Скрытая модель Маркова
Скрытая марковская модель ( HMM ) — это марковская модель , в которой наблюдения зависят от скрытого (или «скрытого») марковского процесса (называемого ). HMM требует, чтобы существовал наблюдаемый процесс. результаты которых зависят от результатов известным способом. С невозможно наблюдать непосредственно, цель состоит в том, чтобы узнать о состоянии наблюдая По определению модели Маркова, HMM имеет дополнительное требование, чтобы результат во время должен «влиять» исключительно на результат в и что результаты и в должна быть условно независимой от в данный во время Оценка параметров в HMM может быть выполнена с использованием метода максимального правдоподобия . Для линейных цепных HMM алгоритм Баума – Уэлча для оценки параметров можно использовать .






Скрытые марковские модели известны своими приложениями в термодинамике , статистической механике , физике , химии , экономике , финансах , обработке сигналов , теории информации , распознавании образов , таких как речь , [1] почерк , распознавание жестов , [2] маркировка частей речи , отслеживание музыкальной партитуры, [3] частичные разряды [4] и биоинформатика . [5] [6]
Определение [ править ]
Позволять и с дискретным временем быть случайными процессами и . Пара является скрытой марковской моделью, если




- представляет собой марковский процесс , поведение которого не наблюдается непосредственно («скрыто»);

- для каждого и каждое Бореля множество .



Позволять и быть непрерывными во времени случайными процессами. Пара является скрытой марковской моделью, если



- представляет собой марковский процесс, поведение которого не наблюдается непосредственно («скрыто»);
- ,

- для каждого каждый набор Бореля и каждое семейство борелевских множеств



Терминология [ править ]
Состояния процесса (соответственно называются скрытыми состояниями , а (соответственно называется вероятностью выброса или вероятностью выхода .



Примеры [ править ]
[ править ]
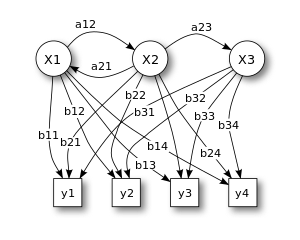
Х — состояния
y — возможные наблюдения
а — вероятности перехода состояний
б — вероятности выхода
В своей дискретной форме скрытый марковский процесс можно представить как обобщение задачи об урне с заменой (когда каждый предмет из урны возвращается в исходную урну перед следующим шагом). [7] Рассмотрим такой пример: в комнате, невидимой для наблюдателя, живет джинн. В комнате находятся урны X1, X2, X3, ... каждая из которых содержит известную смесь шаров, причем каждый шар имеет уникальную метку y1, y2, y3, ... . Джинн выбирает урну в этой комнате и случайным образом достает из нее шар. Затем он помещает шар на конвейерную ленту, где наблюдатель может наблюдать последовательность шаров, но не последовательность урн, из которых они были извлечены. У джинна есть определенная процедура выбора урн; выбор урны для n -го шара зависит только от случайного числа и выбора урны для ( n - 1)-го шара. Выбор урны не зависит напрямую от урн, выбранных перед этой единственной предыдущей урной; поэтому это называется марковским процессом . Его можно описать верхней частью рисунка 1.
Сам марковский процесс наблюдать нельзя, только последовательность помеченных шаров, поэтому такое расположение называется «скрытым марковским процессом». Это иллюстрирует нижняя часть диаграммы, показанной на рисунке 1, где видно, что шары y1, y2, y3, y4 могут быть нарисованы в каждом состоянии. Даже если наблюдатель знает состав урн и только что наблюдал последовательность из трех шаров, например, y1, y2 и y3 на конвейерной ленте, наблюдатель все равно не может быть уверен, какую урну ( т. е . в каком состоянии) нарисовал джинн. третий мяч из. Однако наблюдатель может получить и другую информацию, например, вероятность того, что третий шар выпал из каждой из урн.
Игра «Угадай погоду» [ править ]
Рассмотрим двух друзей, Алису и Боба, которые живут далеко друг от друга и ежедневно разговаривают по телефону о том, что они сделали в тот день. Боба интересуют только три занятия: прогулка в парке, шопинг и уборка в квартире. Выбор того, чем заняться, определяется исключительно погодой в данный день. Алиса не имеет точной информации о погоде, но знает общие тенденции. Основываясь на том, что Боб рассказывает ей, что он делал каждый день, Алиса пытается угадать, какая должна была быть погода.
Алиса считает, что погода действует как дискретная цепь Маркова . Есть два состояния, «Дождливое» и «Солнечное», но она не может наблюдать их непосредственно, то есть они скрыты от нее. Каждый день есть определенный шанс, что Боб выполнит одно из следующих действий, в зависимости от погоды: «гулять», «ходить по магазинам» или «убираться». Поскольку Боб рассказывает Алисе о своей деятельности, это и есть наблюдения . Вся система представляет собой скрытую марковскую модель (СММ).
Алиса знает общие тенденции погоды в этом районе и то, что в среднем любит делать Боб. Другими словами, параметры ГММ известны. их можно представить следующим образом В Python :
states = ("Rainy", "Sunny")
observations = ("walk", "shop", "clean")
start_probability = {"Rainy": 0.6, "Sunny": 0.4}
transition_probability = {
"Rainy": {"Rainy": 0.7, "Sunny": 0.3},
"Sunny": {"Rainy": 0.4, "Sunny": 0.6},
}
emission_probability = {
"Rainy": {"walk": 0.1, "shop": 0.4, "clean": 0.5},
"Sunny": {"walk": 0.6, "shop": 0.3, "clean": 0.1},
}
В этом фрагменте кода start_probability представляет мнение Алисы о том, в каком состоянии находится HMM, когда Боб впервые звонит ей (все, что она знает, это то, что в среднем идет дождь). Используемое здесь конкретное распределение вероятностей не является равновесным, которое (с учетом вероятностей перехода) приблизительно равно {'Rainy': 0.57, 'Sunny': 0.43}. transition_probability представляет изменение погоды в основной цепи Маркова. В этом примере вероятность того, что завтра будет солнечно, составляет всего 30%, если сегодня дождливо. emission_probability показывает, насколько вероятно, что Боб будет выполнять определенное действие каждый день. Если идет дождь, то с вероятностью 50% он убирает свою квартиру; если солнечно, вероятность того, что он вышел на прогулку, составляет 60%.

