Линейная регрессия была первым типом регрессионного анализа, который тщательно изучался и широко использовался в практических приложениях. [4] Это связано с тем, что модели, которые линейно зависят от неизвестных параметров, легче подобрать, чем модели, которые нелинейно связаны с их параметрами, и потому, что статистические свойства полученных оценок легче определить.
Линейная регрессия имеет множество практических применений. Большинство приложений попадают в одну из следующих двух широких категорий:
Если целью является ошибка, т. е. уменьшение дисперсии в прогнозировании или прогнозировании , можно использовать линейную регрессию, чтобы подогнать прогностическую модель к наблюдаемому набору данных значений отклика и объясняющих переменных. Если после разработки такой модели собираются дополнительные значения объясняющих переменных без сопровождающего значения ответа, подобранную модель можно использовать для прогнозирования ответа.
Если цель состоит в том, чтобы объяснить изменение переменной отклика, которое можно отнести к вариациям объясняющих переменных, можно применить линейный регрессионный анализ для количественной оценки силы связи между ответом и объясняющими переменными и, в частности, для определения того, являются ли некоторые объясняющие переменные могут вообще не иметь линейной связи с ответом или определить, какие подмножества объясняющих переменных могут содержать избыточную информацию об ответе.
Модели линейной регрессии часто подбираются с использованием метода наименьших квадратов , но их также можно подбирать и другими способами, например, путем минимизации « несоответствия » какой-либо другой норме (как в случае с регрессией наименьших абсолютных отклонений ) или путем минимизации штрафного наименьших квадратов, версия функции стоимости как в гребневой регрессии ( L 2 -норма штрафа) и аркан ( L 1 -норма штрафа). Использование среднеквадратической ошибки (MSE) в качестве стоимости набора данных, который имеет много крупных выбросов, может привести к тому, что модель будет соответствовать выбросам больше, чем истинным данным, из-за более высокой важности, придаваемой MSE большим ошибкам. следует использовать функции стоимости, устойчивые к выбросам Таким образом, если в наборе данных много крупных выбросов, . И наоборот, метод наименьших квадратов можно использовать для подбора моделей, которые не являются линейными моделями. Таким образом, хотя термины «наименьшие квадраты» и «линейная модель» тесно связаны, они не являются синонимами.
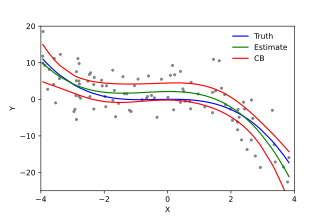
В линейной регрессии предполагается, что наблюдения ( красный ) являются результатом случайных отклонений ( зеленый ) от базовой взаимосвязи ( синий ) между зависимой переменной ( y ) и независимой переменной ( x ).
Учитывая данных набор Для n статистических единиц модель линейной регрессии предполагает, что связь между зависимой переменной y и вектором регрессоров x является линейной . Эта связь моделируется с помощью члена возмущения или переменной ошибки ε — ненаблюдаемой случайной величины , которая добавляет «шум» к линейной зависимости между зависимой переменной и регрессорами. Таким образом, модель принимает вид
представляет собой вектор наблюдаемых значений переменной, называемой регрессией , эндогенной переменной , переменной отклика , целевой переменной , измеряемой переменной , критериальной переменной или зависимой переменной . Эту переменную также иногда называют прогнозируемой переменной , но ее не следует путать с прогнозируемыми значениями , которые обозначаются . Решение о том, какая переменная в наборе данных моделируется как зависимая переменная, а какая — как независимые переменные, может быть основано на предположении, что значение одной из переменных обусловлено другими переменными или напрямую зависит от них. Альтернативно, может существовать оперативная причина моделировать одну из переменных с точки зрения других, и в этом случае не требуется презумпции причинно-следственной связи.
Обычно константа включается в качестве одного из регрессоров. В частности, для . Соответствующий элемент β называется перехватом . Многие процедуры статистического вывода для линейных моделей требуют присутствия точки пересечения, поэтому ее часто включают, даже если теоретические соображения предполагают, что ее значение должно быть равно нулю.
Иногда один из регрессоров может быть нелинейной функцией другого регрессора или значений данных, как в полиномиальной регрессии и сегментированной регрессии . Модель остается линейной до тех пор, пока она линейна по вектору параметров β .
Значения x ij можно рассматривать либо как наблюдаемые значения случайных величин X j , либо как фиксированные значения, выбранные до наблюдения зависимой переменной. Обе интерпретации могут быть уместны в разных случаях и обычно приводят к одним и тем же процедурам оценки; однако в этих двух ситуациях используются разные подходы к асимптотическому анализу.
это -мерный вектор параметров , где — это член пересечения (если он включен в модель, в противном случае является p -мерным). Его элементы известны как эффекты или коэффициенты регрессии (хотя последний термин иногда используется для оценки эффектов). В простой линейной регрессии p = 1, а коэффициент известен как наклон регрессии . Статистическая оценка и вывод в линейной регрессии фокусируются на β . Элементы этого вектора параметров интерпретируются как частные производные зависимой переменной по отношению к различным независимым переменным.
это вектор значений . Эта часть модели называется членом ошибки , членом возмущения или иногда шумом (в отличие от «сигнала», обеспечиваемого остальной частью модели). Эта переменная учитывает все другие факторы, которые влияют на зависимую переменную y, кроме регрессоров x . Взаимосвязь между членом ошибки и регрессорами, например, их корреляция , является решающим фактором при формулировании модели линейной регрессии, поскольку она определяет соответствующий метод оценки.
