Статистика
| Статистика |
|---|
 |
| Часть серии о | ||
| Математика | ||
|---|---|---|


Статистика (от немецкого : Statistik , ориг. «описание государства , страны») [1] [2] это дисциплина, которая занимается сбором, организацией, анализом, интерпретацией и представлением данных . [3] [4] [5] Применяя статистику к научной, промышленной или социальной проблеме, принято начинать со статистической совокупности или статистической модели , которую необходимо изучить. Популяции могут представлять собой различные группы людей или объектов, например «все люди, живущие в стране» или «каждый атом, составляющий кристалл». Статистика касается всех аспектов данных, включая планирование сбора данных с точки зрения планирования обследований и экспериментов . [6]
Когда данные переписи не могут быть собраны, статистики собирают данные путем разработки конкретных планов экспериментов и выборок обследований . Репрезентативная выборка гарантирует, что выводы и выводы могут быть разумно распространены как на выборку, так и на генеральную совокупность в целом. Экспериментальное исследование включает в себя проведение измерений изучаемой системы, манипулирование системой, а затем проведение дополнительных измерений с использованием той же процедуры, чтобы определить, изменило ли манипуляция значения измерений. Напротив, наблюдательное исследование не предполагает экспериментальных манипуляций.
используются два основных статистических метода При анализе данных : описательная статистика , которая суммирует данные выборки с использованием таких индексов , как среднее или стандартное отклонение , и статистика , основанная на выводах, которая делает выводы на основе данных, которые подвержены случайным изменениям (например, ошибки наблюдения, вариация выборки). [7] Описательная статистика чаще всего связана с двумя наборами свойств распределения ( выборки или совокупности): центральная тенденция (или местоположение ) стремится охарактеризовать центральное или типичное значение распределения, тогда как дисперсия (или изменчивость ) характеризует степень, в которой члены распределения отходят от своего центра и друг от друга. Выводы по математической статистике делаются в рамках теории вероятностей , которая занимается анализом случайных явлений.
Стандартная статистическая процедура включает сбор данных, ведущий к проверке взаимосвязи между двумя наборами статистических данных или набором данных и синтетическими данными, полученными из идеализированной модели. Предлагается гипотеза статистической взаимосвязи между двумя наборами данных, и она сравнивается как альтернатива идеализированной нулевой гипотезе об отсутствии связи между двумя наборами данных. Отвержение или опровержение нулевой гипотезы осуществляется с помощью статистических тестов, которые количественно определяют, в каком смысле нулевая гипотеза может оказаться ложной, с учетом данных, которые используются в тесте. При работе с нулевой гипотезой выделяются две основные формы ошибок: ошибки типа I (нулевая гипотеза отклоняется, когда она на самом деле верна, что дает «ложноположительный результат») и ошибки типа II (нулевая гипотеза не может быть отклонена, когда она на самом деле является ложным и дает «ложноотрицательный результат»). С этой структурой связано множество проблем: от получения достаточного размера выборки до определения адекватной нулевой гипотезы. [7]
Процессы статистических измерений также подвержены ошибкам в отношении данных, которые они генерируют. Многие из этих ошибок классифицируются как случайные (шум) или систематические ( предвзятость ), но могут возникать и другие типы ошибок (например, грубая ошибка, например, когда аналитик сообщает неправильные единицы измерения). Наличие недостающих данных или цензуры может привести к необъективным оценкам, и для решения этих проблем были разработаны специальные методы.
Введение [ править ]
Статистика — это математическая область науки, которая занимается сбором, анализом, интерпретацией или объяснением, а также представлением данных . [8] или как раздел математики . [9] Некоторые считают статистику отдельной математической наукой, а не разделом математики. Хотя во многих научных исследованиях используются данные, статистика обычно занимается использованием данных в контексте неопределенности и принятием решений в условиях неопределенности. [10] [11]
При применении статистики к проблеме принято начинать с совокупности изучаемой или процесса. Популяции могут быть разными по темам, например, «все люди, живущие в стране» или «каждый атом, составляющий кристалл». В идеале статистики собирают данные обо всем населении (операция, называемая переписью ). Это может быть организовано государственными статистическими учреждениями. Описательная статистика может использоваться для обобщения данных о населении. Числовые дескрипторы включают среднее и стандартное отклонение для непрерывных данных (например, дохода), тогда как частота и процент более полезны с точки зрения описания категориальных данных (например, образования).
Когда перепись невозможна, выбранная подгруппа населения, называемая выборкой изучается . После того, как определена выборка, репрезентативная для совокупности, собираются данные о членах выборки в условиях наблюдения или эксперимента . Опять же, для обобщения выборочных данных можно использовать описательную статистику. Однако составление выборки содержит элемент случайности; следовательно, числовые дескрипторы выборки также подвержены неопределенности. Чтобы сделать значимые выводы обо всей популяции, статистические выводы необходимы . Он использует закономерности в выборочных данных, чтобы сделать выводы о представленной совокупности с учетом случайности. Эти выводы могут принимать форму ответов да/нет на вопросы о данных ( проверка гипотез ), оценки числовых характеристик данных ( оценка ), описания ассоциаций внутри данных ( корреляция ) и моделирования отношений внутри данных (например, с использованием регрессионный анализ ). Вывод может распространяться на прогнозирование , предсказание и оценка ненаблюдаемых значений либо в изучаемой популяции, либо связанных с ней. Он может включать экстраполяцию и интерполяцию временных рядов или пространственных данных , а также интеллектуальный анализ данных .
Математическая статистика [ править ]
Математическая статистика – это применение математики к статистике. Математические методы, используемые для этого, включают математический анализ , линейную алгебру , стохастический анализ , дифференциальные уравнения и теорию вероятностей на основе теории меры . [12] [13]
История [ править ]

Официальные дискуссии о выводах восходят к арабским математикам и криптографам , во времена Золотого века ислама, между 8 и 13 веками. Аль-Халил (717–786) написал « Книгу криптографических сообщений» , в которой содержится одно из первых применений перестановок и комбинаций , в котором перечислены все возможные арабские слова с гласными и без них. [14] В «Рукописи Аль-Кинди по расшифровке криптографических сообщений» дано подробное описание того, как использовать частотный анализ для расшифровки зашифрованных сообщений, что является ранним примером статистического вывода для декодирования . Ибн Адлан (1187–1268) позже внес важный вклад в использование размера выборки в частотном анализе. [14]
Хотя термин «статистика» был введен итальянским ученым Джироламо Гилини в 1589 году применительно к совокупности фактов и сведений о государстве, именно немец Готфрид Ахенвалль в 1749 году начал использовать этот термин как совокупность количественной информации, в современное применение этой науки. [15] [16] Самое раннее сочинение, содержащее статистические данные, в Европе датируется 1663 годом, когда « Естественные и политические наблюдения над счетами смертности» опубликовал Джон Граун . [17] Ранние применения статистического мышления вращались вокруг потребности государств основывать политику на демографических и экономических данных, отсюда и ее статистическая этимология . В начале XIX века сфера применения статистики расширилась и теперь включает сбор и анализ данных в целом. Сегодня статистика широко используется в правительстве, бизнесе, естественных и социальных науках.

