Таксономия Флинна
Таксономия Флинна — это классификация компьютерных архитектур , предложенная Майклом Дж. Флинном в 1966 году. [ 1 ] и продлен в 1972 г. [ 2 ] Система классификации прижилась и использовалась как инструмент при проектировании современных процессоров и их функциональных возможностей. С появлением многопроцессорных центральных процессоров (ЦП) контекст мультипрограммирования развился как расширение системы классификации. Векторная обработка , охватываемая таксономией Дункана , [ 3 ] отсутствует в работе Флинна, поскольку Cray-1 был выпущен в 1977 году: вторая статья Флинна была опубликована в 1972 году.
Классификации
[ редактировать ]Четыре первоначальные классификации, определенные Флинном, основаны на количестве одновременных потоков инструкций (или управления) и потоков данных, доступных в архитектуре. [ 4 ] Флинн определил три дополнительные подкатегории SIMD в 1972 году. [ 2 ]
| Таксономия Флинна |
|---|
| Единый поток данных |
| Несколько потоков данных |
| Подкатегории SIMD [ 5 ] |
| См. также |
Один поток инструкций, один поток данных (SISD)
[ редактировать ]Последовательный компьютер, который не использует параллелизм ни в потоках команд, ни в потоках данных. Одиночный блок управления (CU) извлекает из памяти один поток команд (IS). Затем CU генерирует соответствующие сигналы управления, чтобы предписать одному обрабатывающему элементу (PE) работать с одним потоком данных (DS), то есть выполнять одну операцию за раз.
Примерами архитектур SISD являются традиционные однопроцессорные машины, такие как старые персональные компьютеры (ПК) (к 2010 году многие ПК имели несколько ядер) и мэйнфреймы .
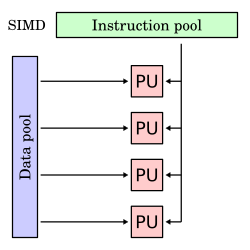
Один поток инструкций, несколько потоков данных (SIMD)
[ редактировать ]Одна инструкция одновременно применяется к нескольким различным потокам данных. Инструкции могут выполняться последовательно, например, по конвейеру, или параллельно несколькими функциональными блоками. В статье Флинна 1972 года SIMD подразделяется на три дополнительные категории: [ 2 ]
- Процессор массива . Они получают одну (одну и ту же) инструкцию, но каждый параллельный процессор имеет свою отдельную память и файл регистров.
- Конвейерный процессор . Они получают одну (одну и ту же) инструкцию, но затем считывают данные из центрального ресурса, каждый обрабатывает фрагменты этих данных, а затем записывает результаты обратно в один и тот же центральный ресурс. На рисунке 5 статьи Флинна 1972 года этим ресурсом является основная память: для современных процессоров этим ресурсом теперь чаще всего является файл регистров.
- Ассоциативный процессор . Они получают одну (одну и ту же) инструкцию, но в каждом параллельном процессоре независимое принимается решение на основе локальных для устройства данных о том, следует ли выполнять выполнение или пропустить его. В современной терминологии это известно как «предикатный» (маскированный) SIMD.
Процессор массива
[ редактировать ]Современный термин для массивного процессора — « одна инструкция, несколько потоков » (SIMT). Это отдельная классификация в таксономии Флинна 1972 года как подкатегория SIMD. Его можно идентифицировать по параллельным подэлементам, имеющим свой собственный независимый регистровый файл и память (кэш и память данных). В оригинальных статьях Флинна приводятся два исторических примера процессоров SIMT: SOLOMON и ILLIAC IV .
Nvidia обычно использует этот термин в своих маркетинговых материалах и технической документации, где доказывает новизну своей архитектуры. [ 6 ] SOLOMON старше Nvidia более чем на 60 лет.
Ассоциативный строковый процессор Aspex Microelectronics (ASP) [ 7 ] в своих маркетинговых материалах классифицировал себя как «массивный широкий SIMD», но имел ALU на уровне битов и предикацию на уровне битов (таксономия Флинна: ассоциативная обработка), а каждый из 4096 процессоров имел свои собственные регистры и память (таксономия Флинна: обработка массивов) . Linedancer, выпущенный в 2010 году, содержал 4096 2-битных предикатных SIMD ALU, каждый из которых имел собственную адресуемую по содержимому память , и был способен выполнять 800 миллиардов инструкций в секунду. [ 8 ] Процессор SIMT с ассоциативным массивом ASP от Aspex появился на 20 лет раньше NVIDIA. [ 9 ] [ 10 ]
Конвейерный процессор
[ редактировать ]В то время, когда Флинн писал свою статью в 1972 году, многие системы использовали оперативную память в качестве ресурса, из которого конвейеры считывали и записывали данные. Когда ресурсом, из которого все «конвейеры» читают и записывают, является файл регистров, а не основная память, возникают современные варианты SIMD. Примеры включают Altivec , NEON и AVX .
