Статистика заказов
В статистике статистической выборки равна статистика k-го порядка k ее - му наименьшему значению. [1] Вместе со статистикой рангов статистика порядков является одним из наиболее фундаментальных инструментов непараметрической статистики и вывода .
Важными особыми случаями порядковой статистики являются минимальное и максимальное значение выборки, а также (с некоторыми оговорками, обсуждаемыми ниже) медиана выборки и другие квантили выборки .
При использовании теории вероятностей для анализа статистики порядка случайных выборок из непрерывного распределения используется кумулятивная функция распределения , чтобы свести анализ к случаю статистики порядка равномерного распределения .
Обозначения и примеры [ править ]
Например, предположим, что наблюдаются или записываются четыре числа, в результате чего получается выборка размером 4. Если значения выборки равны
- 6, 9, 3, 8,
статистика заказов будет обозначаться

где индекс ( i ), заключенный в круглые скобки, указывает статистику i -го порядка выборки.
Статистика первого порядка (или статистика наименьшего порядка ) всегда является минимумом выборки, то есть

где, следуя общепринятому соглашению, мы используем прописные буквы для обозначения случайных величин и строчные буквы (как указано выше) для обозначения их фактических наблюдаемых значений.
Аналогично, для выборки размера n статистика n- го порядка (или статистика наибольшего порядка ) является максимальной , то есть

Диапазон выборки — это разница между максимальным и минимальным значением. Это функция статистики заказов:

Аналогичная важная статистика в исследовательском анализе данных , которая просто связана со статистикой порядка, — это выборочный межквартильный размах .
Выборочная медиана может быть или не быть порядковой статистикой, поскольку единственное среднее значение существует только тогда, когда число n наблюдений нечетно . Точнее, если n = 2 m +1 для некоторого целого числа m , то выборочная медиана равна и такова статистика заказов. С другой стороны, когда n = 2 n четно, м и имеются два средних значения, и , а выборочная медиана является некоторой функцией этих двух значений (обычно средней) и, следовательно, не является порядковой статистикой. Подобные замечания применимы ко всем квантилям выборки.


Вероятностный анализ [ править ]
Учитывая любые случайные величины X 1 , X 2 ..., X n , статистика порядка X (1) , X (2) , ..., X ( n ) также является случайными величинами, определяемыми путем сортировки значений ( реализаций ) X в 1 , ..., X n порядке возрастания.
Когда случайные величины X 1 , X 2 ..., X n образуют выборку, они независимы и одинаково распределены . Именно этот случай рассматривается ниже. В общем, случайные величины X 1 , ..., X n могут возникнуть в результате выборки из более чем одной совокупности. Тогда они независимы , но не обязательно одинаково распределены, а их совместное распределение вероятностей задается теоремой Бапата-Бега .
В дальнейшем мы будем предполагать, что рассматриваемые случайные величины непрерывны , а там, где это удобно, будем также предполагать, что они имеют функцию плотности вероятности (PDF), то есть абсолютно непрерывны . особенности анализа распределений, присваивающих массу точкам (в частности, дискретных распределений В конце обсуждаются ).
Кумулятивная функция распределения статистики заказов [ править ]
Для случайной выборки, как указано выше, с кумулятивным распределением , статистика заказов для этой выборки имеет кумулятивное распределение следующим образом: [2] (где r указывает статистику какого порядка):