Математические основы статистики возникли в результате дискуссий об азартных играх среди таких математиков, как Джероламо Кардано , Блез Паскаль , Пьер де Ферма и Христиан Гюйгенс . Хотя идея вероятности уже рассматривалась в древнем и средневековом праве и философии (например, в работах Хуана Карамуэля ), теория вероятностей как математическая дисциплина оформилась только в самом конце 17 века, особенно в Якоба Бернулли посмертной работе Ars. Конъектанди . [18] Это была первая книга, в которой сфера азартных игр и область вероятного (касающегося мнений, доказательств и аргументов) были объединены и подвергнуты математическому анализу. [19] [20] Метод наименьших квадратов был впервые описан Адрианом-Мари Лежандром в 1805 году, хотя Карл Фридрих Гаусс , предположительно, использовал его десятилетием ранее, в 1795 году. [21]

Современная область статистики возникла в конце 19 - начале 20 века в три этапа. [22] Первую волну, на рубеже веков, возглавили работы Фрэнсиса Гальтона и Карла Пирсона , которые превратили статистику в строгую математическую дисциплину, используемую для анализа не только в науке, но также в промышленности и политике. Вклад Гальтона включал в себя введение концепций стандартного отклонения , корреляции , регрессионного анализа и применение этих методов к изучению различных характеристик человека, среди которых рост, вес и длина ресниц. [23] Пирсон разработал коэффициент корреляции момента произведения Пирсона , определяемый как момент произведения, [24] метод моментов для подгонки распределений к выборкам и распределение Пирсона , среди прочего. [25] Гальтон и Пирсон основали «Биометрику» как первый журнал по математической статистике и биостатистике (тогда называвшейся «биометрией»), а последний основал первый в мире факультет университетской статистики в Университетском колледже Лондона . [26]
Вторая волна 1910-х и 20-х годов была инициирована Уильямом Сили Госсетом и достигла своей кульминации в прозрениях Рональда Фишера , написавшего учебники, которые должны были определить академические дисциплины в университетах по всему миру. Наиболее важными публикациями Фишера были его основополагающая статья 1918 года «Корреляция между родственниками на основании предположения о менделевском наследовании» (в которой впервые использовался статистический термин « дисперсия» ), его классическая работа 1925 года «Статистические методы для научных работников» и его «Планирование экспериментов» 1935 года . [27] [28] [29] где он разработал строгий дизайн моделей экспериментов . Он создал концепции достаточности , вспомогательной статистики , линейного дискриминатора Фишера и информации Фишера . [30] Он также ввел термин «нулевая гипотеза» во время эксперимента с дегустацией чая «Леди» , который «никогда не доказывается и не устанавливается, но, возможно, опровергается в ходе экспериментов». [31] [32] В своей книге 1930 года «Генетическая теория естественного отбора » он применил статистику к различным биологическим концепциям, таким как принцип Фишера. [33] (который А.Ф. Эдвардс назвал «вероятно, самым знаменитым аргументом в эволюционной биологии ») и побег Фишера , [34] [35] [36] [37] [38] [39] концепция полового отбора об эффекте безудержного действия положительной обратной связи, обнаруженная в эволюции .
Последняя волна, которая в основном заключалась в усовершенствовании и расширении более ранних разработок, возникла в результате совместной работы Эгона Пирсона и Ежи Неймана в 1930-х годах. Они ввели понятия ошибки « типа II », мощности теста и доверительных интервалов . Ежи Нейман в 1934 году показал, что стратифицированная случайная выборка в целом является лучшим методом оценки, чем целенаправленная (квотная) выборка. [40]
Сегодня статистические методы применяются во всех областях, связанных с принятием решений, для получения точных выводов на основе сопоставленного массива данных и для принятия решений в условиях неопределенности на основе статистической методологии. Использование современных компьютеров ускорило крупномасштабные статистические вычисления, а также сделало возможными новые методы, которые непрактично выполнять вручную. Статистика продолжает оставаться областью активных исследований, например, по проблеме анализа больших данных . [41]
Статистические данные [ править ]
Сбор данных [ править ]
Выборка [ править ]
Когда полные данные переписи собрать невозможно, статистики собирают выборочные данные, разрабатывая конкретные планы экспериментов и выборки обследований . Сама статистика также предоставляет инструменты для прогнозирования и прогнозирования с помощью статистических моделей .
Чтобы использовать выборку в качестве ориентира для всей совокупности, важно, чтобы она действительно представляла генеральную совокупность в целом. Репрезентативная выборка гарантирует, что выводы и заключения могут безопасно распространяться от выборки на генеральную совокупность в целом. Основная проблема заключается в определении степени репрезентативности выбранной выборки. Статистика предлагает методы оценки и исправления любых ошибок в процедурах выборки и сбора данных. Существуют также методы планирования эксперимента, которые могут уменьшить эти проблемы в начале исследования, укрепляя его способность узнавать правду о населении.
Теория выборки является частью математической дисциплины теории вероятностей . Вероятность используется в математической статистике для изучения выборочных распределений выборочной статистики и, в более общем плане, свойств статистических процедур . Использование любого статистического метода допустимо, если рассматриваемая система или совокупность удовлетворяют предположениям метода. Разница с точки зрения точки зрения между классической теорией вероятностей и теорией выборки, грубо говоря, заключается в том, что теория вероятностей начинается с заданных параметров всей совокупности, чтобы вывести вероятности, относящиеся к выборкам. Статистический вывод, однако, движется в противоположном направлении — индуктивно выводя из выборок параметры более крупной или всей совокупности.
Экспериментальные и наблюдательные исследования [ править ]
Общая цель проекта статистического исследования – изучить причинно-следственную связь и, в частности, сделать вывод о влиянии изменений значений предикторов или независимых переменных на зависимые переменные . Существует два основных типа причинно-следственных статистических исследований: экспериментальные исследования и наблюдательные исследования . В обоих типах исследований наблюдается влияние различий независимой переменной (или переменных) на поведение зависимой переменной. Разница между этими двумя типами заключается в том, как на самом деле проводится исследование. Каждый из них может быть очень эффективным.Экспериментальное исследование включает в себя проведение измерений исследуемой системы, манипулирование системой, а затем проведение дополнительных измерений на разных уровнях с использованием той же процедуры, чтобы определить, изменило ли манипуляция значения измерений. Напротив, наблюдательное исследование не предполагает экспериментальных манипуляций . Вместо этого собираются данные и исследуются корреляции между предикторами и ответом. Хотя инструменты анализа данных лучше всего работают с данными из рандомизированные исследования , они также применяются к другим видам данных, например, к естественным экспериментам и наблюдательным исследованиям. [42] - для которого статистик будет использовать модифицированный, более структурированный метод оценки (например, разница в оценке различий и инструментальных переменных , среди многих других), который дает непротиворечивые оценки .
Эксперименты [ править ]
Основными этапами статистического эксперимента являются:
- Планирование исследования, включая определение количества повторов исследования, с использованием следующей информации: предварительные оценки размера эффектов лечения , альтернативные гипотезы и предполагаемая экспериментальная вариабельность . Необходимо учитывать выбор субъектов эксперимента и этику исследования. Статистики рекомендуют в экспериментах сравнивать (по крайней мере) одно новое лечение со стандартным лечением или контролем, чтобы обеспечить объективную оценку разницы в эффектах лечения.
- Планирование экспериментов с использованием блокировки для уменьшения влияния мешающих переменных и рандомизированное назначение лечения испытуемым, чтобы обеспечить объективную оценку эффектов лечения и ошибок эксперимента. На этом этапе экспериментаторы и статистики пишут протокол эксперимента , который будет определять проведение эксперимента и определяет первичный анализ экспериментальных данных.
- Проведение эксперимента в соответствии с протоколом эксперимента и анализ данных в соответствии с протоколом эксперимента.
- Дальнейшее изучение набора данных в ходе вторичного анализа, чтобы предложить новые гипотезы для будущих исследований.
- Документирование и представление результатов исследования.
