Одна инструкция, несколько данных
этой статьи Фактическая точность может быть нарушена из-за устаревшей информации . ( март 2017 г. ) |
| Таксономия Флинна |
|---|
| Единый поток данных |
| Несколько потоков данных |
| SIMD-подкатегории [1] |
| См. также |

Одна инструкция, несколько данных ( SIMD ) — это тип параллельной обработки в таксономии Флинна . SIMD может быть внутренним (часть аппаратной конструкции) и может быть доступен напрямую через архитектуру набора команд (ISA), но его не следует путать с ISA. SIMD описывает компьютеры с несколькими элементами обработки , которые выполняют одну и ту же операцию с несколькими точками данных одновременно.
Такие машины используют параллелизм на уровне данных , но не параллелизм : выполняются одновременные (параллельные) вычисления, но каждый модуль выполняет одну и ту же инструкцию в любой момент времени (только с разными данными). SIMD особенно применим для решения распространенных задач, таких как регулировка контрастности цифрового изображения или регулировка громкости цифрового звука . Большинство современных процессоров включают инструкции SIMD для повышения производительности использования мультимедиа . SIMD имеет три различные подкатегории в Таксономии Флинна 1972 года , одна из которых — SIMT . SIMT не следует путать с программными или аппаратными потоками , оба из которых представляют собой разделение времени задачи (распределение времени). SIMT — это настоящее одновременное параллельное выполнение на аппаратном уровне.
Современные графические процессоры (GPU) часто представляют собой широкие реализации SIMD, способные выполнять разветвления, загрузку и сохранение по 128 или 256 байтам за раз. Даже процессоры могут выполнять такие большие нагрузки: ширина кэш-линии x86 составляет 512 бит (64 байта).
История [ править ]
Первое использование инструкций SIMD было в ILLIAC IV , строительство которого было завершено в 1966 году.
SIMD послужил основой для векторных суперкомпьютеров начала 1970-х годов, таких как CDC Star-100 и Texas Instruments ASC , которые могли работать с «вектором» данных с помощью одной инструкции. Векторная обработка была особенно популяризирована Креем в 1970-х и 1980-х годах. Архитектуры векторной обработки теперь считаются отдельными от компьютеров SIMD: Таксономия Дункана включает их, а таксономия Флинна - нет, из-за работы Флинна (1966, 1972), предшествовавшей Cray-1 (1977).
Первая эра современных SIMD-компьютеров характеризовалась появлением с массовой параллельной обработкой, таких суперкомпьютеров как мыслительные машины CM-1 и CM-2 . Эти компьютеры имели множество процессоров с ограниченной функциональностью, которые работали параллельно. Например, каждый из 65 536 однобитовых процессоров «Мыслящей машины CM-2» будет одновременно выполнять одну и ту же инструкцию, что позволяет, например, логически объединять 65 536 пар битов одновременно, используя сеть, связанную с гиперкубом, или выделенная для процессора ОЗУ для поиска его операндов. Суперкомпьютеры отошли от подхода SIMD, когда недорогие скалярные подходы MIMD, основанные на обычных процессорах, таких как Intel i860 XP, стали более мощными, и интерес к SIMD пошел на убыль. [2]
Нынешняя эра SIMD-процессоров выросла из рынка настольных компьютеров, а не из рынка суперкомпьютеров. Поскольку в 1990-х годах процессоры для настольных ПК стали достаточно мощными для поддержки игр в реальном времени и обработки аудио/видео, спрос на этот конкретный тип вычислительной мощности вырос, и производители микропроцессоров обратились к SIMD, чтобы удовлетворить этот спрос. [3] Hewlett-Packard представила MAX инструкции в настольных компьютерах PA-RISC 1.1 в 1994 году для ускорения декодирования MPEG. [4] Компания Sun Microsystems представила целочисленные инструкции SIMD в своем « VIS расширении набора команд UltraSPARC I. » в 1995 году в своем микропроцессоре MIPS последовала этому примеру, выпустив аналогичную систему MDMX .
