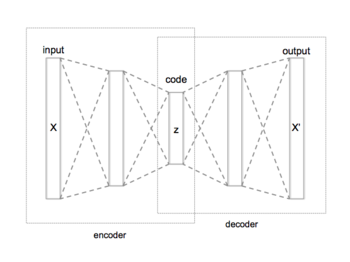
Автоэнкодер
| Часть серии о |
| Машинное обучение и интеллектуальный анализ данных |
|---|
Автоэнкодер используемый — это тип искусственной нейронной сети, для обучения эффективному кодированию немаркированных данных ( обучение без учителя ). [1] [2] Автоэнкодер изучает две функции: функцию кодирования, которая преобразует входные данные, и функцию декодирования, которая воссоздает входные данные из закодированного представления. Автоэнкодер изучает эффективное представление (кодирование) набора данных, обычно для уменьшения размерности .
Существуют варианты, целью которых является заставить изученные представления приобрести полезные свойства. [3] Примерами являются регуляризованные автоэнкодеры ( Sparse , Denoising и Contractive ), которые эффективны при изучении представлений для последующих классификации . задач [4] и вариационные автоэнкодеры с приложениями в качестве генеративных моделей . [5] Автоэнкодеры применяются для решения многих задач, включая распознавание лиц , [6] обнаружение особенностей, [7] обнаружение аномалий и понимание смысла слов. [8] [9] Автоэнкодеры также являются генеративными моделями, которые могут случайным образом генерировать новые данные, аналогичные входным данным (обучающие данные). [7]
Математические принципы [ править ]
Определение [ править ]
Автоэнкодер определяется следующими компонентами:
Два множества: пространство декодированных сообщений ; пространство закодированных сообщений . Почти всегда оба и являются евклидовыми пространствами, т.е. для некоторых .




Два параметризованных семейства функций: семейство энкодеров , параметризованный ; семейство декодеров , параметризованный .




Для любого , мы обычно пишем и называть его кодом, скрытой переменной , скрытым представлением, скрытым вектором и т. д. И наоборот, для любого , мы обычно пишем и называть его (декодированным) сообщением.




Обычно и кодер, и декодер определяются как многослойные перцептроны . Например, однослойный кодер MLP. является:


где — это поэлементная функция активации, такая как сигмовидная функция или выпрямленная линейная единица , представляет собой матрицу, называемую «весом», и представляет собой вектор, называемый «смещением».



Обучение автоэнкодеру [ править ]
Автоэнкодер сам по себе представляет собой просто кортеж из двух функций. Чтобы судить о его качестве , нам нужна задача . Задача определяется эталонным распределением вероятностей. над и функция «качество реконструкции» , такой, что измеряет, насколько отличается от .

![{\displaystyle d:{\mathcal {X}}\times {\mathcal {X}}\to [0,\infty]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/e69538969fb3dc0706fb3368e6312ccb95cf2d6e)



С их помощью мы можем определить функцию потерь для автоэнкодера как
![{\displaystyle L(\theta,\phi):=\mathbb {\mathbb {E}} _{x\sim \mu _{ref}}[d(x,D_{\theta }(E_{\phi } (х)))]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/b67d5c0347ed7cd5dab78196fe3501a843f97d34)


В большинстве ситуаций эталонное распределение — это просто эмпирическое распределение, заданное набором данных. , так что


где — мера Дирака , функция качества — это просто потеря L2: , и является евклидовой нормой. Тогда проблема поиска оптимального автоэнкодера — это всего лишь оптимизация методом наименьших квадратов :




Интерпретация [ править ]

Автокодировщик состоит из двух основных частей: кодировщика, который отображает сообщение в код, и декодера, который восстанавливает сообщение из кода. Оптимальный автоэнкодер будет выполнять реконструкцию как можно более близкую к идеальной, причем «близко к идеальному» определяется функцией качества реконструкции. .

Самый простой способ идеально выполнить задачу копирования — это дублировать сигнал. Чтобы подавить такое поведение, пространство кода обычно имеет меньше измерений, чем пространство сообщений .
Такой автоэнкодер называется undercomplete . Это можно интерпретировать как сжатие сообщения или уменьшение его размерности . [1] [10]
На пределе идеального неполного автокодировщика каждый возможный код в кодовом пространстве используется для кодирования сообщения это действительно появляется в раздаче , и декодер тоже идеален: . Этот идеальный автокодировщик затем можно использовать для генерации сообщений, неотличимых от реальных сообщений, путем подачи в его декодер произвольного кода. и получение , это сообщение, которое действительно появляется в рассылке .



