Остаточная нейронная сеть
Эту статью может потребовать очистки Википедии , чтобы она соответствовала стандартам качества . Конкретная проблема заключается в том, что статья написана не в энциклопедическом тоне и страдает от многих ошибок в соблюдении простых правил стиля. ( февраль 2024 г. ) |

Остаточная нейронная сеть (также называемая остаточной сетью или ResNet ) [1] — это плодотворная модель глубокого обучения , в которой весовые слои изучают остаточные функции со ссылкой на входные данные слоя. Он был разработан в 2015 году для распознавания изображений и выиграл в этом году конкурс ImageNet Large Scale Visual Recognition Challenge ( ILSVRC ). [2] [3]
ResNet ведет себя как сеть автомагистралей , ворота которой открываются благодаря сильно положительным весам смещения. [4] Это позволяет легко обучать модели глубокого обучения с десятками или сотнями слоев и достигать большей точности при углублении. Соединения пропуска идентификации , часто называемые «остаточными соединениями», также используются в исходной сети LSTM . [5] модели -трансформеры (например, модели BERT и GPT, такие как ChatGPT ), система AlphaGo Zero , система AlphaStar и система AlphaFold .
Формулировка [ править ]
Предыстория [ править ]
В 2012 году АлексНет [6] была разработана для ILSVRC (которую она выиграла), став очень влиятельной моделью в развитии глубокого обучения для компьютерного зрения . AlexNet — это восьмислойная сверточная нейронная сеть (CNN), и хотя CNN существовали, по крайней мере, с LeNet в 1990-х годах, [7] AlexNet помог стать пионером в их использовании в реальных приложениях благодаря использованию графических процессоров для выполнения параллельных вычислений и слоев ReLU («выпрямленная линейная единица») для ускорения градиентного спуска .
В 2014 году VGGNet был разработан группой Visual Geometry Group (VGG) Оксфордского университета , улучшив архитектуру AlexNet. В то время как AlexNet использовал лишь несколько сверточных слоев с иногда большими ядрами (до ), VGGNet был пионером в использовании более глубоких CNN (т. е. с большим количеством слоев), используя множество меньших ядер ( ) сложены вместе.


Однако наложение слишком большого количества слоев привело к резкому снижению точности обучения . [8] известная как проблема «деградации». [1] Теоретически добавление дополнительных слоев для углубления сети не должно приводить к более высоким потерям при обучении , но именно это и произошло с VGGNet. [1] Однако если дополнительные уровни можно установить как сопоставления идентификаторов , то более глубокая сеть будет представлять ту же функцию, что и ее более мелкий аналог. Это основная идея остаточного обучения, которая объясняется ниже. Предполагается, что оптимизатор не может выполнить сопоставление идентификаторов для параметризованных слоев.
обучение Остаточное
В модели многослойной нейронной сети рассмотрим подсеть с определенным количеством сложенных слоев (например, 2 или 3). Обозначим основную функцию, выполняемую этой подсетью, как , где является входом в подсеть. Остаточное обучение повторно параметризует эту подсеть и позволяет слоям параметров представлять «остаточную функцию». . Выход этой подсети тогда представляется как:





Операция " » реализуется посредством «пропуска соединения», которое выполняет сопоставление идентификаторов для соединения входа подсети с ее выходом. В более поздней работе это соединение будет называться «остаточным соединением». Функция часто представляется матричным умножением, переплетенным с функциями активации и операциями нормализации (например, пакетной нормализацией или нормализацией слоев). В целом одна из этих подсетей называется «остаточным блоком». [1] Глубокая остаточная сеть создается путем простого объединения этих блоков.