Первый широко распространенный SIMD для настольных компьютеров появился в 1996 году с расширением Intel MMX для архитектуры x86 . Это послужило толчком к внедрению гораздо более мощной системы AltiVec в системах Motorola PowerPC и IBM POWER . В ответ Intel в 1999 году представила совершенно новую систему SSE . С тех пор наборы команд SIMD были несколько расширены для обеих архитектур. Усовершенствованные векторные расширения AVX, AVX2 и AVX-512 разработаны Intel. AMD поддерживает AVX, AVX2 и AVX-512 в своих текущих продуктах. [5]
Все эти разработки были ориентированы на поддержку графики в реальном времени и, следовательно, ориентированы на обработку в двух, трех или четырех измерениях, обычно с длиной векторов от двух до шестнадцати слов, в зависимости от типа данных и архитектуры. Когда необходимо отличить новые архитектуры SIMD от старых, новые архитектуры считаются архитектурами с «короткими векторами», поскольку более ранние SIMD и векторные суперкомпьютеры имели длину векторов от 64 до 64 000. Современный суперкомпьютер почти всегда представляет собой кластер компьютеров MIMD, каждый из которых реализует (коротковекторные) инструкции SIMD.
Преимущества [ править ]
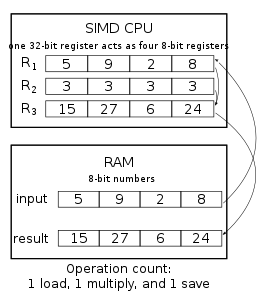
Приложение, которое может использовать преимущества SIMD, — это приложение, в котором одно и то же значение добавляется (или вычитается) к большому количеству точек данных, что является обычной операцией во многих мультимедийных приложениях. Одним из примеров может быть изменение яркости изображения. Каждый пиксель изображения состоит из трех значений яркости красной (R), зеленой (G) и синей (B) частей цвета. Для изменения яркости значения R, G и B считываются из памяти, к ним добавляется (или вычитается) значение, а полученные значения записываются обратно в память. аудио DSP Аналогично, для регулировки громкости одновременно умножает левый и правый каналы.
При использовании SIMD-процессора этот процесс имеет два улучшения. Подразумевается, что данные находятся в блоках, и одновременно можно загрузить несколько значений. Вместо серии инструкций, говорящих «получить этот пиксель, теперь получить следующий пиксель», SIMD-процессор будет иметь одну инструкцию, которая фактически говорит «получить n пикселей» (где n — число, которое варьируется от конструкции к конструкции). По ряду причин это может занять гораздо меньше времени, чем получение каждого пикселя по отдельности, как в случае традиционной конструкции ЦП.
Еще одним преимуществом является то, что инструкция обрабатывает все загруженные данные за одну операцию. Другими словами, если система SIMD работает, загружая одновременно восемь точек данных, add операция, применяемая к данным, будет применена ко всем восьми значениям одновременно. Этот параллелизм отличается от параллелизма, обеспечиваемого суперскалярным процессором ; восемь значений обрабатываются параллельно даже на несуперскалярном процессоре, а суперскалярный процессор может выполнять несколько операций SIMD параллельно.
Недостатки [ править ]
- Не все алгоритмы можно легко векторизовать. Например, сложных задач управления потоком данных, таких как синтаксический анализ SIMD может оказаться неэффективным для решения кода; однако теоретически возможно векторизовать сравнения и «пакетный поток» для достижения максимальной оптимальности кэша, хотя этот метод потребует большего промежуточного состояния. Примечание. Системы пакетного конвейера (пример: графические процессоры или конвейеры растеризации программного обеспечения) наиболее выгодны для управления кэшем при реализации с помощью встроенных функций SIMD, но они не являются исключительными для функций SIMD. Дополнительная сложность может оказаться очевидной, чтобы избежать зависимости внутри серий, таких как кодовые строки; в то время как для векторизации требуется независимость. [ нужны разъяснения ]
- Большие файлы регистров, что увеличивает энергопотребление и требуемую площадь чипа.
- В настоящее время реализация алгоритма с помощью SIMD-инструкций обычно требует человеческого труда; большинство компиляторов не генерируют SIMD-инструкции из типичной программы на языке C. Например, Автоматическая векторизация в компиляторах — активная область исследований в области информатики. (Сравните векторную обработку .)
- Программирование с использованием определенных наборов команд SIMD может включать в себя множество задач низкого уровня.
