Распределенные вычисления
Распределенные вычисления — это область информатики , которая изучает распределенные системы , определяемые как компьютерные системы , взаимодействующие компоненты которых расположены на разных сетевых компьютерах . [1] [2]
Компоненты распределенной системы взаимодействуют и координируют свои действия, передавая друг другу сообщения для достижения общей цели. Тремя важными проблемами распределенных систем являются: поддержание параллельной работы компонентов, преодоление отсутствия глобальных часов и управление независимыми сбоями компонентов. [1] Когда какой-либо компонент одной системы выходит из строя, вся система не выходит из строя. [3] Примеры распределенных систем варьируются от систем на основе SOA до микросервисов , многопользовательских онлайн-игр и одноранговых приложений . Распределенные системы стоят значительно дороже, чем монолитные архитектуры, в первую очередь из-за возросших потребностей в дополнительном оборудовании, серверах, шлюзах, межсетевых экранах, новых подсетях, прокси и так далее. [4] Кроме того, распределенные системы склонны к ошибкам распределенных вычислений . С другой стороны, хорошо спроектированная распределенная система более масштабируема, более надежна, более изменчива и более точно настраивается, чем монолитное приложение , развернутое на одной машине. [5]
, Компьютерная программа работающая в распределенной системе, называется распределенной программой . [6] а распределенное программирование — это процесс написания таких программ. [7] Существует множество различных типов реализаций механизма передачи сообщений, включая чистый HTTP, RPC-подобные соединители и очереди сообщений . [8]
Распределенные вычисления также относятся к использованию распределенных систем для решения вычислительных задач. В распределенных вычислениях задача разбивается на множество задач, каждая из которых решается одним или несколькими компьютерами. [9] которые общаются друг с другом посредством передачи сообщений. [10]
Введение [ править ]
Слово «распределенный» в таких терминах, как «распределенная система», «распределенное программирование» и « распределенный алгоритм », первоначально относилось к компьютерным сетям, в которых отдельные компьютеры были физически распределены в пределах некоторой географической области. [11] В настоящее время эти термины используются в гораздо более широком смысле, даже относясь к автономным процессам , которые выполняются на одном физическом компьютере и взаимодействуют друг с другом посредством передачи сообщений. [10]
Хотя единого определения распределенной системы не существует, [12] следующие определяющие свойства обычно используются как:
- Существует несколько автономных вычислительных объектов ( компьютеров или узлов ), каждый из которых имеет собственную локальную память . [13]
- Сущности общаются друг с другом посредством передачи сообщений . [14]
Распределенная система может иметь общую цель, например решение большой вычислительной задачи; [15] тогда пользователь воспринимает совокупность автономных процессоров как единое целое. Альтернативно, у каждого компьютера может быть свой собственный пользователь с индивидуальными потребностями, а целью распределенной системы является координация использования общих ресурсов или предоставление пользователям услуг связи. [16]
Другие типичные свойства распределенных систем включают следующее:
- Система должна допускать сбои на отдельных компьютерах. [17]
- Структура системы (топология сети, задержка сети, количество компьютеров) заранее не известна, система может состоять из разных типов компьютеров и сетевых связей, а также система может меняться в ходе выполнения распределенной программы. [18]
- Каждый компьютер имеет лишь ограниченное, неполное представление о системе. Каждый компьютер может знать только одну часть входных данных. [19]
Узоры [ править ]
Вот распространенные архитектурные шаблоны, используемые для распределенных вычислений: [20]
- Сага шаблон
- Микросервисы
- Архитектура, управляемая событиями
Параллельные и распределенные вычисления [ править ]
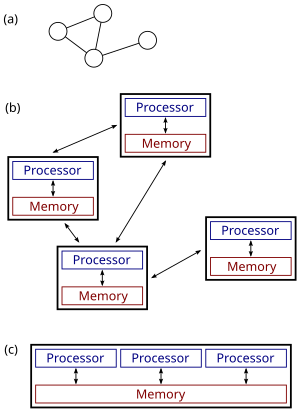
(c): параллельная система.
Распределенные системы — это группы сетевых компьютеров, которые имеют общую цель своей работы.Термины « параллельные вычисления », « параллельные вычисления » и «распределенные вычисления» во многом совпадают, и между ними не существует четкого различия. [21] Одну и ту же систему можно охарактеризовать как «параллельную», так и «распределенную»; процессоры в типичной распределенной системе работают одновременно и параллельно. [22] Параллельные вычисления можно рассматривать как особенно тесно связанную форму распределенных вычислений. [23] а распределенные вычисления можно рассматривать как слабосвязанную форму параллельных вычислений. [12] Тем не менее, можно грубо классифицировать параллельные системы как «параллельные» или «распределенные», используя следующие критерии:
- При параллельных вычислениях все процессоры могут иметь доступ к общей памяти для обмена информацией между процессорами. [24]
- В распределенных вычислениях каждый процессор имеет свою собственную память ( распределенную память ). Обмен информацией осуществляется путем передачи сообщений между процессорами. [25]
Рисунок справа иллюстрирует разницу между распределенными и параллельными системами. Рисунок (a) представляет собой схематическое изображение типичной распределенной системы; система представлена в виде топологии сети, в которой каждый узел представляет собой компьютер, а каждая линия, соединяющая узлы, представляет собой канал связи. На рисунке (б) та же распределенная система показана более подробно: каждый компьютер имеет свою локальную память, а обмен информацией возможен только путем передачи сообщений от одного узла к другому по доступным каналам связи. На рисунке (c) показана параллельная система, в которой каждый процессор имеет прямой доступ к общей памяти.
