Повышение (машинное обучение)
Эту статью необходимо обновить . ( апрель 2023 г. ) |
Эта статья может быть слишком технической для понимания большинства читателей . ( сентябрь 2023 г. ) |
| Часть серии о |
| Машинное обучение и интеллектуальный анализ данных |
|---|
В машинном обучении повышение — это ансамблевый метаалгоритм, предназначенный в первую очередь для уменьшения смещения и дисперсии. [1] Он используется в контролируемом обучении и в семействе алгоритмов машинного обучения, которые превращают слабых учеников в сильных. [2]
Концепция повышения основана на вопросе, поставленном Кернсом и Валиантом (1988, 1989): [3] [4] «Может ли группа слабых учеников создать одного сильного ученика?» Слабый обучающийся определяется как классификатор , который лишь незначительно коррелирует с истинной классификацией (он может маркировать примеры лучше, чем случайное угадывание). Напротив, сильный обучающийся — это классификатор, который сколь угодно хорошо коррелирует с истинной классификацией.
Роберт Шапир утвердительно ответил на вопрос, заданный Кирнсом и Валиантом, в статье, опубликованной в 1990 году. [5] Это имело серьезные последствия для машинного обучения и статистики , в первую очередь приведя к развитию бустинга. [6]
впервые была представлена, Когда проблема повышения гипотез она просто относилась к процессу превращения слабого ученика в сильного ученика. «Неофициально, проблема [подтверждения гипотезы] заключается в том, предполагает ли эффективный алгоритм обучения […], который выводит гипотезу, производительность которой лишь немного лучше, чем случайное предположение [т.е. слабый обучающийся], подразумевает ли существование эффективного алгоритма, который выводит гипотезу произвольного точность [т.е. сильная обучаемость]». [3] Алгоритмы, обеспечивающие усиление гипотез, быстро стали известны как «повышение гипотезы». Дуга Фрейнда и Шапире (Адаптивная [ат]ивная передискретизация и объединение), [7] как общий метод, является более или менее синонимом повышения. [8]
Алгоритмы повышения [ править ]
Хотя повышение не ограничено алгоритмически, большинство алгоритмов повышения состоят из итеративного изучения слабых классификаторов относительно распределения и добавления их к окончательному сильному классификатору. Когда они добавляются, им присваивается вес, связанный с точностью слабых учащихся. После добавления слабого ученика веса данных корректируются, что называется «повторным взвешиванием ». Неправильно классифицированные входные данные приобретают больший вес, а примеры, которые классифицированы правильно, теряют вес. [примечание 1] Таким образом, будущие слабые ученики больше сосредотачиваются на примерах, которые предыдущие слабые ученики неправильно классифицировали.
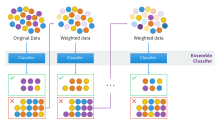
Существует множество алгоритмов повышения. Оригинальные, предложенные Робертом Шапиром ( рекурсивная формулировка мажоритарного вентиля), [5] и Йоав Фройнд (поддержка большинством голосов), [9] не были адаптивными и не могли в полной мере использовать преимущества слабых учащихся. Затем Шапир и Фройнд разработали AdaBoost , алгоритм адаптивного повышения, получивший престижную премию Гёделя .
Только алгоритмы, которые являются доказуемыми алгоритмами повышения в вероятно приблизительно правильной формулировке обучения, могут быть точно названы алгоритмами повышения . Другие алгоритмы, близкие по духу [ нужны разъяснения ] Алгоритмы повышения иногда называют «алгоритмами использования», хотя их также иногда неправильно называют алгоритмами повышения. [9]
Основным отличием многих алгоритмов повышения является их метод взвешивания обучения точек данных и гипотез . AdaBoost очень популярен и наиболее значим в истории, поскольку это был первый алгоритм, который мог адаптироваться к слабым ученикам. Это часто является основой вводного курса повышения квалификации на университетских курсах машинного обучения. [10] Существует множество более свежих алгоритмов, таких как LPBoost , TotalBoost, BrownBoost , xgboost , MadaBoost, LogitBoost и другие. Многие алгоритмы повышения вписываются в структуру AnyBoost. [9] который показывает, что повышение выполняет градиентный спуск в функциональном пространстве с использованием выпуклой функции стоимости .