- SIMD может иметь ограничения на выравнивание данных ; программисты, знакомые с одной конкретной архитектурой, могут этого не ожидать. Хуже того: расклад может меняться от одной ревизии или «совместимого» процессора к другому.
- Сбор данных в SIMD-регистры и распределение их по нужным местам назначения представляет собой сложную задачу (иногда требующую операций перестановки ) и может быть неэффективной.
- Конкретные инструкции, такие как вращение или сложение трех операндов, недоступны в некоторых наборах команд SIMD.
- Наборы инструкций зависят от архитектуры: в некоторых процессорах полностью отсутствуют инструкции SIMD, поэтому программисты должны предоставлять для них невекторизованные реализации (или различные векторизованные реализации).
- Различные архитектуры предоставляют разные размеры регистров (например, 64, 128, 256 и 512 бит) и наборы команд, а это означает, что программистам приходится предоставлять несколько реализаций векторизованного кода для оптимальной работы на любом конкретном ЦП. Кроме того, возможный набор SIMD-инструкций растет с каждым новым размером регистра. К сожалению, из соображений поддержки устаревших версий старые версии не могут быть удалены.
- Ранний набор инструкций MMX разделял файл регистров со стеком с плавающей запятой, что приводило к неэффективности при смешивании кода с плавающей запятой и кода MMX. Однако SSE2 это исправляет.
Чтобы исправить проблемы 1 и 5, векторное расширение RISC-V использует альтернативный подход: вместо того, чтобы раскрывать программисту детали уровня подрегистра, набор команд абстрагирует их как несколько «векторных регистров», которые используют один и тот же код. интерфейсы всех процессоров с этим набором инструкций. Аппаратное обеспечение решает все проблемы выравнивания и «разбора» петель. Машины с разными размерами векторов смогут запускать один и тот же код. LLVM называет этот тип вектора «vscale». [ нужна ссылка ]
Увеличение размера кода на порядок не является чем-то необычным по сравнению с эквивалентным скалярным или эквивалентным векторным кодом, а эффективности на порядок или большую эффективность (работа, выполняемая на инструкцию). с помощью Vector ISA можно достичь [6]
ARM Масштабируемое векторное расширение использует другой подход, известный в таксономии Флинна как «ассоциативная обработка», более известный сегодня как «предикативный» (маскированный) SIMD. Этот подход не так компактен, как векторная обработка , но все же намного лучше, чем непредикатный SIMD. Подробные сравнительные примеры приведены на странице векторной обработки .
Хронология [ править ]
| Год | Пример |
|---|---|
| 1974 | ИЛЛИАК IV |
| 1974 | Процессор распределенных массивов ICL (DAP) |
| 1976 | Научный процессор Берроуза |
| 1981 | Геометрико-арифметический параллельный процессор от Martin Marietta (продолжение в Lockheed Martin , затем в Teranex и Silicon Optix ) |
| 1983-1991 | Массивно-параллельный процессор (MPP) от НАСА / Центра космических полетов Годдарда. |
| 1985 | Соединительная машина моделей 1 и 2 (CM-1 и CM-2) от Thinking Machines Corporation. |
| 1987-1996 | МасПар МП-1 и МП-2 |
| 1991 | Зефир DC из Wavetracer |
| 2001 | Xplor от Pyxsys, Inc. |
Аппаратное обеспечение [ править ]
Малые (64 или 128 бит) SIMD стали популярны в процессорах общего назначения в начале 1990-х годов и продолжались до 1997 года, а затем и позже с инструкциями Motion Video (MVI) для Alpha . Инструкции SIMD можно найти, в той или иной степени, на большинстве процессоров, включая IBM от AltiVec и SPE для PowerPC , HP от PA-RISC Multimedia Acceleration eXtensions (MAX) Intel от , MMX и iwMMXt , SSE , SSE2 , SSE3 SSSE3 и SSE4.x , AMD 3DNow ! , ARC подсистема ARC Video от SPARC и VIS2 от , VIS , Sun от MAJC , ARM от технология Neon , MIPS от MDMX (MaDMaX) и MIPS-3D . , совместно разработанный IBM, Sony и Toshiba, Cell процессора SPU Набор инструкций в значительной степени основан на SIMD. Компания Philips , ныне NXP , разработала несколько SIMD-процессоров под названием Xetal . Xetal имеет 320 16-битных процессорных элементов, специально разработанных для задач машинного зрения.
