Классический конвейер RISC
Эта статья включает список общих ссылок , но в ней отсутствуют достаточные соответствующие встроенные цитаты . ( декабрь 2012 г. ) |
В истории компьютерного оборудования некоторые ранние компьютеров с сокращенным набором команд центральные процессоры (RISC CPU) использовали очень похожее архитектурное решение, теперь называемое классическим RISC-конвейером . Этими процессорами были: MIPS , SPARC , Motorola 88000 , а позже и предполагаемый процессор DLX, изобретенный для образования.
Каждая из этих классических скалярных RISC-схем выбирает и пытается выполнить одну инструкцию за цикл . Основная общая концепция каждого проекта — пятиэтапный конвейер инструкций выполнения . Во время работы каждый этап конвейера одновременно обрабатывает одну инструкцию. Каждый из этих этапов состоит из набора триггеров для удержания состояния и комбинационной логики , которая работает с выходами этих триггеров.
Классический пятиэтапный конвейер - RISC

Получение инструкции [ править ]
Инструкции находятся в памяти, чтение которой занимает один цикл. Эта память может быть выделена для SRAM или кэша инструкций . Термин «задержка» часто используется в информатике и означает время от начала операции до ее завершения. Таким образом, задержка выборки инструкций составляет один такт (при использовании однотактной SRAM или если инструкция находилась в кеше). Таким образом, на этапе выборки инструкций из памяти команд извлекается 32-битная инструкция.
Счетчик программ или PC — это регистр, в котором хранится адрес, представленный в памяти команд. Адрес передается в память команд в начале цикла. Затем в ходе цикла инструкция считывается из памяти инструкций и одновременно производится расчет для определения следующего ПК. Следующий ПК рассчитывается путем увеличения ПК на 4 и выбора, считать ли его следующим ПК или использовать результат расчета ветвления/перехода в качестве следующего ПК. Обратите внимание, что в классическом RISC все инструкции имеют одинаковую длину. (Это то, что отличает RISC от CISC. [1] ). В исходных конструкциях RISC размер инструкции составляет 4 байта, поэтому всегда добавляйте 4 к адресу инструкции, но не используйте PC + 4 в случае взятого перехода, перехода или исключения (см. Задержанные переходы ниже). ). (Обратите внимание, что некоторые современные машины используют более сложные алгоритмы ( предсказание ветвления и предсказание цели ветвления ), чтобы угадать адрес следующей инструкции.)
Декодирование инструкций [ править ]
Еще одна вещь, которая отличает первые машины RISC от более ранних машин CISC, заключается в том, что RISC не имеет микрокода . [2] В случае микрокодированных инструкций CISC, после извлечения из кэша инструкций, биты инструкций сдвигаются вниз по конвейеру, где простая комбинационная логика на каждом этапе конвейера создает сигналы управления для тракта данных непосредственно из битов инструкций. В этих конструкциях CISC очень мало декодирования выполняется на этапе, традиционно называемом этапом декодирования. Следствием отсутствия декодирования является то, что для определения того, что делает инструкция, необходимо использовать больше битов инструкции. Это оставляет меньше битов для таких вещей, как индексы регистров.
Все инструкции MIPS, SPARC и DLX имеют не более двух регистровых входов. На этапе декодирования индексы этих двух регистров идентифицируются внутри инструкции, и индексы представляются в память регистра в виде адреса. Таким образом, два названных регистра считываются из файла регистров . В конструкции MIPS файл регистров содержал 32 записи.
В то же время, когда файл регистров считывается, логика выдачи инструкций на этом этапе определяет, готов ли конвейер выполнить инструкцию на этом этапе. В противном случае логика проблемы приводит к остановке как этапа выборки инструкций, так и этапа декодирования. В цикле остановки входные триггеры не принимают новые биты, поэтому в течение этого цикла новые вычисления не выполняются.
Если декодированная инструкция представляет собой ветвь или переход, целевой адрес ветвления или перехода вычисляется параллельно с чтением файла регистров. Условие перехода вычисляется в следующем цикле (после чтения файла регистров), и если ветвь выбрана или если инструкция является переходом, ПК на первом этапе назначается цель перехода, а не увеличенный ПК, который было вычислено. В некоторых архитектурах на этапе выполнения использовалось арифметико-логическое устройство (АЛУ) за счет небольшого снижения пропускной способности команд.