Подбор линейной модели к заданному набору данных обычно требует оценки коэффициентов регрессии. такой, что член ошибки сведен к минимуму. Например, обычно используют сумму квадратов ошибок. как мера для минимизации.
когда небольшой шарик подбрасывают в воздух, а затем мы измеряем высоту его подъема hi Рассмотрим ситуацию , в различные моменты времени t i . Физика говорит нам, что, игнорируя сопротивление, эту взаимосвязь можно смоделировать как
где β 1 определяет начальную скорость мяча, β 2 пропорциональна стандартной силе тяжести , а ε i обусловлена ошибками измерения. Линейную регрессию можно использовать для оценки значений β 1 и β 2 на основе измеренных данных. Эта модель нелинейна по временной переменной, но линейна по параметрам β 1 и β 2 ; если мы возьмем регрессоры x i = ( x i 1 , x i 2 ) = ( t i , t i 2 ), модель принимает стандартный вид
Стандартные модели линейной регрессии со стандартными методами оценки делают ряд предположений о переменных-предикторах, переменных ответа и их взаимосвязи. Были разработаны многочисленные расширения, которые позволяют ослабить каждое из этих предположений (т.е. привести к более слабой форме), а в некоторых случаях полностью исключить их. Как правило, эти расширения делают процедуру оценки более сложной и трудоемкой, а также могут потребовать больше данных для создания столь же точной модели. [ нужна ссылка ]
Пример кубической полиномиальной регрессии, которая является разновидностью линейной регрессии. Хотя полиномиальная регрессия соответствует данным нелинейной модели, как задача статистической оценки она является линейной в том смысле, что функция регрессии E( y | x ) линейна относительно неизвестных параметров , которые оцениваются на основе данных . По этой причине полиномиальная регрессия считается частным случаем множественной линейной регрессии .
Ниже приведены основные допущения, сделанные с помощью стандартных моделей линейной регрессии со стандартными методами оценки (например, методом наименьших квадратов ):
Слабая экзогенность . По сути, это означает, что переменные-предикторы x можно рассматривать как фиксированные значения, а не как случайные переменные . Это означает, например, что переменные-предикторы считаются безошибочными, то есть не содержат ошибок измерений. Хотя это предположение нереалистично во многих случаях, отказ от него приводит к значительно более сложным моделям ошибок в переменных .
Линейность . Это означает, что среднее значение переменной ответа представляет собой линейную комбинацию параметров (коэффициентов регрессии) и переменных-предикторов. Обратите внимание, что это предположение гораздо менее ограничительно, чем может показаться на первый взгляд. Поскольку переменные-предикторы рассматриваются как фиксированные значения (см. выше), линейность на самом деле является лишь ограничением параметров. Сами переменные-предикторы могут быть преобразованы произвольно, и фактически можно добавить несколько копий одной и той же базовой переменной-предиктора, каждая из которых преобразуется по-разному. Этот метод используется, например, в полиномиальной регрессии , которая использует линейную регрессию для соответствия переменной ответа произвольной полиномиальной функции (до заданной степени) переменной-предиктора. Обладая такой большой гибкостью, такие модели, как полиномиальная регрессия, часто обладают «слишком большой мощностью», поскольку они имеют тенденцию переоценивать данные. В результате обычно необходимо использовать некоторую регуляризацию , чтобы предотвратить появление необоснованных решений в процессе оценки. Распространенными примерами являются гребневая регрессия и лассо-регрессия . Также можно использовать байесовскую линейную регрессию , которая по своей природе более или менее невосприимчива к проблеме переобучения. (Фактически, гребневую регрессию и лассо-регрессию можно рассматривать как частные случаи байесовской линейной регрессии с определенными типами априорных распределений , помещенными в коэффициенты регрессии.)
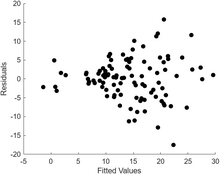
Визуализация гетероскедастичности на диаграмме рассеяния по 100 случайным подобранным значениям с использованием Matlab Постоянная дисперсия (она же гомоскедастичность ). Это означает, что дисперсия ошибок не зависит от значений переменных-предикторов. Таким образом, изменчивость ответов для заданных фиксированных значений предикторов одинакова независимо от того, насколько велики или малы ответы. Зачастую это не так, поскольку переменная с большим средним значением обычно будет иметь большую дисперсию, чем переменная с малым средним значением. Например, человек, чей прогнозируемый доход составит 100 000 долларов, может легко иметь фактический доход в 80 000 или 120 000 долларов, то есть стандартное отклонение около 20 000 долларов, в то время как другой человек с прогнозируемым доходом в 10 000 долларов вряд ли будет иметь такое же стандартное отклонение в 20 000 долларов. , поскольку это будет означать, что их фактический доход может варьироваться от −10 000 до 30 000 долларов. (Фактически, как это показывает, во многих случаях — часто в тех же случаях, когда предположение о нормально распределенных ошибках терпит неудачу — дисперсию или стандартное отклонение следует прогнозировать как пропорциональную среднему значению, а не константу.) Отсутствие гомоскедастичности является следствием отсутствия гомоскедастичности. называется гетероскедастичность . Чтобы проверить это предположение, график остатков в сравнении с прогнозируемыми значениями (или значениями каждого отдельного предиктора) можно проверить на предмет «эффекта веера» (т. е. увеличения или уменьшения вертикального разброса при движении слева направо на графике). . График абсолютных или квадратичных остатков в сравнении с прогнозируемыми значениями (или каждым предиктором) также можно проверить на наличие тенденции или кривизны. Также можно использовать формальные тесты; см . Гетероскедастичность . Наличие гетероскедастичности приведет к использованию общей «средней» оценки дисперсии вместо той, которая учитывает истинную структуру дисперсии. Это приводит к менее точным (но в случае обычного метода наименьших квадратов , не смещенным) оценкам параметров и смещенным стандартным ошибкам, что приводит к вводящим в заблуждение тестам и интервальным оценкам. Среднеквадратическая ошибка модели также будет неверной. Различные методы оценки, включая взвешенные методы наименьших квадратов и использование стандартных ошибок, совместимых с гетероскедастичностью. может справиться с гетероскедастичностью довольно общим способом. Методы байесовской линейной регрессии также можно использовать, когда предполагается, что дисперсия является функцией среднего значения. В некоторых случаях также возможно решить проблему, применив преобразование к переменной отклика (например, подбирая логарифм переменной отклика с помощью модели линейной регрессии, которая подразумевает, что сама переменная отклика имеет логарифмически нормальное распределение, а не логарифмическое) . нормальное распределение ).