Если пространство кода имеет размер больше ( overcomplete ) или равный пространству сообщений Если скрытым модулям предоставлена достаточная емкость, автоэнкодер может изучить функцию идентификации и стать бесполезным. Тем не менее, экспериментальные результаты показали, что автокодировщики с переполным набором данных все равно могут обучиться полезным функциям . [11]
В идеальном случае размерность кода и емкость модели могут быть установлены на основе сложности распределения моделируемых данных. Стандартный способ сделать это — внести изменения в базовый автокодировщик, подробно описанный ниже. [3]
История [ править ]
Автоэнкодер был впервые предложен как нелинейное обобщение анализа главных компонентов (PCA). Крамером [1] Автоэнкодер также называют автоассоциатором. [12] или сеть Diabolo. [13] [11] Первые его применения датируются началом 1990-х годов. [3] [14] [15] Их наиболее традиционным применением было уменьшение размерности или обучение признакам , но эта концепция стала широко использоваться для изучения генеративных моделей данных. [16] [17] Некоторые из самых мощных ИИ 2010-х годов использовали автокодировщики, встроенные в глубокие нейронные сети. [18]
Вариации [ править ]
Регуляризованные автоэнкодеры [ править ]
Существуют различные методы, позволяющие помешать автокодировщикам изучить функцию идентификации и улучшить их способность захватывать важную информацию и изучать более широкие представления.
Разреженный автоэнкодер (SAE) [ править ]
Вдохновленные гипотезой разреженного кодирования в нейробиологии, разреженные автокодеры представляют собой варианты автокодировщиков, такие, что коды поскольку сообщения имеют тенденцию быть разреженными кодами , то есть в большинстве записей близок к нулю. Разреженные автокодировщики могут включать в себя больше (а не меньше) скрытых модулей, чем входных, но только небольшому количеству скрытых модулей разрешено быть активными одновременно. [18] Поощрение разреженности повышает производительность задач классификации. [19]


Есть два основных способа обеспечить разреженность. Один из способов — просто обнулить все активации скрытого кода, кроме самого высокого k. Это k-разреженный автоэнкодер . [20]
K-разреженный автокодировщик вставляет следующую «k-разреженную функцию» в скрытый уровень стандартного автокодировщика:



Обратное распространение ошибки через все просто: установите градиент на 0 для записи и сохраняйте градиент для записи. По сути, это обобщенная функция ReLU . [20]


Другой способ — это упрощенная версия k-разреженного автокодировщика. Вместо принудительной разреженности мы добавляем потерю регуляризации разреженности , а затем оптимизируем для


Пусть архитектура автоэнкодера имеет слои. Чтобы определить потерю регуляризации разреженности, нам нужна «желаемая» разреженность. для каждого слоя вес насколько необходимо обеспечить каждую разреженность и функцию чтобы измерить, насколько различаются две разреженности.



![{\displaystyle s:[0,1]\times [0,1]\to [0,\infty]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/0cd8c20f4b06b6eeddda1f90d5d1b5589ed8e6c3)
Для каждого входа , пусть фактическая разреженность активации в каждом слое быть




Потеря разреженности при вводе за один слой , а потери из-за регуляризации разреженности для всего автоэнкодера представляют собой ожидаемую взвешенную сумму потерь из-за разреженности:

![{\displaystyle L_{разреженность}(\theta,\phi)=\mathbb {\mathbb {E}} _{x\sim \mu _{X}}\left[\sum _{k\in 1:K} w_{k}s({\hat {\rho }}_{k},\rho _{k}(x))\right]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/1f03519624b36193970a4c30d22dd924c41bbbaf)


или потеря L1, как , или потери L2, как .


Альтернативно, потери из-за регуляризации разреженности могут быть определены без ссылки на какую-либо «желаемую разреженность», а просто обеспечить как можно большую разреженность. В этом случае можно определить потерю регуляризации разреженности как
![{\displaystyle L_{разреженность}(\theta,\phi)=\mathbb {\mathbb {E}} _{x\sim \mu _{X}}\left[\sum _{k\in 1:K} w_{k}\|h_{k}\|\right]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/63fae8e84281a591de3fa6f14e89c1347168152c)


Автоэнкодер шумоподавления (DAE) [ править ]
Автоэнкодеры с шумоподавлением (DAE) пытаются добиться хорошего представления, изменяя критерий реконструкции . [3] [4]
DAE, первоначально называвшаяся «надежной автоассоциативной сетью», [2] обучается путем намеренного искажения входных данных стандартного автокодировщика во время обучения. Шумовой процесс определяется распределением вероятностей над функциями . То есть функция принимает сообщение и превращает его в шумную версию . Функция выбирается случайным образом, с распределением вероятностей .