Подобный пример подробно описан на странице алгоритма Витерби .
архитектура Структурная
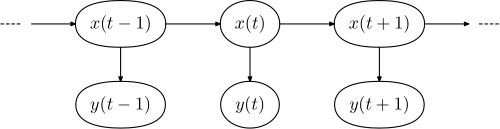
На диаграмме ниже показана общая архитектура экземпляра HMM. Каждый овал представляет собой случайную величину, которая может принимать любое из множества значений. Случайная величина x ( t это скрытое состояние в момент времени t (в модели из приведенной выше диаграммы x ( t ) ∈ { , x1 x2 , ) — x3 } ) . Случайная величина y ( t это наблюдение в момент времени ( где ( t ) ∈ { , y1 y2 , y y3 , ) — y4 } t ). Стрелки на диаграмме (часто называемой решетчатой диаграммой ) обозначают условные зависимости.
Из диаграммы видно, что условное распределение вероятностей скрытой переменной x ( t ) в момент времени t , учитывая значения скрытой переменной x во все моменты времени, зависит только от значения скрытой переменной x ( t − 1 ); значения в момент времени t - 2 и ранее не имеют никакого влияния. Это называется свойством Маркова . Аналогично, значение наблюдаемой переменной y ( t ) зависит только от значения скрытой переменной x ( t ) (оба в момент времени t ).
В рассматриваемом здесь стандартном типе скрытой марковской модели пространство состояний скрытых переменных дискретно, а сами наблюдения могут быть либо дискретными (обычно генерируемыми из категориального распределения ), либо непрерывными (обычно из гауссова распределения ). Параметры скрытой модели Маркова бывают двух типов: вероятности перехода и вероятности выбросов (также известные как выходные вероятности ). Вероятности перехода контролируют способ скрытого состояния в момент времени t с учетом скрытого состояния в момент времени. выбора .

Предполагается, что скрытое пространство состояний состоит из одного из N возможных значений, смоделированных как категориальное распределение. (Другие возможности см. в разделе о расширениях ниже.) Это означает, что для каждого из N возможных состояний, в которых может находиться скрытая переменная в момент времени t , существует вероятность перехода из этого состояния в каждое из N возможных состояний скрытая переменная во времени , на общую сумму вероятности перехода. Обратите внимание, что набор вероятностей перехода из любого данного состояния должен в сумме равняться 1. Таким образом, матрица вероятностей перехода является матрицей Маркова . Поскольку любую вероятность перехода можно определить, как только известны остальные, всего существует параметры перехода.




Кроме того, для каждого из N возможных состояний существует набор вероятностей выбросов, определяющих распределение наблюдаемой переменной в определенный момент времени с учетом состояния скрытой переменной в этот момент. Размер этого набора зависит от природы наблюдаемой переменной. Например, если наблюдаемая переменная дискретна и имеет М возможных значений, определяемых категориальным распределением , будет отдельные параметры, всего параметры излучения по всем скрытым состояниям. С другой стороны, если наблюдаемая переменная представляет собой M -мерный вектор, распределенный в соответствии с произвольным многомерным распределением Гаусса , будет M параметров, управляющих средними значениями и параметры, управляющие ковариационной матрицей , в общей сложности параметры выбросов. (В таком случае, если значение M не мало, может оказаться более практичным ограничить характер ковариаций между отдельными элементами вектора наблюдения, например, предположив, что элементы независимы друг от друга, или менее ограничительно, независимы ни от чего, кроме фиксированного числа соседних элементов.)




Вывод [ править ]

5 3 2 5 3 2
4 3 2 5 3 2
3 1 2 5 3 2
Мы можем найти наиболее вероятную последовательность, оценив совместную вероятность как последовательности состояний, так и наблюдений для каждого случая (просто умножив значения вероятности, которые здесь соответствуют непрозрачности задействованных стрелок). В общем, задачи такого типа (т. е. поиск наиболее вероятного объяснения последовательности наблюдений) можно эффективно решить с помощью алгоритма Витерби .
несколько проблем вывода Со скрытыми моделями Маркова связано , как описано ниже.
последовательности наблюдаемой Вероятность
Задача состоит в том, чтобы наилучшим образом вычислить, учитывая параметры модели, вероятность конкретной выходной последовательности. Это требует суммирования по всем возможным последовательностям состояний:
Вероятность наблюдения последовательности

длины L определяется выражением

где сумма пробегает все возможные последовательности скрытых узлов

Применяя принцип динамического программирования , эту проблему также можно эффективно решить с помощью прямого алгоритма .
переменных скрытых Вероятность
В ряде связанных задач задается вопрос о вероятности одной или нескольких скрытых переменных с учетом параметров модели и последовательности наблюдений.

Фильтрация [ править ]
Задача состоит в том, чтобы по параметрам модели и последовательности наблюдений вычислить распределение по скрытым состояниям последней скрытой переменной в конце последовательности, т.е. вычислить . Эта задача используется, когда последовательность скрытых переменных рассматривается как основные состояния, через которые проходит процесс в последовательность моментов времени, с соответствующими наблюдениями в каждой точке. Тогда естественно спросить о состоянии процесса в конце.

