Обнаружение сходства контента
Эту статью может потребовать очистки Википедии , чтобы она соответствовала стандартам качества . ( декабрь 2010 г. ) |
Обнаружение плагиата или обнаружение сходства контента — это процесс выявления случаев плагиата или нарушения авторских прав в произведении или документе. Широкое использование компьютеров и появление Интернета облегчили плагиат чужих работ. [1] [2]
Обнаружение плагиата может осуществляться различными способами. Обнаружение человека — наиболее традиционная форма выявления плагиата в письменных работах. Это может оказаться длительной и трудоемкой задачей для читателя. [2] а также может привести к несоответствию в том, как выявляется плагиат внутри организации. [3] Программное обеспечение для сопоставления текста (TMS), которое также называют «программным обеспечением для обнаружения плагиата» или «программным обеспечением для борьбы с плагиатом», стало широко доступным как в виде коммерчески доступных продуктов, так и в виде продуктов с открытым исходным кодом. [ необходимы примеры ] программное обеспечение. TMS фактически не обнаруживает плагиат как таковой, а вместо этого находит определенные отрывки текста в одном документе, которые совпадают с текстом в другом документе.
Программное обнаружение плагиата
Компьютерное обнаружение плагиата (CaPD) — это задача поиска информации (IR) , поддерживаемая специализированными системами IR, которая называется системой обнаружения плагиата (PDS) или системой обнаружения сходства документов. Систематический обзор литературы за 2019 год. [4] представляет обзор современных методов обнаружения плагиата.
В текстовых документах [ править ]
Системы обнаружения сходства текста реализуют один из двух общих подходов обнаружения: один является внешним, другой — внутренним. [5] Внешние системы обнаружения сравнивают подозрительный документ с эталонной коллекцией, которая представляет собой набор документов, предположительно подлинных. [6] На основе выбранной модели документа и предопределенных критериев сходства задача обнаружения состоит в том, чтобы извлечь все документы, содержащие текст, который в степени, превышающей выбранный порог, похож на текст в подозрительном документе. [7] Внутренние PDS анализируют исключительно текст, подлежащий оценке, без сравнения с внешними документами. Этот подход направлен на признание изменений в уникальном стиле письма автора как индикатора потенциального плагиата. [8] [9] PDS не способны надежно выявлять плагиат без человеческого суждения. Сходства и особенности стиля письма вычисляются с помощью предопределенных моделей документов и могут представлять собой ложноположительные результаты. [10] [11] [12] [13] [14]
этих инструментов в условиях Эффективность высшего образования
Этот раздел в значительной степени или полностью опирается на один источник . ( декабрь 2017 г. ) |
Было проведено исследование с целью проверить эффективность программного обеспечения для обнаружения сходства в условиях высшего образования. В одной части исследования одной группе студентов было поручено написать статью. Этих студентов сначала проинформировали о плагиате и сообщили, что их работа должна проверяться через систему обнаружения сходства содержания. Второй группе студентов было поручено написать работу без какой-либо информации о плагиате. Исследователи ожидали найти более низкие показатели в первой группе, но обнаружили примерно одинаковый уровень плагиата в обеих группах. [15]
Подходы [ править ]
На рисунке ниже представлена классификация всех подходов к обнаружению, используемых в настоящее время для компьютерного обнаружения сходства контента. Подходы характеризуются типом проводимой ими оценки сходства: глобальная или локальная. Подходы к глобальной оценке сходства используют характеристики, взятые из больших частей текста или документа в целом, для вычисления сходства, тогда как локальные методы исследуют в качестве входных данных только предварительно выбранные сегменты текста. [ нужна ссылка ]

Отпечатки пальцев [ править ]
Отпечатки пальцев в настоящее время являются наиболее широко применяемым подходом к обнаружению сходства контента. Этот метод формирует репрезентативные дайджесты документов, выбирая из них набор из нескольких подстрок ( n-грамм ). Наборы представляют собой отпечатки пальцев , а их элементы называются мелочами. [17] [18] Подозрительный документ проверяется на плагиат путем вычисления его отпечатка пальца и запроса деталей с помощью заранее вычисленного индекса отпечатков пальцев для всех документов справочной коллекции. Совпадение мелочей с деталями других документов указывает на общие сегменты текста и предполагает потенциальный плагиат, если они превышают выбранный порог сходства. [19] Вычислительные ресурсы и время являются ограничивающими факторами для снятия отпечатков пальцев, поэтому этот метод обычно сравнивает только подмножество мелочей, чтобы ускорить вычисления и обеспечить проверку очень больших коллекций, таких как Интернет. [17]
Соответствие строк [ править ]