Дана задача , проблема обучения ДАУ — это задача оптимизации:
![{\displaystyle \min _ {\theta,\phi }L(\theta,\phi)=\mathbb {\mathbb {E}} _{x\sim \mu _{X},T\sim \mu _{ T}}[d(x,(D_{\theta }\circ E_{\phi }\circ T)(x))]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/2bdd1dd52947dc67ec42fba69511b4d28bdd7688)
Обычно шумовой процесс применяется только во время обучения и тестирования, а не во время дальнейшего использования.
Использование DAE зависит от двух предположений:
- Существуют представления сообщений, которые относительно стабильны и устойчивы к типу шума, с которым мы, вероятно, столкнемся;
- Указанные представления фиксируют структуры входного распределения, которые полезны для наших целей. [4]
Примеры шумовых процессов включают в себя:
- аддитивный изотропный гауссовский шум ,
- маскирующий шум (часть входных данных выбирается случайным образом и устанавливается на 0)
- шум типа «соль и перец» (часть входных данных выбирается случайным образом и случайным образом устанавливается на минимальное или максимальное значение). [4]
Сжимающий автоэнкодер (CAE) [ править ]
Сжимающий автоэнкодер добавляет потери сжимающей регуляризации к стандартным потерям автоэнкодера:






DAE можно понимать как бесконечно малый предел CAE: в пределе небольшого гауссовского входного шума DAE заставляют функцию реконструкции сопротивляться небольшим, но конечным входным возмущениям, в то время как CAE делают извлеченные признаки устойчивыми к бесконечно малым входным возмущениям.
Автоэнкодер минимальной длины описания [ править ]
Этот раздел пуст. Вы можете помочь, добавив к нему . ( март 2024 г. ) |
Бетонный автоэнкодер [ править ]
Конкретный автоэнкодер предназначен для дискретного выбора функций. [25] Конкретный автокодировщик заставляет скрытое пространство состоять только из указанного пользователем количества функций. Конкретный автоэнкодер использует непрерывное расслабление категориального распределения , чтобы позволить градиентам проходить через слой выбора признаков, что позволяет использовать стандартное обратное распространение ошибки для изучения оптимального подмножества входных признаков, которые минимизируют потери при реконструкции.
Вариационный автоэнкодер (VAE) [ править ]
Вариационные автоэнкодеры (VAE) относятся к семействам вариационных байесовских методов . Несмотря на архитектурное сходство с базовыми автоэнкодерами, VAE представляют собой архитектуру с другими целями и совершенно другой математической формулировкой. Скрытое пространство в этом случае состоит из смеси распределений, а не фиксированного вектора.
Учитывая входной набор данных характеризуется неизвестной функцией вероятности и многомерный вектор скрытого кодирования , цель состоит в том, чтобы смоделировать данные как распределение , с определяется как набор сетевых параметров, так что .



Преимущества глубины [ править ]
Автоэнкодеры часто обучаются с помощью одноуровневого кодера и одноуровневого декодера, но использование многоуровневых (глубоких) кодеров и декодеров дает много преимуществ. [3]
- Глубина может экспоненциально снизить вычислительные затраты на представление некоторых функций.
- Глубина может экспоненциально уменьшить объем обучающих данных, необходимых для изучения некоторых функций.
- Экспериментально, глубокие автокодеры обеспечивают лучшее сжатие по сравнению с поверхностными или линейными автокодировщиками. [10]
Обучение [ править ]
Джеффри Хинтон разработал метод сети глубоких убеждений для обучения многоуровневых глубоких автокодировщиков. Его метод включает в себя обработку каждого соседнего набора из двух слоев как ограниченной машины Больцмана, так что предварительное обучение приближается к хорошему решению, а затем использование обратного распространения ошибки для точной настройки результатов. [10]
Исследователи спорят о том, будет ли совместное обучение (т.е. обучение всей архитектуры вместе с единой глобальной целью реконструкции для оптимизации) лучше для глубоких автокодировщиков. [26] Исследование 2015 года показало, что совместное обучение изучает лучшие модели данных, а также более репрезентативные функции для классификации по сравнению с послойным методом. [26] Однако их эксперименты показали, что успех совместного обучения во многом зависит от принятых стратегий регуляризации. [26] [27]
Приложения [ править ]
Двумя основными приложениями автоэнкодеров являются уменьшение размерности и поиск информации. [3] но современные вариации были применены и для других задач.
Уменьшение размерности [ править ]
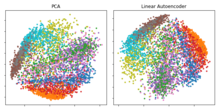
Снижение размерности было одним из первых приложений глубокого обучения . [3]
В исследовании Хинтона 2006 г. [10] он предварительно обучил многоуровневый автокодировщик с помощью набора RBM , а затем использовал их веса для инициализации глубокого автокодировщика с постепенно меньшими скрытыми слоями, пока не достиг узкого места в 30 нейронов. Полученные 30 измерений кода дали меньшую ошибку реконструкции по сравнению с первыми 30 компонентами анализа главных компонентов (PCA) и получили представление, которое было качественно легче интерпретировать, четко разделяя кластеры данных. [3] [10]
Представление измерений может повысить производительность при выполнении таких задач, как классификация. [3] Действительно, отличительной чертой уменьшения размерности является размещение семантически связанных примеров рядом друг с другом. [29]
Анализ компонентов главных