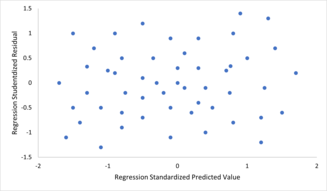
Чтобы проверить наличие нарушений предположений о линейности, постоянной дисперсии и независимости ошибок в модели линейной регрессии, остатки обычно строятся в зависимости от прогнозируемых значений (или каждого из отдельных предикторов). На первый взгляд случайный разброс точек вокруг горизонтальной средней линии в точке 0 является идеальным, но не может исключить определенные виды нарушений, такие как автокорреляция ошибок или их корреляция с одной или несколькими ковариатами.
Независимость ошибок . Это предполагает, что ошибки переменных ответа не коррелируют друг с другом. (Фактическая статистическая независимость является более сильным условием, чем простое отсутствие корреляции, и часто в ней нет необходимости, хотя ее можно использовать, если известно, что она выполняется.) Некоторые методы, такие как обобщенный метод наименьших квадратов, способны обрабатывать коррелированные ошибки, хотя обычно они требуют значительно больше данных, если только не используется какая-то регуляризация , чтобы сместить модель в сторону допущения некоррелированных ошибок. Байесова линейная регрессия — общий способ решения этой проблемы.
Отсутствие идеальной мультиколлинеарности у предикторов. Для стандартных методов оценки методом наименьших квадратов матрица плана X должна иметь полный ранг столбца p ; в противном случае в переменных-предикторах существует идеальная мультиколлинеарность , что означает, что между двумя или более переменными-предикторами существует линейная связь. Это может быть вызвано случайным дублированием переменной в данных, использованием линейного преобразования переменной вместе с оригиналом (например, тех же измерений температуры, выраженными в градусах Фаренгейта и Цельсия) или включением в модель линейной комбинации нескольких переменных. например, их среднее значение. Это также может произойти, если доступных данных слишком мало по сравнению с количеством оцениваемых параметров (например, меньше точек данных, чем коэффициентов регрессии). Близкие нарушения этого предположения, когда предикторы сильно, но не идеально, коррелируют, могут снизить точность оценок параметров (см. Фактор инфляции дисперсии ). В случае совершенной мультиколлинеарности вектор параметров β будет неидентифицируемой — она не имеет единственного решения. В таком случае можно идентифицировать только некоторые параметры (т. е. их значения можно оценить только в пределах некоторого линейного подпространства полного пространства параметров R). п ). См. частичную регрессию наименьших квадратов . Разработаны методы аппроксимации линейных моделей с мультиколлинеарностью. [5] [6] [7] [8] некоторые из них требуют дополнительных предположений, таких как «разреженность эффектов» - что большая часть эффектов равна нулю. Обратите внимание, что более затратные в вычислительном отношении итерационные алгоритмы оценки параметров, например те, которые используются в обобщенных линейных моделях , не страдают от этой проблемы.
Допущение о нулевом среднем значении остатков . В регрессионном анализе еще одним важным допущением является то, что среднее значение остатков равно нулю или близко к нулю. Это предположение имеет основополагающее значение для обоснованности любых выводов, сделанных на основе оценок параметров методом наименьших квадратов. Остатки — это различия между наблюдаемыми значениями и значениями, предсказанными моделью. Если среднее значение этих остатков не равно нулю, это означает, что модель последовательно переоценивает или занижает наблюдаемые значения, что указывает на потенциальное смещение в оценке модели. Обеспечение того, что среднее значение остатков равно нулю, позволяет считать модель несмещенной с точки зрения ее ошибки, что имеет решающее значение для точной интерпретации коэффициентов регрессии.
Нарушение этих предположений может привести к смещенным оценкам β , смещенным стандартным ошибкам, ненадежным доверительным интервалам и тестам значимости. [9] Помимо этих предположений, на эффективность различных методов оценки сильно влияют несколько других статистических свойств данных:
Статистическая связь между членами ошибок и регрессорами играет важную роль в определении того, обладает ли процедура оценки желаемыми свойствами выборки, такими как несмещенность и последовательность.
Расположение или распределение вероятностей переменных-предсказателей x оказывает большое влияние на точность оценок β . Выборка и планирование экспериментов являются высокоразвитыми разделами статистики, которые обеспечивают руководство по сбору данных таким образом, чтобы получить точную оценку β .
Наборы данных в квартете Анскомба имеют примерно одну и ту же линию линейной регрессии (а также почти идентичные средние значения, стандартные отклонения и корреляции), но графически сильно различаются. Это иллюстрирует подводные камни, связанные с использованием только подобранной модели для понимания взаимосвязи между переменными.
