ДРУГОЙ
В этой статье есть несколько проблем. Пожалуйста, помогите улучшить его или обсудите эти проблемы на странице обсуждения . ( Узнайте, как и когда удалять эти шаблонные сообщения )
|
| Разработчик(и) | Нвидиа |
|---|---|
| Первоначальный выпуск | 23 июня 2007 г |
| Стабильная версия | 12.4.1
/ 12 апреля 2024 г |
| Операционная система | Винда , Линукс |
| Платформа | Поддерживаемые графические процессоры |
| Тип | ГПГПУ |
| Лицензия | Собственный |
| Веб-сайт | разработчик |
Compute Unified Device Architecture (CUDA) — это запатентованная [1] параллельных вычислений Платформа и интерфейс прикладного программирования (API), который позволяет программному обеспечению использовать определенные типы графических процессоров (GPU) для ускоренной обработки общего назначения. Этот подход называется вычислениями общего назначения на графических процессорах ( GPGPU ). CUDA API и его среда выполнения. CUDA API — это расширение языка программирования C, которое добавляет возможность указывать параллелизм на уровне потоков в C, а также указывать операции, специфичные для устройства графического процессора (например, перемещение данных между ЦП и графическим процессором). [2] графического процессора CUDA — это программный уровень, который предоставляет прямой доступ к набору виртуальных инструкций и параллельным вычислительным элементам для выполнения вычислительных ядер . [3] Помимо драйверов и ядер среды выполнения, платформа CUDA включает в себя компиляторы, библиотеки и инструменты разработчика, помогающие программистам ускорить работу своих приложений.
CUDA предназначен для работы с такими языками программирования, как C , C++ , Fortran и Python . Эта доступность облегчает специалистам по параллельному программированию использование ресурсов графического процессора, в отличие от предыдущих API, таких как Direct3D и OpenGL , которые требовали продвинутых навыков графического программирования. [4] Графические процессоры на базе CUDA также поддерживают такие платформы программирования, как OpenMP , OpenACC и OpenCL . [5] [3]
CUDA была создана Nvidia в 2006 году. [6] Когда оно было впервые представлено, это название было аббревиатурой от Compute Unified Device Architecture. [7] но позже Nvidia отказалась от общепринятого использования этой аббревиатуры и больше не использует ее. [ когда? ]
Предыстория [ править ]
Графический процессор (GPU) в качестве специализированного компьютерного процессора отвечает требованиям в реальном времени высокого разрешения трехмерной графики ресурсоемких задач обработки . К 2012 году графические процессоры превратились в высокопараллельные многоядерные системы, позволяющие эффективно манипулировать большими блоками данных. общего назначения Эта конструкция более эффективна, чем центральный процессор (ЦП) для алгоритмов в ситуациях, когда обработка больших блоков данных выполняется параллельно, например:
- криптографические хэш-функции
- машинное обучение
- молекулярно-динамическое моделирование
- физические движки
Ян Бак, находясь в Стэнфорде в 2000 году, создал игровую установку 8K с использованием 32 карт GeForce, а затем получил грант DARPA на выполнение параллельного программирования общего назначения на графических процессорах . Затем он присоединился к Nvidia, где с 2004 года курирует разработку CUDA. Продвигая CUDA, Дженсен Хуанг стремился к тому, чтобы графические процессоры Nvidia стали основным оборудованием для научных вычислений. CUDA был выпущен в 2006 году. Примерно в 2015 году фокус CUDA сместился на нейронные сети. [8]
Онтология [ править ]
В следующей таблице представлено неточное описание онтологии платформы CUDA.
| память (аппаратная) | память (код или область видимости переменных ) | вычисление (аппаратное обеспечение) | вычисление (синтаксис кода) | вычисление (семантика кода) |
|---|---|---|---|---|
| БАРАН | переменные, отличные от CUDA | хозяин | программа | один обычный звонок |
| Видеопамять , кэш L2 графического процессора | глобальный, константный, текстура | устройство | сетка | одновременный вызов одной и той же подпрограммы на многих процессорах |
| Кэш L1 графического процессора | локальный, общий | SM («потоковый мультипроцессор») | блокировать | индивидуальный вызов подпрограммы |
| деформация = 32 нити | SIMD-инструкции | |||
| Кэш графического процессора L0, регистрация | поток (он же «SP», «потоковый процессор», «ядро cuda», но эти имена сейчас устарели) | аналогично отдельным скалярным операциям внутри векторной операции |
Способности программирования [ править ]
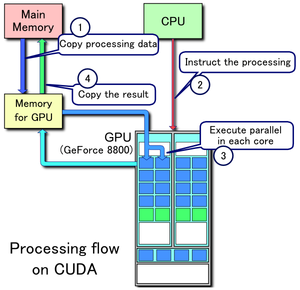
- Копирование данных из основной памяти в память графического процессора
- ЦП запускает вычислительное ядро графического процессора
- Ядра CUDA графического процессора выполняют ядро параллельно
- Скопируйте полученные данные из памяти графического процессора в основную память.
Платформа CUDA доступна разработчикам программного обеспечения через библиотеки с ускорением CUDA, директивы компилятора , такие как OpenACC , и расширения стандартных языков программирования, включая C , C++ , Fortran и Python . Программисты C/C++ могут использовать «CUDA C/C++», скомпилированный в PTX с помощью nvcc от Nvidia , компилятора C/C++ на базе LLVM или самого clang. [9] Программисты на Фортране могут использовать «CUDA Fortran», скомпилированный с помощью компилятора PGI CUDA Fortran от The Portland Group . [ нужно обновить ] Программисты Python могут использовать библиотеку cuNumeric для ускорения приложений на графических процессорах Nvidia.
Помимо библиотек, директив компилятора, CUDA C/C++ и CUDA Fortran, платформа CUDA поддерживает другие вычислительные интерфейсы, включая Khronos Group компании OpenCL , [10] от Microsoft DirectCompute , вычислительный шейдер OpenGL и C++ AMP . [11] Сторонние оболочки также доступны для Python , Perl , Fortran, Java , Ruby , Lua , Common Lisp , Haskell , R , MATLAB , IDL , Julia и встроенная поддержка в Mathematica .
В индустрии компьютерных игр графические процессоры используются для рендеринга графики и для расчетов физики игр (физические эффекты, такие как мусор, дым, огонь, жидкости); примеры включают PhysX и Bullet . CUDA также используется для ускорения неграфических приложений в вычислительной биологии , криптографии и других областях на порядок и более. [12] [13] [14] [15] [16]
CUDA предоставляет как API CUDA низкого уровня (API драйвера , не с одним исходным кодом), так и API более высокого уровня ( API среды выполнения CUDA , с одним исходным кодом). Первоначальный пакет CUDA SDK был обнародован 15 февраля 2007 года для Microsoft Windows и Linux . Поддержка Mac OS X была добавлена позже в версии 2.0. [17] которая заменяет бета-версию, выпущенную 14 февраля 2008 г. [18] CUDA работает со всеми графическими процессорами Nvidia, начиная с серии G8x, включая GeForce , Quadro и линейку Tesla . CUDA совместим с большинством стандартных операционных систем.
CUDA 8.0 поставляется со следующими библиотеками (для компиляции и выполнения, в алфавитном порядке):
- cuBLAS — библиотека базовых подпрограмм линейной алгебры CUDA
- CUDART — библиотека времени выполнения CUDA
- cuFFT — библиотека быстрого преобразования Фурье CUDA
- cuRAND — библиотека генерации случайных чисел CUDA
- cuSOLVER — коллекция плотных и разреженных прямых решателей на основе CUDA.
- cuSPARSE — библиотека разреженных матриц CUDA
- NPP — библиотека NVIDIA Performance Primitives
- nvGRAPH — библиотека NVIDIA Graph Analytics.
- NVML — библиотека управления NVIDIA
- NVRTC — библиотека компиляции среды выполнения NVIDIA для CUDA C++
CUDA 8.0 поставляется со следующими программными компонентами:
- nView – программное обеспечение для управления настольными компьютерами NVIDIA nView
- NVWMI — набор инструментов NVIDIA для управления предприятием
- GameWorks PhysX — многоплатформенный игровой физический движок.
CUDA 9.0–9.2 поставляется со следующими компонентами:
- CUTLASS 1.0 – собственные алгоритмы линейной алгебры,
- Видеодекодер NVIDIA устарел в CUDA 9.2; теперь он доступен в NVIDIA Video Codec SDK.
CUDA 10 поставляется со следующими компонентами:
- nvJPEG – гибридная (ЦП и ГП) обработка JPEG
CUDA 11.0–11.8 поставляется со следующими компонентами: [19] [20] [21] [22]
- CUB — новая из поддерживаемых библиотек C++.
- Поддержка нескольких экземпляров графического процессора MIG
- nvJPEG2000 – JPEG 2000 кодер и декодер
Преимущества [ править ]
CUDA имеет ряд преимуществ перед традиционными вычислениями общего назначения на графических процессорах (GPGPU) с использованием графических API:
- Разбросанное чтение — код может читать из произвольных адресов в памяти.
- Единая виртуальная память (CUDA 4.0 и выше)
- Единая память (CUDA 6.0 и выше)
- Общая память . CUDA предоставляет быструю область общей памяти, которую можно использовать совместно между потоками. Его можно использовать в качестве кэша, управляемого пользователем, обеспечивая более высокую пропускную способность, чем это возможно при использовании поиска текстур. [23]
- Ускоренная загрузка и обратная связь с графическим процессором.
- Полная поддержка целочисленных и побитовых операций, включая целочисленный поиск текстур.