Важно отметить, что основополагающий принцип остаточных блоков также является принципом исходной ячейки LSTM . [5] рекуррентная нейронная сеть , которая прогнозирует результат во времени как , который становится при обратном распространении ошибки во времени . [9]



Распространение сигнала [ править ]
Введение сопоставлений идентичности облегчает распространение сигнала как по прямому, так и по обратному пути, как описано ниже. [10]
Прямое распространение [ править ]
Если вывод -ый остаточный блок является входом в -ый остаточный блок (при условии, что между блоками нет функции активации), то -й вход:



Применяя эту формулировку рекурсивно, например,

дает общее соотношение:

где - индекс остаточного блока и это индекс некоторого более раннего блока. Эта формулировка предполагает, что всегда существует сигнал, который отправляется напрямую из более мелкого блока. в более глубокий блок .

Обратное распространение [ править ]
Формулировка остаточного обучения дает дополнительное преимущество, поскольку в некоторой степени решает проблему исчезающего градиента . Однако важно признать, что проблема исчезновения градиента не является основной причиной проблемы деградации, которая решается с помощью слоев нормализации. Чтобы наблюдать влияние остаточных блоков на обратное распространение ошибки , рассмотрим частную производную функции потерь относительно некоторого входного остаточного блока . Использование приведенного выше уравнения прямого распространения для более позднего остаточного блока : [10]




Эта формулировка предполагает, что вычисление градиента более мелкого слоя, , всегда имеет более поздний срок это добавляется напрямую. Даже если градиенты члены малы, общий градиент сопротивляется исчезновению благодаря добавленному термину .



Варианты остаточных блоков [ править ]

Базовый блок [ править ]
Базовый блок — это самый простой строительный блок, изученный в оригинальной ResNet. [1] Этот блок состоит из двух последовательных сверточных слоев 3x3 и остаточной связи. Входные и выходные размеры обоих слоев равны.
Узкое место [ править ]
Блок с узким местом [1] состоит из трех последовательных сверточных слоев и остаточной связи. Первый слой в этом блоке представляет собой свертку 1x1 для уменьшения размерности, например, до 1/4 входного измерения; второй слой выполняет свертку 3х3; последний слой — это еще одна свертка 1x1 для восстановления размеров. Модели ResNet-50, ResNet-101 и ResNet-152 в [1] все они основаны на блоках узких мест.
Блокировка предварительной активации [ править ]
Остаточный блок предварительной активации [10] применяет функции активации (например, нелинейность и нормализацию) перед применением функции невязки . Формально вычисление остаточного блока предварительной активации можно записать как:


где может быть любой операцией активации нелинейности (например, ReLU ) или нормализации (например, LayerNorm). Такая конструкция уменьшает количество неидентичных сопоставлений между остаточными блоками. Этот дизайн использовался для обучения моделей с количеством слоев от 200 до более 1000. [10]

