Сложность Лемпеля – Зива
Сложность Лемпеля -Зива — это мера, которая впервые была представлена в статье «О сложности конечных последовательностей» (IEEE Trans. On IT-22,1 1976) двумя израильскими учеными-компьютерщиками, Авраамом Лемпелем и Якобом Зивом . Эта мера сложности связана с колмогоровской сложностью , но единственная функция, которую она использует, — это рекурсивная копия (т. е. неглубокая копия).
Базовый механизм этой меры сложности является отправной точкой для некоторых алгоритмов сжатия данных без потерь , таких как LZ77, LZ78 и LZW . Несмотря на то, что она основана на элементарном принципе копирования слов, эта мера сложности не является слишком ограничительной в том смысле, что она удовлетворяет основным качествам, ожидаемым от такой меры: последовательности с определенной регулярностью не имеют слишком большой сложности, и Сложность возрастает по мере увеличения длины и нерегулярности последовательности.
Сложность Лемпеля-Зива можно использовать для измерения повторяемости двоичных последовательностей и текста, например текстов песен или прозы. Также было показано, что оценки фрактальной размерности реальных данных коррелируют со сложностью Лемпеля – Зива. [1] [2]
Принцип
[ редактировать ]Пусть S — двоичная последовательность длины n, для которой нам нужно вычислить сложность Лемпеля–Зива, обозначенную C(S). Последовательность читается слева.
Представьте, что у вас есть разделительная линия, которую можно последовательно перемещать во время расчета. Сначала эта строка устанавливается сразу после первого символа, в начале последовательности. Эта начальная позиция называется позицией 1, откуда мы должны переместить ее в позицию 2, которая считается начальной позицией для следующего шага (и так далее). Нам нужно переместить разделитель (начиная с позиции 1) как можно дальше вправо, чтобы подслово между позицией 1 и позицией разделителя было словом последовательности, которая начинается перед позицией 1 разделителя.
Как только разделитель установлен на позиции, где это условие не выполняется, мы останавливаемся, перемещаем разделитель на эту позицию и начинаем снова, отмечая эту позицию как новую начальную позицию (т. е. позицию 1). Продолжайте повторять до конца последовательности. Сложность Лемпеля-Зива соответствует количеству итераций, необходимых для завершения этой процедуры.
Другими словами, сложность Лемпеля-Зива — это количество различных подстрок (или подслов), встречающихся при рассмотрении двоичной последовательности как потока (слева направо).
Официальные объяснения
[ редактировать ]Метод, предложенный Лемпелем и Зивом, использует три понятия: воспроизводимость, воспроизводимость и исчерпывающая история последовательности, которую мы здесь определили.
Обозначения
[ редактировать ]Пусть S — двоичная последовательность длины n (т. е. символы, принимающие значение 0 или 1). Позволять , с , быть подсловом от индекса i до индекса j (если пустая строка). Длина n S обозначается и последовательность называется фиксированным префиксом если:








Воспроизводимость и технологичность
[ редактировать ]
С одной стороны, последовательность S длины n называется воспроизводимой по ее префиксу S(1,j), если S(j+1,n) является подсловом S(1,j). Это обозначается S(1,j)→S.
Иными словами, S воспроизводимо из своего префикса S(1,j), если остальная часть последовательности S(j+1,n) представляет собой не что иное, как копию другого подслова (начиная с индекса i < j+ 1) из S(1,n−1).
Чтобы доказать, что последовательность S может быть воспроизведена одним из ее префиксов S(1,j), вам нужно показать, что:


С другой стороны, воспроизводимость определяется из воспроизводимости: последовательность S воспроизводима из ее префикса S(1,j), если S(1,n−1) воспроизводима из S(1,j). Это обозначается S(1,j)⇒S. Иными словами, S(j+1,n−1) должно быть копией другого подслова S(1,n-2). Последний символ S может быть новым символом (но не может быть), что, возможно, приведет к созданию нового подслова (отсюда и термин «производимость»).

