Моделирование структурными уравнениями

Моделирование структурными уравнениями ( SEM ) — это разнообразный набор методов, используемых учеными, проводящими как наблюдательные, так и экспериментальные исследования. SEM используется в основном в социальных и поведенческих науках, но также в эпидемиологии. [2] бизнес, [3] и другие поля. Дать определение SEM сложно без обращения к техническому языку, но хорошей отправной точкой является само название.
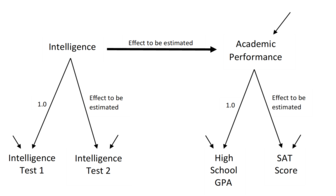
SEM включает в себя модель, показывающую, как различные аспекты некоторого явления , как полагают, причинно связаны друг с другом. Модели структурных уравнений часто содержат постулируемые причинно-следственные связи между некоторыми скрытыми переменными (переменными, которые, как считается, существуют, но которые невозможно наблюдать напрямую). Дополнительные причинно-следственные связи связывают эти скрытые переменные с наблюдаемыми переменными, значения которых появляются в наборе данных. Причинно-следственные связи представлены с помощью уравнений , но постулируемая структуризация также может быть представлена с помощью диаграмм, содержащих стрелки, как на рисунках 1 и 2. Причинно-следственные структуры подразумевают, что среди значений наблюдаемых переменных должны проявляться определенные закономерности. Это позволяет использовать связи между значениями наблюдаемых переменных для оценки величин постулируемых эффектов и проверки соответствия наблюдаемых данных требованиям предполагаемых причинных структур. [4]
Граница между тем, что является и не является моделью структурных уравнений, не всегда ясна, но модели SE часто содержат постулируемые причинно-следственные связи между набором скрытых переменных (переменных, которые, как считается, существуют, но которые нельзя наблюдать напрямую, например отношение, интеллект или поведение). психическое заболевание) и причинные связи, связывающие постулируемые латентные переменные с переменными, которые можно наблюдать и значения которых доступны в некотором наборе данных. Вариации среди стилей скрытых причинных связей, вариации среди наблюдаемых переменных, измеряющих скрытые переменные, и вариации в стратегиях статистической оценки приводят к появлению набора инструментов SEM, включающего подтверждающий факторный анализ , подтверждающий композитный анализ , траекторный анализ , многогрупповое моделирование, продольное моделирование. , частичное моделирование пути наименьших квадратов , моделирование скрытого роста и иерархическое или многоуровневое моделирование. [5] [6] [7] [8] [9]
Исследователи SEM используют компьютерные программы для оценки силы и знака коэффициентов, соответствующих моделируемым структурным связям, например чисел, связанных со стрелками на рисунке 1. Поскольку постулируемая модель, подобная рис. 1, может не соответствовать мирским силам, контролирующим измерения наблюдаемых данных, программы также предоставляют модельные тесты и диагностические подсказки, указывающие, какие индикаторы или какие компоненты модели могут привести к несоответствию между моделью и наблюдаемыми данными. Критика методов SEM намекает на: игнорирование доступных тестов модели, проблемы в спецификации модели, тенденцию принимать модели без учета внешней достоверности и потенциальные философские предубеждения. [10]
Большим преимуществом SEM является то, что все эти измерения и тесты происходят одновременно в одной процедуре статистической оценки, где все коэффициенты модели рассчитываются с использованием всей информации из наблюдаемых переменных. Это означает, что оценки будут более точными, чем если бы исследователь рассчитывал каждую часть модели отдельно. [11]
История [ править ]
Моделирование структурными уравнениями (SEM) начало отличаться от корреляции и регрессии, когда Сьюэлл Райт предоставил явные причинно-следственные интерпретации для набора уравнений в стиле регрессии, основанные на четком понимании физических и физиологических механизмов, вызывающих прямые и косвенные эффекты среди наблюдаемых им переменных. [12] [13] [14] Уравнения оценивались как обычные уравнения регрессии, но существенный контекст измеряемых переменных позволял получить четкое причинно-следственное, а не просто прогнозирующее понимание. О. Д. Дункан представил SEM в социальных науках в своей книге 1975 года. [15] и SEM расцвели в конце 1970-х и 1980-х годах, когда увеличение вычислительной мощности позволило проводить практические оценки моделей. В 1987 году Гайдук [6] представил первое введение в моделирование структурными уравнениями со скрытыми переменными объемом в целую книгу, за которым вскоре последовал популярный текст Боллена (1989). [16]
Различные, но математически связанные подходы к моделированию разработаны в психологии, социологии и экономике. Ранняя Комиссии Коулза работа над оценкой одновременных уравнений была сосредоточена на алгоритмах Купмана и Худа (1953) из экономики транспорта и оптимальной маршрутизации с оценкой максимального правдоподобия и алгебраическими вычислениями в закрытой форме, поскольку итеративные методы поиска решений были ограничены во времена, когда еще не было компьютеров. Слияние двух из этих потоков развития (факторный анализ из психологии и анализ пути из социологии через Дункана) сформировало нынешнее ядро SEM. Одна из нескольких программ, разработанных Карлом Йорескугом в Службе образовательного тестирования, LISREL. [17] [18] [19] встроенные скрытые переменные (которые психологи называли скрытыми факторами факторного анализа) в уравнениях в стиле путевого анализа (которые социологи унаследовали от Райта и Дункана). Факторно-структурированная часть модели включала ошибки измерений, которые позволяли корректировать ошибки измерения, хотя и не обязательно безошибочно, оценивать эффекты, связывающие различные постулируемые латентные переменные.
Следы исторической конвергенции традиций факторного анализа и траекторного анализа сохраняются в виде различия между измерительной и структурной частями моделей; а также продолжающиеся разногласия по поводу тестирования моделей и того, должны ли измерения предшествовать структурным оценкам или сопровождать их. [20] [21] Рассматривая факторный анализ как метод сокращения данных, мы преуменьшаем значение тестирования, что контрастирует с подходом анализа пути к тестированию постулируемых причинно-следственных связей, когда результат теста может сигнализировать о неправильной спецификации модели. В литературе продолжают проявляться разногласия между традициями факторного анализа и траекторного анализа.
Анализ пути Райта оказал влияние на Германа Уолда, ученика Уолда Карла Йорескуга и ученика Йорескога Класа Форнелла, но SEM так и не завоевал большого внимания среди американских специалистов по эконометрике, возможно, из-за фундаментальных различий в целях моделирования и типичных структурах данных. Длительное разделение экономической отрасли СЭМ привело к процедурным и терминологическим различиям, хотя глубокие математические и статистические связи сохраняются. [22] [23] Экономическую версию SEM можно увидеть в дискуссиях SEMNET об эндогенности и в накале, вызванной тем, что подход Джуди Перла к причинно-следственной связи с помощью направленных ациклических графов (DAG) сталкивается с экономическими подходами к моделированию. [4] Доступны обсуждения, сравнивающие и противопоставляющие различные подходы SEM. [24] [25] но дисциплинарные различия в структурах данных и проблемы, мотивирующие экономические модели, делают воссоединение маловероятным. Жемчуг [4] расширил SEM от линейных до непараметрических моделей и предложил причинно-следственную и контрфактическую интерпретации уравнений. Непараметрические SEM позволяют оценивать общие, прямые и косвенные эффекты без каких-либо обязательств по линейности эффектов или предположений о распределении ошибок. [25]
SEM-анализ популярен в социальных науках, поскольку компьютерные программы позволяют оценивать сложные причинные структуры, но сложность моделей приводит к существенной вариативности качества результатов. Некоторые, но не все, результаты получены без «неудобств» понимания плана эксперимента, статистического контроля, последствий размера выборки и других особенностей, способствующих хорошему планированию исследования. [ нужна ссылка ]
Общие шаги и соображения [ править ]
Следующие соображения применимы к построению и оценке многих моделей структурных уравнений.
Спецификация модели [ править ]
Построение или определение модели требует внимания к:
- набор переменных, которые будут использоваться,
- что известно о переменных,
- что предполагается или выдвигается гипотеза о причинных связях и разъединениях переменных,
- что исследователь хочет узнать из моделирования,
- и случаи, для которых значения переменных будут доступны (дети? рабочие? компании? страны? клетки? несчастные случаи? культы?).
Модели структурных уравнений пытаются отразить мировые силы, действующие в причинно однородных случаях, а именно в случаях, запутавшихся в одних и тех же мирских причинных структурах, но чьи значения причин различаются и, следовательно, имеют разные значения исходящих переменных. Причинной однородности можно способствовать путем отбора случаев или разделения случаев в модели с несколькими группами. Спецификация модели не является полной, пока исследователь не укажет:
- какие эффекты и/или корреляции/ковариации необходимо включить и оценить,
- какие эффекты и другие коэффициенты запрещены или считаются ненужными,
- и каким коэффициентам будут присвоены фиксированные/неизменяющиеся значения (например, для обеспечения шкалы измерения скрытых переменных, как показано на рисунке 2).