Если используются линейные активации или только один скрытый слой сигмовидной формы, то оптимальное решение для автокодировщика тесно связано с анализом главных компонентов (PCA). [30] [31] Веса автоэнкодера с одним скрытым слоем размера (где меньше размера входных данных) охватывают то же векторное подпространство, что и первое главные компоненты, а выходные данные автоэнкодера представляют собой ортогональную проекцию на это подпространство. Веса автоэнкодера не равны основным компонентам и, как правило, не ортогональны, однако основные компоненты могут быть восстановлены из них с помощью разложения по сингулярным значениям . [32]

Однако потенциал автоэнкодеров заключается в их нелинейности, что позволяет модели изучать более мощные обобщения по сравнению с PCA и реконструировать входные данные со значительно меньшими потерями информации. [10]
и поисковая оптимизация Поиск информации
Информационный поиск выигрывает, в частности, от уменьшения размерности , поскольку поиск может стать более эффективным в определенных типах низкоразмерных пространств. Автоэнкодеры действительно применялись для семантического хеширования, предложенного Салахутдиновым и Хинтоном в 2007 году. [29] Обучив алгоритм созданию низкоразмерного двоичного кода, все записи базы данных можно будет хранить в хеш-таблице, сопоставляющей векторы двоичного кода с записями. Эта таблица затем будет поддерживать поиск информации, возвращая все записи с тем же двоичным кодом, что и запрос, или немного менее похожие записи, переворачивая некоторые биты из кодировки запроса.
Архитектура кодировщика-декодера, часто используемая в обработке естественного языка и нейронных сетях, может быть научно применена в области SEO (поисковая оптимизация) различными способами:
- Обработка текста . Используя автокодировщик, можно сжать текст веб-страниц в более компактное векторное представление. Это может помочь сократить время загрузки страницы и улучшить ее индексацию поисковыми системами.
- Шумоподавление : автоэнкодеры можно использовать для удаления шума из текстовых данных веб-страниц. Это может привести к лучшему пониманию контента поисковыми системами, тем самым повышая рейтинг на страницах результатов поисковых систем.
- Генерация метатегов и фрагментов . Автоэнкодеры можно обучить автоматически генерировать метатеги, фрагменты и описания для веб-страниц, используя содержимое страницы. Это может оптимизировать представление в результатах поиска, увеличивая рейтинг кликов (CTR).
- Кластеризация контента : с помощью автокодировщика веб-страницы со схожим содержанием могут быть автоматически сгруппированы вместе. Это может помочь логически организовать веб-сайт и улучшить навигацию, что потенциально положительно повлияет на пользовательский опыт и рейтинг в поисковых системах.
- Генерация связанного контента : автокодировщик можно использовать для создания контента, связанного с тем, что уже присутствует на сайте. Это может повысить привлекательность веб-сайта для поисковых систем и предоставить пользователям дополнительную релевантную информацию.
- Обнаружение ключевых слов . Автоэнкодеры можно обучить распознавать ключевые слова и важные понятия в содержании веб-страниц. Это может помочь оптимизировать использование ключевых слов для лучшей индексации.
- Семантический поиск . Используя методы автокодирования, можно создавать модели семантического представления контента. Эти модели можно использовать для улучшения понимания поисковыми системами тем, затронутых на веб-страницах.
По сути, архитектура кодировщика-декодера или автокодировщики могут использоваться в SEO для оптимизации содержимого веб-страниц, улучшения их индексации и повышения их привлекательности как для поисковых систем, так и для пользователей.
Обнаружение аномалий [ править ]
