Наборы данных для обучения, проверки и тестирования
| Часть серии о |
| Машинное обучение и интеллектуальный анализ данных |
|---|
В машинном обучении общей задачей является изучение и построение алгоритмов и делать прогнозы на , которые могут учиться на основе данных их основе . [1] Такие алгоритмы функционируют, делая прогнозы или решения на основе данных. [2] путем построения математической модели на основе входных данных. Эти входные данные, используемые для построения модели, обычно делятся на несколько наборов данных . В частности, на разных этапах создания модели обычно используются три набора данных: наборы для обучения, проверки и тестирования.
Модель изначально подходит для набора обучающих данных , [3] который представляет собой набор примеров, используемых для подбора параметров (например, весов связей между нейронами в искусственных нейронных сетях ) модели. [4] Модель (например, наивный байесовский классификатор ) обучается на наборе обучающих данных с использованием контролируемого метода обучения , например, с использованием таких методов оптимизации, как градиентный спуск или стохастический градиентный спуск . На практике набор обучающих данных часто состоит из пар входного вектора (или скаляра) и соответствующего выходного вектора (или скаляра), где ключ ответа обычно обозначается как цель (или метка ). Текущая модель запускается с набором обучающих данных и выдает результат, который затем сравнивается с целевым значением для каждого входного вектора в наборе обучающих данных. На основании результата сравнения и конкретного используемого алгоритма обучения корректируются параметры модели. Подбор модели может включать как выбор переменных параметров , так и оценку .
Последовательно подобранная модель используется для прогнозирования ответов на наблюдения во втором наборе данных, называемом набором данных проверки . [3] модели. Набор данных проверки обеспечивает объективную оценку соответствия модели набору обучающих данных при настройке гиперпараметров [5] (например, количество скрытых единиц — слоев и ширины слоев — в нейронной сети [4] ). Наборы данных проверки можно использовать для регуляризации путем ранней остановки (остановки обучения, когда ошибка в наборе данных проверки увеличивается, поскольку это является признаком переподгонки набора данных проверки). [6] Эта простая процедура на практике усложняется тем фактом, что ошибка набора проверочных данных может колебаться во время обучения, создавая несколько локальных минимумов. Это осложнение привело к созданию множества специальных правил для определения того, когда действительно началась переобучение. [6]
Наконец, набор тестовых данных — это набор данных, используемый для обеспечения объективной оценки окончательной модели, подходящей для набора обучающих данных. [5] Если данные в наборе тестовых данных никогда не использовались при обучении (например, при перекрестной проверке ), набор тестовых данных также называется набором контрольных данных . В некоторой литературе термин «набор проверки» иногда используется вместо «набор тестов» (например, если исходный набор данных был разделен только на два подмножества, набор тестов можно назвать набором проверки). [5]
Решение о размерах и стратегиях разделения наборов данных на обучающие, тестовые и проверочные наборы во многом зависит от проблемы и доступных данных. [7]
данных обучающих Набор

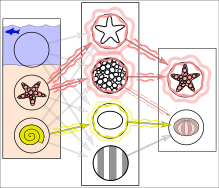
В действительности текстуры и контуры будут представлены не отдельными узлами, а скорее соответствующими весовыми шаблонами нескольких узлов.
Набор обучающих данных представляет собой набор данных примеров, используемых в процессе обучения и используемый для согласования параметров (например, весов), например, классификатора . [9] [10]
Для задач классификации алгоритм обучения с учителем просматривает набор обучающих данных, чтобы определить или изучить оптимальные комбинации переменных, которые позволят создать хорошую прогнозирующую модель . [11] Цель состоит в том, чтобы создать обученную (подогнанную) модель, которая хорошо обобщает новые, неизвестные данные. [12] Подобранная модель оценивается с использованием «новых» примеров из имеющихся наборов данных (наборы проверочных и тестовых данных) для оценки точности модели при классификации новых данных. [5] Чтобы снизить риск возникновения таких проблем, как переподбор, примеры из наборов проверочных и тестовых данных не следует использовать для обучения модели. [5]
Большинство подходов, которые ищут в обучающих данных эмпирические взаимосвязи, имеют тенденцию переопределять данные, а это означает, что они могут идентифицировать и использовать очевидные связи в обучающих данных, которые не выполняются в целом.