Скрытый уровень модели состоит из эндогенных и экзогенных переменных . Эндогенные латентные переменные — это переменные с истинной оценкой, постулируемые как получающие эффекты по крайней мере от одной другой смоделированной переменной. Каждая эндогенная переменная моделируется как зависимая переменная в уравнении регрессии. Экзогенные скрытые переменные — это фоновые переменные, которые постулируются как вызывающие одну или несколько эндогенных переменных и моделируются как переменные-предикторы в уравнениях регрессионного типа. Причинно-следственные связи между экзогенными переменными явно не моделируются, но обычно признаются путем моделирования экзогенных переменных как свободно коррелирующие друг с другом. Модель может включать промежуточные переменные – переменные, получающие эффекты от одних переменных, но также передающие эффекты другим переменным. Как и в регрессии, каждой эндогенной переменной присваивается переменная остатка или ошибки, инкапсулирующая эффекты недоступных и обычно неизвестных причин. Каждая скрытая переменная, независимо от того, экзогенный или эндогенный , считается содержащим истинные баллы случаев по этой переменной, и эти истинные баллы причинно вносят действительные/истинные вариации в одну или несколько наблюдаемых/сообщаемых индикаторных переменных. [26]
Программа LISREL присваивала греческие имена элементам набора матриц, чтобы отслеживать различные компоненты модели. Эти имена стали относительно стандартными обозначениями, хотя обозначения были расширены и изменены с учетом различных статистических соображений. [19] [6] [16] [27] Тексты и программы, «упрощающие» спецификацию модели с помощью диаграмм или с помощью уравнений, позволяющих выбирать имена переменных, выбираемые пользователем, в фоновом режиме повторно преобразуют модель пользователя в некоторую стандартную форму матричной алгебры. «Упрощения» достигаются за счет неявного введения «предположений» программы по умолчанию о функциях модели, о которых пользователям предположительно не нужно беспокоиться. К сожалению, эти допущения по умолчанию легко скрывают компоненты модели, оставляя нераспознанные проблемы внутри структуры модели и лежащих в ее основе матриц.
В SEM выделяются два основных компонента моделей: структурная модель, показывающая потенциальные причинные зависимости между эндогенными и экзогенными латентными переменными , и модель измерения, показывающая причинные связи между латентными переменными и показателями. исследовательского и подтверждающего факторного анализа Например, модели фокусируются на причинно-следственных связях измерений, тогда как модели путей более точно соответствуют скрытым структурным связям SEM.
Разработчики моделей определяют каждый коэффициент в модели как свободный для оценки или фиксированный по некоторому значению. Свободные коэффициенты могут представлять собой постулируемые эффекты, которые исследователь желает проверить, фоновые корреляции между экзогенными переменными или дисперсии остаточных переменных или переменных ошибок, обеспечивающие дополнительные вариации эндогенных скрытых переменных. Фиксированные коэффициенты могут иметь значения, подобные значениям 1,0 на рисунке 2, которые обеспечивают масштабы для скрытых переменных, или значениями 0,0, которые подтверждают причинно-следственные связи, такие как утверждение об отсутствии прямых эффектов (отсутствие стрелок), указывающих от академических достижений к любому из четырех шкал на рисунке 1. Программы SEM предоставляют оценки и тесты свободных коэффициентов, в то время как фиксированные коэффициенты вносят важный вклад в тестирование общей структуры модели. Также можно использовать различные виды ограничений между коэффициентами. [27] [6] [16] Спецификация модели зависит от того, что известно из литературы, опыта исследователя с моделируемыми индикаторными переменными и особенностей, исследуемых с использованием конкретной структуры модели.
Существует ограничение на количество коэффициентов, которые можно оценить в модели. Если точек данных меньше, чем количество оцененных коэффициентов, результирующая модель называется «неидентифицированной», и оценки коэффициентов получить невозможно. Взаимный эффект и другие причинно-следственные связи также могут мешать оценке. [28] [29] [27]
Оценка коэффициентов свободной модели [ править ]
Коэффициенты модели, установленные на нуле, 1,0 или других значениях, не требуют оценки, поскольку они уже имеют указанные значения. Оценочные значения коэффициентов свободной модели получаются путем максимального соответствия данным или минимизации различий с ними относительно того, какими были бы характеристики данных, если бы коэффициенты свободной модели принимали оценочные значения. Влияние модели на то, как должны выглядеть данные для определенного набора значений коэффициентов, зависит от: а) расположение коэффициентов в модели (например, какие переменные связаны/несвязаны), б) характер связей между переменными (ковариации или эффекты; эффекты часто считаются линейными), в) характер ошибки или остаточных переменных (часто предполагается, что они не зависят от многих переменных или причинно не связаны с ними); и d) шкалы измерения, соответствующие переменным (часто предполагается измерение интервального уровня).
Более сильный эффект, связывающий две латентные переменные, означает, что показатели этих латентных переменных должны быть более сильно коррелированы. Следовательно, разумной оценкой латентного эффекта будет любое значение, которое лучше всего соответствует корреляциям между показателями соответствующих латентных переменных, а именно оценочное значение, максимизирующее совпадение с данными или минимизирующее различия с данными. При оценке максимального правдоподобия числовые значения всех коэффициентов свободной модели корректируются индивидуально (постепенно увеличиваются или уменьшаются по сравнению с первоначальными стартовыми значениями) до тех пор, пока они не максимизируют вероятность наблюдения выборочных данных – являются ли данные ковариациями/корреляциями переменных или фактические значения случаев по индикаторным переменным. Обычные оценки методом наименьших квадратов — это значения коэффициентов, которые минимизируют квадратичные различия между данными и тем, как данные выглядели бы, если бы модель была правильно определена, а именно, если бы все оцененные функции модели соответствовали реальным функциям.
Соответствующая статистическая функция для максимизации или минимизации для получения оценок зависит от уровней измерения переменных (оценка обычно проще с помощью измерений на интервальном уровне, чем с помощью номинальных или порядковых показателей), а также от того, где конкретная переменная появляется в модели (например, эндогенные дихотомические переменные). создают больше трудностей с оценкой, чем экзогенные дихотомические переменные). Большинство программ SEM предоставляют несколько вариантов того, что следует максимизировать или минимизировать, чтобы получить оценки коэффициентов модели. Выбор часто включает оценку максимального правдоподобия (MLE), максимального правдоподобия с полной информацией (FIML), обычный метод наименьших квадратов (OLS), взвешенный метод наименьших квадратов (WLS), диагонально взвешенный метод наименьших квадратов (DWLS) и двухэтапный метод наименьших квадратов. [27]
Одна из распространенных проблем заключается в том, что оценочное значение коэффициента может быть недостаточно идентифицировано, поскольку оно недостаточно ограничено моделью и данными. Никакой уникальной наилучшей оценки не существует, если модель и данные вместе не ограничивают или ограничивают значение коэффициента в достаточной степени. Например, величина единственной корреляции данных между двумя переменными недостаточна для оценки взаимной пары смоделированных эффектов между этими переменными. Корреляция может быть объяснена тем, что один из взаимных эффектов сильнее другого эффекта, или тем, что другой эффект сильнее первого, или эффектами равной величины. Недоопределенные оценки эффекта могут быть идентифицированы путем введения дополнительных ограничений модели и/или данных. Например, взаимные эффекты могут быть идентифицированы путем ограничения одной оценки эффекта двойной, тройной или эквивалентной другой оценке эффекта. [29] но полученные оценки будут заслуживающими доверия только в том случае, если дополнительное ограничение модели соответствует структуре мира. Данные о третьей переменной, которая непосредственно вызывает только одну из пары взаимно причинно связанных переменных, также могут помочь в идентификации. [28] Ограничение на то, чтобы третья переменная не вызывала напрямую одну из взаимно-причинных переменных, нарушает симметрию, в противном случае это ухудшает оценки взаимного эффекта, поскольку эта третья переменная должна быть более сильно коррелирована с переменной, которую она вызывает напрямую, чем с переменной на «другом» конце взаимное, на которое оно влияет лишь косвенно. [28] Обратите внимание, что это снова предполагает правильность причинно-следственной спецификации модели, а именно, что действительно существует прямой эффект, ведущий от третьей переменной к переменной на этом конце обратных эффектов, и нет прямого воздействия на переменную на «другом конце» взаимно связанная пара переменных. Теоретические требования нулевых/нулевых эффектов обеспечивают полезные ограничения, помогающие в оценке, хотя теории часто не могут четко указать, какие эффекты предположительно не существуют.
Оценка модели [ править ]
Эта статья может выиграть от сокращения за счет использования краткого стиля . |
Оценка модели зависит от теории, данных, модели и стратегии оценки. Таким образом, модельные оценки учитывают:
- содержат ли данные разумные измерения соответствующих переменных ,
- является ли смоделированный случай причинно-однородным (нет смысла оценивать одну модель, если случаи данных отражают две или более разные причинные сети.)
- представляет ли модель соответствующим образом теорию или интересующие особенности (Модели неубедительны, если в них отсутствуют функции, требуемые теорией, или содержатся коэффициенты, несовместимые с этой теорией.)
- являются ли оценки статистически обоснованными (Оценки по существу могут быть испорчены: из-за нарушения допущений, использования неподходящей оценки и/или из-за несовпадения итерационных оценок.)
- существенная обоснованность оценок (Отрицательные отклонения и корреляции, превышающие 1,0 или -1,0, невозможны. Статистически возможные оценки, несовместимые с теорией, также могут ставить под сомнение теорию и наше понимание.)
- оставшаяся согласованность или несогласованность между моделью и данными . (Процесс оценки сводит к минимуму различия между моделью и данными, но важные и информативные различия могут остаться.)