Еще одно применение автоэнкодеров — обнаружение аномалий . [2] [33] [34] [35] [36] [37] Научившись воспроизводить наиболее характерные особенности обучающих данных при некоторых ограничениях, описанных ранее, модель может научиться точно воспроизводить наиболее часто наблюдаемые характеристики. При столкновении с аномалиями модель должна ухудшать производительность реконструкции. В большинстве случаев для обучения автокодировщика используются только данные с обычными экземплярами; в других частота аномалий мала по сравнению с набором наблюдений, так что ее вклад в изученное представление можно игнорировать. После обучения автоэнкодер точно восстановит «нормальные» данные, но не сможет сделать это с незнакомыми аномальными данными. [35] Ошибка реконструкции (ошибка между исходными данными и их низкоразмерной реконструкцией) используется в качестве показателя аномалии для обнаружения аномалий. [35]
Однако недавняя литература показала, что некоторые модели автокодирования могут, как ни странно, очень хорошо реконструировать аномальные примеры и, следовательно, не способны надежно выполнять обнаружение аномалий. [38] [39]
Обработка изображений [ править ]
Характеристики автоэнкодеров полезны при обработке изображений.
Одним из примеров является сжатие изображений с потерями , где автокодировщики превзошли другие подходы и оказались конкурентоспособными по сравнению с JPEG 2000 . [40] [41]
Еще одним полезным применением автоэнкодеров при предварительной обработке изображений является шумоподавление изображений . [42] [43] [44]
Автокодировщики нашли применение в более требовательных контекстах, таких как медицинская визуализация , где они использовались для шумоподавления изображения. [45] а также супер-разрешение . [46] [47] В диагностике с помощью изображений в экспериментах применялись автоэнкодеры для рака молочной железы. обнаружения [48] и для моделирования связи между снижением когнитивных функций при болезни Альцгеймера и скрытыми особенностями автокодировщика, обученного с помощью МРТ . [49]
Открытие лекарств [ править ]
В 2019 году молекулы, созданные с помощью вариационных автоэнкодеров, были проверены экспериментально на мышах. [50] [51]
Прогноз популярности [ править ]
Недавно многоуровневая структура автокодирования дала многообещающие результаты в прогнозировании популярности публикаций в социальных сетях. [52] что полезно для стратегий онлайн-рекламы.
Машинный перевод [ править ]
Автоэнкодеры были применены к машинному переводу , который обычно называют нейронным машинным переводом (NMT). [53] [54] В отличие от традиционных автоэнкодеров, выходные данные не соответствуют входным — они на другом языке. В NMT тексты рассматриваются как последовательности, подлежащие кодированию в процедуре обучения, в то время как на стороне декодера генерируются последовательности на целевом языке(ах). Автокодировщики, специфичные для языка дополнительные лингвистические функции, такие как функции разложения китайского языка. , включают в процедуру обучения [55] Машинный перевод до сих пор редко выполняется с помощью автокодировщиков из-за наличия более эффективных сетей преобразователей .
См. также [ править ]
Ссылки [ править ]
- ^ Jump up to: Перейти обратно: а б с Крамер, Марк А. (1991). «Нелинейный анализ главных компонент с использованием автоассоциативных нейронных сетей» (PDF) . Журнал Айше . 37 (2): 233–243. Бибкод : 1991АИЧЕ..37..233К . дои : 10.1002/aic.690370209 .
- ^ Jump up to: Перейти обратно: а б с Крамер, Массачусетс (1 апреля 1992 г.). «Автоассоциативные нейронные сети» . Компьютеры и химическая инженерия . Применение нейтральных сетей в химической технологии. 16 (4): 313–328. дои : 10.1016/0098-1354(92)80051-А . ISSN 0098-1354 .
- ^ Jump up to: Перейти обратно: а б с д и ж г час я Гудфеллоу, Ян; Бенджио, Йошуа; Курвиль, Аарон (2016). Глубокое обучение . МТИ Пресс. ISBN 978-0262035613 .