Ограничения [ править ]
- Будь то главный компьютер или устройство графического процессора, весь исходный код CUDA теперь обрабатывается в соответствии с правилами синтаксиса C++. [24] Так было не всегда. Более ранние версии CUDA были основаны на правилах синтаксиса C. [25] Как и в более общем случае компиляции кода C с помощью компилятора C++, возможно, что старый исходный код CUDA в стиле C либо не скомпилируется, либо не будет вести себя так, как изначально предполагалось.
- Взаимодействие с языками рендеринга, такими как OpenGL, является односторонним: OpenGL имеет доступ к зарегистрированной памяти CUDA, но CUDA не имеет доступа к памяти OpenGL.
- Копирование между памятью хоста и устройства может привести к снижению производительности из-за пропускной способности системной шины и задержки (частично это можно облегчить с помощью асинхронной передачи памяти, обрабатываемой механизмом DMA графического процессора).
- Для достижения наилучшей производительности потоки должны выполняться группами по меньшей мере по 32, при этом общее количество потоков исчисляется тысячами. Ветвления в программном коде существенно не влияют на производительность при условии, что каждый из 32 потоков проходит один и тот же путь выполнения; Модель выполнения SIMD становится существенным ограничением для любой по своей сути расходящейся задачи (например, перемещения разделения пространства структуры данных во время трассировки лучей ).
- Для современных версий недоступна эмуляция или резервная функциональность.
- Действительный C++ иногда может быть помечен и препятствовать компиляции из-за того, как компилятор подходит к оптимизации с учетом ограничений целевого графического процессора. [ нужна ссылка ]
- C++ Информация о типе времени выполнения (RTTI) и обработка исключений в стиле C++ поддерживаются только в коде узла, а не в коде устройства.
- В устройствах с одинарной точностью на устройствах с вычислительными возможностями CUDA 1.x первого поколения ненормальные числа не поддерживаются и вместо этого сбрасываются до нуля, а точность операций деления и извлечения квадратного корня немного ниже, чем математические операции с одинарной точностью, соответствующие стандарту IEEE 754. Устройства, поддерживающие вычислительные возможности версии 2.0 и выше, поддерживают ненормальные числа, а операции деления и извлечения квадратного корня по умолчанию соответствуют стандарту IEEE 754. Тем не менее, при желании пользователи могут получить более быструю математику игрового уровня для устройств с вычислительными возможностями 1.x, установив флаги компилятора, отключающие точное деление и точные квадратные корни, а также включив сброс ненормальных чисел до нуля. [26]
- В отличие от OpenCL , графические процессоры с поддержкой CUDA доступны только у Nvidia, поскольку они являются собственностью компании. [27] [1] Попытки реализовать CUDA на других графических процессорах включают:
- Проект Coriander: преобразует исходный код CUDA C++11 в OpenCL 1.2 C. Ответвление CUDA-on-CL, предназначенное для запуска TensorFlow . [28] [29] [30]
- CU2CL: преобразование CUDA 3.2 C++ в OpenCL C. [31]
- GPUOpen HIP: тонкий уровень абстракции поверх CUDA и ROCm, предназначенный для графических процессоров AMD и Nvidia. Имеет инструмент преобразования для импорта исходного кода CUDA C++. Поддерживает CUDA 4.0 плюс C++11 и float16.
- ZLUDA — это замена CUDA на графических процессорах AMD и ранее графических процессорах Intel с производительностью, близкой к исходной. [32] Intel и AMD заключили с разработчиком Анджеем Яником отдельный контракт на разработку программного обеспечения в 2021 и 2022 годах соответственно. Однако ни одна компания не решила выпустить его официально из-за отсутствия варианта использования в бизнесе. Контракт AMD включал пункт, который позволял Янику самостоятельно выпускать свой код для AMD, что позволяло ему выпустить новую версию, поддерживающую только графические процессоры AMD. [33]
- ChipStar может компилировать и запускать программы CUDA/HIP на передовых платформах OpenCL 3.0 или Level Zero. [34]
Пример [ править ]
Этот пример кода на C++ загружает текстуру из изображения в массив на графическом процессоре:
texture<float, 2, cudaReadModeElementType> tex;
void foo()
{
cudaArray* cu_array;
// Allocate array
cudaChannelFormatDesc description = cudaCreateChannelDesc<float>();
cudaMallocArray(&cu_array, &description, width, height);
// Copy image data to array
cudaMemcpyToArray(cu_array, image, width*height*sizeof(float), cudaMemcpyHostToDevice);
// Set texture parameters (default)
tex.addressMode[0] = cudaAddressModeClamp;
tex.addressMode[1] = cudaAddressModeClamp;
tex.filterMode = cudaFilterModePoint;
tex.normalized = false; // do not normalize coordinates
// Bind the array to the texture
cudaBindTextureToArray(tex, cu_array);
// Run kernel
dim3 blockDim(16, 16, 1);
dim3 gridDim((width + blockDim.x - 1)/ blockDim.x, (height + blockDim.y - 1) / blockDim.y, 1);
kernel<<< gridDim, blockDim, 0 >>>(d_data, height, width);
// Unbind the array from the texture
cudaUnbindTexture(tex);
} //end foo()
__global__ void kernel(float* odata, int height, int width)
{
unsigned int x = blockIdx.x*blockDim.x + threadIdx.x;
unsigned int y = blockIdx.y*blockDim.y + threadIdx.y;
if (x < width && y < height) {
float c = tex2D(tex, x, y);
odata[y*width+x] = c;
}
}
Ниже приведен пример на Python , который вычисляет произведение двух массивов на графическом процессоре. Неофициальные привязки языка Python можно получить на PyCUDA . [35]
import pycuda.compiler as comp
import pycuda.driver as drv
import numpy
import pycuda.autoinit
mod = comp.SourceModule(
"""
__global__ void multiply_them(float *dest, float *a, float *b)
{
const int i = threadIdx.x;
dest[i] = a[i] * b[i];
}
"""
)
multiply_them = mod.get_function("multiply_them")
a = numpy.random.randn(400).astype(numpy.float32)
b = numpy.random.randn(400).astype(numpy.float32)
dest = numpy.zeros_like(a)
multiply_them(drv.Out(dest), drv.In(a), drv.In(b), block=(400, 1, 1))
print(dest - a * b)
Дополнительные привязки Python для упрощения операций умножения матриц можно найти в программе pycublas . [36]
import numpy
from pycublas import CUBLASMatrix
A = CUBLASMatrix(numpy.mat([[1, 2, 3], [4, 5, 6]], numpy.float32))
B = CUBLASMatrix(numpy.mat([[2, 3], [4, 5], [6, 7]], numpy.float32))
C = A * B
print(C.np_mat())
в то время как CuPy напрямую заменяет NumPy: [37]
import cupy
a = cupy.random.randn(400)
b = cupy.random.randn(400)
dest = cupy.zeros_like(a)
print(dest - a * b)
Поддерживаемые графические процессоры [ править ]
Поддерживаемые версии CUDA Compute Capability для версии CUDA SDK и микроархитектуры (по кодовому названию):
| CUDA SDK Версия(и) |
Тесла | Ферми | Кеплер (Рано) |
Кеплер (Поздно) |
Максвелл | Паскаль | Время | Тьюринг | Ампер | Есть ловелас |
Хоппер | Блэквелл |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1.0 [38] | 1.0 – 1.1 | |||||||||||
| 1.1 | 1,0 – 1,1+х | |||||||||||
| 2.0 | 1,0 – 1,1+х | |||||||||||
| 2.1 – 2.3.1 [39] [40] [41] [42] | 1.0 – 1.3 | |||||||||||
| 3.0 – 3.1 [43] [44] | 1.0 | 2.0 | ||||||||||
| 3.2 [45] | 1.0 | 2.1 | ||||||||||
| 4.0 – 4.2 | 1.0 | 2.1 | ||||||||||
| 5.0 – 5.5 | 1.0 | 3.5 | ||||||||||
| 6.0 | 1.0 | 3.2 | 3.5 | |||||||||
| 6.5 | 1.1 | 3.7 | 5.х | |||||||||
| 7.0 – 7.5 | 2.0 | 5.х | ||||||||||
| 8.0 | 2.0 | 6.х | ||||||||||
| 9.0 – 9.2 | 3.0 | 7.0 – 7.2 | ||||||||||
| 10.0 – 10.2 | 3.0 | 7.5 | ||||||||||
| 11.0 [46] | 3.5 | 8.0 | ||||||||||
| 11.1 – 11.4 [47] | 3.5 | 8.6 | ||||||||||
| 11.5 – 11.7.1 [48] | 3.5 | 8.7 | ||||||||||
| 11.8 [49] | 3.5 | 8.9 | 9.0 | |||||||||
| 12.0 – 12.5 | 5.0 | 9.0 |
Примечание. CUDA SDK 10.2 — это последняя официальная версия для macOS, поскольку в более новых версиях поддержка macOS не будет доступна.