Категоризация объектов в компьютерном зрении [ править ]
Учитывая изображения, содержащие различные известные объекты в мире, на их основе можно изучить классификатор, чтобы автоматически классифицировать объекты на будущих изображениях. Простые классификаторы, построенные на основе некоторых особенностей изображения объекта, имеют тенденцию быть слабыми в эффективности категоризации. Использование методов повышения категоризации объектов — это способ особым образом унифицировать слабые классификаторы, чтобы повысить общую способность категоризации. [ нужна ссылка ]
Проблема категоризации объектов [ править ]
Категоризация объектов — типичная задача компьютерного зрения , которая включает в себя определение того, содержит ли изображение определенную категорию объектов. Эта идея тесно связана с распознаванием, идентификацией и обнаружением. Категоризация объектов на основе внешнего вида обычно включает признаков , изучение классификатора извлечение и применение классификатора к новым примерам. Существует множество способов представления категории объектов, например, с помощью анализа формы , моделей «мешков слов» или локальных дескрипторов, таких как SIFT и т. д. Примерами контролируемых классификаторов являются наивные классификаторы Байеса , машины опорных векторов , смеси гауссиан и нейронные сети. . Однако исследования [ который? ] показал, что категории объектов и их расположение на изображениях могут быть обнаружены без присмотра . также [11]
Статус-кво для категоризации объектов [ править ]
Распознавание категорий объектов на изображениях является сложной проблемой компьютерного зрения , особенно когда количество категорий велико. Это связано с высокой внутриклассовой изменчивостью и необходимостью обобщения вариаций объектов внутри одной категории. Объекты одной категории могут выглядеть совершенно по-разному. Даже один и тот же объект может выглядеть непохожим под разной точкой зрения, масштабом и освещением . Беспорядок на заднем плане и частичная окклюзия также усложняют распознавание. [12] Люди способны распознавать тысячи типов объектов, тогда как большинство существующих систем распознавания объектов обучены распознавать лишь некоторые из них. [ количественно ] например, человеческие лица , автомобили , простые предметы и т. д. [13] [ нужно обновить? ] Исследования были очень активными, направленными на работу с большим количеством категорий и обеспечение возможности постепенного добавления новых категорий, и, хотя общая проблема остается нерешенной, несколько детекторов объектов с несколькими категориями (до сотен или тысяч категорий) [14] ) были разработаны. Одним из способов является совместное использование функций и их повышение.
Повышение бинарной категоризации [ править ]
AdaBoost можно использовать для распознавания лиц в качестве примера двоичной категоризации . Две категории — это лица и фон. Общий алгоритм следующий:
- Сформируйте большой набор простых функций
- Инициализируйте веса для обучающих изображений
- Для Т-раундов
- Нормализовать веса
- Для доступных функций из набора обучите классификатор, используя одну функцию, и оцените ошибку обучения.
- Выберите классификатор с наименьшей ошибкой
- Обновите веса обучающих изображений: увеличьте, если этот классификатор классифицирует их неправильно, уменьшите, если правильно.
- Сформируйте окончательный сильный классификатор как линейную комбинацию T-классификаторов (коэффициент больше, если ошибка обучения невелика)
После повышения классификатор, построенный из 200 признаков, может обеспечить уровень обнаружения 95 % при ложноположительный уровень . [15]

Еще одно применение повышения бинарной категоризации — это система, которая обнаруживает пешеходов по шаблонам движения и внешнего вида. [16] Эта работа является первой, в которой информация о движении и информация о внешнем виде объединены в качестве функций для обнаружения идущего человека. Он использует аналогичный подход к системе обнаружения объектов Виолы-Джонса .
Повышение категоризации по нескольким классам [ править ]
По сравнению с бинарной категоризацией, многоклассовая категоризация ищет общие черты, которые могут быть общими для всех категорий одновременно. Они становятся более общими функциями, похожими на края . В процессе обучения детекторы каждой категории могут обучаться совместно. По сравнению с обучением отдельно, оно лучше обобщает , требует меньше данных для обучения и требует меньше функций для достижения той же производительности.
Основная часть алгоритма аналогична двоичному случаю. Отличие состоит в том, что мера ошибки совместного обучения должна быть определена заранее. На каждой итерации алгоритм выбирает классификатор одного признака (должны поощряться признаки, которые могут быть общими для большего количества категорий). Это можно сделать путем преобразования многоклассовой классификации в бинарную (набор категорий по сравнению с остальными), [17] или путем введения штрафной ошибки из категорий, не имеющих признака классификатора. [18]
В статье «Обмен визуальными функциями для обнаружения многоклассовых и многовидовых объектов» А. Торральба и др. использовал GentleBoost для повышения и показал, что, когда данные обучения ограничены, обучение с помощью функций совместного использования работает гораздо лучше, чем без совместного использования, при тех же раундах повышения. Кроме того, для данного уровня производительности общее количество требуемых функций (и, следовательно, стоимость времени выполнения классификатора) для детекторов совместного использования функций масштабируется примерно логарифмически с количеством классов, т. е. медленнее, чем линейный рост в случай неразделения. Аналогичные результаты показаны в статье «Поэтапное обучение детекторов объектов с использованием алфавита визуальных форм», однако для улучшения авторы использовали AdaBoost .
