Биномиальное распределение
Функция массы вероятности 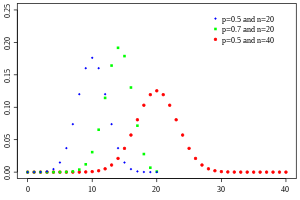 | |||
Кумулятивная функция распределения 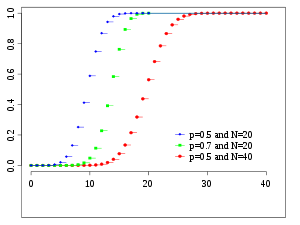 | |||
| Обозначения | |||
|---|---|---|---|
| Параметры | – количество испытаний – вероятность успеха для каждого испытания | ||
| Поддерживать | - количество успехов | ||
| ПМФ | |||
| CDF | ( регуляризованная неполная бета-функция ) | ||
| Иметь в виду | |||
| медиана | или | ||
| Режим | или | ||
| Дисперсия | |||
| асимметрия | |||
| Избыточный эксцесс | |||
| Энтропия | в Шеннонс . Для nats используйте естественный журнал в журнале. | ||
| МГФ | |||
| CF | |||
| ПГФ | |||
| Информация о Фишере | (для фиксированного ) | ||


![{\displaystyle p\in [0,1]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/33c3a52aa7b2d00227e85c641cca67e85583c43c)















![{\displaystyle G(z)=[q+pz]^{n}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/40494c697ce2f88ebb396ac0191946285cadcbdd)


| Часть серии по статистике. |
| Теория вероятностей |
|---|
 |


с n и k, как в треугольнике Паскаля
Вероятность того, что шар в ящике Гальтона с 8 слоями ( n = 8) окажется в центральном контейнере ( k = 4), равна .

В теории вероятностей и статистике биномиальное распределение с параметрами n и p представляет собой дискретное распределение вероятностей числа успехов в последовательности из n независимых экспериментов , каждый из которых задает вопрос «да-нет» и каждый имеет свой логический собственный результат : успех (с вероятностью p ) или неудача (с вероятностью ). Отдельный эксперимент успеха/неудачи также называется испытанием Бернулли или экспериментом Бернулли, а последовательность результатов называется процессом Бернулли ; для одного испытания, т. е. n = 1, биномиальное распределение является распределением Бернулли . Биномиальное распределение является основой популярного биномиального теста статистической значимости . [1]
Биномиальное распределение часто используется для моделирования количества успехов в выборке размера n, с заменой из популяции размера N. взятой Если выборка осуществляется без замены, выборки не являются независимыми, и поэтому результирующее распределение является гипергеометрическим , а не биномиальным. Однако для N , намного большего, чем n , биномиальное распределение остается хорошим приближением и широко используется.
Определения [ править ]
Функция массы вероятности [ править ]
В общем случае, если случайная величина X подчиняется биномиальному распределению с параметрами n ∈ и p ∈ [0,1], мы пишем X ~ B( n , p ). Вероятность получения ровно k успехов в n независимых испытаниях Бернулли (с одинаковой частотой p ) определяется функцией массы вероятности :


для k = 0, 1, 2, ..., n , где

– биномиальный коэффициент , отсюда и название распределения. Формулу можно понять следующим образом: – вероятность получения последовательности Испытания Бернулли, в которых впервые испытания – «успехи», а остальные (последние) испытания заканчиваются «провалом». Поскольку испытания независимы и вероятности между ними остаются постоянными, любая последовательность ( перестановка ) испытания с успехи (и неудачи) имеет одинаковую вероятность достижения (независимо от положения успехов в последовательности). Есть такие последовательности, поскольку подсчитывает количество перестановок (возможных последовательностей) объекты двух типов, с количество объектов одного типа (и количество объектов другого типа, где «тип» означает совокупность идентичных объектов, а два здесь означают «успех» и «неудача»). Биномиальное распределение связано с вероятностью получения любой из этих последовательностей, то есть с вероятностью получения одной из них ( ) необходимо добавить раз, следовательно .








При создании справочных таблиц биномиального распределения вероятностей обычно таблица заполняется до n /2 значений. Это связано с тем, что при k > n /2 вероятность можно вычислить по ее дополнению как

Если посмотреть на выражение f ( k , n , p ) как на функцию k , то можно найти значение k , которое максимизирует его. Это значение k можно найти, вычислив

и сравнивая его с 1. Всегда существует целое число M, удовлетворяющее условию [2]

f ( k , n , p ) монотонно возрастает при k < M и монотонно убывает при k > M , за исключением случая, когда ( n + 1) p является целым числом. В этом случае есть два значения, при которых f максимально: ( n + 1) p и ( n + 1) p − 1. M — наиболее вероятный исход (т. е. наиболее вероятный, хотя это все же может быть маловероятным). в целом) испытаний Бернулли и называется модой .
Эквивалентно, . Взяв функцию пола , получим . [примечание 1]


Пример [ править ]
Предположим, что при броске смещенной монеты выпадет орел с вероятностью 0,3. Вероятность увидеть ровно 4 орла за 6 бросков равна

распределения Кумулятивная функция
Кумулятивную функцию распределения можно выразить как:

где является «полом» под k , т.е. наибольшим целым числом, меньшим или равным k .

