Итерация мощности
В математике ( степенная итерация также известная как степенной метод ) представляет собой алгоритм собственных значений : задана диагонализуемая матрица , алгоритм выдаст число , которое является наибольшим (по абсолютной величине) собственным значением и ненулевой вектор , который является соответствующим собственным вектором , то есть, . Алгоритм также известен как фон Мизеса итерация . [1]




Итерация мощности — очень простой алгоритм, но он может сходиться медленно. Самой трудоемкой операцией алгоритма является умножение матрицы вектором, поэтому он эффективен для очень большой разреженной матрицы с соответствующей реализацией. Скорость сходимости равна (см. следующий раздел ). Другими словами, сходимость является экспоненциальной, а основанием является спектральный разрыв .

Метод
[ редактировать ]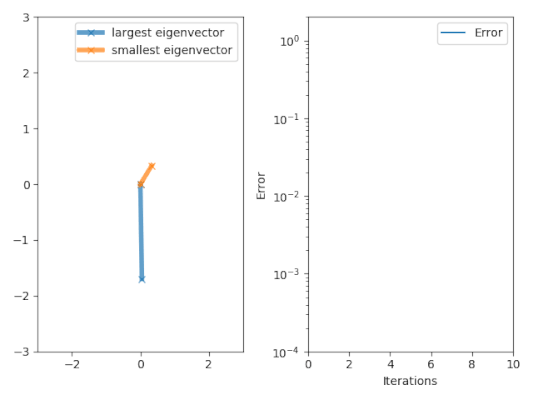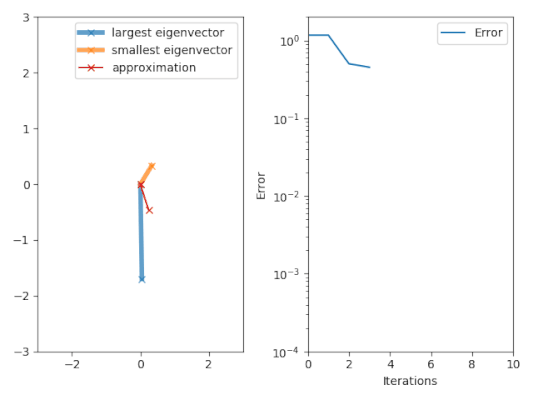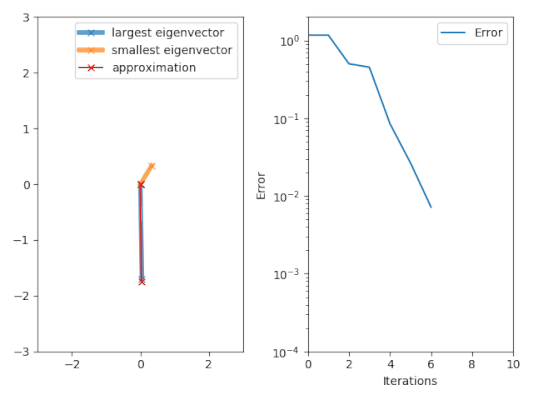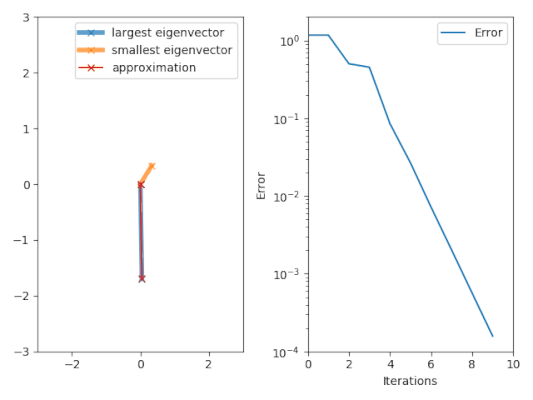

Алгоритм итерации мощности начинается с вектора , который может быть приближением к доминирующему собственному вектору или случайному вектору. Метод описывается рекуррентным соотношением


Итак, на каждой итерации вектор умножается на матрицу и нормализовано.