Вычислительные возможности CUDA по версиям с соответствующими полупроводниковыми процессорами графического процессора и моделями карт графического процессора (отдельными по различным областям применения):
| Вычислить способность (версия) |
Микро- архитектура |
графические процессоры | GeForce | Квадро , НВС | Тесла/ЦОД | Тегра , Джетсон , ВОДИТЬ МАШИНУ |
|---|---|---|---|---|---|---|
| 1.0 | Тесла | G80 | GeForce 8800 Ultra, GeForce 8800 GTX, GeForce 8800 GTS (G80) | Quadro FX 5600, Quadro FX 4600, Quadro Plex 2100 S4 | Тесла C870, Тесла D870, Тесла S870 | |
| 1.1 | Г92, Г94, Г96, Г98, Г84, Г86 | GeForce GTS 250, GeForce 9800 GX2, GeForce 9800 GTX, GeForce 9800 GT, GeForce 8800 GTS(G92), GeForce 8800 GT, GeForce 9600 GT, GeForce 9500 GT, GeForce 9400 GT, GeForce 8600 GTS, GeForce 8600 GT, GeForce 8500 GT , GeForce G110M, GeForce 9300M GS, GeForce 9200M GS, GeForce 9100M G, GeForce 8400M GT, GeForce G105M |
Quadro FX 4700 X2, Quadro FX 3700, Quadro FX 1800, Quadro FX 1700, Quadro FX 580, Quadro FX 570, Quadro FX 470, Quadro FX 380, Quadro FX 370, Quadro FX 370 Low Profile, Quadro NVS 450, Quadro NVS 420 , Квадро НВС 290, Квадро НВС 295, Квадро Плекс 2100 Д4, Quadro FX 3800M, Quadro FX 3700M, Quadro FX 3600M, Quadro FX 2800M, Quadro FX 2700M, Quadro FX 1700M, Quadro FX 1600M, Quadro FX 770M, Quadro FX 570M, Quadro FX 370M, Quadro FX 360M, Quadro NVS 320М, Квадро НВС 160М, Квадро НВС 150М, Квадро НВС 140М, Квадро НВС 135М, Квадро НВС 130М, Квадро НВС 450, Квадро НВС 420, [50] Квадро НВС 295 |
|||
| 1.2 | ГТ218, ГТ216, ГТ215 | GeForce GT 340*, GeForce GT 330*, GeForce GT 320*, GeForce 315*, GeForce 310*, GeForce GT 240, GeForce GT 220, GeForce 210, GeForce GTS 360M, GeForce GTS 350M, GeForce GT 335M, GeForce GT 330M, GeForce GT 325M, GeForce GT 240M, GeForce G210M, GeForce 310M, GeForce 305M |
Quadro FX 380 низкопрофильный, Quadro FX 1800M, Quadro FX 880M, Quadro FX 380M, Нвидиа НВС 300, НВС 5100М, НВС 3100М, НВС 2100М, ИОН |
|||
| 1.3 | ГТ200, ГТ200б | GeForce GTX 295, GTX 285, GTX 280, GeForce GTX 275, GeForce GTX 260 | Quadro FX 5800, Quadro FX 4800, Quadro FX 4800 для Mac, Quadro FX 3800, Quadro CX, Quadro Plex 2200 D2 | Тесла C1060, Тесла S1070, Тесла M1060 | ||
| 2.0 | Ферми | ГФ100, ГФ110 | GeForce GTX 590, GeForce GTX 580, GeForce GTX 570, GeForce GTX 480, GeForce GTX 470, GeForce GTX 465, GeForce GTX 480M |
Quadro 6000, Quadro 5000, Quadro 4000, Quadro 4000 для Mac, Quadro Plex 7000, Квадро 5010М, Квадро 5000М |
Тесла C2075, Тесла C2050/C2070, Тесла M2050/M2070/M2075/M2090 | |
| 2.1 | GF104, GF106 GF108, GF114, GF116, GF117, GF119 | GeForce GTX 560 Ti, GeForce GTX 550 Ti, GeForce GTX 460, GeForce GTS 450, GeForce GTS 450*, GeForce GT 640 (GDDR3), GeForce GT 630, GeForce GT 620, GeForce GT 610, GeForce GT 520, GeForce GT 440, GeForce GT 440*, GeForce GT 430, GeForce GT 430*, GeForce GT 420*, GeForce GTX 675M, GeForce GTX 670M, GeForce GT 635M, GeForce GT 630M, GeForce GT 625M, GeForce GT 720M, GeForce GT 620M, GeForce 710M, GeForce 610M, GeForce 820M, GeForce GTX 580M, GeForce GTX 570M, GeForce GTX 560M, GeForce GT 555M, GeForce GT 550M, GeForce GT 540M, GeForce GT 525M, GeForce GT 520MX, GeForce GT 520M, GeForce GTX 485M, GeForce GTX 470M, GeForce GTX 460M, GeForce GT 445M, GeForce GT 435M, GeForce GT 420M, GeForce GT 415M , GeForce 710M, GeForce 410M |
Квадро 2000, Квадро 2000Д, Квадро 600, Квадро 4000М, Квадро 3000М, Квадро 2000М, Квадро 1000М, НВС 310, НВС 315, НВС 5400М, НВС 5200М, НВС 4200М |
|||
| 3.0 | Кеплер | ГК104, ГК106, ГК107 | GeForce GTX 770, GeForce GTX 760, GeForce GT 740, GeForce GTX 690, GeForce GTX 680, GeForce GTX 670, GeForce GTX 660 Ti, GeForce GTX 660, GeForce GTX 650 Ti BOOST, GeForce GTX 650 Ti, GeForce GTX 650, GeForce GTX 880M, GeForce GTX 870M, GeForce GTX 780M, GeForce GTX 770M, GeForce GTX 765M, GeForce GTX 760M, GeForce GTX 680MX, GeForce GTX 680M, GeForce GTX 675MX, GeForce GTX 670MX, GeForce GTX 660M, GeForce GT 750M, GeForce GT 650M, GeForce GT 745M, GeForce GT 645M, GeForce GT 740M, GeForce GT 730M, GeForce GT 640M, GeForce GT 640M LE, GeForce GT 735M, GeForce GT 730M |
Quadro K5000, Quadro K4200, Quadro K4000, Quadro K2000, Quadro K2000D, Quadro K600, Quadro K420, Квадро К500М, Квадро К510М, Квадро К610М, Квадро К1000М, Квадро К2000М, Квадро К1100М, Квадро К2100М, Квадро К3000М, Квадро К3100М, Квадро К4000М, Квадро К5000М, Квадро К4100М, Квадро К5100М, НВС 510, Квадро 410 |
Тесла К10, СЕТКА К340, СЕТКА К520, СЕТКА К2 | |
| 3.2 | ГК20А | Тегра К1, Джетсон ТК1 | ||||
| 3.5 | ГК110, ГК208 | GeForce GTX Titan Z, GeForce GTX Titan Black, GeForce GTX Titan, GeForce GTX 780 Ti, GeForce GTX 780, GeForce GT 640 (GDDR5), GeForce GT 630 v2, GeForce GT 730, GeForce GT 720, GeForce GT 710, GeForce GT 740M (64-бит, DDR3), GeForce GT 920M | Квадро К6000, Квадро К5200 | Тесла К40, Тесла К20х, Тесла К20 | ||
| 3.7 | ГК210 | Тесла К80 | ||||
| 5.0 | Максвелл | ГМ107, ГМ108 | GeForce GTX 750 Ti, GeForce GTX 750, GeForce GTX 960M, GeForce GTX 950M, GeForce 940M, GeForce 930M, GeForce GTX 860M, GeForce GTX 850M, GeForce 845M, GeForce 840M, GeForce 830M | Quadro K1200, Quadro K2200, Quadro K620, Quadro M2000M, Quadro M1000M, Quadro M600M, Quadro K620M, NVS 810 | Тесла М10 | |
| 5.2 | ГМ200, ГМ204, ГМ206 | GeForce GTX Titan X, GeForce GTX 980 Ti, GeForce GTX 980, GeForce GTX 970, GeForce GTX 960, GeForce GTX 950, GeForce GTX 750 SE, GeForce GTX 980M, GeForce GTX 970M, GeForce GTX 965M |
Quadro M6000 24 ГБ, Quadro M6000, Quadro M5000, Quadro M4000, Quadro M2000, Quadro M5500, Квадро М5000М, Квадро М4000М, Квадро М3000М |
Тесла М4, Тесла М40, Тесла М6, Тесла М60 | ||
| 5.3 | GM20B | Тегра Х1, Джетсон ТХ1, Джетсон Нано, ДРАЙВ СХ, ДРАЙВ ПХ | ||||
| 6.0 | Паскаль | ГП100 | Квадро GP100 | Тесла П100 | ||
| 6.1 | ГП102, ГП104, ГП106, ГП107, ГП108 | Нвидиа ТИТАН Xp, Титан X, GeForce GTX 1080 Ti, GTX 1080, GTX 1070 Ti, GTX 1070, GTX 1060, GTX 1050 Ti, GTX 1050, GT 1030, GT 1010, MX350, MX330, MX250, MX230, MX150, MX130, MX110 |
Quadro P6000, Quadro P5000, Quadro P4000, Quadro P2200, Quadro P2000, Quadro P1000, Quadro P400, Quadro P500, Quadro P520, Quadro P600, Quadro P5000(Мобильный), Quadro P4000(Мобильный), Quadro P3000(Мобильный) |
Тесла П40, Тесла П6, Тесла П4 | ||
| 6.2 | ГП10Б [51] | Тегра Х2, Джетсон ТХ2, ДРАЙВ ПХ 2 | ||||
| 7.0 | Время | ГВ100 | NVIDIA TITAN V | Рама GV100 | Тесла В100, Тесла В100С | |
| 7.2 | ГВ10Б [52] |
Тегра Ксавьер, Джетсон Ксавье NX, Джетсон AGX Ксавьер, ДРАЙВ AGX Ксавьер, ДРАЙВ AGX Пегас, Клара AGX | ||||
| 7.5 | Тьюринг | ТУ102, ТУ104, ТУ106, ТУ116, ТУ117 | NVIDIA ТИТАН РТХ, GeForce RTX 2080 Ti, RTX 2080 Super, RTX 2080, RTX 2070 Super, RTX 2070, RTX 2060 Super, RTX 2060 12 ГБ, RTX 2060, GeForce GTX 1660 Ti, GTX 1660 Супер, GTX 1660, GTX 1650 Супер, GTX 1650, MX550, MX450 |
Quadro RTX 8000, Quadro RTX 6000, Quadro RTX 5000, Quadro RTX 4000, T1000, T600, T400 T1200(мобильный), T600(мобильный), T500(мобильный), Quadro T2000(мобильный), Quadro T1000(мобильный) |
Тесла Т4 | |
| 8.0 | Ампер | GA100 | А100 80 ГБ, А100 40 ГБ, А30 | |||
| 8.6 | ГА102, ГА103, ГА104, ГА106, ГА107 | GeForce RTX 3090 Ti, RTX 3090, RTX 3080 Ti, RTX 3080 12 ГБ, RTX 3080, RTX 3070 Ti, RTX 3070, RTX 3060 Ti, RTX 3060, RTX 3050, RTX 3050 Ti (мобильный), RTX 3050 (мобильный), RTX 2050 (мобильный), MX570 | RTX A6000, RTX A5500, RTX A5000, RTX A4500, RTX A4000, RTX A2000 RTX A5000 (мобильный), RTX A4000 (мобильный), RTX A3000 (мобильный), RTX A2000 (мобильный) |