Особую озабоченность вызывают эксперименты над человеческим поведением. В знаменитом исследовании Хоторна изучались изменения в рабочей среде на заводе в Хоторне компании Western Electric . Исследователей интересовало, повысит ли повышенное освещение производительность труда работников сборочной линии . Исследователи сначала измерили продуктивность растения, затем изменили освещение на участке растения и проверили, влияют ли изменения освещения на продуктивность. Оказалось, что производительность действительно улучшилась (в условиях эксперимента). Однако сегодня исследование подвергается резкой критике за ошибки в экспериментальных процедурах, в частности за отсутствие контрольной группы и слепоту . Эффект Хоторна означает обнаружение того, что результат (в данном случае производительность труда) изменился в результате самого наблюдения. Участники исследования в Хоторне стали более продуктивными не потому, что изменилось освещение, а потому, что за ними наблюдали. [43]
исследование Наблюдательное
Примером наблюдательного исследования является исследование, изучающее связь между курением и раком легких. В этом типе исследования обычно используется опрос для сбора наблюдений об интересующей области, а затем выполняется статистический анализ. В этом случае исследователи будут собирать наблюдения как за курильщиками, так и за некурящими, возможно, посредством когортного исследования , а затем искать количество случаев рака легких в каждой группе. [44] Исследование «случай-контроль» — это еще один тип наблюдательного исследования, в котором приглашаются к участию люди с интересующим исходом или без него (например, рак легких) и собираются истории их воздействия.
Типы данных [ править ]
Были предприняты различные попытки создать таксономию уровней измерения . Психофизик Стэнли Смит Стивенс определил номинальную, порядковую, интервальную и пропорциональную шкалы. Номинальные измерения не имеют значимого рангового порядка значений и допускают любое однозначное (инъективное) преобразование. Порядковые измерения имеют неточную разницу между последовательными значениями, но имеют значимый порядок этих значений и допускают любые преобразования, сохраняющие порядок. Интервальные измерения имеют определенные значимые расстояния между измерениями, но нулевое значение является произвольным (как в случае с измерениями долготы и температуры в градусах Цельсия или Фаренгейта ) и допускает любое линейное преобразование. Измерения отношений имеют как значимое нулевое значение, так и определенные расстояния между различными измерениями и допускают любое преобразование масштабирования.
Поскольку переменные, соответствующие только номинальным или порядковым измерениям, не могут быть разумно измерены численно, иногда они группируются как категориальные переменные , тогда как измерения отношений и интервалов группируются вместе как количественные переменные , которые могут быть дискретными или непрерывными из-за их числовой природы. Такие различия часто можно слабо коррелировать с типом данных в информатике, поскольку дихотомические категориальные переменные могут быть представлены с помощью логического типа данных , политомические категориальные переменные с произвольно назначенными целыми числами в целочисленном типе данных и непрерывные переменные с реальным типом данных , включающим арифметика с плавающей запятой . Но сопоставление типов данных информатики с типами статистических данных зависит от того, какая категоризация последних осуществляется.
Были предложены и другие классификации. Например, Мостеллер и Тьюки (1977). [45] различали чины, звания, подсчитываемые дроби, подсчеты, суммы и остатки. Нелдер (1990) [46] описал непрерывный подсчет, непрерывные отношения, отношения подсчета и категориальные режимы данных. (См. также: Крисман (1998), [47] ван ден Берг (1991). [48] )
Вопрос о том, уместно ли применять различные виды статистических методов к данным, полученным в результате различных процедур измерения, осложняется проблемами, касающимися преобразования переменных и точной интерпретации исследовательских вопросов. «Отношения между данными и тем, что они описывают, просто отражают тот факт, что определенные виды статистических утверждений могут иметь значения истинности, которые не являются инвариантными при некоторых преобразованиях. Разумно ли рассматривать преобразование, зависит от вопроса, на который человек пытается ответить. ." [49] : 82
Методы [ править ]
Этот раздел нуждается в дополнительных цитатах для проверки . ( декабрь 2020 г. ) |
Описательная статистика [ править ]
Описательная статистика (в смысле существительного ) — это сводная статистика , которая количественно описывает или суммирует особенности набора информации . [50] в то время как описательная статистика в смысле массового существительного - это процесс использования и анализа этой статистики. Описательная статистика отличается от статистики выводов (или индуктивной статистики) тем, что описательная статистика направлена на обобщение выборки , а не на использование данных для изучения совокупности , которую, как предполагается, представляет выборка данных. [51]
Инференциальная статистика [ править ]
Статистический вывод — это процесс использования анализа данных для определения свойств основного распределения вероятностей . [52] Инференциальный статистический анализ выводит свойства популяции , например, путем проверки гипотез и получения оценок. Предполагается, что наблюдаемый набор данных выбран из более крупной совокупности. Инференциальную статистику можно противопоставить описательной статистике . Описательная статистика занимается исключительно свойствами наблюдаемых данных и не основывается на предположении, что данные поступают из более крупной совокупности. [53]
логической и теория Терминология статистики
Статистика, оценки основные и величины
Рассмотрим независимые одинаково распределенные (IID) случайные величины с заданным распределением вероятностей : стандартная статистического вывода и теория оценки определяет случайную выборку как случайный вектор , заданный вектором -столбцом этих переменных IID. [54] Исследуемая популяция . описывается распределением вероятностей, которое может иметь неизвестные параметры
Статистика — это случайная величина, которая является функцией случайной выборки, а не функцией неизвестных параметров . Однако распределение вероятностей статистики может иметь неизвестные параметры. Рассмотрим теперь функцию неизвестного параметра: оценщик — это статистика, используемая для оценки такой функции. Обычно используемые оценки включают выборочное среднее , несмещенную выборочную дисперсию и выборочную ковариацию .
Случайная величина, которая является функцией случайной выборки и неизвестного параметра, но распределение вероятностей которой не зависит от неизвестного параметра, называется основной величиной или центром. Широко используемые опорные точки включают z-показатель , статистику хи-квадрат Стьюдента и t-значение .
Из двух оценок данного параметра считается, что тот, у которого меньшая среднеквадратическая ошибка, является более эффективным . Кроме того, оценщик называется несмещенным, если его ожидаемое значение равно истинному значению оцениваемого неизвестного параметра, и асимптотически несмещенным, если его ожидаемое значение сходится в пределе к истинному значению такого параметра.
Другие желательные свойства для оценок включают в себя: оценки UMVUE , которые имеют наименьшую дисперсию для всех возможных значений оцениваемого параметра (обычно это свойство легче проверить, чем эффективность) и непротиворечивые оценки, которые сходятся по вероятности к истинному значению такого параметра. .
При этом остается вопрос о том, как получить оценки в данной ситуации и провести расчет, было предложено несколько методов: метод моментов , метод максимального правдоподобия , метод наименьших квадратов и более новый метод оценки уравнений .
и гипотеза альтернативная Нулевая гипотеза
Интерпретация статистической информации часто может включать разработку нулевой гипотезы , которая обычно (но не обязательно) заключается в том, что между переменными не существует взаимосвязи или что с течением времени не произошло никаких изменений. [55] [56]
Лучшей иллюстрацией для новичка является затруднительное положение, с которым сталкивается уголовный процесс. Нулевая гипотеза H 0 утверждает, что подсудимый невиновен, тогда как альтернативная гипотеза H 1 утверждает, что подсудимый виновен. Обвинение предъявлено в связи с подозрением в вине. H 0 (статус-кво) противостоит H 1 и сохраняется, если H 1 не подкреплен доказательствами «вне разумного сомнения». Однако «неопровержение H 0 » в данном случае не означает невиновности, а лишь то, что доказательств было недостаточно для осуждения. Таким образом, жюри не обязательно принимает H 0 , но не может отклонить H 0 . Хотя невозможно «доказать» нулевую гипотезу, можно проверить, насколько она близка к истинности, с помощью степенного теста , который проверяет наличие ошибок второго рода .
То, что статистики называют альтернативной гипотезой , — это просто гипотеза, противоречащая нулевой гипотезе.
Ошибка [ править ]
Если исходить из нулевой гипотезы , можно выделить две широкие категории ошибок:
- Ошибки типа I, при которых нулевая гипотеза ошибочно отвергается, что дает «ложноположительный результат».
- Ошибки типа II , когда нулевую гипотезу не удается отвергнуть и фактическая разница между популяциями упускается, что дает «ложноотрицательный результат».
