Грамматика ID/LP
Грамматики ID/LP представляют собой подмножество грамматик фразовой структуры , отличающееся от других формальных грамматик различием между ограничениями непосредственного доминирования (ID) и линейного приоритета (LP). В то время как традиционные правила структуры фраз объединяют доминирование и приоритет в одном правиле, грамматики ID/LP поддерживают отдельные наборы правил, которые не нужно обрабатывать одновременно. Грамматики ID/LP используются в компьютерной лингвистике .
Например, типичное правило построения фразы, такое как , что указывает на то, что S-узел доминирует над NP-узлом и VP-узлом и что NP предшествует VP в поверхностной строке. В грамматиках ID/LP это правило будет указывать только на доминирование и оператор линейного приоритета, например: , тоже будет дано.


Идея впервые стала известна как часть грамматики обобщенной фразовой структуры ; [1] [2] подход ID/LP Grammar также используется в грамматике структуры фраз, управляемой головой , [3] лексическая функциональная грамматика и другие унификационные грамматики .
Текущая работа в рамках Минималистской программы также пытается провести различие между доминированием и упорядочением. Например, в недавних работах Ноама Хомского предположено, что, хотя иерархическая структура является результатом операции построения синтаксической структуры Merge , линейный порядок не определяется этой операцией, а является просто результатом экстернализации (устного произношения, или, в в случае языка жестов — ручное подписание). [4] [5] [6]
Определение доминирования и приоритета
[ редактировать ]Немедленное доминирование
[ редактировать ]Непосредственное доминирование — это асимметричные отношения между материнским узлом дерева разбора и его дочерними узлами, при которых материнский узел (слева от стрелки) немедленно доминирует над дочерними узлами (справа от стрелки), но дочери не сразу доминируют над матерью. Над дочерними узлами также доминирует любой узел, который непосредственно доминирует над материнским узлом, однако это не является немедленным отношением доминирования.
Например, контекстно-свободное правило , показывает, что узел с меткой A (материнский узел) немедленно доминирует над узлами с метками B, C и D (дочерние узлы), а узлы с метками B, C и D могут немедленно доминировать узлом с меткой A.


Линейный приоритет
[ редактировать ]Линейный приоритет — это порядок отношений сестринских узлов. Ограничения LP определяют, в каком порядке могут появляться сестринские узлы под одной материнской платой. Узлы, которые появляются раньше в строках, предшествуют своим сестрам. [2] ЛП можно отобразить в правилах построения фраз в виде это означает, что B предшествует C предшествует D, как показано в дереве ниже.

Правило, имеющее ограничения ID, но не LP, записывается с запятыми между дочерними узлами, например . Поскольку для дочерних узлов не существует фиксированного порядка, вполне возможно, что все три показанных здесь дерева генерируются по этому правилу.

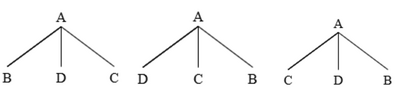
Альтернативно, эти отношения могут быть выражены через операторы линейного приоритета, такие как , что означает, что каждый раз, когда B и C являются сестрами, B должно предшествовать C. [2] [7]

что если К отношениям LP можно применить принцип транзитивности, который означает, и , затем также. Отношения LP асимметричны: если B предшествует C, C никогда не может предшествовать B. Отношения LP, в которых не может быть промежуточных узлов, называются непосредственным приоритетом, тогда как отношения LP, в которых могут быть промежуточные узлы (те, которые получены из принципа транзитивности), являются Говорят, что он имеет слабый приоритет. [8]


Грамматичность в грамматиках ID/LP
[ редактировать ]Чтобы строка была грамматической в грамматике ID/LP, она должна принадлежать локальному поддереву , которое соответствует хотя бы одному правилу ID и всем операторам LP грамматики. Если каждая возможная строка, сгенерированная грамматикой, соответствует этому критерию, то это грамматика ID/LP. Кроме того, чтобы грамматику можно было записать в формате ID/LP, она должна обладать свойством исчерпывающего постоянного частичного упорядочения (ECPO): а именно, чтобы по крайней мере часть отношений ID/LP в одном правиле соблюдалась во всех других правилах. правила. [2] Например, набор правил:
(1)
(2)

не обладает свойством ECPO, поскольку (1) говорит, что C всегда должно предшествовать D, а (2) говорит, что D всегда должно предшествовать C.
Преимущества грамматик ID/LP
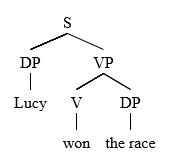
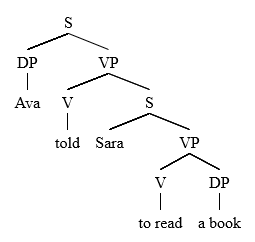
[ редактировать ]Поскольку операторы LP применяются независимо от контекста правила ID, они позволяют нам делать обобщения по всей грамматике. [2] [7] Например, учитывая утверждение LP , где V является главой VP, это означает, что в любом предложении в любом предложении V всегда будет появляться перед своей сестрой DP. [7] в любом контексте, как показано в следующих примерах.