Сопоставление строк — распространенный подход, используемый в информатике. Применительно к проблеме обнаружения плагиата документы сравниваются на предмет дословного совпадения текста. Для решения этой задачи было предложено множество методов, некоторые из которых были адаптированы для внешнего обнаружения плагиата. Проверка подозрительного документа в этом режиме требует вычисления и хранения эффективно сопоставимых представлений для всех документов в коллекции ссылок для их попарного сравнения. Обычно модели суффиксных документов, такие как суффиксные деревья для этой задачи используются или суффиксные векторы. Тем не менее, сопоставление подстрок остается дорогостоящим с точки зрения вычислений, что делает его нежизнеспособным решением для проверки больших коллекций документов. [20] [21] [22]
Мешочек слов [ править ]
Анализ мешка слов представляет собой внедрение поиска в векторном пространстве , традиционной концепции IR, в область обнаружения сходства контента. Документы представлены как один или несколько векторов, например, для разных частей документа, которые используются для вычислений попарного сходства. Вычисление сходства может затем опираться на традиционную косинусную меру сходства или на более сложные меры сходства. [23] [24] [25]
Анализ цитирования [ править ]
Обнаружение плагиата на основе цитирования (CbPD) [26] опирается на анализ цитирования и является единственным подходом к обнаружению плагиата, который не основан на текстовом сходстве. [27] CbPD исследует цитирование и справочную информацию в текстах, чтобы выявить схожие закономерности в последовательностях цитирования. Таким образом, этот подход подходит для научных текстов или других академических документов, содержащих цитаты. Анализ цитирования для выявления плагиата — относительно молодая концепция. Он не был принят в коммерческом программном обеспечении, но существует первый прототип системы обнаружения плагиата на основе цитирования. [28] Схожий порядок и близость цитирования в исследованных документах являются основными критериями, используемыми для расчета сходства шаблонов цитирования. Шаблоны цитирования представляют собой подпоследовательности, неисключительно содержащие цитаты, общие для сравниваемых документов. [27] [29] Факторы, включая абсолютное количество или относительную долю общих цитат в шаблоне, а также вероятность того, что цитаты встречаются в документе одновременно, также учитываются для количественной оценки степени сходства шаблонов. [27] [29] [30] [31]
Стилометрия [ править ]
Стилометрия включает статистические методы количественной оценки уникального стиля письма автора. [32] [33] и в основном используется для установления авторства или выявления фактического плагиата. [34] Для выявления плагиата путем указания авторства необходимо проверить, соответствует ли стиль написания подозрительного документа, который предположительно написан определенным автором, стилю написания корпуса документов, написанных тем же автором. С другой стороны, обнаружение внутреннего плагиата выявляет плагиат на основе внутренних доказательств подозрительного документа без сравнения его с другими документами. Это осуществляется путем построения и сравнения стилометрических моделей для разных фрагментов текста подозрительного документа, а отрывки, стилистически отличающиеся от других, помечаются как потенциально плагиатные/нарушенные. [8] Несмотря на простоту извлечения, n-граммы символов оказались одними из лучших стилометрических признаков для обнаружения внутреннего плагиата. [35]
Нейронные сети [ править ]
Более поздние подходы к оценке сходства контента с использованием нейронных сетей достигли значительно большей точности, но требуют больших вычислительных затрат. [36] Традиционные подходы к нейронным сетям встраивают обе части контента в вложения семантических векторов, чтобы вычислить их сходство, которое часто является их косинусным сходством. Более продвинутые методы выполняют сквозное прогнозирование сходства или классификации с использованием архитектуры Transformer . [37] [38] Обнаружение перефразирования особенно выигрывает от предварительно обученных моделей с высокой степенью параметризации.
Производительность [ править ]
Сравнительная оценка систем обнаружения сходства контента [6] [39] [40] [41] [42] [43] указывают, что их эффективность зависит от типа присутствующего плагиата (см. рисунок). За исключением анализа шаблонов цитирования, все подходы к обнаружению основаны на текстовом сходстве. Поэтому симптоматично, что точность обнаружения снижается по мере того, как больше случаев плагиата запутывается.
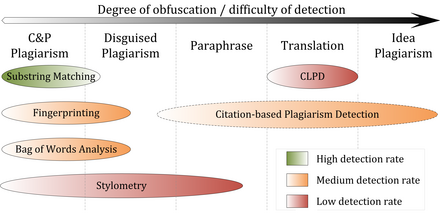
Буквальные копии, т. е. плагиат копирования и вставки (c&p), явное нарушение авторских прав или случаи скромно замаскированного плагиата, могут быть обнаружены с высокой точностью с помощью текущей внешней PDS, если источник доступен для программного обеспечения. В частности, процедуры сопоставления подстрок обеспечивают хорошую производительность при плагиате c&p, поскольку они обычно используют модели документов без потерь, такие как суффиксные деревья . Производительность систем, использующих отпечатки пальцев или анализ набора слов при обнаружении копий, зависит от потери информации, вызванной используемой моделью документа. Применяя гибкие стратегии разделения и отбора, они лучше способны обнаруживать умеренные формы замаскированного плагиата по сравнению с процедурами сопоставления подстрок.
