения
[ редактировать ]Ряд политик пытались использовать перцептроны , цепи Маркова или другие типы машинного обучения, чтобы предсказать, какую строку исключить. [28] [29] Для замены кэша также существуют алгоритмы расширенного обучения . [30] [31]
Другие политики
[ редактировать ]Набор с низкой периодичностью между ссылками (LIRS)
[ редактировать ]LIRS — это алгоритм замены страниц с более высокой производительностью, чем LRU и другие, более новые алгоритмы замены. Расстояние повторного использования — это показатель динамического ранжирования страниц, к которым осуществляется доступ, для принятия решения о замене. [32] LIRS устраняет ограничения LRU, используя новизну для оценки новизны между ссылками (IRR) для принятия решения о замене.

На диаграмме X указывает, что доступ к блоку осуществляется в определенное время. Если доступ к блоку A1 осуществляется в момент времени 1, его актуальность будет равна 0; это блок, к которому осуществляется первый доступ, и IRR будет равен 1, поскольку он прогнозирует, что к A1 будет снова осуществлен доступ во время 3. Во время 2, поскольку осуществляется доступ к A4, давность станет 0 для A4 и 1 для A1; A4 — это объект, к которому последний раз обращались, и IRR станет равным 4. В момент 10 алгоритм LIRS будет иметь два набора: набор LIR = {A1, A2} и набор HIR = {A3, A4, A5}. В момент времени 10, если есть доступ к А4, происходит промах; LIRS исключит A5 вместо A2 из-за его большей давности.
Адаптивный кэш замены
[ редактировать ]Адаптивный кэш замены (ARC) постоянно балансирует между LRU и LFU для улучшения совокупного результата. [33] Он улучшает SLRU, используя информацию о недавно удаленных элементах кэша, чтобы настроить размер защищенных и пробных сегментов, чтобы наилучшим образом использовать доступное пространство кэша. [34]
Часы с адаптивной заменой
[ редактировать ]Часы с адаптивной заменой (CAR) сочетают в себе преимущества ARC и Clock . CAR работает сравнимо с ARC и превосходит LRU и Clock. Как и ARC, CAR является самонастраивающимся и не требует никаких параметров, указываемых пользователем.
Многохвостый
[ редактировать ]Алгоритм многоочередной замены (MQ) был разработан для повышения производительности буферного кэша второго уровня, такого как буферный кэш сервера, и был представлен в статье Чжоу, Филбина и Ли. [35] Кэш MQ содержит m очередей LRU: Q 0 , Q 1 , ..., Q m -1 . Значение m представляет собой иерархию, основанную на времени жизни всех блоков в этой очереди. [36]

Паннье
[ редактировать ]Паннье [37] — это механизм флэш-кэширования на основе контейнеров, который идентифицирует контейнеры, блоки которых имеют переменные шаблоны доступа. Pannier имеет структуру очереди выживания на основе приоритетной очереди, позволяющую ранжировать контейнеры на основе времени их выживания, которое пропорционально актуальным данным в контейнере.
Статический анализ
[ редактировать ]Статический анализ определяет, какие обращения являются попаданиями или промахами в кэш, чтобы указать наихудшее время выполнения программы. [38] Подход к анализу свойств кэшей LRU заключается в присвоении каждому блоку в кэше «возраста» (0 для самого последнего использованного) и интервалов вычисления для возможного возраста. [39] Этот анализ можно уточнить, чтобы выявить случаи, когда одна и та же точка программы доступна по путям, которые приводят к промахам или попаданиям. [40] Эффективный анализ может быть получен путем абстрагирования наборов состояний кэша с помощью антицепей , которые представлены компактными диаграммами двоичных решений . [41]
Статический анализ LRU не распространяется на политики псевдо-LRU. Согласно теории сложности вычислений , проблемы статического анализа, возникающие при использовании псевдо-LRU и FIFO, относятся к более высоким классам сложности, чем проблемы для LRU. [42] [43]
См. также
[ редактировать ]Ссылки
[ редактировать ]- ^ Jump up to: а б Алан Джей Смит. «Проектирование кэш-памяти ЦП». Учеб. IEEE ТЕНКОН, 1987. [1]
- ^ Пол В. Болотов. «Функциональные принципы кэш-памяти». Архивировано 14 марта 2012 года в Wayback Machine . 2007.