![{\displaystyle F_{X_{(r)}}(x)=\sum _{j=r}^{n}{\binom {n}{j}}[F_{X}(x)]^{j }[1-F_{X}(x)]^{j}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/83743dea76239b9e15addd74a877f0c3b51ac769)
соответствующая функция плотности вероятности может быть получена из этого результата и оказывается равной
![{\displaystyle f_{X_{(r)}}(x)={\frac {n!}{(r-1)!(nr)!}}f_{X}(x)[F_{X}(x )]^{r-1}[1-F_{X}(x)]^{nr}.}](https://wikimedia.org/api/rest_v1/media/math/render/svg/0bfc29ad37f782caf50c1fab6d501876a397a9a2)
Более того, есть два особых случая, в которых CDF легко вычислить.
![{\displaystyle F_{X_{(n)}}(x)=\operatorname {Prob} (\max\{\,X_{1},\ldots,X_{n}\,\}\leq x)=[ F_{X}(x)]^{n}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/892b889a61d2577115a5d8c8ea010aaa6a03e840)
![{\displaystyle F_{X_{(1)}}(x)=\operatorname {Prob} (\min\{\,X_{1},\ldots,X_{n}\,\}\leq x)=1 -[1-F_{X}(x)]^{n}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/a4600e4a349458eb8c93b2bcdc7dd7e10f491423)
Что можно получить путем тщательного рассмотрения вероятностей.
статистики Распределение вероятностей заказов
распределения выбранная из равномерного заказов , Статистика
В этом разделе мы показываем, что порядковая статистика равномерного распределения на единичном интервале имеет маргинальные распределения, принадлежащие семейству бета-распределений . Мы также даем простой метод получения совместного распределения любого количества статистик порядка и, наконец, переводим эти результаты в произвольные непрерывные распределения с помощью cdf .
На протяжении всего этого раздела мы предполагаем, что это случайная выборка, полученная из непрерывного распределения с помощью cdf . Обозначая мы получаем соответствующую случайную выборку из стандартного равномерного распределения . Обратите внимание, что статистика заказов также удовлетворяет .





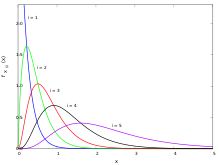
Функция плотности вероятности статистики порядка равно [3]


то есть статистика k -го порядка равномерного распределения представляет собой случайную величину с бета-распределением . [3] [4]

Доказательство этих утверждений состоит в следующем. Для Чтобы находиться между u и u + du , необходимо, чтобы ровно k − 1 элементов выборки были меньше u и чтобы хотя бы один находился между u и u + d u . Вероятность того, что в этом последнем интервале окажется более одного, уже равна , поэтому нам нужно вычислить вероятность того, что ровно k − 1, 1 и n − k наблюдений попадут в интервалы , и соответственно. см. Полиномиальное распределение Это равно ( подробнее )





и результат следующий.
Среднее значение этого распределения равно k /( n + 1).
Совместное распределение статистики заказов равномерного распределения [ править ]
Аналогично, для i < j , что совместная функция плотности вероятности статистики двух порядков U ( i ) < U ( j ) можно показать равна

что (с точностью до членов более высокого порядка, чем ) вероятность того, что i − 1, 1, j − 1 − i , 1 и n − j элементов выборки попадают в интервалы , , , , соответственно.




Совершенно аналогичным образом можно рассуждать и о выводе совместных распределений более высокого порядка. Возможно, это удивительно, но совместная плотность статистики n-го порядка оказывается постоянной :

Один из способов понять это состоит в том, что неупорядоченный образец действительно имеет постоянную плотность, равную 1, и что существует n ! разные перестановки выборки, соответствующие одной и той же последовательности статистики порядка. Это связано с тем, что 1/ n ! это объем региона . Это связано также с другой особенностью порядковой статистики однородных случайных величин: из BRS-неравенства следует , что максимальное ожидаемое число однородных U(0,1] случайных величин, которое можно выбрать из выборки размера n с суммой не превышающий ограничено сверху , который, таким образом, инвариантен на множестве всех с постоянным продуктом .