Эту проблему можно эффективно решить с помощью прямого алгоритма . Примером может служить применение алгоритма к скрытой марковской сети для определения .

Сглаживание [ править ]
Это похоже на фильтрацию, но требует распределения скрытой переменной где-то в середине последовательности, т.е. для вычисления для некоторых . С точки зрения, описанной выше, это можно рассматривать как распределение вероятностей по скрытым состояниям для момента времени k в прошлом относительно времени t .


Алгоритм вперед-назад — хороший метод вычисления сглаженных значений для всех скрытых переменных состояния.
Наиболее вероятное объяснение [ править ]
Задача, в отличие от двух предыдущих, спрашивает о совместной вероятности всей последовательности скрытых состояний, породивших определенную последовательность наблюдений (см . иллюстрацию справа). Эта задача обычно применима, когда СММ применяются к задачам, отличным от тех, для которых применимы задачи фильтрации и сглаживания. Примером может служить маркировка частей речи , где скрытые состояния представляют собой основные части речи, соответствующие наблюдаемой последовательности слов. В этом случае интерес представляет вся последовательность частей речи, а не просто часть речи для одного слова, как это можно было бы вычислить при фильтрации или сглаживании.
Эта задача требует нахождения максимума по всем возможным последовательностям состояний и может быть эффективно решена с помощью алгоритма Витерби .
значимость Статистическая
Для некоторых из вышеперечисленных проблем также может быть интересно задаться вопросом о статистической значимости . Какова вероятность того, что последовательность, полученная из некоторого нулевого распределения , будет иметь вероятность HMM (в случае прямого алгоритма) или максимальную вероятность последовательности состояний (в случае алгоритма Витерби), по крайней мере такую же большую, как и у конкретного последовательность вывода? [8] Когда HMM используется для оценки релевантности гипотезы для конкретной выходной последовательности, статистическая значимость указывает на частоту ложных срабатываний , связанную с невозможностью отклонения гипотезы для выходной последовательности.
Обучение [ править ]
Задача обучения параметров в HMM состоит в том, чтобы найти, учитывая выходную последовательность или набор таких последовательностей, лучший набор вероятностей перехода состояний и выбросов. Задача обычно состоит в том, чтобы получить оценку максимального правдоподобия параметров HMM с учетом набора выходных последовательностей. Неизвестен понятный алгоритм для точного решения этой проблемы, но локальное максимальное правдоподобие можно эффективно получить с помощью алгоритма Баума – Уэлча или алгоритма Бальди – Шовена. Алгоритм Баума-Уэлча является частным случаем алгоритма максимизации ожидания .
Если HMM используются для прогнозирования временных рядов, более сложные методы байесовского вывода, такие как выборка цепей Маркова Монте-Карло (MCMC), оказываются более предпочтительными по сравнению с поиском единой модели максимального правдоподобия как с точки зрения точности, так и стабильности. [9] Поскольку MCMC налагает значительную вычислительную нагрузку, в случаях, когда вычислительная масштабируемость также представляет интерес, можно альтернативно прибегнуть к вариационным аппроксимациям байесовского вывода, например [10] Действительно, приближенный вариационный вывод обеспечивает вычислительную эффективность, сравнимую с максимизацией ожидания, но дает профиль точности лишь немного уступающий точному байесовскому выводу типа MCMC.
Приложения [ править ]