Подобранная модель линейной регрессии может использоваться для определения взаимосвязи между одной переменной-предиктором x j и переменной отклика y, когда все остальные переменные-предикторы в модели «удерживаются фиксированными». В частности, интерпретация β j — это ожидаемое изменение y на одну единицу для изменения x j когда другие ковариаты остаются фиксированными, то есть ожидаемое значение частной производной y , по отношению к x j . называют уникальным эффектом xj это y на Иногда . Напротив, предельное влияние xj связывающей можно на y оценить с помощью корреляции или простой модели линейной регрессии, только xj коэффициента с y ; эффект является полной производной y j по x этот .
Необходимо соблюдать осторожность при интерпретации результатов регрессии, поскольку некоторые регрессоры могут не допускать незначительных изменений (например, фиктивные переменные или член-перехват), в то время как другие не могут быть фиксированными (вспомните пример из введения: было бы невозможно «удерживать t i фиксированным» и в то же время изменять значение t i 2 ).
Вполне возможно, что уникальный эффект может быть почти нулевым, даже если предельный эффект велик. Это может означать, что какая-то другая ковариата фиксирует всю информацию в x j , так что, как только эта переменная появится в модели, x j не будет вносить вклад в изменение y . И наоборот, уникальный эффект x j может быть большим, в то время как его предельный эффект почти равен нулю. Это произошло бы, если бы другие ковариаты объясняли большую часть вариаций y они объясняют вариацию способом, дополняющим то, что отражается xj , но в основном . В этом случае включение других переменных в модель уменьшает ту часть изменчивости y , которая не связана с x j , тем самым усиливая очевидную связь с x j .
Значение выражения «удерживается фиксированным» может зависеть от того, как возникают значения переменных-предсказателей. Если экспериментатор непосредственно устанавливает значения переменных-предикторов в соответствии с планом исследования, интересующие сравнения могут буквально соответствовать сравнениям между единицами, переменные-предикторы которых были «фиксированы» экспериментатором. Альтернативно, выражение «удерживается фиксированным» может относиться к выбору, который происходит в контексте анализа данных. В этом случае мы «фиксируем переменную», ограничивая наше внимание подмножествами данных, которые имеют общее значение для данной переменной-предиктора. Это единственная интерпретация термина «фиксированный», которую можно использовать в обсервационном исследовании.
Идея «уникального эффекта» привлекательна при изучении сложной системы, в которой множество взаимосвязанных компонентов влияют на переменную отклика. В некоторых случаях его можно буквально интерпретировать как причинный эффект вмешательства, связанного со значением предикторной переменной. Однако утверждалось, что во многих случаях множественный регрессионный анализ не может прояснить взаимосвязь между переменными-предикторами и переменной ответа, когда предикторы коррелируют друг с другом и не назначаются в соответствии с дизайном исследования. [10]
Были разработаны многочисленные расширения линейной регрессии, которые позволяют ослабить некоторые или все предположения, лежащие в основе базовой модели.
Самый простой случай одной скалярной переменной-предиктора x и одной скалярной переменной отклика y известен как простая линейная регрессия . Расширение множественных и/или векторных переменных-предикторов (обозначаемых заглавной буквой X ) известно как множественная линейная регрессия , также известная как многомерная линейная регрессия (не путать с многомерной линейной регрессией). [11] ).
Множественная линейная регрессия — это обобщение простой линейной регрессии на случай более чем одной независимой переменной и частный случай общих линейных моделей, ограниченных одной зависимой переменной. Базовая модель множественной линейной регрессии:
за каждое наблюдение .
В приведенной выше формуле мы рассматриваем n наблюдений одной зависимой переменной и p независимых переменных. Таким образом, Y i - это i й наблюдение зависимой переменной, X ij - это i й наблюдение за j й независимая переменная, j = 1, 2, ..., p . Значения β j представляют параметры, подлежащие оценке, а ε i — это i й независимая одинаково распределенная нормальная ошибка.
В более общей многомерной линейной регрессии существует одно уравнение приведенной выше формы для каждой из m > 1 зависимых переменных, которые имеют один и тот же набор объясняющих переменных и, следовательно, оцениваются одновременно друг с другом:
для всех наблюдений, индексированных как i = 1,..., n , и для всех зависимых переменных, индексированных как j = 1,..., m .
Почти все реальные модели регрессии включают в себя множественные предикторы, и базовые описания линейной регрессии часто формулируются в терминах модели множественной регрессии. Однако обратите внимание, что в этих случаях переменная ответа y по-прежнему является скаляром. Другой термин, многомерная линейная регрессия , относится к случаям, когда y является вектором, то есть то же самое, что и общая линейная регрессия .
Общая линейная модель рассматривает ситуацию, когда переменная отклика является не скаляром (для каждого наблюдения), а вектором y i . Условная линейность по-прежнему предполагается, при этом матрица B заменяет вектор β классической модели линейной регрессии. многомерные аналоги обычного метода наименьших квадратов (OLS) и обобщенного метода наименьших квадратов Разработаны (GLS). «Общие линейные модели» также называют «многомерными линейными моделями». Это не то же самое, что многомерные линейные модели (также называемые «множественными линейными моделями»).