Инструкции Intel AVX-512 SIMD обрабатывают 512 бит данных одновременно.
Программное обеспечение [ править ]

Инструкции SIMD широко используются для обработки 3D-графики, хотя современные видеокарты со встроенным SIMD в значительной степени взяли на себя эту задачу от ЦП. Некоторые системы также включают функции перестановки, которые переупаковывают элементы внутри векторов, что делает их особенно полезными для обработки и сжатия данных. Они также используются в криптографии. [7] [8] [9] Тенденция вычислений общего назначения на графических процессорах ( GPGPU ) может привести к более широкому использованию SIMD в будущем.
Внедрение систем SIMD в программное обеспечение персональных компьютеров поначалу шло медленно из-за ряда проблем. Во-первых, многие из ранних наборов команд SIMD имели тенденцию замедлять общую производительность системы из-за повторного использования существующих регистров с плавающей запятой. Другие системы, такие как MMX и 3DNow! , предлагал поддержку типов данных, которые не были интересны широкой аудитории, и имел дорогостоящие инструкции по переключению контекста для переключения между использованием FPU и MMX регистров . Компиляторам также часто не хватало поддержки, что вынуждало программистов прибегать к кодированию на ассемблере .
SIMD на x86 запускался медленно. Внедрение 3DNow! от AMD и SSE от Intel несколько запутали ситуацию, но сегодня система, кажется, успокоилась (после того, как AMD приняла SSE), и новые компиляторы должны привести к появлению большего количества программного обеспечения с поддержкой SIMD. Intel и AMD теперь предоставляют оптимизированные математические библиотеки, использующие инструкции SIMD, и альтернативы с открытым исходным кодом, такие как libSIMD , SIMDx86 и SLEEF начали появляться (см. также libm ). [10]
Apple Computer имела несколько больший успех, хотя и вышла на рынок SIMD позже остальных. AltiVec предлагал богатую систему и мог быть запрограммирован с использованием все более совершенных компиляторов от Motorola , IBM и GNU , поэтому программирование на ассемблере требуется редко. Кроме того, многие системы, которые могли бы получить выгоду от SIMD, поставлялись самой Apple, например iTunes и QuickTime . Однако в 2006 году компьютеры Apple перешли на процессоры Intel x86. Apple API и инструменты разработки ( XCode ) были модифицированы для поддержки SSE2 и SSE3, а также AltiVec. Apple была доминирующим покупателем чипов PowerPC у IBM и Freescale Semiconductor . Несмотря на то, что Apple прекратила использовать процессоры PowerPC в своих продуктах, дальнейшее развитие AltiVec продолжается в нескольких разработках PowerPC и Power ISA от Freescale и IBM.
SIMD внутри регистра , или SWAR , представляет собой ряд методов и приемов, используемых для выполнения SIMD в регистрах общего назначения на оборудовании, которое не обеспечивает никакой прямой поддержки инструкций SIMD. Это можно использовать для использования параллелизма в определенных алгоритмах даже на оборудовании, которое не поддерживает SIMD напрямую.
Интерфейс программатора [ править ]
Издатели наборов инструкций SIMD обычно создают свои собственные расширения языка C/C++ со встроенными функциями или специальными типами данных (с перегрузкой операторов ), гарантирующими генерацию векторного кода. Intel, AltiVec и ARM NEON предоставляют расширения, широко используемые компиляторами для своих процессоров. (Более сложные операции — задача библиотек векторной математики.)
Компилятор GNU C развивает расширения, абстрагируя их в универсальный интерфейс, который можно использовать на любой платформе, предоставляя способ определения типов данных SIMD. [11] Компилятор LLVM Clang также реализует эту функцию с аналогичным интерфейсом, определенным в IR. [12] Руста packed_simd ящик (и экспериментальный std::sims) использует этот интерфейс, как и Swift 2.0+.