Люси выиграла гонку.
Ава посоветовала Саре прочитать книгу.
Это можно обобщить до правила, действующего для всего английского языка. , где X — начало любой фразы, а YP — ее дополнение . Грамматики, не относящиеся к ID/LP, не способны делать такие обобщения по всей грамматике и поэтому должны повторять ограничения порядка для каждого отдельного контекста. [7]

Отделение требований LP от правил ID также объясняет феномен свободного порядка слов в естественном языке. Например, в английском языке можно поставить наречия до или после глагола, и обе строки будут грамматическими. [7]
Джон внезапно вскрикнул. Джон внезапно вскрикнул .
Традиционное правило PS потребует двух отдельных правил, но это можно описать одним правилом ID/LP. Это свойство грамматик ID/LP позволяет упростить межлингвистические обобщения, описывая специфические языковые различия в порядке составляющих с помощью операторов LP отдельно от правил ID, которые аналогичны для разных языков. [7]

Разбор грамматик ID/LP
[ редактировать ]Для анализа грамматик ID/LP используются два алгоритма синтаксического анализа: анализатор Эрли и алгоритм Шибера. [9]
Эрли Парсер в грамматиках ID/LP
[ редактировать ]Правила ID и LP накладывают ограничения на строки предложений; [9] при работе с большими строками, [9] ограничения этих правил могут привести к тому, что анализируемая строка станет бесконечной, что затруднит синтаксический анализ. Earley Parser решает эту проблему, изменяя [10] формат грамматики ID/LP в контекстно-свободную грамматику (CFG), разделяющий грамматику ID/LP на упорядоченную контекстно-свободную грамматику (CFG) и неупорядоченную контекстно-свободную грамматику (UCFG). Это позволяет двум алгоритмам более эффективно анализировать строки; [9] в частности, Earley Parser использует метод отслеживания точек, который следует линейному пути, установленному правилами LP. [9] В CFG правила LP не допускают повторяющихся составляющих в анализируемой строке, но UCFG допускает повторяющиеся составляющие в анализируемой строке. [9] Если грамматика ID/LP преобразуется в UCFG, то правила LP не доминируют в процессе анализа, однако все равно следуют методу отслеживания точек.
Анализ Эрли в CFG
[ редактировать ]После того как грамматика ID/LP будет преобразована в эквивалентную форму в CFG, алгоритм проанализирует строку. Позволять стоять на старте и обозначают элементы строки, а также представляют синтаксические категории . Затем алгоритм анализирует строку и определяет следующее:


- Исходное положение точки; обычно он начинается с крайнего левого элемента строки.
- Текущее положение точки; это предсказывает следующий элемент.
- Изготовление готовой струны. [9]
(1)

(2) ( прогнозируется)


(3)

Проанализированные строки затем используются вместе для формирования списка синтаксического анализа. [10] например:

список которых поможет определить, завершен ли производственный элемент ( ) принимается в основной строке. Для этого он проверяет, найдены ли созданные отдельные строки в списке синтаксического анализа. Если одна или все отдельные строки не найдены в списке анализа, то вся строка завершится ошибкой. Если одна или все отдельные строки найдены в списке анализа, то будет принята вся строка. [10]

Эрли-парсинг в UCFG
[ редактировать ]UCFG является подходящим эквивалентом для преобразования грамматики ID/LP в целях использования анализатора Earley. [9] Этот алгоритм читает строки аналогично тому, как он анализирует CFG, однако в этом случае порядок элементов не соблюдается; что приводит к отсутствию соблюдения правил LP. Это позволяет повторять некоторые элементы в анализируемых строках, а UCFG принимает пустые мультинаборы вместе с заполненными мультинаборами в своих строках. [9] Например:
- Исходное положение точки; оно находится между пустым и заполненным множеством.
- Текущая позиция точки, которая предсказывает следующий набор; элемент, который передала точка, переместится в пустой набор.
- Изготовление готовой струны. В этом случае положение двух наборов в исходной позиции поменяется местами; заполненное множество находится на левом краю, а пустое множество — на правом. [9]
(1)