- ^ Руководство программиста серии ARM Cortex-R
- ^ Эффективный алгоритм моделирования кэша политики случайной замены [2]
- ^ Ян, Цзюньчэн; Цю, Зиюэ; Чжан, Ячжуо; Юэ, Яо; Рашми, К.В. (22 июня 2023 г.). «FIFO может быть лучше, чем LRU: сила ленивого повышения и быстрого понижения в должности» . Материалы 19-го семинара по актуальным темам операционных систем . ХОТОС '23. Нью-Йорк, штат Нью-Йорк, США: Ассоциация вычислительной техники. стр. 70–79. дои : 10.1145/3593856.3595887 . ISBN 979-8-4007-0195-5 .
- ^ Чжан, Ячжуо; Ян, Цзюньчэн; Юэ, Яо; Вигфуссон, Имир; Рашми, КВ (2024). {SIEVE} проще, чем {LRU}: эффективный алгоритм вытеснения веб-кешей {под ключ} . стр. 1229–1246. ISBN 978-1-939133-39-7 .
- ^ Джонсон, Теодор; Шаша, Деннис (12 сентября 1994 г.). «2Q: Алгоритм замены высокопроизводительного управления буфером с низкими накладными расходами» (PDF) . Материалы 20-й Международной конференции по очень большим базам данных . ВЛДБ '94. Сан-Франциско, Калифорния: Morgan Kaufmann Publishers Inc.: 439–450. ISBN 978-1-55860-153-6 . S2CID 6259428 .
- ^ О'Нил, Элизабет Дж .; О'Нил, Патрик Э.; Вейкум, Герхард (1993). «Алгоритм замены страниц LRU-K для буферизации диска базы данных». Материалы международной конференции ACM SIGMOD 1993 года по управлению данными - SIGMOD '93 . Нью-Йорк, штат Нью-Йорк, США: ACM. стр. 297–306. CiteSeerX 10.1.1.102.8240 . дои : 10.1145/170035.170081 . ISBN 978-0-89791-592-2 . S2CID 207177617 .
- ^ Билал, Мухаммед; и др. (2014). «Политика управления кэшем с учетом времени последнего использования (TLRU) в ICN». 16-я Международная конференция по передовым коммуникационным технологиям . стр. 528–532. arXiv : 1801.00390 . Бибкод : 2018arXiv180100390B . дои : 10.1109/ICACT.2014.6779016 . ISBN 978-89-968650-3-2 . S2CID 830503 .
- ^ Хун-Тай Чоу и Дэвид Дж. ДеВитт. Оценка стратегий управления буфером для систем реляционных баз данных. ВЛДБ, 1985.
- ^ Шауль Дар, Майкл Дж. Франклин, Бьорн Тор Йонссон, Дивеш Шривастава и Майкл Тан. Семантическое кэширование и замена данных. ВЛДБ, 1996.
- ^ Рамакришна Каредла, Дж. Спенсер Лав и Брэдли Г. Уэрри. Стратегии кэширования для повышения производительности дисковой системы. В компьютере , 1994.
- ^ Цзян, Сун; Чен, Фэн; Чжан, Сяодун (2005). «CLOCK-Pro: эффективное улучшение замены ЧАСОВ» (PDF) . Материалы ежегодной конференции USENIX. Ежегодная техническая конференция . Ассоциация USENIX: 323–336.
- ^ «Управление памятью Linux: дизайн замены страниц» . 30 декабря 2017 года . Проверено 30 июня 2020 г.
- ^ «Реализация замены страниц CLOCK-Pro» . LWN.net . 16 августа 2005 г. Проверено 30 июня 2020 г.
- ^ Билал, Мухаммед; и др. (2017). «Схема управления кэшем для эффективного удаления и репликации контента в сетях кэша». Доступ IEEE . 5 : 1692–1701. arXiv : 1702.04078 . Бибкод : 2017arXiv170204078B . дои : 10.1109/ACCESS.2017.2669344 . S2CID 14517299 .
- ^ Джаярекха, П.; Наир, Т (2010). «Подход к адаптивной динамической замене для многоадресной системы кэш-памяти префиксов с учетом популярности». arXiv : 1001.4135 [ cs.MM ].
- ^ Ян, Цзюньчэн; Чжан, Ячжуо; Цю, Зиюэ; Юэ, Яо; Винаяк, Рашми (23 октября 2023 г.). «Очереди FIFO — это все, что вам нужно для вытеснения кэша» . Материалы 29-го симпозиума по принципам работы операционных систем . СОСП '23. Нью-Йорк, штат Нью-Йорк, США: Ассоциация вычислительной техники. стр. 130–149. дои : 10.1145/3600006.3613147 . ISBN 979-8-4007-0229-7 .