Начиная с GPT-2 , блоки- трансформеры преимущественно реализовывались как блоки предварительной активации. В литературе по моделям Трансформеров это часто называют «предварительной нормализацией». [11]
Трансформаторный блок [ править ]
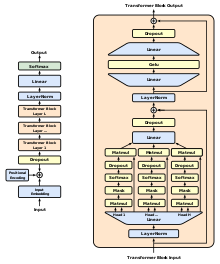
Блок -трансформер представляет собой набор из двух остаточных блоков. Каждый остаточный блок имеет остаточное соединение.
Первый остаточный блок — это многоголовый блок внимания , который выполняет вычисление (само) внимания, за которым следует линейная проекция.
Второй остаточный блок представляет собой блок многослойного персептрона с прямой связью ( MLP ) . Этот блок аналогичен «обратному» блоку узкого места: он имеет слой линейной проекции (который эквивалентен свертке 1x1 в контексте сверточных нейронных сетей), который увеличивает размерность, и еще одну линейную проекцию, которая уменьшает размерность.
Блок Трансформатора имеет глубину 4 слоев (линейных проекций).Модель GPT-3 имеет 96 блоков-трансформеров (в литературе по трансформерам блок-трансформер часто называют «слоем трансформатора»). Эта модель имеет глубину около 400 проекционных слоев, включая слои 96x4 в блоках-трансформерах и несколько дополнительных слоев для встраивания входных данных и прогнозирования выходных данных.
Очень глубокие модели Трансформаторов не могут быть успешно обучены без Остаточных Связей. [12]
Связанная работа [ править ]
В 1961 году Фрэнк Розенблатт описал модель трехслойного многослойного перцептрона (MLP) с пропускаемыми соединениями. [13] Модель называлась «системой с перекрестной связью», а скиповые соединения представляли собой формы перекрестных соединений.
В двух книгах, изданных в 1994 г. [14] и 1996 г., [15] Соединения «пропущенного уровня» были представлены в моделях MLP с прямой связью: « Общее определение [MLP] допускает более одного скрытого уровня, а также допускает соединения «пропускаемого уровня» от входа к выходу » (p261 в, [14] p144 в [15] ), «... что позволяет нелинейным узлам нарушать линейную функциональную форму » (стр.262 в [14] ). Это описание предполагает, что нелинейная MLP работает как функция невязки (возмущение), добавленная к линейной функции.
Зепп Хохрайтер проанализировал проблему исчезающего градиента в 1991 году и объяснил, почему глубокое обучение не работает должным образом. [16] Чтобы решить эту проблему, с длинной краткосрочной памятью (LSTM). были созданы рекуррентные нейронные сети [5] имели пропущенные соединения или остаточные соединения с весом 1,0 в каждой ячейке LSTM (называемой каруселью постоянных ошибок) для вычисления . При обратном распространении ошибки во времени это становится вышеупомянутой формулой остатка для нейронных сетей прямого распространения. Это позволяет обучать очень глубокие рекуррентные нейронные сети в течение очень длительного периода времени. Более поздняя версия LSTM, опубликованная в 2000 году. [17] модулирует идентификационные соединения LSTM с помощью так называемых шлюзов забывания, так что их веса не имеют фиксированного значения 1,0, но могут быть изучены. В экспериментах ворота забывания инициализировались с положительными весами смещения, [17] таким образом открывается, решая проблему исчезновения градиента.
Дорожная сеть мая 2015 г. [4] [18] применяет эти принципы к нейронным сетям прямого распространения .Сообщалось, что это «первая очень глубокая сеть прямой связи с сотнями слоев». [19] Это похоже на LSTM с воротами забвения, раскрытыми во времени . [17] в то время как более поздние Residual Nets не имеют эквивалента шлюзов забывания и похожи на развернутый оригинальный LSTM. [5] Если соединения пропуска в сетях шоссе «без ворот» или если их ворота остаются открытыми (активация 1.0) благодаря сильным положительным весам смещения, они становятся соединениями пропуска идентичности в остаточных сетях.