HMM можно применять во многих областях, где целью является восстановление последовательности данных, которую нельзя наблюдать немедленно (но другие данные, зависящие от последовательности, можно). Приложения включают в себя:
- Вычислительные финансы [11] [12]
- Одномолекулярный кинетический анализ [13]
- Нейронаука [14] [15]
- Криптоанализ
- Распознавание речи , включая Siri [16]
- Синтез речи
- Маркировка частей речи
- Разделение документов в решениях для сканирования
- Машинный перевод
- Частичный разряд
- Генное предсказание
- Распознавание рукописного ввода [17]
- Выравнивание биопоследовательностей
- Анализ временных рядов
- Признание активности
- Складывание белка [18]
- Классификация последовательностей [19]
- Обнаружение метаморфического вируса [20]
- Открытие мотивов последовательности (ДНК и белки) [21]
- Кинетика гибридизации ДНК [22] [23]
- хроматина Открытие состояния [24]
- Прогнозирование перевозок [25]
- солнечного излучения Изменчивость [26] [27] [28]
История [ править ]
Скрытые марковские модели были описаны в серии статистических статей Леонарда Э. Баума и других авторов во второй половине 1960-х годов. [29] [30] [31] [32] [33] Одним из первых применений HMM было распознавание речи , начиная с середины 1970-х годов. [34] [35] [36] [37]
Во второй половине 1980-х годов СММ начали применять для анализа биологических последовательностей. [38] в частности ДНК . С тех пор они стали повсеместными в области биоинформатики . [39]
Расширения [ править ]
Эта статья может оказаться слишком длинной для удобного чтения и навигации . ( март 2023 г. ) |
Общие государственные пространства [ править ]
В рассмотренных выше скрытых марковских моделях пространство состояний скрытых переменных дискретно, а сами наблюдения могут быть либо дискретными (обычно генерируемыми из категориального распределения ), либо непрерывными (обычно из гауссова распределения ). Скрытые марковские модели также можно обобщить, чтобы обеспечить непрерывные пространства состояний. Примерами таких моделей являются модели, в которых марковский процесс над скрытыми переменными представляет собой линейную динамическую систему с линейной зависимостью между связанными переменными и где все скрытые и наблюдаемые переменные подчиняются гауссовскому распределению . В простых случаях, таких как только что упомянутая линейная динамическая система, возможен точный вывод (в данном случае с использованием фильтра Калмана ); однако, как правило, точный вывод в СММ с непрерывными скрытыми переменными невозможен, и необходимо использовать приближенные методы, такие как расширенный фильтр Калмана или фильтр частиц .
В настоящее время вывод в скрытых моделях Маркова выполняется в непараметрических настройках, где структура зависимостей позволяет идентифицировать модель. [40] а пределы обучаемости все еще изучаются. [41]
переходов Байесовское вероятностей моделирование
Скрытые марковские модели — это генеративные модели , в которых совместное распределение наблюдений и скрытых состояний или, что эквивалентно, как априорное распределение скрытых состояний ( вероятности перехода ), так и условное распределение наблюдений по заданным состояниям ( вероятности выбросов моделируется ). Вышеупомянутые алгоритмы неявно предполагают равномерное априорное распределение вероятностей перехода. Однако также возможно создавать скрытые марковские модели с другими типами априорных распределений. Очевидным кандидатом, учитывая категориальное распределение вероятностей перехода, является распределение Дирихле , которое является сопряженным априорным распределением категориального распределения. Обычно выбирается симметричное распределение Дирихле, отражающее незнание того, какие состояния по своей природе более вероятны, чем другие. Единственный параметр этого распределения (называемый параметром концентрации ) контролирует относительную плотность или разреженность результирующей матрицы перехода. Выбор 1 дает равномерное распределение. Значения больше 1 создают плотную матрицу, в которой вероятности перехода между парами состояний, вероятно, будут почти равны. Значения меньше 1 приводят к разреженной матрице, в которой для каждого данного исходного состояния только небольшое количество состояний назначения имеет непренебрежимо малые вероятности перехода. Также возможно использовать двухуровневое априорное распределение Дирихле, в котором одно распределение Дирихле (верхнее распределение) управляет параметрами другого распределения Дирихле (нижнее распределение), которое, в свою очередь, определяет вероятности перехода. Верхнее распределение управляет общим распределением состояний, определяя, насколько вероятно возникновение каждого состояния; его параметр концентрации определяет плотность или разреженность состояний. Такое двухуровневое априорное распределение, в котором оба параметра концентрации установлены для получения разреженных распределений, может быть полезно, например, в неконтролируемая маркировка частей речи , при которой некоторые части речи встречаются гораздо чаще, чем другие; Алгоритмы обучения, предполагающие равномерное априорное распределение, обычно плохо справляются с этой задачей. Параметры моделей такого типа с неравномерными априорными распределениями можно узнать с помощью выборки Гиббса или расширенных версий алгоритма максимизации ожидания .
Расширение ранее описанных скрытых моделей Маркова с помощью априорных значений Дирихле использует процесс Дирихле вместо распределения Дирихле. Этот тип модели допускает неизвестное и потенциально бесконечное количество состояний. Обычно используется двухуровневый процесс Дирихле, аналогичный ранее описанной модели с двумя уровнями распределений Дирихле. Такая модель называется скрытой марковской моделью иерархического процесса Дирихле , или HDP-HMM сокращенно . Первоначально она была описана под названием «Бесконечная скрытая марковская модель». [42] и был дополнительно формализован в «Иерархических процессах Дирихле». [43]
Дискриминационный подход [ править ]
Другой тип расширения использует дискриминативную модель вместо генеративной модели стандартных HMM. Этот тип модели напрямую моделирует условное распределение скрытых состояний с учетом наблюдений, а не моделирует совместное распределение. Примером такой модели является так называемая модель Маркова с максимальной энтропией (MEMM), которая моделирует условное распределение состояний с помощью логистической регрессии (также известной как « модель максимальной энтропии »). Преимущество этого типа модели заключается в том, что можно моделировать произвольные характеристики (т.е. функции) наблюдений, что позволяет внедрить в модель специфичные для предметной области знания о рассматриваемой проблеме. Модели такого типа не ограничиваются моделированием прямых зависимостей между скрытым состоянием и связанным с ним наблюдением; скорее, особенности близлежащих наблюдений, комбинаций связанных наблюдений и близлежащих наблюдений или фактически произвольных наблюдений на любом расстоянии от данного скрытого состояния могут быть включены в процесс, используемый для определения значения скрытого состояния. Более того, нет необходимости использовать эти функции. статистически независимы друг от друга, как это было бы, если бы такие признаки использовались в генеративной модели. Наконец, вместо простых вероятностей перехода можно использовать произвольные функции над парами соседних скрытых состояний. Недостатками таких моделей являются: (1) Типы априорных распределений, которые можно поместить в скрытые состояния, сильно ограничены; (2) Невозможно предсказать вероятность увидеть произвольное наблюдение. Это второе ограничение часто не является проблемой на практике, поскольку многие распространенные применения HMM не требуют таких прогнозируемых вероятностей.
Вариантом ранее описанной дискриминативной модели является линейно-цепное условное случайное поле . При этом используется неориентированная графическая модель (также известная как марковское случайное поле ), а не направленные графические модели MEMM и подобных моделей. Преимущество модели этого типа заключается в том, что она не страдает от так называемой проблемы смещения меток, характерной для MEMM, и, таким образом, может делать более точные прогнозы. Недостатком является то, что обучение может быть медленнее, чем у MEMM.
Другие расширения [ править ]
Еще одним вариантом является факториальная скрытая марковская модель , которая позволяет обусловить одно наблюдение соответствующими скрытыми переменными набора независимые цепи Маркова, а не одна цепь Маркова. Это эквивалентно одному HMM, с государства (при условии, что существуют состояний для каждой цепочки), поэтому обучение в такой модели затруднено: для последовательности длины , простой алгоритм Витерби имеет сложность . Чтобы найти точное решение, можно использовать алгоритм дерева соединений, но это приводит к сложность. На практике можно использовать приближенные методы, такие как вариационные подходы. [44]






Все вышеперечисленные модели могут быть расширены, чтобы обеспечить более отдаленные зависимости между скрытыми состояниями, например, позволяя данному состоянию зависеть от двух или трех предыдущих состояний, а не от одного предыдущего состояния; т.е. вероятности перехода расширяются, чтобы охватить наборы из трех или четырех соседних состояний (или, вообще говоря, соседние государства). Недостатком таких моделей является то, что алгоритмы динамического программирования для их обучения имеют время работы, за соседние государства и общее количество наблюдений (т.е. цепь Маркова). Это расширение широко использовалось в биоинформатике , при моделировании последовательностей ДНК .

