Случайный лес
| Часть серии о |
| Машинное обучение и интеллектуальный анализ данных |
|---|
Случайные леса или леса случайных решений — это метод ансамблевого обучения для классификации , регрессии и других задач, который работает путем построения множества деревьев решений во время обучения. Для задач классификации выходными данными случайного леса является класс, выбранный большинством деревьев. Для задач регрессии возвращается среднее или среднее предсказание отдельных деревьев. [1] [2] Случайные леса решений корректируют привычку деревьев решений подстраиваться под свой обучающий набор . [3] : 587–588
Первый алгоритм для леса случайных решений был создан в 1995 году Тином Кам Хо. [1] используя метод случайных подпространств , [2] что, по формулировке Хо, является способом реализации подхода «стохастической дискриминации» к классификации, предложенного Юджином Кляйнбергом. [4] [5] [6]
Расширение алгоритма было разработано Лео Брейманом. [7] и Адель Катлер , [8] кто зарегистрировался [9] «Случайные леса» как товарный знак в 2006 г. (по состоянию на 2019 г. [update], принадлежащий Minitab, Inc. ). [10] Расширение сочетает в себе идею « упаковки » Бреймана и случайный выбор функций, впервые представленный Хо. [1] а позже независимо Амита и Гемана [11] для построения набора деревьев решений с контролируемой дисперсией.
История [ править ]
Общий метод лесов случайных решений был впервые предложен Зальцбергом и Хитом в 1993 году. [12] с методом, который использовал алгоритм рандомизированного дерева решений для создания нескольких разных деревьев, а затем объединял их с помощью голосования большинством. Эта идея была развита Хо в 1995 году. [1] Хо установил, что леса деревьев, разделенные наклонными гиперплоскостями, могут получать точность по мере роста, не страдая от переобучения, при условии, что леса случайным образом ограничены чувствительностью только к выбранным размерам объектов . Последующая работа в том же духе [2] пришли к выводу, что другие методы разделения ведут себя аналогичным образом, пока они случайным образом вынуждены быть нечувствительными к некоторым размерам объектов. Обратите внимание, что это наблюдение за тем, как более сложный классификатор (большой лес) становится более точным почти монотонно, резко контрастирует с распространенным убеждением, что сложность классификатора может вырасти только до определенного уровня точности, прежде чем она пострадает от переобучения. Объяснение устойчивости метода леса к перетренированности можно найти в теории стохастической дискриминации Клейнберга. [4] [5] [6]
На раннее развитие идеи Бреймана о случайных лесах повлияли работы Амита и Гемана. [11] который представил идею поиска по случайному подмножеству доступных решений при разделении узла в контексте выращивания одного дерева . Идея случайного выбора подпространства от Хо [2] также оказал влияние на создание случайных лесов. В этом методе выращивается лес деревьев, и различия между деревьями вводятся путем проецирования обучающих данных в случайно выбранное подпространство перед подгонкой каждого дерева или каждого узла. Наконец, идея рандомизированной оптимизации узлов, при которой решение в каждом узле выбирается с помощью рандомизированной процедуры, а не детерминированной оптимизации, была впервые предложена Томасом Г. Диттерихом . [13]
Правильное введение случайных лесов было сделано в статье Лео Бреймана . [7] В этой статье описывается метод построения леса некоррелированных деревьев с использованием процедуры, подобной CART , в сочетании со рандомизированной оптимизацией узлов и пакетированием . Кроме того, в этой статье сочетаются несколько ингредиентов, как ранее известных, так и новых, которые составляют основу современной практики случайных лесов, в частности:
- Использование ошибки «вне пакета» в качестве оценки ошибки обобщения .
- Измерение важности переменной посредством перестановки.
В отчете также представлен первый теоретический результат для случайных лесов в виде оценки ошибки обобщения , которая зависит от силы деревьев в лесу и их корреляции .
Алгоритм [ править ]
Предварительные сведения: изучение дерева решений [ править ]
Деревья решений — популярный метод для решения различных задач машинного обучения. Обучение деревьям «наиболее близко соответствует требованиям, предъявляемым к использованию в качестве готовой процедуры интеллектуального анализа данных», говорят Хасти и др. , «поскольку он инвариантен при масштабировании и различных других преобразованиях значений признаков, устойчив к включению нерелевантных признаков и создает проверяемые модели. Однако они редко бывают точными». [3] : 352
В частности, деревья, выросшие очень глубоко, имеют тенденцию обучаться крайне нерегулярным шаблонам: они переопределяют свои обучающие наборы, т. е. имеют низкую систематическую ошибку, но очень высокую дисперсию . Случайные леса — это способ усреднения нескольких глубоких деревьев решений, обученных на разных частях одного и того же обучающего набора, с целью уменьшения дисперсии. [3] : 587–588 Это достигается за счет небольшого увеличения систематической ошибки и некоторой потери интерпретируемости, но в целом значительно повышает производительность окончательной модели.
Упаковка [ править ]
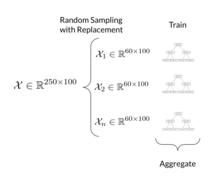
Алгоритм обучения случайных лесов применяет к обучающимся деревьям общий метод бутстрап-агрегирования или пакетирования. Учитывая обучающий набор X = x 1 , ..., x n с ответами Y = y 1 , ..., y n , повторное пакетирование ( B раз) выбирает случайную выборку с заменой обучающего набора и подбирает к ним деревья. образцы:
- Выборка с заменой n обучающих примеров из X , Y ; назовите их X b , Y b .
- Обучите дерево классификации или регрессии f b на X b , Y b .
После обучения прогнозы для невидимых выборок x' можно сделать путем усреднения прогнозов всех отдельных деревьев регрессии по x' :