Ситуация еще больше усложняется традиционным использованием терминов «параллельный» и «распределенный алгоритм» , которые не совсем соответствуют приведенным выше определениям параллельных и распределенных систем ( см. ниже более подробное обсуждение ). Тем не менее, как правило, для высокопроизводительных параллельных вычислений в мультипроцессоре с общей памятью используются параллельные алгоритмы, тогда как для координации крупномасштабной распределенной системы используются распределенные алгоритмы. [26]
История [ править ]
Использование параллельных процессов, которые взаимодействуют посредством передачи сообщений, уходит корнями в архитектуры операционных систем , изучавшиеся в 1960-х годах. [27] Первыми широко распространенными распределенными системами были локальные сети , такие как Ethernet , изобретенные в 1970-х годах. [28]
ARPANET , один из предшественников Интернета , был представлен в конце 1960-х годов, а электронная почта ARPANET была изобретена в начале 1970-х годов. Электронная почта стала самым успешным приложением ARPANET. [29] и это, вероятно, самый ранний пример крупномасштабного распределенного приложения . Помимо ARPANET (и его преемника, глобального Интернета), другие ранние всемирные компьютерные сети включали Usenet и FidoNet 1980-х годов, обе из которых использовались для поддержки распределенных дискуссионных систем. [30]
Исследование распределенных вычислений стало отдельной отраслью информатики в конце 1970-х и начале 1980-х годов. Первая конференция в этой области, Симпозиум по принципам распределенных вычислений (PODC), датируется 1982 годом, а ее аналог Международный симпозиум по распределенным вычислениям (DISC) впервые был проведен в Оттаве в 1985 году как Международный семинар по распределенным алгоритмам на графах. [31]
Архитектуры [ править ]
Для распределенных вычислений используются различные аппаратные и программные архитектуры. На более низком уровне необходимо соединить несколько процессоров с помощью какой-либо сети, независимо от того, напечатана ли эта сеть на печатной плате или состоит из слабо связанных устройств и кабелей. На более высоком уровне необходимо связать процессы, работающие на этих процессорах, с какой-то системой связи . [32]
Разделяют ли эти процессоры ресурсы или нет, определяет первое различие между тремя типами архитектуры:
Распределенное программирование обычно относится к одной из нескольких базовых архитектур: клиент-серверная , трехуровневая , n- уровневая или одноранговая ; или категории: слабая связь или сильная связь . [33]
- Клиент-сервер : архитектуры, в которых интеллектуальные клиенты обращаются к серверу за данными, затем форматируют и отображают их пользователям. Ввод на клиенте передается обратно на сервер, если он представляет собой постоянное изменение.
- Трехуровневая : архитектуры, которые перемещают интеллект клиента на средний уровень, чтобы без сохранения состояния можно было использовать клиентов . Это упрощает развертывание приложений. Большинство веб-приложений являются трехуровневыми.
- n -уровень : архитектуры, которые обычно относятся к веб-приложениям, которые далее пересылают свои запросы другим корпоративным службам. Этот тип приложений является наиболее ответственным за успех серверов приложений .
- Одноранговая сеть : архитектуры, в которых нет специальных машин, предоставляющих услуги или управляющих сетевыми ресурсами. [34] : 227 Вместо этого все обязанности равномерно распределяются между всеми машинами, называемыми одноранговыми узлами. Пиры могут выступать как клиентами, так и серверами. [35] Примеры этой архитектуры включают BitTorrent и сеть биткойн .
Еще одним базовым аспектом архитектуры распределенных вычислений является метод взаимодействия и координации работы параллельных процессов. Через различные протоколы передачи сообщений процессы могут напрямую взаимодействовать друг с другом, обычно в отношениях «основной/подчиненный» . Альтернативно, архитектура, ориентированная на базу данных, может позволить выполнять распределенные вычисления без какой-либо формы прямого межпроцессного взаимодействия , используя общую базу данных . [36] Архитектура, ориентированная на базы данных, в частности, обеспечивает аналитику реляционной обработки в схематической архитектуре, позволяющей ретранслировать живую среду. Это позволяет выполнять функции распределенных вычислений как внутри параметров сетевой базы данных, так и за их пределами. [37]
Приложения [ править ]
Причины использования распределенных систем и распределенных вычислений могут включать:
- Сама природа приложения может требовать использования сети связи, соединяющей несколько компьютеров: например, данные производятся в одном физическом месте, а требуются в другом.
- Во многих случаях использование одного компьютера в принципе возможно, но использование распределенной системы выгодно по практическим соображениям. Например:
- Он может обеспечить гораздо больший объем хранилища и памяти, более быстрые вычисления и более высокую пропускную способность, чем одна машина.
- Она может обеспечить большую надежность, чем нераспределенная система, поскольку нет единой точки отказа . Более того, распределенную систему может быть проще расширять и управлять ею, чем монолитную однопроцессорную систему. [38]
- Возможно, будет более рентабельно получить желаемый уровень производительности, используя кластер из нескольких компьютеров начального уровня, по сравнению с одним компьютером высокого класса.