C++ имеет экспериментальный интерфейс std::experimental::simd это работает аналогично расширению GCC. Кажется, что libcxx LLVM реализует это. [ нужна ссылка ] Для GCC и libstdc++ доступна библиотека-оболочка, созданная на основе расширения GCC. [13]
Microsoft добавила SIMD в .NET в RyuJIT. [14] System.Numerics.Vector Пакет, доступный на NuGet, реализует типы данных SIMD. [15] Java также предлагает новый API для инструкций SIMD, доступный в OpenJDK 17 в модуле инкубатора. [16] Он также имеет безопасный механизм возврата к простым циклам на неподдерживаемых процессорах.
Вместо предоставления типа данных SIMD компиляторам также можно дать подсказку выполнить автоматическую векторизацию некоторых циклов, потенциально принимая некоторые утверждения об отсутствии зависимости данных. Это не так гибко, как непосредственное управление переменными SIMD, но его проще использовать. OpenMP 4.0+ имеет #pragma omp simd намекать. [17] Этот интерфейс OpenMP заменил широкий набор нестандартных расширений, включая Cilk . #pragma simd, [18] GCC #pragma GCC ivdepи многие другие. [19]
Многоверсионность SIMD [ править ]
Обычно ожидается, что потребительское программное обеспечение будет работать на различных процессорах нескольких поколений, что может ограничить возможности программиста использовать новые инструкции SIMD для повышения вычислительной производительности программы. Решение состоит в том, чтобы включить несколько версий одного и того же кода, использующих старые или новые технологии SIMD, и выбрать ту, которая лучше всего подходит для процессора пользователя во время выполнения ( динамическая диспетчеризация ). Есть два основных лагеря решений:
- Многоверсионность функций (FMV): подпрограмма в программе или библиотеке дублируется и компилируется для многих расширений набора команд, и программа решает, какое из них использовать во время выполнения.
- Многоверсионность библиотеки (LMV): вся программная библиотека дублируется для многих расширений набора команд, и операционная система или программа решают, какой из них загружать во время выполнения.
FMV, написанный вручную на языке ассемблера, довольно часто используется в ряде критичных к производительности библиотек, таких как glibc и libjpeg-turbo. Компилятор Intel C++ , коллекция компиляторов GNU, начиная с GCC 6, и Clang , начиная с clang 7, допускают упрощенный подход, при этом компилятор заботится о дублировании и выборе функций. GCC и clang требуют явного target_clones метки в коде для «клонирования» функций, [20] в то время как ICC делает это автоматически (с помощью параметра командной строки /Qax). Язык программирования Rust также поддерживает FMV. Настройка аналогична GCC и Clang в том, что код определяет, какие наборы команд компилируются, но клонирование выполняется вручную посредством встраивания. [21]
Поскольку использование FMV требует модификации кода в GCC и Clang, поставщики чаще используют многоверсионность библиотек: этого легче достичь, поскольку необходимо изменить только переключатели компилятора. Glibc поддерживает LMV, и эта функциональность используется в проекте Clear Linux, поддерживаемом Intel. [22]
SIMD в сети [ править ]
В 2013 году Джон Маккатчан объявил, что он создал высокопроизводительный интерфейс для наборов инструкций SIMD для языка программирования Dart , впервые привнеся преимущества SIMD в веб-программы. Интерфейс состоит из двух типов: [23]
- Float32x4, 4 значения с плавающей запятой одинарной точности.
- Int32x4, 4 32-битных целых значения.
Экземпляры этих типов неизменяемы и в оптимизированном коде отображаются непосредственно в регистры SIMD. Операции, выраженные в Dart, обычно компилируются в одну инструкцию без каких-либо накладных расходов. Это похоже на встроенные функции C и C++. Тесты для 4×4 умножения матриц , 3D-преобразования вершин и визуализации множества Мандельброта показывают ускорение почти на 400 % по сравнению со скалярным кодом, написанным на Dart.
Работа МакКутчана над Dart, которая теперь называется SIMD.js, была принята ECMAScript , и Intel объявила на IDF 2013, что они реализуют спецификацию МакКутчана как для V8 , так и для SpiderMonkey . [24] Однако к 2017 году SIMD.js был исключен из очереди стандартов ECMAScript в пользу использования аналогичного интерфейса в WebAssembly . [25] По состоянию на август 2020 года интерфейс WebAssembly остается незавершенным, но его переносимая 128-битная функция SIMD уже нашла применение во многих движках.