Ее также можно представить через регуляризованную неполную бета-функцию следующим образом: [3]

что эквивалентно кумулятивной функции распределения распределения F - : [4]

Некоторые оценки в замкнутой форме для кумулятивной функции распределения приведены ниже .
Свойства [ править ]
и дисперсия Ожидаемое значение
Если X ~ B ( n , p ), то есть X — случайная величина с биномиальным распределением, где n общее количество экспериментов, а p — вероятность того, что каждый эксперимент даст успешный результат, то ожидаемое значение X — равно: [5]
![{\displaystyle \operatorname {E} [X]=np.}](https://wikimedia.org/api/rest_v1/media/math/render/svg/3f16b365410a1b23b5592c53d3ae6354f1a79aff)
Это следует из линейности ожидаемого значения, а также из того факта, что X представляет собой сумму n одинаковых случайных величин Бернулли, каждая из которых имеет ожидаемое значение p . Другими словами, если являются идентичными (и независимыми) случайными величинами Бернулли с параметром p , то и


![{\displaystyle \operatorname {E} [X]=\operatorname {E} [X_{1}+\cdots +X_{n}]=\operatorname {E} [X_{1}]+\cdots +\operatorname { E} [X_{n}]=p+\cdots +p=np.}](https://wikimedia.org/api/rest_v1/media/math/render/svg/5f238d520c68a1d1b9b318492ddda39f4cc45bb8)
Разница составляет :

Это аналогичным образом следует из того факта, что дисперсия суммы независимых случайных величин есть сумма дисперсий.
Высшие моменты [ править ]
Первые 6 центральных моментов , определяемые как , даны
![{\displaystyle \mu _{c}=\operatorname {E} \left[(X-\operatorname {E} [X])^{c}\right]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/1c5ea3e05b674668550675c3c4593c725a1ec86b)

Нецентральные моменты удовлетворяют
![{\displaystyle {\begin{aligned}\operatorname {E} [X]&=np,\\\operatorname {E} [X^{2}]&=np(1-p)+n^{2}p ^{2},\end{выровнено}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/b3f2b3a9af52fc1ea633476400290069fc3ae7b4)
![{\displaystyle \operatorname {E} [X^{c}]=\sum _{k=0}^{c}\left\{{c \atop k}\right\}n^{\underline {k} }p^{k},}](https://wikimedia.org/api/rest_v1/media/math/render/svg/db435ced7af59fa481fe26a023a1429d18a6a83a)
где – числа Стирлинга второго рода , а это падающая сила .Простая граница [8] следует путем ограничения биномиальных моментов через высшие моменты Пуассона :



![{\displaystyle \operatorname {E} [X^{c}]\leq \left({\frac {c}{\log(c/(np)+1)}}\right)^{c}\leq ( np)^{c}\exp \left({\frac {c^{2}}{2np}}\right).}](https://wikimedia.org/api/rest_v1/media/math/render/svg/e6b86926254189719acfa57fcc1650caf698c292)
Это показывает, что если , затем в лучшем случае является постоянным фактором вдали от

![{\displaystyle \operatorname {E} [X^{c}]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/5989f9c9f5202059ad1c0a4026d267ee2a975761)
![{\displaystyle \operatorname {E} [X]^{c}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/74d46bd564a6f77db38e12b156443bdbc3262cfb)
Режим [ править ]
Обычно мода биномиального распределения B ( n , p ) равна , где это функция пола . Однако, когда ( n + 1) p является целым числом и p не равно ни 0, ни 1, тогда распределение имеет два режима: ( n + 1) p и ( n + 1) p - 1. Когда p равно 0 или 1, режим будет 0 и n соответственно. Эти случаи можно резюмировать следующим образом:


Доказательство: Пусть

Для только имеет ненулевое значение с . Для мы находим и для . Это доказывает, что мода равна 0 для и для .







Позволять . Мы находим

- .