Примеры [ править ]
Примеры распределенных систем и приложений распределенных вычислений включают следующее: [39]
- телекоммуникационные сети:
- сетевые приложения:
- Всемирная паутина и одноранговые сети ,
- массовые многопользовательские онлайн-игры и виртуальной реальности , сообщества
- распределенные базы данных и системы управления распределенными базами данных ,
- сетевые файловые системы ,
- распределенный кеш, такой как пакетные буферы ,
- распределенные системы обработки информации, такие как банковские системы и системы бронирования авиабилетов;
- контроль процесса в режиме реального времени:
- самолетом , системы управления
- промышленные системы управления ;
- параллельные вычисления :
- научные вычисления , включая кластерные вычисления , грид-вычисления , облачные вычисления , [40] и различные волонтерские компьютерные проекты ,
- распределенный рендеринг в компьютерной графике.
- пиринговый
Теоретические основы [ править ]
Модели [ править ]
Многие задачи, которые мы хотели бы автоматизировать с помощью компьютера, относятся к типу «вопрос-ответ»: мы хотим задать вопрос, а компьютер должен дать ответ. В теоретической информатике такие задачи называются вычислительными задачами . Формально вычислительная задача состоит из экземпляров вместе с решением для каждого экземпляра. Примеры — это вопросы, которые мы можем задать, а решения — это желаемые ответы на эти вопросы.
Теоретическая информатика стремится понять, какие вычислительные задачи можно решить с помощью компьютера ( теория вычислимости ) и насколько эффективно ( теория сложности вычислений ). Традиционно говорят, что проблему можно решить с помощью компьютера, если мы сможем разработать алгоритм , который дает правильное решение для любого данного случая. Такой алгоритм можно реализовать в виде компьютерной программы , которая работает на компьютере общего назначения: программа считывает экземпляр задачи из входных данных , выполняет некоторые вычисления и выдает решение в качестве выходных данных . Такие формализмы, как машины произвольного доступа или универсальные машины Тьюринга, можно использовать в качестве абстрактных моделей последовательного компьютера общего назначения, выполняющего такой алгоритм. [41] [42]
Область параллельных и распределенных вычислений изучает аналогичные вопросы в случае нескольких компьютеров или компьютера, выполняющего сеть взаимодействующих процессов: какие вычислительные задачи можно решить в такой сети и насколько эффективно? Однако совсем не очевидно, что подразумевается под «решением проблемы» в случае параллельной или распределенной системы: например, какова задача разработчика алгоритма и каков параллельный или распределенный эквивалент последовательного решения. универсальный компьютер? [ нужна ссылка ]
Обсуждение ниже сосредоточено на случае нескольких компьютеров, хотя многие проблемы одинаковы для параллельных процессов, выполняемых на одном компьютере.
Обычно используются три точки зрения:
- Параллельные алгоритмы в модели с общей памятью
- Все процессоры имеют доступ к общей памяти. Разработчик алгоритма выбирает программу, выполняемую каждым процессором.
- Одной из теоретических моделей являются параллельные машины с произвольным доступом (PRAM). используемые [43] Однако классическая модель PRAM предполагает синхронный доступ к общей памяти.
- Программы с общей памятью можно распространить на распределенные системы, если базовая операционная система инкапсулирует связь между узлами и фактически объединяет память во всех отдельных системах.
- Модель, которая ближе к поведению реальных многопроцессорных машин и учитывает использование машинных инструкций, таких как сравнение и замена (CAS), — это модель асинхронной общей памяти . По этой модели существует множество работ, краткое изложение которых можно найти в литературе. [44] [45]
- Параллельные алгоритмы в модели передачи сообщений
- Разработчик алгоритма выбирает структуру сети, а также программу, выполняемую каждым компьютером.
- такие модели, как логические схемы и сортировочные сети . Используются [46] Булеву схему можно рассматривать как компьютерную сеть: каждый вентиль представляет собой компьютер, на котором выполняется чрезвычайно простая компьютерная программа. Аналогично, сортировочную сеть можно рассматривать как компьютерную сеть: каждый компаратор представляет собой компьютер.
- Распределенные алгоритмы в модели передачи сообщений
- Разработчик алгоритма выбирает только компьютерную программу. На всех компьютерах работает одна и та же программа. Система должна работать корректно независимо от структуры сети.
- Обычно используемая модель представляет собой граф с одним конечным автоматом на узел.
В случае распределенных алгоритмов вычислительные задачи обычно связаны с графами. граф, описывающий структуру компьютерной сети является Зачастую примером проблемы . Это проиллюстрировано в следующем примере. [47]
Пример [ править ]
поиска раскраски заданного графа G. Рассмотрим вычислительную задачу В разных областях могут использоваться следующие подходы:
- Централизованные алгоритмы [47]
- Граф G кодируется как строка, и строка передается в качестве входных данных в компьютер. Компьютерная программа находит раскраску графа, кодирует ее в виде строки и выводит результат.
- Параллельные алгоритмы
- Опять же, граф G кодируется как строка. Однако несколько компьютеров могут параллельно обращаться к одной и той же строке. Каждый компьютер может сосредоточиться на одной части графика и раскрасить эту часть.
- Основное внимание уделяется высокопроизводительным вычислениям, которые используют вычислительную мощность нескольких компьютеров параллельно.
