Параллелизм данных

Параллелизм данных — это распараллеливание нескольких процессоров в параллельных вычислительных средах. Он фокусируется на распределении данных между различными узлами, которые работают с данными параллельно. Его можно применять к обычным структурам данных, таким как массивы и матрицы, работая над каждым элементом параллельно. Это контрастирует с параллелизмом задач как другой формой параллелизма.
Параллельная работа с данными над массивом из n элементов может быть поровну разделена между всеми процессорами. Предположим, мы хотим суммировать все элементы данного массива, а время одной операции сложения составляет Ta единиц времени. В случае последовательного выполнения время, затрачиваемое процессом, будет составлять n ×Ta единиц времени, поскольку он суммирует все элементы массива. С другой стороны, если мы выполним это задание как параллельное задание по обработке данных на 4 процессорах, затраченное время уменьшится до ( n /4) × Ta + единиц времени накладных расходов на слияние. Параллельное выполнение приводит к ускорению в 4 раза по сравнению с последовательным выполнением. Важно отметить, что локальность ссылок на данные играет важную роль в оценке производительности модели параллельного программирования данных. Локальность данных зависит от обращений к памяти, выполняемых программой, а также от размера кэша.
История [ править ]
Использование концепции параллелизма данных началось в 1960-х годах с разработки машины Соломона. [1] Машина Соломона, также называемая векторным процессором , была разработана для ускорения выполнения математических операций за счет работы с большим массивом данных (операции с несколькими данными в последовательных временных шагах). Параллельность операций с данными также использовалась при одновременной работе с несколькими данными с использованием одной инструкции. Эти процессоры назывались «процессорами массива». [2] В 1980-е годы был введен термин [3] для описания этого стиля программирования, который широко использовался для программирования соединительных машин на языках с параллельными данными, таких как C* . Сегодня параллелизм данных лучше всего проявляется в графических процессорах (GPU), которые используют как методы работы с несколькими данными в пространстве, так и во времени с использованием одной инструкции.
Большинство аппаратных средств параллельного обмена данными поддерживают только фиксированное количество параллельных уровней, часто только один. Это означает, что в рамках параллельной операции невозможно рекурсивно запускать больше параллельных операций, а значит, программисты не могут использовать вложенный аппаратный параллелизм. Язык программирования NESL был первой попыткой реализовать вложенную модель параллельного программирования данных на плоскопараллельных машинах и, в частности, представил сглаживающее преобразование , которое преобразует вложенный параллелизм данных в плоский параллелизм данных. Эту работу продолжили другие языки, такие как Data Parallel Haskell и Futhark , хотя произвольный параллелизм вложенных данных не широко доступен в современных языках программирования с параллельными данными.
Описание [ править ]
В многопроцессорной системе, выполняющей один набор инструкций ( SIMD ), параллелизм данных достигается, когда каждый процессор выполняет одну и ту же задачу с разными распределенными данными. В некоторых ситуациях один поток выполнения управляет операциями со всеми данными. В других операциями управляют разные потоки, но они выполняют один и тот же код.
Например, рассмотрим умножение и сложение матриц последовательное , как описано в примере.
Пример [ править ]
Ниже приведен последовательный псевдокод умножения и сложения двух матриц, результат которого сохраняется в C. матрице Псевдокод умножения вычисляет скалярное произведение двух матриц A , B и сохраняет результат в выходную C. матрицу
Если бы следующие программы выполнялись последовательно, время, затраченное на вычисление результата, было бы (при условии, что длины строк и столбцов обеих матриц равны n) и для умножения и сложения соответственно.