Обнаружение внутреннего плагиата с помощью стилометрии может в некоторой степени преодолеть границы текстового сходства за счет сравнения лингвистического сходства. Учитывая, что стилистические различия между плагиатом и оригинальными фрагментами значительны и могут быть надежно идентифицированы, стилометрия может помочь в выявлении замаскированного и перефразированного плагиата. Стилометрические сравнения, скорее всего, не принесут результата в тех случаях, когда фрагменты сильно перефразированы до такой степени, что они больше напоминают личный стиль письма плагиатора, или если текст был составлен несколькими авторами. Результаты Международных конкурсов по выявлению плагиата, проведенных в 2009, 2010 и 2011 годах, [6] [42] [43] а также эксперименты, проведенные Штейном, [34] указывают на то, что стилометрический анализ, по-видимому, работает надежно только для документов длиной в несколько тысяч или десятков тысяч слов, что ограничивает применимость метода в условиях CaPD.
Все больше исследований проводится по методам и системам, способным обнаруживать плагиат в переводе. В настоящее время обнаружение межъязыкового плагиата (CLPD) не рассматривается как зрелая технология. [44] и соответствующие системы на практике не смогли достичь удовлетворительных результатов обнаружения. [41]
Обнаружение плагиата на основе цитирования с использованием анализа шаблонов цитирования способно выявлять более сильные парафразы и переводы с более высокими показателями успеха по сравнению с другими подходами к обнаружению, поскольку оно не зависит от текстовых характеристик. [27] [30] Однако, поскольку анализ структуры цитирования зависит от наличия достаточной информации о цитировании, он ограничивается академическими текстами. Он по-прежнему уступает текстовым подходам в обнаружении более коротких фрагментов плагиата, которые типичны для случаев плагиата методом копирования и вставки или встряхивания и вставки; последнее относится к смешиванию слегка измененных фрагментов из разных источников. [45]
Программное обеспечение [ править ]
Разработка программного обеспечения для обнаружения сходства контента для использования с текстовыми документами характеризуется рядом факторов: [46]
| Фактор | Описание и альтернативы |
|---|---|
| Область поиска | В общедоступном Интернете с использованием поисковых систем / Институциональные базы данных / Локальная, системная база данных. [ нужна ссылка ] |
| Время анализа | Задержка между моментом подачи документа и моментом предоставления результатов. [ нужна ссылка ] |
| Емкость документов/пакетная обработка | Количество документов, которые система может обработать за единицу времени. [ нужна ссылка ] |
| Проверьте интенсивность | Как часто и для каких типов фрагментов документов (абзацев, предложений, последовательностей слов фиксированной длины) система запрашивает внешние ресурсы, например поисковые системы. |
| Тип алгоритма сравнения | Алгоритмы, определяющие способ, которым система сравнивает документы друг с другом. [ нужна ссылка ] |
| Точность и отзыв | Количество документов, правильно помеченных как плагиат, по сравнению с общим количеством помеченных документов и общим количеством документов, которые фактически были плагиатом. Высокая точность означает, что было обнаружено мало ложноположительных результатов , а высокая полнота означает, что мало ложноотрицательных результатов осталось незамеченными. [ нужна ссылка ] |
Большинство крупномасштабных систем обнаружения плагиата используют большие внутренние базы данных (в дополнение к другим ресурсам), которые растут с каждым дополнительным документом, представленным на анализ. Однако некоторые считают эту функцию нарушением студенческих авторских прав . [ нужна ссылка ]
В исходном коде [ править ]
Плагиат в компьютерном исходном коде также встречается часто и требует использования других инструментов, чем те, которые используются для сравнения текста в документе. Значительные исследования были посвящены плагиату академического исходного кода. [47]
Отличительной особенностью плагиата исходного кода является отсутствие «фабрик эссе» , которые можно найти в традиционном плагиате. Поскольку большинство заданий по программированию предполагают, что учащиеся напишут программы с очень специфическими требованиями, очень сложно найти существующие программы, которые уже отвечают им. Поскольку интегрировать внешний код зачастую сложнее, чем писать его с нуля, большинство студентов, занимающихся плагиатом, предпочитают делать это у своих сверстников.
По словам Роя и Корди, [48] Алгоритмы обнаружения сходства исходного кода можно классифицировать как основанные либо на
- Строки – ищите точные текстовые совпадения сегментов, например, по пять слов. Быстро, но можно запутаться при переименовании идентификаторов.
