Теория сложности вычислений
В теоретической информатике и математике теория сложности вычислений фокусируется на классификации вычислительных задач в соответствии с использованием ими ресурсов и связывании этих классов друг с другом. Вычислительная задача – это задача, решаемая компьютером. Вычислительная задача решается путем механического применения математических шагов, таких как алгоритм .
Проблема считается по своей сути сложной, если ее решение требует значительных ресурсов, независимо от используемого алгоритма. Теория формализует эту интуицию, вводя математические модели вычислений для изучения этих проблем и количественно оценивая их вычислительную сложность , то есть количество ресурсов, необходимых для их решения, таких как время и память. Также используются другие меры сложности, такие как объем связи (используется в сложности связи ), количество вентилей в схеме (используется в сложности схемы ) и количество процессоров (используется в параллельных вычислениях ). Одна из задач теории сложности вычислений — определить практические пределы того, что компьютеры могут и чего не могут делать. Проблема P против NP , одна из семи задач Премии тысячелетия . [1] является частью области вычислительной сложности.
Тесно связанными областями теоретической информатики являются анализ алгоритмов и теория вычислимости . Ключевое различие между анализом алгоритмов и теорией сложности вычислений состоит в том, что первая посвящена анализу количества ресурсов, необходимых конкретному алгоритму для решения проблемы, тогда как вторая задает более общий вопрос обо всех возможных алгоритмах, которые можно использовать для решения задачи. решить ту же проблему. Точнее, теория сложности вычислений пытается классифицировать проблемы, которые можно или невозможно решить с помощью соответствующим образом ограниченных ресурсов. В свою очередь, наложение ограничений на доступные ресурсы — это то, что отличает сложность вычислений от теории вычислимости: последняя теория спрашивает, какие типы проблем в принципе могут быть решены алгоритмически.
Вычислительные задачи [ править ]
Проблемные случаи [ править ]
можно Вычислительную задачу рассматривать как бесконечную совокупность примеров вместе с набором (возможно, пустым) решений для каждого экземпляра. Входная строка вычислительной задачи называется экземпляром задачи, и ее не следует путать с самой задачей. В теории сложности вычислений проблема относится к абстрактному вопросу, который необходимо решить. Напротив, примером этой проблемы является довольно конкретное высказывание, которое может служить входными данными для решения проблемы. Например, рассмотрим проблему проверки простоты . Экземпляром является число (например, 15), и решением является «да», если число простое, и «нет» в противном случае (в этом случае 15 не является простым и ответ «нет»). Другими словами, экземпляр — это конкретный вход в задачу, а решение — это результат, соответствующий данному входу.
Чтобы еще больше подчеркнуть разницу между задачей и примером, рассмотрим следующий вариант решения задачи о коммивояжере : существует ли маршрут длиной не более 2000 километров, проходящий через все 15 крупнейших городов Германии? Количественный ответ на этот конкретный пример проблемы малопригоден для решения других случаев проблемы, таких как запрос на поездку туда и обратно через все объекты Милана , общая длина которых составляет не более 10 км. По этой причине теория сложности рассматривает вычислительные проблемы, а не конкретные экземпляры проблем.
Представление примеров проблем [ править ]
При рассмотрении вычислительных задач экземпляром задачи является строка в алфавите . Обычно в качестве алфавита принимается двоичный алфавит (т. е. набор {0,1}), и, таким образом, строки представляют собой битовые строки . Как и в реальном компьютере , математические объекты, отличные от битовых строк, должны быть соответствующим образом закодированы. Например, целые числа могут быть представлены в двоичной записи , а графы могут быть закодированы непосредственно с помощью их матриц смежности или путем кодирования их списков смежности в двоичном формате.
Несмотря на то, что некоторые доказательства теорем теории сложности регулярно предполагают некоторый конкретный выбор входной кодировки, мы стараемся сохранить обсуждение достаточно абстрактным, чтобы быть независимым от выбора кодировки. Этого можно достичь, гарантируя, что различные представления могут быть эффективно преобразованы друг в друга.
как формальные Проблемы принятия решений языки

Проблемы принятия решений являются одним из центральных объектов исследования в теории сложности вычислений. Проблема принятия решения — это особый тип вычислительной задачи, ответом на которую является либо да , либо нет , либо попеременно либо 1, либо 0. Задачу принятия решения можно рассматривать как формальный язык , где членами языка являются экземпляры, вывод которых — да, и не-члены — это те экземпляры, вывод которых равен «нет». Цель состоит в том, чтобы с помощью алгоритма решить , является ли данная входная строка членом рассматриваемого формального языка. Если алгоритм, решающий эту задачу, возвращает ответ «да» , говорят, что алгоритм принимает входную строку, в противном случае говорят, что он отклоняет входные данные.
Примером проблемы принятия решения является следующий. Входные данные — произвольный граф . Задача состоит в том, чтобы решить, связен данный граф или нет. Формальный язык, связанный с этой проблемой решения, тогда представляет собой набор всех связанных графов — чтобы получить точное определение этого языка, нужно решить, как графы кодируются как двоичные строки.
Функциональные проблемы [ править ]
Функциональная задача один выходной результат ( суммарной функции — это вычислительная задача, в которой для каждого входного параметра ожидается ), но выходной результат более сложен, чем в задаче принятия решения , то есть выходной сигнал — это не просто «да» или «нет». Яркие примеры включают задачу коммивояжера и задачу факторизации целых чисел .