Выпуклые и невыпуклые алгоритмы повышения [ править ]
Алгоритмы повышения могут быть основаны на алгоритмах выпуклой или невыпуклой оптимизации. Выпуклые алгоритмы, такие как AdaBoost и LogitBoost , могут быть «побеждены» случайным шумом, так что они не смогут изучить базовые и обучаемые комбинации слабых гипотез. [19] [20] На это ограничение указали Long & Servedio в 2008 году. Однако к 2009 году несколько авторов продемонстрировали, что алгоритмы повышения, основанные на невыпуклой оптимизации, такие как BrownBoost , могут учиться на зашумленных наборах данных и, в частности, могут изучать базовый классификатор Long- Набор данных Серведио.
См. также [ править ]
Реализации [ править ]
- scikit-learn — библиотека машинного обучения с открытым исходным кодом для Python.
- Orange — бесплатный пакет программного обеспечения для интеллектуального анализа данных, модуль Orange.ensemble.
- Weka — это набор инструментов машинного обучения, который предлагает различные реализации алгоритмов повышения, таких как AdaBoost и LogitBoost.
- R Пакет GBM (Обобщенные модели регрессии с усилением) реализует расширения алгоритма AdaBoost Фрейнда и Шапире и машины повышения градиента Фридмана.
- jboost ; AdaBoost, LogitBoost, RobustBoost, Boostexter и альтернативные деревья решений
- Пакет R adabag : применяет мультикласс AdaBoost.M1, AdaBoost-SAMME и пакетирование.
- Пакет R xgboost : реализация повышения градиента для линейных и древовидных моделей.
Примечания [ править ]
- ^ Некоторые алгоритмы классификации на основе повышения фактически уменьшают вес неоднократно ошибочно классифицированных примеров; например, повышение большинством и BrownBoost .
Ссылки [ править ]
- ^ Лео Брейман (1996). «СМЕЩЕНИЕ, ДИСПЕРСИЯ И КЛАССИФИКАТОРЫ ДУГ» (PDF) . ТЕХНИЧЕСКИЙ ОТЧЕТ. Архивировано из оригинала (PDF) 19 января 2015 г. Проверено 19 января 2015 г.
Arcing [Boosting] более успешен, чем объединение в уменьшении дисперсии.
- ^ Чжоу Чжи-Хуа (2012). Ансамблевые методы: основы и алгоритмы . Чепмен и Холл/CRC. п. 23. ISBN 978-1439830031 .
Термин «повышение» относится к семейству алгоритмов, которые способны превращать слабых учеников в сильных учеников.
- ^ Jump up to: Перейти обратно: а б Майкл Кернс (1988); Мысли о повышении гипотезы , неопубликованная рукопись (проект класса машинного обучения, декабрь 1988 г.)
- ^ Майкл Кернс ; Лесли Валиант (1989). «Критографические ограничения на изучение булевых формул и конечных автоматов». Материалы двадцать первого ежегодного симпозиума ACM по теории вычислений - STOC '89 . Том. 21. АКМ. стр. 433–444. дои : 10.1145/73007.73049 . ISBN 978-0897913072 . S2CID 536357 .
- ^ Jump up to: Перейти обратно: а б Шапире, Роберт Э. (1990). «Сила слабой обучаемости» (PDF) . Машинное обучение . 5 (2): 197–227. CiteSeerX 10.1.1.20.723 . дои : 10.1007/bf00116037 . S2CID 53304535 . Архивировано из оригинала (PDF) 10 октября 2012 г. Проверено 23 августа 2012 г.
- ^ Лео Брейман (1998). «Классификатор дуговых разрядов (с обсуждением и возражением автора)» . Энн. Стат . 26 (3): 801–849. дои : 10.1214/aos/1024691079 .