Из этого следует

Итак, когда является целым числом, то и это режим. В случае, если , тогда только это режим. [9]




Медиана [ править ]
В общем, не существует единой формулы для нахождения медианы для биномиального распределения, и она может даже быть неоднозначной. Однако было установлено несколько особых результатов:
- Если является целым числом, то среднее значение, медиана и мода совпадают и равны . [10] [11]
- Любая медиана m должна лежать в интервале . [12]
- Медиана m не может находиться слишком далеко от среднего значения: . [13]
- Медиана уникальна и равна m = round ( np ), когда (кроме случая, когда и n нечетно). [12]
- Когда p — рациональное число (за исключением и n нечетно) медиана уникальна. [14]
- Когда и n нечетно, любое число m в интервале является медианой биномиального распределения. Если и n четно, тогда является уникальной медианой.






Границы хвоста [ править ]
При k ≤ np можно получить верхние оценки для нижнего хвоста кумулятивной функции распределения. , вероятность того, что будет не более k успехов. С эти границы также можно рассматривать как границы верхнего хвоста кумулятивной функции распределения при k ≥ np .


Неравенство Хеффдинга дает простую оценку

что, однако, не очень плотно. В частности, для p = 1 мы имеем, что F ( k ; n , p ) = 0 (при фиксированном k , n с k < n ), но оценка Хеффдинга оценивается как положительная константа.
Более точную оценку можно получить из оценки Чернова : [15]

где D ( a || p ) — относительная энтропия (или расхождение Кульбака-Лейблера) между a -монетой и p -монетой (т.е. между распределениями Бернулли( a ) и Бернулли( p )):

Асимптотически эта граница достаточно точна; видеть [15] для подробностей.
Можно также получить нижние оценки хвоста , известные как границы антиконцентрации. Аппроксимируя биномиальный коэффициент формулой Стирлинга, можно показать, что [16]


что подразумевает более простую, но более слабую оценку

Для p = 1/2 и k ≥ 3 n /8 для четного n можно сделать знаменатель постоянным: [17]

Статистический вывод
Оценка параметров [ править ]
Когда n известно, параметр p можно оценить, используя долю успехов:

Эта оценка находится с использованием оценки максимального правдоподобия , а также метода моментов . Эта оценка является несмещенной и равномерной с минимальной дисперсией , что доказано с помощью теоремы Лемана-Шеффе , поскольку она основана на минимальной достаточной и полной статистике (т. е.: x ). Оно также согласовано как по вероятности, так и по MSE .
Закрытая форма оценки Байеса для p также существует при использовании бета-распределения в качестве сопряженного априорного распределения . При использовании общего априорная апостериорного среднего оценка равна:


Оценка Байеса асимптотически эффективна , и когда размер выборки приближается к бесконечности ( n → ∞), она приближается к решению MLE . [18] Оценка Байеса смещена (насколько зависит от априорных значений), допустима и непротиворечива по вероятности.
В частном случае использования стандартного равномерного распределения в качестве неинформативного априорного значения : , апостериорная средняя оценка становится:


( Апостериорная мода должна просто приводить к стандартной оценке.) Этот метод называется правилом последовательности , которое было введено в 18 веке Пьером-Симоном Лапласом .
При использовании априора Джеффриса априором является , [19] что приводит к оценке:


При оценке p с очень редкими событиями и малым n (например, если x=0), использование стандартной оценки приводит к что иногда нереально и нежелательно. В таких случаях существуют различные альтернативные оценки. [20] Один из способов — использовать оценку Байеса. , что приводит к:



Другой метод заключается в использовании верхней границы доверительного интервала, полученного с помощью правила трех :

Доверительные интервалы [ править ]
Даже для довольно больших значений n фактическое распределение среднего существенно ненормально. [21] Из-за этой проблемы было предложено несколько методов оценки доверительных интервалов.
В приведенных ниже уравнениях доверительных интервалов переменные имеют следующее значение:
- n 1 — количество успехов из n , общее количество попыток
- это доля успехов
- это квантиль стандартного нормального распределения (т. е. пробита ), соответствующий целевой частоте ошибок . Например, для уровня достоверности 95% ошибка = 0,05, поэтому = 0,975 и = 1.96.




Метод Вальда [ править ]

поправка на непрерывность 0,5/ n . Может быть добавлена [ нужны разъяснения ]
Метод Агрести-Кулла [ править ]

Здесь оценка p изменяется на

Этот метод хорошо работает для и . [23] Смотрите здесь для . [24] Для используйте приведенный ниже метод Уилсона (оценка).