Исследования, претендующие на проверку или «исследование» теории, требуют внимания к невероятным несоответствиям модели и данных. Оценка корректирует свободные коэффициенты модели, чтобы обеспечить наилучшее соответствие данным. Результаты программ SEM включают матрицу, сообщающую о взаимосвязях между наблюдаемыми переменными, которые наблюдались бы, если бы предполагаемые эффекты модели фактически контролировали значения наблюдаемых переменных. «Соответствие» модели сообщает о совпадении или несоответствии между подразумеваемыми моделью связями (часто ковариациями) и соответствующими наблюдаемыми связями между переменными. Большие и существенные различия между данными и последствиями модели сигнализируют о проблемах. Вероятность, сопровождающая χ 2 Критерий ( хи-квадрат ) — это вероятность того, что данные могут возникнуть в результате случайных изменений выборки, если предполагаемая модель представляет собой реальные основные силы населения. Небольшой χ 2 Вероятность сообщает, что появление текущих данных было бы маловероятным, если бы смоделированная структура представляла собой реальные причинные силы населения, а остальные различия объяснялись случайными вариациями выборки.
Если модель остается несовместимой с данными, несмотря на выбор оптимальных оценок коэффициентов, честный исследовательский ответ сообщает и учитывает эти доказательства (часто значимая модель χ 2 тест). [30] Неслучайное несоответствие данных модели ставит под сомнение как оценки коэффициентов, так и способность модели определять структуру модели, независимо от того, возникает ли несогласованность из-за проблемных данных, неподходящей статистической оценки или неправильной спецификации модели. Оценки коэффициентов в моделях, несовместимых с данными («неудачных»), можно интерпретировать как отчеты о том, как мир будет выглядеть для человека, верящего в модель, которая противоречит имеющимся данным. Оценки в моделях, несовместимых с данными, не обязательно становятся «очевидно неправильными», становясь статистически странными или неправильно подписанными в соответствии с теорией. Оценки могут даже близко соответствовать требованиям теории, но остающаяся несогласованность данных делает соответствие между оценками и теорией неспособным обеспечить помощь. Неудачные модели остаются интерпретируемыми, но только как интерпретации, противоречащие имеющимся данным.
Репликация вряд ли обнаружит неправильно определенные модели, которые не соответствуют данным. Если данные репликации находятся в пределах случайных вариаций исходных данных, те же самые неправильные размещения коэффициентов, которые обеспечивали несоответствие исходным данным, вероятно, также будут ненадлежащим образом соответствовать данным репликации. Репликация помогает обнаружить такие проблемы, как ошибки в данных (допущенные разными исследовательскими группами), но особенно слаба при обнаружении неправильных спецификаций после исследовательской модификации модели – например, когда подтверждающий факторный анализ (CFA) применяется к случайной второй половине данных после исследовательского факторного анализа. (EFA) по данным за первое полугодие.
Индекс модификации — это оценка того, насколько «улучшится» соответствие модели данным (но не обязательно насколько улучшится структура модели), если для оценки будет освобожден конкретный фиксированный в настоящее время коэффициент модели. Исследователи, сталкивающиеся с моделями, несовместимыми с данными, могут легко освободить коэффициенты, которые, как сообщают индексы модификации, могут привести к существенному улучшению соответствия. Это одновременно создает существенный риск перехода от причинно-неправильной и неудачной модели к причинно-неправильной, но подходящей модели, поскольку улучшенное соответствие данных не дает уверенности в том, что освобожденные коэффициенты по существу разумны или соответствуют миру. Исходная модель может содержать причинно-следственные ошибки, такие как неправильно направленные эффекты или неверные предположения о недоступных переменных, и такие проблемы нельзя исправить путем добавления коэффициентов в текущую модель. Следовательно, такие модели остаются неточными, несмотря на более точное соответствие, обеспечиваемое дополнительными коэффициентами. Подбор, но несовместимых с миром моделей особенно вероятен, если исследователь, приверженный конкретной модели (например, факторной модели, имеющей желаемое количество факторов), получает первоначально несостоятельную модель, подгоняемую путем введения ковариаций ошибок измерения, «предложенных» модификацией. индексы. МакКаллум (1986) продемонстрировал, что «даже при благоприятных условиях к моделям, возникающим в результате поиска спецификаций, следует относиться с осторожностью». [31] Неправильную спецификацию модели иногда можно исправить путем введения коэффициентов, предложенных индексами модификации, но гораздо больше возможностей для исправления возникает за счет использования нескольких индикаторов похожих, но важных латентных переменных. [32]
«Принятие» неудачных моделей как «достаточно близких» также не является разумной альтернативой. Предостерегающий пример был предоставлен Брауном, МакКаллумом, Кимом, Андерсоном и Глейзером, которые обратились к математическим обоснованиям того, почему χ 2 Тест может обладать (хотя и не всегда) значительной способностью обнаруживать неверную спецификацию модели. [33] Вероятность, сопровождающая χ 2 Тест — это вероятность того, что данные могут возникнуть в результате случайных изменений выборки, если текущая модель с ее оптимальными оценками представляет собой реальные основные силы населения. Небольшой χ 2 Вероятность сообщает, что появление текущих данных было бы маловероятным, если бы текущая структура модели представляла собой реальные причинные силы населения, а остальные различия объяснялись случайными вариациями выборки. Браун, МакКаллум, Ким, Андерсен и Глейзер представили факторную модель, которую они считали приемлемой, несмотря на то, что модель существенно не согласовывалась с их данными согласно χ 2 . Ошибочность их утверждения о том, что плотное прилегание следует рассматривать как достаточно хорошее, продемонстрировали Гайдук, Пазкерка-Робинсон, Каммингс, Леверс и Берес. [34] который продемонстрировал подходящую модель для собственных данных Брауна и др., включив экспериментальную особенность. Браун и др. упустили из виду. Ошибка была не в математике индексов или в чрезмерной чувствительности χ. 2 тестирование. Ошибка заключалась в том, что Браун, МакКаллум и другие авторы забыли, пренебрегли или упустили из виду, что нельзя полагать, что степень несоответствия соответствует характеру, местоположению или серьезности проблем в спецификации модели. [35]
Многие исследователи пытались оправдать переход к индексам соответствия, а не тестированию своих моделей, утверждая, что χ 2 возрастает (и, следовательно, χ 2 вероятность уменьшается) с увеличением размера выборки (N). есть две ошибки При дисконтировании χ 2 на этом основании. Во-первых, для собственных моделей χ 2 не увеличивается с увеличением N, [30] так что если х 2 увеличивается с ростом N, что само по себе является признаком того, что что-то заметно проблематично. Во-вторых, для моделей, которые явно определены неверно, χ 2 Увеличение с увеличением N дает хорошие новости об увеличении статистической мощности для обнаружения ошибок спецификации модели (а именно, способности обнаруживать ошибки второго рода). Некоторые виды важных неточностей не могут быть обнаружены с помощью χ 2 , [35] поэтому любое несоответствие, выходящее за рамки того, что может быть разумно вызвано случайными вариациями, требует сообщения и рассмотрения. [36] [30] χ 2 модельное испытание, возможно скорректированное, [37] является самым надежным из доступных тестов модели структурных уравнений.
Многочисленные индексы соответствия количественно определяют, насколько близко модель соответствует данным, но все индексы соответствия страдают от логической трудности, заключающейся в том, что размер или степень несоответствия не надежно скоординированы с серьезностью или характером проблем, вызывающих несогласованность данных. [35] Модели с разными причинно-следственными структурами, которые одинаково хорошо соответствуют данным, называются эквивалентными моделями. [27] Такие модели эквивалентны данным, но не причинно эквивалентны, поэтому по крайней мере одна из так называемых эквивалентных моделей должна быть несовместима со структурой мира. Если между X и Y существует идеальная корреляция 1,0, и мы моделируем это, поскольку X вызывает Y, будет идеальное соответствие и нулевая остаточная ошибка. Но модель может не соответствовать миру, потому что Y на самом деле может быть причиной X, или и X, и Y могут реагировать на общую причину Z, или мир может содержать смесь этих эффектов (например, общая причина плюс следствие Y). на X) или другие причинные структуры. Идеальное соответствие не говорит нам о том, что структура модели соответствует структуре мира, а это, в свою очередь, подразумевает, что приближение к идеальному совпадению не обязательно соответствует приближению к структуре мира – возможно, так оно и есть, а может быть, и нет. Это делает неверным заявление исследователя о том, что даже идеальное соответствие модели подразумевает, что модель правильно каузально определена. Даже для моделей умеренной сложности точно эквивалентные модели встречаются редко. Модели, почти соответствующие данным по любому индексу, неизбежно вносят дополнительные потенциально важные, но неизвестные неверные спецификации моделей. Эти модели представляют собой еще большее препятствие для исследований.
Эта логическая слабость делает все индексы соответствия «бесполезными», когда модель структурного уравнения существенно не согласуется с данными. [36] однако некоторые силы продолжают пропагандировать использование индекса соответствия. Например, Даг Сорбом сообщил, что когда кто-то спросил Карла Йорескога, разработчика первой программы моделирования структурными уравнениями: «Почему вы тогда добавили GFI?» На вашу программу LISREL Джорескуг ответил: «Ну, пользователи угрожают нам, говоря, что перестанут использовать LISREL, если он всегда будет выдавать такие большие хи-квадраты. Поэтому нам пришлось изобрести что-то, чтобы сделать людей счастливыми. GFI служит этой цели». [38] χ 2 Доказательства несоответствия данных модели были слишком статистически достоверными, чтобы их можно было вытеснить или отбросить, но людям, по крайней мере, можно было предоставить способ отвлечься от «тревожных» доказательств. Карьерную прибыль по-прежнему можно получать, разрабатывая дополнительные индексы, сообщая об исследованиях поведения индексов и публикуя модели, намеренно скрывая доказательства несоответствия данных модели под MDI (кучей отвлекающих индексов). Кажется, не существует общего обоснования того, почему исследователь должен «принять» причинно неправильную модель, а не пытаться исправить обнаруженные неверные спецификации. И некоторые части литературы, похоже, не заметили, что «принятие модели» (на основе «удовлетворения» значению индекса) страдает от усиленной версии критики, применяемой к «принятию» нулевой гипотезы. В текстах по вводной статистике обычно рекомендуется заменить термин «принять» на «не удалось отвергнуть нулевую гипотезу», чтобы признать возможность ошибки второго рода. Ошибка типа III возникает в результате «принятия» гипотезы модели, когда текущих данных достаточно, чтобы отвергнуть модель.
