Несколько инструкций, несколько данных
| Таксономия Флинна |
|---|
| Единый поток данных |
| Несколько потоков данных |
| SIMD-подкатегории [1] |
| См. также |
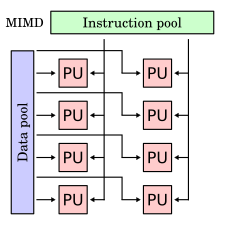
В вычислениях множественные инструкции , множественные данные ( MIMD ) — это метод, используемый для достижения параллелизма. Машины, использующие MIMD, имеют ряд процессоров , которые работают асинхронно и независимо. В любой момент разные процессоры могут выполнять разные инструкции для разных фрагментов данных.
Архитектуры MIMD могут использоваться в ряде прикладных областей, таких как автоматизированное проектирование / автоматизированное производство , моделирование , моделирование и в качестве коммутаторов связи . Машины MIMD могут относиться как к общей, так и к распределенной памяти . Эти классификации основаны на том, как процессоры MIMD получают доступ к памяти. Машины с общей памятью могут быть шинного , расширенного или иерархического типа. Машины с распределенной памятью могут иметь гиперкуба или ячеистой схемы связи.
Примеры [ править ]
Примером системы MIMD является Intel Xeon Phi , произошедшая от микроархитектуры Larrabee . [2] Эти процессоры имеют несколько вычислительных ядер (до 61 по состоянию на 2015 год), которые могут выполнять разные инструкции для разных данных.
Большинство параллельных компьютеров по состоянию на 2013 год представляют собой системы MIMD. [3]
[ править ]
В модели с общей памятью все процессоры подключены к «глобально доступной» памяти либо программными , либо аппаратными средствами. Операционная система обычно поддерживает согласованность своей памяти . [4]
С точки зрения программиста, эта модель памяти лучше понятна, чем модель распределенной памяти. Еще одним преимуществом является то, что согласованностью памяти управляет операционная система, а не написанная программа. Двумя известными недостатками являются: затруднена масштабируемость за пределами тридцати двух процессоров, а модель общей памяти менее гибка, чем модель распределенной памяти. [4]
Существует множество примеров разделяемой памяти (мультипроцессоры): UMA ( унифицированный доступ к памяти ), COMA ( доступ только к кэш-памяти ). [5]
На базе автобуса [ править ]
MIMD-машины с общей памятью имеют процессоры, которые используют общую центральную память. В простейшей форме все процессоры подключены к шине, соединяющей их с памятью. Это означает, что каждая машина с общей памятью использует определенную CM, общую систему шин для всех клиентов.
Например, если мы рассмотрим шину с клиентами A, B, C, подключенными с одной стороны, и P, Q, R, подключенными с противоположной стороны,любой из клиентов будет связываться с другим посредством интерфейса шины между ними.
Иерархический [ править ]
MIMD-машины с иерархической общей памятью используют иерархию шин (как, например, в « толстом дереве »), чтобы предоставить процессорам доступ к памяти друг друга. Процессоры на разных платах могут обмениваться данными через межузловые шины. Автобусы поддерживают связь между платами. Благодаря архитектуре такого типа машина может поддерживать более девяти тысяч процессоров.
Распределенная память [ править ]
В машинах MIMD с распределенной памятью (несколько инструкций, несколько данных) каждый процессор имеет свою индивидуальную ячейку памяти. Каждый процессор не имеет прямых сведений о памяти другого процессора. Для совместного использования данных их необходимо передать от одного процессора к другому в виде сообщения. Поскольку общей памяти нет, конкуренция на этих машинах не является такой серьезной проблемой. Соединять большое количество процессоров напрямую друг с другом экономически нецелесообразно. Чтобы избежать такого множества прямых соединений, необходимо соединить каждый процессор всего с несколькими другими. Этот тип конструкции может оказаться неэффективным из-за дополнительного времени, необходимого для передачи сообщения от одного процессора к другому по пути сообщения. Количество времени, необходимое процессорам для выполнения простой маршрутизации сообщений, может быть значительным. Системы были разработаны для уменьшения этих потерь времени, а гиперкуб и сетка входят в число двух популярных схем межсетевого взаимодействия.
Примеры распределенной памяти (несколько компьютеров) включают MPP (массово-параллельные процессоры) , COW (кластеры рабочих станций) и NUMA ( неравномерный доступ к памяти ). Первый вариант сложен и дорог: множество суперкомпьютеров соединены широкополосными сетями. Примеры включают гиперкуб и межсетевые соединения. COW — это «самодельная» версия за небольшую цену. [5]
Соединительная сеть гиперкуба [ править ]
В машине с распределенной памятью MIMD с сетью межсистемных связей системы гиперкуба , содержащей четыре процессора, процессор и модуль памяти размещаются в каждой вершине квадрата. Диаметр системы — это минимальное количество шагов, необходимое одному процессору для отправки сообщения процессору, находящемуся дальше всего. Так, например, диаметр 2-куба равен 2. В системе гиперкуба с восемью процессорами, где каждый процессор и модуль памяти размещены в вершине куба, диаметр равен 3. В общем случае система, содержащая 2 ^N процессоров, каждый из которых напрямую подключен к N другим процессорам, диаметр системы равен N. Одним из недостатков системы гиперкуба является то, что она должна быть сконфигурирована со степенями двойки, поэтому необходимо построить машину, которая потенциально может иметь гораздо больше процессоров. процессоров, чем действительно необходимо для приложения.
Mesh-сеть [ править ]
В машине с распределенной памятью MIMD с ячеистой сетью взаимосвязей процессоры размещаются в двумерной сетке. Каждый процессор связан со своими четырьмя непосредственными соседями. По краям сетки могут быть предусмотрены обертывающие соединения. Одним из преимуществ ячеистой сети взаимосвязей по сравнению с гиперкубом является то, что ячеистую систему не нужно настраивать по степени двойки. Недостатком является то, что диаметр ячеистой сети больше, чем у гиперкуба для систем с числом процессоров более четырех.
См. также [ править ]
- МЛАДШАЯ СРЕДНЯЯ ШКОЛА
- НУМА
- Межблочное соединение тора
- Таксономия Флинна
- СПМД
- Суперскаляр
- Очень длинное командное слово
Ссылки [ править ]
- ^ Флинн, Майкл Дж. (сентябрь 1972 г.). «Некоторые компьютерные организации и их эффективность» (PDF) . Транзакции IEEE на компьютерах . С-21 (9): 948–960. дои : 10.1109/TC.1972.5009071 .
- ^ «Опасности параллельности: Ларраби против Nvidia, MIMD против SIMD» . 19 сентября 2008 г.
- ^ «MIMD | Зона разработчиков Intel®» . Архивировано из оригинала 16 октября 2013 г. Проверено 16 октября 2013 г.
- ↑ Перейти обратно: Перейти обратно: а б Ибаруден, Джаффер. «Параллельная обработка, EG6370G: Глава 1, Мотивация и история». Слайды лекций. Университет Святой Марии , Сан-Антонио, Техас . Весна 2008 года.
- ↑ Перейти обратно: Перейти обратно: а б Эндрю С. Таненбаум (1997). Структурированная компьютерная организация (4-е изд.). Прентис-Холл. стр. 559–585. ISBN 978-0130959904 . Архивировано из оригинала 1 декабря 2013 г. Проверено 15 марта 2013 г.
| Базы данных органов управления : Национальные |
|---|