Вариационный автоэнкодер


| Часть серии о |
| Машинное обучение и интеллектуальный анализ данных |
|---|
В машинном обучении ( вариационный автоэнкодер VAE ) — это архитектура искусственной нейронной сети, представленная Дидериком П. Кингмой и Максом Веллингом . Он входит в семейство вероятностных графических моделей и вариационных байесовских методов . [1]
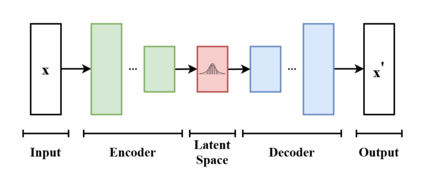
Вариационные автоэнкодеры не только рассматриваются как архитектура нейронной сети автоэнкодера , но и могут быть изучены в рамках математической формулировки вариационных байесовских методов , соединяющих сеть нейронного кодировщика с ее декодером через вероятностное скрытое пространство (например, как многомерное гауссово распределение ). что соответствует параметрам вариационного распределения.
Таким образом, кодер отображает каждую точку (например, изображение) из большого сложного набора данных в распределение внутри скрытого пространства, а не в одну точку в этом пространстве. Декодер имеет противоположную функцию: отображать скрытое пространство во входное пространство, опять же в соответствии с распределением (хотя на практике шум редко добавляется на этапе декодирования). Сопоставляя точку с распределением вместо одной точки, сеть может избежать переобучения обучающих данных. [2] Обе сети обычно обучаются вместе с использованием приема перепараметризации , хотя дисперсию модели шума можно изучить отдельно.
Хотя этот тип модели изначально был разработан для обучения без учителя , [3] [4] его эффективность была доказана для полуконтролируемого обучения [5] [6] и контролируемое обучение . [7]
Обзор архитектуры и работы [ править ]
Вариационный автоэнкодер — это генеративная модель с априорным распределением и распределением шума соответственно. Обычно такие модели обучаются с использованием мета-алгоритма максимизации ожидания (например, вероятностного PCA , разреженного кодирования (всплеск и плита)). Такая схема оптимизирует нижнюю границу вероятности данных, что обычно неразрешимо и при этом требует открытия q-распределений или вариационных апостериорных данных . Эти q-распределения обычно параметризуются для каждой отдельной точки данных в отдельном процессе оптимизации. Однако вариационные автоэнкодеры используют нейронную сеть как амортизированный подход для совместной оптимизации точек данных. Эта нейронная сеть принимает в качестве входных данных сами точки данных и выводит параметры для вариационного распределения. Поскольку он отображает известное входное пространство в низкомерное скрытое пространство, он называется кодировщиком.
Декодер — вторая нейронная сеть этой модели. Это функция, которая отображает скрытое пространство во входное пространство, например, как средство распределения шума. Можно использовать другую нейронную сеть, которая отображает дисперсию, однако для простоты ее можно опустить. В таком случае дисперсию можно оптимизировать с помощью градиентного спуска.
Чтобы оптимизировать эту модель, необходимо знать два термина: «ошибка реконструкции» и расхождение Кульбака – Лейблера (KL-D). Оба термина выводятся из выражения свободной энергии вероятностной модели и, следовательно, различаются в зависимости от распределения шума и предполагаемого априора данных. Например, обычно предполагается, что стандартная задача VAE, такая как IMAGENET, имеет гауссово распределенный шум; однако такие задачи, как бинаризация MNIST, требуют шума Бернулли. KL-D из выражения свободной энергии максимизирует массу вероятности q-распределения, которое перекрывается с p-распределением, что, к сожалению, может привести к поиску режима. Термин «реконструкция» представляет собой остаток выражения свободной энергии и требует аппроксимации выборки для вычисления его среднего значения. [8]
Формулировка [ править ]
С точки зрения вероятностного моделирования хочется максимизировать вероятность того, что данные по выбранному ими параметризованному распределению вероятностей . Это распределение обычно выбирается гауссовым. который параметризуется и соответственно, и как член экспоненциального семейства, с ним легко работать как с распределением шума. Простые распределения достаточно легко максимизировать, однако распределения, в которых предполагается априорное значение над скрытыми приводит к трудноразрешимым интегралам. Давайте найдем через маргинализацию .







где представляет собой совместное распределение в рамках наблюдаемых данных и его скрытое представление или кодирование . Согласно цепному правилу уравнение можно переписать в виде



В ванильном вариационном автоэнкодере обычно считается конечномерным вектором действительных чисел, а быть распределением Гаусса . Затем представляет собой смесь гауссовских распределений.