На этапе декодирования потребовалось довольно много аппаратного обеспечения: MIPS имеет возможность ветвления, если два регистра равны, поэтому 32-битное дерево И выполняется последовательно после чтения файла регистров, создавая очень длинный критический путь через это стадии (что означает меньшее количество циклов в секунду). Кроме того, вычисление цели ветвления обычно требует 16-битного сложения и 14-битного инкрементатора. Разрешение ветвления на этапе декодирования позволило получить штраф за неправильное предсказание ветвления всего за один цикл. Поскольку ветки были взяты очень часто (и, следовательно, неправильно предсказаны), было очень важно сохранить этот штраф на низком уровне.
Выполнить [ править ]
На этапе «Выполнение» происходят фактические вычисления. Обычно этот каскад состоит из АЛУ и битового переключателя. Он также может включать в себя многократный умножитель и делитель.
АЛУ отвечает за выполнение логических операций (и (или не) nand, nor, xor, xnor), а также за выполнение целочисленного сложения и вычитания. Помимо результата, АЛУ обычно предоставляет биты состояния, например, был ли результат равен 0 или произошло переполнение.
Бит-шифтер отвечает за сдвиг и вращение.
Инструкции на этих простых RISC-машинах можно разделить на три класса задержки в зависимости от типа операции:
- Операция регистр-регистр (задержка в одном цикле): сложение, вычитание, сравнение и логические операции. На этапе выполнения два аргумента были переданы в простой АЛУ, который сгенерировал результат к концу этапа выполнения.
- Ссылка на память (задержка в два цикла). Все загружается из памяти. На этапе выполнения АЛУ добавило два аргумента (регистр и постоянное смещение) для создания виртуального адреса к концу цикла.
- Многоцикловые инструкции (многоцикловая задержка). Целочисленное умножение и деление, а также все операции с плавающей запятой . На этапе выполнения операнды этих операций передавались в многотактный блок умножения/деления. Остальная часть конвейера могла продолжать выполнение, пока модуль умножения/деления выполнял свою работу. Чтобы не усложнять этап обратной записи и логику выдачи, многоцикловые инструкции записывали свои результаты в отдельный набор регистров.
Доступ к памяти [ править ]
Если необходимо получить доступ к памяти данных, это делается на этом этапе.
На этом этапе результаты команд с задержкой в один цикл просто передаются на следующий этап. Такая пересылка гарантирует, что инструкции как с одним, так и с двумя циклами всегда записывают свои результаты на одном и том же этапе конвейера, так что можно использовать только один порт записи в файл регистров, и он всегда доступен.
Для кэширования данных с прямым отображением и виртуальными тегами, самой простой из многочисленных организаций кэширования данных , две SRAM используются : одна для хранения данных, а другая для хранения тегов.
Обратная запись [ править ]
На этом этапе как однотактные, так и двухтактные инструкции записывают свои результаты в файл регистров. Обратите внимание, что два разных этапа одновременно обращаются к файлу регистров: этап декодирования считывает два исходных регистра, в то время как этап обратной записи записывает регистр назначения предыдущей инструкции. На реальном кремнии это может представлять опасность (более подробную информацию об опасностях см. ниже). Это связано с тем, что один из исходных регистров, считываемых при декодировании, может совпадать с регистром назначения, записываемым при обратной записи. Когда это происходит, одни и те же ячейки памяти в файле регистров читаются и записываются одновременно. На кремнии многие реализации ячеек памяти не будут работать корректно при одновременном чтении и записи.
Опасности [ править ]
Хеннесси и Паттерсон придумали термин «опасность» для ситуаций, когда инструкции в конвейере приводят к неверным ответам.
опасности Структурные
Структурные опасности возникают, когда две инструкции могут попытаться использовать одни и те же ресурсы одновременно. Классические конвейеры RISC позволяют избежать этих опасностей за счет репликации аппаратного обеспечения. В частности, инструкции ветвления могли использовать ALU для вычисления целевого адреса ветвления. Если бы для этой цели на этапе декодирования использовалось ALU, то за командой ALU, за которой следовала ветвь, обе инструкции попытались бы использовать ALU одновременно. Этот конфликт легко разрешить, внедрив на этапе декодирования специализированный сумматор целей ветвления.
Опасности для данных [ править ]
Опасность данных возникает, когда инструкция, запланированная вслепую, пытается использовать данные до того, как они станут доступны в файле регистра.
В классическом RISC-конвейере опасностей, связанных с данными, можно избежать одним из двух способов:
Решение А. Обход [ править ]
Обход также известен как пересылка операндов .