Соблазнительно думать, что понятие функциональных проблем гораздо богаче, чем понятие проблем принятия решений. Однако на самом деле это не так, поскольку функциональные проблемы можно преобразовать в проблемы принятия решений. Например, умножение двух целых чисел можно выразить как набор троек ( a , b , c ) таких, что выполняется соотношение a × b = c . Решение о том, является ли данная тройка членом этого множества, соответствует решению задачи умножения двух чисел.
Измерение размера экземпляра [ править ]
Чтобы измерить сложность решения вычислительной задачи, можно посмотреть, сколько времени потребуется лучшему алгоритму для решения проблемы. Однако время работы в целом может зависеть от экземпляра. В частности, для решения более крупных случаев потребуется больше времени. Таким образом, время, необходимое для решения проблемы (или необходимое пространство, или любая мера сложности), рассчитывается как функция размера экземпляра. Обычно это размер входных данных в битах. Теория сложности интересуется тем, как алгоритмы масштабируются с увеличением размера входных данных. Например, в задаче определения связности графа, насколько больше времени требуется для решения задачи для графа с 2 n вершинами по сравнению со временем, затрачиваемым на решение задачи для графа с n вершинами?
Если входной размер равен n , затраченное время можно выразить как функцию от n . Поскольку время, затраченное на разные входные данные одного и того же размера, может быть разным, временная сложность T( n ) в худшем случае определяется как максимальное время, затраченное на все входные данные размера n . Если T( n ) является полиномом от n , то алгоритм называется алгоритмом с полиномиальным временем . Тезис Кобэма утверждает, что проблему можно решить с возможным количеством ресурсов, если она допускает алгоритм с полиномиальным временем.
Модели машин сложности меры и
Машина Тьюринга [ править ]

Машина Тьюринга — это математическая модель вычислительной машины общего назначения. Это теоретическое устройство, которое манипулирует символами, содержащимися на полоске ленты. Машины Тьюринга задуманы не как практическая вычислительная технология, а скорее как общая модель вычислительной машины — от продвинутого суперкомпьютера до математика с карандашом и бумагой. Считается, что если проблему можно решить с помощью алгоритма, то существует машина Тьюринга, решающая эту проблему. Действительно, это утверждение тезиса Чёрча-Тьюринга . Более того, известно, что все, что можно вычислить на других известных нам сегодня моделях вычислений, таких как машина с оперативной памятью , игра жизни Конвея , клеточные автоматы , лямбда-исчисление или любой язык программирования, можно вычислить на машине Тьюринга. Поскольку машины Тьюринга легко анализировать математически и считаются столь же мощными, как и любая другая модель вычислений, машина Тьюринга является наиболее часто используемой моделью в теории сложности.
Для определения классов сложности используются многие типы машин Тьюринга, такие как детерминированные машины Тьюринга , вероятностные машины Тьюринга , недетерминированные машины Тьюринга , квантовые машины Тьюринга , симметричные машины Тьюринга и альтернативные машины Тьюринга . В принципе, все они одинаково сильны, но когда ресурсы (например, время или пространство) ограничены, некоторые из них могут быть более мощными, чем другие.
Детерминированная машина Тьюринга — это самая простая машина Тьюринга, которая использует фиксированный набор правил для определения своих будущих действий. Вероятностная машина Тьюринга — это детерминированная машина Тьюринга с дополнительным запасом случайных битов. Способность принимать вероятностные решения часто помогает алгоритмам решать проблемы более эффективно. Алгоритмы, использующие случайные биты, называются рандомизированными алгоритмами . Недетерминированная машина Тьюринга — это детерминированная машина Тьюринга с дополнительной функцией недетерминизма, которая позволяет машине Тьюринга иметь несколько возможных будущих действий из данного состояния. Один из способов рассматривать недетерминизм состоит в том, что машина Тьюринга на каждом этапе разветвляется на множество возможных вычислительных путей, и если она решает проблему в любой из этих ветвей, говорят, что она решила проблему. Очевидно, что эта модель не является физически реализуемой моделью, это просто теоретически интересная абстрактная машина, порождающая особенно интересные классы сложности. Примеры см. недетерминированный алгоритм .
Другие модели машин [ править ]
В литературе было предложено множество моделей машин, отличных от стандартных многоленточных машин Тьюринга , например машины с произвольным доступом . Возможно, это удивительно, но каждую из этих моделей можно преобразовать в другую без каких-либо дополнительных вычислительных мощностей. Потребление времени и памяти этих альтернативных моделей может различаться. [2] Все эти модели объединяет то, что машины работают детерминированно .
Однако некоторые вычислительные проблемы легче анализировать с точки зрения более необычных ресурсов. Например, недетерминированная машина Тьюринга — это вычислительная модель, которую можно расширять для одновременной проверки множества различных возможностей. Недетерминированная машина Тьюринга имеет мало общего с тем, как мы физически хотим вычислять алгоритмы, но ее ветвление точно охватывает многие математические модели, которые мы хотим анализировать, поэтому недетерминированное время является очень важным ресурсом при анализе вычислительных задач. .