Теперь можно определить набор отношений между входными данными и их скрытым представлением как
- Прежний
- Вероятность
- задний



К сожалению, расчет дорого и в большинстве случаев трудноразрешимо. Чтобы ускорить расчет и сделать его возможным, необходимо ввести дополнительную функцию для аппроксимации апостериорного распределения как

с определяется как набор реальных значений, которые параметризуют . Иногда это называют амортизированным выводом , поскольку, «инвестируя» в поиск хорошего , позже можно сделать вывод от быстро, не делая никаких интегралов.



Таким образом, проблема состоит в том, чтобы найти хороший вероятностный автокодировщик, в котором условное распределение правдоподобия вычисляется вероятностным декодером , а аппроксимированное апостериорное распределение вычисляется вероятностным кодировщиком .

Параметризуйте энкодер как , а декодер как .


Нижняя граница доказательств (ELBO) [ править ]
Как и в каждой задаче глубокого обучения , необходимо определить дифференцируемую функцию потерь, чтобы обновлять веса сети посредством обратного распространения ошибки .
Идея вариационных автоэнкодеров состоит в том, чтобы совместно оптимизировать параметры генеративной модели. уменьшить ошибку восстановления между входом и выходом, и сделать как можно ближе к . В качестве потерь при реконструкции среднеквадратическая ошибка и перекрестная энтропия часто используются .


По мере потери расстояния между двумя распределениями расхождение Кульбака – Лейблера хороший выбор, чтобы сжать под . [8] [9]

Только что определенная потеря расстояния выражается как
![{\displaystyle {\begin{aligned}D_{KL}(q_{\phi }({z|x})\parallel p_{\theta }({z|x}))&=\mathbb {E} _{ z\sim q_{\phi }(\cdot |x)}\left[\ln {\frac {q_{\phi }(z|x)}{p_{\theta }(z|x)}}\right ]\\&=\mathbb {E} _{z\sim q_{\phi }(\cdot |x)}\left[\ln {\frac {q_{\phi }({z|x})p_{ \theta }(x)}{p_{\theta }(x,z)}}\right]\\&=\ln p_{\theta }(x)+\mathbb {E} _{z\sim q_{ \phi }(\cdot |x)}\left[\ln {\frac {q_{\phi }({z|x})}{p_{\theta }(x,z)}}\right]\end {выровнено}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/12961b671abd2f6d9f8333b9fd2c69f5729452e6)
Теперь определим нижнюю границу доказательства (ELBO):
![{\displaystyle L_{\theta,\phi }(x):=\mathbb {E} _{z\sim q_{\phi }(\cdot |x)}\left[\ln {\frac {p_{\ theta }(x,z)}{q_{\phi }({z|x})}}\right]=\ln p_{\theta }(x)-D_{KL}(q_{\phi }({ \cdot |x})\parallel p_{\theta }({\cdot |x}))}](https://wikimedia.org/api/rest_v1/media/math/render/svg/f3930aaedee5df702f84e1571372c645eefa6572)




Приведенная форма не очень удобна для максимизации, но есть следующая эквивалентная форма:
![{\ displaystyle L _ {\ theta, \ phi } (x) = \ mathbb {E} _ {z \ sim q_ {\ phi } (\ cdot | x)} \ left [\ ln p_ {\ theta } (x | z)\right]-D_{KL}(q_{\phi }({\cdot |x})\parallel p_{\theta }(\cdot ))}](https://wikimedia.org/api/rest_v1/media/math/render/svg/e4ab2e155d237ffd569ef918817953a3ef82612c)






![{\displaystyle L_{\theta,\phi }(x)=-{\frac {1}{2}}\mathbb {E} _{z\sim q_{\phi }(\cdot |x)}\left [\|x-D_{\theta }(z)\|_{2}^{2}\right]-{\frac {1}{2}}\left(N\sigma _{\phi }(x )^{2}+\|E_{\phi }(x)\|_{2}^{2}-2N\ln \sigma _{\phi }(x)\right)+Const}](https://wikimedia.org/api/rest_v1/media/math/render/svg/166eb4fc2e504a10271e5bad8ba9fd0f69bc6de5)

Репараметризация [ править ]
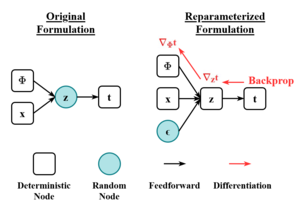

Для эффективного поиска
Это легко найти
![{\ displaystyle \ nabla _ {\ theta } \ mathbb {E} _ {z \ sim q_ {\ phi } (\ cdot | x)} \ left [\ ln {\ frac {p_ {\ theta } (x, z) )}{q_{\phi }({z|x})}}\right]=\mathbb {E} _{z\sim q_{\phi }(\cdot |x)}\left[\nabla _{ \theta }\ln {\frac {p_{\theta }(x,z)}{q_{\phi }({z|x})}}\right]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/95305894e3cfbd10c985a9569091220891523aef)
![{\ displaystyle \ nabla _ {\ phi } \ mathbb {E} _ {z \ sim q_ {\ phi } (\ cdot | x)} \ left [\ ln {\ frac {p_ {\ theta } (x, z) )}{q_{\phi }({z|x})}}\right]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/bd826d47c8a9e4ac5fc59cef9026f401e9806df6)

Самый важный пример – это когда нормально распределяется, так как .