Альтернативное название этого типа SIMD на основе регистров — «упакованный SIMD». [ 11 ] и еще один — SIMD в регистре (SWAR) . Когда применяется предикация, она становится ассоциативной обработкой (ниже).
Ассоциативный процессор
[ редактировать ]Современный термин для обозначения ассоциативного процессора — « предикатный » (или замаскированный) SIMD. Примеры включают AVX-512 .
Некоторые современные конструкции ( в частности, графические процессоры ) используют функции более чем одной из этих подкатегорий: современные графические процессоры являются SIMT, но также являются ассоциативными, т.е. каждый обрабатывающий элемент в массиве SIMT также предикативен.
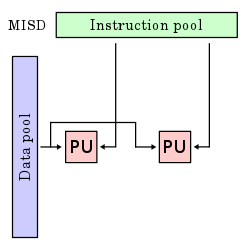
Несколько потоков инструкций, один поток данных (MISD)
[ редактировать ]Несколько инструкций работают с одним потоком данных. Это необычная архитектура, которая обычно используется для обеспечения отказоустойчивости. Гетерогенные системы работают с одним и тем же потоком данных и должны согласовывать результаты. Примеры включают компьютер управления полетом космического корабля "Шаттл" . [ 12 ]
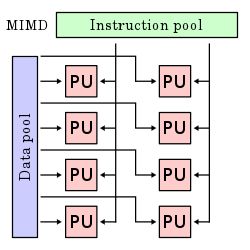
Несколько потоков инструкций, несколько потоков данных (MIMD)
[ редактировать ]Несколько автономных процессоров одновременно выполняют разные инструкции для разных данных. Архитектуры MIMD включают многоядерные суперскалярные процессоры и распределенные системы , использующие либо одно общее пространство памяти, либо распределенное пространство памяти.
Диаграмма сравнения классификаций
[ редактировать ]Эти четыре архитектуры визуально показаны ниже. Каждый процессор (PU) показан для одноядерного или многоядерного компьютера:

Дальнейшие подразделения
[ редактировать ]По состоянию на 2006 год [update]Все суперкомпьютеры из первой десятки и большинство из топ-500 суперкомпьютеров основаны на архитектуре MIMD.
Хотя это не является частью работы Флинна, некоторые разделяют категорию MIMD на две категории, указанные ниже: [ 13 ] [ 14 ] [ 15 ] [ 16 ] [ 17 ] иногда рассматриваются даже дальнейшие подразделения. [ 18 ]
Одна программа, несколько потоков данных (SPMD)
[ редактировать ]Несколько автономных процессоров одновременно выполняют одну и ту же программу (но в независимых точках, а не в синхронном режиме , который навязывает SIMD) над разными данными. Также называется «один процесс, несколько данных». [ 17 ] - использование этой терминологии для SPMD технически неверно, поскольку SPMD представляет собой модель параллельного выполнения и предполагает выполнение программы несколькими взаимодействующими процессорами. SPMD — наиболее распространенный стиль явного параллельного программирования. [ 19 ] Модель SPMD и этот термин были предложены Фредерикой Дарема из команды RP3. [ 20 ]
Несколько программ, несколько потоков данных (MPMD)
[ редактировать ]Несколько автономных процессоров одновременно выполняют как минимум две независимые программы. В контексте высокопроизводительных вычислений такие системы часто выбирают один узел в качестве «хоста» («явная модель программирования хост/узел») или «менеджера» (стратегия «Менеджер/Работник»), который запускает одну программу, передающую данные на ферму. все остальные узлы, на которых выполняется вторая программа. Эти другие узлы затем возвращают свои результаты непосредственно менеджеру. Примером может служить игровая консоль Sony PlayStation 3 с процессором SPU/PPU .
MPMD распространен в контекстах, не связанных с HPC. Например, система сборки make может параллельно создавать несколько зависимостей, используя целевые программы в дополнение к самому исполняемому файлу make. MPMD также часто принимает форму конвейеров. Простая команда оболочки Unix, например ls | команда "А" | more запускает три процесса, одновременно запускающие отдельные программы, при этом выходные данные одного используются в качестве входных данных для следующего.
Оба они отличаются от явного параллельного программирования, используемого в HPC, тем, что отдельные программы представляют собой общие строительные блоки, а не реализуют часть конкретного параллельного алгоритма. При конвейерном подходе объем доступного параллелизма не увеличивается с размером набора данных.