- Токены — как и строки, но сначала используется лексер для преобразования программы в токены . При этом пробелы, комментарии и имена идентификаторов отбрасываются, что делает систему более устойчивой к простым заменам текста. Большинство академических систем обнаружения плагиата работают на этом уровне, используя различные алгоритмы для измерения сходства между последовательностями токенов.
- Деревья разбора – создавайте и сравнивайте деревья разбора. Это позволяет обнаружить сходства на более высоком уровне. Например, сравнение деревьев может нормализовать условные операторы и обнаружить эквивалентные конструкции, похожие друг на друга.
- Графы зависимостей программ (PDG) - PDG фиксирует фактический поток управления в программе и позволяет находить эквиваленты гораздо более высокого уровня, с большими затратами в сложности и времени вычислений.
- Метрики – метрики фиксируют «оценки» сегментов кода в соответствии с определенными критериями; например, «количество циклов и условий» или «количество различных используемых переменных». Метрики легко вычисляются и их можно быстро сравнивать, но они также могут приводить к ложным срабатываниям: два фрагмента с одинаковыми оценками по набору метрик могут делать совершенно разные вещи.
- Гибридные подходы – например, деревья синтаксического анализа + суффиксные деревья могут сочетать в себе возможности обнаружения деревьев синтаксического анализа со скоростью, обеспечиваемой суффиксными деревьями, типом структуры данных для сопоставления строк.
Предыдущая классификация была разработана для рефакторинга кода , а не для обнаружения академического плагиата (важная цель рефакторинга — избежать дублирования кода , называемого в литературе клонами кода). Вышеупомянутые подходы эффективны против разных уровней сходства; Сходство низкого уровня относится к идентичному тексту, тогда как сходство высокого уровня может быть связано с схожими спецификациями. В академических условиях, когда ожидается, что все учащиеся будут писать код в соответствии с одинаковыми спецификациями, полностью ожидается функционально эквивалентный код (с высоким уровнем сходства), и только низкоуровневое сходство рассматривается как доказательство мошенничества.
Алгоритмы [ править ]
Для обнаружения дублированного кода был предложен ряд различных алгоритмов. Например:
- . Алгоритм Бейкера [49]
- Алгоритм поиска строки Рабина-Карпа .
- Использование абстрактных синтаксических деревьев . [50]
- Визуальное обнаружение клонов. [51]
- Подсчет обнаружения клонов матрицы. [52] [53]
- Хэширование с учетом местоположения
- Антиобъединение [54]
при использовании программного обеспечения для сопоставления текстов для плагиата обнаружения Осложнения
Были задокументированы различные осложнения при использовании программного обеспечения для сопоставления текста для обнаружения плагиата. Одна из наиболее распространенных проблем документально сосредоточена на проблеме прав интеллектуальной собственности. Основной аргумент заключается в том, что материалы должны быть добавлены в базу данных, чтобы TMS могла эффективно определить соответствие, но добавление материалов пользователей в такую базу данных может нарушить их права интеллектуальной собственности. Этот вопрос поднимался в ряде судебных дел.
Дополнительная сложность при использовании TMS заключается в том, что программа находит только точные совпадения с другим текстом. Например, он не выявляет плохо перефразированную работу или практику плагиата с использованием достаточного количества замен слов, чтобы избежать обнаружения программным обеспечением, что известно как рогетинг .
См. также [ править ]
- Программное обеспечение для обнаружения искусственного интеллекта — программное обеспечение для обнаружения контента, созданного искусственным интеллектом.
- Категория:Детекторы плагиата
- Сравнение программ антиплагиата
- Хеширование с учетом локальности - алгоритмический метод с использованием хеширования.
- Поиск ближайшего соседа - Задача оптимизации в информатике
- Обнаружение перефразирования — автоматическое создание или распознавание перефразированного текста.
- Колмогоровская сложность # Сжатие - используется для оценки сходства между последовательностями токенов в нескольких системах.
- Обнаружение копирования видео
Ссылки [ править ]
- ^ Калвин, Финтан; Ланкастер, Томас (2001). «Плагиат, предотвращение, сдерживание и выявление» . CiteSeerX 10.1.1.107.178 . Архивировано из оригинала 18 апреля 2021 года . Проверено 11 ноября 2022 г. - через Академию высшего образования .
- ↑ Перейти обратно: Перейти обратно: а б Бретаг Т. и Махмуд С. (2009). Модель определения студенческого плагиата: электронное обнаружение и академическая оценка. Журнал практики университетского преподавания и обучения, 6 (1). Получено с http://ro.uow.edu.au/jutlp/vol6/iss1/6.