Обобщенные линейные модели (GLM) представляют собой основу для моделирования ограниченных или дискретных переменных отклика. Это используется, например:
при моделировании положительных величин (например, цен или численности населения), которые изменяются в большом масштабе, которые лучше описываются с помощью асимметричного распределения, такого как логарифмически нормальное распределение или распределение Пуассона (хотя GLM не используются для логарифмически нормальных данных, вместо этого используется ответ переменная просто преобразуется с помощью функции логарифма);
при моделировании порядковых данных , например, рейтингов по шкале от 0 до 5, где различные результаты могут быть упорядочены, но сама величина может не иметь абсолютного значения (например, рейтинг 4 не может быть «вдвое лучше» для какой-либо цели) означает оценку 2, а просто указывает на то, что она лучше, чем 2 или 3, но не так хороша, как 5).
Обобщенные линейные модели допускают произвольную связи функцию g , которая связывает среднее значение переменной (переменных) ответа с предикторами: . Функция связи часто связана с распределением ответа и, в частности, обычно имеет эффект преобразования между диапазон линейного предиктора и диапазон переменной отклика.
Модели с одним индексом [ нужны разъяснения ] допускают некоторую степень нелинейности во взаимосвязи между x и y , сохраняя при этом центральную роль линейного предиктора β ′ x, как в классической модели линейной регрессии. При определенных условиях простое применение МНК к данным одноиндексной модели позволит последовательно оценить β с точностью до константы пропорциональности. [12]
Иерархические линейные модели (или многоуровневая регрессия ) организуют данные в иерархию регрессий, например, где регрессируется на B , а B регрессируется на C. A Он часто используется там, где интересующие переменные имеют естественную иерархическую структуру, например, в статистике образования, где учащиеся вложены в классы, классы вложены в школы, а школы вложены в некоторую административную группу, например, в школьный округ. Переменная ответа может служить показателем успеваемости учащихся, например, результатом теста, а различные ковариаты будут собираться на уровне класса, школы и школьного округа.
Модели ошибок в переменных (или «модели ошибок измерения») расширяют традиционную модель линейной регрессии, позволяя переменные-предикторы X наблюдать с ошибкой. Эта ошибка приводит к тому, что стандартные оценки β становятся смещенными. Как правило, формой смещения является затухание, что означает, что эффекты смещаются к нулю.
параметр переменной-предиктора представляет собой индивидуальный эффект . Он интерпретируется как ожидаемое изменение переменной отклика. когда увеличивается на одну единицу, при этом другие переменные-предикторы остаются постоянными. Когда сильно коррелирует с другими переменными-предикторами, маловероятно, что может увеличиться на одну единицу при неизменных других переменных. В этом случае интерпретация становится проблематичным, поскольку оно основано на маловероятном условии, а эффект невозможно оценить изолированно.
Для группы переменных-предикторов, скажем, , групповой эффект определяется как линейная комбинация их параметров
где является весовым вектором, удовлетворяющим . Из-за ограничения на , также называется нормализованным групповым эффектом. Групповой эффект интерпретируется как ожидаемое изменение когда переменные в группе изменить на сумму соответственно, в то же время с переменными, не входящими в группу, оставались постоянными. Он обобщает индивидуальный эффект переменной на группу переменных в том смысле, что ( ) если , то групповой эффект сводится к индивидуальному эффекту, и ( ) если и для , то групповой эффект также сводится к индивидуальному эффекту.Групповой эффект считается значимым, если лежащие в его основе одновременные изменения переменные вероятно.
Групповые эффекты предоставляют средства для изучения коллективного влияния сильно коррелированных переменных-предикторов в моделях линейной регрессии. Индивидуальные эффекты таких переменных не определены четко, поскольку их параметры не имеют хорошей интерпретации. Более того, когда размер выборки невелик, ни один из ее параметров не может быть точно оценен с помощью регрессии наименьших квадратов из-за проблемы мультиколлинеарности . Тем не менее, существуют значимые групповые эффекты, которые хорошо интерпретируются и могут быть точно оценены с помощью регрессии наименьших квадратов. Простой способ выявить эти значимые групповые эффекты — использовать схему всех положительных корреляций (APC) сильно коррелирующих переменных, при которой все парные корреляции между этими переменными положительны, и стандартизировать все переменные-предикторы в модели так, чтобы все они имели нулевое среднее значение и длину один. Чтобы проиллюстрировать это, предположим, что представляет собой группу сильно коррелированных переменных в схеме APC и что они не сильно коррелируют с переменными-предикторами вне группы. Позволять быть центрированным и быть стандартизированным . Тогда стандартизованная модель линейной регрессии имеет вид
Параметры в исходной модели, включая , являются простыми функциями в стандартизированной модели. Стандартизация переменных не меняет их корреляций, поэтому представляет собой группу сильно коррелированных переменных в схеме APC, и они не сильно коррелируют с другими переменными-предикторами в стандартизированной модели. Групповой эффект является
и его несмещенная линейная оценка с минимальной дисперсией равна
где является оценкой методом наименьших квадратов . В частности, средний групповой эффект стандартизированные переменные
которое интерпретируется как ожидаемое изменение когда все в сильно коррелированной группе увеличивается на единицы в то же время, когда переменные вне группы остаются постоянными. При сильных положительных корреляциях и в стандартизированных единицах переменные в группе примерно равны, поэтому они, скорее всего, будут увеличиваться одновременно и в одинаковой величине. Таким образом, средний групповой эффект это значимый эффект. Его можно точно оценить с помощью несмещенной линейной оценки с минимальной дисперсией. , даже если по отдельности ни один из можно точно оценить по .