(2) ( прогнозируются)


(3)

При анализе строки, содержащей несколько неупорядоченных элементов, Earley Parser обрабатывает ее как перестановку Y! и генерирует каждую строку индивидуально вместо использования одной строки для представления повторяющихся анализируемых строк. [9] Всякий раз, когда точка перемещается над одним элементом, алгоритм начинает генерировать анализируемые строки элементов на правом краю в случайных позициях до тех пор, пока в наборе правого края больше не останется элементов. Пусть X 0 представляет исходную строку, а X 1 — первую проанализированную строку; например:
![{\displaystyle \mathrm {X} _{0}:[\mathrm {X} \longrightarrow \{\}\cdot \{t,v,w,z\},0]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/999c405f60d02257cec0f65e8316183f0eba3a64)
![{\displaystyle \mathrm {X} _{1}:[\mathrm {X} \longrightarrow \{t\}\cdot \{v,w,z\},0]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/42d65c4a57770fc4b70e9df1289f8db857432d9c)
строка X 1 выдаст 3! = 6, разные анализируемые строки набора правых ребер:
(1) (4)
![{\displaystyle [\mathrm {X} \longrightarrow t.vwz,0]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/7c66d2b655fad0954b865e30ccb0a3fcc9a9097f)
![{\displaystyle [\mathrm {X} \longrightarrow t.zvw,0]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/deeeb2a25aa7d7ac6b7788637e339c9fca168763)
(2) (5)
![{\displaystyle [\mathrm {X} \longrightarrow t.vzw,0]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/ee68b634544148645602bb83487862f772eca48f)
![{\displaystyle [\mathrm {X} \longrightarrow t.wvz,0]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/1ec9c119269d3840c15f1c4a66151a5e02666ec9)
(3) (6)
![{\displaystyle [\mathrm {X} \longrightarrow t.zwv,0]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/bbd30b7ffcea4e7e3a54126e9d0184e38dbaa421)
![{\displaystyle [\mathrm {X} \longrightarrow t.wzv,0]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/747b9b9dbf1d282351acee98511668960aefd21d)
Earley Parser применяет каждую строку к отдельным правилам грамматики. [9] и это приводит к очень большим наборам. Большие наборы частично приводят к преобразованию грамматики ID/LP в эквивалентную грамматику, однако анализ всей грамматики ID/LP с самого начала затруднен. [9]
Алгоритм Шибера
[ редактировать ]Основа алгоритма Шибера [9] основан на Earley Parser для CFG, [10] однако он не требует преобразования грамматики ID/LP в другую грамматику. [10] для того, чтобы быть разобранным. Правила ID можно анализировать в отдельной форме, S → ID {V, NP, S}, из правил LP, V < S. [10] Шибер сравнил анализ CFG с упорядоченной строкой грамматики ID/LP, а Бартон сравнил анализ UCFG с неупорядоченной строкой грамматики ID/LP.
Прямой анализ упорядоченной грамматики ID/LP
[ редактировать ]Непосредственный анализ грамматики ID/LP генерирует список наборов, который будет определять, будет ли создание строки принято или ошибочно. Алгоритм состоит из 6 шагов (используемые символы также могут обозначать синтаксические категории):
- Для всех правил идентификатора добавьте к начальному элементу в списке разбора, . [10]
- Если все элементы в , и элементы, , из не позволяет предшествовать Z , , и Z не является элементом , ; затем следующая строка, можно добавить в .
- Если все предметы, , являются элементами , затем , и и все то в этот список можно добавить следующий элемент, .
- На этом этапе будет построен сет-лист, , более. Каждый предмет, , это элемент и где , и затем добавляется следующий элемент: , к .
- Если предметы, , являются элементами и предметы, , являются элементами где , и ; строка, , добавляется к .
- Если предметы, , является элементом где , и ; строка, , добавляется к .
![{\displaystyle [S,\mathrm {T},\beta,0]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/ab8c6117dd1e5a820e874cbca03efd60d1c4085f)

![{\displaystyle [\mathrm {Z},\лямбда,\тета,0]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/36093b39724c82c18b63c1e6ef6f9f759b16fa58)
![{\displaystyle [\mathrm {A},\альфа,\{Z\}\чашка \бета,0]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/ba08939ce70f3f831f1b7da30dbdd8a65bc6d0e3)