Вопрос о том, привержены ли исследователи поиску структуры мира, является фундаментальной проблемой. Замещение тестовых доказательств несоответствия данных модели путем сокрытия их за заявлениями об индексе приемлемого соответствия приводит к общедисциплинарным издержкам, связанным с отвлечением внимания от того, что дисциплина могла бы сделать для достижения структурно улучшенного понимания сути дисциплины. Дисциплина в конечном итоге платит реальную цену за индексное смещение доказательств неправильной спецификации модели. Разногласия, возникающие из-за разногласий по поводу необходимости исправления неправильных спецификаций моделей, вероятно, будут увеличиваться по мере увеличения использования нефакторных моделей и использования меньшего количества более точных индикаторов схожих, но, что немаловажно, различных скрытых переменных. [32]
Соображения, относящиеся к использованию индексов соответствия, включают проверку:
- были ли решены проблемы с данными (чтобы гарантировать, что ошибки в данных не приводят к несогласованности данных модели);
- исследовались ли значения критерия индекса для моделей, структурированных подобно модели исследователя (например, критерий индекса, основанный на факторно-структурированных моделях, подходит только в том случае, если модель исследователя действительно является факторно-структурированной);
- соответствуют ли типы потенциальных неточностей в текущей модели типам неточностей, на которых основан индексный критерий (например, критерии, основанные на моделировании пропущенных факторных нагрузок, могут не подходить для неправильных спецификаций, возникающих из-за невозможности включить соответствующие контрольные переменные);
- соглашается ли исследователь сознательно игнорировать доказательства, указывающие на виды неправильных спецификаций, на которых были основаны критерии индекса. (Если критерий индекса основан на моделировании одной или двух недостающих факторных нагрузок, использование этого критерия подтверждает готовность исследователя принять модель, в которой отсутствует одна или две факторные нагрузки.);
- используются ли самые последние, не устаревшие критерии индексов (поскольку критерии для некоторых индексов со временем ужесточились);
- требуются ли удовлетворяющие критериальным значениям пары индексов (например, Ху и Бентлер [39] сообщают, что некоторые общие индексы функционируют ненадлежащим образом, если они не оцениваются вместе.);
- доступен ли модельный тест или нет. (А х 2 значение, степени свободы и вероятность будут доступны для моделей, сообщающих индексы на основе χ 2 .)
- и учитывал ли исследователь как альфа (тип I), так и бета (тип II) ошибки при принятии решений на основе индексов (например, если модель существенно несовместима с данными, «приемлемая» степень несогласованности, вероятно, будет различаться в зависимости от модели). контексте медицинского, делового, социального и психологического контекста.).
Некоторые из наиболее часто используемых статистических данных соответствия включают в себя
- Хи-квадрат
- Фундаментальный тест на соответствие, используемый при расчете многих других показателей соответствия. Это функция несоответствия между наблюдаемой ковариационной матрицей и подразумеваемой моделью ковариационной матрицей. Хи-квадрат увеличивается с увеличением размера выборки только в том случае, если модель явно определена неверно. [30]
- Информационный критерий Акаике (AIC)
- Индекс относительного соответствия модели: Предпочтительной является модель с наименьшим значением AIC.
- где k — количество параметров статистической модели , а L — максимальное значение правдоподобия модели .
- Среднеквадратическая ошибка аппроксимации (RMSEA)
- Стандартизированный среднеквадратичный остаток (SRMR)
- SRMR – популярный индикатор абсолютного соответствия. Ху и Бентлер (1999) предложили 0,08 или меньше в качестве ориентира для хорошей подгонки. [42]
- Сравнительный индекс соответствия (CFI)
- При изучении базовых сравнений CFI во многом зависит от среднего размера корреляций в данных. Если средняя корреляция между переменными невысока, то CFI не будет очень высоким. Желательно значение CFI 0,95 или выше. [42]

В следующей таблице приведены ссылки, документирующие эти и другие характеристики некоторых распространенных индексов: RMSEA (среднеквадратическая ошибка аппроксимации), SRMR (стандартизованная среднеквадратическая невязка), CFI (индекс подтверждающего соответствия) и TLI (такер -Индекс Льюиса). Дополнительные индексы, такие как AIC (информационный критерий Акаике), можно найти в большинстве руководств по SEM. [27] Для каждой меры соответствия решение о том, что представляет собой достаточно хорошее соответствие между моделью и данными, отражает цель моделирования исследователя (возможно, оспаривание чужой модели или улучшение измерения); следует ли утверждать, что модель была «протестирована»; и удобно ли исследователю «игнорировать» доказательства документированной индексом степени несоответствия. [30]
| РМСЭА | СРМР | CFI | |
|---|---|---|---|
| Имя индекса | Среднеквадратическая ошибка аппроксимации | Стандартизированный среднеквадратичный остаток | Индекс подтверждающего соответствия |
| Формула | RMSEA = квадратный корень(( χ 2 - д)/(д(N-1))) | ||
| Основные ссылки | [43] [44] [45] | ||
| факторной модели Предлагаемая формулировка для критических значений | формулировка .06? [39] | ||
| НЕФакторной модели Предлагаемая формулировка для критических значений | |||
| Ссылки, предлагающие пересмотр/изменение, разногласия по поводу критических ценностей | [39] | [39] | [39] |
| Ссылки, указывающие двухиндексный или парный индекс критерии необходимы | [39] | [39] | [39] |
| Индекс на основе χ 2 | Да | Нет | Да |
| Ссылки, рекомендующие против использования этого индекса | [36] | [36] | [36] |
, мощность и оценка Размер выборки
Исследователи согласны с тем, что выборки должны быть достаточно большими, чтобы обеспечить стабильные оценки коэффициентов и разумную мощность тестирования, но не существует общего согласия относительно конкретных требуемых размеров выборки или даже того, как определить подходящие размеры выборки. Рекомендации основывались на количестве коэффициентов, подлежащих оценке, количестве смоделированных переменных и моделировании Монте-Карло, касающемся конкретных коэффициентов модели. [27] Рекомендации по размеру выборки, основанные на соотношении количества показателей к скрытым, являются факторно-ориентированными и не применяются к моделям, использующим одиночные показатели с фиксированными ненулевыми отклонениями ошибок измерения. [32] В целом, для моделей среднего размера без статистически трудно поддающихся оценке коэффициентов требуемые размеры выборки (N) кажутся примерно сопоставимыми с N, необходимыми для регрессии, использующей все индикаторы.
Чем больше размер выборки, тем выше вероятность включения в нее случаев, которые не являются причинно-однородными. Следовательно, увеличение N для повышения вероятности возможности сообщить о желаемом коэффициенте как статистически значимом одновременно увеличивает риск неправильной спецификации модели и возможность обнаружения неправильной спецификации. Исследователи, стремящиеся извлечь уроки из своего моделирования (в том числе потенциально узнать, что их модель требует корректировки или замены), будут стремиться к как можно большему размеру выборки, насколько это позволяет финансирование и их оценка вероятной популяционной причинной гетерогенности/однородности. Если доступное N огромно, моделирование подмножеств случаев может контролировать переменные, которые в противном случае могли бы нарушить причинную однородность. Исследователи, опасающиеся, что им, возможно, придется сообщать о недостатках своей модели, разрываются между желанием большего N, чтобы обеспечить достаточную мощность для обнаружения интересующих структурных коэффициентов, и избеганием мощности, способной сигнализировать о несоответствии данных модели. Огромные различия в структурах моделей и характеристиках данных позволяют предположить, что адекватные размеры выборок могут быть полезны при рассмотрении опыта других исследователей (как хорошего, так и плохого) с моделями сопоставимого размера и сложности, которые были оценены с использованием аналогичных данных.