Не все групповые эффекты значимы и не могут быть точно оценены. Например, это специальный групповой эффект с весами и для , но его нельзя точно оценить с помощью . Это также не имеет значимого эффекта. В целом для группы сильно коррелированные переменные-предикторы в схеме APC в стандартизированной модели, групповые эффекты, весовые векторы которых находятся в центре симплекса или рядом с ним ( ) имеют смысл и могут быть точно оценены с помощью несмещенных линейных оценок с минимальной дисперсией. Эффекты с весовыми векторами, расположенными далеко от центра, не имеют смысла, поскольку такие весовые векторы представляют собой одновременные изменения переменных, которые нарушают сильные положительные корреляции стандартизированных переменных в схеме APC. Как таковые они маловероятны. Эти эффекты также не могут быть точно оценены.
Применение групповых эффектов включает (1) оценку и вывод о значимых групповых эффектах на переменную ответа, (2) проверку «групповой значимости» переменные посредством тестирования против и (3) характеризуют область пространства переменных предиктора, в которой прогнозы по модели наименьших квадратов являются точными.
Групповой эффект исходных переменных может быть выражен как константа, умноженная на групповой эффект стандартизированных переменных . Первое имеет смысл, когда второе. Таким образом, значимые групповые эффекты исходных переменных можно найти через значимые групповые эффекты стандартизированных переменных. [13]
В теории Демпстера-Шейфера или, в частности, в линейной функции доверия , модель линейной регрессии может быть представлена как частично скользящая матрица, которую можно комбинировать с аналогичными матрицами, представляющими наблюдения и другие предполагаемые нормальные распределения и уравнения состояния. Комбинация матриц с качающейся и несверткой обеспечивает альтернативный метод оценки моделей линейной регрессии.
Было разработано большое количество процедур для оценки параметров и вывода в линейной регрессии. Эти методы отличаются вычислительной простотой алгоритмов, наличием решения в замкнутой форме, устойчивостью к распределениям с тяжелым хвостом и теоретическими предположениями, необходимыми для проверки желаемых статистических свойств, таких как согласованность и асимптотическая эффективность .
Некоторые из наиболее распространенных методов оценки линейной регрессии кратко изложены ниже.
Оценка методом наименьших квадратов и связанные ней с методы
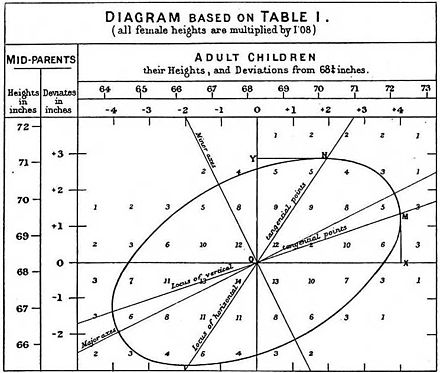
Фрэнсис Гальтон, 1886 год. [14] иллюстрация корреляции между ростом взрослых и их родителей. Наблюдение за тем, что рост взрослых детей имеет тенденцию меньше отклоняться от среднего роста, чем у их родителей, натолкнуло на мысль о концепции « регрессии к среднему значению », давшей регрессии свое название. «Место горизонтальных касательных точек», проходящее через крайнюю левую и крайнюю правую точки эллипса (который представляет собой кривую уровня двумерного нормального распределения, оцененного на основе данных), представляет собой оценку МНК регрессии роста родителей на рост детей, в то время как «место вертикальных касательных точек» - это оценка OLS регрессии роста детей от роста родителей. Большая ось эллипса — это оценка TLS .
Предполагая, что независимая переменная равна и параметры модели , то предсказание модели будет
.
Если распространяется на затем станет скалярным произведением параметра и независимой переменной, т.е.
.
В методе наименьших квадратов оптимальный параметр определяется как такой, который минимизирует сумму среднеквадратичных потерь:
Теперь помещаем независимые и зависимые переменные в матрицы и соответственно, функцию потерь можно переписать как:
Поскольку потери выпуклые, оптимальное решение находится при нулевом градиенте. Градиент функции потерь (с использованием соглашения о расположении знаменателя ):
Установка градиента на ноль дает оптимальный параметр:
Примечание. Чтобы доказать, что полученное значение действительно является локальным минимумом, нужно еще раз дифференцировать, чтобы получить матрицу Гессе и показать, что она положительно определена. Это обеспечивает теорема Гаусса–Маркова .
Линейные методы наименьших квадратов включают в себя в основном:
Оценка максимального правдоподобия и связанные методы с ней
Оценка максимального правдоподобия может быть выполнена, когда известно, что распределение членов ошибок принадлежит определенному параметрическому семейству ƒ θ вероятностей распределений . [16] Когда f θ является нормальным распределением с нулевым средним значением и дисперсией θ, результирующая оценка идентична оценке МНК. Оценки GLS представляют собой оценки максимального правдоподобия, когда ε соответствует многомерному нормальному распределению с известной ковариационной матрицей .
Адаптивная оценка . Если предположить, что члены ошибок не зависят от регрессоров, , то оптимальной оценкой является двухэтапный MLE, где первый шаг используется для непараметрической оценки распределения ошибки. [21]
Квантильная регрессия фокусируется на условных квантилях y с учетом X, не на условном среднем y с учетом X. а Линейная квантильная регрессия моделирует конкретный условный квантиль, например условную медиану, как линейную функцию β. Т x предикторов.
Смешанные модели широко используются для анализа отношений линейной регрессии с участием зависимых данных, когда зависимости имеют известную структуру. Общие применения смешанных моделей включают анализ данных, включающих повторные измерения, таких как продольные данные или данные, полученные в результате кластерной выборки. Обычно они подходят как параметрические модели, использующие максимальное правдоподобие или байесовскую оценку. В случае, когда ошибки моделируются как обычные случайные величины, существует тесная связь между смешанными моделями и обобщенным методом наименьших квадратов. [22] Оценка фиксированных эффектов — альтернативный подход к анализу данных этого типа.