Меры сложности [ править ]
Для точного определения того, что значит решить задачу с использованием заданного количества времени и пространства, вычислительная модель, такая как детерминированная машина Тьюринга используется . Время , необходимое детерминированной машине Тьюринга M на входе x, представляет собой общее количество переходов состояний или шагов, которые машина делает, прежде чем она остановится и выдаст ответ («да» или «нет»). машина Тьюринга M Говорят, что работает за время f ( n ), если время, требуемое M на каждом входе длины n, не превышает f ( n ). Проблема принятия решения A может быть решена за время f ( n ), если существует машина Тьюринга, работающая за время f ( n ), которая решает эту проблему. Поскольку теория сложности заинтересована в классификации проблем в зависимости от их сложности, наборы проблем определяются на основе некоторых критериев. Например, набор задач, решаемых за время f ( n ) на детерминированной машине Тьюринга, затем обозначается DTIME ( f ( n )).
Аналогичные определения можно дать и для требований к пространству. Хотя время и пространство являются наиболее известными ресурсами сложности, любую меру сложности можно рассматривать как вычислительный ресурс. Меры сложности в общих чертах определяются аксиомами сложности Блюма . Другие меры сложности, используемые в теории сложности, включают сложность связи , сложность схемы и сложность дерева решений .
Сложность алгоритма часто выражается с помощью обозначения «большое О» .
Лучший, худший и средний случай сложности [ править ]


Наилучшая , наихудшая и средняя сложность случая относятся к трем различным способам измерения временной сложности (или любой другой меры сложности) разных входных данных одного и того же размера. Поскольку некоторые входные данные размера n могут решаться быстрее, чем другие, мы определяем следующие сложности:
- Сложность в лучшем случае: это сложность решения проблемы для наилучшего ввода размера n .
- Сложность в среднем случае: это сложность решения задачи в среднем. Эта сложность определяется только в отношении распределения вероятностей по входным данным. Например, если предполагается, что все входные данные одинакового размера появятся с одинаковой вероятностью, среднюю сложность случая можно определить относительно равномерного распределения по всем входным данным размера n .
- Амортизированный анализ . Амортизированный анализ учитывает как дорогостоящие, так и менее затратные операции вместе по всей серии операций алгоритма.
- Сложность наихудшего случая: это сложность решения проблемы для наихудшего входного сигнала размера n .
Порядок от дешевого к дорогостоящему следующий: лучший, средний ( дискретно-равномерного распределения ), амортизированный, худший.
Например, рассмотрим алгоритм детерминированной сортировки Quicksort . Это решает проблему сортировки списка целых чисел, заданного в качестве входных данных. Худший случай — это когда опорной точкой всегда является наибольшее или наименьшее значение в списке (поэтому список никогда не делится). В этом случае алгоритм требует времени O ( n 2 ). Если предположить, что все возможные перестановки входного списка одинаково вероятны, среднее время, затраченное на сортировку, составит O( n log n ). В лучшем случае каждый поворот делит список пополам, что также требует времени O( n log n ).
Верхняя и нижняя границы сложности задач [ править ]
Чтобы классифицировать время вычислений (или аналогичные ресурсы, такие как потребление пространства), полезно продемонстрировать верхние и нижние границы максимального количества времени, необходимого наиболее эффективному алгоритму для решения данной проблемы. За сложность алгоритма обычно принимают сложность наихудшего случая, если не указано иное. Анализ конкретного алгоритма подпадает под область анализа алгоритмов . Чтобы показать верхнюю границу T ( n ) временной сложности задачи, нужно только показать, что существует конкретный алгоритм с временем работы не более T ( n ). Однако доказать нижние оценки гораздо сложнее, поскольку нижние оценки говорят обо всех возможных алгоритмах, решающих данную задачу. Фраза «все возможные алгоритмы» включает не только алгоритмы, известные сегодня, но и любой алгоритм, который может быть открыт в будущем. Чтобы показать нижнюю границу T ( n ) для задачи, необходимо показать, что ни один алгоритм не может иметь временную сложность ниже T ( n ).
Верхние и нижние границы обычно обозначаются с использованием большого обозначения O , которое скрывает постоянные коэффициенты и меньшие члены. Это делает границы независимыми от конкретных деталей используемой вычислительной модели. Например, если T ( n ) = 7 n 2 + 15 n + 40, в записи большого O можно было бы написать T ( n ) = O( n 2 ).
Классы сложности [ править ]
Определение классов сложности [ править ]
Класс сложности — это совокупность задач связанной сложности. Более простые классы сложности определяются следующими факторами:
- Тип вычислительной задачи. Наиболее часто используемые задачи — это задачи принятия решений. Однако классы сложности могут быть определены на основе функциональных задач , задач подсчета , задач оптимизации , проблем обещаний и т. д.
- Модель вычислений: Наиболее распространенной моделью вычислений является детерминированная машина Тьюринга, но многие классы сложности основаны на недетерминированных машинах Тьюринга, булевых схемах , квантовых машинах Тьюринга , монотонных схемах и т. д.
- Ограничиваемый ресурс (или ресурсы) и граница: эти два свойства обычно указываются вместе, например «полиномиальное время», «логарифмическое пространство», «постоянная глубина» и т. д.