- ^ Ян, Цзюньчэн; Чжан, Ячжуо; Цю, Зиюэ; Юэ, Яо; Винаяк, Рашми (23 октября 2023 г.). «Очереди FIFO — это все, что вам нужно для вытеснения кэша» . Материалы 29-го симпозиума по принципам работы операционных систем . СОСП '23. Нью-Йорк, штат Нью-Йорк, США: Ассоциация вычислительной техники. стр. 130–149. дои : 10.1145/3600006.3613147 . ISBN 979-8-4007-0229-7 .
- ^ Jump up to: а б Джайн, Аканкша; Лин, Кальвин (июнь 2016 г.). «Назад в будущее: использование алгоритма Белади для улучшенной замены кэша» . 43-й ежегодный международный симпозиум ACM/IEEE по компьютерной архитектуре (ISCA) , 2016 г. стр. 78–89. дои : 10.1109/ISCA.2016.17 . ISBN 978-1-4673-8947-1 .
- ^ Jump up to: а б Джалил, Аамер; Теобальд, Кевин Б.; Стили, Саймон С.; Эмер, Джоэл (19 июня 2010 г.). «Высокопроизводительная замена кэша с использованием прогнозирования интервала повторного обращения (RRIP)» . Материалы 37-го ежегодного международного симпозиума по компьютерной архитектуре . ИСКА '10. Нью-Йорк, штат Нью-Йорк, США: Ассоциация вычислительной техники. стр. 60–71. дои : 10.1145/1815961.1815971 . ISBN 978-1-4503-0053-7 . S2CID 856628 .
- ^ Куреши, Мойнуддин К.; Джалил, Аамер; Патт, Йель Н.; Стили, Саймон С.; Эмер, Джоэл (9 июня 2007 г.). «Адаптивные политики вставки для высокопроизводительного кэширования» . Новости компьютерной архитектуры ACM SIGARCH . 35 (2): 381–391. дои : 10.1145/1273440.1250709 . ISSN 0163-5964 .
- ^ Керамидас, Георгиос; Петуменос, Павлос; Каширас, Стефанос (2007). «Замена кэша на основе прогнозирования расстояния повторного использования» . 2007 25-я Международная конференция по компьютерному дизайну . стр. 245–250. дои : 10.1109/ICCD.2007.4601909 . ISBN 978-1-4244-1257-0 . S2CID 14260179 .
- ^ «ВТОРОЙ ЧЕМПИОНАТ ПО ЗАМЕНЕ КЭША – проводится совместно с ISCA, июнь 2017 г.» . crc2.ece.tamu.edu . Проверено 24 марта 2022 г.
- ^ Джайн, Аканкша; Лин, Кальвин (июнь 2018 г.). «Переосмысление алгоритма Белади для поддержки предварительной выборки» . ACM/IEEE, 2018 г. 45-й ежегодный международный симпозиум по компьютерной архитектуре (ISCA ) стр. 110–123. дои : 10.1109/ISCA.2018.00020 . ISBN 978-1-5386-5984-7 . S2CID 5079813 .
- ^ Шах, Ишан; Джайн, Аканкша; Лин, Кальвин (апрель 2022 г.). «Эффективная мимикрия политики Белади MIN». HPCA .
- ^ Саттон, Ричард С. (1 августа 1988 г.). «Учимся прогнозировать методами временных разностей» . Машинное обучение . 3 (1): 9–44. дои : 10.1007/BF00115009 . ISSN 1573-0565 . S2CID 207771194 .
- ^ Лю, Эван; Хашеми, Милад; Сверски, Кевин; Ранганатан, Партасарати; Ан, Джунван (21 ноября 2020 г.). «Подход к имитационному обучению для замены кэша» . Международная конференция по машинному обучению . ПМЛР: 6237–6247. arXiv : 2006.16239 .
- ^ Хименес, Дэниел А.; Теран, Эльвира (14 октября 2017 г.). «Многоперспективное предсказание повторного использования» . Материалы 50-го ежегодного международного симпозиума IEEE/ACM по микроархитектуре . Нью-Йорк, штат Нью-Йорк, США: ACM. стр. 436–448. дои : 10.1145/3123939.3123942 . ISBN 9781450349529 . S2CID 1811177 .