Еще одним недавним расширением является триплетная марковская модель . [45] в котором добавляется вспомогательный базовый процесс для моделирования некоторых особенностей данных. Было предложено множество вариантов этой модели. Следует также упомянуть об интересной связи, которая установлена между теорией доказательств и тройными марковскими моделями. [46] и который позволяет объединять данные в марковском контексте [47] и моделировать нестационарные данные. [48] [49] Обратите внимание, что в недавней литературе также были предложены альтернативные стратегии объединения многопоточных данных, например [50]
Наконец, в 2012 году было предложено другое обоснование решения проблемы моделирования нестационарных данных с помощью скрытых моделей Маркова. [51] Он заключается в использовании небольшой рекуррентной нейронной сети (RNN), в частности сети резервуаров. [52] чтобы уловить эволюцию временной динамики в наблюдаемых данных. Эта информация, закодированная в форме многомерного вектора, используется в качестве обуславливающей переменной вероятностей перехода состояний HMM. При такой настройке мы в конечном итоге получаем нестационарную СММ, вероятности перехода которой меняются со временем таким образом, который выводится из самих данных, в отличие от некоторой нереалистичной специальной модели временной эволюции.
В 2023 году для скрытой марковской модели были представлены два инновационных алгоритма. Эти алгоритмы позволяют вычислить апостериорное распределение HMM без необходимости явного моделирования совместного распределения, используя только условные распределения. [53] [54] В отличие от традиционных методов, таких как алгоритмы «Вперед-назад» и «Витерби», которые требуют знания совместного закона HMM и могут потребовать больших вычислительных ресурсов для изучения, алгоритмы «Дискриминативный вперед-назад» и «Дискриминативный Витерби» обходят необходимость в законе наблюдения. [55] [56] Этот прорыв позволяет применять СММ в качестве дискриминационной модели, предлагая более эффективный и универсальный подход к использованию скрытых марковских моделей в различных приложениях.
Модель, подходящая для продольных данных, называется скрытой моделью Маркова. [57] Базовая версия этой модели была расширена и теперь включает отдельные ковариаты, случайные эффекты и моделирует более сложные структуры данных, такие как многоуровневые данные. Полный обзор скрытых моделей Маркова с особым вниманием к предположениям модели и их практическому использованию представлен в [58]
Теория меры [ править ]

Учитывая матрицу марковского перехода и инвариантное распределение состояний, мы можем наложить вероятностную меру на набор подсдвигов. Например, рассмотрим цепь Маркова, приведенную слева для состояний , с инвариантным распределением . Если мы «забудем» различие между , проецируем это пространство подсдвигов на в другое пространство подсдвигов на , и эта проекция также проецирует вероятностную меру до вероятностной меры на подсдвигах на .




Любопытно то, что вероятностная мера подсдвигов на не создается цепью Маркова на , даже не несколько заказов. Интуитивно это происходит потому, что если наблюдать длинную последовательность , то можно было бы все больше убеждаться в том, что Это означает, что на наблюдаемую часть системы может бесконечно влиять что-то в прошлом. [59] [60]


И наоборот, существует пространство подсдвигов на 6 символов, проецируемых на подсдвиги на 2 символа, такое, что любая марковская мера на меньшем подсдвиге имеет меру прообраза, не являющуюся марковской ни одного порядка (пример 2.6). [60] ).
См. также [ править ]
- Andrey Markov
- Алгоритм Баума – Уэлча
- Байесовский вывод
- Байесовское программирование
- Ричард Джеймс Бойз
- Условное случайное поле
- Теория оценки
- HHpred / HHsearch бесплатный сервер и программное обеспечение для поиска последовательностей белков
- HMMER , бесплатная программа скрытых марковских моделей для анализа последовательностей белков.
- Скрытая модель Бернулли
- Скрытая полумарковская модель
- Иерархическая скрытая марковская модель
- Многослойная скрытая марковская модель
- Последовательная динамическая система
- Стохастическая контекстно-свободная грамматика
- временных рядов Анализ
- Марковская модель переменного порядка
- Алгоритм Витерби
Ссылки [ править ]
- ^ «Гугл Академика» .
- ^ Тад Старнер, Алекс Пентленд. Визуальное распознавание американского языка жестов в реальном времени по видео с использованием скрытых марковских моделей . Магистерская диссертация, Массачусетский технологический институт, февраль 1995 г., программа по медиаискусству.
- ^ Б. Пардо и В. Бирмингем. Форма моделирования для онлайн-слежения за музыкальными выступлениями. Архивировано 6 февраля 2012 г. в Wayback Machine . AAAI-05 Proc., июль 2005 г.
- ^ Сатиш Л., Гурурадж Б.И. (апрель 2003 г.). « Использование скрытых марковских моделей для классификации моделей частичных разрядов ». Транзакции IEEE по диэлектрикам и электроизоляции .
- ^ Ли, Н; Стивенс, М. (декабрь 2003 г.). «Моделирование неравновесия по сцеплению и выявление горячих точек рекомбинации с использованием данных однонуклеотидного полиморфизма» . Генетика . 165 (4): 2213–33. дои : 10.1093/генетика/165.4.2213 . ПМК 1462870 . ПМИД 14704198 .
- ^ Эрнст, Джейсон; Келлис, Манолис (март 2012 г.). «ChromHMM: автоматизация обнаружения и характеристики состояния хроматина» . Природные методы . 9 (3): 215–216. дои : 10.1038/nmeth.1906 . ПМЦ 3577932 . ПМИД 22373907 .
- ^ Лоуренс Р. Рабинер (февраль 1989 г.). «Учебное пособие по скрытым марковским моделям и избранным приложениям для распознавания речи» (PDF) . Труды IEEE . 77 (2): 257–286. CiteSeerX 10.1.1.381.3454 . дои : 10.1109/5.18626 . S2CID 13618539 . [1]
- ^ Ньюберг, Л. (2009). «Статистика ошибок скрытой модели Маркова и результатов скрытой модели Больцмана» . БМК Биоинформатика . 10 :212. дои : 10.1186/1471-2105-10-212 . ПМК 2722652 . ПМИД 19589158 .