Набор проверочных данных [ править ]
Набор данных проверки — это набор данных примеров, используемых для настройки гиперпараметров (т. е. архитектуры) классификатора. Иногда его также называют набором разработки или «набором разработчика». [13] Пример гиперпараметра для искусственных нейронных сетей включает количество скрытых блоков в каждом слое. [9] [10] Он, как и набор для тестирования (как указано ниже), должен иметь то же распределение вероятностей, что и набор обучающих данных.
Чтобы избежать переобучения, когда необходимо скорректировать какой-либо параметр классификации , необходимо иметь набор данных проверки в дополнение к наборам обучающих и тестовых данных. Например, если ищется наиболее подходящий классификатор для задачи, набор обучающих данных используется для обучения различных классификаторов-кандидатов, набор проверочных данных используется для сравнения их характеристик и решения, какой из них выбрать, и, наконец, тестовые данные. Набор используется для получения характеристик производительности, таких как точность , чувствительность , специфичность , F-мера и так далее. Набор данных проверки функционирует как гибрид: это обучающие данные, используемые для тестирования, но не как часть низкоуровневого обучения и не как часть итогового тестирования.
Основной процесс использования набора проверочных данных для выбора модели (как части набора обучающих данных, набора проверочных данных и набора тестовых данных): [10] [14]
Поскольку наша цель — найти сеть, имеющую наилучшую производительность на новых данных, самый простой подход к сравнению различных сетей — оценить функцию ошибок с использованием данных, которые не зависят от тех, которые используются для обучения. Различные сети обучаются путем минимизации соответствующей функции ошибок, определенной относительно набора обучающих данных. Затем производительность сетей сравнивается путем оценки функции ошибок с использованием независимого набора проверки, и выбирается сеть, имеющая наименьшую ошибку по отношению к набору проверки. Этот подход называется методом удержания . Поскольку эта процедура сама по себе может привести к некоторому переоснащению проверочного набора, производительность выбранной сети должна быть подтверждена путем измерения ее производительности на третьем независимом наборе данных, называемом тестовым набором.
Применение этого процесса заключается в ранней остановке , когда модели-кандидаты представляют собой последовательные итерации одной и той же сети, а обучение останавливается, когда ошибка в наборе проверки растет, выбирая предыдущую модель (ту, которая имеет минимальную ошибку).
Набор тестовых данных [ править ]
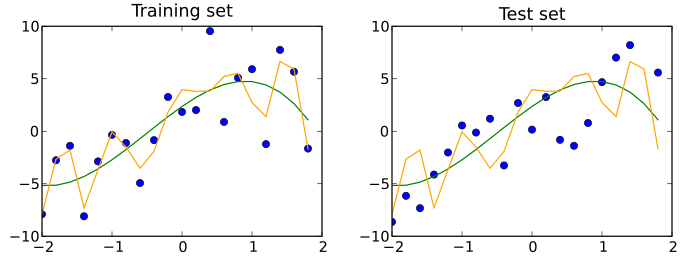
Набор тестовых данных — это набор данных , который не зависит от набора обучающих данных, но соответствует тому же распределению вероятностей, что и набор обучающих данных. Если модель, соответствующая набору обучающих данных, также хорошо соответствует набору тестовых данных, минимальное переобучение имело место (см. рисунок ниже). Лучшее соответствие набора обучающих данных по сравнению с набором тестовых данных обычно указывает на переобучение.