Emscripten, компилятор Mozilla C/C++-to-JavaScript, с расширениями может обеспечить компиляцию программ C++, использующих встроенные функции SIMD или векторный код в стиле GCC, с SIMD API JavaScript, что приводит к эквивалентному ускорению по сравнению со скалярным кодом. [26] Он также поддерживает (и теперь предпочитает) предложение 128-битного SIMD WebAssembly. [27]
Коммерческие приложения [ править ]
В целом оказалось сложно найти устойчивое коммерческое применение для процессоров, поддерживающих только SIMD.
Одним из проектов, который имел определенный успех, является GAPP , который был разработан Lockheed Martin и внедрен в коммерческий сектор их дочерней компанией Teranex . Последние воплощения GAPP стали мощным инструментом в приложениях обработки видео в реальном времени , таких как преобразование между различными видеостандартами и частотой кадров ( NTSC в/из PAL , NTSC в/из HDTV форматов и т. д.), деинтерлейсинг , уменьшение шума изображения , адаптивное сжатие видео и улучшение изображения.
Более распространенное применение SIMD можно найти в видеоиграх : почти каждая современная игровая консоль с 1998 года где-то в своей архитектуре включает процессор SIMD. PlayStation 2 была необычна тем, что один из ее векторных блоков с плавающей запятой мог функционировать как автономный DSP , выполняющий собственный поток инструкций, или как сопроцессор, управляемый обычными инструкциями ЦП. Приложения 3D-графики, как правило, хорошо подходят для обработки SIMD, поскольку они в значительной степени полагаются на операции с 4-мерными векторами. Microsoft Direct3D 9.0 теперь выбирает во время выполнения специфичные для процессора реализации своих собственных математических операций, включая использование инструкций с поддержкой SIMD.
Более поздним процессором, использовавшим векторную обработку, является процессор Cell, используемый в Playstation 3, который был разработан IBM в сотрудничестве с Toshiba и Sony . Он использует несколько процессоров SIMD ( архитектура NUMA , каждый из которых имеет независимое локальное хранилище и управляется центральным процессором общего назначения) и ориентирован на огромные наборы данных, необходимые приложениям для обработки 3D и видео. Он отличается от традиционных ISA тем, что изначально представляет собой SIMD, без отдельных скалярных регистров.
Ziilabs выпустила процессор типа SIMD для использования на мобильных устройствах, таких как медиаплееры и мобильные телефоны. [28]
Коммерческие SIMD-процессоры большего размера можно приобрести у компаний ClearSpeed Technology, Ltd. и Stream Processors, Inc. ClearSpeed CSX600 (2004 г.) имеет 96 ядер каждое с двумя модулями с плавающей запятой двойной точности, тогда как CSX700 (2008 г.) имеет 192 ядра. возглавляемый компьютерным архитектором Биллом Далли . Их процессор Storm-1 (2007 г.) содержит 80 ядер SIMD, управляемых процессором MIPS.
См. также [ править ]
- Потоковые расширения SIMD , MMX , SSE2 , SSE3 , Advanced Vector Extensions , AVX-512
- Архитектура набора команд
- Таксономия Флинна
- SIMD внутри реестра (SWAR)
- Одна программа, несколько данных (SPMD)
- OpenCL
Ссылки [ править ]
- ^ Флинн, Майкл Дж. (сентябрь 1972 г.). «Некоторые компьютерные организации и их эффективность» (PDF) . Транзакции IEEE на компьютерах . С-21 (9): 948–960. дои : 10.1109/TC.1972.5009071 .
- ^ «MIMD1 - XP/S, CM-5» (PDF) .
- ^ Конте, Г.; Томмесани, С.; Заничелли, Ф. (2000). «Долгий и извилистый путь к высокопроизводительной обработке изображений с помощью MMX/SSE». Учеб. Пятый международный семинар IEEE по компьютерным архитектурам для машинного восприятия . дои : 10.1109/CAMP.2000.875989 . hdl : 11381/2297671 . S2CID 13180531 .