Если мы предположим имеет собственное значение, которое строго больше по величине, чем другие его собственные значения и стартовый вектор имеет ненулевой компонент в направлении собственного вектора, связанного с доминирующим собственным значением, то подпоследовательность сходится к собственному вектору, связанному с доминирующим собственным значением.

Без двух сделанных выше предположений последовательность не обязательно сходится. В этой последовательности
- ,

где - собственный вектор, связанный с доминирующим собственным значением, и . Наличие термина подразумевает, что не сходится, если . При двух перечисленных выше предположениях последовательность определяется






сходится к доминирующему собственному значению (с коэффициентом Рэлея ). [ нужны разъяснения ]
Это можно вычислить с помощью следующего алгоритма (показанного в Python с NumPy):
#!/usr/bin/env python3
import numpy as np
def power_iteration(A, num_iterations: int):
# Ideally choose a random vector
# To decrease the chance that our vector
# Is orthogonal to the eigenvector
b_k = np.random.rand(A.shape[1])
for _ in range(num_iterations):
# calculate the matrix-by-vector product Ab
b_k1 = np.dot(A, b_k)
# calculate the norm
b_k1_norm = np.linalg.norm(b_k1)
# re normalize the vector
b_k = b_k1 / b_k1_norm
return b_k
power_iteration(np.array([[0.5, 0.5], [0.2, 0.8]]), 10)
Вектор сходится к соответствующему собственному вектору. следует использовать коэффициент Рэлея В идеале для получения соответствующего собственного значения .
Этот алгоритм используется для расчета Google PageRank .
Этот метод также можно использовать для расчета спектрального радиуса (собственного значения с наибольшей величиной для квадратной матрицы) путем вычисления коэффициента Рэлея.

Анализ
[ редактировать ]Позволять разложиться в свою жорданову каноническую форму : , где первый столбец является собственным вектором соответствующее доминирующему собственному значению . Поскольку в общем случае доминирующее собственное значение уникален, первый иорданский блок это матрица где является наибольшим собственным значением A по величине. Стартовый вектор можно записать как линейную комбинацию столбцов V :





![{\displaystyle [\lambda _{1}],}](https://wikimedia.org/api/rest_v1/media/math/render/svg/0f3c83a8bae265cd5523c330d3b5f9901fee6ab0)

По предположению, имеет ненулевой компонент в направлении доминирующего собственного значения, поэтому .

Полезное в вычислительном отношении рекуррентное соотношение для можно переписать как:


где выражение: более поддается следующему анализу.


Выражение выше упрощается как

![{\displaystyle \left({\frac {1}{\lambda _{1}}}J\right)^{k}={\begin{bmatrix}[1]&&&&\\&\left({\frac { 1}{\lambda _{1}}}J_{2}\right)^{k}&&&\\&&\ddots &\\&&&\left({\frac {1}{\lambda _{1}}} J_{m}\right)^{k}\\\end{bmatrix}}\rightarrow {\begin{bmatrix}1&&&&\\&0&&&\\&&\ddots &\\&&&0\\\end{bmatrix}}\quad {\text{as}}\quad k\to \infty .}](https://wikimedia.org/api/rest_v1/media/math/render/svg/cec7d61aee7e07ab39497f6cf782f074c415a7fd)
Предел следует из того, что собственное значение меньше 1 по величине, поэтому


Отсюда следует, что:

Используя этот факт, может быть записано в форме, подчеркивающей его связь с когда k велико:
![{\displaystyle {\begin{aligned}b_{k}&=\left({\frac {\lambda _{1}}{|\lambda _{1}|}}\right)^{k}{\frac {c_{1}}{|c_{1}|}}{\frac {v_{1}+{\frac {1}{c_{1}}}V\left({\frac {1}{\lambda _{1}}}J\right)^{k}\left(c_{2}e_{2}+\cdots +c_{n}e_{n}\right)}{\left\|v_{1} +{\frac {1}{c_{1}}}V\left({\frac {1}{\lambda _{1}}}J\right)^{k}\left(c_{2}e_{ 2}+\cdots +c_{n}e_{n}\right)\right\|}}\\[6pt]&=e^{i\phi _{k}}{\frac {c_{1}} {|c_{1}|}}{\frac {v_{1}}{\|v_{1}\|}}+r_{k}\end{aligned}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/024832f7d5c7731b36d56df90fde0723dd480484)
где и как