А40, А16, А10, А2 | ||
| 8.7 | ГА10Б | Джетсон Мьюзик Нано, Джетсон Мьюзик NX, Джетсон AGX Музыка, ДРАЙВ AGX Музыка, ПРИВОД AGX Пегас ОА, Клара Холоскан | ||||
| 8.9 | Ада Лавлейс [55] | AD102, AD103, AD104, AD106, AD107 | GeForce RTX 4090, RTX 4080 Super, RTX 4080, RTX 4070 Ti Super, RTX 4070 Ti, RTX 4070 Super, RTX 4070, RTX 4060 Ti, RTX 4060 | Доступен RTX 6000, Доступен RTX 5880, Доступен RTX 5000, Доступен RTX 4500, Доступен RTX 4000, Доступен RTX 4000 SFF | Л40С, Л40, Л20, Л4, Л2 | |
| 9.0 | Хоппер | ГХ100 | Н200, Н100 | |||
| 10.0 | Блэквелл | 100 ГБ | Б200, Б100 | |||
| 10.х | ГБ202, ГБ203, ГБ205, ГБ206, ГБ207 | GeForce RTX 5090, RTX 5080 | Б40 | |||
| Вычислить способность (версия) |
Микро- архитектура |
графические процессоры | GeForce | Квадро , НВС | Тесла/ЦОД | Тегра , Джетсон , ВОДИТЬ МАШИНУ |
'*' — OEM. продукция только
Особенности и характеристики версии [ править ]
Этот раздел необходимо обновить . Причина: отсутствие вычислительных возможностей CUDA 10.x (Blackwell). ( март 2024 г. ) |
| Поддержка функций (неуказанные функции поддерживаются для всех вычислительных возможностей) | Вычислительные возможности (версия) | |||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1.0, 1.1 | 1.2, 1.3 | 2.х | 3.0 | 3.2 | 3.5, 3.7, 5.х, 6.х, 7.0, 7.2 | 7.5 | 8.х | 9.0 | ||||||
| Функции голосования по деформации (__all(), __any()) | Нет | Да | ||||||||||||
| Функции деформационного голосования (__ballot()) | Нет | Да | ||||||||||||
| Функции ограничения памяти (__threadfence_system()) | ||||||||||||||
| Функции синхронизации (__syncthreads_count(), __syncthreads_and(), __syncthreads_or()) | ||||||||||||||
| Поверхностные функции | ||||||||||||||
| 3D сетка блоков резьбы | ||||||||||||||
| Функции варп-перетасовки | Нет | Да | ||||||||||||
| Программирование единой памяти | ||||||||||||||
| Сдвиг воронки | Нет | Да | ||||||||||||
| Динамический параллелизм | Нет | Да | ||||||||||||
| Единый путь к данным [56] | Нет | Да | ||||||||||||
| Асинхронное копирование с аппаратным ускорением | Нет | Да | ||||||||||||
| Аппаратно-ускоренное разделение барьера прибытия/ожидания | ||||||||||||||
| Поддержка варп-уровня для операций по сокращению | ||||||||||||||
| Управление резидентностью кэша L2 | ||||||||||||||
| Инструкции DPX для ускоренного динамического программирования | Нет | Да | ||||||||||||
| Распределенная общая память | ||||||||||||||
| Кластер блоков потоков | ||||||||||||||
| Блок ускорителя тензорной памяти (ТМА) | ||||||||||||||
| Поддержка функций (неуказанные функции поддерживаются для всех вычислительных возможностей) | 1.0,1.1 | 1.2,1.3 | 2.х | 3.0 | 3.2 | 3.5, 3.7, 5.х, 6.х, 7.0, 7.2 | 7.5 | 8.х | 9.0 | |||||
| Вычислительные возможности (версия) | ||||||||||||||
Типы данных [ править ]
| Тип данных | Операция | Поддерживается с |
Атомная операция | Поддерживается с для глобальной памяти |
Поддерживается с для общей памяти |
|---|---|---|---|---|---|
| 8-битное целое число подписанный/неподписанный |
загрузка, хранение, преобразование | 1.0 | — | — | |
| 16-битное целое число подписанный/неподписанный |
общие операции | 1.0 | атомныйCAS() | 3.5 | |
| 32-битное целое число подписанный/неподписанный |
общие операции | 1.0 | атомарные функции | 1.1 | 1.2 |
| 64-битное целое число подписанный/неподписанный |
общие операции | 1.0 | атомарные функции | 1.2 | 2.0 |
| любой 128-битный тривиально копируемый тип | общие операции | Нет | атомныйExch, атомныйCAS | 9.0 | |
| 16-битная с плавающей запятой РП16 |
сложение, вычитание, умножение, сравнение, функции warp shuffle, преобразование |
5.3 | атомное сложение Half2 | 6.0 | |
| атомное присоединение | 7.0 | ||||
| 16-битная с плавающей запятой БФ16 |
сложение, вычитание, умножение, сравнение, функции warp shuffle, преобразование |
8.0 | атомное присоединение | 8.0 | |
| 32-битная с плавающей запятой | общие операции | 1.0 | атомныйExch() | 1.1 | 1.2 |
| атомное присоединение | 2.0 | ||||
| 32-битные числа с плавающей запятой float2 и float4 | общие операции | Нет | атомное присоединение | 9.0 | |
| 64-битная с плавающей запятой | общие операции | 1.3 | атомное присоединение | 6.0 | |
Примечание. Любые пропущенные строки или пустые записи отражают некоторый недостаток информации по конкретному элементу. [58]
Тензорные ядра [ править ]
| FMA за цикл на тензорное ядро [59] | Поддерживается с | 7.0 | 7.2 | 7.5 Рабочая станция | 7.5 Рабочий стол | 8.0 | 8.6 Рабочая станция | 8.7 | 8.9 Рабочая станция | 8.6 Рабочий стол | 8.9 Рабочий стол | 9.0 | 10.0 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Тип данных | Для плотных матриц | Для разреженных матриц | 1-е поколение (8x/SM) | 1-е поколение? (8x/СМ) | 2-е поколение (8x/СМ) | 3-е поколение (4x/SM) | 4-е поколение (4x/SM) | 3-е поколение (4x/SM) | 4-е поколение (4x/SM) | 5-е поколение (4x/SM) | ||||
| 1-битные значения (И) | 8.0 как экспериментальный |
Нет | Нет | 4096 | 2048 | 4096 | скорость подлежит уточнению | |||||||
| 1-битные значения (XOR) | 7,5–8,9 как экспериментальный |
Нет | 1024 | Устарело или удалено? | ||||||||||
| 4-битные целые числа | 8,0–8,9 как экспериментальный |
256 | 1024 | 512 | 1024 | |||||||||
| 4-битная плавающая запятая FP4 (E2M1?) | 10.0 | Нет | 4096 | |||||||||||
| 6-битная плавающая запятая FP6 (E3M2 и E2M3?) | 10.0 | Нет | 2048 | |||||||||||
| 8-битные целые числа | 7.2 | 8.0 | Нет | 128 | 128 | 512 | 256 | 512 | 1024 | 2048 | ||||
| 8-битная плавающая запятая FP8 (E4M3 и E5M2) с накоплением FP16 | 8.9 | Нет | 512 | Нет | ||||||||||
| 8-битная плавающая запятая FP8 (E4M3 и E5M2) с накоплением FP32 | ||||||||||||||
| 16-битная плавающая запятая FP16 с накоплением FP16 | 7.0 | 8.0 | 64 | 64 | 64 | 256 | 128 | 256 | 512 | 1024 | ||||
| 16-битная плавающая запятая FP16 с накоплением FP32 | 32 | 64 | 128 | |||||||||||
| 16-битная плавающая запятая BF16 с накоплением FP32 | 7.5 [60] | 8.0 | Нет | |||||||||||
| 32-битный (используется 19 бит) с плавающей запятой TF32 | скорость подлежит уточнению (32?) | 128 | 32 | 64 | 256 | 512 | ||||||||
| 64-битная с плавающей запятой | 8.0 | Нет | Нет | 16 | скорость подлежит уточнению | 32 | 16 | |||||||
Примечание. Любые пропущенные строки или пустые записи отражают некоторый недостаток информации по конкретному элементу. [61] [62] [63] [64] [65] [66]
| Состав тензорного ядра | 7.0 | 7.2, 7.5 | 8.0, 8.6 | 8.7 | 8.9 | 9.0 |
|---|---|---|---|---|---|---|
| Ширина единицы скалярного произведения в единицах FP16 (в байтах) [67] [68] [69] [70] | 4 (8) | 8 (16) | 4 (8) | 16 (32) | ||
| Единицы скалярного произведения на тензорное ядро | 16 | 32 | ||||
| Тензорные ядра на раздел SM | 2 | 1 | ||||
| Полная пропускная способность (байт/цикл) [71] на раздел SM [72] | 256 | 512 | 256 | 1024 | ||
| Тензорные ядра FP: минимальные циклы для расчета матрицы по всей деформации | 8 | 4 | 8 | |||
| Тензорные ядра FP: минимальная форма матрицы для полной пропускной способности (байты) [73] | 2048 | |||||
| INT Tensor Cores: минимальные циклы для расчета матрицы по всей деформации. | Нет | 4 | ||||
| Тензорные ядра INT: минимальная форма матрицы для полной пропускной способности (байты) | Нет | 1024 | 2048 | 1024 | ||