- ^ Макдональд Р. и Кэрролл Дж. (2006). Плагиат — сложная проблема, требующая целостного институционального подхода. Оценка и оценка в высшем образовании, 31 (2), 233–245. дои : 10.1080/02602930500262536
- ^ Фолтынек, Томаш; Меушке, Норман; Гипп, Бела (16 октября 2019 г.). «Обнаружение академического плагиата: систематический обзор литературы» . Обзоры вычислительной техники ACM . 52 (6): 1–42. дои : 10.1145/3345317 .
- ^ Штейн, Бенно; Коппель, Моше; Стамататос, Эфстатиос (декабрь 2007 г.), «Анализ плагиата, идентификация авторства и обнаружение почти дубликатов PAN'07» (PDF) , SIGIR Forum , 41 (2): 68, doi : 10.1145/1328964.1328976 , S2CID 6379659 , заархивировано из оригинал (PDF) 2 апреля 2012 г. , дата обращения 7 октября 2011 г.
- ↑ Перейти обратно: Перейти обратно: а б с Поттаст, Мартин; Штейн, Бенно; Эйзельт, Андреас; Баррон-Седеньо, Альберто; Россо, Паоло (2009 г.), «Обзор 1-го международного конкурса по обнаружению плагиата», PAN09 - 3-й семинар по выявлению плагиата, авторства и неправомерного использования программного обеспечения в социальных сетях и 1-й международный конкурс по обнаружению плагиата (PDF) , Материалы семинара CEUR, том. 502, стр. 1–9, ISSN 1613-0073 , заархивировано из оригинала (PDF) 2 апреля 2012 г.
- ^ Штейн, Бенно; Мейер цу Эйссен, Свен; Поттаст, Мартин (2007), «Стратегии поиска плагиатных документов», Материалы 30-й ежегодной международной конференции ACM SIGIR (PDF) , ACM, стр. 825–826, doi : 10.1145/1277741.1277928 , ISBN 978-1-59593-597-7 , S2CID 3898511 , заархивировано из оригинала (PDF) 2 апреля 2012 г. , получено 7 октября 2011 г.
- ↑ Перейти обратно: Перейти обратно: а б Мейер цу Эйссен, Свен; Стейн, Бенно (2006), «Обнаружение внутреннего плагиата», Достижения в области поиска информации, 28-я Европейская конференция по IR-исследованиям, ECIR 2006, Лондон, Великобритания, 10–12 апреля 2006 г., Материалы (PDF) , Конспекты лекций по информатике, том. 3936, Springer, стр. 565–569, CiteSeerX 10.1.1.110.5366 , doi : 10.1007/11735106_66 , ISBN 978-3-540-33347-0 , заархивировано из оригинала (PDF) 2 апреля 2012 г. , получено 7 октября 2011 г.
- ^ Бенсалем, Имене (2020). «Внутреннее обнаружение плагиата: исследование». Обнаружение плагиата: акцент на внутренний подход и оценку арабского языка (кандидатская диссертация) . Константин 2 Университет. дои : 10.13140/RG.2.2.25727.84641 .
- ^ Бао, Цзюнь-Пэн; Малкольм, Джеймс А. (2006), «Сходство текстов в статьях академических конференций», Материалы 2-й Международной конференции по плагиату (PDF) , Northumbria University Press, заархивировано из оригинала (PDF) 16 сентября 2018 г. , получено 7 октября 2011 г.
- ^ Клаф, Пол (2000), Плагиат в естественных языках и языках программирования, обзор современных инструментов и технологий (PDF) (технический отчет), факультет компьютерных наук Шеффилдского университета, заархивировано из оригинала (PDF) 18 августа 2011 г.
- ^ Калвин, Финтан; Ланкастер, Томас (2001), «Проблемы плагиата в высшем образовании» (PDF) , Vine , 31 (2): 36–41, doi : 10.1108/03055720010804005 , заархивировано из оригинала (PDF) 5 апреля 2012 г.
- ^ Ланкастер, Томас (2003), «Эффективное и действенное обнаружение плагиата» (докторская диссертация), Школа вычислительной техники, информационных систем и математики Университета Саут-Бэнк
- ^ Маурер, Герман; Зака, Билал (2007 г.), «Плагиат - проблема и как с ней бороться», Материалы Всемирной конференции по образовательным мультимедиа, гипермедиа и телекоммуникациям, 2007 г. , AACE, стр. 4451–4458, ISBN 9781880094624
- ^ Юманс, Роберт Дж. (ноябрь 2011 г.). «Снижает ли внедрение программного обеспечения для обнаружения плагиата в высшем образовании количество плагиата?». Исследования в сфере высшего образования . 36 (7): 749–761. дои : 10.1080/03075079.2010.523457 . S2CID 144143548 .