или путем голосования большинства в случае деревьев классификации.
Эта процедура начальной загрузки приводит к повышению производительности модели, поскольку уменьшает дисперсию модели без увеличения систематической ошибки. Это означает, что, хотя прогнозы одного дерева очень чувствительны к шуму в его обучающем наборе, среднее значение многих деревьев нет, пока деревья не коррелированы. Простое обучение многих деревьев на одном обучающем наборе приведет к получению сильно коррелированных деревьев (или даже одного и того же дерева много раз, если алгоритм обучения является детерминированным); Бутстрап-выборка — это способ декорреляции деревьев путем показа им различных обучающих наборов.
Кроме того, оценку неопределенности прогноза можно сделать как стандартное отклонение прогнозов всех отдельных деревьев регрессии по x' :

Количество выборок/деревьев B является свободным параметром. Обычно используется от нескольких сотен до нескольких тысяч деревьев, в зависимости от размера и характера обучающего набора. Оптимальное количество деревьев B можно найти с помощью перекрестной проверки или путем наблюдения за ошибкой «вне пакета» : средней ошибкой прогнозирования для каждой обучающей выборки x i с использованием только тех деревьев, у которых не было x i в их начальной выборке. . [14] Ошибка обучения и тестирования имеет тенденцию выравниваться после того, как некоторое количество деревьев было подобрано.
От сбора в мешки до случайных лесов [ править ]
Вышеуказанная процедура описывает исходный алгоритм упаковки деревьев. Случайные леса также включают в себя другой тип схемы объединения: они используют модифицированный алгоритм обучения дерева, который выбирает при каждом разделении кандидатов в процессе обучения случайное подмножество функций . Этот процесс иногда называют «сборкой функций». Причиной этого является корреляция деревьев в обычной бутстреп-выборке: если один или несколько признаков являются очень сильными предикторами для переменной ответа (целевой результат), эти признаки будут выбраны во многих B -деревьях, что приведет к их стать коррелированным. Анализ того, как пакетирование и случайное проецирование подпространства способствуют повышению точности в различных условиях, проведен Хо. [15]
Обычно для задачи классификации с p признаками √ p (округленных вниз) признаков. в каждом разбиении используется [3] : 592 Для задач регрессии изобретатели рекомендуют p /3 (округленное вниз) с минимальным размером узла 5 по умолчанию. [3] : 592 На практике оптимальные значения этих параметров следует подбирать индивидуально для каждой проблемы. [3] : 592
ExtraTrees [ править ]
Добавление еще одного шага рандомизации дает чрезвычайно рандомизированные деревья или ExtraTrees. Несмотря на то, что они похожи на обычные случайные леса в том, что они представляют собой ансамбль отдельных деревьев, есть два основных различия: во-первых, каждое дерево обучается с использованием всей обучающей выборки (а не бутстрап-выборки), а во-вторых, разбиение сверху вниз в обучаемый дерево рандомизировано. Вместо вычисления локально оптимальной точки отсечения для каждого рассматриваемого признака (на основе, например, прироста информации или примеси Джини ), случайная выбирается точка отсечения. Это значение выбирается из равномерного распределения в пределах эмпирического диапазона признака (в обучающем наборе дерева). Затем из всех случайно сгенерированных разделений для разделения узла выбирается разделение, которое дает наивысший балл. Подобно обычным случайным лесам, можно указать количество случайно выбранных объектов, которые будут учитываться в каждом узле. Значения по умолчанию для этого параметра: для классификации и для регрессии, где количество функций в модели. [16]