Последовательность ограничен, поэтому содержит сходящую подпоследовательность. Обратите внимание, что собственный вектор, соответствующий доминирующему собственному значению, уникален только с точностью до скаляра, поэтому, хотя последовательность может не сойтись, является почти собственным вектором A для больших k .
Альтернативно, если A диагонализуемо результат , то следующее доказательство дает тот же
Пусть λ 1 , λ 2 , ..., λ m — m собственных значений (подсчитанных с кратностью) оператора A , и пусть v 1 , v 2 , ..., v m — соответствующие собственные векторы. Предположим, что является доминирующим собственным значением, так что для .


Начальный вектор можно написать:

Если выбирается случайно (с равномерной вероятностью), тогда c 1 ≠ 0 с вероятностью 1 . Сейчас,

С другой стороны:

Поэтому, сходится к (кратному) собственному вектору . Сходимость геометрическая с отношением

где обозначает второе доминирующее собственное значение. Таким образом, метод сходится медленно, если существует собственное значение, близкое по величине к доминирующему собственному значению.

Приложения
[ редактировать ]Хотя метод степенной итерации аппроксимирует только одно собственное значение матрицы, он остается полезным для некоторых вычислительных задач . Например, Google использует его для расчета PageRank документов в своей поисковой системе. [2] и Twitter использует его, чтобы показывать пользователям рекомендации, которым следует следовать. [3] Метод степенной итерации особенно подходит для разреженных матриц , таких как веб-матрица, или в качестве безматричного метода , не требующего хранения матрицы коэффициентов. явно, но вместо этого может получить доступ к функции, оценивающей произведения матрицы-вектора . Для несимметричных матриц, которые хорошо обусловлены, метод степенной итерации может превзойти более сложную итерацию Арнольди . Для симметричных матриц метод степенной итерации используется редко, поскольку его скорость сходимости можно легко увеличить, не жертвуя при этом небольшой стоимостью итерации; см., например, итерацию Ланцоша и LOBPCG .

Некоторые из более продвинутых алгоритмов собственных значений можно понимать как вариации степенной итерации. Например, метод обратной итерации применяет степенную итерацию к матрице . Другие алгоритмы рассматривают все подпространство, порожденное векторами. . Это подпространство известно как подпространство Крылова . Его можно вычислить с помощью итерации Арнольди или итерации Ланцоша . Итерация грамма [4] это суперлинейный и детерминированный метод вычисления наибольшей собственной пары.

См. также
[ редактировать ]Ссылки
[ редактировать ]- ^ Рихард фон Мизес и Х. Поллачек-Гейрингер, Практические методы решения уравнений , ЗАММ - Журнал прикладной математики и механики 9, 152-164 (1929).
- ^ Ипсен, Ильза и Ребекка М. Уиллс (5–8 мая 2005 г.). «7-й Международный симпозиум IMACS по итеративным методам научных вычислений» (PDF) . Институт Филдса, Торонто, Канада.
{{cite news}}: CS1 maint: несколько имен: список авторов ( ссылка ) - ^ Панкадж Гупта, Ашиш Гоэл, Джимми Лин, Аниш Шарма, Донг Ван и Реза Босаг Заде WTF: Система «за кем следить» в Твиттере , Материалы 22-й международной конференции по Всемирной паутине
- ^ Делатр, Б.; Бартелеми, К.; Араужо, А.; Аллаузен, А. (2023), «Эффективная оценка константы Липшица для сверточных слоев путем итерации по Граму» , Материалы 40-й Международной конференции по машинному обучению