Метод арксинуса [ править ]

Метод Вильсона (оценка) [ править ]
Обозначения в приведенной ниже формуле отличаются от предыдущих формул в двух отношениях: [26]
- Во-первых, z x в приведенной ниже формуле имеет несколько иную интерпретацию: она имеет свое обычное значение « х- й квантиль стандартного нормального распределения», а не является сокращением от «(1 - x )-й квантиль».
- Во-вторых, эта формула не использует плюс-минус для определения двух границ. Вместо этого можно использовать чтобы получить нижнюю границу, или используйте чтобы получить верхнюю границу. Например: для уровня достоверности 95% ошибка = 0,05, поэтому нижнюю границу можно получить, используя , и можно получить верхнюю границу, используя .





Сравнение [ править ]
Так называемый «точный» ( Клоппер-Пирсон ) метод является наиболее консервативным. [21] ( Точный не означает абсолютно точный; скорее, он указывает на то, что оценки не будут менее консервативными, чем истинное значение.)
Метод Вальда, хотя его обычно рекомендуют в учебниках, является наиболее предвзятым. [ нужны разъяснения ]
Связанные дистрибутивы [ править ]
Суммы биномов [ править ]
Если X ~ B( n , p ) и Y ~ B( m , p ) — независимые биномиальные переменные с одинаковой вероятностью p , то X + Y снова является биномиальной переменной; его распределение Z=X+Y ~ B( n+m , p ): [28]
![{\displaystyle {\begin{aligned}\operatorname {P} (Z=k)&=\sum _{i=0}^{k}\left[{\binom {n}{i}}p^{i }(1-p)^{ni}\right]\left[{\binom {m}{ki}}p^{ki}(1-p)^{m-k+i}\right]\\& = {\binom {n+m}{k}}p^{k}(1-p)^{n+mk}\end{aligned}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/38fc38e9a5e2c49743f45b4dab5dae6230ab2ad5)
Биномиально распределенную случайную величину X ~ B( n , p ) можно рассматривать как сумму n случайных величин, распределенных по Бернулли. Таким образом, сумма двух случайных величин с биномиальным распределением X ~ B( n , p ) и Y ~ B( m , p ) эквивалентна сумме n + m случайных величин с распределением Бернулли, что означает Z=X+Y ~ B( п+т , р ). Это также можно доказать непосредственно с помощью правила сложения.
Однако если X и Y не имеют одинаковую вероятность p , то дисперсия суммы будет меньше, чем дисперсия биномиальной переменной, распределенной как

Пуассона Биномиальное распределение
Биномиальное распределение — это частный случай биномиального распределения Пуассона , которое представляет собой распределение суммы n независимых неидентичных испытаний Бернулли B( p i ). [29]
двух биномиальных Отношение распределений
Этот результат был впервые получен Кацем и соавторами в 1978 году. [30]
Пусть X ~ B( n , p1 B ) и Y ( m , p2 ~ ) независимы. Пусть Т = ( Икс / п ) / ( Y / м ) .
Тогда log( T ) примерно нормально распределяется со средним log( p 1 / p 2 ) и дисперсией ((1/ p 1 ) − 1)/ n + ((1/ p 2 ) − 1)/ m .
Условные биномы [ править ]
Если X ~ B( n , p ) и Y | X ~ B( X , q ) (условное распределение Y при заданном X ), тогда Y — простая биномиальная случайная величина с распределением Y ~ B( n , pq ).
Например, представьте, что вы бросаете n мячей в корзину UX , берете попавшие мячи и бросаете их в другую корзину U Y . Если p — вероятность попадания в U X, то X ~ B( n , p ) — количество шаров, попавших U X. в Если q — вероятность попасть в U Y, то количество шаров, попавших в U Y, равно Y ~ B( X , q ) и, следовательно, Y ~ B( n , pq ).


![{\displaystyle {\begin{aligned}\Pr[Y=m]&=\sum _{k=m}^{n}\Pr[Y=m\mid X=k]\Pr[X=k]\\[2pt]&=\sum _{k=m}^{n}{\binom {n}{k}}{\binom {k}{m}}p^{k}q^{m}(1-p)^{n-k}(1-q)^{k-m}\end{aligned}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/7e8f896e04f3bc2c13d2eed61e48bd43e63f6406)

![{\displaystyle \Pr[Y=m]=\sum _{k=m}^{n}{\binom {n}{m}}{\binom {n-m}{k-m}}p^{k}q^{m}(1-p)^{n-k}(1-q)^{k-m}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/8369ef846ffda72900efc67b334923f70ce48ca5)

![{\displaystyle {\begin{aligned}\Pr[Y=m]&={\binom {n}{m}}p^{m}q^{m}\left(\sum _{k=m}^{n}{\binom {n-m}{k-m}}p^{k-m}(1-p)^{n-k}(1-q)^{k-m}\right)\\[2pt]&={\binom {n}{m}}(pq)^{m}\left(\sum _{k=m}^{n}{\binom {n-m}{k-m}}\left(p(1-q)\right)^{k-m}(1-p)^{n-k}\right)\end{aligned}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/caaa36dbcb3b4c43d7d5310533ef9d4809ba9db8)