- Распределенные алгоритмы
- Граф G представляет собой структуру компьютерной сети. имеется один компьютер Для каждого узла G канал связи для каждого ребра G. и один Первоначально каждый компьютер знает только о своих непосредственных соседях в графе G ; чтобы узнать больше о структуре G. компьютеры должны обмениваться сообщениями друг с другом , Каждый компьютер должен выдавать на выходе свой собственный цвет.
- Основное внимание уделяется координации работы произвольной распределенной системы. [47]
Хотя область параллельных алгоритмов имеет иную направленность, чем область распределенных алгоритмов, между этими двумя областями существует большое взаимодействие. Например, алгоритм Коула – Вишкина для раскраски графов. [48] изначально был представлен как параллельный алгоритм, но тот же метод можно использовать и непосредственно как распределенный алгоритм.
Более того, параллельный алгоритм может быть реализован как в параллельной системе (с использованием общей памяти), так и в распределенной системе (с использованием передачи сообщений). [49] Традиционная граница между параллельными и распределенными алгоритмами (выбор подходящей сети или запуск в любой данной сети) не лежит в том же месте, что и граница между параллельными и распределенными системами (общая память и передача сообщений).
Меры сложности [ править ]
В параллельных алгоритмах, помимо времени и пространства, еще одним ресурсом является количество компьютеров. Действительно, часто существует компромисс между временем работы и количеством компьютеров: проблему можно решить быстрее, если параллельно работает больше компьютеров (см. ускорение ). Если проблему решения можно решить за полилогарифмическое время с использованием полиномиального числа процессоров, то говорят, что проблема относится к классу NC . [50] Класс NC можно одинаково хорошо определить, используя формализм PRAM или логические схемы — машины PRAM могут эффективно моделировать логические схемы и наоборот. [51]
При анализе распределенных алгоритмов больше внимания обычно уделяется операциям связи, чем вычислительным этапам. Возможно, самая простая модель распределенных вычислений — это синхронная система, в которой все узлы работают синхронно. Эта модель широко известна как ЛОКАЛЬНАЯ модель. Во время каждого раунда связи все узлы параллельно (1) получают последние сообщения от своих соседей, (2) выполняют произвольные локальные вычисления и (3) отправляют новые сообщения своим соседям. В таких системах основным показателем сложности является количество раундов синхронной связи, необходимых для выполнения задачи. [52]
Эта мера сложности тесно связана с диаметром сети. Пусть D — диаметр сети. С одной стороны, любая вычислимая задача может быть тривиально решена в синхронной распределенной системе примерно за 2 D раунда связи: просто собрать всю информацию в одном месте ( D раундов), решить проблему и сообщить каждому узлу о решении ( D раундов). ).
С другой стороны, если время работы алгоритма намного меньше, чем D раундов связи, то узлы сети должны выдавать свои выходные данные, не имея возможности получить информацию об удаленных частях сети. Другими словами, узлы должны принимать глобально согласованные решения на основе информации, доступной в их локальном D-соседстве . Известны многие распределенные алгоритмы, время работы которых намного меньше D раундов, и понимание того, какие проблемы могут быть решены с помощью таких алгоритмов, является одним из центральных исследовательских вопросов в этой области. [53] Обычно в этой модели эффективным считается алгоритм, который решает проблему за полилогарифмическое время в зависимости от размера сети.
Другой часто используемой мерой является общее количество битов, передаваемых в сети (см. сложность связи ). [54] Особенности этой концепции обычно фиксируются с помощью модели CONGEST(B), которая определяется аналогично модели LOCAL, но в которой отдельные сообщения могут содержать только B бит.
Другие проблемы [ править ]
Традиционные вычислительные задачи предполагают, что пользователь задает вопрос, компьютер (или распределенная система) обрабатывает вопрос, затем выдает ответ и останавливается. Однако существуют и проблемы, в которых система обязана не останавливаться, в том числе проблема обедающих философов и другие подобные проблемы взаимного исключения . В этих задачах распределенная система должна постоянно координировать использование общих ресурсов, чтобы не возникало конфликтов или взаимоблокировок .
Существуют также фундаментальные проблемы, уникальные для распределенных вычислений, например, связанные с отказоустойчивостью . Примеры связанных проблем включают проблемы консенсуса , [55] Византийская отказоустойчивость , [56] и самостабилизация . [57]
Многие исследования также направлены на понимание асинхронной природы распределенных систем:
- Синхронизаторы можно использовать для запуска синхронных алгоритмов в асинхронных системах. [58]
- Логические часы обеспечивают причинно до того, как они произошли . -следственную связь событий [59]
- Алгоритмы синхронизации часов обеспечивают глобально согласованные физические отметки времени. [60]
Обратите внимание, что в распределенных системах задержку следует измерять через «99-й процентиль», поскольку значения «медиана» и «среднее» могут вводить в заблуждение. [61]
Выборы [ править ]
Выборы координатора (или выборы лидера ) — это процесс назначения отдельного процесса организатором некоторой задачи, распределенной между несколькими компьютерами (узлами). До начала задачи все сетевые узлы либо не знают, какой узел будет «координатором» (или лидером) задачи, либо не могут связаться с текущим координатором. Однако после запуска алгоритма выбора координатора каждый узел в сети распознает конкретный уникальный узел в качестве координатора задачи. [62]
Узлы сети общаются между собой, чтобы решить, кто из них перейдет в состояние «координатор». Для этого им нужен какой-то метод, позволяющий нарушить симметрию между ними. Например, если каждый узел имеет уникальные и сопоставимые идентификаторы, то узлы могут сравнить свои идентификаторы и решить, что узел с наивысшим идентификатором является координатором. [62]
Определение этой проблемы часто приписывают Леланну, который формализовал ее как метод создания нового токена в сети Token Ring , в которой токен был утерян. [63]
Алгоритмы выбора координатора разработаны таким образом, чтобы быть экономичными с точки зрения общего количества передаваемых байтов и времени. Алгоритм, предложенный Галлагером, Хамблетом и Спирой [64] для общих неориентированных графов оказал сильное влияние на разработку распределенных алгоритмов в целом и получил премию Дейкстры за влиятельную статью в области распределенных вычислений.