Исчерпывающая история и сложность
[ редактировать ]По определению продуктивности пустая строка Λ=S(1,0) ⇒ S(1,1). Таким образом, с помощью рекурсивного производственного процесса на шаге i мы имеем S(1,hi) ⇒ S(1,hi+1), поэтому мы можем построить S из его префиксов. А поскольку S(1,i) ⇒ S(1,i+1) (при hi+1 =hi + 1) всегда верно, этот процесс производства S занимает не более n=l(S) шагов. Пусть м, , — количество шагов, необходимых для этого процесса производства S. S можно записать в разложенной форме, называемой историей S, и обозначать H(S), определяемую следующим образом:



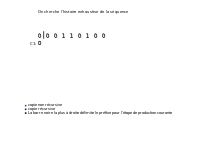
Компонент S, Hi(S), называется исчерпывающим, если S(1,hi) — самая длинная последовательность, порождаемая S(1,hi−1) (т. е. S(1,hi−1) ⇒ S( 1,hi)) но так, чтобы S(1,hi−1) не производило S(1,hi) (обозначено). Индекс p, который позволяет иметь самую длинную продукцию, называется указателем.

История S называется исчерпывающей, если все ее компоненты являются исчерпывающими, за исключением, возможно, последнего. Из определения можно показать, что любая последовательность S имеет только одну исчерпывающую историю, и эта история — это история с наименьшим числом компонентов из всех возможных историй S. Наконец, количество компонентов этой уникальной исчерпывающей истории S называется сложностью Лемпеля–Зива S.
Алгоритм
[ редактировать ]К счастью, существует очень эффективный метод вычисления этой сложности за линейное число операций ( для длина последовательности S).


Формальное описание этого метода дается следующим алгоритмом :
- i = p − 1, p — указатель (см. выше)
- u — длина текущего префикса
- v — длина текущего компонента для текущего указателя p
- vmax — конечная длина, используемая для текущего компонента (наибольшая из всех возможных указателей p)
- C — сложность Лемпеля–Зива, увеличиваемая итеративно.
// S is a binary sequence of size n
i := 0
C := 1
u := 1
v := 1
vmax := v
while u + v <= n do
if S[i + v] = S[u + v] then
v := v + 1
else
vmax := max(v, vmax)
i := i + 1
if i = u then // all the pointers have been treated
C := C + 1
u := u + vmax
v := 1
i := 0
vmax := v
else
v := 1
end if
end if
end while
if v != 1 then
C := C+1
end if
См. также
[ редактировать ]- LZ77 и LZ78 — алгоритмы сжатия, использующие аналогичную идею поиска совпадающих подстрок.
Примечания и ссылки
[ редактировать ]Ссылки
[ редактировать ]- ^ Бернс, Т.; Раджан, Р. (2015). «Бернс и Раджан (2015) Объединение показателей сложности данных ЭЭГ: умножение показателей раскрывает ранее скрытую информацию. F1000Research. 4:137» . F1000Исследования . 4 : 137. doi : 10.12688/f1000research.6590.1 . ПМЦ 4648221 . ПМИД 26594331 .
- ^ Бернс, Т.; Раджан, Р. (2019). «Математический подход к корреляции объективных спектрально-временных особенностей нелингвистических звуков с их субъективным восприятием людьми» . Границы в неврологии . 13 : 794. дои : 10.3389/fnins.2019.00794 . ПМЦ 6685481 . ПМИД 31417350 .
Библиография
[ редактировать ]- Авраам Лемпель и Джейкоб Зив, «О сложности конечных последовательностей», IEEE Trans. по теории информации, январь 1976 г., с. 75–81, том. 22, № 1
Приложение
[ редактировать ]- « Становятся ли поп-тексты более повторяющимися? » Колин Моррис — это сообщение в блоге, объясняющее, как использовать сложность Лемпеля-Зива для измерения повторяемости текстов песен (с доступным исходным кодом) .
- Бернс и Раджан (2015) Объединение показателей сложности данных ЭЭГ: умножение показателей раскрывает ранее скрытую информацию. F1000Исследования. 4:137. [1] (с доступным общедоступным кодом MATLAB).
- Бернс и Раджан (2019) Математический подход к корреляции объективных спектрально-временных характеристик нелингвистических звуков с их субъективным восприятием людьми. Границы неврологии 13:794. [2] (с доступным общедоступным кодом MATLAB).