Предположим, что ЦП выполняет следующий фрагмент кода:
SUB r3,r4 -> r10 ; Writes r3 - r4 to r10
AND r10,r3 -> r11 ; Writes r10 & r3 to r11
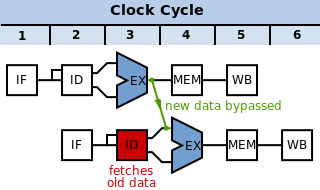
Этапы выборки и декодирования инструкций отправляют вторую команду на один такт после первой. Они текут по трубопроводу, как показано на этой схеме:

В простом конвейере , без учета опасностей, опасность данных развивается следующим образом:
В третьем цикле SUB инструкция вычисляет новое значение для r10. В этом же цикле AND операция декодируется, и значение r10 извлекается из файла реестра. Однако SUB инструкция еще не записала свой результат в r10. Обратная запись обычно происходит в цикле 5 (зеленый квадрат). Таким образом, значение, считанное из файла регистров и переданное в АЛУ (на этапе выполнения AND операция, красная рамка) неверно.
Вместо этого мы должны передать данные, вычисленные с помощью SUB вернуться на стадию «Выполнение» (т. е. к красному кружку на диаграмме) AND операция до того, как она будет нормально записана. Решением этой проблемы является пара обходных мультиплексоров. Эти мультиплексоры находятся в конце этапа декодирования, а их перевернутые выходные данные являются входами для АЛУ. Каждый мультиплексор выбирает между:
- Порт чтения регистрового файла (т.е. выход этапа декодирования, как в наивном конвейере): красная стрелка
- Текущий конвейер регистрации АЛУ (для обхода на один этап): синяя стрелка
- Текущий конвейер регистрации этапа доступа (который представляет собой либо загруженное значение, либо пересылаемый результат ALU, это обеспечивает обход двух этапов): фиолетовая стрелка. Обратите внимание, что для этого требуется, чтобы данные передавались назад во времени на один цикл. В этом случае пузырь , чтобы остановить необходимо вставить
ANDработа до тех пор, пока данные не будут готовы.
Логика этапа декодирования сравнивает регистры, записанные инструкциями на этапах выполнения и доступа конвейера, с регистрами, считанными инструкцией на этапе декодирования, и заставляет мультиплексоры выбирать самые последние данные. Эти обходные мультиплексоры позволяют конвейеру выполнять простые инструкции с задержкой только АЛУ, мультиплексора и триггера. Без мультиплексоров задержка записи и последующего чтения файла регистров должна была бы быть включена в задержку этих инструкций.
Обратите внимание, что данные можно передавать только вперед во времени — данные нельзя вернуть на более раннюю стадию, если они еще не были обработаны. В приведенном выше случае данные передаются вперед (к моменту AND готов к регистрации в АЛУ, SUB уже посчитал).
Решение B. Блокировка трубопровода [ править ]
Однако обратите внимание на следующие инструкции:
LD adr -> r10
AND r10,r3 -> r11
Данные, считанные с адреса adr не присутствует в кэше данных до завершения этапа доступа к памяти LD инструкция. К этому времени AND инструкция уже проходит через АЛУ. Чтобы решить эту проблему, потребуется передать данные из памяти назад во времени на вход АЛУ. Это невозможно. Решение состоит в том, чтобы отложить AND инструкция за один цикл. Опасность данных обнаруживается на этапе декодирования, а этапы выборки и декодирования останавливаются — они не могут перепутать свои входы и поэтому остаются в одном и том же состоянии в течение цикла. На последующих этапах выполнения, доступа и обратной записи между ними вставляется дополнительная инструкция без операции (NOP). LD и AND инструкции.
Этот NOP называется пузырем трубопровода , поскольку он плавает в трубопроводе, как пузырь воздуха в водопроводной трубе, занимая ресурсы, но не принося полезных результатов. Аппаратное обеспечение, позволяющее обнаружить угрозу данных и остановить конвейер до тех пор, пока опасность не будет устранена, называется блокировкой конвейера .
| Обход назад во времени | Проблема решена с помощью пузыря |

|

|
Однако блокировку конвейера не обязательно использовать при пересылке данных. Первый пример SUB с последующим AND и второй пример LD с последующим AND можно решить, остановив первый этап на три цикла, пока не будет достигнута обратная запись и данные в файле регистров не будут правильными, в результате чего правильное значение регистра будет выбрано ANDЭтап декодирования. Это приводит к значительному снижению производительности, поскольку процессор тратит много времени на ничего не обрабатывая, но тактовую частоту можно увеличить, поскольку требуется меньше логики пересылки.