// Matrix multiplication
for (i = 0; i < row_length_A; i++)
{
for (k = 0; k < column_length_B; k++)
{
sum = 0;
for (j = 0; j < column_length_A; j++)
{
sum += A[i][j] * B[j][k];
}
C[i][k] = sum;
}
}
// Array addition
for (i = 0; i < n; i++) {
c[i] = a[i] + b[i];
}
Мы можем использовать параллелизм данных в предыдущем коде, чтобы выполнить его быстрее, поскольку арифметика не зависит от цикла. Распараллеливание кода умножения матриц достигается с помощью OpenMP . Директива OpenMP «omp Parallel for» предписывает компилятору параллельно выполнять код в цикле for. Для умножения мы можем разделить матрицы A и B на блоки по строкам и столбцам соответственно. Это позволяет нам вычислять каждый элемент матрицы C индивидуально, тем самым делая задачу параллельной. Например: A[mxn] точка B [nxk] можно закончить за вместо при параллельном выполнении с использованием m*k процессоров .

// Matrix multiplication in parallel
#pragma omp parallel for schedule(dynamic,1) collapse(2)
for (i = 0; i < row_length_A; i++){
for (k = 0; k < column_length_B; k++){
sum = 0;
for (j = 0; j < column_length_A; j++){
sum += A[i][j] * B[j][k];
}
C[i][k] = sum;
}
}
Из примера видно, что процессоров потребуется много, поскольку размеры матриц продолжают увеличиваться. Сохранение низкого времени выполнения является приоритетом, но по мере увеличения размера матрицы мы сталкиваемся с другими ограничениями, такими как сложность такой системы и связанные с ней затраты. Следовательно, ограничивая количество процессоров в системе, мы все равно можем применить тот же принцип и разделить данные на более крупные фрагменты для вычисления произведения двух матриц. [4]
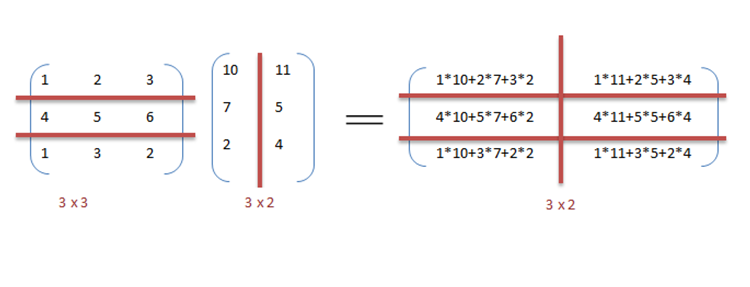
Для добавления массивов в реализацию параллельного обмена данными предположим, что это более скромная система с двумя центральными процессорами (ЦП) A и B. ЦП А может добавлять все элементы из верхней половины массивов, а ЦП Б может добавлять все элементы из нижняя половина массивов. Поскольку два процессора работают параллельно, операция сложения массива займет вдвое меньше времени, чем выполнение той же операции последовательно с использованием только одного ЦП.
Программа, выраженная в псевдокоде ниже, который применяет некоторую произвольную операцию, foo, для каждого элемента массива d— иллюстрирует параллелизм данных: [номер 1]
if CPU = "a" then
lower_limit := 1
upper_limit := round(d.length / 2)
else if CPU = "b" then
lower_limit := round(d.length / 2) + 1
upper_limit := d.length
for i from lower_limit to upper_limit by 1 do
foo(d[i])
В системе SPMD , работающей на двухпроцессорной системе, оба ЦП будут выполнять код.
Параллелизм данных подчеркивает распределенный (параллельный) характер данных, в отличие от обработки (параллелизм задач). Большинство реальных программ находятся где-то на континууме между параллелизмом задач и параллелизмом данных.