![{\displaystyle \Pr[Y=m]={\binom {n}{m}}(pq)^{m}\left(\sum _{i=0}^{n-m}{\binom {n-m}{i}}(p-pq)^{i}(1-p)^{n-m-i}\right)}](https://wikimedia.org/api/rest_v1/media/math/render/svg/54401b2dd0936ca0904832912df2fe9b2c3d5153)

![{\displaystyle {\begin{aligned}\Pr[Y=m]&={\binom {n}{m}}(pq)^{m}(p-pq+1-p)^{n-m}\\[4pt]&={\binom {n}{m}}(pq)^{m}(1-pq)^{n-m}\end{aligned}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/324b106ed5f362da979eebfc0feaa94b44b713b2)

Распределение Бернулли [ править ]
Распределение Бернулли является частным случаем биномиального распределения, где n = 1. Символически X ~ B(1, p ) имеет тот же смысл, что и X ~ Бернулли( p ). И наоборот, любое биномиальное распределение B( n , p ) представляет собой распределение суммы n независимых испытаний Бернулли , Бернулли ( p ), каждое с одинаковой вероятностью p . [31]
Нормальное приближение [ править ]

Если n достаточно велико, то перекос распределения не слишком велик. В этом случае разумное приближение к B( n , p ) дается нормальным распределением

и это базовое приближение можно простым способом улучшить, используя подходящую поправку на непрерывность .Базовое приближение обычно улучшается по мере увеличения n (не менее 20) и становится лучше, когда p не близко к 0 или 1. [32] различные эмпирические правила можно использовать n Чтобы решить , достаточно ли велико , а p достаточно далеко от крайних значений нуля или единицы, :
- Одно правило [32] заключается в том, что для n > 5 нормальное приближение адекватно, если абсолютное значение асимметрии строго меньше 0,3; то есть, если

Это можно уточнить, используя теорему Берри-Эссеена .
- Более строгое правило гласит, что нормальное приближение подходит только в том случае, если все в пределах трех стандартных отклонений от его среднего значения находится в диапазоне возможных значений; то есть только если
- Это правило трех стандартных отклонений эквивалентно следующим условиям, которые также подразумевают первое правило, приведенное выше.











- Другое часто используемое правило заключается в том, что оба значения и должно быть больше, чем [33] [34] или равно 5. Однако конкретное число варьируется от источника к источнику и зависит от того, насколько хорошее приближение требуется. В частности, если вместо 5 использовать 9, правило подразумевает результаты, указанные в предыдущих параграфах.




Ниже приведен пример применения поправки на непрерывность . кто-то хочет вычислить Pr( X ≤ 8) для биномиальной случайной величины X. Предположим , Если Y имеет распределение, заданное нормальным приближением, то Pr( X ≤ 8) аппроксимируется Pr( Y ≤ 8,5). Добавление 0,5 представляет собой поправку на непрерывность; неисправленное нормальное приближение дает значительно менее точные результаты.
Это приближение, известное как теорема Муавра – Лапласа , значительно экономит время при выполнении вычислений вручную (точные вычисления с большими n очень обременительны); исторически это было первое использование нормального распределения, представленное в Абрахама де Муавра книге «Доктрина шансов» в 1738 году. Сегодня это можно рассматривать как следствие центральной предельной теоремы, поскольку B( n , p ) является сумма n независимых, одинаково распределенных переменных Бернулли с параметром p . Этот факт является основой проверки гипотезы , «z-критерия пропорции», для значения p с использованием x/n , выборочной доли и оценки p , в общей тестовой статистике . [35]
Например, предположим, что кто-то случайным образом выбирает n человек из большой популяции и спрашивает их, согласны ли они с определенным утверждением. Доля согласных, конечно, будет зависеть от выборки. Если бы группы из n человек отбирались повторно и по-настоящему случайным образом, пропорции следовали бы приблизительно нормальному распределению со средним значением, равным истинной доле согласия p в популяции, и со стандартным отклонением.