Оригинальный документ о сети автомобильных дорог [4] не только представил основной принцип очень глубоких сетей прямой связи, но также включил экспериментальные результаты с сетями с 20, 50 и 100 слоями и упомянул текущие эксперименты с числом слоев до 900.Сети с 50 или 100 слоями имели меньшую ошибку обучения, чем их простые сетевые аналоги, но не меньшую ошибку обучения, чем их аналог с 20 слоями (в наборе данных MNIST, рисунок 1 в [4] ). Никакого улучшения точности тестирования не наблюдалось в сетях с глубиной более 19 слоев (в наборе данных CIFAR-10; таблица 1 в [4] ). Документ ResNet, [10] однако предоставил убедительные экспериментальные доказательства преимуществ проникновения глубже 20 слоев. Он утверждал, что тождественное отображение без модуляции имеет решающее значение, и упомянул, что модуляция в пропускном соединении все еще может приводить к исчезновению сигналов при прямом и обратном распространении (раздел 3 в [10] ). Именно поэтому ворота забвения LSTM 2000 года [17] изначально были открыты с помощью положительных весов смещения: пока ворота открыты, он ведет себя как LSTM 1997 года. Аналогично, сеть Highway Net, ворота которой открываются благодаря сильно положительным весам смещения, ведет себя как ResNet.Пропускные соединения, используемые в современных нейронных сетях (например, Трансформерах ), преимущественно представляют собой тождественные сопоставления.
Денсенетс в 2016 году [20] были разработаны как глубокие нейронные сети, которые пытаются соединить каждый уровень с каждым другим слоем. DenseNets подошла к этой цели, используя сопоставления идентификаторов в качестве пропускных соединений. В отличие от ResNets, DenseNets объединяют выходные данные слоев с пропуском соединений путем конкатенации, а не сложения.
Нейронные сети со стохастической глубиной [21] стали возможными благодаря архитектуре остаточной сети. Эта процедура обучения случайным образом удаляет подмножество слоев и позволяет сигналу распространяться через соединение с пропуском идентификаторов. Это эффективный метод регуляризации, также известный как «DropPath», для обучения больших и глубоких моделей, таких как Vision Transformer (ViT).
отношение Биологическое
Оригинальная статья «Остаточная сеть» не претендует на то, чтобы быть вдохновленной биологическими системами. Но более поздние исследования связали Остаточные сети с биологически правдоподобными алгоритмами. [22] [23]
Исследование, опубликованное в журнале Science в 2023 году. [24] раскрыл полный коннектом мозга насекомого (личинки плодовой мухи). В ходе этого исследования были обнаружены « многослойные ярлыки », напоминающие пропускные соединения в искусственных нейронных сетях, включая ResNets.
Ссылки [ править ]
- ^ Jump up to: Перейти обратно: а б с д и ж г час , Шаоцин; Сунь, Цзянь (10 декабря 2015 г. . Сянюй ; Рен Хэ, Каймин; Чжан , )
- ^ «Итоги ILSVRC2015» . image-net.org .
- ^ Цзя; Фей-Фей, Ли (2009) - Дэн , Цзя; Сочер, Ричард, Ли .
- ^ Jump up to: Перейти обратно: а б с д и Шривастава, Рупеш Кумар; Грефф, Клаус; Шмидхубер, Юрген (3 мая 2015 г.). «Дорожные сети». arXiv : 1505.00387 [ cs.LG ].
- ^ Jump up to: Перейти обратно: а б с д Зепп Хохрайтер ; Юрген Шмидхубер (1997). «Долгая кратковременная память» . Нейронные вычисления . 9 (8): 1735–1780. дои : 10.1162/neco.1997.9.8.1735 . ПМИД 9377276 . S2CID 1915014 .
- ^ Крижевский, Алекс; Суцкевер, Илья; Хинтон, Джеффри Э. (24 мая 2017 г.). «Классификация ImageNet с глубокими сверточными нейронными сетями» . Коммуникации АКМ . 60 (6): 84–90. дои : 10.1145/3065386 .
- ^ ЛеКун, Янн ; Ботту, Леон; Бенджио, Йошуа; Хаффнер, Патрик (ноябрь 1998 г.). «Градиентное обучение применительно к распознаванию документов». Труды IEEE . 86 (11): 2278–2324. дои : 10.1109/5.726791 .
