Альтернативное дерево решений
Альтернативное дерево решений (ADTree) — это метод машинного обучения для классификации. Он обобщает деревья решений и связан с повышением .
ADTree состоит из чередующихся узлов решения, которые определяют условие предиката, и узлов прогнозирования, которые содержат одно число. Экземпляр классифицируется с помощью ADTree путем следования по всем путям, для которых все узлы принятия решений являются истинными, и суммирования всех пройденных узлов прогнозирования.
История [ править ]
ADTree были представлены Йоавом Фройндом и Лью Мейсоном. [1] Однако представленный алгоритм содержал несколько опечаток. Разъяснения и оптимизации были позже представлены Бернхардом Пфарингером, Джеффри Холмсом и Ричардом Киркби. [2] Реализации доступны в Weka и JBoost.
Мотивация [ править ]
В оригинальных алгоритмах повышения обычно использовались либо пни решений, либо или деревья решений как слабые гипотезы. Например, увеличение количества пней при принятии решений создает набор взвешенные пни решений (где — количество итераций повышения), которые затем голосуют за окончательную классификацию в соответствии со своими весами. Отдельные пни решений взвешиваются в зависимости от их способности классифицировать данные.

Повышение эффективности простого обучающегося приводит к получению неструктурированного набора гипотезы, что затрудняет вывод корреляций между атрибутами. Чередующиеся деревья решений придают структуру набору гипотез, требуя, чтобы они основывались на гипотезе, созданной на более ранней итерации. Полученный набор гипотез можно визуализировать в виде дерева на основе отношений между гипотезой и ее «родителем».
Еще одна важная особенность усиленных алгоритмов заключается в том, что на каждой итерации данные получают разное распределение . Экземпляры, которые неправильно классифицированы, получают больший вес, тогда как точно классифицированные экземпляры имеют меньший вес.
Альтернативная древовидная структура решений [ править ]
Альтернативное дерево решений состоит из узлов принятия решений и узлов прогнозирования. Узлы решений определяют предикатное условие. Узлы прогнозирования содержат одно число. У ADTree всегда есть узлы прогнозирования как корневые, так и листья. Экземпляр классифицируется с помощью ADTree путем следования всем путям, для которых все узлы решений являются истинными, и суммирования всех пройденных узлов прогнозирования. Это отличается от деревьев двоичной классификации, таких как CART ( дерево классификации и регрессии ) или C4.5 , в которых экземпляр следует только одному пути через дерево.
Пример [ править ]
Следующее дерево было построено с использованием JBoost на наборе данных базы спама. [3] (доступно в репозитории машинного обучения UCI). [4] В этом примере спам кодируется как 1 , а обычная электронная почта — как −1 .
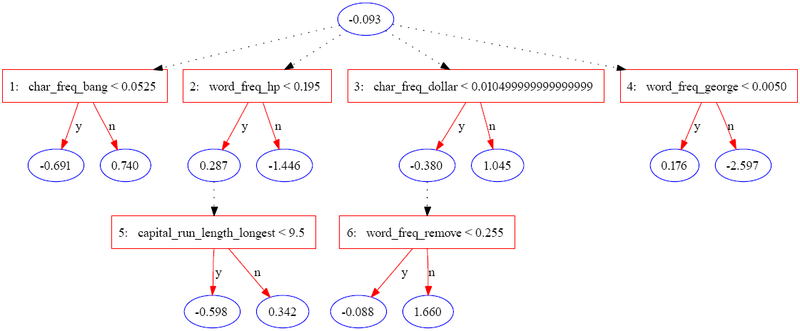
В следующей таблице содержится часть информации для одного экземпляра.
| Особенность | Ценить |
|---|---|
| char_freq_bang | 0.08 |
| word_freq_hp | 0.4 |
| Capital_run_length_longest | 4 |
| char_freq_dollar | 0 |
| word_freq_remove | 0.9 |
| word_freq_george | 0 |
| Другие особенности | ... |
Экземпляр оценивается путем суммирования всех узлов прогнозирования, через которые он проходит. В приведенном выше случае оценка равна рассчитано как
| Итерация | 0 | 1 | 2 | 3 | 4 | 5 | 6 |
|---|---|---|---|---|---|---|---|
| Значения экземпляра | — | 0,08 < 0,052 = f | .4 < .195 = f | 0 < 0,01 = т | 0 <0,005 = т | — | 0,9 < 0,225 = е |
| Прогноз | -0.093 | 0.74 | -1.446 | -0.38 | 0.176 | 0 | 1.66 |
Итоговая оценка 0,657 является положительной, поэтому экземпляр классифицируется как спам. Величина значения является мерой уверенности в прогнозе. Первоначальные авторы перечисляют три потенциальных уровня интерпретации набора атрибутов, идентифицируемых ADTree:
- Отдельные узлы можно оценить на предмет их собственных прогнозирующих способностей.
- Наборы узлов на одном и том же пути могут интерпретироваться как имеющие совместный эффект.
- Дерево можно интерпретировать как единое целое.
Необходимо проявлять осторожность при интерпретации отдельных узлов, поскольку оценки отражают повторное взвешивание данных на каждой итерации.
Описание алгоритма [ править ]
Входными данными для алгоритма альтернативного дерева решений являются:
- Набор входов где вектор атрибутов и равно -1 или 1. Входные данные также называются экземплярами.
- Набор гирь соответствующий каждому экземпляру.