- ^ Меушке, Норман; Гипп, Бела (2013), «Современное состояние обнаружения академического плагиата» (PDF) , Международный журнал честности образования , 9 (1): 50–71, doi : 10.5281/zenodo.3482941 , получено 15 февраля 2024 г.
- ↑ Перейти обратно: Перейти обратно: а б Хоад, Тимоти; Зобель, Джастин (2003), «Методы идентификации версионных и плагиатных документов» (PDF) , Журнал Американского общества информационных наук и технологий , 54 (3): 203–215, CiteSeerX 10.1.1.18.2680 , doi : 10.1002 /asi.10170 , заархивировано из оригинала (PDF) 30 апреля 2015 г. , получено 14 октября 2014 г.
- ^ Штейн, Бенно (июль 2005 г.), «Нечеткие отпечатки пальцев для поиска текстовой информации», Труды I-KNOW '05, 5-й Международной конференции по управлению знаниями, Грац, Австрия (PDF) , Springer, Know-Center, стр. . 572–579, заархивировано из оригинала (PDF) 2 апреля 2012 г. , получено 7 октября 2011 г.
- ^ Брин, Сергей; Дэвис, Джеймс; Гарсиа-Молина, Гектор (1995), «Механизмы обнаружения копирования для цифровых документов», Труды Международной конференции ACM SIGMOD 1995 года по управлению данными (PDF) , ACM, стр. 398–409, CiteSeerX 10.1.1.49.1567 , doi : 10.1145/223784.223855 , ISBN 978-1-59593-060-6 , S2CID 8652205 , заархивировано из оригинала (PDF) 18 августа 2016 г. , получено 7 октября 2011 г.
- ^ Моностори, Кристиан; Заславский, Аркадий; Шмидт, Хайнц (2000), «Система обнаружения перекрытия документов для распределенных цифровых библиотек», Материалы пятой конференции ACM по цифровым библиотекам (PDF) , ACM, стр. 226–227, doi : 10.1145/336597.336667 , ISBN 978-1-58113-231-1 , S2CID 5796686 , заархивировано из оригинала (PDF) 15 апреля 2012 г. , получено 7 октября 2011 г.
- ^ Бейкер, Бренда С. (февраль 1993 г.), «Об обнаружении дублирования в строках и программном обеспечении» (технический отчет), AT&T Bell Laboratories, Нью-Джерси, заархивировано из оригинала (gs) 30 октября 2007 г.
- ^ Хмелев Дмитрий В.; Тихан, Уильям Дж. (2003), «Мера, основанная на повторении, для проверки текстовых коллекций и категоризации текста», SIGIR'03: Материалы 26-й ежегодной международной конференции ACM SIGIR по исследованиям и разработкам в области поиска информации , ACM, стр. 104–110 , CiteSeerX 10.1.1.9.6155 , doi : 10.1145/860435.860456 , ISBN 978-1581136463 , S2CID 7316639
- ^ Си, Антонио; Леонг, Хонг Ва; Лау, Ринсон WH (1997), «ПРОВЕРКА: Система обнаружения плагиата в документах», SAC '97: Материалы симпозиума ACM 1997 года по прикладным вычислениям (PDF) , ACM, стр. 70–77, doi : 10.1145/331697.335176 , ISBN 978-0-89791-850-3 , S2CID 15273799
- ^ Дреер, Хайнц (2007), «Автоматический концептуальный анализ для обнаружения плагиата» (PDF) , Информация и не только: Журнал проблем информатизации науки и информационных технологий , 4 : 601–614, doi : 10.28945/974
- ^ Мюр, Маркус; Зехнер, Марио; Керн, Роман; Гранитцер, Майкл (2009), «Обнаружение внешнего и внутреннего плагиата с использованием векторных пространственных моделей», PAN09 - 3-й семинар по выявлению плагиата, авторства и неправомерного использования программного обеспечения в социальных сетях и 1-й международный конкурс по обнаружению плагиата (PDF) , Материалы семинара CEUR, том. 502, стр. 47–55, ISSN 1613-0073 , заархивировано из оригинала (PDF) 2 апреля 2012 г.
- ^ Гипп, Бела (2014), Обнаружение плагиата на основе цитирования , Springer Vieweg Research, ISBN 978-3-658-06393-1
- ↑ Перейти обратно: Перейти обратно: а б с д Гипп, Бела; Бил, Йоран (июнь 2010 г.), «Обнаружение плагиата на основе цитирования - новый подход к независимому выявлению плагиата на рабочем языке», Материалы 21-й конференции ACM по гипертексту и гипермедиа (HT'10) (PDF) , ACM, стр. 273– 274, номер домена : 10.1145/1810617.1810671 , ISBN 978-1-4503-0041-4 , S2CID 2668037 , заархивировано из оригинала (PDF) 25 апреля 2012 г. , получено 21 октября 2011 г.