Приближение Пуассона [ править ]
Биномиальное распределение сходится к распределению Пуассона , когда количество испытаний стремится к бесконечности, а произведение np сходится к конечному пределу. Следовательно, распределение Пуассона с параметром λ = np можно использовать как аппроксимацию B( n , p ) биномиального распределения, если n достаточно велико, а p достаточно мало. Согласно эмпирическим правилам, это приближение хорошо, если n ≥ 20 и p ≤ 0,05. [36] такое, что np ≤ 1, или если n > 50 и p < 0,1 такое, что np < 5, [37] или если n ≥ 100 и np ≤ 10. [38] [39]
О точности приближения Пуассона см. Новак, [40] гл. 4 и ссылки в нем.
Ограничение распространения [ править ]
- Предельная теорема Пуассона : когда n приближается к ∞, а p произведении np приближается к 0 при фиксированном , биномиальное распределение ( n , p ) приближается к распределению Пуассона с ожидаемым значением λ = np . [38]
- Теорема Муавра – Лапласа : когда n приближается к ∞, а p остается фиксированным, распределение

- приближается к нормальному распределению с ожидаемым значением 0 и дисперсией 1. Иногда этот результат формулируют в общих чертах, говоря, что распределение X является асимптотически нормальным с ожидаемым значением 0 и дисперсией 1. Этот результат является частным случаем центральной предельной теоремы .
Бета-дистрибутив [ править ]
Биномиальное распределение и бета-распределение представляют собой разные взгляды на одну и ту же модель повторяющихся испытаний Бернулли. Биномиальное распределение представляет собой PMF k успехов при n независимых событиях, каждое из которых имеет вероятность p успеха . Математически, когда α = k + 1 и β = n − k + 1 , бета-распределение и биномиальное распределение связаны соотношением [ нужны разъяснения ] коэффициент n + 1 :

Бета-распределения также представляют собой семейство априорных распределений вероятностей для биномиальных распределений в байесовском выводе : [41]