Было предложено множество других алгоритмов для различных видов сетевых графов , таких как неориентированные кольца, однонаправленные кольца, полные графы, сетки, ориентированные графы Эйлера и другие. Общий метод, который отделяет проблему семейства графов от разработки алгоритма выбора координатора, был предложен Корахом, Каттеном и Мораном. [65]
Для осуществления координации в распределенных системах используется концепция координаторов. Проблема выбора координатора состоит в том, чтобы выбрать процесс из группы процессов на разных процессорах в распределенной системе, который будет действовать в качестве центрального координатора. Существует несколько алгоритмов выборов центрального координатора. [66]
Свойства распределенных систем [ править ]
До сих пор основное внимание уделялось разработке распределенной системы, решающей заданную задачу. Дополнительной исследовательской задачей является изучение свойств данной распределенной системы. [67] [68]
Проблема остановки — аналогичный пример из области централизованных вычислений: нам дана компьютерная программа, и задача состоит в том, чтобы решить, остановится она или будет работать вечно. Проблема остановки в общем случае неразрешима , и, естественно, понять поведение компьютерной сети по меньшей мере так же сложно, как понять поведение одного компьютера. [69]
Однако существует много интересных частных случаев, которые разрешимы. В частности, можно рассуждать о поведении сети конечных автоматов. Одним из примеров является вопрос о том, может ли данная сеть взаимодействующих (асинхронных и недетерминированных) конечных автоматов зайти в тупик. Эта проблема является PSPACE-полной , [70] т. е. разрешимо, но маловероятно, что существует эффективный (централизованный, параллельный или распределенный) алгоритм, который решит проблему в случае больших сетей.
См. также [ править ]
- Модель актера
- AppScale
- БОИНК
- Мобильность кода
- Программирование потоков данных
- Децентрализованные вычисления
- Распределенный алгоритм
- Проектирование распределенного алгоритмического механизма
- Распределенный кеш
- Распределенная ГИС
- Распределенная сеть
- Распределенная операционная система
- Окончательная согласованность
- Премия Эдсгера В. Дейкстры в области распределенных вычислений
- Федерация (информационные технологии)
- Плоская районная сеть
- Туманные вычисления
- Складной@дома
- Грид-вычисления
- Инферно
- Интернет ГИС
- Джунглевые вычисления
- Многоуровневая сеть массового обслуживания
- Библиотечно-ориентированная архитектура (LOA)
- Список конференций по распределенным вычислениям
- Список волонтерских компьютерных проектов
- Проверка модели
- OpenHarmony
- ГармонияОС
- Параллельная распределенная обработка
- Модель параллельного программирования
- План 9 от Bell Labs
- Ничего не разделяемая архитектура
- Веб-ГИС
Примечания [ править ]
- ↑ Перейти обратно: Перейти обратно: а б Таненбаум, Эндрю С.; Стин, Мартен ван (2002). Распределенные системы: принципы и парадигмы . Река Аппер-Сэддл, Нью-Джерси: Пирсон Прентис Холл. ISBN 0-13-088893-1 . Архивировано из оригинала 12 августа 2020 г. Проверено 28 августа 2020 г.
- ^ «Распределенные программы». Тексты по информатике . Лондон: Спрингер Лондон. 2010. стр. 373–406. дои : 10.1007/978-1-84882-745-5_11 . ISBN 978-1-84882-744-8 . ISSN 1868-0941 .
Системы состоят из ряда физически распределенных компонентов, которые работают независимо, используя свое личное хранилище, но также время от времени обмениваются данными посредством явной передачи сообщений. Такие системы называются распределенными системами.
- ^ Дюссо и Дюссо 2016 , с. 1–2.
- ^ Форд, Нил (3 марта 2020 г.). Основы архитектуры программного обеспечения: инженерный подход (1-е изд.). О'Рейли Медиа. стр. 146–147. ISBN 978-1492043454 .
- ^ От монолита к микросервисам. Эволюционные закономерности для преобразования вашего монолита . О'Рейли Медиа. ISBN 9781492047810 .
- ^ «Распределенные программы». Тексты по информатике . Лондон: Спрингер Лондон. 2010. стр. 373–406. дои : 10.1007/978-1-84882-745-5_11 . ISBN 978-1-84882-744-8 . ISSN 1868-0941 .
Распределенные программы — это абстрактные описания распределенных систем. Распределенная программа состоит из набора процессов, которые работают одновременно и взаимодействуют посредством явной передачи сообщений. Каждый процесс может получить доступ к набору переменных, которые не пересекаются с переменными, которые могут быть изменены любым другим процессом.
- ^ Эндрюс (2000) . Долев (2000) . Гош (2007) , с. 10.