Используя приведенные выше формулы, можно вывести распределение диапазона статистики порядка, то есть распределение , то есть максимум минус минимум. В более общем смысле для , также есть бета-дистрибутив:








заказов, полученная из распределения экспоненциального Статистика
Для случайная выборка размером n из экспоненциального распределения с параметром λ , статистика порядка X ( i ) для i = 1,2,3, ..., n имеет распределение


где Z j — стандартные экспоненциальные случайные величины iid (т.е. с параметром скорости 1). Этот результат был впервые опубликован Альфредом Реньи . [5] [6]
взятая из дистрибутива Erlang заказов , Статистика
Преобразование Лапласа статистики порядка можно выбрать из распределения Эрланга с помощью метода подсчета путей. [ нужны разъяснения ] . [7]
Совместное распределение статистики заказов абсолютно непрерывного распределения [ править ]
Если F X , абсолютно непрерывен он имеет такую плотность, что , и мы можем использовать замены


и

чтобы получить следующие функции плотности вероятности для статистики порядка выборки размера n, взятой из распределения X :
![{\displaystyle f_{X_{(k)}}(x)={\frac {n!}{(k-1)!(nk)!}}[F_{X}(x)]^{k-1 }[1-F_{X}(x)]^{nk}f_{X}(x)}](https://wikimedia.org/api/rest_v1/media/math/render/svg/a3b85adac3788d1a67f96c80edfc10ad56cc8dba)
- где
![{\displaystyle f_{X_{(j)},X_{(k)}}(x,y)={\frac {n!}{(j-1)!(kj-1)!(nk)!} }[F_{X}(x)]^{j-1}[F_{X}(y)-F_{X}(x)]^{k-1-j}[1-F_{X}(y )]^{nk}f_{X}(x)f_{X}(y)}](https://wikimedia.org/api/rest_v1/media/math/render/svg/7a57558c8a25cfa2a2648f386caa9679006499df)

- где


: доверительные интервалы квантилей для Приложение
Интересный вопрос заключается в том, насколько хорошо статистика порядка выполняет функцию оценки квантилей основного распределения.
Пример небольшого размера выборки [ править ]
Самый простой случай, который следует рассмотреть, — это то, насколько хорошо медиана выборки оценивает медиану совокупности.
В качестве примера рассмотрим случайную выборку размером 6. В этом случае медиана выборки обычно определяется как середина интервала, ограниченного статистикой 3-го и 4-го порядка. Однако из предыдущего обсуждения мы знаем, что вероятность того, что этот интервал действительно содержит медиану совокупности, равна [ нужны разъяснения ]

Хотя выборочная медиана, вероятно, является одной из лучших точечных оценок медианы совокупности, не зависящих от распределения, этот пример иллюстрирует то, что она не особенно хороша в абсолютном выражении. В данном конкретном случае лучшим доверительным интервалом для медианы является интервал, ограниченный статистикой 2-го и 5-го порядка, который содержит медиану совокупности с вероятностью
^{6}={25 \более 32}\приблизительно 78\% .}](https://wikimedia.org/api/rest_v1/media/math/render/svg/092bfad29672b7903b0d5df1efb34f6c30c85c09)
При таком небольшом размере выборки, если кто-то хочет иметь уверенность не менее 95%, приходится говорить, что медиана находится между минимумом и максимумом из 6 наблюдений с вероятностью 31/32 или примерно 97%. Размер 6 фактически представляет собой наименьший размер выборки, при котором интервал, определяемый минимумом и максимумом, составляет как минимум 95% доверительный интервал для медианы генеральной совокупности.
Большие размеры выборки [ править ]
Для равномерного распределения, когда n стремится к бесконечности, p й Квантиль выборки асимптотически нормально распределен , поскольку он аппроксимируется выражением