- ^ Сипос, И. Роберт. Параллельная стратифицированная выборка MCMC AR-HMM для стохастического прогнозирования временных рядов . В: Материалы 4-й Международной конференции по методам стохастического моделирования и анализа данных с семинаром по демографии (SMTDA2016), стр. 295-306. Валлетта, 2016. PDF
- ^ Хацис, Сотириос П.; Космопулос, Димитриос И. (2011). «Вариационная байесовская методология для скрытых моделей Маркова с использованием смесей Стьюдента» (PDF) . Распознавание образов . 44 (2): 295–306. Бибкод : 2011PatRe..44..295C . CiteSeerX 10.1.1.629.6275 . дои : 10.1016/j.patcog.2010.09.001 . Архивировано из оригинала (PDF) 1 апреля 2011 г. Проверено 11 марта 2018 г.
- ^ Сипос, Роберт I; Сеффер, Аттила; Левендовский, Янош (2016). «Параллельная оптимизация разреженных портфелей с помощью AR-HMM». Вычислительная экономика . 49 (4): 563–578. дои : 10.1007/s10614-016-9579-y . S2CID 61882456 .
- ^ Петропулос, Анастасиос; Хацис, Сотириос П.; Ксантопулос, Стилианос (2016). «Новая система корпоративных кредитных рейтингов, основанная на скрытых марковских моделях Стьюдента». Экспертные системы с приложениями . 53 : 87–105. дои : 10.1016/j.eswa.2016.01.015 .
- ^ НИКОЛАЙ, КРИСТОФЕР (2013). «РЕШЕНИЕ КИНЕТИКИ ИОННЫХ КАНАЛОВ С ПОМОЩЬЮ ПРОГРАММНОГО ОБЕСПЕЧЕНИЯ QuB». Биофизические обзоры и письма . 8 (3n04): 191–211. дои : 10.1142/S1793048013300053 .
- ^ Хиггинс, Кэмерон; Видаурре, Диего; Коллинг, Нильс; Лю, Юньчжэ; Беренс, Тим; Вулрич, Марк (2022). «Многомерный анализ закономерностей с пространственно-временным разрешением для М/ЭЭГ» . Картирование человеческого мозга . 43 (10): 3062–3085. дои : 10.1002/hbm.25835 . ПМЦ 9188977 . ПМИД 35302683 .
- ^ Диомеди, С.; Ваккари, FE; Галлетти, К.; Хаджидимитракис, К.; Фаттори, П. (01 октября 2021 г.). «Моторная нервная динамика в двух теменных областях при вытягивании руки» . Прогресс нейробиологии . 205 : 102116. doi : 10.1016/j.pneurobio.2021.102116 . hdl : 11585/834094 . ISSN 0301-0082 . ПМИД 34217822 . S2CID 235703641 .
- ^ Домингос, Педро (2015). Главный алгоритм: как поиски совершенной обучающейся машины изменят наш мир . Основные книги. п. 37 . ISBN 9780465061921 .
- ^ Кунду, Амлан, Ян Хэ и Парамвир Бахл. порядка Распознавание рукописного слова: подход на основе скрытой марковской модели первого и второго [ мертвая ссылка ] Распознавание образов 22.3 (1989): 283-297.
- ^ Стиглер, Дж.; Зиглер, Ф.; Гизеке, А.; Гебхардт, JCM; Риф, М. (2011). «Сложная складчатая сеть одиночных молекул кальмодулина». Наука . 334 (6055): 512–516. Бибкод : 2011Sci...334..512S . дои : 10.1126/science.1207598 . ПМИД 22034433 . S2CID 5502662 .
- ^ Блазиак, С.; Рангвала, Х. (2011). «Скрытый вариант марковской модели для классификации последовательностей». IJCAI Proceedings — Международная совместная конференция по искусственному интеллекту . 22 :1192.
- ^ Вонг, В.; Штамп, М. (2006). «Охота на метаморфические двигатели». Журнал компьютерной вирусологии . 2 (3): 211–229. дои : 10.1007/s11416-006-0028-7 . S2CID 8116065 .
- ^ Вонг, К.-К.; Чан, Т.-М.; Пэн, К.; Ли, Ю.; Чжан, З. (2013). «Выяснение мотива ДНК с использованием распространения убеждений» . Исследования нуклеиновых кислот . 41 (16): е153. дои : 10.1093/нар/gkt574 . ПМЦ 3763557 . ПМИД 23814189 .
- ^ Шах, Шалин; Дубей, Абхишек К.; Рейф, Джон (17 мая 2019 г.). «Улучшенное оптическое мультиплексирование с временными штрих-кодами ДНК». ACS Синтетическая биология . 8 (5): 1100–1111. дои : 10.1021/acsynbio.9b00010 . ПМИД 30951289 . S2CID 96448257 .