- ^ Гипп, Бела; Меушке, Норман; Брайтингер, Коринна; Липински, Марио; Нюрнбергер, Андреас (28 июля 2013 г.), «Демонстрация анализа шаблонов цитирования для обнаружения плагиата», Материалы 36-й Международной конференции ACM SIGIR по исследованиям и разработкам в области информационного поиска (PDF) , ACM, стр. 1119, номер домена : 10.1145/2484028.2484214 , ISBN 9781450320344 , S2CID 2106222
- ↑ Перейти обратно: Перейти обратно: а б Гипп, Бела; Мейшке, Норман (сентябрь 2011 г.), «Алгоритмы сопоставления шаблонов цитирования для обнаружения плагиата на основе цитирования: жадное разбиение цитирования, фрагментирование цитирования и самая длинная общая последовательность цитирования», Материалы 11-го симпозиума ACM по документальной инженерии (DocEng2011) (PDF) , ACM , стр. 249–258, doi : 10.1145/2034691.2034741 , ISBN. 978-1-4503-0863-2 , S2CID 207190305 , заархивировано из оригинала (PDF) 25 апреля 2012 г. , получено 7 октября 2011 г.
- ↑ Перейти обратно: Перейти обратно: а б Гипп, Бела; Меушке, Норман; Бил, Йоран (июнь 2011 г.), «Сравнительная оценка подходов к обнаружению плагиата на основе текста и цитирования с использованием GuttenPlag», Материалы 11-й совместной конференции ACM/IEEE-CS по цифровым библиотекам (JCDL'11) (PDF) , ACM, стр. . 255–258, CiteSeerX 10.1.1.736.4865 , номер doi : 10.1145/1998076.1998124 , ISBN. 978-1-4503-0744-4 , S2CID 3683238 , заархивировано из оригинала (PDF) 25 апреля 2012 г. , получено 7 октября 2011 г.
- ^ Гипп, Бела; Бил, Йоран (июль 2009 г.), «Анализ близости цитирования (CPA) - новый подход к выявлению связанных работ на основе анализа совместного цитирования», Материалы 12-й Международной конференции по наукометрике и информаметрике (ISSI'09) (PDF) , Международное общество наукометрии и информаметрики, стр. 571–575, ISSN 2175-1935 , заархивировано из оригинала (PDF) 13 сентября 2012 г. , получено 7 октября 2011 г.
- ^ Холмс, Дэвид И. (1998), «Эволюция стилометрии в гуманитарных науках», Literary and Linguistic Computing , 13 (3): 111–117, doi : 10.1093/llc/13.3.111
- ^ Юола, Патрик (2006), «Атрибуция авторства» (PDF) , Основы и тенденции в области информационного поиска , 1 (3): 233–334, CiteSeerX 10.1.1.219.1605 , doi : 10.1561/1500000005 , ISSN 1554-0669 , в архиве из оригинала (PDF) 24 октября 2020 г. , получено 7 октября 2011 г.
- ↑ Перейти обратно: Перейти обратно: а б Штейн, Бенно; Липка, Недим; Преттенхофер, Питер (2011), «Внутренний анализ плагиата» (PDF) , Языковые ресурсы и оценка , 45 (1): 63–82, doi : 10.1007/s10579-010-9115-y , ISSN 1574-020X , S2CID 13426762 , архивировано из оригинала (PDF) 2 апреля 2012 г. , получено 7 октября 2011 г.
- ^ Бенсалем, Имене; Россо, Паоло; Чихи, Салим (2019). «Об использовании символьных n-грамм как единственного доказательства плагиата». Языковые ресурсы и оценка . 53 (3): 363–396. дои : 10.1007/s10579-019-09444-w . hdl : 10251/159151 . S2CID 86630897 .
- ^ Реймерс, Нильс; Гуревич, Ирина (2019). «Предложение-BERT: встраивание предложений с использованием сиамских BERT-сетей». arXiv : 1908.10084 [ cs.CL ].
- ^ Лан, Увэй; Сюй, Вэй (2018). «Модели нейронных сетей для идентификации перефразирования, семантического текстового сходства, вывода на естественном языке и ответов на вопросы» . Материалы 27-й Международной конференции по компьютерной лингвистике . Санта-Фе, Нью-Мексико, США: Ассоциация компьютерной лингвистики: 3890–3902. arXiv : 1806.04330 .
- ^ Вале, Ян Филип; Руас, Терри; Фолтынек, Томаш; Меушке, Норман; Гипп, Бела (2022), Смитс, Малте (редактор), «Выявление машинно-перефразированного плагиата» , Информация для лучшего мира: формирование глобального будущего , Конспекты лекций по информатике, том. 13192, Чам: Springer International Publishing, стр. 393–413, arXiv : 2103.11909 , doi : 10.1007/978-3-030-96957-8_34 , ISBN 978-3-030-96956-1 , S2CID 232307572 , получено 6 октября 2022 г.