| Состав ядра тензора FP64 | 8.0 | 8.6 | 8.7 | 8.9 | 9.0 |
|---|---|---|---|---|---|
| Ширина единицы скалярного произведения в единицах FP64 (в байтах) | 4 (32) | подлежит уточнению | 4 (32) | ||
| Единицы скалярного произведения на тензорное ядро | 4 | подлежит уточнению | 8 | ||
| Тензорные ядра на раздел SM | 1 | ||||
| Полная пропускная способность (байт/цикл) [78] на раздел SM [79] | 128 | подлежит уточнению | 256 | ||
| Минимальные циклы для расчета матрицы всей основы | 16 | подлежит уточнению | |||
| Минимальная форма матрицы для полной пропускной способности (байты) [80] | 2048 | ||||
Техническая спецификация [ править ]
| Технические характеристики | Вычислительные возможности (версия) | ||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1.0 | 1.1 | 1.2 | 1.3 | 2.х | 3.0 | 3.2 | 3.5 | 3.7 | 5.0 | 5.2 | 5.3 | 6.0 | 6.1 | 6.2 | 7.0 | 7.2 | 7.5 | 8.0 | 8.6 | 8.7 | 8.9 | 9.0 | |
| Максимальное количество резидентных сеток на устройство (параллельное выполнение ядра, может быть ниже для определенных устройств) |
1 | 16 | 4 | 32 | 16 | 128 | 32 | 16 | 128 | 16 | 128 | ||||||||||||
| Максимальная размерность сетки блоков резьбы | 2 | 3 | |||||||||||||||||||||
| Максимальный размер x сетки блоков резьбы | 65535 | 2 31 − 1 | |||||||||||||||||||||
| Максимальный размер y или z сетки блоков резьбы | 65535 | ||||||||||||||||||||||
| Максимальная размерность резьбового блока | 3 | ||||||||||||||||||||||
| Максимальный размер x или y блока | 512 | 1024 | |||||||||||||||||||||
| Максимальный z-размер блока | 64 | ||||||||||||||||||||||
| Максимальное количество потоков на блок | 512 | 1024 | |||||||||||||||||||||
| Размер деформации | 32 | ||||||||||||||||||||||
| Максимальное количество резидентных блоков на мультипроцессор | 8 | 16 | 32 | 16 | 32 | 16 | 24 | 32 | |||||||||||||||
| Максимальное количество резидентных варпов на мультипроцессор | 24 | 32 | 48 | 64 | 32 | 64 | 48 | 64 | |||||||||||||||
| Максимальное количество резидентных потоков на мультипроцессор | 768 | 1024 | 1536 | 2048 | 1024 | 2048 | 1536 | 2048 | |||||||||||||||
| Количество 32-битных обычных регистров на мультипроцессор | 8 К | 16 К | 32 К | 64 К | 128 К | 64 К | |||||||||||||||||
| Количество 32-битных унифицированных регистров на мультипроцессор | Нет | 2 К [81] | |||||||||||||||||||||
| Максимальное количество 32-битных регистров на блок потока | 8 К | 16 К | 32 К | 64 К | 32 К | 64 К | 32 К | 64 К | 32 К | 64 К | |||||||||||||
| Максимальное количество 32-битных обычных регистров на поток | 124 | 63 | 255 | ||||||||||||||||||||
| Максимальное количество 32-битных универсальных регистров на варп | Нет | 63 [83] | |||||||||||||||||||||
| Объем общей памяти на мультипроцессор (из общей общей памяти + кэш L1, если применимо) |
16 КиБ | 16/48 КиБ (или 64 КиБ) | 16/32/48 КиБ (или 64 КиБ) | 80/96/112 КиБ (или 128 КиБ) | 64 КиБ | 96 КиБ | 64 КиБ | 96 КиБ | 64 КиБ | 0/8/16/32/64/96 КиБ (или 128 КиБ) | 32/64 КиБ (или 96 КиБ) | 0/8/16/32/64/100/132/164 КиБ (из 192 КиБ) | 0/8/16/32/64/100 КиБ (или 128 КиБ) | 0/8/16/32/64/100/132/164 КиБ (из 192 КиБ) | 0/8/16/32/64/100 КиБ (или 128 КиБ) | 0/8/16/32/64/100/132/164/196/228 КиБ (из 256 КиБ) | |||||||
| Максимальный объем общей памяти на блок потока | 16 КиБ | 48 КиБ | 96 КиБ | 48 КиБ | 64 КиБ | 163 КиБ | 99 КиБ | 163 КиБ | 99 КиБ | 227 КиБ | |||||||||||||
| Количество общих банков памяти | 16 | 32 | |||||||||||||||||||||
| Объем локальной памяти на поток | 16 КиБ | 512 КиБ | |||||||||||||||||||||
| Постоянный размер памяти, доступный CUDA C/C++ (1 банк, PTX имеет доступ к 11 банкам, SASS имеет доступ к 18 банкам) |
64 КиБ | ||||||||||||||||||||||
| Кэшируйте рабочий набор для каждого мультипроцессора для постоянной памяти. | 8 КиБ | 4 КиБ | 8 КиБ | ||||||||||||||||||||
| Кэш рабочего набора для каждого мультипроцессора для памяти текстур. | 16 КиБ на TPC | 24 КиБ на TPC | 12 КиБ | 12 – 48 КиБ [85] | 24 КиБ | 48 КиБ | 32 КиБ [86] | 24 КиБ | 48 КиБ | 24 КиБ | 32 – 128 КиБ | 32 – 64 КиБ | 28 – 192 КиБ | 28 – 128 КиБ | 28 – 192 КиБ | 28 – 128 КиБ | 28 – 256 КиБ | ||||||
| Максимальная ширина ссылки на одномерную текстуру, привязанной к CUDA множество |
8192 | 65536 | 131072 | ||||||||||||||||||||
| Максимальная ширина для ссылки на одномерную текстуру, привязанная к линейной память |
2 27 | 2 28 | 2 27 | 2 28 | 2 27 | 2 28 | |||||||||||||||||
| Максимальная ширина и количество слоев для одномерного слоя ссылка на текстуру |
8192 × 512 | 16384 × 2048 | 32768 х 2048 | ||||||||||||||||||||
| Максимальная ширина и высота для привязки ссылки на 2D-текстуру в массив CUDA |
65536 × 32768 | 65536 × 65535 | 131072 х 65536 | ||||||||||||||||||||
| Максимальная ширина и высота для привязки ссылки на 2D-текстуру в линейную память |
65000 х 65000 | 65536 х 65536 | 131072 х 65000 | ||||||||||||||||||||
| Максимальная ширина и высота для привязки ссылки на 2D-текстуру в массив CUDA, поддерживающий сбор текстур |
— | 16384 х 16384 | 32768 х 32768 | ||||||||||||||||||||
| Максимальная ширина, высота и количество слоев для 2D-файла. ссылка на многослойную текстуру |
8192 × 8192 × 512 | 16384 × 16384 × 2048 | 32768 х 32768 х 2048 | ||||||||||||||||||||
| Максимальная ширина, высота и глубина 3D-текстуры. ссылка, привязанная к линейной памяти или массиву CUDA |
2048 3 | 4096 3 | 16384 3 | ||||||||||||||||||||
| Максимальная ширина (и высота) для ссылки на текстуру кубической карты | — | 16384 | 32768 | ||||||||||||||||||||
| Максимальная ширина (и высота) и количество слоев для справки по многослойной текстуре кубической карты |
— | 16384 × 2046 | 32768 × 2046 | ||||||||||||||||||||
| Максимальное количество текстур, которые можно привязать к ядро |
128 | 256 | |||||||||||||||||||||
| Максимальная ширина для одномерной привязки поверхности, привязанной к CUDA-массив |
Нет поддерживается |
65536 | 16384 | 32768 | |||||||||||||||||||
| Максимальная ширина и количество слоев для одномерного слоя привязка к поверхности |
65536 × 2048 | 16384 × 2048 | 32768 × 2048 | ||||||||||||||||||||
| Максимальная ширина и высота для привязки 2D-поверхности привязан к массиву CUDA |
65536 × 32768 | 16384 × 65536 | 131072 × 65536 | ||||||||||||||||||||
| Максимальная ширина, высота и количество слоев для 2D-файла. эталон многослойной поверхности |
65536 × 32768 × 2048 | 16384 × 16384 × 2048 | 32768 × 32768 × 2048 | ||||||||||||||||||||
| Максимальная ширина, высота и глубина трехмерной поверхности. ссылка, привязанная к массиву CUDA |
65536 × 32768 × 2048 | 4096 × 4096 × 4096 | 16384 × 16384 × 16384 | ||||||||||||||||||||
| Максимальная ширина (и высота) для ссылки на поверхность кубической карты, привязанной к массиву CUDA. | 32768 | 16384 | 32768 | ||||||||||||||||||||
| Максимальная ширина и количество слоев кубической карты эталон многослойной поверхности |
32768 × 2046 | 16384 × 2046 | 32768 × 2046 | ||||||||||||||||||||
| Максимальное количество поверхностей, которые можно привязать к ядро |
8 | 16 | 32 | ||||||||||||||||||||
| Максимальное количество инструкций на ядро | 2 миллиона | 512 миллионов | |||||||||||||||||||||
| Максимальное количество блоков потоков на кластер блоков потоков [87] | Нет | 16 | |||||||||||||||||||||
| Технические характеристики | 1.0 | 1.1 | 1.2 | 1.3 | 2.х | 3.0 | 3.2 | 3.5 | 3.7 | 5.0 | 5.2 | 5.3 | 6.0 | 6.1 | 6.2 | 7.0 | 7.2 | 7.5 | 8.0 | 8.6 | 8.7 | 8.9 | 9.0 |