- ^ Магнони, Л. (2015). «Современный обмен сообщениями для распределенных систем (так в оригинале)» . Физический журнал: серия конференций . 608 (1): 012038. doi : 10.1088/1742-6596/608/1/012038 . ISSN 1742-6596 .
- ^ Годфри (2002) .
- ↑ Перейти обратно: Перейти обратно: а б Эндрюс (2000) , с. 291–292. Долев (2000) , с. 5.
- ^ Линч (1996) , с. 1.
- ↑ Перейти обратно: Перейти обратно: а б Гош (2007) , с. 10.
- ^ Эндрюс (2000) , стр. 8–9, 291. Долев (2000) , стр. 5. Гош (2007) , с. 3. Линч (1996) , с. xix, 1. Пелег (2000) , с. хв.
- ^ Эндрюс (2000) , с. 291. Гош (2007) , с. 3. Пелег (2000) , с. 4.
- ^ Гош (2007) , с. 3–4. Пелег (2000) , с. 1.
- ^ Гош (2007) , с. 4. Пелег (2000) , с. 2.
- ^ Гош (2007) , с. 4, 8. Линч (1996) , с. 2–3. Пелег (2000) , с. 4.
- ^ Линч (1996) , с. 2. Пелег (2000) , с. 1.
- ^ Гош (2007) , с. 7. Линч (1996) , с. xix, 2. Пелег (2000) , с. 4.
- ^ Основы архитектуры программного обеспечения: инженерный подход . О'Рейли Медиа. 2020. ISBN 978-1492043454 .
- ^ Гош (2007) , с. 10. Кейдар (2008) .
- ^ Линч (1996) , с. XIX, 1–2. Пелег (2000) , с. 1.
- ^ Пелег (2000) , с. 1.
- ^ Пападимитриу (1994) , Глава 15. Кейдар (2008) .
- ^ См. ссылки во Введении .
- ^ Бенталеб, А.; Ифань, Л.; Синь, Дж.; и др. (2016). «Параллельные и распределенные алгоритмы» (PDF) . Национальный университет Сингапура. Архивировано (PDF) из оригинала 26 марта 2017 г. Проверено 20 июля 2018 г.
- ^ Эндрюс (2000) , с. 348.
- ^ Эндрюс (2000) , с. 32.
- ^ Питер (2004) , История электронной почты . Архивировано 15 апреля 2009 г. в Wayback Machine .
- ^ Бэнкс, М. (2012). На пути к Интернету: Тайная история Интернета и его основателей . Апресс. стр. 44–5. ISBN 9781430250746 . Архивировано из оригинала 20 января 2023 г. Проверено 20 июля 2018 г.
- ^ Тел, Г. (2000). Введение в распределенные алгоритмы . Издательство Кембриджского университета. стр. 35–36. ISBN 9780521794831 . Архивировано из оригинала 20 января 2023 г. Проверено 20 июля 2018 г.
- ^ Олидал, М.; Ярош, Ю.; Шварц, Дж.; и др. (2006). «Эволюционный дизайн расписаний связи OAB и AAB для межсетевых сетей». В Ротлауфе, Ф.; Бранке, Дж.; Каньони, С. (ред.). Применение эволюционных вычислений . Springer Science & Business Media. стр. 267–78. ISBN 9783540332374 .
- ^ «Системы реального времени и распределенные вычисления» (PDF) . ISSN 2278-0661 . Архивировано из оригинала (PDF) 10 января 2017 г. Проверено 9 января 2017 г.
{{cite journal}}: Для цитирования журнала требуется|journal=( помощь ) - ^ Винья П., Кейси MJ. Эпоха криптовалют: как Биткойн и блокчейн бросают вызов глобальному экономическому порядку. St. Martin's Press, 27 января 2015 г. ISBN 9781250065636
- ^ Куанг Хиеу Ву; Михай Лупу; Бенг Чин Оой (2010). Одноранговые вычисления: принципы и приложения . Гейдельберг: Спрингер. п. 16. ISBN 9783642035135 . OCLC 663093862 .
- ^ Линд П., Альм М. (2006), «Виртуальная химическая система, ориентированная на базу данных», J Chem Inf Model , 46 (3): 1034–9, doi : 10.1021/ci050360b , PMID 16711722 .
- ^ Чиу, Г (1990). «Модель оптимального распределения баз данных в распределенных вычислительных системах». Слушания. IEEE INFOCOM'90: Девятая ежегодная совместная конференция обществ компьютеров и коммуникаций IEEE .
- ^ Эльмасри и Навате (2000) , раздел 24.1.2.
- ^ Эндрюс (2000) , с. 10–11. Гош (2007) , с. 4–6. Линч (1996) , с. xix, 1. Пелег (2000) , с. хв. Эльмасри и Навате (2000) , раздел 24.
- ^ Османн, Дж. (2019). «Экономичная параллельная обработка задач нерегулярной структуры в средах облачных вычислений». Журнал кластерных вычислений . 22 (3): 887–909. дои : 10.1007/s10586-018-2879-3 . S2CID 54447518 .
- ^ Тоомарян, НБ; Бархен, Дж.; Гулати, С. (1992). «Нейронные сети для робототехнических приложений реального времени» . В Фиджани, А.; Бейчи, А. (ред.). Системы параллельных вычислений для робототехники: алгоритмы и архитектуры . Всемирная научная. п. 214. ИСБН 9789814506175 . Архивировано из оригинала 01 августа 2020 г. Проверено 20 июля 2018 г.