- ^ Portal Plagiat - Softwaretest 2004 (на немецком языке), HTW University of Applied Sciences Berlin, заархивировано из оригинала 25 октября 2011 г. , получено 6 октября 2011 г.
- ^ Portal Plagiat — Softwaretest 2008 (на немецком языке), Университет прикладных наук HTW в Берлине , получено 6 октября 2011 г.
- ↑ Перейти обратно: Перейти обратно: а б Portal Plagiat — Softwaretest 2010 (на немецком языке), Университет прикладных наук HTW в Берлине , получено 6 октября 2011 г.
- ↑ Перейти обратно: Перейти обратно: а б Поттаст, Мартин; Баррон-Седеньо, Альберто; Эйзельт, Андреас; Штейн, Бенно; Россо, Паоло (2010 г.), «Обзор 2-го Международного конкурса по обнаружению плагиата», записные книжки лабораторий и семинаров CLEF 2010, 22–23 сентября, Падуя, Италия (PDF) , заархивировано из оригинала (PDF) 3 апреля. 2012 , дата обращения 7 октября 2011 г.
- ↑ Перейти обратно: Перейти обратно: а б Поттаст, Мартин; Эйзельт, Андреас; Баррон-Седеньо, Альберто; Штейн, Бенно; Россо, Паоло (2011), «Обзор 3-го Международного конкурса по обнаружению плагиата», записные книжки лабораторий и семинаров CLEF 2011, 19–22 сентября, Амстердам, Нидерланды (PDF) , заархивировано из оригинала (PDF) 2 апреля. 2012 , дата обращения 7 октября 2011 г.
- ^ Поттаст, Мартин; Баррон-Седеньо, Альберто; Штейн, Бенно; Россо, Паоло (2011), «Обнаружение межъязыкового плагиата» (PDF) , Языковые ресурсы и оценка , 45 (1): 45–62, doi : 10.1007/s10579-009-9114-z , hdl : 10251/37479 , ISSN 1574-020X , S2CID 14942239 , заархивировано из оригинала (PDF) 26 ноября 2013 г. , получено 7 октября 2011 г.
- ^ Вебер-Вульф, Дебора (июнь 2008 г.), «О полезности программного обеспечения для обнаружения плагиата», в материалах 3-й Международной конференции по плагиату, Ньюкасл-апон-Тайн (PDF) , заархивировано из оригинала (PDF) 1 октября 2013 г. , получено 29 Сентябрь 2013 г.
- ^ Как проверить текст на плагиат
- ^ «Предотвращение и обнаружение плагиата — онлайн-ресурсы по плагиату исходного кода». Архивировано 15 ноября 2012 г. на Wayback Machine . высшего образования Академия Ольстерского университета .
- ↑ Рой, Чанчал Кумар; Корди, Джеймс Р. (26 сентября 2007 г.). «Опрос по исследованиям в области обнаружения клонов программного обеспечения» . Школа вычислительной техники, Королевский университет, Канада .
- ^ Бренда С. Бейкер . Программа для выявления дублированного кода. Информатика и статистика,24:49–57, 1992.
- ^ Ира Д. Бакстер и др. Обнаружение клонов с использованием абстрактных синтаксических деревьев
- ^ Визуальное обнаружение дублированного кода. Архивировано 29 июня 2006 г. в Wayback Machine Матиасом Ригером и Стефаном Дюкассом.
- ^ Юань, Ю. и Го, Ю. CMCD: Обнаружение клонов кода на основе матрицы подсчета, 18-я Азиатско-Тихоокеанская конференция по разработке программного обеспечения, 2011 г. IEEE, декабрь 2011 г., стр. 250–257.
- ^ Чен, X., Ван, AY, и Темперо, ED (2014). Репликация и воспроизведение исследований по обнаружению клонов кода . В ACSC (стр. 105-114).
- ^ Bulychev, Peter, and Marius Minea. " Duplicate code detection using anti-unification ." Proceedings of the Spring/Summer Young Researchers’ Colloquium on Software Engineering. No. 2. Федеральное государственное бюджетное учреждение науки Институт системного программирования Российской академии наук, 2008.
Литература [ править ]
- Кэрролл, Дж. (2002). Руководство по предотвращению плагиата в высшем образовании . Оксфорд: Оксфордский центр развития персонала и обучения, Оксфордский университет Брукса. (96 стр.), ISBN 1873576560
- Зейдман, Б. (2011). Справочник программного IP-детектива . Прентис Холл. (480 стр.), ISBN 0137035330