- ^ Он, Кайминг; Чжан, Сянъюй; Рен, Шаоцин; Сунь, Цзянь (2016). «Углубление выпрямителей: превосходство производительности человеческого уровня в классификации ImageNet». arXiv : 1502.01852 [ cs.CV ].
- ^ Сегеди, Кристиан; Иоффе, Сергей; Ванхук, Винсент; Алеми, Алекс (2016). «Inception-v4, Inception-ResNet и влияние остаточных связей на обучение». arXiv : 1602.07261 [ cs.CV ].
- ^ Jump up to: Перейти обратно: а б с д и ж Он, Кайминг; Чжан, Сянъюй; Рен, Шаоцин; Сунь, Цзянь (2015). «Отображения идентичности в глубоких остаточных сетях». arXiv : 1603.05027 [ cs.CV ].
- ^ Рэдфорд, Алек; Ву, Джеффри; Дитя, Ревон; Луан, Дэвид; Амодей, Дарио; Суцкевер, Илья (14 февраля 2019 г.). «Языковые модели предназначены для многозадачного обучения без присмотра» (PDF) . Архивировано (PDF) из оригинала 6 февраля 2021 года . Проверено 19 декабря 2020 г.
- ^ Донг, Ихэ; Кордонье, Жан-Батист; Лукас, Андреас (2021). «Внимание — это еще не все, что вам нужно: чистое внимание теряет свой ранг в двойне экспоненциально с глубиной». arXiv : 2103.03404 [ cs.LG ].
- ^ Розенблатт, Франк (1961). Принципы нейродинамики. Перцептроны и теория механизмов мозга (PDF) .
- ^ Jump up to: Перейти обратно: а б с Венейблс, Западная Нью-Йорк; Рипли, Брэйн Д. (1994). Современная прикладная статистика с S-Plus . Спрингер. ISBN 9783540943501 .
- ^ Jump up to: Перейти обратно: а б Рипли, Б.Д. (1996). Распознавание образов и нейронные сети . Издательство Кембриджского университета. дои : 10.1017/CBO9780511812651 . ISBN 978-0-521-46086-6 .
- ^ Хохрейтер, Зепп (1991). Исследования по динамическим нейронным сетям (PDF) (дипломная работа). Технический университет Мюнхена, Институт компьютерных наук, руководитель: Й. Шмидхубер.
- ^ Jump up to: Перейти обратно: а б с д Феликс А. Герс; Юрген Шмидхубер; Фред Камминс (2000). «Учимся забывать: постоянное прогнозирование с помощью LSTM». Нейронные вычисления . 12 (10): 2451–2471. CiteSeerX 10.1.1.55.5709 . дои : 10.1162/089976600300015015 . ПМИД 11032042 . S2CID 11598600 .
- ^ Шривастава, Рупеш Кумар; Грефф, Клаус; Шмидхубер, Юрген (22 июля 2015 г.). «Обучение очень глубоких сетей». arXiv : 1507.06228 [ cs.LG ].
- ^ Шмидхубер, Юрген (2015). «Microsoft выигрывает ImageNet 2015 благодаря Highway Net (или Feedforward LSTM) без шлюзов» .
- ^ Хуан, Гао; Лю, Чжуан; ван дер Маатен, Лоренс; Вайнбергер, Килиан (2016). Плотносвязанные сверточные сети . arXiv : 1608.06993 .
- ^ Хуан, Гао; Сунь, Ю; Лю, Чжуан; Вайнбергер, Килиан (2016). Глубокие сети со стохастической глубиной . arXiv : 1603.09382 .
- ^ Ляо, Цяньли; Поджо, Томазо (2016). Преодоление разрыва между остаточным обучением, рекуррентными нейронными сетями и зрительной корой . arXiv : 1604.03640 .
- ^ Сяо, Уилл; Чен, Хунлинь; Ляо, Цяньли; Поджо, Томазо (2018). Биологически правдоподобные алгоритмы обучения могут масштабироваться до больших наборов данных . arXiv : 1811.03567 .
- ^ Виндинг, Майкл; Педиго, Бенджамин; Барнс, Кристофер; Патсолик, Хизер; Пак, Янгсер; Казимирс, Том; Фушики, Акира; Андраде, Ингрид; Хандельвал, Авинаш; Вальдес-Алеман, Хавьер; Ли, Фэн; Рэндел, Надин; Барсотти, Элизабет; Коррейя, Ана; Феттер, Феттер; Хартенштейн, Волкер; Прибе, Кэри; Фогельштейн, Джошуа; Кардона, Альберт; Златич, Марта (10 марта 2023 г.). «Коннектом мозга насекомого» . Наука . 379 (6636): eadd9330. bioRxiv 10.1101/2022.11.28.516756v1 . дои : 10.1126/science.add9330 . ПМК 7614541 . ПМИД 36893230 . S2CID 254070919 .
Дифференцируемые вычисления | |||||||
|---|---|---|---|---|---|---|---|
| Общий | |||||||
| Концепции | |||||||
| Приложения | |||||||
| Аппаратное обеспечение | |||||||
| Библиотеки программного обеспечения | |||||||
| Реализации |
| ||||||
| Люди | |||||||
| Организации | |||||||
| Архитектуры |
| ||||||
| |||||||