- ^ Jump up to: Перейти обратно: а б с д Винсент, Паскаль; Ларошель, Хьюго (2010). «Автоэнкодеры со сложенным шумоподавлением: изучение полезных представлений в глубокой сети с локальным критерием шумоподавления». Журнал исследований машинного обучения . 11 : 3371–3408.
- ^ Веллинг, Макс; Кингма, Дидерик П. (2019). «Введение в вариационные автоэнкодеры». Основы и тенденции в машинном обучении . 12 (4): 307–392. arXiv : 1906.02691 . Бибкод : 2019arXiv190602691K . дои : 10.1561/2200000056 . S2CID 174802445 .
- ^ Хинтон Г.Э., Крижевский А., Ван С.Д. Преобразование автоэнкодеров. На Международной конференции по искусственным нейронным сетям, 14 июня 2011 г. (стр. 44–51). Шпрингер, Берлин, Гейдельберг.
- ^ Jump up to: Перейти обратно: а б Жерон, Орельен (2019). Практическое машинное обучение с помощью Scikit-Learn, Keras и TensorFlow . Канада: O'Reilly Media, Inc., стр. 739–740.
- ^ Лю, Чэн-Юань; Хуанг, Джау-Чи; Ян, Вэнь-Чи (2008). «Моделирование восприятия слова с помощью сети Элмана» . Нейрокомпьютинг . 71 (16–18): 3150. doi : 10.1016/j.neucom.2008.04.030 .
- ^ Вэй; Доу-Ран (2014). Нейрокомпьютинг . 139 : 84–96. Лю, Цзюнь - , Ченг-Юань ; Лю .055 .
- ^ Jump up to: Перейти обратно: а б с д и ж Хинтон, GE; Салахутдинов, Р.Р. (28 июля 2006 г.). «Уменьшение размерности данных с помощью нейронных сетей». Наука . 313 (5786): 504–507. Бибкод : 2006Sci...313..504H . дои : 10.1126/science.1127647 . ПМИД 16873662 . S2CID 1658773 .
- ^ Jump up to: Перейти обратно: а б Бенджио, Ю. (2009). «Изучение глубокой архитектуры для искусственного интеллекта» (PDF) . Основы и тенденции в машинном обучении . 2 (8): 1795–7. CiteSeerX 10.1.1.701.9550 . дои : 10.1561/2200000006 . ПМИД 23946944 . S2CID 207178999 .
- ^ Япкович, Натали ; Хэнсон, Стивен Хосе ; Глюк, Марк А. (1 марта 2000 г.). «Нелинейная автоассоциация не эквивалентна PCA». Нейронные вычисления . 12 (3): 531–545. дои : 10.1162/089976600300015691 . ISSN 0899-7667 . ПМИД 10769321 . S2CID 18490972 .
- ^ Швенк, Хольгер; Бенджио, Йошуа (1997). «Методы обучения адаптивному бустингу нейронных сетей» . Достижения в области нейронных систем обработки информации . 10 . МТИ Пресс.
- ^ Шмидхубер, Юрген (январь 2015 г.). «Глубокое обучение в нейронных сетях: обзор». Нейронные сети . 61 : 85–117. arXiv : 1404.7828 . дои : 10.1016/j.neunet.2014.09.003 . ПМИД 25462637 . S2CID 11715509 .
- ^ Хинтон, GE, и Земель, RS (1994). Автоэнкодеры, минимальная длина описания и свободная энергия Гельмгольца. В «Достижениях в области нейронных систем обработки информации» 6 (стр. 3–10).
- ^ Дидерик П. Кингма; Веллинг, Макс (2013). «Автокодирование вариационного Байеса». arXiv : 1312.6114 [ stat.ML ].
- ^ Генерация лиц с помощью факела, Бозен А., Ларсен Л. и Сондерби С.К., факел , 2015 г.
.ч /блог /2015 /11 /13 / оба .html - ^ Jump up to: Перейти обратно: а б Домингос, Педро (2015). «4». Главный алгоритм: как поиски совершенной обучающейся машины изменят наш мир . Основные книги. Подраздел «Глубже в мозг». ISBN 978-046506192-1 .
- ^ Jump up to: Перейти обратно: а б Фрей, Брендан; Махзани, Алиреза (19 декабря 2013 г.). «k-разреженные автоэнкодеры». arXiv : 1312.5663 . Бибкод : 2013arXiv1312.5663M .
{{cite journal}}: Для цитирования журнала требуется|journal=( помощь ) - ^ Jump up to: Перейти обратно: а б Махзани, Алиреза; Фрей, Брендан (2013). «K-разреженные автоэнкодеры». arXiv : 1312.5663 [ cs.LG ].
- ^ Jump up to: Перейти обратно: а б Нг, А. (2011). Разреженный автоэнкодер . CS294A Конспекты лекций , 72 (2011), 1–19.
- ^ Наир, Винод; Хинтон, Джеффри Э. (2009). «Распознавание 3D-объектов с помощью сетей глубокого доверия» . Материалы 22-й Международной конференции по нейронным системам обработки информации . НИПС'09. США: Curran Associates Inc.: 1339–1347. ISBN 9781615679119 .
- ^ Лю, Вейбо; Ли, Добайе, Абдулла М. (17 января 2018 . Цзэн, Ньяньин, Хун ; ) г. 649. doi : 10.1016/ j.neucom.2017.08.043 ISSN 0925-2312 .