Шаги к распараллеливанию [ править ]
Процесс распараллеливания последовательной программы можно разбить на четыре отдельных этапа. [5]
| Тип | Описание |
|---|---|
| Разложение | Программа разбита на задачи — наименьшую единицу параллелизма, которую можно использовать. |
| Назначение | Задачи назначаются процессам. |
| оркестровка | Доступ к данным, связь и синхронизация процессов. |
| Картирование | Процессы привязаны к процессорам. |
Параллелизм данных параллелизм и задач
| Параллелизм данных | Параллелизм задач |
|---|---|
| Одни и те же операции выполняются с разными подмножествами одних и тех же данных. | Различные операции выполняются с одними и теми же или разными данными. |
| Синхронные вычисления | Асинхронные вычисления |
| Ускорение больше, поскольку со всеми наборами данных работает только один поток выполнения. | Ускорение меньше, поскольку каждый процессор будет выполнять отдельный поток или процесс с одним и тем же или другим набором данных. |
| Степень распараллеливания пропорциональна размеру входных данных. | Объем распараллеливания пропорционален количеству независимых задач, которые необходимо выполнить. |
| Разработан для оптимального баланса нагрузки в многопроцессорной системе. | Балансировка нагрузки зависит от доступности оборудования и алгоритмов планирования, таких как статическое и динамическое планирование. |
Параллелизм данных параллелизм и моделей
| Параллелизм данных | Модельный параллелизм |
|---|---|
| Одна и та же модель используется для каждого потока, но данные, передаваемые каждому из них, разделены и совместно используются. | Для каждого потока используются одни и те же данные, а модель распределяется между потоками. |
| Это быстро для небольших сетей, но очень медленно для больших сетей, поскольку между процессорами необходимо одновременно передавать большие объемы данных. | Это медленно для небольших сетей и быстро для больших сетей. |
| Параллелизм данных идеально используется в вычислениях массивов и матриц, а также в сверточных нейронных сетях. | Модельный параллелизм находит свое применение в глубоком обучении |
данные и параллелизм задач Смешанные
Параллелизм данных и задач можно реализовать одновременно, объединив их для одного приложения. Это называется параллелизмом смешанных данных и задач. Смешанный параллелизм требует сложных алгоритмов планирования и программной поддержки. Это лучший вид параллелизма, когда обмен данными медленный и количество процессоров велико. [7]
Параллелизм смешанных данных и задач имеет множество применений. Он особенно используется в следующих приложениях:
- Параллелизм смешанных данных и задач находит применение в моделировании глобального климата. Параллельные вычисления с большими данными выполняются путем создания сеток данных, представляющих атмосферу и океаны Земли, а параллелизм задач используется для моделирования функции и модели физических процессов.
- При моделировании схем на основе синхронизации . Данные распределяются между различными подсхемами, а параллелизм достигается за счет оркестровки задач.
Среды параллельного данных программирования
Сегодня доступны различные среды параллельного программирования данных, наиболее широко используемые из которых:
- Интерфейс передачи сообщений : это кроссплатформенный программный интерфейс передачи сообщений для параллельных компьютеров. Он определяет семантику библиотечных функций, позволяющую пользователям писать переносимые программы передачи сообщений на C, C++ и Fortran.
- Открытая многопроцессорная обработка [8] (Open MP): это интерфейс прикладного программирования (API), который поддерживает модели программирования с общей памятью на нескольких платформах многопроцессорных систем. Начиная с версии 4.5, OpenMP также может работать с устройствами, отличными от типичных процессоров. Он может программировать FPGA, DSP, графические процессоры и многое другое. Это не ограничивается графическими процессорами, такими как OpenACC.
- CUDA и OpenACC : CUDA и OpenACC (соответственно) — это платформы API параллельных вычислений, разработанные для того, чтобы инженер-программист мог использовать вычислительные блоки графического процессора для обработки общего назначения.
- Строительные блоки Threading и RaftLib : обе среды программирования с открытым исходным кодом, которые обеспечивают параллелизм смешанных данных и задач в средах C/C++ для гетерогенных ресурсов.