Шапире (1990) доказал, что усиление возможно. (Страница 823)
- ^ Йоав Фройнд и Роберт Э. Шапир (1997); Теоретико-решающее обобщение онлайн-обучения и приложение к повышению , Журнал компьютерных и системных наук, 55 (1): 119-139
- ^ Лео Брейман (1998); Классификатор дуговых разрядов (с обсуждением и ответом автора) , Анналы статистики, том. 26, нет. 3, стр. 801-849: «Концепция слабого обучения была введена Кернсом и Валиантом (1988, 1989), которые оставили открытым вопрос о том, эквивалентны ли слабая и сильная обучаемость. Этот вопрос был назван проблемой повышения, поскольку [а решение должно] повысить низкую точность слабого ученика до высокой точности сильного ученика. Шапир (1990) доказал, что повышение возможно. Алгоритм повышения — это метод, который превращает слабого ученика в сильного ученика. и Шапире (1997) доказали, что алгоритм, аналогичный arc-fs, обеспечивает усиление.
- ^ Jump up to: Перейти обратно: а б с Лью Мейсон, Джонатан Бакстер, Питер Бартлетт и Маркус Фрин (2000); Алгоритмы повышения как градиентный спуск , в С.А. Солле , Т.К. Лине и К.-Р. Мюллер, редакторы, «Достижения в области нейронных систем обработки информации», 12, стр. 512–518, MIT Press.
- ^ Эмер, Эрик. «Бустинг (алгоритм AdaBoost)» (PDF) . Массачусетский технологический институт . Архивировано (PDF) из оригинала 9 октября 2022 г. Проверено 10 октября 2018 г.
- ^ Сивик, Рассел, Эфрос, Фриман и Зиссерман, «Обнаружение объектов и их местоположения на изображениях», ICCV 2005
- ^ А. Опельт, А. Пинц и др., «Общее распознавание объектов с усилением», Транзакции IEEE на PAMI 2006
- ^ М. Маршалек, «Семантические иерархии для визуального распознавания объектов», 2007 г.
- ^ «Масштабная задача по визуальному распознаванию» . Декабрь 2017.
- ^ П. Виола, М. Джонс, «Надежное обнаружение объектов в реальном времени», 2001 г.
- ^ Виола, П.; Джонс, М.; Сноу, Д. (2003). Обнаружение пешеходов по моделям движения и внешнему виду (PDF) . ICCV. Архивировано (PDF) из оригинала 9 октября 2022 г.
- ^ А. Торральба, К. П. Мерфи и др., «Обмен визуальными функциями для обнаружения многоклассовых и многопредставленных объектов», Транзакции IEEE на PAMI 2006
- ^ А. Опельт и др., «Поэтапное обучение детекторов объектов с использованием алфавита визуальных форм», CVPR 2006.
- ^ П. Лонг и Р. Серведио. 25-я Международная конференция по машинному обучению (ICML), 2008 г., стр. 608–615.
- ^ Лонг, Филип М.; Серведио, Рокко А. (март 2010 г.). «Случайный классификационный шум побеждает все выпуклые потенциальные усилители» (PDF) . Машинное обучение . 78 (3): 287–304. дои : 10.1007/s10994-009-5165-z . S2CID 53861 . Архивировано (PDF) из оригинала 9 октября 2022 г. Проверено 17 ноября 2015 г.
Дальнейшее чтение [ править ]
- Фройнд, Йоав; Шапире, Роберт Э. (1997). «Обобщение онлайн-обучения с точки зрения принятия решений и применение к повышению» (PDF) . Журнал компьютерных и системных наук . 55 (1): 119–139. дои : 10.1006/jcss.1997.1504 .
- Шапире, Роберт Э. (1990). «Сила слабой обучаемости» . Машинное обучение . 5 (2): 197–227. дои : 10.1007/BF00116037 . S2CID 6207294 .
- Шапире, Роберт Э.; Певец Йорам (1999). «Улучшенные алгоритмы повышения с использованием предикторов с рейтингом достоверности» . Машинное обучение . 37 (3): 297–336. дои : 10.1023/А:1007614523901 . S2CID 2329907 .
- Чжоу, Чжихуа (2008). «Политическое объяснение алгоритма повышения» (PDF) . В: Материалы 21-й ежегодной конференции по теории обучения (COLT'08) : 479–490.
- Чжоу, Чжихуа (2013). «О сомнениях в маржинальном объяснении повышения» (PDF) . Искусственный интеллект . 203 : 1–18. arXiv : 1009.3613 . дои : 10.1016/j.artint.2013.07.002 . S2CID 2828847 .
Внешние ссылки [ править ]
- Роберт Э. Шапир (2003); Усиливающий подход к машинному обучению: обзор , Семинар MSRI (Научно-исследовательский институт математических наук) по нелинейному оцениванию и классификации
- Чжоу Чжи-Хуа (2014). Продление 25 лет. Архивировано 20 августа 2016 г. в Wayback Machine , основной доклад CCL 2014.
| Базы данных органов управления : Национальные |
|---|