Интерпретация [ править ]
Причинные интерпретации моделей SE являются наиболее ясными и понятными, но эти интерпретации будут ошибочными/неправильными, если структура модели не соответствует причинной структуре мира. Следовательно, интерпретация должна учитывать общий статус и структуру модели, а не только оцененные коэффициенты модели. Соответствует ли модель данным и/или как модель соответствует данным, имеет первостепенное значение для интерпретации. Подбор данных, полученный путем изучения или отслеживания индексов последовательных модификаций, не гарантирует, что модель неверна, но вызывает серьезные сомнения, поскольку эти подходы склонны к неправильному моделированию характеристик данных. Например, изучение того, сколько факторов требуется, упреждает обнаружение того, что данные не являются факторно-структурированными, особенно если факторную модель «убедили» в ее соответствии посредством включения ковариаций ошибок измерения. Способность данных выступать против постулируемой модели постепенно снижается с каждым необоснованным включением эффекта «предлагаемого индекса модификации» или ковариации ошибок. Становится чрезвычайно сложно восстановить правильную модель, если исходная/базовая модель содержит несколько неверных спецификаций. [46]
Оценки прямого эффекта интерпретируются параллельно с интерпретацией коэффициентов в уравнениях регрессии, но с причинно-следственной связью. Увеличение значения причинной переменной на каждую единицу рассматривается как изменение расчетной величины значения зависимой переменной при условии контроля или корректировки всех других действующих/моделируемых причинных механизмов. Косвенные эффекты интерпретируются аналогичным образом: величина конкретного косвенного эффекта равна произведению ряда прямых эффектов, составляющих этот косвенный эффект. В качестве единиц измерения используются реальные масштабы значений наблюдаемых переменных и присвоенные масштабные значения скрытых переменных. Заданный/фиксированный эффект 1.0 скрытого значения на конкретном индикаторе координирует масштаб этого индикатора с масштабом скрытой переменной. Предположение о том, что остальная часть модели остается постоянной или неизменной, может потребовать дисконтирования косвенных эффектов, которые в реальном мире могут быть одновременно вызваны реальным увеличением единицы продукции. И само увеличение единицы может быть несовместимо с тем, что возможно в реальном мире, потому что может не быть известного способа изменить значение причинной переменной. Если модель корректируется с учетом ошибок измерения, эта корректировка позволяет интерпретировать эффекты скрытого уровня как относящиеся к различиям в истинных показателях. [26]
Интерпретации SEM наиболее радикально отличаются от интерпретаций регрессии, когда сеть причинных коэффициентов соединяет скрытые переменные, поскольку регрессии не содержат оценок косвенных эффектов. Интерпретации SEM должны отражать последствия закономерностей косвенных эффектов, которые переносят эффекты от фоновых переменных через промежуточные переменные к последующим зависимым переменным. Интерпретации СЭМ способствуют пониманию того, как многочисленные мирские причинно-следственные связи могут работать согласованно, независимо или даже противодействовать друг другу. Прямым эффектам могут противодействовать (или усиливаться) косвенные эффекты, а их корреляционные последствия могут противодействоваться (или усиливаться) эффектами общих причин. [15] Значение и интерпретация конкретных оценок должны быть контекстуализированы в полной модели.
Интерпретация модели SE должна связывать конкретные причинные сегменты модели с их последствиями дисперсии и ковариации. Одиночный прямой эффект сообщает, что дисперсия независимой переменной приводит к определенному изменению значений зависимой переменной, но причинные детали того, что именно вызывает это, остаются неопределенными, поскольку один коэффициент эффекта не содержит подкомпонентов, доступных для интеграции. в структурированную историю о том, как возникает этот эффект. Для предоставления характеристик, составляющих историю о том, как функционирует тот или иной эффект, потребуется более детальная модель SE, включающая переменные, промежуточные между причиной и следствием. Пока такая модель не появится, каждый оцененный прямой эффект сохраняет оттенок неизвестного, тем самым обращаясь к сути теории. Параллельная существенная неизвестность будет сопровождать каждый оцененный коэффициент даже в более детализированной модели, поэтому ощущение фундаментальной тайны никогда полностью не искореняется из моделей SE.
Даже если каждый смоделированный эффект неизвестен, за исключением идентичности задействованных переменных и предполагаемой величины эффекта, структуры, связывающие несколько смоделированных эффектов, дают возможность выразить, как вещи функционируют для координации наблюдаемых переменных, тем самым предоставляя полезные возможности интерпретации. Например, общая причина способствует ковариации или корреляции между двумя затронутыми переменными, потому что, если значение причины возрастает, значения обоих эффектов также должны расти (при условии положительных эффектов), даже если мы не знаем всей истории. лежащую в основе каждой причины. [15] (Корреляция — это ковариация между двумя переменными, обе из которых стандартизированы и имеют дисперсию 1,0). Другой вклад в интерпретацию можно внести, выразив, как две причинные переменные могут объяснить дисперсию зависимой переменной, а также как ковариация между двумя такими причинами может увеличить или уменьшить объясненную дисперсию зависимой переменной. То есть интерпретация может включать объяснение того, как набор эффектов и ковариаций может способствовать уменьшению дисперсии зависимой переменной. [47] Понимание причинно-следственных связей неявно связано с пониманием «контроля» и потенциально объясняет, почему следует контролировать одни переменные, а не другие. [4] [48] По мере усложнения моделей эти фундаментальные компоненты могут объединяться неинтуитивным образом, например, объясняя, почему не может быть корреляции (нулевой ковариации) между двумя переменными, несмотря на то, что переменные связаны прямым ненулевым причинным эффектом. [15] [16] [6] [29]
Статистическая незначительность оценки эффекта указывает на то, что эта оценка может довольно легко возникнуть как случайное изменение выборки вокруг нулевого/нулевого эффекта, поэтому интерпретация оценки как реального эффекта становится двусмысленной. Как и в регрессии, доля дисперсии каждой зависимой переменной, объясняемая вариациями смоделированных причин, определяется как R. 2 , хотя заблокированная ошибка R 2 следует использовать, если зависимая переменная участвует во взаимных или циклических эффектах или если она имеет переменную ошибки, коррелирующую с какой-либо переменной ошибки предиктора. [49]
Предостережение, показанное в разделе «Оценка модели», требует повторения. Должна быть возможна интерпретация независимо от того, согласуется ли модель с данными. Оценки показывают, как мир будет выглядеть для того, кто верит в эту модель – даже если это убеждение необоснованно, потому что модель оказывается ошибочной. Интерпретация должна признать, что коэффициенты модели могут соответствовать или не соответствовать «параметрам» – потому что коэффициенты модели могут не иметь соответствующих мирских структурных особенностей.
Добавление новых скрытых переменных, входящих в исходную модель или выходящих из нее в нескольких явных причинных местах/переменных, способствует обнаружению неправильных спецификаций модели, которые в противном случае могли бы испортить интерпретацию коэффициентов. Корреляции между новыми скрытыми показателями и всеми исходными показателями способствуют тестированию структуры исходной модели, поскольку несколько новых и сфокусированных коэффициентов эффекта должны работать в координации с исходными прямыми и косвенными эффектами модели для координации новых показателей с исходными показателями. Если структура исходной модели была проблематичной, новых причинно-следственных связей будет недостаточно для координации новых показателей с исходными показателями, тем самым сигнализируя о несоответствии коэффициентов исходной модели из-за несоответствия данных модели. [29] Корреляционные ограничения, основанные на коэффициентах нулевого/нулевого эффекта, а также коэффициентах, которым присвоены фиксированные ненулевые значения, способствуют как тестированию модели, так и оценке коэффициентов, и, следовательно, заслуживают признания в качестве основы, поддерживающей оценки и их интерпретацию. [29]
Интерпретации становятся все более сложными для моделей, содержащих взаимодействия, нелинейности, несколько групп, несколько уровней и категориальные переменные. [27] Эффекты, затрагивающие причинно-следственные связи, обратные эффекты или коррелированные остатки, также требуют слегка пересмотренной интерпретации. [6] [29]
Тщательная интерпретация как неудачных, так и подходящих моделей может способствовать продвижению исследований. Чтобы быть надежной, модель должна исследовать академически информативные причинные структуры, согласовывать применимые данные с понятными оценками и не включать пустые коэффициенты. [50] Надежно подогнанные модели встречаются реже, чем неудачные модели или модели, которые неправильно подогнаны, но вполне возможны модели, подходящие по размеру. [34] [51] [52] [53]
Несколько способов концептуализации моделей PLS [54] усложнить интерпретацию моделей PLS. Многие из приведенных выше комментариев применимы, если разработчик PLS придерживается реалистичной точки зрения, стремясь обеспечить, чтобы смоделированные индикаторы сочетались таким образом, чтобы соответствовать некоторой существующей, но недоступной скрытой переменной. Некаузальные модели PLS, например те, которые ориентированы в первую очередь на R. 2 или предсказательная сила за пределами выборки, измените критерии интерпретации, уменьшив озабоченность тем, имеют ли коэффициенты модели мировые аналоги. Фундаментальные особенности, отличающие пять точек зрения PLS-моделирования, обсуждаемые Ригдоном, Сарстедтом и Ринглом. [54] указывают на различия в целях разработчиков моделей PLS и соответствующие различия в функциях модели, требующих интерпретации.
Следует проявлять осторожность, заявляя о причинно-следственной связи, даже если проводились эксперименты или запланированные по времени исследования. Термин причинно-следственная модель следует понимать как означающий «модель, которая передает причинно-следственные предположения», а не обязательно модель, которая дает обоснованные причинно-следственные выводы - возможно, это так, а может быть, и нет. Сбор данных в различные моменты времени и использование экспериментального или квазиэкспериментального плана может помочь исключить определенные конкурирующие гипотезы, но даже рандомизированные эксперименты не могут полностью исключить угрозы причинно-следственным утверждениям. Ни один исследовательский план не может полностью гарантировать причинно-следственные структуры. [4]
и движения Споры
Моделирование структурными уравнениями чревато противоречиями. Исследователи, придерживающиеся традиции факторного анализа, обычно пытаются сократить наборы множественных показателей до меньшего количества, более управляемых шкал или показателей факторов для последующего использования в моделях с траекторной структурой. Это представляет собой поэтапный процесс, в котором на начальном этапе измерения предоставляются шкалы или коэффициентные оценки, которые будут использоваться позже в модели с траекторной структурой. Такой поэтапный подход кажется очевидным, но на самом деле он сталкивается с серьезными основными недостатками. Сегментация на этапы мешает тщательной проверке того, действительно ли шкалы или оценки факторов представляют индикаторы и/или достоверно сообщают о эффектах скрытого уровня. Модель структурного уравнения, одновременно включающая как структуры измерения, так и структуры скрытого уровня, не только проверяет, надлежащим ли образом координируют скрытые факторы показатели, но также проверяет, одновременно ли тот же самый скрытый одновременно соответствующим образом координирует показатели каждого скрытого показателя с показателями теоретических причин и/или последствий это скрыто. [29] Если латентный человек не способен выполнять оба этих стиля координации, достоверность этого латентного состояния подвергается сомнению, а шкала или коэффициенты, предназначенные для измерения этого латентного состояния, подвергаются сомнению. Разногласия вращались вокруг уважения или неуважения к доказательствам, оспаривающим обоснованность постулируемых скрытых факторов. Кипящие, а иногда и кипящие дискуссии привели к появлению специального выпуска журнала Structural Equation Modeling, посвященного целевой статье Гайдука и Глейзера. [20] после чего последовало несколько комментариев и ответ, [21] все они стали бесплатными благодаря усилиям Джорджа Маркулидеса.