Некоторые классы сложности имеют сложные определения, которые не вписываются в эту структуру. Таким образом, типичный класс сложности имеет следующее определение:
- Набор задач решения, решаемых детерминированной машиной Тьюринга за время f ( n ). (Этот класс сложности известен как DTIME( f ( n )).)
Но ограничение времени вычислений, описанного выше, некоторой конкретной функцией f ( n ) часто дает классы сложности, которые зависят от выбранной модели машины. Например, язык { xx | x — любая двоичная строка} может быть решена за линейное время на многоленточной машине Тьюринга, но обязательно требует квадратичного времени в модели одноленточных машин Тьюринга. Если мы допускаем полиномиальные изменения времени выполнения, тезис Кобэма-Эдмондса утверждает, что «временные сложности в любых двух разумных и общих моделях вычислений связаны полиномиально» ( Goldreich 2008 , Глава 1.2). Это формирует основу для класса сложности P , который представляет собой набор задач решения, решаемых детерминированной машиной Тьюринга за полиномиальное время. Соответствующий набор функциональных задач — FP .
классы Важные сложности
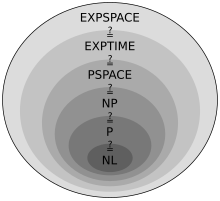
Многие важные классы сложности могут быть определены путем ограничения времени или пространства, используемого алгоритмом. Некоторые важные классы сложности задач принятия решений, определенные таким образом, следующие:
| Ресурс | Детерминизм | Класс сложности | Ограничение ресурсов |
|---|---|---|---|
| Космос | Недетерминированный | NSPACE ( ж ( п )) | О( ж ( п )) |
| Нидерланды | О(логарифм n ) | ||
| НПСПЕЙС | О (поли ( п )) | ||
| НЕКСПСПЕЙС | О(2 поли( п ) ) | ||
| Детерминированный | ДСПЕЙС ( ж ( п )) | О( ж ( п )) | |
| л | О(логарифм n ) | ||
| PSPACE | О (поли ( п )) | ||
| EXPSPACE | О(2 поли( п ) ) | ||
| Время | Недетерминированный | НВРЕМЯ ( f ( n )) | О( ж ( п )) |
| НАПРИМЕР | О (поли ( п )) | ||
| СЛЕДУЮЩЕЕ ВРЕМЯ | О(2 поли( п ) ) | ||
| Детерминированный | DTIME ( f ( n )) | О( ж ( п )) | |
| П | О (поли ( п )) | ||
| ВРЕМЯ ЭКСПРЕСС | О(2 поли( п ) ) |
Классы логарифмического пространства (обязательно) не учитывают пространство, необходимое для представления проблемы.
оказывается, что PSPACE = NPSPACE и EXPSPACE = NEXPSPACE По теореме Савича .
Другие важные классы сложности включают BPP , ZPP и RP , которые определяются с использованием вероятностных машин Тьюринга ; AC и NC , которые определяются с помощью логических схем; и BQP и QMA , которые определяются с использованием квантовых машин Тьюринга. #P — это важный класс сложности задач подсчета (не задач решения). Такие классы, как IP и AM, определяются с использованием систем интерактивных доказательств . ALL — это класс всех задач решения.
Теоремы иерархии об
Для классов сложности, определенных таким образом, желательно доказать, что ослабление требований, скажем, к времени вычислений действительно определяет больший набор проблем. В частности, хотя DTIME( n ) содержится в DTIME( n 2 ), было бы интересно узнать, является ли включение строгим. Что касается требований времени и пространства, ответ на такие вопросы даются теоремами об иерархии времени и пространства соответственно. Их называют теоремами об иерархии, поскольку они создают правильную иерархию классов, определенных путем ограничения соответствующих ресурсов. Таким образом, существуют пары классов сложности, один из которых правильно включен в другой. Выведя такие правильные включения множества, мы можем перейти к количественным утверждениям о том, насколько еще необходимо дополнительное время или пространство, чтобы увеличить количество проблем, которые можно решить.
Точнее, теорема об иерархии времени утверждает, что
- .

Теорема о пространственной иерархии утверждает, что
- .

Теоремы об иерархии времени и пространства составляют основу большинства результатов разделения классов сложности. Например, теорема об иерархии времени говорит нам, что P строго содержится в EXPTIME, а теорема о пространственной иерархии говорит нам, что L строго содержится в PSPACE.
Сокращение [ править ]
Многие классы сложности определяются с использованием концепции сокращения. Редукция – это трансформация одной проблемы в другую. Он отражает неформальное представление о том, что проблема не менее сложна, чем другая проблема. Например, если проблему X можно решить с помощью алгоритма для Y , X не сложнее, чем Y , и мы говорим, что X сводится к Y. то Существует много различных типов сокращений, основанных на методе сокращения, таких как сокращения Кука, сокращения Карпа и сокращения Левина, а также ограничениях сложности сокращений, таких как сокращения полиномиального времени или сокращения логарифмического пространства .
Наиболее часто используемым сокращением является сокращение за полиномиальное время. Это означает, что процесс приведения занимает полиномиальное время. Например, задачу возведения в квадрат целого числа можно свести к задаче умножения двух целых чисел. Это означает, что для возведения целого числа в квадрат можно использовать алгоритм умножения двух целых чисел. Действительно, это можно сделать, подав одинаковые входные данные на оба входа алгоритма умножения. Таким образом, мы видим, что возведение в квадрат не сложнее умножения, поскольку возведение в квадрат можно свести к умножению.