- ^ Шах, Шалин; Дубей, Абхишек К.; Рейф, Джон (10 апреля 2019 г.). «Программирование временных штрих-кодов ДНК для снятия отпечатков пальцев одной молекулы». Нано-буквы . 19 (4): 2668–2673. Бибкод : 2019NanoL..19.2668S . дои : 10.1021/acs.nanolett.9b00590 . ISSN 1530-6984 . ПМИД 30896178 . S2CID 84841635 .
- ^ «ChromHMM: открытие и характеристика состояния хроматина» . compbio.mit.edu . Проверено 01 августа 2018 г.
- ^ Эль Зарви, Фераз (май 2011 г.). «Моделирование и прогнозирование эволюции предпочтений с течением времени: скрытая марковская модель поведения в путешествиях». arXiv : 1707.09133 [ стат.AP ].
- ^ Морф, Х. (февраль 1998 г.). «Стохастическая модель солнечного излучения с двумя состояниями (STSIM)». Солнечная энергия . 62 (2): 101–112. Бибкод : 1998SoEn...62..101M . дои : 10.1016/S0038-092X(98)00004-8 .
- ^ Мункхаммар, Дж.; Виден, Дж. (август 2018 г.). «Подход к индексу ясного неба, основанный на смешанном распределении вероятностей с помощью цепи Маркова». Солнечная энергия . 170 : 174–183. Бибкод : 2018SoEn..170..174M . doi : 10.1016/j.solener.2018.05.055 . S2CID 125867684 .
- ^ Мункхаммар, Дж.; Виден, Дж. (октябрь 2018 г.). «Модель распределения смеси индекса ясного неба с N-состоянием марковской цепи». Солнечная энергия . 173 : 487–495. Бибкод : 2018SoEn..173..487M . doi : 10.1016/j.solener.2018.07.056 . S2CID 125538244 .
- ^ Баум, Л.Э.; Петри, Т. (1966). «Статистический вывод для вероятностных функций цепей Маркова с конечным состоянием» . Анналы математической статистики . 37 (6): 1554–1563. дои : 10.1214/aoms/1177699147 .
- ^ Баум, Л.Э.; Иагон, Дж. А. (1967). «Неравенство с приложениями к статистическому оцениванию вероятностных функций марковских процессов и к модели экологии» . Бюллетень Американского математического общества . 73 (3): 360. doi : 10.1090/S0002-9904-1967-11751-8 . Збл 0157.11101 .
- ^ Баум, Л.Э.; Селл, Г. Р. (1968). «Преобразования роста функций на многообразиях» . Тихоокеанский математический журнал . 27 (2): 211–227. дои : 10.2140/pjm.1968.27.211 .
- ^ Баум, Ю.Л. ; Петри, Т.; Соулз, Г.; Вайс, Н. (1970). «Техника максимизации, используемая при статистическом анализе вероятностных функций цепей Маркова» . Анналы математической статистики . 41 (1): 164–171. дои : 10.1214/aoms/1177697196 . JSTOR 2239727 . МР 0287613 . Збл 0188.49603 .
- ^ Баум, Л.Е. (1972). «Неравенство и связанный с ним метод максимизации в статистической оценке вероятностных функций марковского процесса». Неравенства . 3 : 1–8.
- ^ Бейкер, Дж. (1975). «Система ДРАКОН — Обзор». Транзакции IEEE по акустике, речи и обработке сигналов . 23 : 24–29. дои : 10.1109/ТАССП.1975.1162650 .
- ^ Елинек, Ф.; Бахл, Л.; Мерсер, Р. (1975). «Разработка лингвостатистического декодера для распознавания слитной речи». Транзакции IEEE по теории информации . 21 (3): 250. doi : 10.1109/TIT.1975.1055384 .
- ^ Сюэдун Хуан ; М. Джек; Ю. Арики (1990). Скрытые марковские модели распознавания речи . Издательство Эдинбургского университета. ISBN 978-0-7486-0162-2 .
- ^ Сюэдун Хуан ; Алекс Асеро; Сяо-Вуэнь Хон (2001). Обработка разговорной речи . Прентис Холл. ISBN 978-0-13-022616-7 .
- ^ М. Бишоп и Э. Томпсон (1986). «Выравнивание последовательностей ДНК с максимальной вероятностью». Журнал молекулярной биологии . 190 (2): 159–165. дои : 10.1016/0022-2836(86)90289-5 . ПМИД 3641921 . (требуется подписка)