| Вычислительные возможности (версия) | |||||||||||||||||||||||
Многопроцессорная архитектура [ править ]
| Спецификации архитектуры | Вычислительные возможности (версия) | |||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1.0 | 1.1 | 1.2 | 1.3 | 2.0 | 2.1 | 3.0 | 3.2 | 3.5 | 3.7 | 5.0 | 5.2 | 5.3 | 6.0 | 6.1 | 6.2 | 7.0 | 7.2 | 7.5 | 8.0 | 8.6 | 8.7 | 8.9 | 9.0 | |
| Количество полос ALU для арифметических операций INT32 | 8 | 32 | 48 | 192 [90] | 128 | 128 | 64 | 128 | 128 | 64 | 64 | 64 | ||||||||||||
| Количество полос ALU для любой арифметической операции INT32 или FP32. | — | — | ||||||||||||||||||||||
| Количество полос ALU для арифметических операций FP32 | 64 | 64 | 128 | 128 | ||||||||||||||||||||
| Количество полос ALU для арифметических операций FP16x2 | Нет | 1 | 128 [91] | 128 [92] | 64 [93] | |||||||||||||||||||
| Количество полос ALU для арифметических операций FP64 | Нет | 1 | 16 от ФП32 [94] | 4 от ФП32 [95] | 8 | 8 / 64 [96] | 64 | 4 [97] | 32 | 4 | 32 | 2 | 32 | 2 | 2? | 2 | 64 | |||||||
| Количество единиц загрузки/хранения | 4 на 2 см. | 8 за 2 см. | 8 на 2 см/3 см [96] | 8 за 3 см. | 16 | 32 | 16 | 32 | 16 | 32 | ||||||||||||||
| Количество специальных функциональных блоков для трансцендентных функций одинарной точности с плавающей запятой | 2 [98] | 4 | 8 | 32 | 16 | 32 | 16 | |||||||||||||||||
| Количество блоков текстурирования (TMU) | 4 на 2 см. | 8 за 2 см. | 8 за 2/3см [96] | 8 за 3 см. | 4 | 4 / 8 [96] | 16 | 8 | 16 | 8 | 4 | |||||||||||||
| Количество полос ALU для единых арифметических операций INT32 | Нет | 2 [99] | ||||||||||||||||||||||
| Количество тензорных ядер | Нет | 8 (1-е поколение) [100] | 0 / 8 [96] (2-е поколение) | 4 (3-е поколение) | 4 (4-е поколение) | |||||||||||||||||||
| Количество ядер трассировки лучей | Нет | 0 / 1 [96] (1-е поколение) | Нет | 1 (2-е поколение) | Нет | 1 (3-е поколение) | Нет | |||||||||||||||||
| Количество разделов SM = блоки обработки [101] | 1 | 4 | 2 | 4 | ||||||||||||||||||||
| Количество планировщиков деформации на раздел SM | 1 | 2 | 4 | 1 | ||||||||||||||||||||
| Максимальное количество новых инструкций, выдаваемых в каждом цикле одним планировщиком [102] | 2 [103] | 1 | 2 [104] | 2 | 1 | |||||||||||||||||||
| Размер единой памяти для кэша данных и общей памяти | 16 КиБ [105] | 16 КиБ [105] | 64 КиБ | 128 КиБ | 64 КиБ SM + 24 КиБ L1 (отдельный) [106] | 96 КиБ SM + 24 КиБ L1 (отдельный) [106] | 64 КиБ SM + 24 КиБ L1 (отдельный) [106] | 64 КиБ SM + 24 КиБ L1 (отдельный) [106] | 96 КиБ SM + 24 КиБ L1 (отдельный) [106] | 64 КиБ SM + 24 КиБ L1 (отдельный) [106] | 128 КиБ | 96 КиБ [107] | 192 КиБ | 128 КиБ | 192 КиБ | 128 КиБ | 256 КиБ | |||||||
| Размер кэша инструкций L3 на графический процессор | 32 КиБ [108] | использовать кэш данных L2 | ||||||||||||||||||||||
| Размер кэша инструкций L2 на кластер текстурных процессоров (TPC) | 8 КиБ | |||||||||||||||||||||||
| Размер кэша инструкций L1.5 на SM [109] | 4 КиБ | 32 КиБ | 32 КиБ | 48 КиБ [110] | 128 КиБ | 32 КиБ | 128 КиБ | ~46 КиБ [111] | 128 КиБ [112] | |||||||||||||||
| Размер кэша инструкций L1 на SM | 8 КиБ | 8 КиБ | ||||||||||||||||||||||
| Размер кэша инструкций L0 на раздел SM | только 1 раздел на SM | Нет | 12 КиБ | 16 КиБ? [113] | 32 КиБ | |||||||||||||||||||
| Ширина инструкции [114] | 32-битные инструкции и 64-битные инструкции [115] | 64-битные инструкции + 64-битная управляющая логика каждые 7 инструкций | 64-битные инструкции + 64-битная управляющая логика каждые 3 инструкции | 128-битная комбинированная логика инструкций и управления | ||||||||||||||||||||
| Ширина шины памяти на раздел памяти в битах | 64 ((Г)ГДР) | 32 ((Г)ГДР) | 512 (ХБМ) | 32 ((Г)ГДР) | 512 (ХБМ) | 32 ((Г)ГДР) | 512 (ХБМ) | 32 ((Г)ГДР) | 512 (ХБМ) | |||||||||||||||
| Кэш L2 на раздел памяти | 16 КиБ [116] | 32 КиБ [116] | 128 КиБ | 256 КиБ | 1 МиБ | 512 КиБ | 128 КиБ | 512 КиБ | 256 КиБ | 128 КиБ | 768 КиБ | 64 КиБ | 512 КиБ | 4 МБ | 512 КиБ | 8 МБ [117] | 5 МБ | |||||||
| Количество блоков вывода рендеринга (ROP) на раздел памяти (или на GPC в более поздних моделях) | 4 | 8 | 4 | 8 | 16 | 8 | 12 | 8 | 4 | 16 | 2 | 8 | 16 | 16 на ГПК | 3 на ГПК | 16 на ГПК | ||||||||
| Спецификации архитектуры | 1.0 | 1.1 | 1.2 | 1.3 | 2.0 | 2.1 | 3.0 | 3.2 | 3.5 | 3.7 | 5.0 | 5.2 | 5.3 | 6.0 | 6.1 | 6.2 | 7.0 | 7.2 | 7.5 | 8.0 | 8.6 | 8.7 | 8.9 | 9.0 |
| Вычислительные возможности (версия) | ||||||||||||||||||||||||
Для получения дополнительной информации прочтите руководство по программированию Nvidia CUDA. [119]
архитектуры использование Текущее и будущее CUDA
- Ускоренный рендеринг 3D-графики
- Ускоренное взаимное преобразование форматов видеофайлов
- Ускоренное шифрование , дешифрование и сжатие
- Биоинформатика , например NGS BarraCUDA секвенирование ДНК [120]
- Распределенные расчеты, такие как прогнозирование нативной конформации белков.
- Моделирование медицинского анализа, например, виртуальная реальность на основе КТ и МРТ. изображений
- Физическое моделирование, [121] в частности в гидродинамике
- нейронных сетей Обучение машинного обучения решению задач
- Распознавание лиц
- Волонтерские компьютерные проекты, такие как SETI@home и другие проекты с использованием BOINC. программного обеспечения
- Молекулярная динамика
- Майнинг криптовалют
- Программное обеспечение «Структура из движения» (SfM)
Сравнение с конкурентами [ править ]
CUDA конкурирует с другими стеками вычислений на графических процессорах: Intel OneAPI и AMD ROCm .
В то время как CUDA от Nvidia имеет закрытый исходный код, OneAPI от Intel и ROCm от AMD имеют открытый исходный код.
Intel OneAPI [ править ]
oneAPI имеет открытый исходный код, и все соответствующие библиотеки опубликованы на его странице GitHub.
Первоначально разработанное Intel, другими производителями аппаратного обеспечения являются, например, Fujitsu и Huawei.
Фонд унифицированного ускорения (UXL) [ править ]
Unified Acceleration Foundation (UXL) — это новый технологический консорциум, который работает над продолжением инициативы OneAPI с целью создать новую экосистему программного обеспечения для ускорителей открытых стандартов, соответствующие проекты открытых стандартов и спецификаций через рабочие группы и группы по специальным интересам (SIG). ). Цель будет конкурировать с CUDA от Nvidia. Основными компаниями, стоящими за ним, являются Intel, Google, ARM, Qualcomm, Samsung, Imagination и VMware. [122]
AMD ROCm [ править ]
РПЦм [123] — это стек программного обеспечения с открытым исходным кодом для программирования графических процессоров (GPU) от Advanced Micro Devices (AMD).
См. также [ править ]
- SYCL — открытый стандарт от Khronos Group для программирования различных платформ, включая графические процессоры, с использованием современного C++ с одним исходным кодом , аналогичный высокоуровневому API CUDA Runtime API ( с одним исходным кодом ).
- BrookGPU - компилятор графической группы Стэнфордского университета.
- Программирование массивов
- Параллельные вычисления
- Потоковая обработка
- rCUDA — API для вычислений на удаленных компьютерах
- Молекулярное моделирование на графических процессорах
- Vulkan — низкоуровневый высокопроизводительный API для 3D-графики и вычислений.