- ^ Ликурис, Тодорис; Васильвицкий, Сергей (7 июля 2021 г.). «Конкурентное кэширование с помощью машинного обучения» . Журнал АКМ . 68 (4): 1–25. arXiv : 1802.05399 . дои : 10.1145/3447579 . eISSN 1557-735X . ISSN 0004-5411 . S2CID 3625405 .
- ^ Митценмахер, Михаэль ; Васильвицкий, Сергей (31 декабря 2020 г.). «Алгоритмы с предсказаниями». Помимо анализа алгоритмов наихудшего случая . Издательство Кембриджского университета. стр. 646–662. arXiv : 2006.09123 . дои : 10.1017/9781108637435.037 . ISBN 9781108637435 .
- ^ Цзян, Сун; Чжан, Сяодун (июнь 2002 г.). «LIRS: эффективная политика замены набора с низкой периодичностью между ссылками для повышения производительности буферного кэша» (PDF) . Обзор оценки производительности ACM Sigmetrics . 30 (1). Ассоциация вычислительной техники: 31–42. дои : 10.1145/511399.511340 . ISSN 0163-5999 .
- ^ Нимрод Мегиддо и Дхармендра С. Модха. ARC: самонастраивающийся кэш замены с низкими издержками. ФАСТ, 2003.
- ^ «Некоторые сведения о кеше чтения ZFS — или: ARC — c0t0d0s0.org» . Архивировано из оригинала 24 февраля 2009 года.
- ^ Юаньюань Чжоу , Джеймс Филбин и Кай Ли. Алгоритм многоочередной замены буферных кэшей второго уровня. УСЕНИКС, 2002.
- ^ Эдуардо Пиньейру, Рикардо Бьянкини, Методы энергосбережения для серверов на базе дисковых массивов, Материалы 18-й ежегодной международной конференции по суперкомпьютерам, 26 июня - 1 июля 2004 г., Мало, Франция
- ^ Ченг Ли, Филип Шилейн, Фред Дуглис и Грант Уоллес. Pannier: контейнерный флэш-кэш для составных объектов. Промежуточное ПО ACM/IFIP/USENIX, 2015 г.
- ^ Кристиан Фердинанд; Рейнхард Вильгельм (1999). «Эффективное и точное прогнозирование поведения кэша для систем реального времени». Система реального времени . 17 (2–3): 131–181. дои : 10.1023/А:1008186323068 . S2CID 28282721 .
- ^ Кристиан Фердинанд; Флориан Мартин; Рейнхард Вильгельм; Мартин Альт (ноябрь 1999 г.). «Прогнозирование поведения кэша посредством абстрактной интерпретации». Наука компьютерного программирования . 35 (2–3). Спрингер: 163–189. дои : 10.1016/S0167-6423(99)00010-6 .
- ^ Валентин Тузо; Клэр Майза; Дэвид Моннио; Ян Рейнеке (2017). «Обнаружение неопределенности для эффективного точного анализа кэша». Компьютерная проверка (2) . arXiv : 1709.10008 . doi : 10.1007/978-3-319-63390-9_2 (неактивен 3 мая 2024 г.).
{{cite conference}}: CS1 maint: DOI неактивен по состоянию на май 2024 г. ( ссылка ) - ^ Валентин Тузо; Клэр Майза; Дэвид Моннио; Ян Рейнеке (2019). «Быстрый и точный анализ кэшей LRU». Учеб. Программа {ACM}. Ланг . 3 (ПОПЛ): 54:1–54:29. arXiv : 1811.01670 .
- ^ Дэвид Моннио; Валентин Тузо (11 ноября 2019 г.). «О сложности анализа кэша для разных политик замены» . Журнал АКМ . 66 (6). Ассоциация вычислительной техники: 1–22. дои : 10.1145/3366018 . S2CID 53219937 .
- ^ Дэвид Моннио (13 мая 2022 г.). «Разрыв в сложности статического анализа доступа к кэшу возрастает, если добавляются вызовы процедур» . Формальные методы проектирования систем . 59 (1–3). Спрингер Верлаг: 1–20. arXiv : 2201.13056 . doi : 10.1007/s10703-022-00392-w (неактивен 3 мая 2024 г.). S2CID 246430884 .
{{cite journal}}: CS1 maint: DOI неактивен по состоянию на май 2024 г. ( ссылка )