Выравнивание битового текста
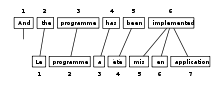
Выравнивание битового текста или просто выравнивание слов — это задача обработки естественного языка , заключающаяся в выявлении переводческих отношений между словами (или, реже, многословными единицами) в битексте словами . , в результате чего между двумя сторонами битекста образуется двудольный граф с дугой между двумя тогда и только тогда, когда они являются переводами друг друга. Выравнивание слов обычно выполняется после того, как при выравнивании предложений уже были идентифицированы пары предложений, которые являются переводами друг друга.
Выравнивание битового текста является важной вспомогательной задачей для большинства методов статистического машинного перевода . Параметры статистических моделей машинного перевода обычно оцениваются путем наблюдения за битовыми текстами, выровненными по словам. [1] и наоборот, автоматическое выравнивание слов обычно выполняется путем выбора того выравнивания, которое лучше всего соответствует модели статистического машинного перевода. Круговое применение этих двух идей приводит к созданию алгоритма максимизации ожидания . [2]
Этот подход к обучению является примером неконтролируемого обучения , при котором системе не предоставляются примеры желаемого результата, а она пытается найти значения для ненаблюдаемой модели и выравниваний, которые лучше всего объясняют наблюдаемый битекст. Недавняя работа началась с изучения контролируемых методов, которые основаны на предоставлении системе (обычно небольшого) количества выровненных вручную предложений. [3] В дополнение к преимуществам дополнительной информации, предоставляемой контролем, эти модели, как правило, также могут более легко использовать преимущества объединения многих функций данных, таких как контекст, синтаксическая структура , часть речи или о лексиконе перевода информация . которые трудно интегрировать в традиционно используемые генеративные статистические модели . [ нужна ссылка ]
Помимо обучения систем машинного перевода, другие применения выравнивания слов включают переводческой лексики индукцию , обнаружение смысла слова , устранение смысловой неоднозначности и межъязыковое проецирование лингвистической информации.
Обучение
[ редактировать ]Модели IBM
[ редактировать ]Модели IBM [4] используются в статистическом машинном переводе для обучения модели перевода и модели выравнивания. Они являются примером алгоритма ожидания-максимизации : на этапе ожидания вычисляются вероятности перевода внутри каждого предложения, на этапе максимизации они суммируются до глобальных вероятностей перевода. Функции:
- Модель IBM 1: вероятности лексического выравнивания
- Модель IBM 2: абсолютные позиции
- IBM Model 3: плодородие (поддерживает вставки)
- Модель IBM 4: относительные позиции
- IBM Model 5: исправляет недостатки (гарантирует, что никакие два слова не могут быть выровнены по одной и той же позиции)
ХМ
[ редактировать ]Фогель и др. [5] разработал подход, включающий вероятности лексического перевода и относительное выравнивание, отображая проблему в скрытой марковской модели . Состояния и наблюдения представляют собой исходные и целевые слова соответственно. Вероятности перехода моделируют вероятности выравнивания. При обучении вероятности перевода и выравнивания можно получить из и в алгоритме вперед-назад .


Программное обеспечение
[ редактировать ]- GIZA++ (свободное программное обеспечение под лицензией GPL)
- Наиболее широко используемый набор инструментов для выравнивания, реализующий известные модели IBM с множеством улучшений.
- Berkeley Word Aligner (бесплатное программное обеспечение под лицензией GPL)
- Еще один широко используемый механизм выравнивания, реализующий выравнивание по соглашению, и дискриминационные модели выравнивания.
- Нил (свободное программное обеспечение под лицензией GPL)
- Контролируемый выравниватель слов, который может использовать синтаксическую информацию на исходной и целевой стороне.
- pialign (бесплатное программное обеспечение под лицензией Common Public License)
- Средство выравнивания, которое выравнивает слова и фразы с использованием байесовских грамматик обучения и инверсионной трансдукции.
- Natura Alignment Tools (NATools, бесплатное программное обеспечение под лицензией GPL)
- UNL aligner (бесплатное программное обеспечение под лицензией Creative Commons Attribution 3.0 Unported License)
- Геометрическое картографирование и выравнивание (GMA) (бесплатное программное обеспечение под лицензией GPL)
- HunAlign (бесплатное программное обеспечение под лицензией LGPL-2.1)
- Anymalign (свободное программное обеспечение под лицензией GPL)
Ссылки
[ редактировать ]- ^ П. Ф. Браун и др. 1993. Математика статистического машинного перевода: оценка параметров. Архивировано 24 апреля 2009 года в Wayback Machine . Компьютерная лингвистика, 19(2):263–311.
- ^ Ох, Ф.Дж., Тиллманн, К., Ней, Х. и другие, 1999, Улучшенные модели выравнивания для статистического машинного перевода , Proc. Объединенной конференции SIGDAT. по эмпирическим методам обработки естественного языка и очень большим корпусам
- ^ ACL 2005: Создание и использование параллельных текстов для языков с ограниченными ресурсами. Архивировано 9 мая 2009 г., на Wayback Machine.
- ^ Филипп Коэн (2009). Статистический машинный перевод . Издательство Кембриджского университета. п. 86 и след. ISBN 978-0521874151 . Проверено 21 октября 2015 г.
- ^ С. Фогель, Х. Ней и К. Тиллманн. 1996. Выравнивание слов на основе HMM в статистическом переводе. Архивировано 2 марта 2018 г. в Wayback Machine . В COLING '96: 16-я Международная конференция по компьютерной лингвистике, стр. 836-841, Копенгаген, Дания.