Для общего распределения F с непрерывной ненулевой плотностью в F −1 ( p ), применяется аналогичная асимптотическая нормальность:
![{\displaystyle X_{(\lceil np\rceil)}\sim AN\left(F^{-1}(p),{\frac {p(1-p)}{n[f(F^{-1) }(p))]^{2}}}\right)}](https://wikimedia.org/api/rest_v1/media/math/render/svg/9ec5ea20cea909919df56456bd279b4c26c1091b)
где f — функция плотности , а F −1 — функция квантиля, с F. связанная Одним из первых, кто упомянул и доказал этот результат, был Фредерик Мостеллер в своей основополагающей статье 1946 года. [8] Дальнейшие исследования привели в 1960-х годах к представлению Бахадура , которое предоставляет информацию о границах ошибок. Сходимость к нормальному распределению также имеет место в более сильном смысле, например, сходимость по относительной энтропии или КЛ-дивергенция . [9]
Интересное наблюдение можно сделать в случае, когда распределение симметрично, а медиана населения равна среднему значению населения. В этом случае выборочное среднее по центральной предельной теореме также асимптотически нормально распределено, но с дисперсией σ 2 /n вместо этого. Этот асимптотический анализ предполагает, что среднее значение превосходит медиану в случаях низкого эксцесса , и наоборот. Например, медиана обеспечивает лучшие доверительные интервалы для распределения Лапласа , в то время как среднее работает лучше для X , которые имеют нормальное распределение.
Доказательство [ править ]
Можно показать, что

где

где Z i являются независимыми одинаково распределенными экспоненциальными случайными величинами с частотой 1. Поскольку X / n и Y / n асимптотически нормально распределяются с помощью CLT, наши результаты получены на основе применения дельта-метода .
Непараметрическая оценка плотности Приложение :
Моменты распределения статистики первого порядка можно использовать для разработки непараметрической оценки плотности. [10] Предположим, мы хотим оценить плотность в точку . Рассмотрим случайные величины , которые являются iid с функцией распределения . В частности, .





Ожидаемое значение статистики первого порядка дали образец общая доходность наблюдений,



где - функция квантиля, связанная с распределением , и . Это уравнение в сочетании с методом складного ножа становится основой для следующего алгоритма оценки плотности:



Input: A sample of observations. points of density evaluation. Tuning parameter (usually 1/3). Output: estimated density at the points of evaluation.



1: Set 2: Set 3: Create an matrix which holds subsets with observations each. 4: Create a vector to hold the density evaluations. 5: for do 6: for do 7: Find the nearest distance to the current point within the th subset 8: end for 9: Compute the subset average of distances to 10: Compute the density estimate at 11: end for 12: return














В отличие от параметров настройки на основе полосы пропускания/длины для подходов на основе гистограммы и ядра , параметром настройки для оценки плотности на основе статистики порядка является размер подмножеств выборки. Такая оценка более надежна, чем подходы, основанные на гистограмме и ядре, например, такие плотности, как распределение Коши (в котором отсутствуют конечные моменты), можно вывести без необходимости специальных модификаций, таких как пропускная способность на основе IQR . Это связано с тем, что первый момент статистики порядка всегда существует, если существует ожидаемое значение базового распределения, но обратное не обязательно верно. [11]
Работа с дискретными переменными [ править ]
Предполагать являются iid случайными величинами из дискретного распределения с кумулятивной функцией распределения и функция массы вероятности . Чтобы найти вероятности статистика порядка, сначала нужны три значения, а именно




Кумулятивная функция распределения Статистику порядка можно вычислить, отметив, что

Сходным образом, дается


Обратите внимание, что функция массы вероятности это просто разница этих значений, то есть