Регрессия главных компонентов (ПЦР) [7] [8] используется, когда количество переменных-предикторов велико или когда между переменными-предикторами существуют сильные корреляции. Эта двухэтапная процедура сначала уменьшает переменные-предикторы с помощью анализа главных компонентов , а затем использует уменьшенные переменные при подборе регрессии OLS. Хотя на практике это часто хорошо работает, не существует общей теоретической причины, по которой наиболее информативная линейная функция переменных-предикторов должна лежать среди доминирующих главных компонентов многомерного распределения переменных-предикторов. Частичная регрессия наименьших квадратов является расширением метода ПЦР, лишенным указанного недостатка.
Регрессия по наименьшему углу [6] — это процедура оценки моделей линейной регрессии, которая была разработана для обработки многомерных векторов ковариат, потенциально с большим количеством ковариат, чем наблюдений.
Оценщик Тейла -Сена представляет собой простой метод надежной оценки , который выбирает наклон аппроксимационной линии в качестве медианы наклонов линий, проходящих через пары точек выборки. Он имеет те же свойства статистической эффективности, что и простая линейная регрессия, но гораздо менее чувствителен к выбросам . [23]
другие надежные методы оценки, включая подход с усеченным средним значением α и L-, M-, S- и R-оценки . Были представлены
Линейная регрессия широко используется в биологических, поведенческих и социальных науках для описания возможных связей между переменными. Он считается одним из наиболее важных инструментов, используемых в этих дисциплинах.
Линия тренда представляет собой тенденцию, долгосрочное движение данных временного ряда после учета других компонентов. Он показывает, увеличился или уменьшился конкретный набор данных (например, ВВП, цены на нефть или цены на акции) за определенный период времени. Линию тренда можно просто нарисовать на глаз через набор точек данных, но более правильно их положение и наклон рассчитываются с использованием статистических методов, таких как линейная регрессия. Линии тренда обычно представляют собой прямые линии, хотя в некоторых вариантах используются полиномы более высокой степени в зависимости от желаемой степени кривизны линии.
Линии тренда иногда используются в бизнес-аналитике, чтобы показать изменения данных с течением времени. Это имеет то преимущество, что является простым. Линии тренда часто используются, чтобы доказать, что конкретное действие или событие (например, обучение или рекламная кампания) вызвало наблюдаемые изменения в определенный момент времени. Это простой метод, не требующий создания контрольной группы, планирования эксперимента или сложной техники анализа. Однако он страдает отсутствием научной обоснованности в тех случаях, когда другие потенциальные изменения могут повлиять на данные.
Первые данные о связи курения табака со смертностью и заболеваемостью были получены в ходе наблюдательных исследований с использованием регрессионного анализа. Чтобы уменьшить ложные корреляции при анализе данных наблюдений, исследователи обычно включают в свои регрессионные модели несколько переменных в дополнение к переменной, представляющей основной интерес. Например, в регрессионную модель, в которой курение сигарет является независимой переменной, представляющей основной интерес, а зависимой переменной является продолжительность жизни, измеряемая в годах, исследователи могут включить образование и доход в качестве дополнительных независимых переменных, чтобы гарантировать, что любое наблюдаемое влияние курения на продолжительность жизни является достоверным. не из-за других социально-экономических факторов . Однако никогда невозможно включить все возможные мешающие в эмпирический анализ переменные. Например, гипотетический ген может увеличить смертность, а также заставить людей больше курить. По этой причине рандомизированные контролируемые исследования часто способны предоставить более убедительные доказательства причинно-следственных связей, чем те, которые можно получить с помощью регрессионного анализа данных наблюдений. Когда контролируемые эксперименты невозможны, используются варианты регрессионного анализа, такие как Регрессия инструментальных переменных может использоваться, чтобы попытаться оценить причинно-следственные связи на основе данных наблюдений.
Модель ценообразования капитальных активов использует линейную регрессию, а также концепцию бета-версии для анализа и количественной оценки систематического риска инвестиций. Это происходит непосредственно из бета-коэффициента модели линейной регрессии, которая связывает доходность инвестиций с доходностью всех рискованных активов.
Этот раздел нуждается в расширении . Вы можете помочь, добавив к нему . ( апрель 2024 г. )
Линейная регрессия находит применение в широком спектре приложений науки об окружающей среде, таких как землепользование, [28] инфекционные заболевания, [29] и загрязнение воздуха. [30]
Линейная регрессия обычно используется в полевых исследованиях в области строительства для получения характеристик жильцов здания. При полевых исследованиях теплового комфорта ученые-строители обычно запрашивают голоса жильцов по тепловым ощущениям, которые варьируются от -3 (ощущение холода) до 0 (нейтральное) и до +3 (ощущение жары), и измеряют данные о температуре окружающей среды жильцов. Нейтральная или комфортная температура может быть рассчитана на основе линейной регрессии между показателем теплового ощущения и температурой в помещении и установкой показателя теплового ощущения равным нулю. Однако были дебаты о направлении регрессии: регрессия голосов тепловых ощущений (ось Y) в зависимости от температуры в помещении (ось X) или наоборот: регрессия температуры в помещении (ось Y) в зависимости от голосов тепловых ощущений (ось X). . [31]
Линейная регрессия по методу наименьших квадратов как средство нахождения хорошей грубой линейной аппроксимации набора точек была выполнена Лежандром (1805) и Гауссом (1809) для предсказания движения планет. Кетле сделал эту процедуру широко известной и широко использовал ее в социальных науках. [33]
^ Дэвид А. Фридман (2009). Статистические модели: теория и практика . Издательство Кембриджского университета . п. 26. Простое уравнение регрессии имеет в правой части точку пересечения и объясняющую переменную с коэффициентом наклона. Правая часть множественной регрессии, каждая из которых имеет свой собственный коэффициент наклона.