Это мотивирует концепцию сложности проблемы для класса сложности. Задача X является сложной для класса задач C если каждую задачу из C можно свести к X. , Таким образом, ни одна проблема в C чем X , поскольку алгоритм для X позволяет нам решить любую проблему в C. не является более сложной , Понятие сложных задач зависит от типа используемой редукции. Для классов сложности выше P обычно используются сокращения за полиномиальное время. В частности, набор задач, сложных для NP, представляет собой набор NP-трудных задач.
Если проблема X находится в C сложна для C , то X называется полной для C. и Это означает, что — самая сложная проблема в C. X (Поскольку многие задачи могут быть одинаково трудными, можно сказать, что X — одна из сложнейших задач в C. ) Таким образом, класс NP-полных задач содержит наиболее трудные задачи в NP в том смысле, что они являются наиболее вероятными. не находиться в P. Поскольку проблема P = NP не решена, возможность свести известную NP-полную задачу Π 2 к другой задаче Π 1 будет означать, что не существует известного решения за полиномиальное время для Π. 1 . за полиномиальное время Это связано с тем, что решение Π 1 приведет к решению Π 2 за полиномиальное время . Аналогично, поскольку все задачи NP можно свести к набору, нахождение NP-полной задачи, которую можно решить за полиномиальное время, будет означать, что P = NP. [3]
Важные открытые проблемы [ править ]
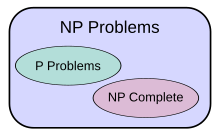
и Проблема NP P
Класс сложности P часто рассматривается как математическая абстракция, моделирующая те вычислительные задачи, которые допускают эффективный алгоритм. Эта гипотеза называется тезисом Кобэма-Эдмондса . Класс сложности NP , с другой стороны, содержит множество проблем, которые люди хотели бы эффективно решать, но для которых не известен эффективный алгоритм, например, проблема булевой выполнимости , проблема гамильтоновых путей и проблема вершинного покрытия . Поскольку детерминированные машины Тьюринга являются особыми недетерминированными машинами Тьюринга, легко заметить, что каждая задача из P также является членом класса NP.
Вопрос о том, равно ли P NP, является одним из наиболее важных открытых вопросов в теоретической информатике из-за широких последствий решения. [3] Если ответ положительный, можно доказать, что многие важные проблемы имеют более эффективные решения. К ним относятся различные типы задач целочисленного программирования в исследовании операций , многие проблемы в логистике , предсказании структуры белков в биологии , [5] и способность находить формальные доказательства теорем чистой математики . [6] Проблема P и NP — одна из задач Премии тысячелетия, предложенная Математическим институтом Клея . За решение проблемы предусмотрен приз в размере 1 000 000 долларов США. [7]
Проблемы в NP, о которых не известно, находятся в P или NP-полных [ править ]
Ладнер показал, что если P ≠ NP, существуют проблемы то в NP , которые не являются ни P , ни NP-полными . [4] Такие задачи называются NP-промежуточными задачами. Проблема изоморфизма графов , проблема дискретного логарифма и проблема целочисленной факторизации являются примерами проблем, которые считаются NP-промежуточными. Это одни из немногих задач NP, которые, как известно, не относятся к P или не являются NP-полными .
Проблема изоморфизма графов задача определения изоморфности двух графов конечных — это вычислительная . Важная нерешенная проблема в теории сложности заключается в том, находится ли проблема изоморфизма графов в P , NP-полных или NP-промежуточных. Ответ неизвестен, но считается, что задача как минимум не NP-полная. [8] Если изоморфизм графов NP-полный, полиномиальная временная иерархия схлопывается на второй уровень. [9] Поскольку широко распространено мнение, что полиномиальная иерархия не схлопывается ни на один конечный уровень, считается, что изоморфизм графов не является NP-полным. Лучший алгоритм для этой задачи, предложенный Ласло Бабаем и Юджином Люксом, имеет время выполнения. для графов с n вершинами, хотя некоторые недавние работы Бабая предлагают некоторые потенциально новые точки зрения на этот вопрос. [10]

Проблема целочисленной факторизации — это вычислительная задача определения простой факторизации данного целого числа. Сформулированная как проблема принятия решения, это проблема определения того, имеет ли входной простой множитель меньше k . Эффективный алгоритм факторизации целых чисел неизвестен, и этот факт лежит в основе нескольких современных криптографических систем, таких как алгоритм RSA . Проблема целочисленной факторизации находится в NP и в co-NP (и даже в UP и co-UP). [11] ). Если задача NP-полная , полиномиальная временная иерархия рухнет на первый уровень (т. е. NP будет равна co-NP ). Самый известный алгоритм факторизации целых чисел — это решето общего числового поля , которое требует времени. [12] факторизовать нечетное целое число n . Однако самый известный квантовый алгоритм для решения этой задачи, алгоритм Шора , работает за полиномиальное время. К сожалению, этот факт мало что говорит о том, в чем заключается проблема в отношении классов неквантовой сложности.