- ^ Дурбин, Ричард М .; Эдди, Шон Р .; Крог, Андерс ; Митчисон, Грэм (1998), Анализ биологических последовательностей: вероятностные модели белков и нуклеиновых кислот (1-е изд.), Кембридж, Нью-Йорк: Cambridge University Press , ISBN 0-521-62971-3 , OCLC 593254083
- ^ Гассиат, Э.; Клейнен, А.; Робин, С. (01 января 2016 г.). «Вывод в конечном пространстве состояний, непараметрические скрытые марковские модели и приложения» . Статистика и вычисления . 26 (1): 61–71. дои : 10.1007/s11222-014-9523-8 . ISSN 1573-1375 .
- ^ Авраам, дядя; Гассиат, Элизабет; Наулет, Захари (март 2023 г.). «Фундаментальные ограничения для изучения скрытых параметров марковской модели» . Транзакции IEEE по теории информации . 69 (3): 1777–1794. arXiv : 2106.12936 . дои : 10.1109/TIT.2022.3213429 . ISSN 0018-9448 .
- ^ Бил, Мэтью Дж., Зубин Гахрамани и Карл Эдвард Расмуссен. «Бесконечная скрытая марковская модель». Достижения в области нейронных систем обработки информации 14 (2002): 577-584.
- ^ Тех, Йи Уай и др. «Иерархические процессы Дирихле». Журнал Американской статистической ассоциации 101.476 (2006).
- ^ Гахрамани, Зубин ; Джордан, Майкл И. (1997). «Факторные скрытые марковские модели» . Машинное обучение . 29 (2/3): 245–273. дои : 10.1023/А:1007425814087 .
- ^ Печинский, Войцех (2002). «Триплетные цепи Маркова» (PDF) . Математические отчеты . 335 (3): 275–278. дои : 10.1016/S1631-073X(02)02462-7 .
- ^ Печинский, Войцех (2007). «Мультисенсорные триплетные цепи Маркова и теория доказательств» . Международный журнал приближенного рассуждения . 45 : 1–16. дои : 10.1016/j.ijar.2006.05.001 .
- ^ Бударен и др. Архивировано 11 марта 2014 г. в Wayback Machine , М. Я. Бударен, Э. Монфрини, В. Печински и А. Айссани, Слияние мультисенсорных сигналов Демпстера-Шафера в нестационарном марковском контексте, Журнал EURASIP по достижениям в области обработки сигналов, № 134. , 2012.
- ^ Ланчантен и др. , П. Ланчантин и В. Печински, Неконтролируемое восстановление скрытой нестационарной цепи Маркова с использованием априорных доказательств, Транзакции IEEE по обработке сигналов, Vol. 53, № 8, стр. 3091-3098, 2005.
- ^ Бударен и др. , М. Я. Бударен, Э. Монфрини и В. Печински, Неконтролируемая сегментация случайных дискретных данных, скрытых с переключением распределений шума, IEEE Signal Processing Letters, Vol. 19, № 10, стр. 619-622, октябрь 2012 г.
- ^ Сотириос П. Чацис, Димитриос Космопулос, «Визуальное распознавание рабочего процесса с использованием вариационной байесовской обработки многопоточных объединенных скрытых марковских моделей», Транзакции IEEE в схемах и системах для видеотехнологий, том. 22, нет. 7, стр. 1076–1086, июль 2012 г.
- ^ Хацис, Сотириос П.; Демирис, Яннис (2012). «Нестационарная модель скрытой Маркова, управляемая резервуаром». Распознавание образов . 45 (11): 3985–3996. Бибкод : 2012PatRe..45.3985C . дои : 10.1016/j.patcog.2012.04.018 . hdl : 10044/1/12611 .
- ^ М. Лукошевичиус, Х. Джагер (2009) Подходы к резервным вычислениям к рекуррентному обучению нейронных сетей, Computer Science Review 3 : 127–149.
- ^ Азераф Э., Монфрини Э. и Печински В. (2023). Эквивалентность между LC-CRF и HMM и дискриминативные вычисления MPM и MAP на основе HMM. Алгоритмы, 16(3), 173.
- ^ Азераф Э., Монфрини Э., Виньон Э. и Печинский В. (2020). Скрытые цепи Маркова, энтропийное движение вперед-назад и маркировка частей речи. Препринт arXiv arXiv:2005.10629.
- ^ Азераф Э., Монфрини Э. и Печински В. (2022). Выведение дискриминативных классификаторов из генеративных моделей. Препринт arXiv arXiv:2201.00844.
- ^ Нг, А., и Джордан, М. (2001). О дискриминативных и генеративных классификаторах: сравнение логистической регрессии и наивного Байеса. Достижения в области нейронных систем обработки информации, 14.
- ^ Виггинс, LM (1973). Панельный анализ: модели скрытой вероятности для процессов отношения и поведения . Амстердам: Эльзевир.
- ^ Бартолуччи, Ф.; Фаркомени, А.; Пеннони, Ф. (2013). Скрытые марковские модели для продольных данных . Бока-Ратон: Чепмен и Холл/CRC. ISBN 978-14-3981-708-7 .
- ^ Софические меры: характеристики скрытых цепей Маркова с помощью линейной алгебры, формальных языков и символической динамики - Карл Петерсен, Математика 210, весна 2006 г., Университет Северной Каролины в Чапел-Хилл
- ^ Jump up to: Перейти обратно: а б Бойл, Майк; Петерсен, Карл (13 января 2010 г.), Скрытые марковские процессы в контексте символической динамики , arXiv : 0907.1858
Внешние ссылки [ править ]
Концепции [ править ]
- Тейф, В.Б.; Риппе, К. (2010). «Статистически-механические решетчатые модели связывания белка с ДНК в хроматине». J. Phys.: Condens. Иметь значение . 22 (41): 414105. arXiv : 1004.5514 . Бибкод : 2010JPCM...22O4105T . дои : 10.1088/0953-8984/22/41/414105 . ПМИД 21386588 . S2CID 103345 .
- Показательное введение в скрытые марковские модели , Марк Стэмп, Государственный университет Сан-Хосе.
- Соответствие HMM максимизации ожиданий - полный вывод
- Пошаговое руководство по HMM. Архивировано 13 августа 2017 г. в Wayback Machine (Университет Лидса).
- Скрытые марковские модели (экспозиция с использованием базовой математики)
- Скрытые марковские модели (Нарада Варакагода)
- Скрытые марковские модели: основы и приложения Часть 1 , Часть 2 (В. Петрушин)
- Лекция Джейсона Эйснера об электронной таблице, Видео и интерактивная таблица
| Базы данных органов управления : Национальные |
|---|