![{\displaystyle [\mathrm {A},\альфа Z,\бета,0]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/8a299b56735dceafc726a12a747d647b36349446)

![{\displaystyle [Z,T,\lambda,0]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/d032a702b7a4a0e235026340d7277f7869c42e7f)

![{\displaystyle [А,\альфа,\{q\}\чашка \бета,я]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/67a6cbd6d3e18e5255f0869502fcf01fa8e0eb2d)




![{\displaystyle [A,\alpha q,\beta,i]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/1b28aa563a2883780d08f5e057442b721677b433)
![{\displaystyle [Z,\лямбда,\тета,я]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/44c28f66f861565e20a67c3a7fcd32152c0ff51e)
![{\displaystyle [A,\alpha \{Z\}\чашка \beta,k]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/e87ee9ed6d6d5767f4f339871123d5ad31d94f3f)

![{\displaystyle [A,\alpha Z,\beta,k]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/47978e333cf1e7867b7e9a498ddf6a2227007f2e)
![{\displaystyle [A,\альфа,\{Z\}\чашка \бета,я]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/8a4bbfd36cdae9ad01f6256aeef753c55c82b9a4)
![{\displaystyle [Z,T,\lambda,n]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/42f86f143848ce9486ca8ceb1a03677c9ab1026f)
Шаги 2-3 повторяются до конца. [10] до тех пор, пока новые элементы не перестанут добавляться, а затем перейдите к шагу 4. Шаги 5–6 также полностью повторяются. [10] до тех пор, пока в сет-лист не будет добавлено больше новых элементов. Строка будет принята, если строка ведет себя или напоминает продукцию, является элементом . [10] Например:
![{\displaystyle [S,\альфа,\тета,0]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/8e6362ca84a93ea615d455a13210dd701c1c4508)




| Сет-листы | Предметы |
|---|---|
![{\displaystyle [S,T,\{C,D,F\},0],}](https://wikimedia.org/api/rest_v1/media/math/render/svg/97e8060f30ab7ca6e55817a59deb38112b72a854)
![{\displaystyle [C,T,\{c\},0],}](https://wikimedia.org/api/rest_v1/media/math/render/svg/18690765bb4303dbb178a17078cd2e4894c0ea27)
![{\displaystyle [F,T,\{f\},0]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/589c48e8ceef990e2d6fa1f4c722623cb96727a2)

![{\displaystyle [C,c,\emptyset,0],}](https://wikimedia.org/api/rest_v1/media/math/render/svg/f5b028bee6384fb695cb9c812cb755798f3d349a)
![{\displaystyle [S,C,\{D,F\},0],}](https://wikimedia.org/api/rest_v1/media/math/render/svg/9d6f8690e1cbd443b7e5658eb74e1bae26a17c19)
![{\displaystyle [D,T,\{d\},1],}](https://wikimedia.org/api/rest_v1/media/math/render/svg/be4e218c85cc1fbeacbb4a9c669df29ab627c6c4)
![{\displaystyle [F,T,\{f\},1]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/b15858d831d23b409b1b9f7599c0a09f42275912)

![{\displaystyle [F,f,\emptyset,1],}](https://wikimedia.org/api/rest_v1/media/math/render/svg/a7530d47d46c576f69f15bb90c799adf664444ac)
![{\displaystyle [S,CF,\{D\},0],}](https://wikimedia.org/api/rest_v1/media/math/render/svg/5136538387f45326f16b153cf0726478e49d0956)
![{\displaystyle [D,T,\{d\},2]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/8bb3aba8317a6b29e481197cc3d8dd86ec5d8de1)

![{\displaystyle [D,d,\emptyset,2],}](https://wikimedia.org/api/rest_v1/media/math/render/svg/ccc42538f31413f1f6c400c217edee1a1ce36e98)
![{\displaystyle [S,CDF,\emptyset,0]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/f4dee533569f2d4d17dd4532a4a469535fe70741)
Полное производство принимается и создает следующую производственную строку: . [10]