Эту угрозу данным можно довольно легко обнаружить, когда машинный код программы пишется компилятором. В этом случае машина MIPS в Стэнфорде полагалась на то, что компилятор добавил инструкции NOP, вместо того, чтобы иметь схему для обнаружения и (что более трудоемко) остановки первых двух этапов конвейера. Отсюда и название MIPS: микропроцессор без взаимосвязанных этапов конвейера. Оказалось, что дополнительные инструкции NOP, добавленные компилятором, настолько расширили двоичные файлы программы, что скорость попадания в кэш инструкций снизилась. Аппаратное обеспечение стойла, хотя и дорогое, было возвращено в более поздние разработки, чтобы улучшить скорость попадания в кэш инструкций, после чего аббревиатура больше не имела смысла.
Контроль опасностей [ править ]
Опасности управления вызваны условным и безусловным ветвлением. Классический RISC-конвейер разрешает ветки на этапе декодирования, что означает, что повторение разрешения ветвей длится два цикла. Есть три последствия:
- Повторение разрешения ветвления проходит через довольно много схем: чтение кэша инструкций, чтение файла регистров, вычисление условия ветвления (которое включает 32-битное сравнение на процессорах MIPS) и мультиплексор адреса следующей инструкции.
- Поскольку цели ветвления и перехода вычисляются параллельно с чтением регистра, RISC ISA обычно не имеют инструкций, которые выполняют переход к адресу регистр+смещение. Поддерживается переход к регистрации.
- При любом переходе инструкция сразу после перехода всегда извлекается из кэша инструкций. Если эта инструкция игнорируется, за каждую взятую ветвь взимается штраф IPC в один цикл , что достаточно велико.
Существует четыре схемы решения этой проблемы производительности с помощью ветвей:
- Предсказать непринятие: Всегда извлекайте инструкцию после перехода из кэша инструкций, но выполняйте ее только в том случае, если ветвь не занята. Если ветвь не занята, конвейер остается заполненным. Если ветвь выбрана, инструкция сбрасывается (помечается как NOP), и возможность одного цикла завершить инструкцию теряется.
- Вероятность перехода: Всегда извлекайте инструкцию после перехода из кэша инструкций, но выполняйте ее только в том случае, если ветвь была занята. Компилятор всегда может заполнить слот задержки ветвления в такой ветке, и поскольку ветки чаще выполняются, чем нет, такие ветки имеют меньший штраф IPC, чем предыдущий тип.
- Слот задержки перехода : в зависимости от конструкции задержанного перехода и условий перехода определяется, выполняется ли команда, следующая сразу за командой перехода, даже если переход выполнен. Вместо того, чтобы взимать штраф IPC за некоторую долю ветвей, которые были приняты (возможно, 60%) или не выполнены (возможно, 40%), слоты задержки ветвления взимают штраф IPC для тех ветвей, для которых компилятор не смог запланировать слот задержки ветвления. Разработчики SPARC, MIPS и MC88K разработали слот задержки ветвления в своих ISA.
- Прогнозирование ветвей : параллельно с выборкой каждой инструкции угадывайте, является ли инструкция ветвью или переходом, и если да, то угадывайте цель. В цикле после ветвления или перехода извлеките инструкцию в предполагаемой цели. Если предположение неверно, сбросьте неправильно полученную цель.
Отложенные ветки вызывали споры, во-первых, потому, что их семантика сложна. Задержанная ветвь указывает, что переход в новое место происходит после выполнения следующей инструкции. Эта следующая инструкция неизбежно загружается кэшем инструкций после перехода.
Задержанные ветки подверглись критике [ кем? ] как плохой краткосрочный выбор в дизайне ISA:
- Компиляторы обычно испытывают некоторые трудности с поиском логически независимых инструкций для размещения после ветвления (инструкция после ветвления называется слотом задержки), поэтому им приходится вставлять NOP в слоты задержки.
- Суперскалярные процессоры, которые выполняют несколько инструкций за такт и должны иметь некоторую форму прогнозирования ветвлений, не получают преимуществ от отложенных ветвлений. Alpha ISA не учитывала отложенные переходы , поскольку была предназначена для суперскалярных процессоров.
- Самым серьезным недостатком отложенных ветвей является дополнительная сложность управления, которую они влекут за собой. Если команда слота задержки принимает исключение, процессор должен быть перезапущен на ветке, а не на следующей инструкции. Тогда исключения имеют по существу два адреса: адрес исключения и адрес перезапуска, и правильная генерация и различие между ними во всех случаях была источником ошибок для более поздних проектов.
Исключения [ править ]
Предположим, 32-битный RISC обрабатывает инструкцию ADD, которая складывает два больших числа, и результат не умещается в 32 бита.