Приложения [ править ]
Параллелизм данных находит свое применение в самых разных областях: от физики, химии, биологии, материаловедения до обработки сигналов. Наука подразумевает параллелизм данных для моделирования таких моделей, как молекулярная динамика, [9] анализ последовательности данных генома [10] и другие физические явления. Движущими силами обработки сигналов для параллелизма данных являются кодирование видео, обработка изображений и графики, беспроводная связь. [11] чтобы назвать несколько.
данных использованием с интенсивным Вычисления
См. также [ править ]
- Активное сообщение
- Параллелизм на уровне инструкций
- Модель параллельного программирования
- Префиксная сумма
- Масштабируемый параллелизм
- Сегментированное сканирование
- Параллелизм на уровне потоков
Примечания [ править ]
- ^ Некоторые входные данные (например, когда
d.lengthоценивается как 1 иroundокругление в сторону нуля [это всего лишь пример, требований к тому, какой тип округления не существует]) приведет кlower_limitбыть больше, чемupper_limit, предполагается, что цикл завершится немедленно (т. е. произойдет ноль итераций), когда это произойдет.
Ссылки [ править ]
- ^ «Компьютер Соломона» .
- ^ «SIMD/Вектор/ГП» (PDF) . Проверено 7 сентября 2016 г.
- ^ Хиллис, В. Дэниел и Стил, Гай Л. , Коммуникации по параллельным алгоритмам данных ACM, декабрь 1986 г.
- ^ Барни, Блейз. «Введение в параллельные вычисления» . Computing.llnl.gov . Архивировано из оригинала 10 июня 2013 г. Проверено 7 сентября 2016 г.
- ^ Солихин, Ян (2016). Основы параллельной архитектуры Бока-Ратон, Флорида: CRC Press. ISBN 978-1-4822-1118-4 .
- ^ «Как распараллелить глубокое обучение на графических процессорах. Часть 2/2: Параллелизм моделей» . Тим Деттмерс . 09.11.2014 . Проверено 13 сентября 2016 г.
- ^ «Netlib» (PDF) .
- ^ «ОпенМП.орг» . openmp.org . Архивировано из оригинала 5 сентября 2016 г. Проверено 7 сентября 2016 г.
- ^ Бойер, Л.Л; Поли, Г.С. (1 октября 1988 г.). «Молекулярная динамика кластеров частиц, взаимодействующих с парными силами, с использованием массово-параллельного компьютера». Журнал вычислительной физики . 78 (2): 405–423. Бибкод : 1988JCoPh..78..405B . дои : 10.1016/0021-9991(88)90057-5 .
- ^ Яп, ТК; Фридер, О.; Мартино, РЛ (1998). «Параллельные вычисления в анализе биологических последовательностей». Транзакции IEEE в параллельных и распределенных системах . 9 (3): 283–294. CiteSeerX 10.1.1.30.2819 . дои : 10.1109/71.674320 .
- ^ Сингх, Х.; Ли, Минг-Хау; Лу, Гуанмин; Курдахи, Ф.Дж.; Багерзаде, Н.; Фильо, Э.М. Чавес (1 июня 2000 г.). «MorphoSys: интегрированная реконфигурируемая система для приложений с параллельными данными и интенсивными вычислениями» . Транзакции IEEE на компьютерах . 49 (5): 465–481. дои : 10.1109/12.859540 . ISSN 0018-9340 .
- ^ Справочник по облачным вычислениям , «Технологии с интенсивным использованием данных для облачных вычислений», А. М. Миддлтон. Справочник по облачным вычислениям. Спрингер, 2010.
- Хиллис, В. Дэниел и Стил, Гай Л. , параллельным алгоритмам данных, Коммуникации ACM по декабрь 1986 г.
- Блеллок, Гай Э., Векторные модели для параллельных вычислений, MIT Press, 1990. ISBN 0-262-02313-X
| Общий | |
|---|---|
| Уровни | |
| Многопоточность | |
| Теория | |
| Элементы | |
| Координация | |
| Программирование | |
| Аппаратное обеспечение | |
| API | |
| Проблемы | |