Таким образом, тестовый набор представляет собой набор примеров, используемых только для оценки производительности (т. е. обобщения) полностью определенного классификатора. [9] [10] Для этого финальная модель используется для прогнозирования классификации примеров в тестовом наборе. Эти прогнозы сравниваются с истинными классификациями примеров, чтобы оценить точность модели. [11]
В сценарии, где используются наборы данных как для проверки, так и для тестирования, набор тестовых данных обычно используется для оценки окончательной модели, выбранной в процессе проверки. В случае, когда исходный набор данных разделен на два подмножества (наборы обучающих и тестовых данных), набор тестовых данных может оценивать модель только один раз (например, в методе удержания ). [15] Обратите внимание, что некоторые источники не рекомендуют использовать такой метод. [12] Однако при использовании такого метода, как перекрестная проверка , двух разделов может быть достаточно и эффективно, поскольку результаты усредняются после повторных раундов обучения и тестирования модели, чтобы помочь уменьшить систематическую ошибку и изменчивость. [5] [12]
Путаница в терминологии [ править ]
Тестирование — это попытка что-то узнать об этом («Доказать; доказать истинность, подлинность или качество посредством эксперимента» согласно Совместному международному словарю английского языка), а валидировать — значит доказать, что что-то действительно ( «Подтвердить; сделать действительным» Международный совместный словарь английского языка). С этой точки зрения наиболее распространенным использованием терминов «набор тестов» и «набор проверки» является описанный здесь. Однако как в промышленности, так и в научных кругах их иногда используют взаимозаменяемо, учитывая, что внутренний процесс заключается в тестировании различных моделей для улучшения (набор тестов как набор для разработки), а окончательная модель — это та модель, которую необходимо проверить перед реальным использованием с невидимые данные (набор проверки). «В литературе по машинному обучению часто перепутаны значения «проверочных» и «тестовых» наборов. Это наиболее вопиющий пример терминологической путаницы, которая пронизывает исследования искусственного интеллекта». [16] Тем не менее, важная концепция, которую необходимо соблюдать, заключается в том, что окончательный набор, независимо от того, называется ли он тестом или проверкой, должен использоваться только в финальном эксперименте.
Перекрестная проверка [ править ]
Чтобы получить более стабильные результаты и использовать все ценные данные для обучения, набор данных можно многократно разбить на несколько наборов данных для обучения и проверки. Это известно как перекрестная проверка . Для подтверждения работоспособности модели обычно используется дополнительный набор тестовых данных, полученный в результате перекрестной проверки.
Причины ошибки [ править ]

Упущения в обучении алгоритмов являются основной причиной ошибочных результатов. [17] К типам таких упущений относятся: [17]
- Конкретные обстоятельства или варианты не были включены.
- Устаревшие данные
- Неоднозначная входная информация
- Неспособность адаптироваться к новым условиям.
- Невозможность запросить помощь у человека или другой системы искусственного интеллекта, когда это необходимо.
Примером упущения конкретных обстоятельств является случай, когда мальчик смог разблокировать телефон, потому что его мать зарегистрировала ее лицо при ночном освещении в помещении, - условие, которое не было должным образом включено в обучение системы. [17] [18]
Использование относительно нерелевантных входных данных может включать ситуации, когда алгоритмы используют фон, а не интересующий объект для обнаружения объекта , например, обучение на изображениях овец на лугах, что приводит к риску того, что другой объект будет интерпретирован как овца, если он будет обнаружен. на лугу. [17]
См. также [ править ]
- Статистическая классификация
- Список наборов данных для исследований в области машинного обучения
- Иерархическая классификация
Ссылки [ править ]
- ^ Рон Кохави; Фостер Провост (1998). «Словарь терминов» . Машинное обучение . 30 : 271–274. дои : 10.1023/A:1007411609915 .
- ^ Бишоп, Кристофер М. (2006). Распознавание образов и машинное обучение . Нью-Йорк: Спрингер. п. VII. ISBN 0-387-31073-8 .
Распознавание образов зародилось в инженерии, тогда как машинное обучение выросло из информатики. Однако эту деятельность можно рассматривать как два аспекта одной и той же области, и вместе они претерпели существенное развитие за последние десять лет.
- ↑ Перейти обратно: Перейти обратно: а б Джеймс, Гарет (2013). Введение в статистическое обучение: с приложениями на R. Спрингер. п. 176. ИСБН 978-1461471370 .