См. также
[ редактировать ]- Классификация Фэна
- дилеров Система классификации (ECS)
Ссылки
[ редактировать ]- ^ Флинн, Майкл Дж. (декабрь 1966 г.). «Сверхбыстродействующие вычислительные системы» . Труды IEEE . 54 (12): 1901–1909. дои : 10.1109/PROC.1966.5273 .
- ^ Перейти обратно: а б с Флинн, Майкл Дж. (сентябрь 1972 г.). «Некоторые компьютерные организации и их эффективность» (PDF) . Транзакции IEEE на компьютерах . С-21 (9): 948–960. дои : 10.1109/TC.1972.5009071 . S2CID 18573685 .
- ^ Дункан, Ральф (февраль 1990 г.). «Обзор параллельных компьютерных архитектур» (PDF) . Компьютер . 23 (2): 5–16. дои : 10.1109/2.44900 . S2CID 15036692 . Архивировано (PDF) из оригинала 18 июля 2018 г. Проверено 18 июля 2018 г.
- ^ «Параллелизм на уровне данных в векторных, SIMD и графических архитектурах» (PDF) . 12 ноября 2013 г.
- ^ Флинн, Майкл Дж. (сентябрь 1972 г.). «Некоторые компьютерные организации и их эффективность» (PDF) . Транзакции IEEE на компьютерах . С-21 (9): 948–960. дои : 10.1109/TC.1972.5009071 .
- ^ «Вычислительная архитектура CUDA нового поколения NVIDIA: Fermi» (PDF) . Нвидия .
- ^ Леа, РМ (1988). «ASP: экономичный параллельный микрокомпьютер». IEEE микро . 8 (5): 10–29. дои : 10.1109/40.87518 . S2CID 25901856 .
- ^ «Linedancer HD – Обзор» . Аспекс Полупроводник . Архивировано из оригинала 13 октября 2006 года.
- ^ Крикелис, А. (1988). Искусственная нейронная сеть на основе массово-параллельной ассоциативной архитектуры . Международная конференция по нейронным сетям. Дордрехт: Спрингер . дои : 10.1007/978-94-009-0643-3_39 . ISBN 978-94-009-0643-3 .
- ^ Одор, Геза; Крикелис, Арги; Вестергомби, Дьёрдь; Рорбах, Франсуа. «Эффективное моделирование Монте-Карло на архитектуре массово-параллельной обработки ассоциативных строк System-V» (PDF) .
- ^ Мияока, Ю.; Чой, Дж.; Тогава, Н.; Янагисава, М.; Оцуки, Т. (2002). Алгоритм формирования аппаратного блока для синтеза процессорного ядра с упакованными инструкциями типа SIMD . Азиатско-Тихоокеанская конференция по схемам и системам. стр. 171–176. дои : 10.1109/APCCAS.2002.1114930 . hdl : 2065/10689 . ISBN 0-7803-7690-0 .
- ^ Спектор, А.; Гиффорд, Д. (сентябрь 1984 г.). «Основная компьютерная система космического корабля» . Коммуникации АКМ . 27 (9): 872–900. дои : 10.1145/358234.358246 . S2CID 39724471 .
- ^ «Однопрограммный множественный поток данных (SPMD)» . Llnl.gov. Архивировано из оригинала 4 июня 2004 г. Проверено 9 декабря 2013 г.
- ^ «Требования к программированию для компиляции, построения и выполнения заданий» . Руководство пользователя Lightning . Архивировано из оригинала 1 сентября 2006 года.
- ^ «Виртуальная мастерская СТС» . Web0.tc.cornell.edu . Проверено 9 декабря 2013 г.
- ^ «NIST SP2 Primer: программирование с распределенной памятью» . Math.nist.gov. Архивировано из оригинала 13 декабря 2013 г. Проверено 9 декабря 2013 г.
- ^ Перейти обратно: а б «Понимание параллельного управления заданиями и передачи сообщений в системах IBM SP» . Архивировано из оригинала 3 февраля 2007 года.
- ^ «9.2 Стратегии» . Программирование распределенной памяти . Архивировано из оригинала 10 сентября 2006 года.
- ^ «Одна программа, несколько данных» . Nist.gov. 17 декабря 2004 г. Проверено 9 декабря 2013 г.
- ^ Дарема, Фредерика ; Джордж, Дэвид А.; Нортон, В. Алан; Пфистер, Грегори Ф. (1988). «Вычислительная модель с одной программой и несколькими данными для EPEX/FORTRAN». Параллельные вычисления . 7 (1): 11–24. дои : 10.1016/0167-8191(88)90094-4 .
| Общий | |
|---|---|
| Уровни | |
| Многопоточность | |
| Теория | |
| Элементы | |
| Координация | |
| Программирование | |
| Аппаратное обеспечение | |
| API | |
| Проблемы | |