- ^ Ли, РБ (1995). «Видео MPEG в реальном времени посредством программного распаковывания на процессоре PA-RISC». дайджест докладов Компкон '95. Технологии для информационной супермагистрали . стр. 186–192. дои : 10.1109/CMPCON.1995.512384 . ISBN 0-8186-7029-0 . S2CID 2262046 .
- ^ «Анализ производительности AMD Zen 4 AVX-512 в обзоре Ryzen 9 7950X» . www.phoronix.com . Проверено 13 июля 2023 г.
- ^ Паттерсон, Дэвид; Уотерман, Эндрю (18 сентября 2017 г.). «Инструкции SIMD считаются вредными» . СИГАРХ .
- ^ RE: Скорость SSE2 , показывающая, как SSE2 используется для реализации алгоритмов хеширования SHA.
- ^ Скорость Сальсы20; Программное обеспечение Salsa20 , демонстрирующее потоковый шифр, реализованный с использованием SSE2.
- ^ Тема: пропускная способность RSA до 1,4x с использованием SSE2 , демонстрирующая реализацию RSA с использованием инструкции целочисленного умножения SSE2, отличной от SIMD.
- ^ «Математические функции библиотеки SIMD» . Переполнение стека . Проверено 16 января 2020 г. .
- ^ «Векторные расширения» . Использование коллекции компиляторов GNU (GCC) . Проверено 16 января 2020 г. .
- ^ «Расширения языка Clang» . Документация Clang 11 . Проверено 16 января 2020 г. .
- ^ «ВкДевел/стд-симд» . ВкДевел. 6 августа 2020 г.
- ^ «RyuJIT: JIT-компилятор нового поколения для .NET» . 30 сентября 2013 г.
- ^ «JIT наконец сделала предложение. JIT и SIMD женятся» . 7 апреля 2014 г.
- ^ «JEP 338: Векторный API» .
- ^ «Директивы SIMD» . www.openmp.org .
- ^ «Учебное пособие по SIMD» . СилкПлюс . 18 июля 2012 г. Архивировано из оригинала 4 декабря 2020 г. . Проверено 9 августа 2020 г.
- ^ Крузе, Майкл. «OMP5.1: Преобразования цикла» (PDF) .
- ^ «Функция многоверсионности в GCC 6» . lwn.net .
- ^ «2045-целевой объект» . Книга Rust RFC .
- ^ «Прозрачное использование пакетов библиотек, оптимизированных для архитектуры Intel®» . Очистить проект Linux* . Проверено 8 сентября 2019 г.
- ^ Джон Маккатчан. «Перенос SIMD в Интернет через Dart» (PDF) . Архивировано из оригинала (PDF) 3 декабря 2013 г.
- ^ «SIMD в JavaScript» . 01.орг . 8 мая 2014 г.
- ^ «tc39/ecmascript_simd: числовой тип SIMD для EcmaScript» . Гитхаб . Экма TC39. 22 августа 2019 г. Проверено 8 сентября 2019 г.
- ^ Дженсен, Питер; Джибая, Иван; Ху, Нинсинь; Гоман, Дэн; Маккатчан, Джон (2015). «SIMD в JavaScript через C++ и Emscripten» (PDF) .
- ^ «Перенос кода SIMD для WebAssembly» . Документация Emscripten 1.40.1 .
- ^ "Медиапроцессор ZiiLABS ZMS-05 ARM 9" . ЗииЛабс . Архивировано из оригинала 18 июля 2011 г. Проверено 24 мая 2010 г.
Внешние ссылки [ править ]
- SIMD-архитектуры (2000)
- Взлом Pentium 3 (1999)
- Короткие векторные расширения в коммерческих микропроцессорах
- Статья об оптимизации конвейера рендеринга анимированных моделей с помощью расширений Intel Streaming SIMD
- «Yeppp!»: кроссплатформенная SIMD-библиотека с открытым исходным кодом от Технологического института Джорджии.
- Введение в параллельные вычисления от LLNL Ливерморской национальной лаборатории Лоуренса. Архивировано 10 июня 2013 г. в Wayback Machine.
- simde на GitHub : переносимая реализация встроенных функций, специфичных для других платформ (например, встроенных функций SSE для ARM NEON), с использованием заголовков C/C++.
| Базы данных органов управления : Национальные |
|---|