- ↑ Перейти обратно: Перейти обратно: а б Рипли, Брайан (1996). Распознавание образов и нейронные сети . Издательство Кембриджского университета. п. 354 . ISBN 978-0521717700 .
- ↑ Перейти обратно: Перейти обратно: а б с д и ж Браунли, Джейсон (13 июля 2017 г.). «В чем разница между тестовыми и проверочными наборами данных?» . Проверено 12 октября 2017 г.
- ↑ Перейти обратно: Перейти обратно: а б Пречелт, Лутц; Женевьева Б. Орр (1 января 2012 г.). «Ранняя остановка — но когда?». В Грегуаре Монтавоне; Клаус-Роберт Мюллер (ред.). Нейронные сети: хитрости . Конспекты лекций по информатике. Шпрингер Берлин Гейдельберг. стр. 53–67 . дои : 10.1007/978-3-642-35289-8_5 . ISBN 978-3-642-35289-8 .
- ^ «Машинное обучение. Существует ли практическое правило, позволяющее разделить набор данных на обучающий и проверочный наборы?» . Переполнение стека . Проверено 12 августа 2021 г.
- ^ Ферри К. и Кайзер С. (2019). Нейронные сети для детей . Справочники. ISBN 1492671207 .
{{cite book}}: CS1 maint: несколько имен: список авторов ( ссылка ) - ↑ Перейти обратно: Перейти обратно: а б с Рипли, Б.Д. (1996) Распознавание образов и нейронные сети , Кембридж: Издательство Кембриджского университета, стр. 354
- ↑ Перейти обратно: Перейти обратно: а б с д « Тема: Что такое совокупность, выборка, обучающий набор, набор проектирования, набор проверки и набор тестов? », Часто задаваемые вопросы по нейронным сетям, часть 1 из 7: Введение ( txt ), comp.ai.neural-nets, Sarle, WS , изд. (1997 г., последнее изменение: 17 мая 2002 г.)
- ↑ Перейти обратно: Перейти обратно: а б Лароз, DT; Лароуз, компакт-диск (2014). Обнаружение знаний в данных: введение в интеллектуальный анализ данных . Хобокен: Уайли. дои : 10.1002/9781118874059 . ISBN 978-0-470-90874-7 . OCLC 869460667 .
- ↑ Перейти обратно: Перейти обратно: а б с Сюй, Юн; Гудакр, Ройстон (2018). «О разделении набора обучения и проверки: сравнительное исследование перекрестной проверки, начальной загрузки и систематической выборки для оценки эффективности обобщения контролируемого обучения» . Журнал анализа и тестирования . 2 (3). ООО «Спрингер Сайенс энд Бизнес Медиа»: 249–262. дои : 10.1007/s41664-018-0068-2 . ISSN 2096-241X . ПМК 6373628 . ПМИД 30842888 .
- ^ «Глубокое обучение» . Курсера . Проверено 18 мая 2021 г.
- ^ Бишоп, CM (1995), Нейронные сети для распознавания образов , Оксфорд: Oxford University Press, стр. 372
- ^ Кохави, Рон (3 марта 2001 г.). «Исследование перекрестной проверки и начальной загрузки для оценки точности и выбора модели» . 14 .
{{cite journal}}: Для цитирования журнала требуется|journal=( помощь ) - ^ Рипли, Брайан Д. (10 января 2008 г.). «Глоссарий». Распознавание образов и нейронные сети . Издательство Кембриджского университета. ISBN 9780521717700 . OCLC 601063414 .
- ↑ Перейти обратно: Перейти обратно: а б с д и Чанда СС, Банерджи Д.Н. (2022). «Ошибки упущения и совершения ошибок, лежащие в основе сбоев ИИ» . AI Soc : 1–24. дои : 10.1007/s00146-022-01585-x . ПМЦ 9669536 . ПМИД 36415822 .
- ^ Гринберг А. (14 ноября 2017 г.). «Наблюдайте, как лицо 10-летнего ребенка разблокирует iPhone X своей мамы» . Проводной .
Дифференцируемые вычисления |
|---|