Учитывая однородность априора, апостериорное распределение вероятности успеха p при условии n независимых событий с k наблюдаемыми успехами является бета-распределением. [42]
Вычислительные методы [ править ]
Генерация случайных чисел [ править ]
Методы генерации случайных чисел , в которых маргинальное распределение является биномиальным, хорошо известны. [43] [44] Одним из способов создания выборок случайных величин из биномиального распределения является использование алгоритма инверсии. Для этого необходимо вычислить вероятность того, что Pr( X = k ) для всех значений k от 0 до n . (Эти вероятности должны в сумме давать значение, близкое к единице, чтобы охватить все пространство выборок.) Затем, используя генератор псевдослучайных чисел для равномерной генерации выборок от 0 до 1, можно преобразовать вычисленные выборки в дискретные числа, используя вероятности, рассчитанные на первом этапе.
История [ править ]
Это распределение было получено Якобом Бернулли . Он рассмотрел случай, когда p = r /( r + s ), где p — вероятность успеха, а r и s — положительные целые числа. Блез Паскаль ранее рассмотрел случай, когда p = 1/2, составив таблицу соответствующих биномиальных коэффициентов в том, что теперь известно как треугольник Паскаля . [45]
См. также [ править ]
- Логистическая регрессия
- Полиномиальное распределение
- Отрицательное биномиальное распределение
- Бета-биномиальное распределение
- Биномиальная мера, пример мультифрактальной меры . [46]
- Статистическая механика
- Лемма о накоплении , результирующая вероятность при выполнении XOR независимых логических переменных
Ссылки [ править ]
- ^ Вестленд, Дж. Кристофер (2020). Аудиторская аналитика: наука о данных для бухгалтерской профессии . Чикаго, Иллинойс, США: Спрингер. п. 53. ИСБН 978-3-030-49091-1 .
- ^ Феллер, В. (1968). Введение в теорию вероятностей и ее приложения (Третье изд.). Нью-Йорк: Уайли. п. 151 (теорема в разделе VI.3).
- ^ Уодсворт, врач общей практики (1960). Введение в теорию вероятности и случайных величин . Нью-Йорк: МакГроу-Хилл. п. 52 .
- ^ Джоветт, GH (1963). «Связь между биномиальным и F-распределениями». Журнал Королевского статистического общества, серия D. 13 (1): 55–57. дои : 10.2307/2986663 . JSTOR 2986663 .
- ^ См . Доказательство Wiki.
- ^ Кноблаух, Андреас (2008), «Выражения в замкнутой форме для моментов биномиального распределения вероятностей» , SIAM Journal on Applied Mathematics , 69 (1): 197–204, doi : 10.1137/070700024 , JSTOR 40233780
- ^ Нгуен, Дуй (2021), «Вероятностный подход к моментам биномиальных случайных величин и его применение» , The American Statistician , 75 (1): 101–103, doi : 10.1080/00031305.2019.1679257 , S2CID 209923008
- ^ Д. Але, Томас (2022), «Точные и простые границы для необработанных моментов биномиального и пуассоновского распределений», « Statistics & Probability Letters» , 182 : 109306, arXiv : 2103.17027 , doi : 10.1016/j.spl.2021.109306
- ^ См. также Николя, Андре (7 января 2019 г.). «Режим поиска по биномиальному распределению» . Обмен стеками .
- ^ Нойманн, П. (1966). «О медиане биномиального и пуассоновского распределения». Научный журнал Технического университета Дрездена (на немецком языке). 19 :29–33.
- ^ Господи, Ник. (июль 2010 г.). «Биномиальные средние значения, когда среднее значение является целым числом», The Mathematical Gazette 94, 331–332.
- ^ Jump up to: Перейти обратно: а б Каас, Р.; Бурман, Дж. М. (1980). «Среднее, медиана и мода в биномиальных распределениях». Статистика Неерландики . 34 (1): 13–18. дои : 10.1111/j.1467-9574.1980.tb00681.x .
- ^ Хамза, К. (1995). «Наименьшая равномерная верхняя граница расстояния между средним значением и медианой биномиального распределения и распределения Пуассона». Статистика и вероятностные буквы . 23 : 21–25. дои : 10.1016/0167-7152(94)00090-У .
- ^ Новаковский, С. (2021). «Единственность медианы биномиального распределения с рациональной вероятностью». Успехи математики: Научный журнал . 10 (4): 1951–1958. arXiv : 2004.03280 . дои : 10.37418/amsj.10.4.9 . ISSN 1857-8365 . S2CID 215238991 .
- ^ Jump up to: Перейти обратно: а б Арратия, Р.; Гордон, Л. (1989). «Урок по большим отклонениям биномиального распределения». Бюллетень математической биологии . 51 (1): 125–131. дои : 10.1007/BF02458840 . ПМИД 2706397 . S2CID 189884382 .
- ^ Роберт Б. Эш (1990). Теория информации . Дуврские публикации. п. 115 . ISBN 9780486665214 .
- ^ Матушек Ю.; Вондрак, Дж. «Вероятностный метод» (PDF) . конспекты лекций . Архивировано (PDF) из оригинала 9 октября 2022 г.
- ^ Уилкокс, Рэнд Р. (1979). «Оценка параметров бета-биномиального распределения» . Образовательные и психологические измерения . 39 (3): 527–535. дои : 10.1177/001316447903900302 . ISSN 0013-1644 . S2CID 121331083 .
- ^ Марко Лалович ( https://stats.stackexchange.com/users/105848/marko-lalovic ), априор Джеффриса для биномиальной вероятности, URL (версия: 04 марта 2019 г.): https://stats.stackexchange.com/ q/275608
- ^ Раззаги, Мехди (2002). «Об оценке биномиальной вероятности успеха при нулевом вхождении в выборку» . Журнал современных прикладных статистических методов . 1 (2): 326–332. дои : 10.22237/jmasm/1036110000 .