Фундаментальным элементом алгоритма ADTree является правило. Одиночный Правило состоит из предварительного условия, условия и двух оценок. А условие — это предикат формы «значение атрибута <сравнение>». Предварительное условие — это просто логическое сочетание условий. Оценка правила включает пару вложенных операторов if:
1 if (precondition) 2 if (condition) 3 return score_one 4 else 5 return score_two 6 end if 7 else 8 return 0 9 end if
Алгоритму также необходимы несколько вспомогательных функций:
- возвращает сумму весов всех положительно помеченных примеров, удовлетворяющих предикату
- возвращает сумму весов всех примеров с отрицательной пометкой, которые удовлетворяют предикату
- возвращает сумму весов всех примеров, удовлетворяющих предикату




Алгоритм следующий:
1 function ad_tree 2 input Set of m training instances 3 4 wi = 1/m for all i 5 6 R0 = a rule with scores a and 0, precondition "true" and condition "true." 7 8 the set of all possible conditions 9 for 10 get values that minimize 11 12 13 14 Rj = new rule with precondition p, condition c, and weights a1 and a2 15 16 end for 17 return set of Rj










Набор увеличивается на два предусловия в каждой итерации, и можно получить древовидную структуру набора правил, отмечая предусловие, которое используется в каждом последующем правиле.

результаты Эмпирические
Рисунок 6 в оригинальной статье [1] демонстрирует, что ADTree обычно столь же надежны, как расширенные деревья решений и усиленные пни решений . Обычно эквивалентная точность может быть достигнута с помощью гораздо более простой древовидной структуры, чем алгоритмы рекурсивного разделения.
Ссылки [ править ]
- ^ Jump up to: Перейти обратно: а б Фройнд, Ю.; Мейсон, Л. (1999). «Алгоритм обучения попеременного дерева решений» (PDF) . Материалы шестнадцатой международной конференции по машинному обучению (ICML '99) . Морган Кауфманн. стр. 124–133. ISBN 978-1-55860-612-8 .
- ^ Пфарингер, Бернхард; Холмс, Джеффри; Киркби, Ричард (2001). «Оптимизация индукции альтернативных деревьев решений» (PDF) . Достижения в области обнаружения знаний и интеллектуального анализа данных. ПАКДД 2001 . Конспекты лекций по информатике. Том. 2035. Спрингер. стр. 477–487. дои : 10.1007/3-540-45357-1_50 . ISBN 978-3-540-45357-4 .
- ^ «Набор данных базы спама» . Репозиторий машинного обучения UCI . 1999.
- ^ Дуа, Д.; Графф, К. (2019). «Репозиторий машинного обучения UCI» . Калифорнийский университет, Ирвайн, Школа информационных и компьютерных наук.
Внешние ссылки [ править ]
- Введение в Boosting и ADTree (содержит множество графических примеров чередующихся деревьев решений на практике).
- Программное обеспечение JBoost, реализующее ADTrees.