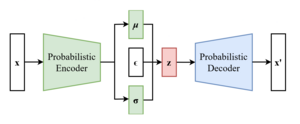
Схема вариационного автоэнкодера после трюка с перепараметризацией

Это можно перепараметризовать, позволив быть «стандартным генератором случайных чисел » и построить как . Здесь, получается разложением Холецкого :




![{\ displaystyle \ nabla _ {\ phi } \ mathbb {E} _ {z \ sim q_ {\ phi } (\ cdot | x)} \ left [\ ln {\ frac {p_ {\ theta } (x, z) )}{q_{\phi }({z|x})}}\right]=\mathbb {E} _{\epsilon }\left[\nabla _{\phi }\ln {\frac {p_{\ тета }(x,\mu _{\phi }(x)+L_{\phi }(x)\epsilon )}{q_{\phi }(\mu _{\phi }(x)+L_{\phi }(x)\эпсилон |x)}}\right]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/ab3c8e4238659d4273a37de83c8c40ce58c789fb)
Поскольку мы перепараметризовали , нам нужно найти . Позволять быть функцией плотности вероятности для , затем [ нужны разъяснения ]





Вариации [ править ]
Многие приложения и расширения вариационных автоэнкодеров использовались для адаптации архитектуры к другим областям и повышения ее производительности.
-VAE — это реализация с взвешенным термином расхождения Кульбака-Лейблера для автоматического обнаружения и интерпретации факторизованных скрытых представлений. С помощью этой реализации можно принудительно распутать многообразие для значения больше единицы. Эта архитектура может обнаруживать распутанные скрытые факторы без присмотра. [13] [14]