Вычисление статистики заказов [ править ]
Задача вычисления k -го наименьшего (или наибольшего) элемента списка называется проблемой выбора и решается с помощью алгоритма выбора. Хотя эта проблема сложна для очень больших списков, были созданы сложные алгоритмы выбора, которые могут решить эту проблему за время, пропорциональное количеству элементов в списке, даже если список совершенно неупорядочен. Если данные хранятся в определенных специализированных структурах данных, это время можно сократить до O(log n ). Во многих приложениях требуется вся статистика по порядку, и в этом случае можно использовать алгоритм сортировки , а затрачиваемое на это время составляет O( n log n ).
См. также [ править ]
- Ранкит
- Коробочный сюжет
- BRS-неравенство
- Сопутствующее (статистика)
- Распределение Фишера – Типпета
- Теорема Бапата–Бега о порядковой статистике независимых, но не обязательно одинаково распределенных случайных величин.
- Полином Бернштейна
- L-оценщик - линейные комбинации статистики заказов
- Распределение по рангам
- Алгоритм выбора
Примеры статистики заказов [ править ]
- Примерный максимум и минимум
- Квантиль
- процентиль
- Дециль
- Квартиль
- медиана
- Иметь в виду
- Выборочное среднее и ковариация
Эта статья включает список общих ссылок , но в ней отсутствуют достаточные соответствующие встроенные цитаты . ( декабрь 2010 г. ) |
Ссылки [ править ]
- ^ Дэвид, ХА; Нагараджа, Х.Н. (2003). Статистика заказов . Ряд Уайли по вероятности и статистике. дои : 10.1002/0471722162 . ISBN 9780471722168 .
- ^ Казелла, Джордж; Бергер, Роджер (2002). Статистический вывод (2-е изд.). Cengage Обучение. п. 229. ИСБН 9788131503942 .
- ^ Jump up to: Перейти обратно: а б Джентл, Джеймс Э. (2009), Вычислительная статистика , Springer, стр. 63, ISBN 9780387981444 .
- ^ Джонс, MC (2009), «Распределение Кумарасвами: распределение бета-типа с некоторыми преимуществами управляемости», Статистическая методология , 6 (1): 70–81, doi : 10.1016/j.stamet.2008.04.001 ,
Как хорошо известно , бета-распределение — это распределение статистики m -го порядка из случайной выборки размера n из равномерного распределения (по (0,1)).
- ^ Дэвид, ХА; Нагараджа, Х.Н. (2003), «Глава 2. Основная теория распределения», Статистика порядков , Ряды Вили по вероятности и статистике, стр. 9, дои : 10.1002/0471722162.ch2 , ISBN 9780471722168
- ^ Реньи, Альфред (1953). «К теории порядковой статистики» . Acta Mathematica Hungarica . 4 (3): 191–231. дои : 10.1007/BF02127580 .
- ^ Глинка, М.; Брилл, штат Пенсильвания; Хорн, В. (2010). «Метод получения преобразований Лапласа порядковой статистики случайных величин Эрланга». Статистика и вероятностные буквы . 80 : 9–18. дои : 10.1016/j.spl.2009.09.006 .
- ^ Мостеллер, Фредерик (1946). «О некоторой полезной «неэффективной» статистике» . Анналы математической статистики . 17 (4): 377–408. дои : 10.1214/aoms/1177730881 . Проверено 26 февраля 2015 г.
- ^ М. Кардоне, А. Дитсо и К. Раш, «Энтропийная центральная предельная теорема для статистики заказов», в IEEE Transactions on Information Theory, vol. 69, нет. 4, стр. 2193–2205, апрель 2023 г., doi: 10.1109/TIT.2022.3219344.
- ^ Гарг, Викрам В.; Тенорио, Луис; Уиллкокс, Карен (2017). «Оценка минимальной локальной плотности расстояний». Коммуникации в статистике - теория и методы . 46 (1): 148–164. arXiv : 1412.2851 . дои : 10.1080/03610926.2014.988260 . S2CID 14334678 .
- ^ Дэвид, ХА; Нагараджа, Х.Н. (2003), «Глава 3. Ожидаемые значения и моменты», Статистика заказов , Ряды Вили в вероятности и статистике, стр. 34, номер домена : 10.1002/0471722162.ch3 , ISBN 9780471722168
Внешние ссылки [ править ]
- Заказать статистику на PlanetMath . Проверено 2 февраля 2005 г.
- Вайсштейн, Эрик В. «Статистика заказов» . Математический мир . Проверено 2 февраля 2005 г.
- исходного кода C++ Статистика динамического порядка
| |||||||||||||||||||||||||||