- ^ Сэвидж, Дж. Э. (1998). Модели вычислений: исследование возможностей вычислений . Эддисон Уэсли. п. 209. ИСБН 9780201895391 .
- ^ Кормен, Лейзерсон и Ривест (1990) , Раздел 30.
- ^ Херлихи и Шавит (2008) , главы 2–6.
- ^ Линч (1996)
- ^ Кормен, Лейзерсон и Ривест (1990) , разделы 28 и 29.
- ↑ Перейти обратно: Перейти обратно: а б с ТУЛСИРАМДЖИ ГАЙКВАД-ПАТИЛ Инженерно-технологический колледж,НагпурДепартамент информационных технологийВведение в распределенные системы [1]
- ^ Коул и Вишкин (1986) . Кормен, Лейзерсон и Ривест (1990) , раздел 30.5.
- ^ Эндрюс (2000) , с. ix.
- ^ Арора и Барак (2009) , Раздел 6.7. Пападимитриу (1994) , раздел 15.3.
- ^ Пападимитриу (1994) , раздел 15.2.
- ^ Линч (1996) , с. 17–23.
- ^ Пелег (2000) , разделы 2.3 и 7. Линиал (1992) . Наор и Стокмейер (1995) .
- ^ Шнайдер, Дж.; Ваттенхофер, Р. (2011). «Торговый бит, сообщение и временная сложность распределенных алгоритмов» . В Пелеге, Д. (ред.). Распределенные вычисления . Springer Science & Business Media. стр. 51–65. ISBN 9783642240997 . Архивировано из оригинала 01 августа 2020 г. Проверено 20 июля 2018 г.
- ^ Линч (1996) , разделы 5–7. Гош (2007) , Глава 13.
- ^ Линч (1996) , с. 99–102. Гош (2007) , с. 192–193.
- ^ Долев (2000) . Гош (2007) , Глава 17.
- ^ Линч (1996) , Раздел 16. Пелег (2000) , Раздел 6.
- ^ Линч (1996) , раздел 18. Гош (2007) , разделы 6.2–6.3.
- ^ Гош (2007) , Раздел 6.4.
- ^ Основы приложений с интенсивным использованием данных Крупномасштабный анализ данных «под капотом» . 2021. ISBN 9781119713012 .
- ↑ Перейти обратно: Перейти обратно: а б Халой, С. (2015). Основы Apache ZooKeeper . Packt Publishing Ltd., стр. 100–101. ISBN 9781784398323 . Архивировано из оригинала 20 января 2023 г. Проверено 20 июля 2018 г.
- ^ ЛеЛанн, Г. (1977). «Распределенные системы – к формальному подходу». Обработка информации . 77 : 155·160 – через Elsevier.
- ^ Р.Г. Галлагер , П.А. Хамблет и П.М. Спира (январь 1983 г.). «Распределенный алгоритм для остовных деревьев минимального веса» (PDF) . Транзакции ACM в языках и системах программирования . 5 (1): 66–77. дои : 10.1145/357195.357200 . S2CID 2758285 . Архивировано (PDF) из оригинала 26 сентября 2017 г.
{{cite journal}}: CS1 maint: несколько имен: список авторов ( ссылка ) - ^ Корах, Ефрем; Каттен, Шей ; Моран, Шломо (1990). «Модульная методика разработки эффективных распределенных алгоритмов поиска лидеров» (PDF) . Транзакции ACM в языках и системах программирования . 12 (1): 84–101. CiteSeerX 10.1.1.139.7342 . дои : 10.1145/77606.77610 . S2CID 9175968 . Архивировано (PDF) из оригинала 18 апреля 2007 г.
- ^ Гамильтон, Ховард. «Распределенные алгоритмы» . Архивировано из оригинала 24 ноября 2012 г. Проверено 03 марта 2013 г.
- ^ «Основные нерешенные проблемы в распределенных системах?» . cstheory.stackexchange.com . Архивировано из оригинала 20 января 2023 года . Проверено 16 марта 2018 г.
- ^ «Как большие данные и распределенные системы решают традиционные проблемы масштабируемости» . theserverside.com . Архивировано из оригинала 17 марта 2018 года . Проверено 16 марта 2018 г.
- ^ Свозил, К. (2011). «Индетерминизм и случайность через физику» . В Гекторе З. (ред.). Случайность посредством вычислений: несколько ответов, больше вопросов . Всемирная научная. стр. 112–3. ISBN 9789814462631 . Архивировано из оригинала 01 августа 2020 г. Проверено 20 июля 2018 г.
- ^ Пападимитриу (1994) , раздел 19.3.
Ссылки [ править ]
- Книги
- Эндрюс, Грегори Р. (2000), Основы многопоточного, параллельного и распределенного программирования , Аддисон-Уэсли , ISBN 978-0-201-35752-3 .
- Арора, Санджив ; Барак, Воаз (2009), Сложность вычислений – современный подход , Кембридж , ISBN 978-0-521-42426-4 .
- Кормен, Томас Х .; Лейзерсон, Чарльз Э .; Ривест, Рональд Л. (1990), Введение в алгоритмы (1-е изд.), MIT Press , ISBN 978-0-262-03141-7 .
- Долев, Шломи (2000), Самостабилизация , MIT Press , ISBN 978-0-262-04178-2 .