Условный VAE (CVAE) вставляет информацию метки в скрытое пространство, чтобы обеспечить детерминированное ограниченное представление изученных данных. [15]
Некоторые структуры напрямую занимаются качеством генерируемых образцов. [16] [17] или реализовать более одного скрытого пространства для дальнейшего улучшения обучения представлению.
Некоторые архитектуры смешивают VAE и генеративно-состязательные сети для получения гибридных моделей. [18] [19] [20]
См. также [ править ]
Ссылки [ править ]
- ^ Пиньейру Синелли, Лукас; и др. (2021). «Вариационный автоэнкодер» . Вариационные методы машинного обучения с приложениями к глубоким сетям . Спрингер. стр. 111–149. дои : 10.1007/978-3-030-70679-1_5 . ISBN 978-3-030-70681-4 . S2CID 240802776 .
- ^ Рокка, Джозеф (21 марта 2021 г.). «Понимание вариационных автоэнкодеров (VAE)» . Середина .
- ^ Дилоктанакул, Нат; Медиано, Педро AM; Гарнело, Марта; Ли, Мэтью CH; Салимбени, Хью; Арулкумаран, Кай; Шанахан, Мюррей (13 января 2017 г.). «Глубокая неконтролируемая кластеризация с помощью вариационных автоэнкодеров гауссовой смеси». arXiv : 1611.02648 [ cs.LG ].
- ^ Сюй, Вэй-Нин; Чжан, Ю; Гласс, Джеймс (декабрь 2017 г.). «Неконтролируемая адаптация предметной области для надежного распознавания речи посредством вариационного увеличения данных на основе автокодировщика» . Семинар IEEE по автоматическому распознаванию и пониманию речи (ASRU) , 2017 г. стр. 16–23. arXiv : 1707.06265 . дои : 10.1109/ASRU.2017.8268911 . ISBN 978-1-5090-4788-8 . S2CID 22681625 .
- ^ Эхсан Аббаснежад, М.; Дик, Энтони; ван ден Хенгель, Антон (2017). Бесконечный вариационный автоэнкодер для полуконтролируемого обучения . стр. 5888–5897.
- ^ Сюй, Вейди; Сунь, Хаозе; Дэн, Чао; Тан, Ин (12 февраля 2017 г.). «Вариационный автоэнкодер для полуконтролируемой классификации текста» . Материалы конференции AAAI по искусственному интеллекту . 31 (1). дои : 10.1609/aaai.v31i1.10966 . S2CID 2060721 .
- ^ Камеока, Хирокадзу; Ли, Ли; Иноуэ, Шота; Макино, Сёдзи (01 сентября 2019 г.). «Контролируемое разделение источников с помощью многоканального вариационного автоэнкодера» . Нейронные вычисления . 31 (9): 1891–1914. дои : 10.1162/neco_a_01217 . ПМИД 31335290 . S2CID 198168155 .
- ^ Jump up to: а б с Кингма, Дидерик П.; Веллинг, Макс (20 декабря 2013 г.). «Автокодирование вариационного Байеса». arXiv : 1312.6114 [ stat.ML ].
- ^ «От автоэнкодера до бета-VAE» . Лил'Лог . 2018-08-12.
- ^ Резенде, Данило Хименес; Мохамед, Шакир; Виерстра, Даан (18 июня 2014 г.). «Стохастическое обратное распространение ошибки и приближенный вывод в глубоких генеративных моделях» . Международная конференция по машинному обучению . ПМЛР: 1278–1286. arXiv : 1401.4082 .
- ^ Бенджио, Йошуа; Курвиль, Аарон; Винсент, Паскаль (2013). «Обучение репрезентации: обзор и новые перспективы» . Транзакции IEEE по анализу шаблонов и машинному интеллекту . 35 (8): 1798–1828. arXiv : 1206.5538 . дои : 10.1109/TPAMI.2013.50 . ISSN 1939-3539 . ПМИД 23787338 . S2CID 393948 .
- ^ Кингма, Дидерик П.; Резенде, Данило Дж.; Мохамед, Шакир; Веллинг, Макс (31 октября 2014 г.). «Полуконтролируемое обучение с использованием глубоких генеративных моделей». arXiv : 1406.5298 [ cs.LG ].
- ^ Хиггинс, Ирина; Мэтти, Лоик; Пал, Арка; Берджесс, Кристофер; Глорот, Ксавье; Ботвиник, Мэтью; Мохамед, Шакир; Лерхнер, Александр (4 ноября 2016 г.). «бета-VAE: изучение основных визуальных концепций с помощью ограниченной вариационной структуры» .
{{cite journal}}: Для цитирования журнала требуется|journal=( помощь ) - ^ Берджесс, Кристофер П.; Хиггинс, Ирина; Пал, Арка; Мэтти, Лоик; Уоттерс, Ник; Дежарден, Гийом; Лерхнер, Александр (10 апреля 2018 г.). «Понимание распутывания в β-VAE». arXiv : 1804.03599 [ stat.ML ].
- ^ Сон, Кихёк; Ли, Хонглак; Ян, Синьчэнь (01 января 2015 г.). «Изучение структурированного представления выходных данных с использованием глубоких условных генеративных моделей» (PDF) .
{{cite journal}}: Для цитирования журнала требуется|journal=( помощь ) - ^ Дай, Бин; Випф, Дэвид (30 октября 2019 г.). «Диагностика и улучшение моделей VAE». arXiv : 1903.05789 [ cs.LG ].
- ^ Дорта, Гароэ; Висенте, Сара; Агапито, Лурдес; Кэмпбелл, Нил Д.Ф.; Симпсон, Айвор (31 июля 2018 г.). «Обучение VAE по структурированным остаткам». arXiv : 1804.01050 [ stat.ML ].
- ^ Ларсен, Андерс Боесен Линдбо; Сёндербю, Сорен Кааэ; Ларошель, Хьюго; Винтер, Оле (11 июня 2016 г.). «Автокодирование за пределами пикселей с использованием изученной метрики сходства» . Международная конференция по машинному обучению . ПМЛР: 1558–1566. arXiv : 1512.09300 .
- ^ Бао, Цзяньминь; Чен, Донг; Вэнь, Фанг; Ли, Хоуцян; Хуа, Банда (2017). «CVAE-GAN: создание детализированных изображений посредством асимметричного обучения». стр. 2745–2754. arXiv : 1703.10155 [ cs.CV ].
- ^ Гао, Руй; Хоу, Синсун; Цинь, Цзе; Чен, Цзясинь; Лю, Ли; Чжу, Фань; Чжан, Чжао; Шао, Линг (2020). «Zero-VAE-GAN: создание невидимых функций для обобщенного и трансдуктивного обучения с нулевым выстрелом» . Транзакции IEEE при обработке изображений . 29 : 3665–3680. Бибкод : 2020ITIP...29.3665G . дои : 10.1109/TIP.2020.2964429 . ISSN 1941-0042 . ПМИД 31940538 . S2CID 210334032 .
Дифференцируемые вычисления |
|---|