для многомерных данных Случайные леса
Базовая процедура случайного леса может не работать должным образом в ситуациях, когда имеется большое количество признаков, но лишь небольшая часть этих признаков информативна для классификации выборки. Эту проблему можно решить, поощряя процедуру фокусироваться главным образом на информативных объектах и деревьях. Вот некоторые методы достижения этой цели:
- Предварительная фильтрация: удаление функций, которые в основном представляют собой просто шум. [17] [18]
- Обогащенный случайный лес (ERF): используйте взвешенную случайную выборку вместо простой случайной выборки в каждом узле каждого дерева, придавая больший вес функциям, которые кажутся более информативными. [19] [20]
- Случайный лес, взвешенный по деревьям (TWRF): взвешивайте деревья, чтобы деревьям, демонстрирующим более высокую точность, присваивались более высокие веса. [21] [22]
Свойства [ править ]
Важность переменной [ править ]
Случайные леса можно использовать для естественного ранжирования важности переменных в задаче регрессии или классификации. Следующая техника была описана в оригинальной статье Бреймана. [7] и реализован в R пакете randomForest . [8]
Важность перестановки [ править ]
Первый шаг в измерении важности переменной в наборе данных заключается в подгонке случайного леса к данным. В процессе подгонки ошибка выхода из пакета для каждой точки данных записывается и усредняется по лесу (ошибки на независимом тестовом наборе могут быть заменены, если во время обучения не используется пакетирование).

Чтобы измерить важность -й признак после обучения, значения -й признак переставляется в выборках «вне пакета», и ошибка «вне пакета» снова вычисляется на этом искаженном наборе данных. Оценка важности для -й признак вычисляется путем усреднения разницы ошибок выхода из пакета до и после перестановки по всем деревьям. Оценка нормализуется по стандартному отклонению этих различий.

Функции, которые дают большие значения для этой оценки, оцениваются как более важные, чем функции, которые дают маленькие значения. Статистическое определение показателя значимости переменной было дано и проанализировано Zhu et al. [23]
Этот метод определения важности переменной имеет некоторые недостатки.
- Для данных, включающих категориальные переменные с разным количеством уровней, случайные леса смещаются в пользу атрибутов с большим количеством уровней. Такие методы, как частичные перестановки [24] [25] [26] и выращивание непредвзятых деревьев [27] [28] можно использовать для решения проблемы.
- Если данные содержат группы коррелированных характеристик, имеющих одинаковое значение для выходных данных, то меньшие группы имеют преимущество перед более крупными. [29]
- Кроме того, процедура перестановки может не идентифицировать важные функции, если есть коллинеарные функции. В этом случае решением проблемы является перестановка групп коррелирующих признаков. [30]
Среднее снижение примесных важности свойств
Эта функция, важная для случайных лесов, является реализацией по умолчанию в научных наборах и R. Она описана в книге Лео Бреймана «Деревья классификации и регрессии». [31] Важными считаются переменные, которые значительно уменьшают примеси во время разделения: [32]








Нормализованная важность затем получается путем нормализации всех признаков, так что сумма нормализованных важностей признаков равна 1.
Реализация по умолчанию среднего уменьшения важности примесных функций в научном наборе обучения подвержена вводящим в заблуждение значениям функций: [30]
- мера важности предпочитает функции с высокой мощностью
- он использует статистику обучения и, следовательно, не «отражает способность функции быть полезной для составления прогнозов, которые обобщаются для тестового набора» [33]
Отношения с ближайшими соседями [ править ]
На связь между случайными лесами и алгоритмом k -ближайшего соседа ( k -NN) указали Лин и Чон в 2002 году. [34] Оказывается, обе схемы можно рассматривать как так называемые схемы взвешенных окрестностей . Это модели, построенные на основе обучающего набора. которые делают прогнозы для новых точек x' , рассматривая «окрестность» точки, формализованную весовой функцией W :



Здесь, - это неотрицательный вес i -й точки обучения относительно новой точки x' в том же дереве. Для любого конкретного x' веса точек сумма должна быть равна единице. Весовые функции задаются следующим образом:


- В k -NN веса равны если x i — одна из k точек, ближайших к x' , и ноль в противном случае.
- На дереве, если x i — одна из k' точек того же листа, что и x' , и ноль в противном случае.