Стандартное отклонение относится к степени, в которой отдельные наблюдения в выборке отличаются от центрального значения, такого как среднее значение выборки или совокупности, тогда как стандартная ошибка относится к оценке разницы между средним значением выборки и средним значением генеральной совокупности.
Статистическая ошибка — это величина, на которую наблюдение отличается от ожидаемого значения . Остаток — это величина , на которую наблюдение отличается от значения, которое оценщик ожидаемого значения принимает на данной выборке (также называемый прогнозом).
Среднеквадратическая ошибка используется для получения эффективных оценок — широко используемого класса оценок. Среднеквадратическая ошибка — это просто квадратный корень из среднеквадратической ошибки.
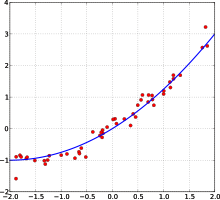
Многие статистические методы стремятся минимизировать остаточную сумму квадратов , и они называются « методами наименьших квадратов » в отличие от метода наименьших абсолютных отклонений . Последний придает равный вес малым и большим ошибкам, тогда как первый придает больший вес большим ошибкам. Остаточная сумма квадратов также дифференцируема , что обеспечивает удобное свойство для выполнения регрессии . Метод наименьших квадратов, применяемый к линейной регрессии, называется наименьших квадратов обычным методом , а метод наименьших квадратов, применяемый к нелинейной регрессии, называется нелинейным методом наименьших квадратов . Также в модели линейной регрессии недетерминированная часть модели называется ошибкой, возмущением или, проще говоря, шумом. И линейная, и нелинейная регрессия рассматриваются в полиномиальном методе наименьших квадратов , который также описывает дисперсию в прогнозе зависимой переменной (ось Y) как функцию независимой переменной (ось X) и отклонений (ошибок, шума, возмущений) по расчетной (подогнанной) кривой.
Процессы измерения, генерирующие статистические данные, также подвержены ошибкам. Многие из этих ошибок классифицируются как случайные (шум) или систематические ( предвзятость ), но другие типы ошибок (например, грубая ошибка, например, когда аналитик сообщает неправильные единицы измерения) также могут иметь важное значение. Наличие недостающих данных или цензуры может привести к необъективным оценкам , и для решения этих проблем были разработаны специальные методы. [57]
Интервальная оценка [ править ]
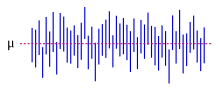
Большинство исследований выбирают только часть населения, поэтому результаты не полностью отражают всю популяцию. Любые оценки, полученные на основе выборки, лишь приблизительно соответствуют величине совокупности. Доверительные интервалы позволяют статистикам выразить, насколько близко оценка выборки соответствует истинному значению для всей совокупности. Часто они выражаются как 95% доверительные интервалы. Формально 95% доверительный интервал для значения — это диапазон, в котором, если бы отбор проб и анализ повторялись в тех же условиях (с получением другого набора данных), интервал включал бы истинное (популяционное) значение в 95% всех возможных случаев. . Это не означает, что вероятность того, что истинное значение находится в доверительном интервале, составляет 95%. С точки зрения частотности такое утверждение даже не имеет смысла, поскольку истинное значение не является случайной величиной . Либо истинное значение находится в пределах заданного интервала, либо выходит за его пределы. Однако верно то, что до того, как будут выбраны какие-либо данные и составлен план построения доверительного интервала, вероятность того, что еще не рассчитанный интервал покроет истинное значение, составляет 95 %: в этот момент границы интервала еще предстоит наблюдать случайные величины . Один из подходов, который действительно дает интервал, который можно интерпретировать как имеющий заданную вероятность содержания истинного значения, заключается в использовании достоверного интервала из байесовской статистики : этот подход зависит от другого способа интерпретации того, что подразумевается под «вероятностью» , то есть как байесовская вероятность .
В принципе доверительные интервалы могут быть симметричными или асимметричными. Интервал может быть асимметричным, поскольку он работает как нижняя или верхняя граница параметра (левосторонний интервал или правосторонний интервал), но он также может быть асимметричным, поскольку двусторонний интервал построен с нарушением симметрии вокруг оценки. Иногда границы доверительного интервала достигаются асимптотически, и они используются для аппроксимации истинных границ.
Значение [ править ]
Статистика редко дает простой ответ типа «да/нет» на анализируемый вопрос. Интерпретация часто сводится к уровню статистической значимости, применяемой к числам, и часто относится к вероятности того, что значение точно отвергнет нулевую гипотезу (иногда называемое p-значением ).

Стандартный подход [54] заключается в проверке нулевой гипотезы против альтернативной гипотезы. Критическая область — это набор значений оценщика, который приводит к опровержению нулевой гипотезы. Таким образом, вероятность ошибки типа I — это вероятность того, что средство оценки принадлежит критической области при условии, что нулевая гипотеза верна ( статистическая значимость ), а вероятность ошибки типа II — это вероятность того, что средство оценки не принадлежит критической области при условии, что альтернативная гипотеза верна. Статистическая мощность теста — это вероятность того, что он правильно отклонит нулевую гипотезу, когда нулевая гипотеза ложна.
Ссылка на статистическую значимость не обязательно означает, что общий результат значим в реальном мире. Например, в крупном исследовании лекарства может быть показано, что лекарство оказывает статистически значимый, но очень небольшой положительный эффект, так что препарат вряд ли сможет заметно помочь пациенту.
Хотя в принципе приемлемый уровень статистической значимости может быть предметом споров, уровень значимости — это наибольшее значение p, которое позволяет тесту отклонить нулевую гипотезу. Этот тест логически эквивалентен утверждению, что значение p — это вероятность (при условии, что нулевая гипотеза верна) наблюдения результата, по крайней мере, столь же экстремального, как статистика теста . Следовательно, чем меньше уровень значимости, тем меньше вероятность совершения ошибки I рода.
С этой структурой обычно связаны некоторые проблемы (см. Критику проверки гипотез ):
- Разница, которая имеет высокую статистическую значимость, все же может не иметь практического значения, но можно правильно сформулировать тесты, чтобы учесть это. Один из ответов предполагает выход за рамки сообщения только об уровне значимости и включение p значения при сообщении о том, отклонена или принята гипотеза. Однако значение p не указывает на размер или важность наблюдаемого эффекта и может также преувеличивать важность незначительных различий в крупных исследованиях. Лучшим и все более распространенным подходом является сообщение о доверительных интервалах . Хотя они производятся на основе тех же расчетов, что и тесты гипотез или значения p , они описывают как размер эффекта, так и окружающую его неопределенность.
- Ошибка транспонированного условного условия, также известная как ошибка прокурора : критика возникает потому, что подход к проверке гипотез заставляет отдавать предпочтение одной гипотезе ( нулевой гипотезе ), поскольку оценивается вероятность наблюдаемого результата при условии нулевой гипотезы, а не вероятность нулевая гипотеза с учетом наблюдаемого результата. Альтернативой этому подходу является байесовский вывод , хотя он требует установления априорной вероятности . [58]
- Отвержение нулевой гипотезы не означает автоматического доказательства альтернативной гипотезы.
- Как и все в индуктивной статистике, он зависит от размера выборки, и поэтому при «толстых хвостах» значения p могут быть серьезно рассчитаны неправильно. [ нужны разъяснения ]
Примеры [ править ]
Некоторые известные статистические тесты и процедуры:
- Дисперсионный анализ (ANOVA)
- Тест хи-квадрат
- Корреляция
- Факторный анализ
- Манн-Уитни Ю
- Среднеквадратичное взвешенное отклонение (MSWD)
- Коэффициент корреляции момента произведения Пирсона
- Регрессионный анализ
- Коэффициент ранговой корреляции Спирмена
- Стьюдента t -тест
- Анализ временных рядов
- Совместный анализ
данных Исследовательский анализ
Исследовательский анализ данных ( EDA ) — это подход к анализу наборов данных для обобщения их основных характеристик, часто с помощью визуальных методов. Статистическая модель может использоваться или нет, но в первую очередь EDA предназначена для того, чтобы увидеть, что данные могут сказать нам помимо формального моделирования или задачи проверки гипотез.