- ^ Хинтон, Джеффри Э; Земель, Ричард (1993). «Автоэнкодеры, минимальная длина описания и свободная энергия Гельмгольца» . Достижения в области нейронных систем обработки информации . 6 . Морган-Кауфманн.
- ^ Абид, Абубакар; Балин, Мухаммад Фатих; Цзоу, Джеймс (27 января 2019 г.). «Конкретные автоэнкодеры для выбора и реконструкции дифференцируемых функций». arXiv : 1901.09346 [ cs.LG ].
- ^ Jump up to: Перейти обратно: а б с Чжоу, Инбо; Арпит, Деванш; Нвогу, Ифеома; Говиндараджу, Вену (2014). «Лучше ли совместное обучение для глубоких автокодировщиков?». arXiv : 1405.1380 [ stat.ML ].
- ^ Р. Салахутдинов и Г. Э. Хинтон, «Глубокие машины Больцмана», в AISTATS, 2009, стр. 448–455.
- ^ Jump up to: Перейти обратно: а б «Модный МНИСТ» . Гитхаб . 12 июля 2019 г.
- ^ Jump up to: Перейти обратно: а б Салахутдинов Руслан; Хинтон, Джеффри (1 июля 2009 г.). «Семантическое хеширование» . Международный журнал приближенного рассуждения . Специальный раздел по графическим моделям и информационному поиску. 50 (7): 969–978. дои : 10.1016/j.ijar.2008.11.006 . ISSN 0888-613X .
- ^ Бурлард, Х.; Камп, Ю. (1988). «Автоассоциация с помощью многослойных перцептронов и разложение по сингулярным значениям» . Биологическая кибернетика . 59 (4–5): 291–294. дои : 10.1007/BF00332918 . ПМИД 3196773 . S2CID 206775335 .
- ^ Чикко, Давиде; Садовский, Питер; Бальди, Пьер (2014). «Нейронные сети глубокого автокодирования для прогнозирования аннотаций онтологии генов». Материалы 5-й конференции ACM по биоинформатике, вычислительной биологии и медицинской информатике - BCB '14 . п. 533. дои : 10.1145/2649387.2649442 . hdl : 11311/964622 . ISBN 9781450328944 . S2CID 207217210 .
- ^ Плаут, Э (2018). «От главных подпространств к главным компонентам с линейными автоэнкодерами». arXiv : 1804.10253 [ stat.ML ].
- ^ Моралес-Фореро, А.; Бассетто, С. (декабрь 2019 г.). «Тематическое исследование: полуконтролируемая методология обнаружения и диагностики аномалий» . Международная конференция IEEE по промышленной инженерии и инженерному менеджменту (IEEM) 2019 . Макао, Макао: IEEE. стр. 1031–1037. дои : 10.1109/IEEM44572.2019.8978509 . ISBN 978-1-7281-3804-6 . S2CID 211027131 .
- ^ Сакурада, Маю; Яири, Такехиса (декабрь 2014 г.). «Обнаружение аномалий с использованием автоэнкодеров с нелинейным уменьшением размерности» . Материалы 2-го семинара MLSDA 2014 г. по машинному обучению для анализа сенсорных данных . Голд-Кост, Австралия, Квинсленд, Австралия: ACM Press. стр. 4–11. дои : 10.1145/2689746.2689747 . ISBN 978-1-4503-3159-3 . S2CID 14613395 .
- ^ Jump up to: Перейти обратно: а б с Ан Дж. и Чо С. (2015). Обнаружение аномалий на основе вариационного автоэнкодера с использованием вероятности реконструкции . Специальная лекция по IE , 2 , 1-18.
- ^ Чжоу, Чонг; Паффенрот, Рэнди К. (4 августа 2017 г.). «Обнаружение аномалий с помощью надежных глубоких автоэнкодеров» . Материалы 23-й Международной конференции ACM SIGKDD по обнаружению знаний и интеллектуальному анализу данных . АКМ. стр. 665–674. дои : 10.1145/3097983.3098052 . ISBN 978-1-4503-4887-4 . S2CID 207557733 .
- ^ Рибейро, Манассис; Лаццаретти, Андре Эудженио; Лопес, Эйтор Сильверио (2018). «Исследование глубоких сверточных автокодеров для обнаружения аномалий в видео». Буквы для распознавания образов . 105 : 13–22. Бибкод : 2018PaReL.105...13R . дои : 10.1016/j.patrec.2017.07.016 .
- ^ Налисник, Эрик; Мацукава, Акихиро; Да, да, почему; Горур, Дилан; Лакшминараянан, Баладжи (24 февраля 2019 г.). «Знают ли глубокие генеративные модели то, чего они не знают?». arXiv : 1810.09136 [ stat.ML ].
- ^ Сяо, Чжишэн; Ян, Цин; Амит, Яли (2020). «Сожаление о вероятности: оценка обнаружения выхода за пределы распределения для вариационного автокодировщика» . Достижения в области нейронных систем обработки информации . 33 . arXiv : 2003.02977 .
- ^ Тайс, Лукас; Ши, Вэньчжэ; Каннингем, Эндрю; Гусар, Ференц (2017). «Сжатие изображений с потерями с помощью сжимающих автоэнкодеров». arXiv : 1703.00395 [ stat.ML ].