Эти дискуссии породили разногласия по поводу того, следует ли проверять модели структурных уравнений на соответствие данным, и тестирование моделей стало следующим предметом дискуссий. Ученые, имеющие опыт моделирования путей, были склонны защищать тщательное тестирование моделей, в то время как ученые, имеющие факторные истории, были склонны защищать индексацию соответствия, а не тестирование соответствия. Эти обсуждения привели к появлению целевой статьи Пола Барретта «Личность и индивидуальные различия». [36] который сказал: «На самом деле, я бы теперь рекомендовал запретить ВСЕ такие индексы когда-либо появляться в любой статье как показатель «приемлемости» модели или «степени несоответствия»». [36] (стр. 821). Статья Барретта также сопровождалась комментариями с обеих точек зрения. [50] [55]
Споры по поводу тестирования моделей утихли, поскольку четкое сообщение о значительных несоответствиях данных модели становится обязательным. Ученые не могут игнорировать или не сообщать доказательства только потому, что им не нравится то, о чем сообщают доказательства. [30] Требование внимания к доказательствам, указывающим на неправильную спецификацию модели, лежит в основе недавней озабоченности решением проблемы «эндогенности» – стиля неправильной спецификации модели, который мешает оценке из-за отсутствия независимости ошибок/остаточных переменных. В целом, споры о причинной природе моделей структурных уравнений, включая факторные модели, также утихают. Стэн Мулайк, приверженец факторного анализа, признал причинную основу факторных моделей. [56] Комментарии Боллена и Перла относительно мифов о причинности в контексте SEM [25] усилили центральную роль причинно-следственного мышления в контексте SEM.
Более краткая полемика была сосредоточена на конкурирующих моделях. Сравнение конкурирующих моделей может быть очень полезным, но существуют фундаментальные проблемы, которые невозможно решить путем создания двух моделей и сохранения более подходящей модели. Статистическая сложность таких презентаций, как Леви и Хэнкок (2007), [57] например, позволяет легко упустить из виду, что исследователь может начать с одной ужасной модели и одной ужасной модели, а закончить сохранением структурно ужасной модели, потому что некоторые индексы сообщают, что она лучше подходит, чем ужасная модель. К сожалению, даже такие сильные в других отношениях тексты SEM, как Клайн (2016), [27] остаются тревожно слабыми в своем представлении о тестировании моделей. [58] В целом, вклад, который может внести моделирование структурными уравнениями, зависит от тщательной и детальной оценки модели, даже если неудачная модель оказывается лучшей из имеющихся.
Еще один спор, затронувший периферию предыдущих споров, ждет своего часа. [ нужна ссылка ] Факторные модели и встроенные в теорию факторные структуры, имеющие несколько индикаторов, имеют тенденцию давать сбой, а исключение слабых индикаторов имеет тенденцию уменьшать несогласованность данных модели. Сокращение количества индикаторов приводит к беспокойству и разногласиям по поводу минимального количества индикаторов, необходимых для поддержки скрытой переменной в модели структурного уравнения. Исследователей, привязанных к факторной традиции, можно убедить сократить количество индикаторов до трех на каждую скрытую переменную, но три или даже два индикатора все равно могут быть несовместимы с предполагаемой общей причиной основных факторов. Гайдук и Литтвей (2012) [32] обсудили, как учитывать, защищать и корректировать ошибки измерения при использовании только одного индикатора для каждой моделируемой скрытой переменной. Одиночные индикаторы уже давно эффективно используются в моделях SE. [51] но разногласия остаются лишь в пределах рецензента, который рассматривал измерение только с точки зрения факторного анализа.
Следы этих противоречий, хотя и уменьшаются, но разбросаны по всей литературе по SEM, и вы можете легко спровоцировать разногласия, задав вопрос: что следует делать с моделями, которые существенно не согласуются с данными? Или задав вопрос: преобладает ли простота модели над уважением к доказательствам несогласованности данных? Или какой вес следует придавать индексам, которые показывают близкие или не очень близкие данные, подходящие для некоторых моделей? Или нам следует быть особенно снисходительными и «вознаграждать» экономные модели, которые не соответствуют данным? Или, учитывая, что RMSEA оправдывает игнорирование некоторых действительно неподходящих для каждой степени свободы модели, не означает ли это, что люди, тестирующие модели с нулевыми гипотезами ненулевого RMSEA, проводят неудовлетворительное тестирование модели? Для убедительного ответа на такие вопросы требуются значительные различия в уровне статистической сложности, хотя ответы, скорее всего, будут сосредоточены на нетехническом вопросе: обязаны ли исследователи сообщать и уважать доказательства.
, альтернативы моделирования и статистические аналоги Расширения
- Категориальные зависимые переменные [ нужна ссылка ]
- Категориальные промежуточные переменные [ нужна ссылка ]
- Копуляции [ нужна ссылка ]
- Исследовательское моделирование структурных уравнений [59]
- Модели валидности слияния [60]
- теории реагирования на предмет Модели [ нужна ссылка ]
- Модели скрытого класса [ нужна ссылка ]
- Моделирование скрытого роста [ нужна ссылка ]
- Функции связи [ нужна ссылка ]
- Продольные модели [61]
- Модели инвариантности измерений [62]
- Модель смеси [ нужна ссылка ]
- Многоуровневые модели , иерархические модели (например, люди, вложенные в группы) [63]
- Множественное групповое моделирование с ограничениями между группами или без них (пол, культура, формы тестирования, языки и т. д.) [ нужна ссылка ]
- Мультиметодические модели с несколькими признаками [ нужна ссылка ]
- Модели случайных перехватов [ нужна ссылка ]
- Деревья моделей структурных уравнений [ нужна ссылка ]
Программное обеспечение [ править ]
Программы моделирования структурными уравнениями сильно различаются по своим возможностям и требованиям пользователей. [64]
См. также [ править ]
- Причинная модель - Концептуальная модель в философии науки.
- Графическая модель – Вероятностная модель
- Многомерная статистика – одновременное наблюдение и анализ более чем одной конечной переменной.
- Частичное моделирование пути методом наименьших квадратов
- Частичная регрессия наименьших квадратов - Статистический метод
- Модель одновременных уравнений – Тип статистической модели
- Причинно-следственная карта - сеть, состоящая из связей или дуг между узлами или факторами.
- Байесовская сеть –
Ссылки [ править ]
- ^ Салкинд, Нил Дж. (2007). «Интеллектуальные тесты». Энциклопедия измерений и статистики . дои : 10.4135/9781412952644.n220 . ISBN 978-1-4129-1611-0 .
- ^ Босло, С.; МакНатт, Лос-Анджелес. (2008). «Моделирование структурными уравнениями». Энциклопедия эпидемиологии. doi 10.4135/9781412953948.n443, ISBN 978-1-4129-2816-8.
- ^ Шелли, MC (2006). «Моделирование структурными уравнениями». Энциклопедия образовательного лидерства и управления. doi 10.4135/9781412939584.n544, ISBN 978-0-7619-3087-7.
- ↑ Перейти обратно: Перейти обратно: а б с д и Перл, Дж. (2009). Причинность: модели, рассуждения и выводы. Второе издание. Нью-Йорк: Издательство Кембриджского университета.
- ^ Клайн, Рекс Б. (2016). Принципы и практика моделирования структурными уравнениями (4-е изд.). Нью-Йорк. ISBN 978-1-4625-2334-4 . OCLC 934184322 .
{{cite book}}: CS1 maint: отсутствует местоположение издателя ( ссылка ) - ↑ Перейти обратно: Перейти обратно: а б с д и ж Гайдук, Л. (1987) Моделирование структурными уравнениями с помощью LISREL: основы и достижения. Балтимор, Издательство Университета Джонса Хопкинса. ISBN 0-8018-3478-3
- ^ Боллен, Кеннет А. (1989). Структурные уравнения со скрытыми переменными . Нью-Йорк: Уайли. ISBN 0-471-01171-1 . OCLC 18834634 .
- ^ Каплан, Дэвид (2009). Моделирование структурными уравнениями: основы и расширения (2-е изд.). Лос-Анджелес: SAGE. ISBN 978-1-4129-1624-0 . OCLC 225852466 .
- ^ Карран, Патрик Дж. (01 октября 2003 г.). «Были ли многоуровневые модели всегда моделями структурных уравнений?». Многомерное поведенческое исследование . 38 (4): 529–569. дои : 10.1207/s15327906mbr3804_5 . ISSN 0027-3171 . ПМИД 26777445 . S2CID 7384127 .
- ^ Тарка, Петр (2017). «Обзор моделирования структурными уравнениями: его начало, историческое развитие, полезность и противоречия в социальных науках» . Качество и количество . 52 (1): 313–54. дои : 10.1007/s11135-017-0469-8 . ПМЦ 5794813 . ПМИД 29416184 .
- ^ МакКаллум и Остин 2000 , стр. 209.