![{\displaystyle O(e^{\left({\sqrt[{3}]{\frac {64}{9}}}\right){\sqrt[{3}]{(\log n)}}{ \sqrt[{3}]{(\log \log n)^{2}}}})}](https://wikimedia.org/api/rest_v1/media/math/render/svg/d50912fbf223d0bbadd2a028262414397fbee1a9)
Разделение между другими классами сложности [ править ]
Предполагается, что многие известные классы сложности неравны, но это не доказано. Например, P ⊆ NP ⊆ PP ⊆ PSPACE , но возможно, что P = PSPACE . Если P не равен NP , то P также не равен PSPACE . существует множество известных классов сложности Поскольку между P и PSPACE , таких как RP , BPP , PP , BQP , MA , PH и т. д., возможно, что все эти классы сложности схлопнутся в один класс. Доказательство того, что любой из этих классов неравен, могло бы стать крупным прорывом в теории сложности.
Аналогичным образом, co-NP — это класс, содержащий проблемы дополнения (т.е. проблемы с обратными ответами «да » или «нет» ) задач NP . Считается, что [13] что NP не равен co-NP ; однако это еще не доказано. Понятно, что если эти два класса сложности не равны, то P не равен NP , поскольку P = co-P . Таким образом, если P = NP, мы будем иметь co-P = co-NP , откуда NP = P = co-P = co-NP .
Точно так же неизвестно, содержится ли L (множество всех задач, которые можно решить в логарифмическом пространстве) строго в P или равно P . Опять же, между ними существует множество классов сложности, таких как NL и NC , и неизвестно, являются ли они разными или равными классами.
Предполагается, что P и BPP равны. Однако в настоящее время он открыт, если BPP = NEXP .
Несговорчивость [ править ]
Проблема, которую можно решить теоретически (например, при наличии больших, но ограниченных ресурсов, особенно времени), но для которой на практике любое решение требует слишком много ресурсов, чтобы быть полезным, называется проблемой. неразрешимая проблема . [14] И наоборот, проблема, которую можно решить на практике, называется разрешимая проблема , буквально «проблема, с которой можно справиться». Термин «невозможно» (буквально «невозможно сделать») иногда используется как синоним слова « неразрешимый » . [15] хотя это может привести к путанице с возможным решением математической оптимизации . [16]
Решаемые проблемы часто отождествляются с проблемами, которые имеют решения за полиномиальное время ( P , PTIME ); это известно как тезис Кобэма-Эдмондса . К проблемам, которые, как известно, являются неразрешимыми в этом смысле, относятся проблемы EXPTIME -трудные. Если NP — это не то же самое, что P, то NP-сложные проблемы также в этом смысле неразрешимы.
Однако эта идентификация неточна: решение за полиномиальное время с большой степенью или большим старшим коэффициентом быстро растет и может быть непрактичным для практических задач размера; и наоборот, решение с экспоненциальным временем, которое медленно растет, может быть практичным при реалистичных входных данных, или решение, которое занимает много времени в худшем случае, может занять короткое время в большинстве случаев или в среднем случае и, таким образом, все еще быть практичным. Утверждение, что проблема не в P, не означает, что все большие случаи проблемы сложны или даже что большинство из них таковы. Например, проблема решения в арифметике Пресбургера было показано, что не находится в P, однако были написаны алгоритмы, которые в большинстве случаев решают проблему за разумное время. Аналогичным образом, алгоритмы могут решить задачу о NP-полном рюкзаке в широком диапазоне размеров за время, меньшее, чем квадратичное, а решатели SAT обычно обрабатывают большие экземпляры NP-полной задачи о булевой выполнимости .
Чтобы понять, почему алгоритмы с экспоненциальным временем практически непригодны для использования, рассмотрим программу, которая выдает 2 н операции до остановки. Для небольшого n , скажем, 100, и предположим, например, что компьютер делает 10. 12 операций каждую секунду, программа будет выполняться примерно 4 × 10 10 лет, что соответствует возрасту Вселенной . Даже при наличии гораздо более быстрого компьютера программа будет полезна только в очень небольших случаях, и в этом смысле неразрешимость проблемы в некоторой степени не зависит от технического прогресса. Однако алгоритм экспоненциального времени, который принимает 1,0001 н операции практичны до тех пор, пока n не станет относительно большим.
Точно так же алгоритм с полиномиальным временем не всегда практичен. Если время его работы равно, скажем, n 15 , неразумно считать его эффективным, и он по-прежнему бесполезен, за исключением небольших случаев. Действительно, на практике даже n 3 или н 2 алгоритмы часто непрактичны для задач реального размера.
Теория непрерывной сложности [ править ]
Теория непрерывной сложности может относиться к теории сложности задач, которые включают в себя непрерывные функции, аппроксимируемые дискретизацией, как это изучается в численном анализе . Один подход к теории сложности численного анализа [17] это сложность, основанная на информации .
Теория непрерывной сложности может также относиться к теории сложности использования аналоговых вычислений , которая использует непрерывные динамические системы и дифференциальные уравнения . [18] Теорию управления можно рассматривать как форму вычислений, а дифференциальные уравнения используются при моделировании систем с непрерывным временем и гибридных систем с дискретным и непрерывным временем. [19]
История [ править ]
Ранним примером анализа сложности алгоритма является анализ времени выполнения алгоритма Евклида, выполненный Габриэлем Ламе в 1844 году.