- Эльмасри, Рамез; Навате, Шамкант Б. (2000), Основы систем баз данных (3-е изд.), Аддисон – Уэсли , ISBN 978-0-201-54263-9 .
- Гош, Сукумар (2007), Распределенные системы – алгоритмический подход , Chapman & Hall/CRC, ISBN 978-1-58488-564-1 .
- Линч, Нэнси А. (1996), Распределенные алгоритмы , Морган Кауфманн , ISBN 978-1-55860-348-6 .
- Херлихи, Морис П .; Шавит, Нир Н. (2008), Искусство многопроцессорного программирования , Морган Кауфманн , ISBN 978-0-12-370591-4 .
- Пападимитриу, Христос Х. (1994), Вычислительная сложность , Аддисон – Уэсли , ISBN 978-0-201-53082-7 .
- Пелег, Дэвид (2000), Распределенные вычисления: локально-чувствительный подход , SIAM , ISBN 978-0-89871-464-7 , заархивировано из оригинала 6 августа 2009 г. , получено 16 июля 2009 г.
- Статьи
- Коул, Ричард; Вишкин, Узи (1986), «Детерминистическое подбрасывание монеты с применением оптимального ранжирования параллельных списков», Information and Control , 70 (1): 32–53, doi : 10.1016/S0019-9958(86)80023-7 .
- Кейдар, Идит (2008), «Колонка 32 по распределенным вычислениям – Обзор года» , ACM SIGACT News , 39 (4): 53–54, CiteSeerX 10.1.1.116.1285 , doi : 10.1145/1466390.1466402 , S2CID 7607391 , заархивировано из оригинал 16 января 2014 г. , получен 20 августа 2009 г.
- Линиал, Натан (1992), «Локальность в алгоритмах распределенных графов», SIAM Journal on Computing , 21 (1): 193–201, CiteSeerX 10.1.1.471.6378 , doi : 10.1137/0221015 .
- Наор, Мони ; Стокмейер, Ларри (1995), «Что можно вычислить локально?» (PDF) , SIAM Journal on Computing , 24 (6): 1259–1277, CiteSeerX 10.1.1.29.669 , doi : 10.1137/S0097539793254571 , заархивировано (PDF) из оригинала 08 января 2013 г.
- Веб-сайты
- Годфри, Билл (2002). «Букварь по распределенным вычислениям» . Архивировано из оригинала 13 мая 2021 г. Проверено 13 мая 2021 г.
- Питер, Ян (2004). «История Интернета Яна Питера» . Архивировано из оригинала 20 января 2010 г. Проверено 4 августа 2009 г.
Дальнейшее чтение [ править ]
- Книги
- Аттия, Хагит и Дженнифер Уэлч (2004), Распределенные вычисления: основы, моделирование и дополнительные темы , Wiley-Interscience ISBN 0-471-45324-2 .
- Кристиан Кашен; Рашид Геррауи; Луис Родригес (2011), Введение в надежное и безопасное распределенное программирование (2-е изд.), Springer, Bibcode : 2011itra.book.....C , ISBN 978-3-642-15259-7
- Кулурис, Джордж; и др. (2011), Распределенные системы: концепции и проектирование (5-е издание) , Аддисон-Уэсли ISBN 0-132-14301-1 .
- Фабер, Джим (1998), Распределенные вычисления на Java , О'Рейли, заархивировано из оригинала 24 августа 2010 г. , получено 29 сентября 2010 г .: Распределенные вычисления на Java, Джим Фабер, 1998. Архивировано 24 августа 2010 г. в Wayback. Машина
- Гарг, Виджей К. (2002), Элементы распределенных вычислений , Wiley-IEEE Press ISBN 0-471-03600-5 .
- Тел, Джерард (1994), Введение в распределенные алгоритмы , издательство Кембриджского университета.
- Чанди, Мани ; и др. (1988), Разработка параллельных программ , Аддисон-Уэсли ISBN 0201058669
- Дюссо, Ремзи Х.; Дюссо, Андреа (2016). Операционные системы: три простых части, глава 48 Распределенные системы (PDF) . Архивировано из оригинала (PDF) 31 августа 2021 года . Проверено 8 октября 2021 г.
- Статьи
- Кейдар, Идит; Райсбаум, Серджио, ред. (2000–2009), «Колонка распределенных вычислений» , ACM SIGACT News , заархивировано из оригинала 16 января 2014 г. , получено 16 августа 2009 г.
- Биррелл, AD; Левин Р.; Шредер, доктор медицины; Нидхэм, Р.М. (апрель 1982 г.). «Виноградная лоза: упражнение в распределенных вычислениях» (PDF) . Коммуникации АКМ . 25 (4): 260–274. дои : 10.1145/358468.358487 . S2CID 16066616 . Архивировано (PDF) из оригинала 30 июля 2016 г.
- Доклады конференции
- Родригес, Карлос; Вильягра, Маркос; Баран, Бенджамин (2007). «Асинхронные командные алгоритмы для логической выполнимости». 2007 2-я Биомодели сетевых, информационных и вычислительных систем . стр. 66–69. дои : 10.1109/BIMNICS.2007.4610083 . S2CID 15185219 .
Внешние ссылки [ править ]
 СМИ, связанные с распределенными вычислениями, на Викискладе?
СМИ, связанные с распределенными вычислениями, на Викискладе? - Распределенные вычисления в Curlie
- Журналы распределенных вычислений в Curlie