- ^ Райт, Сьюэлл. (1921) «Корреляция и причинно-следственная связь». Журнал сельскохозяйственных исследований. 20: 557-585.
- ^ Райт, Сьюэлл. (1934) «Метод коэффициентов пути». Анналы математической статистики. 5 (3): 161–215. дои: 10.1214/aoms/1177732676.
- ^ Вольфл, Л.М. (1999) «Сьюэлл Райт о методе коэффициентов пути: аннотированная библиография» Моделирование структурными уравнениями: 6 (3): 280-291.
- ↑ Перейти обратно: Перейти обратно: а б с д Дункан, Отис Дадли. (1975). Введение в модели структурных уравнений. Нью-Йорк: Академическая пресса. ISBN 0-12-224150-9.
- ↑ Перейти обратно: Перейти обратно: а б с д Боллен, К. (1989). Структурные уравнения со скрытыми переменными. Нью-Йорк, Уайли. ISBN 0-471-01171-1.
- ^ Йорескуг, Карл; Грувеус, Гуннар Т.; ван Тилло, Мариэль. (1970) ACOVS: Общая компьютерная программа для анализа ковариационных структур. Принстон, Нью-Джерси; Услуги образовательного тестирования.
- ^ Йорескуг, Карл Густав; ван Тилло, Мариэлла (1972). «LISREL: общая компьютерная программа для оценки системы линейных структурных уравнений, включающей множественные индикаторы неизмеренных переменных» (PDF) . Исследовательский бюллетень: Управление образования . ETS-RB-72-56 – через правительство США.
- ↑ Перейти обратно: Перейти обратно: а б Йорескуг, Карл; Сорбом, Даг. (1976) LISREL III: Оценка систем линейных структурных уравнений методами максимального правдоподобия. Чикаго: Национальные образовательные ресурсы, Inc.
- ↑ Перейти обратно: Перейти обратно: а б Гайдук, Л.; Глейзер, Д. Н. (2000) «Развлечение с четырьмя шагами, вальсирование вокруг факторного анализа и другие серьезные развлечения». Моделирование структурными уравнениями. 7 (1): 1-35.
- ↑ Перейти обратно: Перейти обратно: а б Гайдук, Л.; Глейзер, Д.Н. (2000) «Выполнение четырех шагов, правильно-2-3, неправильно-2-3: краткий ответ Мулайку и Миллсапу; Боллену; Бентлеру; Хертингу и Костнеру». Моделирование структурными уравнениями. 7 (1): 111-123.
- ^ Вестленд, JC (2015). Моделирование структурными уравнениями: от путей к сетям. Нью-Йорк, Спрингер.
- ^ Христос, Карл Ф. (1994). «Вклад Комиссии Коулза в эконометрику в Чикаго, 1939–1955» . Журнал экономической литературы . 32 (1): 30–59. ISSN 0022-0515 . JSTOR 2728422 .
- ^ Имбенс, GW (2020). «Потенциальный результат и направленные ациклические графические подходы к причинности: актуальность для эмпирической практики в экономике». Журнал экономической литературы. 58 (4): 11-20-1179.
- ↑ Перейти обратно: Перейти обратно: а б с Боллен, Калифорния; Перл, Дж. (2013) «Восемь мифов о причинно-следственной связи и моделях структурных уравнений». В SL Morgan (ред.) «Справочник по причинному анализу социальных исследований», глава 15, 301–328, Springer. doi:10.1007/978-94-007-6094-3_15
- ↑ Перейти обратно: Перейти обратно: а б Борсбум, Д.; Мелленберг, Дж.Дж.; ван Херден, Дж. (2003). «Теоретический статус скрытых переменных». Психологический обзор, 110 (2): 203–219. https://doi.org/10.1037/0033-295X.110.2.203 }
- ↑ Перейти обратно: Перейти обратно: а б с д и ж г час я Клайн, Рекс. (2016) Принципы и практика моделирования структурными уравнениями (4-е изд.). Нью-Йорк, Гилфорд Пресс. ISBN 978-1-4625-2334-4
- ↑ Перейти обратно: Перейти обратно: а б с Ригдон, Э. (1995). «Необходимое и достаточное правило идентификации структурных моделей, оцениваемых на практике». Многомерное поведенческое исследование. 30 (3): 359–383.
- ↑ Перейти обратно: Перейти обратно: а б с д и ж г Гайдук, Л. (1996) Проблемы, дебаты и стратегии LISREL. Балтимор, Издательство Университета Джона Хопкинса. ISBN 0-8018-5336-2
- ↑ Перейти обратно: Перейти обратно: а б с д и ж Гайдук, Л.А. (2014b) «Позор за неуважение к доказательствам: личные последствия недостаточного уважения к тестированию моделей структурных уравнений. BMC: Medical Research Methodology, 14 (124): 1-10 DOI 10.1186/1471-2288-14-24 http: //www.biomedcentral.com/1471-2288/14/124
- ^ МакКаллум, Роберт (1986). «Поиск спецификаций при моделировании ковариационной структуры». Психологический вестник . 100 : 107–120. дои : 10.1037/0033-2909.100.1.107 .
- ↑ Перейти обратно: Перейти обратно: а б с д Гайдук, Луизиана; Литтвей, Л. (2012) «Должны ли исследователи использовать отдельные индикаторы, лучшие индикаторы или несколько индикаторов в моделях структурных уравнений?» Методология медицинских исследований BMC, 12 (159): 1-17. дои: 10,1186/1471-2288-12-159
- ^ Браун, МВт; МакКаллум, RC; Ким, Коннектикут; Андерсен, БЛ; Глейзер, Р. (2002) «Когда индексы соответствия и остатки несовместимы». Психологические методы. 7: 403-421.
- ↑ Перейти обратно: Перейти обратно: а б Гайдук, Луизиана; Паздерка-Робинсон, Х.; Каммингс, Дж.Г.; Леверс, М.Дж. Д.; Берес, Массачусетс (2005) «Тестирование модели структурных уравнений и качество измерений активности естественных клеток-киллеров». Методология медицинских исследований BMC. 5 (1): 1-9. дои: 10.1186/1471-2288-5-1. Обратите внимание на поправку от 0,922 до 0,992 и поправку от 0,944 до 0,994 в Hayduk, et al. Таблица 1.
- ↑ Перейти обратно: Перейти обратно: а б с Гайдук, Л.А. (2014a) «Видеть идеально подходящие факторные модели, которые причинно неверно определены: понимание того, что близко подходящие модели могут быть хуже». Образовательные и психологические измерения. 74 (6): 905–926. дои: 10.1177/0013164414527449
- ↑ Перейти обратно: Перейти обратно: а б с д и ж г Барретт, П. (2007). «Моделирование структурными уравнениями: определение соответствия модели». Личность и индивидуальные различия. 42 (5): 815–824.
- ^ Саторра, А.; и Бентлер, П.М. (1994) «Поправки к статистике тестирования и стандартным ошибкам в анализе ковариационной структуры». В книге А. фон Айя и К. К. Клогга (ред.), «Анализ скрытых переменных: приложения для исследований в области развития» (стр. 399–419). Таузенд-Оукс, Калифорния: Сейдж.
- ^ Сорбом, Д. "xxxxx" в Кудеке, Р.; дю Туа Р.; Сорбом, Д. (редакторы) (2001) Моделирование структурными уравнениями: настоящее и будущее: Festschrift в честь Карла Йорескога. Scientific Software International: Линкольнвуд, Иллинойс.
- ↑ Перейти обратно: Перейти обратно: а б с д и ж г час Ху, Л.; Бентлер, П.М. (1999) «Критерии отсечения индексов соответствия в анализе ковариационной структуры: традиционные критерии и новые альтернативы». Моделирование структурными уравнениями. 6:1-55.
- ^ Кляйн 2011 , с. 205.
- ^ Кляйн 2011 , с. 206.
- ↑ Перейти обратно: Перейти обратно: а б Ху и Бентлер 1999 , с. 27.
- ^ Штайгер, Дж. Х.; и Линд Дж. (1980) «Статистические тесты на количество общих факторов». Доклад представлен на ежегодном собрании Психометрического общества в Айова-Сити.
- ^ Штайгер, Дж. Х. (1990) «Оценка и модификация структурной модели: подход к интервальной оценке». Многомерное поведенческое исследование 25:173-180.
- ^ Браун, МВт; Кудек, Р. (1992) «Альтернативные способы оценки соответствия модели». Социологические методы и исследования. 21(2): 230–258.
- ^ Хертинг, Р.Х.; Костнер, Х.Л. (2000) «Другой взгляд на «правильное количество факторов» и соответствующее количество шагов». Моделирование структурными уравнениями. 7 (1): 92-110.
- ^ Гайдук, Л. (1987) Моделирование структурных уравнений с помощью LISREL: основы и достижения, стр. 20. Балтимор, издательство Университета Джонса Хопкинса. ISBN 0-8018-3478-3 Страница 20
- ^ Гайдук, Луизиана; Каммингс, Г.; Страткоттер, Р.; Ниммо, М.; Гругорьев К.; Досман, Д.; Гиллеспи, М.; Паздерка-Робинсон, Х. (2003) «D-разделение Перла: еще один шаг к причинному мышлению». Моделирование структурными уравнениями. 10 (2): 289–311.
- ^ Гайдук, Л.А. (2006) «Блокированная ошибка-R2: концептуально улучшенное определение доли объясненной дисперсии в моделях, содержащих петли или коррелированные остатки». Качество и количество. 40: 629-649.
