МЕТЕОР
Эта статья может быть слишком технической для понимания большинства читателей . ( Октябрь 2010 г. ) |
METEOR ( Метрика для оценки перевода с явным упорядочением ) — это метрика для оценки результатов машинного перевода . Метрика основана на гармоническом среднем значении точности униграмм и полноты , причем вес отзыва выше, чем точность. Он также имеет несколько функций, которых нет в других метриках, таких как определение основы и сопоставление синонимов , а также стандартное точное сопоставление слов. Эта метрика была разработана для устранения некоторых проблем, обнаруженных в более популярной метрике BLEU , а также для обеспечения хорошей корреляции с человеческими суждениями на уровне предложения или сегмента. Это отличается от метрики BLEU тем, что BLEU ищет корреляцию на уровне корпуса.

Были представлены результаты, которые дают корреляцию до 0,964 с человеческим суждением на уровне корпуса по сравнению с . достижением BLEU 0,817 на том же наборе данных На уровне предложения максимальная корреляция с человеческим суждением составила 0,403. [1]
Алгоритм
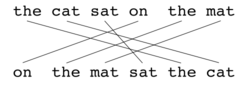
[ редактировать ]Как и в случае с BLEU , основной единицей оценки является предложение, алгоритм сначала создает выравнивание (см. иллюстрации) между двумя предложениями , строкой-кандидатом перевода и строкой эталонного перевода. Выравнивание — это набор отображений между униграммами . Отображение можно рассматривать как линию между униграммой в одной строке и униграммой в другой строке. Ограничения заключаются в следующем; каждая униграмма в потенциальном переводе должна сопоставляться с нулем или одной униграммой в ссылке. Сопоставления выбираются для создания выравнивания, как определено выше. Если имеются две трассы с одинаковым количеством отображений, выбирается трасса с наименьшим количеством крестов , то есть с меньшим количеством пересечений двух отображений. Из двух показанных трасс в этой точке будет выбрана трасса (a). Этапы выполняются последовательно, и каждый этап добавляет к выравниванию только те униграммы, которые не были сопоставлены на предыдущих этапах. После расчета окончательного выравнивания оценка рассчитывается следующим образом: Точность в униграммах. P рассчитывается как:
| Модуль | Кандидат | Ссылка | Соответствовать |
|---|---|---|---|
| Точный | Хороший | Хороший | Да |
| Голоса | Товары | Хороший | Да |
| Синонимия | хорошо | Хороший | Да |

Где m — количество униграмм в возможном переводе, которые также встречаются в справочном переводе, и — количество униграмм в возможном переводе. Запоминание униграмм R рассчитывается как:


Где m такое же, как указано выше, и — количество униграмм в эталонном переводе. Точность и полнота объединяются с использованием среднего гармонического значения следующим образом, при этом вес полноты в 9 раз превышает точность:


Показатели, которые были введены до сих пор, учитывают соответствие только в отношении отдельных слов, но не в отношении более крупных сегментов, которые появляются как в отсылочном, так и в предложении-кандидате. Чтобы принять это во внимание, n используются более длинные совпадения -грамм для расчета штрафа p за выравнивание. Чем больше отображений, которые не являются соседними в ссылке и предложении-кандидате, тем выше будет штраф.
Чтобы вычислить этот штраф, униграммы группируются в наименьшее количество возможных фрагментов , где фрагмент определяется как набор униграмм, соседних в гипотезе и в ссылке. Чем длиннее соседние сопоставления между кандидатом и ссылкой, тем меньше фрагментов. Перевод, идентичный ссылке, даст только один фрагмент. Штраф p рассчитывается следующим образом:

Где c — количество кусков, а — это количество отображенных униграмм. Итоговая оценка сегмента рассчитывается как M ниже. Штраф имеет эффект уменьшения до 50%, если нет биграммных или более длинных совпадений.



Чтобы вычислить оценку по всему корпусу или набору сегментов, совокупные значения P , R и p берутся , а затем объединяются по той же формуле. Алгоритм также работает для сравнения возможного перевода с несколькими эталонными переводами. В этом случае алгоритм сравнивает кандидата с каждым из ссылок и выбирает наивысший балл.
Примеры
[ редактировать ]| Ссылка | тот | кот | сидел | на | тот | вместе с |
|---|---|---|---|---|---|---|
| Гипотеза | на | тот | вместе с | сидел | тот | кот |
| Счет | ||||||
| Fсред. | ||||||
| Штраф | ||||||
| Фрагментация | ||||||




| Ссылка | тот | кот | сидел | на | тот | вместе с |
|---|---|---|---|---|---|---|
| Гипотеза | тот | кот | сидел | на | тот | вместе с |
| Счет | ||||||
| Fсред. | ||||||
| Штраф | ||||||
| Фрагментация | ||||||



| Ссылка | тот | кот | сидел | на | тот | вместе с | |
|---|---|---|---|---|---|---|---|
| Гипотеза | тот | кот | был | сидел | на | тот | вместе с |
| Счет | |||||||
| Fсред. | |||||||
| Штраф | |||||||
| Фрагментация | |||||||




См. также
[ редактировать ]- СИНИЙ
- F-мера
- НИСТ (метрический)
- РУМЯ (метрическая)
- Коэффициент ошибок в словах (WER)
- ЗАЯЦ
- Разделение существительных и фраз
Примечания
[ редактировать ]- ^ Банерджи, С. и Лави, А. (2005)
Ссылки
[ редактировать ]- Банерджи, С. и Лави, А. (2005) «МЕТЕОР: Автоматическая метрика для оценки МП с улучшенной корреляцией с человеческими суждениями» в материалах семинара по внутренним и внешним мерам оценки МП и/или обобщения на 43-м ежегодном собрании Ассоциация компьютерной лингвистики (ACL-2005), Анн-Арбор, Мичиган, июнь 2005 г.
- Лави А., Сагае К. и Джаяраман С. (2004) «Значение отзыва в автоматических метриках для оценки MT» в материалах AMTA 2004, Вашингтон, округ Колумбия. сентябрь 2004 г.
Внешние ссылки
[ редактировать ]- Автоматическая система оценки машинного перевода METEOR (включая ссылку для скачивания)