![{\displaystyle [S,CDF,\emptyset,0],}](https://wikimedia.org/api/rest_v1/media/math/render/svg/dd518da0300fda376d9a601fba5dbbd2ffcd3a0a)
![{\displaystyle [_{S}[_{C}c][_{D}d][_{F}f]]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/d0a116ae310ba6186dc76369a45611e9b8f53971)
Прямой анализ неупорядоченной грамматики ID/LP
[ редактировать ]Неупорядоченная грамматика ID/LP использует описанный выше шестишаговый алгоритм для анализа строк. Заметная разница заключается в постановке каждого сет-листа; есть одна строка, которая представляет множество отдельных строк в одном списке. [9] В таблице ниже показан список настроек Таблицы 1.0. в неупорядоченной грамматике:
| Сет-лист | Предметы |
|---|---|
![{\displaystyle [S,T,C\cdot d,f,\emptyset,0]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/e3afb806e4f5b0e7baf268edc4befd6415495555)
![{\displaystyle [S,T\cdot c,d,f,\emptyset,0]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/2dd9806f1cc34377067ca343ccce95c56c4fa11c)
![{\displaystyle [S,T,C,d\cdot F,\emptyset,0]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/261f144061b8362ecc3a3f48714deb369a3b0bcd)
![{\displaystyle [S,T,C,D,F\cdot \emptyset,0]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/fb9d9d1a6686eaec190adaed1be0baec40e349a5)
Полная производственная цепочка, в результате получается строка, аналогичная упорядоченной грамматике ID/LP; однако порядок элементов в строке не соблюдается. Окончательная строка принимается, если она соответствует элементам исходной строки.
![{\displaystyle [S,T,C,D,F\cdot \emptyset,0],}](https://wikimedia.org/api/rest_v1/media/math/render/svg/6556c6966673b75a255651ac4ee43c0f9c007d25)
Обратите внимание, что неупорядоченная версия грамматики ID/LP содержит гораздо меньше строк, чем UCFG; Алгоритм Шибера использует одну строку для представления нескольких разных строк для повторяющихся элементов. Оба алгоритма могут одинаково анализировать упорядоченные грамматики, однако алгоритм Шибера кажется более эффективным. [9] при анализе неупорядоченной грамматики.
См. также
[ редактировать ]Ссылки
[ редактировать ]- ^ Газдар, Джеральд; Пуллум, Джеффри К. (1981). «Подкатегоризация, порядок составляющих и понятие «голова» ». В М. Моортгате; Хвд Хюлст; Т. Хукстра (ред.). Область применения лексических правил . стр. 107–124. ISBN 9070176521 .
- ^ Jump up to: а б с д и Газдар, Джеральд; Юэн Х. Кляйн; Джеффри К. Пуллум; Иван А. Саг (1985). Грамматика обобщенной структуры фразы . Оксфорд: Блэквелл и Кембридж, Массачусетс: Издательство Гарвардского университета. ISBN 0-674-34455-3 .
- ^ Дэниелс, Майк; Мёрерс, Детмар (2004). «GIDLP: грамматический формат для HPSG на основе линеаризации» (PDF) . Материалы одиннадцатой Международной конференции по грамматике фразовых структур, управляемых головой . дои : 10.21248/hpsg.2004.5 . S2CID 17009554 .
- ^ Хомский, Ноам (2007). «Биолингвистические исследования: дизайн, развитие, эволюция». Международный журнал философских исследований . 15 (1): 1–21. дои : 10.1080/09672550601143078 . S2CID 144566546 .
- ^ Хомский, Ноам (2011). «Язык и другие когнитивные системы. Что особенного в языке?». Изучение и развитие языка . 7 (4): 263–278. дои : 10.1080/15475441.2011.584041 . S2CID 122866773 .
- ^ Бервик, Роберт С.; и др. (2011). «Возвращение к бедности стимулов» . Когнитивная наука . 35 (7): 1207–1242. дои : 10.1111/j.1551-6709.2011.01189.x . ПМИД 21824178 .
- ^ Jump up to: а б с д и ж Беннетт, Пол (1995). Курс грамматики обобщенной фразовой структуры . Лондон: UCL Press. ISBN 1-85728-217-5 .
- ^ Дэниэлс, М. (2005). Обобщенная грамматика ID/LP: формализм для анализа грамматик HPSG на основе линеаризации . (Электронная диссертация или диссертация). Получено с https://etd.ohiolink.edu/.
- ^ Jump up to: а б с д и ж г час я дж к л м н тот п Бартон-младший, Дж. Эдвард (1985). «О сложности разбора ID/LP» . Компьютерная лингвистика . 11 (4): 205–218 – через Ассоциацию компьютерной лингвистики.
- ^ Jump up to: а б с д и ж г час я дж к л Шибер, Стюарт М. (1983). «Прямой анализ грамматик ID/LP» . Языкознание и философия . 7 (2): 1–30 – через SRI International.