Прежде чем начались настоящие исследования, явно посвященные сложности алгоритмических задач, различными исследователями были заложены многочисленные основы. Наиболее влиятельным среди них было определение машины Тьюринга, данное Аланом Тьюрингом в 1936 году, которое оказалось очень надежным и гибким упрощением компьютера.
Начало систематических исследований вычислительной сложности приписывается основополагающей статье 1965 года «О вычислительной сложности алгоритмов» Юриса Хартманиса и Ричарда Э. Стернса , в которой были изложены определения временной сложности и пространственной сложности , а также доказаны теоремы об иерархии. [20] Кроме того, в 1965 году Эдмондс предложил считать «хорошим» алгоритмом тот, время работы которого ограничено полиномом от размера входных данных. [21]
Более ранние статьи, изучающие проблемы, решаемые машинами Тьюринга с конкретными ограниченными ресурсами, включают [20] Джона Майхилла Определение линейных ограниченных автоматов (Майхилл, 1960), исследование элементарных множеств Рэймондом Смалльяном (1961), а также Хисао Ямады . статья [22] по вычислениям в реальном времени (1962). Несколько ранее Борис Трахтенброт (1956) исследовал еще одну специфическую меру сложности. пионер этой области из СССР [23] Как он помнит:
Однако [мой] первоначальный интерес [к теории автоматов] все больше отступал в пользу вычислительной сложности, захватывающего слияния комбинаторных методов, унаследованных от теории переключения , с концептуальным арсеналом теории алгоритмов. Эти идеи пришли мне в голову ранее, в 1955 году, когда я ввел термин «сигнальная функция», который сегодня широко известен как «мера сложности». [24]
В 1967 году Мануэль Блюм сформулировал набор аксиом (ныне известных как аксиомы Блюма ), определяющих желаемые свойства мер сложности на множестве вычислимых функций, и доказал важный результат, так называемую теорему об ускорении . Эта область начала процветать в 1971 году, когда Стивен Кук и Леонид Левин доказали существование практически важных задач, которые являются NP-полными . В 1972 году Ричард Карп сделал шаг вперед в этой идее в своей знаковой статье «Сводимость среди комбинаторных задач», в которой он показал, что 21 разнообразная комбинаторная задача и задача теории графов , каждая из которых печально известна своей вычислительной неразрешимостью, являются NP-полными. [25]
См. также [ править ]
- Вычислительная сложность
- Описательная теория сложности
- Сложность игры
- Язык листьев
- Пределы вычислений
- Список классов сложности
- Список тем по вычислимости и сложности
- Список нерешенных проблем информатики
- Параметризованная сложность
- Сложность доказательства
- Квантовая теория сложности
- Теория структурной сложности
- Трансвычислительная проблема
- Вычислительная сложность математических операций
Работает над сложностью [ править ]
- Вупулури, Шьям; Дориа, Франсиско А., ред. (2020), Распутывая сложность: жизнь и работа Грегори Чайтина , World Scientific, doi : 10.1142/11270 , ISBN 978-981-12-0006-9 , S2CID 198790362
Ссылки [ править ]
Цитаты [ править ]
- ^ «Проблема P против NP | Математический институт Клэя» . www.claymath.org . Архивировано из оригинала 6 июля 2018 года . Проверено 6 июля 2018 г.
- ^ См. Arora & Barak 2009 , Глава 1: Вычислительная модель и почему это не имеет значения.
- ↑ Перейти обратно: Перейти обратно: а б См. Sipser 2006 , Глава 7: Временная сложность.
- ↑ Перейти обратно: Перейти обратно: а б Ладнер, Ричард Э. (1975), «О структуре полиномиальной сводимости по времени», Журнал ACM , 22 (1): 151–171, doi : 10.1145/321864.321877 , S2CID 14352974 .
- ^ Бергер, Бонни А .; Лейтон, Т. (1998), «Сворачивание белка в гидрофобно-гидрофильной (HP) модели является NP-полным», Journal of Computational Biology , 5 (1): 27–40, CiteSeerX 10.1.1.139.5547 , doi : 10.1089/ cmb.1998.5.27 , PMID 9541869 .
- ^ Кук, Стивен (апрель 2000 г.), Проблема P и NP (PDF) , Институт математики Клэя , заархивировано из оригинала (PDF) 12 декабря 2010 г. , получено 18 октября 2006 г.
- ^ Джаффе, Артур М. (2006), «Большой вызов тысячелетия в математике» (PDF) , Уведомления AMS , 53 (6), заархивировано (PDF) из оригинала 12 июня 2006 г. , получено 18 октября 2006 г.
- ^ Арвинд, Викраман; Курур, Пиюш П. (2006), «Изоморфизм графов в SPP», Information and Computation , 204 (5): 835–852, doi : 10.1016/j.ic.2006.02.002 .
- ^ Шёнинг, Уве (1988), «Изоморфизм графов в низкой иерархии», Journal of Computer and System Sciences , 37 (3): 312–323, doi : 10.1016/0022-0000(88)90010-4
- ^ Бабай, Ласло (2016). «Изоморфизм графов за квазиполиномиальное время». arXiv : 1512.03547 [ cs.DS ].
- ^ Фортнау, Лэнс (13 сентября 2002 г.). «Блог о сложности вычислений: факторинг» . weblog.fortnow.com .