Злоупотребление [ править ]
Неправильное использование статистики может привести к тонким, но серьезным ошибкам в описании и интерпретации — тонким в том смысле, что такие ошибки допускают даже опытные профессионалы, и серьезным в том смысле, что они могут привести к разрушительным ошибкам в принятии решений. Например, социальная политика, медицинская практика и надежность таких сооружений, как мосты, — все это зависит от правильного использования статистики.
Даже если статистические методы применяются правильно, результаты могут быть трудно интерпретировать тем, у кого нет опыта. Статистическая значимость тенденции в данных, которая измеряет степень, в которой тенденция может быть вызвана случайными изменениями в выборке, может совпадать, а может и не совпадать с интуитивным ощущением ее значимости. Набор базовых статистических навыков (и скептицизма), которые необходимы людям для правильного обращения с информацией в повседневной жизни, называется статистической грамотностью .
Существует общее мнение, что статистическими знаниями слишком часто намеренно злоупотребляют , находя способы интерпретации только тех данных, которые выгодны их представителю. [59] Недоверие и непонимание статистики связано с цитатой: « Есть три вида лжи: ложь, наглая ложь и статистика ». Неправильное использование статистики может быть как непреднамеренным, так и преднамеренным, и книга « Как лгать со статистикой » [59] Даррелл Хафф излагает ряд соображений. В попытке пролить свет на использование и неправильное использование статистики проводятся обзоры статистических методов, используемых в конкретных областях (например, Warne, Lazo, Ramos и Ritter (2012)). [60]
Способы избежать неправильного использования статистики включают использование правильных диаграмм и избежание предвзятости . [61] Неправильное использование может произойти, когда выводы слишком обобщены и утверждают, что они репрезентативны для большего, чем они есть на самом деле, часто из-за преднамеренного или неосознанного игнорирования систематической ошибки выборки. [62] Гистограммы, возможно, являются самыми простыми для использования и понимания диаграммами, и их можно создавать вручную или с помощью простых компьютерных программ. [61] Большинство людей не ищут предвзятости или ошибок, поэтому их не замечают. Таким образом, люди часто могут верить, что что-то является правдой, даже если это не очень хорошо представлено . [62] Чтобы данные, собранные на основе статистики, были правдоподобными и точными, взятая выборка должна быть репрезентативной в целом. [63] По словам Хаффа, «надежность образца может быть подорвана [предвзятостью]... позвольте себе некоторую степень скептицизма». [64]
Чтобы помочь в понимании статистики, Хафф предложил ряд вопросов, которые следует задавать в каждом случае: [59]
- Кто так говорит? (Есть ли у него/нее корысть?)
- Откуда он/она знает? (Есть ли у него/нее ресурсы, чтобы знать факты?)
- Чего не хватает? (Дает ли он/она полную картину?)
- Кто-то сменил тему? (Предлагает ли он/она нам правильный ответ на неверную проблему?)
- Имеет ли это смысл? (Логично ли его/ее заключение и соответствует ли оно тому, что мы уже знаем?)
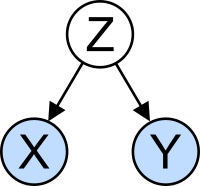
Неправильная интерпретация: корреляция [ править ]
Концепция корреляции особенно примечательна из-за потенциальной путаницы, которую она может вызвать. Статистический анализ набора данных часто показывает, что две переменные (свойства) рассматриваемой совокупности имеют тенденцию изменяться вместе, как если бы они были связаны. Например, исследование годового дохода, в котором также учитывается возраст смерти, может обнаружить, что бедные люди, как правило, живут короче, чем богатые люди. Говорят, что эти две переменные коррелируют; однако они могут быть или не быть причиной друг друга. Явление корреляции может быть вызвано третьим, ранее не рассматривавшимся явлением, называемым скрытой переменной или мешающей переменной . По этой причине невозможно сразу сделать вывод о наличии причинно-следственной связи между двумя переменными.
Приложения [ править ]
, теоретическая статистика и математическая статистика Прикладная статистика
Прикладная статистика, иногда называемая статистической наукой, [65] включает в себя описательную статистику и применение логической статистики. [66] [67] Теоретическая статистика касается логических аргументов, лежащих в основе обоснования подходов к статистическим выводам , а также охватывает математическую статистику . Математическая статистика включает в себя не только манипуляции с распределениями вероятностей, необходимые для получения результатов, связанных с методами оценки и вывода, но также различные аспекты вычислительной статистики и планирования экспериментов .
Статистические консультанты могут помочь организациям и компаниям, у которых нет собственного опыта по их конкретным вопросам.
Машинное обучение и интеллектуальный анализ данных
Модели машинного обучения — это статистические и вероятностные модели, которые фиксируют закономерности в данных с помощью вычислительных алгоритмов.
в академических кругах Статистика
Статистика применима к широкому кругу академических дисциплин , включая естественные и социальные науки , управление и бизнес. Статистика бизнеса применяет статистические методы в эконометрике , аудите , производстве и операциях, включая улучшение услуг и маркетинговые исследования. [68] Исследование двух журналов по тропической биологии показало, что 12 наиболее частыми статистическими тестами являются: дисперсионный анализ (ANOVA), критерий хи-квадрат , t-критерий Стьюдента , линейная регрессия , коэффициент корреляции Пирсона , U-критерий Манна-Уитни , Краскал- Критерий Уоллиса , индекс разнообразия Шеннона , критерий диапазона Тьюки , кластерный анализ , коэффициент ранговой корреляции Спирмена и анализ главных компонент . [69]
Типичный курс статистики охватывает описательную статистику, вероятность, биномиальное и нормальное распределения , проверку гипотез и доверительных интервалов, линейную регрессию и корреляцию. [70] Современные фундаментальные статистические курсы для студентов бакалавриата ориентированы на правильный выбор тестов, интерпретацию результатов и использование бесплатного программного обеспечения для статистики . [69]
Статистические вычисления [ править ]
Быстрый и устойчивый рост вычислительной мощности, начавшийся со второй половины 20-го века, оказал существенное влияние на практику статистической науки. Ранние статистические модели почти всегда относились к классу линейных моделей , но мощные компьютеры в сочетании с подходящими численными алгоритмами вызвали повышенный интерес к нелинейным моделям (таким как нейронные сети ), а также создание новых типов, таких как обобщенные линейные модели. и многоуровневые модели .
Увеличение вычислительной мощности также привело к растущей популярности вычислительно интенсивных методов, основанных на повторной выборке , таких как тесты перестановки и бутстрап , в то время как такие методы, как выборка Гиббса, сделали использование байесовских моделей более осуществимым. Компьютерная революция имеет последствия для будущего статистики с новым акцентом на «экспериментальную» и «эмпирическую» статистику. большое количество статистического программного обеспечения В настоящее время доступно включают такие программы, как Mathematica , SAS , SPSS и R. как общего, так и специального назначения. Примеры доступного программного обеспечения, способного выполнять сложные статистические вычисления ,
Бизнес-статистика [ править ]
В бизнесе «статистика» является широко используемым инструментом управления и поддержки принятия решений . Он особенно применяется в финансовом менеджменте , маркетинговом менеджменте , а также в управлении производством , услугами и операциями . [71] [72] Статистика также широко используется в управленческом учете и аудите . Дисциплина « Наука управления» формализует использование статистики и другой математики в бизнесе. ( Эконометрика – это применение статистических методов к экономическим данным с целью придания эмпирического содержания экономическим отношениям .)