- OptiX — API трассировки лучей от NVIDIA
- Бинарный файл CUDA (кубин) – разновидность жирного бинарного файла.
- Коллекция числовых библиотек - от NEC для их векторного процессора.
Ссылки [ править ]
- ↑ Перейти обратно: Перейти обратно: а б Шах, Агам. «Nvidia не категорически против того, чтобы третьи стороны производили чипы CUDA» . www.theregister.com . Проверено 25 апреля 2024 г.
- ^ Нвидиа. «Что такое CUDA?» . Нвидиа . Проверено 21 марта 2024 г.
- ↑ Перейти обратно: Перейти обратно: а б Аби-Чахла, Феди (18 июня 2008 г.). «CUDA от Nvidia: конец процессоров?» . Аппаратное обеспечение Тома . Проверено 17 мая 2015 г.
- ^ Зунич, Питер (24 января 2018 г.). «CUDA против OpenCL против OpenGL» . Видеомейкер . Проверено 16 сентября 2018 г.
- ^ «ОпенКЛ» . Разработчик NVIDIA . 24 апреля 2013 г. Проверено 4 ноября 2019 г.
- ^ «Домашняя страница NVIDIA CUDA» . 18 июля 2017 г.
- ^ Шимпи, Ананд Лал; Уилсон, Дерек (8 ноября 2006 г.). «Nvidia GeForce 8800 (G80): графические процессоры, переработанные для DirectX 10» . АнандТех . Проверено 16 мая 2015 г.
- ^ Витт, Стивен (27 ноября 2023 г.). «Как Nvidia Дженсена Хуанга способствует революции искусственного интеллекта» . Житель Нью-Йорка . ISSN 0028-792X . Проверено 10 декабря 2023 г.
- ^ «CUDA LLVM-компилятор» . 7 мая 2012 г.
- ^ Первая демонстрация OpenCL на графическом процессоре на YouTube.
- ^ Демонстрация DirectCompute Ocean, работающая на графическом процессоре Nvidia CUDA, на YouTube
- ^ Василиадис, Гиоргос; Антонатос, Спирос; Полихронакис, Михалис; Маркатос, Евангелос П.; Иоаннидис, Сотирис (сентябрь 2008 г.). «Gnort: Высокопроизводительное обнаружение сетевых вторжений с использованием графических процессоров» (PDF) . Последние достижения в области обнаружения вторжений . Конспекты лекций по информатике. Том. 5230. стр. 116–134. дои : 10.1007/978-3-540-87403-4_7 . ISBN 978-3-540-87402-7 .
- ^ Шац, Майкл С.; Трапнелл, Коул; Делчер, Артур Л.; Варшней, Амитабх (2007). «Высокопроизводительное выравнивание последовательностей с использованием графических процессоров» . БМК Биоинформатика . 8 : 474. дои : 10.1186/1471-2105-8-474 . ПМК 2222658 . ПМИД 18070356 .
- ^ «Пирит – Код Google» .
- ^ «Используйте графический процессор Nvidia для научных вычислений» . БОИНК. 18 декабря 2008 г. Архивировано из оригинала 28 декабря 2008 г. Проверено 8 августа 2017 г.
- ^ «Комплект разработки программного обеспечения Nvidia CUDA (CUDA SDK) — примечания к выпуску версии 2.0 для MAC OS X» . Архивировано из оригинала 6 января 2009 г.
- ^ «CUDA 1.1 – теперь и в Mac OS X» . 14 февраля 2008 г. Архивировано из оригинала 22 ноября 2008 г.
- ^ «Раскрыты возможности CUDA 11» . 14 мая 2020 г.
- ^ «CUDA Toolkit 11.1 представляет поддержку графических процессоров серий GeForce RTX 30 и Quadro RTX» . 23 сентября 2020 г.
- ^ «Улучшение распределения памяти с помощью новых функций NVIDIA CUDA 11.2» . 16 декабря 2020 г.
- ^ «Изучение новых возможностей CUDA 11.3» . 16 апреля 2021 г.
- ^ Зильберштейн, Марк; Шустер, Ассаф ; Гейгер, Дэн; Патни, Анджул; Оуэнс, Джон Д. (2008). «Эффективное вычисление произведений суммы на графических процессорах с помощью программно-управляемого кэша» (PDF) . Материалы 22-й ежегодной международной конференции по суперкомпьютерам – ICS '08 (PDF) . Материалы 22-й ежегодной международной конференции по суперкомпьютерам – ICS '08. стр. 309–318. дои : 10.1145/1375527.1375572 . ISBN 978-1-60558-158-3 .
- ^ «Руководство по программированию на CUDA C, версия 8.0» (PDF) . Зона разработчиков nVidia . Январь 2017. с. 19 . Проверено 22 марта 2017 г.
- ^ «NVCC принудительно компилирует C++ файлов .cu» . 29 ноября 2011 г.
- ^ Уайтхед, Натан; Фит-Флоря, Алекс. «Точность и производительность: числа с плавающей запятой и соответствие стандарту IEEE 754 для графических процессоров Nvidia» (PDF) . Нвидиа . Проверено 18 ноября 2014 г.
- ^ «Продукты с поддержкой CUDA» . Зона КУДА . Корпорация Нвидиа . Проверено 3 ноября 2008 г.
- ^ «Проект Coriander: компилируйте коды CUDA в OpenCL и запускайте повсюду» . Фороникс.
- ^ Перкинс, Хью (2017). «куда-он-кл» (PDF) . ИВОКЛ . Проверено 8 августа 2017 г.
- ^ «hughperkins/coriander: Создайте код NVIDIA® CUDA™ для устройств OpenCL™ 1.2» . Гитхаб. 6 мая 2019 г.
- ^ «Документация CU2CL» . chrec.cs.vt.edu .
- ^ «GitHub – возен/ЗЛУДА» . Гитхаб .
- ^ Ларабель, Майкл (12 февраля 2024 г.), «AMD незаметно профинансировала внешнюю реализацию CUDA, основанную на ROCm: теперь это открытый исходный код» , Phoronix , получено 12 февраля 2024 г.
- ^ «GitHub – чип-spv/chipStar» . Гитхаб .
- ^ «ПиКУДА» .
- ^ «пикубла» . Архивировано из оригинала 20 апреля 2009 г. Проверено 8 августа 2017 г.
- ^ «КуПи» . Проверено 8 января 2020 г.
- ^ «Руководство по программированию NVIDIA CUDA. Версия 1.0» (PDF) . 23 июня 2007 г.
- ^ «Руководство по программированию NVIDIA CUDA. Версия 2.1» (PDF) . 8 декабря 2008 г.
- ^ «Руководство по программированию NVIDIA CUDA. Версия 2.2» (PDF) . 2 апреля 2009 г.
- ^ «Руководство по программированию NVIDIA CUDA. Версия 2.2.1» (PDF) . 26 мая 2009 г.
- ^ «Руководство по программированию NVIDIA CUDA. Версия 2.3.1» (PDF) . 26 августа 2009 г.
- ^ «Руководство по программированию NVIDIA CUDA. Версия 3.0» (PDF) . 20 февраля 2010 г.
- ^ «Руководство по программированию NVIDIA CUDA C. Версия 3.1.1» (PDF) . 21 июля 2010 г.
- ^ «Руководство по программированию NVIDIA CUDA C. Версия 3.2» (PDF) . 9 ноября 2010 г.
- ^ «Примечания к выпуску CUDA 11.0» . Разработчик NVIDIA .
- ^ «Примечания к выпуску CUDA 11.1» . Разработчик NVIDIA .
- ^ «Примечания к выпуску CUDA 11.5» . Разработчик NVIDIA .
- ^ «Примечания к выпуску CUDA 11.8» . Разработчик NVIDIA .
- ^ «Характеристики NVIDIA Quadro NVS 420» . База данных графических процессоров TechPowerUp . 25 августа 2023 г.
- ^ Ларабель, Майкл (29 марта 2017 г.). «NVIDIA внедряет поддержку графического процессора Tegra X2 в версии Nouveau» . Фороникс . Проверено 8 августа 2017 г.
- ^ Спецификации Nvidia Xavier на TechPowerUp (предварительные)
- ^ «Добро пожаловать — документация Jetson Linux Developer Guide 34.1» .
- ^ «NVIDIA представляет поддержку графического процессора Volta с открытым исходным кодом для своей SoC Xavier» .
- ^ «Архитектура NVIDIA Ады Лавлейс» .
- ^ Анализ архитектуры графического процессора Тьюринга с помощью микробенчмаркинга
- ^ «H.1. Функции и технические характеристики – Таблица 13. Поддержка функций в зависимости от вычислительных возможностей» . docs.nvidia.com . Проверено 23 сентября 2020 г.
- ^ «Руководство по программированию CUDA C++» .
- ^ Fused-Multiply-Add, фактически выполнено, Dense Matrix
- ^ как SASS с версии 7.5, как PTX с версии 8.0
- ^ «Техническое описание. Серия NVIDIA Jetson AGX Orin» (PDF) . nvidia.com . Получено 5 сентября.
- ^ «Архитектура графического процессора NVIDIA Ampere GA102» (PDF) . nvidia.com . Проверено 5 сентября 2023 г.
- ^ Луо, Вейле; Ли, Зею; Ван, Цян ( ) 2024 , Сяовэнь .
- ^ «Техническое описание NVIDIA A40» (PDF) . nvidia.com . Проверено 27 апреля 2024 г.
- ^ «АРХИТЕКТУРА графического процессора NVIDIA AMPERE GA102» (PDF) . 27 апреля 2024 г.
- ^ «Техническое описание NVIDIA L40» (PDF) . 27 апреля 2024 г.