- ^ Wolfram MathWorld: Сито с числовыми полями
- ^ Курс Боаза Барака по сложности вычислений, лекция 2.
- ^ Хопкрофт, Дж. Э., Мотвани, Р. и Уллман, Дж. Д. (2007) Введение в теорию автоматов, языки и вычисления , Аддисон Уэсли, Бостон/Сан-Франциско/Нью-Йорк (стр. 368)
- ^ Меран, Жерар (2014). Алгоритмы и сложность . Эльзевир. п. п. 4 . ISBN 978-0-08093391-7 .
- ^ Зобель, Джастин (2015). Написание статей по информатике . Спрингер. п. 132 . ISBN 978-1-44716639-9 .
- ^ Смейл, Стив (1997). «Теория сложности и численный анализ». Акта Нумерика . 6 . Издательство Кембриджского университета: 523–551. Бибкод : 1997AcNum...6..523S . CiteSeerX 10.1.1.33.4678 . дои : 10.1017/s0962492900002774 . S2CID 5949193 .
- ^ Бабай, Ласло; Кампаньоло, Мануэль (2009). «Обзор вычислений в непрерывном времени». arXiv : 0907.3117 [ cs.CC ].
- ^ Томлин, Клэр Дж.; Митчелл, Ян; Байен, Александр М.; Оиси, Мико (июль 2003 г.). «Вычислительные методы проверки гибридных систем». Труды IEEE . 91 (7): 986–1001. CiteSeerX 10.1.1.70.4296 . дои : 10.1109/jproc.2003.814621 .
- ↑ Перейти обратно: Перейти обратно: а б Фортнау и Гомер (2003)
- ^ Ричард М. Карп, « Комбинаторика, сложность и случайность », лекция на премию Тьюринга 1985 г.
- ^ Ямада, Х. (1962). «Вычисления в реальном времени и рекурсивные функции, не вычислимые в реальном времени». Транзакции IEEE на электронных компьютерах . EC-11 (6): 753–760. дои : 10.1109/TEC.1962.5219459 .
- ^ Трахтенброт, Б.А.: Функции сигнализации и табличные операторы. Учёные запискиПензенского пединститута (Известия Пензенского педагогического института) 4, 75–87 (1956) (на русском языке)
- ^ Борис Трахтенброт, « От логики к теоретической информатике – обновление ». В: Столпы информатики , LNCS 4800, Springer 2008.
- ^ Ричард М. Карп (1972), «Сводимость среди комбинаторных задач» (PDF) , в Р.Э. Миллере; Дж. Тэтчер (ред.), Сложность компьютерных вычислений , Нью-Йорк: Пленум, стр. 85–103, заархивировано из оригинала (PDF) 29 июня 2011 г. , получено 28 сентября 2009 г.
Учебники [ править ]
- Арора, Санджив ; Барак, Боаз (2009), Сложность вычислений: современный подход , Издательство Кембриджского университета, ISBN 978-0-521-42426-4 , Збл 1193,68112
- Дауни, Род; Стипендиаты, Майкл (1999), Параметризованная сложность , Монографии по информатике, Берлин, Нью-Йорк: Springer-Verlag, ISBN 9780387948836
- Ду, Дин-Чжу; Ко, Кер-И (2000), Теория вычислительной сложности , John Wiley & Sons, ISBN 978-0-471-34506-0
- Гэри, Майкл Р .; Джонсон, Дэвид С. (1979). Компьютеры и трудноразрешимые проблемы: Руководство по теории NP-полноты . Серия книг по математическим наукам (1-е изд.). Нью-Йорк: WH Freeman and Company . ISBN 9780716710455 . МР 0519066 . OCLC 247570676 .
- Гольдрайх, Одед (2008), Вычислительная сложность: концептуальная перспектива , Cambridge University Press
- ван Леувен, Ян , изд. (1990), Справочник по теоретической информатике (том A): алгоритмы и сложность , MIT Press, ISBN 978-0-444-88071-0
- Пападимитриу, Христос (1994), Вычислительная сложность (1-е изд.), Аддисон Уэсли, ISBN 978-0-201-53082-7
- Сипсер, Майкл (2006), Введение в теорию вычислений (2-е изд.), США: Технология курса Thomson, ISBN 978-0-534-95097-2
Опросы [ править ]
- Халил, Хатем; Улери, Дана (1976), «Обзор текущих исследований сложности алгоритмов для уравнений в частных производных», Материалы ежегодной конференции - ACM 76 , стр. 197–201, doi : 10.1145/800191.805573 , ISBN 9781450374897 , S2CID 15497394
- Кук, Стивен (1983), «Обзор вычислительной сложности», Communications of the ACM , 26 (6): 400–408, doi : 10.1145/358141.358144 , ISSN 0001-0782 , S2CID 14323396
- Пока, Лэнс; Гомер, Стивен (2003), «Краткая история вычислительной сложности» (PDF) , Бюллетень EATCS , 80 : 95–133
- Мертенс, Стефан (2002), «Сложность вычислений для физиков», Computing in Science & Engineering , 4 (3): 31–47, arXiv : cond-mat/0012185 , Bibcode : 2002CSE.....4c..31M , doi : 10.1109/5992.998639 , ISSN 1521-9615 , S2CID 633346