Типичный курс «Бизнес-статистика» предназначен для специалистов по бизнесу и охватывает [73] описательная статистика ( сбор , описание, анализ и обобщение данных), вероятность (обычно биномиальное и нормальное распределения ), проверка гипотез и доверительных интервалов, линейная регрессия и корреляция; (Последующие) курсы могут включать прогнозирование , временные ряды , деревья решений , множественную линейную регрессию и другие темы из бизнес-аналитики в целом. См. также Бизнес-математика § Университетский уровень . Программы профессиональной сертификации , такие как CFA , часто включают темы из статистики.
искусству применительно к математике или Статистика
Традиционно статистика занималась выводами с использованием полустандартизированной методологии, которая «требовала изучения» в большинстве наук. Эта традиция изменилась с использованием статистики в контекстах, не связанных с выводами. То, что когда-то считалось сухим предметом, воспринимаемым во многих областях как требование для получения ученой степени, теперь рассматривается с энтузиазмом. [ по мнению кого? ] Первоначально высмеиваемая некоторыми математическими пуристами, теперь она считается важной методологией в определенных областях.
- В теории чисел диаграммы рассеяния данных, генерируемые функцией распределения, могут быть преобразованы с помощью знакомых инструментов, используемых в статистике, для выявления основных закономерностей, которые затем могут привести к гипотезам.
- Предиктивные методы статистики в прогнозировании, сочетающие теорию хаоса и фрактальную геометрию, могут быть использованы для создания видеоработ. [74]
- Процессуальное искусство Джексона Поллока основывалось на художественных экспериментах, посредством которых художественно раскрывались основные закономерности в природе. [75] С появлением компьютеров статистические методы стали применяться для формализации таких естественных процессов, основанных на распространении, для создания и анализа движущегося видеоарта. [ нужна ссылка ]
- Методы статистики могут использоваться предикативно в перформансе , например, в карточном фокусе, основанном на марковском процессе , который работает только в некоторых случаях, случай которого можно предсказать с помощью статистической методологии.
- Статистику можно использовать для предикативного создания искусства, как в статистической или стохастической музыке, изобретенной Яннисом Ксенакисом , где музыка зависит от исполнения. Хотя этот тип артистизма не всегда проявляется так, как ожидалось, его поведение предсказуемо и настраивается с помощью статистики.
Специализированные дисциплины [ править ]
Статистические методы используются в широком спектре видов научных и социальных исследований, включая: биостатистику , вычислительную биологию , вычислительную социологию , сетевую биологию , социальные науки , социологию и социальные исследования . В некоторых областях исследований прикладная статистика используется настолько широко, что для них используется специализированная терминология . К этим дисциплинам относятся:
- Актуарная наука (оценивает риски в страховой и финансовой отраслях)
- Прикладная информационная экономика
- Астростатистика (статистическая оценка астрономических данных)
- Биостатистика
- Хемометрика (для анализа данных по химии )
- Интеллектуальный анализ данных (применение статистики и распознавания образов для извлечения знаний из данных)
- Наука о данных ( )
- Демография (статистическое изучение населения)
- Эконометрика (статистический анализ экономических данных)
- Энергетическая статистика
- Инженерная статистика
- Эпидемиология (статистический анализ заболеваний)
- География и географические информационные системы , особенно в области пространственного анализа.
- Обработка изображений
- Юриметрика ( право )
- Медицинская статистика
- Политология
- Психологическая статистика
- Инженерия надежности
- Социальная статистика
- Статистическая механика
Кроме того, существуют отдельные виды статистического анализа, для которых также разработана собственная специализированная терминология и методология:
- Бутстрап / складной нож передискретизация
- Многомерная статистика
- Статистическая классификация
- Структурированный анализ данных
- Моделирование структурными уравнениями
- Методика опроса
- Анализ выживания
- Статистика в различных видах спорта, особенно в бейсболе (известном как саберметрика ) и крикете.
Статистика также является ключевым базовым инструментом в бизнесе и производстве. Он используется для понимания изменчивости систем измерения, процессов управления (например, в статистическом управлении процессами или SPC), для обобщения данных и принятия решений на основе данных. В этих ролях это ключевой инструмент и, возможно, единственный надежный инструмент. [ нужна ссылка ]
См. также [ править ]
- Оценка численности
- Глоссарий вероятности и статистики
- Список академических статистических ассоциаций
- Список важных публикаций по статистике
- Список национальных и международных статистических служб
- Список статистических пакетов (программного обеспечения)
- Список статей по статистике
- Список университетских статистических консультационных центров
- Обозначения вероятности и статистики
- Статистическое образование
- Всемирный день статистики
- Основы и основные области статистики
- Философия статистики
- Вероятностные интерпретации
- Основы статистики
- Список статистиков
- Официальная статистика
- Многомерный дисперсионный анализ
Ссылки [ править ]
- ^ «статистика» . Оксфордский словарь английского языка (онлайн-изд.). Издательство Оксфордского университета . (Требуется подписка или членство участвующей организации .)
- ^ « Статистика » в Цифровом словаре немецкого языка.
- ^ "Статистика". Оксфордский справочник . Издательство Оксфордского университета. Январь 2008 г. ISBN . 978-0-19-954145-4 . Архивировано из оригинала 03 сентября 2020 г. Проверено 14 августа 2019 г.
- ^ Ромейн, Ян-Виллем (2014). «Философия статистики» . Стэнфордская энциклопедия философии . Архивировано из оригинала 19 октября 2021 г. Проверено 3 ноября 2016 г.
- ^ «Кембриджский словарь» . Архивировано из оригинала 22 ноября 2020 г. Проверено 14 августа 2019 г.
- ^ Додж, Ю. (2006) Оксфордский словарь статистических терминов , Oxford University Press. ISBN 0-19-920613-9
- ^ Jump up to: а б Lund Research Ltd. «Описательная и инференциальная статистика» . Статистика.laerd.com. Архивировано из оригинала 26 октября 2020 г. Проверено 23 марта 2014 г.
- ^ Моисей, Линкольн Э. (1986) Думайте и объясняйте с помощью статистики , Аддисон-Уэсли, ISBN 978-0-201-15619-5 . стр. 1–3
- ^ Хейс, Уильям Ли, (1973) Статистика для социальных наук , Холт, Райнхарт и Уинстон, стр. хii, ISBN 978-0-03-077945-9
- ^ Мур, Дэвид (1992). «Преподавание статистики как уважаемый предмет» . У Ф. Гордона; С. Гордон (ред.). Статистика XXI века . Вашингтон, округ Колумбия: Математическая ассоциация Америки. стр. 14–25 . ISBN 978-0-88385-078-7 .
- ^ Шанс, Бет Л .; Россман, Аллан Дж. (2005). «Предисловие» (PDF) . Исследование статистических концепций, приложений и методов . Даксбери Пресс. ISBN 978-0-495-05064-3 . Архивировано (PDF) из оригинала 22 ноября 2020 г. Проверено 6 декабря 2009 г.
- ^ Лакшмикантам, Д.; Каннан, В. (2002). Справочник по стохастическому анализу и его приложениям . Нью-Йорк: М. Деккер. ISBN 0824706609 .
- ^ Шервиш, Марк Дж. (1995). Теория статистики (Иср. 2-е изд.). Нью-Йорк: Спрингер. ISBN 0387945466 .
- ^ Jump up to: а б Бромелинг, Лайл Д. (1 ноября 2011 г.). «Отчет о ранних статистических выводах в арабской криптологии». Американский статистик . 65 (4): 255–257. дои : 10.1198/tas.2011.10191 . S2CID 123537702 .
- ^ Остасевич, Валенти (2014). «Зарождение статистической науки» . Силезский статистический обзор . 12 (18): 76–77. дои : 10.15611/sps.2014.12.04 .
- ^ Брюно, Квентин (2022). Государства и хозяева капитала: суверенное кредитование, старое и новое . Издательство Колумбийского университета . ISBN 978-0231555647 .