Самое простое решение, предоставляемое большинством архитектур, — это арифметика переноса. У чисел, превышающих максимально возможное закодированное значение, старшие биты отсекаются до тех пор, пока они не поместятся. В обычной системе целых чисел 3000000000+3000000000=6000000000. С беззнаковой 32-битной арифметикой переноса, 3000000000+3000000000=1705032704 (6000000000 mod 2^32). Это может показаться не очень полезным. Самым большим преимуществом переносной арифметики является то, что каждая операция имеет четко определенный результат.
Но программист, особенно если программирует на языке, поддерживающем большие целые числа (например, Lisp или Scheme ), может не захотеть использовать арифметику переноса. Некоторые архитектуры (например, MIPS) определяют специальные операции сложения, которые при переполнении переходят в специальные места, а не переносят результат. Программное обеспечение в целевом расположении отвечает за устранение проблемы. Эта специальная ветвь называется исключением. Исключения отличаются от обычных ветвей тем, что целевой адрес не указывается самой инструкцией, а решение о переходе зависит от результата выполнения инструкции.
Самый распространенный тип видимого программным обеспечением исключения на одной из классических RISC-машин — это промах TLB .
Исключения отличаются от ветвей и переходов, поскольку эти другие изменения потока управления разрешаются на этапе декодирования. Исключения разрешаются на этапе обратной записи. При обнаружении исключения следующие инструкции (ранее находящиеся в конвейере) помечаются как недействительные, и по мере их прохождения к концу конвейера их результаты отбрасываются. В программный счетчик устанавливается адрес специального обработчика исключений, а в специальные регистры записываются место и причина исключения.
Чтобы программное обеспечение могло легко (и быстро) устранить проблему и перезапустить программу, ЦП должен принять точное исключение. Точное исключение означает, что все инструкции до исключающей инструкции были выполнены, а исключающая инструкция и все последующие не были выполнены.
Чтобы принять точные исключения, ЦП должен зафиксировать изменения в видимом состоянии программного обеспечения в порядке выполнения программы. Такая фиксация по порядку происходит очень естественно в классическом RISC-конвейере. Большинство инструкций записывают свои результаты в файл регистров на этапе обратной записи, и поэтому эти записи автоматически происходят в программном порядке. Однако инструкции сохранения записывают свои результаты в очередь данных сохранения на этапе доступа. Если инструкция сохранения принимает исключение, запись очереди данных сохранения становится недействительной, и она не записывается в SRAM данных кэша позже.
Обработка промахов в кэше [ править ]
Иногда кэш данных или инструкций не содержит необходимых данных или инструкций. В этих случаях ЦП должен приостановить работу до тех пор, пока кэш не будет заполнен необходимыми данными, а затем возобновить выполнение. Проблема заполнения кэша необходимыми данными (и, возможно, обратной записи в память вытесненной строки кэша) не является специфичной для конвейерной организации и здесь не обсуждается.
Существует две стратегии решения проблемы приостановки/возобновления. Первый — это глобальный сигнал сваливания. Этот сигнал, когда он активирован, предотвращает продвижение инструкций по конвейеру, как правило, путем отключения тактового сигнала триггеров в начале каждого этапа. Недостатком этой стратегии является наличие большого количества триггеров, поэтому для распространения глобального сигнала срыва требуется много времени. Поскольку машина обычно должна остановиться в том же цикле, в котором она определяет состояние, требующее остановки, сигнал остановки становится критическим путем, ограничивающим скорость.
Другая стратегия обработки приостановки/возобновления — повторное использование логики исключений. Машина принимает исключение для нарушающей инструкции, и все дальнейшие инструкции становятся недействительными. Когда кэш заполнится необходимыми данными, инструкция, вызвавшая промах в кэше, перезапускается. Чтобы ускорить обработку промахов в кэше данных, инструкцию можно перезапустить, чтобы ее цикл доступа происходил через один цикл после заполнения кэша данных.
См. также [ править ]
Ссылки [ править ]
- ^ Паттерсон, Дэвид (12 мая 1981 г.). «RISC I: Компьютер VLSI с сокращенным набором команд» . Иска '81. стр. 443–457.
- ^ Паттерсон, Дэвид (12 мая 1981 г.). «RISC I: Компьютер VLSI с сокращенным набором команд» . Иска '81. стр. 443–457.
- Хеннесси, Джон Л.; Паттерсон, Дэвид А. (2011). Компьютерная архитектура, количественный подход (5-е изд.). Морган Кауфманн. ISBN 978-0123838728 .