- ^ Jump up to: Перейти обратно: а б Браун, Лоуренс Д.; Кай, Т. Тони; ДасГупта, Анирбан (2001), «Интервальная оценка биномиальной пропорции» , Statistical Science , 16 (2): 101–133, CiteSeerX 10.1.1.323.7752 , doi : 10.1214/ss/1009213286 , получено 5 января 2015 г.
- ^ Агрести, Алан; Коулл, Брент А. (май 1998 г.), «Приблизительное лучше, чем« точное »для интервальной оценки биномиальных пропорций» (PDF) , The American Statistician , 52 (2): 119–126, doi : 10.2307/2685469 , JSTOR 2685469 , получено 5 января 2015 г.
- ^ Гулотта, Джозеф. «Интервальный метод Агрести-Кулла» . pellucid.atlassian.net . Проверено 18 мая 2021 г.
- ^ «Доверительные интервалы» . itl.nist.gov . Проверено 18 мая 2021 г.
- ^ Пирес, Массачусетс (2002). «Доверительные интервалы для биномиальной пропорции: сравнение методов и оценка программного обеспечения» (PDF) . В Клинке, С.; Аренд, П.; Рихтер, Л. (ред.). Материалы конференции CompStat 2002 . Краткие сообщения и плакаты. Архивировано (PDF) из оригинала 9 октября 2022 г.
- ^ Уилсон, Эдвин Б. (июнь 1927 г.), «Вероятный вывод, закон последовательности и статистический вывод» (PDF) , Журнал Американской статистической ассоциации , 22 (158): 209–212, doi : 10.2307/2276774 , JSTOR 2276774 , заархивировано из оригинала (PDF) 13 января 2015 г. , получено 5 января 2015 г.
- ^ «Доверительные интервалы» . Справочник по инженерной статистике . НИСТ/Сематех. 2012 . Проверено 23 июля 2017 г.
- ^ Декинг, FM; Краайкамп, К.; Лопохаа, HP; Мистер, Л.Е. (2005). Современное введение в вероятность и статистику (1-е изд.). Springer-Publishers Лондон. ISBN 978-1-84628-168-6 .
- ^ Ван, Ю.Х. (1993). «О количестве успехов в независимых испытаниях» (PDF) . Статистика Синица . 3 (2): 295–312. Архивировано из оригинала (PDF) 03 марта 2016 г.
- ^ Кац, Д.; и др. (1978). «Получение доверительных интервалов для соотношения рисков в когортных исследованиях». Биометрия . 34 (3): 469–474. дои : 10.2307/2530610 . JSTOR 2530610 .
- ^ Табога, Марко. «Лекции по теории вероятностей и математической статистике» . statlect.com . Проверено 18 декабря 2017 г.
- ^ Jump up to: Перейти обратно: а б Бокс, Охотник и охотник (1978). Статистика для экспериментаторов . Уайли. п. 130 . ISBN 9780471093152 .
- ^ Чен, Зак (2011). Справочник по математике H2 (1-е изд.). Сингапур: Образовательное издательство. п. 350. ИСБН 9789814288484 .
- ^ «6.4: Нормальное приближение к биномиальному распределению — LibreTexts статистики» . 29 мая 2023 г. Архивировано из оригинала 29 мая 2023 г. Проверено 7 октября 2023 г.
{{cite web}}: CS1 maint: bot: исходный статус URL неизвестен ( ссылка ) - ^ NIST / SEMATECH , «7.2.4. Соответствует ли доля дефектов требованиям?» Электронный справочник по статистическим методам.
- ^ «12.4 — Аппроксимация биномиального распределения | STAT 414» . 28 марта 2023 г. Архивировано из оригинала 28 марта 2023 г. Проверено 8 октября 2023 г.
{{cite web}}: CS1 maint: bot: исходный статус URL неизвестен ( ссылка ) - ^ Чен, Зак (2011). Справочник по математике H2 (1-е изд.). Сингапур: Учебное издательство. п. 348. ИСБН 9789814288484 .
- ^ Jump up to: Перейти обратно: а б NIST / SEMATECH , «6.3.3.1. Контрольные диаграммы подсчета» , электронный справочник по статистическим методам.
- ^ «Связь между распределениями Пуассона и биномиальным распределениями» . 13 марта 2023 г. Архивировано из оригинала 13 марта 2023 г. Проверено 8 октября 2023 г.
{{cite web}}: CS1 maint: bot: исходный статус URL неизвестен ( ссылка ) - ^ Новак С.Ю. (2011) Методы экстремальной стоимости с применением в финансировании. Лондон: CRC/Чепмен и Холл/Тейлор и Фрэнсис. ISBN 9781-43983-5746 .
- ^ Маккей, Дэвид (2003). Теория информации, логический вывод и алгоритмы обучения . Издательство Кембриджского университета; Первое издание. ISBN 978-0521642989 .
- ^ «Бета-распределение» .
- ^ Деврой, Люк (1986) Генерация неоднородных случайных переменных , Нью-Йорк: Springer-Verlag. (Смотрите особенно главу X «Дискретные одномерные распределения» ).
- ^ Качитвичянукул, В.; Шмайзер, Б.В. (1988). «Генерация биномиальных случайных величин». Коммуникации АКМ . 31 (2): 216–222. дои : 10.1145/42372.42381 . S2CID 18698828 .
- ^ Кац, Виктор (2009). «14.3: Элементарная вероятность». История математики: Введение . Аддисон-Уэсли. п. 491. ИСБН 978-0-321-38700-4 .
- ^ Мандельброт, Б.Б., Фишер, А.Дж., и Кальвет, Л.Е. (1997). Мультифрактальная модель доходности активов. 3.2. Биномиальная мера – простейший пример мультифрактала.
- ^ За исключением тривиального случая , что необходимо проверить отдельно.
Дальнейшее чтение [ править ]
- Хирш, Вернер З. (1957). «Биномиальное распределение — успех или неудача, насколько они вероятны?» . Введение в современную статистику . Нью-Йорк: Макмиллан. стр. 140–153.
- Нетер, Джон; Вассерман, Уильям; Уитмор, Джорджия (1988). Прикладная статистика (Третье изд.). Бостон: Аллин и Бэкон. стр. 185–192. ISBN 0-205-10328-6 .
Внешние ссылки [ править ]
- Интерактивная графика: одномерные отношения распределения
- Калькулятор формулы биномиального распределения
- Разница двух биномиальных переменных: XY или |XY|
- Запрос биномиального распределения вероятностей в WolframAlpha
- Доверительные (достоверные) интервалы для биномиальной вероятности, p: онлайн-калькулятор доступен на сайте causaScientia.org.