- ^ Балле, Дж; Лапарра, В; Симончелли, EP (апрель 2017 г.). «Сквозное оптимизированное сжатие изображений». Международная конференция по обучению представлений . arXiv : 1611.01704 .
- ^ Чо, К. (2013, февраль). Простая разреженность улучшает работу автокодировщиков разреженного шумоподавления при удалении сильно поврежденных изображений. На Международной конференции по машинному обучению (стр. 432-440).
- ^ Чо, Кёнхён (2013). «Машины Больцмана и автокодеры шумоподавления для шумоподавления изображений». arXiv : 1301.3468 [ stat.ML ].
- ^ Буадес, А.; Колл, Б.; Морель, Дж. М. (2005). «Обзор алгоритмов шумоподавления изображений с новым» . Многомасштабное моделирование . 4 (2): 490–530. дои : 10.1137/040616024 . S2CID 218466166 .
- ^ Гондара, Лавдип (декабрь 2016 г.). «Подавление шума медицинских изображений с использованием автоэнкодеров сверточного шумоподавления». 16-я Международная конференция IEEE по интеллектуальному анализу данных (ICDMW) , 2016 г. Барселона, Испания: IEEE. стр. 241–246. arXiv : 1608.04667 . Бибкод : 2016arXiv160804667G . дои : 10.1109/ICDMW.2016.0041 . ISBN 9781509059102 . S2CID 14354973 .
- ^ Цзэн, Кун; Ю, Джун; Ван, Руксин; Ли, Цуйхуа; Тао, Дачэн (январь 2017 г.). «Связанный глубокий автоэнкодер для сверхвысокого разрешения одного изображения». Транзакции IEEE по кибернетике . 47 (1): 27–37. дои : 10.1109/TCYB.2015.2501373 . ISSN 2168-2267 . ПМИД 26625442 . S2CID 20787612 .
- ^ Цзы-Си, Сун; Санчес, Виктор; Хешам, ЭйДали; Насир М., Раджпут (2017). «Гибридный глубокий автоэнкодер с гауссовой кривизной для обнаружения различных типов клеток на изображениях трепанобиопсии костного мозга». 2017 IEEE 14-й Международный симпозиум по биомедицинской визуализации (ISBI 2017) . стр. 1040–1043. дои : 10.1109/ISBI.2017.7950694 . ISBN 978-1-5090-1172-8 . S2CID 7433130 .
- ^ Сюй, Цзюнь; Сян, Лей; Лю, Циншань; Гилмор, Ханна; Ву, Цзяньчжун; Тан, Цзинхай; Мадабхуши, Анант (январь 2016 г.). «Сложенный разреженный автоэнкодер (SSAE) для обнаружения ядер на гистопатологических изображениях рака молочной железы» . Транзакции IEEE по медицинской визуализации . 35 (1): 119–130. дои : 10.1109/TMI.2015.2458702 . ПМЦ 4729702 . ПМИД 26208307 .
- ^ Мартинес-Мурсия, Франсиско Х.; Ортис, Андрес; Горрис, Хуан М.; Рамирес, Хавьер; Кастильо-Барнс, Диего (2020). «Изучение многообразной структуры болезни Альцгеймера: подход глубокого обучения с использованием сверточных автоэнкодеров» . Журнал IEEE по биомедицинской и медицинской информатике . 24 (1): 17–26. дои : 10.1109/JBHI.2019.2914970 . hdl : 10630/28806 . ПМИД 31217131 . S2CID 195187846 .
- ^ Жаворонков, Алексей (2019). «Глубокое обучение позволяет быстро идентифицировать мощные ингибиторы киназы DDR1». Природная биотехнология . 37 (9): 1038–1040. дои : 10.1038/s41587-019-0224-x . ПМИД 31477924 . S2CID 201716327 .
- ^ Грегори, Барбер. «Молекула, созданная искусственным интеллектом, обладает свойствами, подобными лекарству» . Проводной .
- ^ Де, Шонак; Майти, Абхишек; Гоэл, Вритти; Шитоле, Санджай; Бхаттачарья, Авик (2017). «Прогнозирование популярности постов в Instagram для журнала о стиле жизни с помощью глубокого обучения». 2017 2-я Международная конференция IEEE по системам связи, вычислениям и ИТ-приложениям (CSCITA) . стр. 174–177. дои : 10.1109/CSCITA.2017.8066548 . ISBN 978-1-5090-4381-1 . S2CID 35350962 .
- ^ Чо, Кёнхён; Барт ван Мерриенбур; Богданов Дмитрий; Бенджио, Йошуа (2014). «О свойствах нейронного машинного перевода: подходы кодировщика-декодера». arXiv : 1409.1259 [ cs.CL ].
- ^ Суцкевер, Илья; Виньялс, Ориол; Ле, Куок В. (2014). «Последовательное обучение с помощью нейронных сетей». arXiv : 1409.3215 [ cs.CL ].
- ^ Хан, Лифенг; Куанг, Шаохуэй (2018). «Включение китайских радикалов в нейронный машинный перевод: глубже, чем уровень символов». arXiv : 1805.01565 [ cs.CL ].
Дифференцируемые вычисления |
|---|