- ^ Уиллкокс, Уолтер (1938) «Основатель статистики». Обзор Международного статистического института 5 (4): 321–328. JSTOR 1400906
- ^ Дж. Франклин, Наука догадок: доказательства и вероятности до Паскаля, Университет Джонса Хопкинса, Pr, 2002 г.
- ^ Шнайдер, И. (2005). Якоб Бернулли, Ars Conjectandi (1713). В книге И. Граттан-Гиннесс (ред.), «Важные произведения в западной математике, 1640–1940» (стр. 88–103).
- ^ Силла, Эд; Бернулли, Джейкоб (2006). Искусство строить предположения вместе с письмом другу о сетах в теннисе на корте (пер.) . Джу Пресс. ISBN 978-0-8018-8235-7 .
- ^ Лим, М. (2021). «Гаусс, метод наименьших квадратов и недостающая планета» . Актуарии Цифровые . Проверено 1 ноября 2022 г.
- ^ Хелен Мэри Уокер (1975). Исследования по истории статистического метода . Арно Пресс. ISBN 978-0405066283 . Архивировано из оригинала 27 июля 2020 г. Проверено 27 июня 2015 г.
- ^ Гальтон, Ф. (1877). «Типичные законы наследственности» . Природа . 15 (388): 492–553. Бибкод : 1877Природа..15..492. . дои : 10.1038/015492a0 .
- ^ Стиглер, С.М. (1989). «Отчет Фрэнсиса Гальтона об изобретении корреляции» . Статистическая наука . 4 (2): 73–79. дои : 10.1214/ss/1177012580 .
- ^ Пирсон, К. (1900). «О критерии, что данная система отклонений от вероятного в случае коррелированной системы переменных такова, что можно разумно предположить, что она возникла в результате случайной выборки» . Философский журнал . Серия 5. 50 (302): 157–175. дои : 10.1080/14786440009463897 . Архивировано из оригинала 18 августа 2020 г. Проверено 27 июня 2019 г.
- ^ «Карл Пирсон (1857–1936)» . Департамент статистических наук – Университетский колледж Лондона . Архивировано из оригинала 25 сентября 2008 г.
- ^ Бокс, Дж. Ф. (февраль 1980 г.). «Р. А. Фишер и план экспериментов, 1922–1926». Американский статистик . 34 (1): 1–7. дои : 10.2307/2682986 . JSTOR 2682986 .
- ^ Йейтс, Ф. (июнь 1964 г.). «Сэр Рональд Фишер и планирование экспериментов». Биометрия . 20 (2): 307–321. дои : 10.2307/2528399 . JSTOR 2528399 .
- ^ Стэнли, Джулиан К. (1966). «Влияние «Плана экспериментов» Фишера на исследования в области образования тридцать лет спустя». Американский журнал исследований в области образования . 3 (3): 223–229. дои : 10.3102/00028312003003223 . JSTOR 1161806 . S2CID 145725524 .
- ^ Агрести, Алан; Дэвид Б. Хичкок (2005). «Байесовский вывод для категориального анализа данных» (PDF) . Статистические методы и приложения . 14 (3): 298. doi : 10.1007/s10260-005-0121-y . S2CID 18896230 . Архивировано (PDF) из оригинала 19 декабря 2013 г. Проверено 19 декабря 2013 г.
- ^ Цитата OED: 1935 Р. А. Фишер, План экспериментов ii. 19: «Мы можем говорить об этой гипотезе как о «нулевой гипотезе», причем нулевая гипотеза никогда не доказывается и не устанавливается, но, возможно, опровергается в ходе экспериментов».
- ^ Фишер|1971|loc=Глава II. Принципы экспериментирования, иллюстрированные психофизическим экспериментом, раздел 8. Нулевая гипотеза
- ^ Эдвардс, AWF (1998). «Естественный отбор и соотношение полов: источники Фишера». Американский натуралист . 151 (6): 564–569. дои : 10.1086/286141 . ПМИД 18811377 . S2CID 40540426 .
- ^ Фишер, Р.А. (1915) Эволюция сексуальных предпочтений. Евгеническое обозрение (7) 184:192
- ^ Фишер, Р.А. (1930) Генетическая теория естественного отбора . ISBN 0-19-850440-3
- ^ Эдвардс, AWF (2000) Перспективы: анекдотические, исторические и критические комментарии по генетике. Генетическое общество Америки (154) 1419:1426
- ^ Андерссон, Мальте (1994). Половой отбор . Издательство Принстонского университета. ISBN 0-691-00057-3 . Архивировано из оригинала 25 декабря 2019 г. Проверено 19 сентября 2019 г.
- ^ Андерссон, М. и Симмонс, Л.В. (2006) Половой отбор и выбор партнера. Тенденции, экология и эволюция (21) 296:302
- ^ Гайон, Дж. (2010) Половой отбор: еще один дарвиновский процесс. Comptes Rendus Biologies (333) 134:144
- ^ Нейман, Дж (1934). «О двух различных аспектах репрезентативного метода: методе стратифицированной выборки и методе целенаправленного отбора». Журнал Королевского статистического общества . 97 (4): 557–625. дои : 10.2307/2342192 . JSTOR 2342192 .
- ^ «Наука в сложном мире – большие данные: возможность или угроза?» . Институт Санта-Фе . 2 декабря 2013 г. Архивировано из оригинала 30 мая 2016 г. Проверено 13 октября 2014 г.
- ^ Фридман, Д.А. (2005) Статистические модели: теория и практика , Cambridge University Press. ISBN 978-0-521-67105-7
- ^ Маккарни Р., Уорнер Дж., Илифф С., ван Хаселен Р., Гриффин М., Фишер П. (2007). «Эффект Хоторна: рандомизированное контролируемое исследование» . Методология BMC Med Res . 7 (1): 30. дои : 10.1186/1471-2288-7-30 . ЧВК 1936999 . ПМИД 17608932 .
- ^ Ротман, Кеннет Дж; Гренландия, Сандер; Лэш, Тимоти, ред. (2008). «7». Современная эпидемиология (3-е изд.). Липпинкотт Уильямс и Уилкинс. п. 100 . ISBN 978-0781755641 .
- ^ Мостеллер, Ф .; Тьюки, JW (1977). Анализ данных и регрессия . Бостон: Аддисон-Уэсли.
- ^ Нелдер, Дж. А. (1990). Знания, необходимые для компьютеризации анализа и интерпретации статистической информации. Экспертные системы и искусственный интеллект: потребность в информации о данных . Отчет Библиотечной ассоциации, Лондон, 23–27 марта.
- ^ Крисман, Николас Р. (1998). «Переосмысление уровней измерения для картографии». Картография и географическая информатика . 25 (4): 231–242. Бибкод : 1998CGISy..25..231C . дои : 10.1559/152304098782383043 .
- ^ ван ден Берг, Г. (1991). Выбор метода анализа . Лейден: DSWO Press
- ^ Хэнд, диджей (2004). Теория и практика измерения: мир через количественную оценку. Лондон: Арнольд.
- ^ Манн, Прем С. (1995). Вводная статистика (2-е изд.). Уайли. ISBN 0-471-31009-3 .
- ^ «Описательная статистика | Исследовательские связи» . www.researchconnections.org . Проверено 10 января 2023 г.
- ^ Аптон, Г., Кук, И. (2008) Оксфордский статистический словарь , OUP. ISBN 978-0-19-954145-4 .
- ^ «Основная статистика вывода — Purdue OWL® — Университет Пердью» . owl.purdue.edu . Проверено 10 января 2023 г.
- ^ Jump up to: а б Пьяцца Элио, Вероятность и статистика, Esculapius, 2007 г.
- ^ Эверитт, Брайан (1998). Кембриджский статистический словарь . Кембридж, Великобритания, Нью-Йорк: Издательство Кембриджского университета. ISBN 0521593468 .