- ↑ Перейти обратно: Перейти обратно: а б Миллсап, Р.Э. (2007) «Моделирование структурными уравнениями затруднено». Личность и индивидуальные различия. 42: 875-881.
- ↑ Перейти обратно: Перейти обратно: а б Энтуисл, ДР; Гайдук, Луизиана; Рейли, Т.В. (1982) Раннее школьное обучение: когнитивные и аффективные результаты. Балтимор: Издательство Университета Джонса Хопкинса.
- ^ Гайдук, Луизиана (1994). «Личное пространство: понимание симплексной модели». Журнал невербального поведения., 18 (3): 245-260.
- ^ Гайдук, Луизиана; Страткоттер, Р.; Роверс, М.В. (1997) «Сексуальная ориентация и готовность студентов католической семинарии соответствовать церковным учениям». Журнал научного изучения религии. 36 (3): 455–467.
- ↑ Перейти обратно: Перейти обратно: а б Ригдон, Э.Э.; Сарстедт, М.; Рингл, М. (2017) «О сравнении результатов CB-SEM и PLS-SEM: пять точек зрения и пять рекомендаций». Маркетинг ZFP. 39 (3): 4–16. дои: 10.15358/0344-1369-2017-3-4
- ^ Гайдук, Луизиана; Каммингс, Г.; Боаду, К.; Паздерка-Робинсон, Х.; Булианна, С. (2007) «Тестирование! тестирование! раз, два, три – проверка теории на моделях структурных уравнений!» Личность и индивидуальные различия. 42 (5): 841-850
- ^ Мулайк, С.А. (2009) Основы факторного анализа (второе издание). Чепмен и Холл/CRC. Бока-Ратон, страницы 130–131.
- ^ Леви, Р.; Хэнкок, Г.Р. (2007) «Система статистических тестов для сравнения моделей средней и ковариационной структуры». Многомерное поведенческое исследование. 42(1): 33–66.
- ^ Гайдук, Луизиана (2018) «Обзорное эссе о принципах и практике моделирования структурных уравнений Рекса Б. Клайна: поддержка пятого издания». Канадские исследования в области народонаселения. 45 (3–4): 154–178. DOI 10.25336/csp29397
- ^ Марш, Герберт В.; Морен, Александр Ж.С.; Паркер, Филип Д.; Каур, Гурвиндер (28 марта 2014 г.). «Исследовательское моделирование структурными уравнениями: интеграция лучших особенностей исследовательского и подтверждающего факторного анализа» . Ежегодный обзор клинической психологии . 10 (1): 85–110. doi : 10.1146/annurev-clinpsy-032813-153700 . ISSN 1548-5943 . ПМИД 24313568 .
- ^ Гайдук, Луизиана; Эстабрукс, Калифорния; Хобен, М. (2019). «Достоверность слияния: теоретическая оценка масштаба посредством моделирования причинно-следственных структурных уравнений». Границы психологии, 10: 1139. doi: 10.3389/psyg.2019.01139.
- ^ Зифур, Майкл Дж.; Эллисон, Пол Д.; Тэй, Луи; Фелькле, Мануэль К.; Проповедник, Кристофер Дж.; Чжан, Чжэнь; Хамакер, Эллен Л.; Шамсоллахи, Али; Пьеридес, Дин К.; Коваль, Петр; Динер, Эд (октябрь 2020 г.). «От данных к причинам I: построение общей панельной модели с перекрестной задержкой (GCLM)» . Организационные методы исследования . 23 (4): 651–687. дои : 10.1177/1094428119847278 . hdl : 11343/247887 . ISSN 1094-4281 . S2CID 181878548 .
- ^ Лейтгоб, Хайнц; Седдиг, Дэниел; Аспарухов, Тихомир; Бер, Дороти; Давыдов, Эльдад; Де Рувер, Ким; Джек, Сюзанна; Мейтингер, Катарина; Менольд, Наталья; Мутен, Бенгт; Руднев Максим; Шмидт, Питер; ван де Шут, Ренс (февраль 2023 г.). «Инвариантность измерений в социальных науках: историческое развитие, методологические проблемы, современное состояние и перспективы на будущее» . Социально-научные исследования . 110 : 102805. doi : 10.1016/j.ssresearch.2022.102805 . hdl : 1874/431763 . ПМИД 36796989 . S2CID 253343751 .
- ^ Садикадж, Джентьяна; Райт, Эйдан Г.К.; Данкли, Дэвид М.; Зурофф, Дэвид С.; Московиц, Д.С. (2021), «Моделирование многоуровневыми структурными уравнениями для интенсивных продольных данных: практическое руководство для исследователей личности» , Справочник по динамике и процессам личности , Elsevier, стр. 855–885, doi : 10.1016/b978-0-12 -813995-0.00033-9 , ISBN 978-0-12-813995-0 , получено 3 ноября 2023 г.
- ^ Нарайанан, А. (1 мая 2012 г.). «Обзор восьми пакетов программного обеспечения для моделирования структурными уравнениями» . Американский статистик . 66 (2): 129–138. дои : 10.1080/00031305.2012.708641 . ISSN 0003-1305 . S2CID 59460771 .
Библиография [ править ]
- Ху, Ли-цзы; Бентлер, Питер М. (1999). «Критерии отсечения индексов соответствия в анализе ковариационной структуры: традиционные критерии и новые альтернативы». Моделирование структурными уравнениями . 6 :1–55. дои : 10.1080/10705519909540118 . hdl : 2027.42/139911 .
- Каплан, Д. (2008). Моделирование структурными уравнениями: основы и расширения (2-е изд.). МУДРЕЦ. ISBN 978-1412916240 .
- Клайн, Рекс (2011). Принципы и практика моделирования структурными уравнениями (Третье изд.). Гилфорд. ISBN 978-1-60623-876-9 .
- МакКаллум, Роберт; Остин, Джеймс (2000). «Применение моделирования структурными уравнениями в психологических исследованиях» (PDF) . Ежегодный обзор психологии . 51 : 201–226. дои : 10.1146/annurev.psych.51.1.201 . ПМИД 10751970 . Архивировано из оригинала (PDF) 28 января 2015 года . Проверено 25 января 2015 г.
- Кинтана, Стивен М.; Максвелл, Скотт Э. (1999). «Последствия последних разработок в моделировании структурными уравнениями для консультативной психологии». Консультирующий психолог . 27 (4): 485–527. дои : 10.1177/0011000099274002 . S2CID 145586057 .
Дальнейшее чтение [ править ]
- Багоцци, Ричард П.; Йи, Юдже (2011). «Спецификация, оценка и интерпретация моделей структурных уравнений». Журнал Академии маркетинговых наук . 40 (1): 8–34. дои : 10.1007/s11747-011-0278-x . S2CID 167896719 .
- Бартоломью Д.Д. и Нотт М. (1999) Модели со скрытыми переменными и факторный анализ. Статистическая библиотека Кендалла, том. 7, Издательство Эдварда Арнольда , ISBN 0-340-69243-X
- Бентлер, П.М. и Бонетт, Д.Г. (1980), «Тестирование значимости и степень соответствия при анализе ковариационных структур», Psychoological Bulletin , 88, 588–606.
- Боллен, К.А. (1989). Структурные уравнения со скрытыми переменными . Уайли, ISBN 0-471-01171-1
- Бирн, Б.М. (2001) Моделирование структурными уравнениями с помощью AMOS - основные концепции, приложения и программирование . LEA, ISBN 0-8058-4104-0
- Гольдбергер, А.С. (1972). Модели структурных уравнений в социальных науках . Эконометрика 40, 979–1001.
- Хаавельмо, Трюгве (январь 1943 г.). «Статистические последствия системы одновременных уравнений». Эконометрика . 11 (1): 1–12. дои : 10.2307/1905714 . JSTOR 1905714 .
- Хойл, Р.Х. (редактор) (1995) Моделирование структурными уравнениями: концепции, проблемы и приложения . МУДРЕЦ, ISBN 0-8039-5318-6
- Йорескуг, Карл Г .; Ян, Фань (1996). «Модели нелинейных структурных уравнений: модель Кенни-Джадда с эффектами взаимодействия» . В Маркулидесе, Джордж А.; Шумакер, Рэндалл Э. (ред.). Расширенное моделирование структурными уравнениями: концепции, проблемы и приложения . Таузенд-Оукс, Калифорния: Публикации Sage. стр. 57–88. ISBN 978-1-317-84380-1 .
- Льюис-Бек, Майкл; Брайман, Алан Э.; Брайман, заслуженный профессор Алан; Ляо, Тим Футинг (2004). «Моделирование структурными уравнениями». Энциклопедия методов исследования социальных наук SAGE . дои : 10.4135/9781412950589.n979 . HDL : 2022/21973 . ISBN 978-0-7619-2363-3 .
- Шермелле-Энгель, К.; Моосбругер, Х.; Мюллер, Х. (2003), «Оценка соответствия моделей структурных уравнений» (PDF) , Методы психологических исследований , 8 (2): 23–74 .
Внешние ссылки [ править ]
- Страница моделирования структурных уравнений в StatNotes Дэвида Гарсона, NCSU
- Проблемы и мнения о моделировании структурными уравнениями , SEM в исследованиях информационной безопасности
- Причинная интерпретация структурных уравнений (или набора выживания SEM) Джуди Перл, 2000.
- Справочный список Джейсона Ньюсома по моделированию структурных уравнений : журнальные статьи и главы книг, посвященные моделям структурных уравнений
- Справочник по шкалам управления , сборник ранее использовавшихся многопунктовых шкал для измерения конструкций для SEM.
| |||||||||||||||||||||||||||
| Базы данных органов управления : Национальные |
|---|