- ^ В технических документах диаграммы куба Tensor Core представляют ширину единицы скалярного произведения в высоту (4 FP16 для Volta и Turing, 8 FP16 для A100, 4 FP16 для GA102, 16 FP16 для GH100). Два других измерения представляют количество единиц скалярного произведения (4x4 = 16 для Вольты и Тьюринга, 8x4 = 32 для Ампера и Хоппера). Полученные серые блоки представляют собой операции FMA FP16 за цикл. Pascal без ядра Tensor показан только для сравнения скорости, как и Volta V100 с типами данных, отличными от FP16.
- ^ «Информационный документ по архитектуре NVIDIA Turing» (PDF) . nvidia.com . Проверено 5 сентября 2023 г.
- ^ «Графический процессор NVIDIA с тензорными ядрами» (PDF) . nvidia.com . Проверено 5 сентября 2023 г.
- ^ «Подробное описание архитектуры NVIDIA Hopper» . 22 марта 2022 г.
- ^ форма x преобразованный размер операнда, например, 2 тензорных ядра x 4x4x4xFP16/цикл = 256 байт/цикл
- ^ = продукт в первых 3 строках таблицы
- ^ = произведение двух предыдущих строк таблицы; форма: например, 8x8x4xFP16 = 512 байт
- ^ Сунь, Вэй; Ли, Анг; Гэн, Тонг; Стейк, Сандер; Капрал, Хенк (2023 г.). «Анализ тензорных ядер с помощью микротестов: задержка, пропускная способность и числовое поведение». Транзакции IEEE в параллельных и распределенных системах . 34 (1): 246–261. arXiv : 2206.02874 . дои : 10.1109/tpds.2022.3217824 . S2CID 249431357 .
- ^ «Параллельное выполнение потоков ISA версии 7.7» .
- ^ Райхан, штат Мэриленд Аамир; Голи, Негар; Аамодт, Тор (2018). «Моделирование графических процессоров с поддержкой ускорителя глубокого обучения». arXiv : 1811.08309 [ cs.MS ].
- ^ «Архитектура NVIDIA Ады Лавлейс» .
- ^ форма x преобразованный размер операнда, например, 2 тензорных ядра x 4x4x4xFP16/цикл = 256 байт/цикл
- ^ = продукт в первых 3 строках таблицы
- ^ = произведение двух предыдущих строк таблицы; форма: например, 8x8x4xFP16 = 512 байт
- ^ Цзя, Чжэ; Маджиони, Марко; Смит, Джеффри; Даниэле Паоло Скарпацца (2019). «Анализ графического процессора NVidia Turing T4 с помощью микробенчмаркинга». arXiv : 1903.07486 [ cs.DC ].
- ^ Берджесс, Джон (2019). «RTX ON – графический процессор NVIDIA TURING» . 31-й симпозиум IEEE Hot Chips 2019 (HCS) . стр. 1–27. дои : 10.1109/HOTCHIPS.2019.8875651 . ISBN 978-1-7281-2089-8 . S2CID 204822166 .
- ^ Цзя, Чжэ; Маджиони, Марко; Смит, Джеффри; Даниэле Паоло Скарпацца (2019). «Анализ графического процессора NVidia Turing T4 с помощью микробенчмаркинга». arXiv : 1903.07486 [ cs.DC ].
- ^ Берджесс, Джон (2019). «RTX ON – графический процессор NVIDIA TURING» . 31-й симпозиум IEEE Hot Chips 2019 (HCS) . стр. 1–27. дои : 10.1109/HOTCHIPS.2019.8875651 . ISBN 978-1-7281-2089-8 . S2CID 204822166 .
- ^ зависит от устройства
- ^ «Тегра Х1» . 9 января 2015 г.
- ^ Архитектура графического процессора NVIDIA H100 с тензорным ядром
- ^ Ч.1. Функции и технические характеристики. Таблица 14. Технические характеристики по вычислительным возможностям.
- ^ Подробное описание архитектуры NVIDIA Hopper
- ^ может выполнять только 160 целочисленных инструкций согласно руководству по программированию.
- ^ 128 по данным [1] . 64 от ФП32 + 64 отдельных блока?
- ^ 64 ядрами FP32 и 64 гибкими ядрами FP32/INT.
- ^ «Руководство по программированию CUDA C++» .
- ^ 32 полосы FP32 объединяются в 16 полос FP64. Возможно, ниже в зависимости от модели.
- ^ поддерживается только 16 полосами FP32, они объединяются в 4 полосы FP64.
- ↑ Перейти обратно: Перейти обратно: а б с д и ж в зависимости от модели
- ^ Эффективная скорость, вероятно, через порты FP32. Нет описания реальных ядер FP64.
- ^ Также может использоваться для сложения и сравнения целых чисел.
- ^ 2 такта/инструкция для каждого раздела SM Берджесс, Джон (2019). «RTX ON – графический процессор NVIDIA TURING» . 31-й симпозиум IEEE Hot Chips 2019 (HCS) . стр. 1–27. дои : 10.1109/HOTCHIPS.2019.8875651 . ISBN 978-1-7281-2089-8 . S2CID 204822166 .
- ^ Дюрант, Люк; Жиру, Оливье; Харрис, Марк; Стэм, Ник (10 мая 2017 г.). «Внутри Volta: самый продвинутый в мире графический процессор для центров обработки данных» . Блог разработчиков NVIDIA .
- ^ Планировщики и диспетчеры имеют отдельные исполнительные блоки, в отличие от Ферми и Кеплера.
- ^ Диспетчеризация может перекрываться одновременно, если это занимает более одного цикла (когда количество исполнительных блоков меньше, чем 32/SM Partition)
- ^ Возможна двойная выпуск трубы MAD и трубы SFU.
- ^ Не более одного планировщика может выдать 2 инструкции одновременно. Первый планировщик отвечает за варпы с нечетными идентификаторами. Второй планировщик отвечает за варпы с четными ID.
- ↑ Перейти обратно: Перейти обратно: а б с д и ж общая память отдельная, но L1 включает в себя кэш текстур
- ^ «Н.6.1. Архитектура» . docs.nvidia.com . Проверено 13 мая 2019 г.
- ^ «Демистификация микроархитектуры графического процессора посредством микробенчмаркинга» (PDF) .
- ^ Цзя, Чжэ; Маджиони, Марко; Штайгер, Бенджамин; Скарпацца, Даниэле П. (2018). «Анализ архитектуры графического процессора NVIDIA Volta с помощью микробенчмаркинга». arXiv : 1804.06826 [ cs.DC ].
- ^ «Тегра Х1» . 9 января 2015 г.
- ^ Цзя, Чжэ; Маджиони, Марко; Смит, Джеффри; Даниэле Паоло Скарпацца (2019). «Анализ графического процессора NVidia Turing T4 с помощью микробенчмаркинга». arXiv : 1903.07486 [ cs.DC ].
- ^ «Анализ архитектуры графического процессора Ampere посредством микробенчмаркинга» .
- ^ Обратите внимание, что Цзя, Чжэ; Маджиони, Марко; Смит, Джеффри; Даниэле Паоло Скарпацца (2019). «Анализ графического процессора NVidia Turing T4 с помощью микробенчмаркинга». arXiv : 1903.07486 [ cs.DC ]. не согласен и заявляет, что кэш инструкций L0 составляет 2 КБ на раздел SM и кэш инструкций L1 16 КБ на SM.
- ^ Цзя, Чжэ; Маджиони, Марко; Штайгер, Бенджамин; Скарпацца, Даниэле П. (2018). «Анализ архитектуры графического процессора NVIDIA Volta с помощью микробенчмаркинга». arXiv : 1804.06826 [ cs.DC ].
- ^ «код операции асферми» . Гитхаб .
- ↑ Перейти обратно: Перейти обратно: а б для доступа только с текстурным движком
- ^ 25% отключено на RTX 4090.
- ^ «I.7. Вычислительные возможности 8.x» . docs.nvidia.com . Проверено 12 октября 2022 г.
- ^ «Приложение F. Характеристики и технические характеристики» (PDF) . (3,2 МБ) , стр. 148 из 175 (версия 5.0, октябрь 2012 г.).
- ^ «Биоинформатика nVidia CUDA: BarraCUDA» . БиоЦентрик . 19 июля 2019 г. Проверено 15 октября 2019 г.
- ^ «Часть V: Физическое моделирование» . Разработчик NVIDIA . Проверено 11 сентября 2020 г.
- ^ «Эксклюзив: за заговором с целью ослабить контроль Nvidia над искусственным интеллектом, нацелившись на программное обеспечение» . Рейтер . Проверено 5 апреля 2024 г.
- ^ «Вопрос: Что означает ROCm? · Проблема № 1628 · RadeonOpenCompute/ROCm» . Гитхаб.com . Проверено 18 января 2022 г.
Дальнейшее чтение [ править ]
- Бак, Ян; Фоули, Тим; Хорн, Дэниел; Шугерман, Джереми; Фатахалян, Кайвон; Хьюстон, Майк; Ханрахан, Пэт (1 августа 2004 г.). «Брук для графических процессоров: потоковые вычисления на графическом оборудовании» . Транзакции ACM с графикой . 23 (3): 777–786. дои : 10.1145/1015706.1015800 . ISSN 0730-0301 .
- Николлс, Джон; Бак, Ян; Гарланд, Майкл; Скадрон, Кевин (01 марта 2008 г.). «Масштабируемое параллельное программирование с помощью CUDA: является ли CUDA той моделью параллельного программирования, которую ждали разработчики приложений?» . Очередь . 6 (2): 40–53. дои : 10.1145/1365490.1365500 . ISSN 1542-7730 .
Внешние ссылки [ править ]
| Базы данных органов управления : Национальные |
|---|