- ^ «Коэн (1994) Земля круглая (p < 0,05)» . YourStatsGuru.com. Архивировано из оригинала 5 сентября 2015 г. Проверено 20 июля 2015 г.
- ^ Рубин, Дональд Б.; Литтл, Родерик Дж.А., Статистический анализ с отсутствующими данными, Нью-Йорк: Wiley, 2002.
- ^ Иоаннидис, JPA (2005). «Почему большинство опубликованных результатов исследований являются ложными» . ПЛОС Медицина . 2 (8): е124. doi : 10.1371/journal.pmed.0020124 . ПМЦ 1182327 . ПМИД 16060722 .
- ^ Jump up to: а б с Хафф, Даррелл (1954) Как лгать со статистикой , WW Norton & Company, Inc., Нью-Йорк. ISBN 0-393-31072-8
- ^ Варн, Р. Лазо; Рамос, Т.; Риттер, Н. (2012). «Статистические методы, используемые в журналах по образованию одаренных людей, 2006–2010 гг.». Одаренный ребенок Ежеквартально . 56 (3): 134–149. дои : 10.1177/0016986212444122 . S2CID 144168910 .
- ^ Jump up to: а б Дреннан, Роберт Д. (2008). «Статистика в археологии». В Пирсолле, Дебора М. (ред.). Энциклопедия археологии . Elsevier Inc., стр. 2093–2100 . ISBN 978-0-12-373962-9 .
- ^ Jump up to: а б Коэн, Джером Б. (декабрь 1938 г.). «Неправильное использование статистики». Журнал Американской статистической ассоциации . 33 (204). JSTOR: 657–674. дои : 10.1080/01621459.1938.10502344 .
- ^ Фройнд, Дж. Э. (1988). «Современная элементарная статистика». Справочник по Кредо .
- ^ Хафф, Даррелл; Ирвинг Гейс (1954). Как лгать со статистикой . Нью-Йорк: Нортон.
Надежность образца может быть подорвана [предвзятостью]… позвольте себе некоторую долю скептицизма.
- ^ Нелдер, Джон А. (1999). «От статистики к статистической науке» . Журнал Королевского статистического общества. Серия D (Статист) . 48 (2): 257–269. дои : 10.1111/1467-9884.00187 . ISSN 0039-0526 . JSTOR 2681191 . Архивировано из оригинала 15 января 2022 г. Проверено 15 января 2022 г.
- ^ Nikoletseas, MM (2014) «Статистика: концепции и примеры». ISBN 978-1500815684
- ^ Андерсон, доктор медицинских наук; Суини, диджей; Уильямс, Т.А. (1994) Введение в статистику: концепции и приложения , стр. 5–9. Западная группа. ISBN 978-0-314-03309-3
- ^ «Журнал деловой и экономической статистики» . Журнал деловой и экономической статистики . Тейлор и Фрэнсис. Архивировано из оригинала 27 июля 2020 года . Проверено 16 марта 2020 г.
- ^ Jump up to: а б Наталья Лоаиса Веласкес, Мария Исабель Гонсалес Лутц и Хулиан Монге-Нахера (2011). «Какую статистику следует изучить тропическим биологам?» (PDF) . Журнал тропической биологии . 59 : 983–992. Архивировано (PDF) из оригинала 19 октября 2020 г. Проверено 26 апреля 2020 г.
- ^ Пекоз, Эрол (2009). Руководство менеджера по статистике . Эррол Пекоз. ISBN 978-0979570438 .
- ^ «Цели и возможности» . Журнал деловой и экономической статистики . Тейлор и Фрэнсис. Архивировано из оригинала 23 июня 2021 года . Проверено 16 марта 2020 г.
- ^ «Журнал деловой и экономической статистики» . Журнал деловой и экономической статистики . Тейлор и Фрэнсис. Архивировано из оригинала 27 июля 2020 года . Проверено 16 марта 2020 г.
- ^ Доступно множество текстов, отражающих масштабы и охват этой дисциплины в деловом мире:
- Шарп, Н. (2014). Бизнес-статистика , Пирсон. ISBN 978-0134705217
- Вегнер, Т. (2010). Прикладная бизнес-статистика: методы и приложения на основе Excel, Juta Academic. ISBN 0702172863
- Холмс Л., Илловски Б., Дин С. (2017). Вводная бизнес-статистика, заархивированная 16 июня 2021 г. на Wayback Machine.
- Ника, М. (2013). Принципы бизнес-статистики. Архивировано 18 мая 2021 г. на Wayback Machine.
- ^ Клайн, Грейсен (2019). Непараметрические статистические методы, использующие R. ЭДТЕХ. ISBN 978-1-83947-325-8 . OCLC 1132348139 . Архивировано из оригинала 15 мая 2022 г. Проверено 16 сентября 2021 г.
- ^ Паласиос, Бернардо; Росарио, Альфонсо; Вильгельмус, Моника М.; Зетина, Сандра; Зенит, Роберто (30 октября 2019 г.). «Поллок избегал гидродинамических нестабильностей при рисовании с помощью своей техники капания» . ПЛОС ОДИН . 14 (10): e0223706. Бибкод : 2019PLoSO..1423706P . дои : 10.1371/journal.pone.0223706 . ISSN 1932-6203 . ПМК 6821064 . ПМИД 31665191 .
Дальнейшее чтение [ править ]
- Лидия Денворт, «Значительная проблема: стандартные научные методы подвергаются критике. Изменится ли что-нибудь?», Scientific American , vol. 321, нет. 4 (октябрь 2019 г.), стр. 62–67. «Использование p значений в течение почти столетия [с 1925 года] для определения статистической значимости экспериментальных ... результатов способствовало возникновению иллюзии уверенности и [к] кризисам воспроизводимости во многих научных областях . Растет решимость реформировать статистический анализ Некоторые [исследователи] предлагают изменить статистические методы, тогда как другие готовы отказаться от порога для определения «значимых» результатов». (стр. 63.)
- Барбара Илловски; Сьюзан Дин (2014). Вводная статистика . OpenStax CNX. ISBN 978-1938168208 .
- Стокбургер, Дэвид В. «Вводная статистика: концепции, модели и приложения» . Государственный университет Миссури (3-е веб-изд.). Архивировано из оригинала 28 мая 2020 года.
- Статистика OpenIntro, заархивированная 16 июня 2019 г. на Wayback Machine , 3-е издание, авторы: Диез, Барр и Четинкая-Рундель.
- Стивен Джонс, 2010. Статистика в психологии: объяснения без уравнений . Пэлгрейв Макмиллан. ISBN 978-1137282392 .
- Коэн, Дж (1990). «Что я узнал (на данный момент)» (PDF) . Американский психолог . 45 (12): 1304–1312. дои : 10.1037/0003-066x.45.12.1304 . S2CID 7180431 . Архивировано из оригинала (PDF) 18 октября 2017 г.
- Гигеренцер, Г. (2004). «Бессмысленная статистика». Журнал социально-экономики . 33 (5): 587–606. doi : 10.1016/j.socec.2004.09.033 .
- Иоаннидис, JPA (2005). «Почему большинство опубликованных результатов исследований являются ложными» . ПЛОС Медицина . 2 (4): 696–701. doi : 10.1371/journal.pmed.0040168 . ПМК 1855693 . ПМИД 17456002 .
Внешние ссылки [ править ]
- (Электронная версия): TIBCO Software Inc. (2020). Учебник по науке о данных .
- Онлайн-статистическое образование: интерактивный мультимедийный курс обучения . Разработано Университетом Райса (ведущим разработчиком), Университетом Хьюстона Клир-Лейк, Университетом Тафтса и Национальным научным фондом.
- Ресурсы статистических вычислений Калифорнийского университета в Лос-Анджелесе (архивировано 17 июля 2006 г.)
- Философия статистики из Стэнфордской энциклопедии философии.
Основные математики области |
|---|