^ Ренчер, Элвин К.; Кристенсен, Уильям Ф. (2012), «Глава 10, Многомерная регрессия - Раздел 10.1, Введение», Методы многомерного анализа , Ряды Уайли в вероятности и статистике, том. 709 (3-е изд.), John Wiley & Sons, с. 19, ISBN 9781118391679 .
^ Ян, Синь (2009), Линейный регрессионный анализ: теория и вычисления , World Scientific, стр. 1–2, ISBN 9789812834119 , Регрессионный анализ... вероятно, одна из старейших тем математической статистики, возникшая около двухсот лет назад. Самой ранней формой линейной регрессии был метод наименьших квадратов, который был опубликован Лежандром в 1805 году и Гауссом в 1809 году ... Лежандр и Гаусс оба применили этот метод к проблеме определения на основе астрономических наблюдений орбит тел. о солнце.
^ Дрейпер, Норман Р.; ван Ностранд; Р. Крейг (1979). «Гребтовая регрессия и оценка Джеймса-Стейна: обзор и комментарии». Технометрика . 21 (4): 451–466. дои : 10.2307/1268284 . JSTOR 1268284 .
^ Хёрл, Артур Э.; Кеннард, Роберт В.; Хёрл, Роджер В. (1985). «Практическое использование ридж-регрессии: решенная задача». Журнал Королевского статистического общества, серия C. 34 (2): 114–120. JSTOR 2347363 .
^ Нарула, Субхаш К.; Веллингтон, Джон Ф. (1982). «Регрессия минимальной суммы абсолютных ошибок: современное исследование». Международный статистический обзор . 50 (3): 317–326. дои : 10.2307/1402501 . JSTOR 1402501 .
Чарльз Дарвин . Изменение животных и растений при одомашнивании . (1868) (Глава XIII описывает то, что было известно о реверсии во времена Гальтона. Дарвин использует термин «реверсия».)
Дрейпер, Северная Каролина; Смит, Х. (1998). Прикладной регрессионный анализ (3-е изд.). Джон Уайли. ISBN 978-0-471-17082-2 .
Фрэнсис Гальтон. «Регрессия к посредственности в наследственном росте», Журнал Антропологического института , 15:246-263 (1886). (Факсимиле: [1] )
Роберт С. Пиндик и Дэниел Л. Рубинфельд (1998, 4-е изд.). Эконометрические модели и экономические прогнозы , гл. 1 (Введение, включая приложения по Σ-операторам и получению оценок параметров) и Приложение 4.3 (множественная регрессия в матричной форме).
Национальная физическая лаборатория (1961). «Глава 1: Линейные уравнения и матрицы: прямые методы». Современные вычислительные методы . Заметки по прикладной науке. Том. 16 (2-е изд.). Канцелярия Ее Величества .
Arc.Ask3.Ru Номер скриншота №: 5e4e2bb501bf47256a78fc1684d07e74__1715568420 URL1:https://arc.ask3.ru/arc/aa/5e/74/5e4e2bb501bf47256a78fc1684d07e74.html Заголовок, (Title) документа по адресу, URL1: Linear regression - Wikipedia
Данный printscreen веб страницы (снимок веб страницы, скриншот веб страницы), визуально-программная копия документа расположенного по адресу URL1 и сохраненная в файл, имеет: квалифицированную, усовершенствованную (подтверждены: метки времени, валидность сертификата), открепленную ЭЦП (приложена к данному файлу), что может быть использовано для подтверждения содержания и факта существования документа в этот момент времени. Права на данный скриншот принадлежат администрации Ask3.ru, использование в качестве доказательства только с письменного разрешения правообладателя скриншота. Администрация Ask3.ru не несет ответственности за информацию размещенную на данном скриншоте. Права на прочие зарегистрированные элементы любого права, изображенные на снимках принадлежат их владельцам. Качество перевода предоставляется как есть. Любые претензии, иски не могут быть предъявлены. Если вы не согласны с любым пунктом перечисленным выше, вы не можете использовать данный сайт и информация размещенную на нем (сайте/странице), немедленно покиньте данный сайт. В случае нарушения любого пункта перечисленного выше, штраф 55! (Пятьдесят пять факториал, Денежную единицу (имеющую самостоятельную стоимость) можете выбрать самостоятельно, выплаичвается товарами в течение 7 дней с момента нарушения.)











































































![{\displaystyle {\vec {x_{i}}}=\left[x_{1}^{i},x_{2}^{i},\ldots,x_{m}^{i}\right]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/156ecace8a311d501c63ca49c73bba6efc915283)
![{\displaystyle {\vec {\beta }}=\left[\beta _{0},\beta _{1},\ldots,\beta _{m}\right]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/32434f0942d63c868f23d5af39442bb90783633b)


![{\displaystyle {\vec {x_{i}}}=\left[1,x_{1}^{i},x_{2}^{i},\ldots,x_{m}^{i}\right ]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/f72fa7acd1682497c285884b0686d784d8b0eb15)