Поскольку лес усредняет предсказания набора из m деревьев с отдельными весовыми функциями , его предсказания


Это показывает, что весь лес снова представляет собой схему взвешенного соседства с весами, усредняющими веса отдельных деревьев. Соседями точки x' в этой интерпретации являются точки общий лист на любом дереве . Таким образом, окрестность x' сложным образом зависит от структуры деревьев и, следовательно, от структуры обучающего набора. Лин и Чон показывают, что форма окрестности, используемая случайным лесом, адаптируется к локальной важности каждого объекта. [34]
Обучение без учителя со случайными лесами [ править ]
В рамках своей конструкции случайные лесные предикторы естественным образом приводят к показателю различия между наблюдениями. Можно также определить меру различия случайного леса между немаркированными данными: идея состоит в том, чтобы построить предиктор случайного леса, который отличает «наблюдаемые» данные от сгенерированных соответствующим образом синтетических данных. [7] [35] Наблюдаемые данные представляют собой исходные немаркированные данные, а синтетические данные взяты из эталонного распределения. Случайное несходство леса может быть привлекательным, поскольку оно очень хорошо обрабатывает смешанные типы переменных, инвариантно к монотонным преобразованиям входных переменных и устойчиво к внешним наблюдениям. Случайное несходство леса легко справляется с большим количеством полунепрерывных переменных благодаря выбору внутренних переменных; например, различие случайного леса «Addcl 1» взвешивает вклад каждой переменной в зависимости от того, насколько она зависит от других переменных. Случайное несходство леса использовалось в различных приложениях, например, для поиска групп пациентов на основе данных тканевых маркеров. [36]
Варианты [ править ]
Вместо деревьев решений были предложены и оценены линейные модели в качестве базовых оценок в случайных лесах, в частности, полиномиальная логистическая регрессия и наивные классификаторы Байеса . [37] [38] [39] В случаях, когда связь между предикторами и целевой переменной линейна, базовые учащиеся могут иметь такую же высокую точность, как и ансамблевый учащийся. [40] [37]
Случайный лес ядра [ править ]
В машинном обучении случайные леса ядра (KeRF) устанавливают связь между случайными лесами и методами ядра . Немного изменив их определение, случайные леса можно переписать в методы ядра , которые более интерпретируются и легче анализируются. [41]
История [ править ]
Лео Брейман [42] был первым, кто заметил связь между случайным лесом и методами ядра . Он отметил, что случайные леса, которые выращиваются с использованием случайных векторов iid при построении дерева, эквивалентны ядру, действующему на истинное поле. Лин и Чон [43] установил связь между случайными лесами и адаптивным ближайшим соседом, подразумевая, что случайные леса можно рассматривать как адаптивные оценки ядра. Дэвис и Гахрамани [44] предложил ядро случайного леса и показал, что оно может эмпирически превосходить современные методы ядра. Скорнет [41] впервые определил оценки KeRF и установил явную связь между оценками KeRF и случайным лесом. Он также дал явные выражения для ядер, основанных на центрированном случайном лесу. [45] и однородный случайный лес, [46] две упрощенные модели случайного леса. Он назвал эти два KeRF «Центрированным KeRF» и «Униформным KeRF» и доказал верхние границы их степени согласованности.
Обозначения и определения [ править ]
Предварительные сведения: Центрированные леса [ править ]
Центрированный лес [45] представляет собой упрощенную модель исходного случайного леса Бреймана, которая равномерно выбирает атрибут среди всех атрибутов и выполняет разбиение в центре ячейки по заранее выбранному атрибуту. Алгоритм останавливается, когда полностью бинарное дерево уровня построен там, где является параметром алгоритма.


Равномерный лес [ править ]
Равномерный лес [46] — это еще одна упрощенная модель исходного случайного леса Бреймана, которая равномерно выбирает объект среди всех объектов и выполняет разбиение в точке, равномерно нарисованной на боковой стороне ячейки вдоль заранее выбранного объекта.
леса KeRF От случайного к
Учитывая обучающую выборку из -значные независимые случайные величины, распределенные как пара независимых прототипов , где . Мы стремимся предсказать реакцию , связанный со случайной величиной , оценивая функцию регрессии . Лес случайной регрессии представляет собой ансамбль деревья рандомизированной регрессии. Обозначим прогнозируемое значение в точке по -е дерево, где являются независимыми случайными величинами, распределенными как общая случайная величина , независимо от выборки . Эту случайную величину можно использовать для описания случайности, вызванной разделением узлов и процедурой выборки для построения дерева. Деревья объединяются для формирования оценки конечного леса. .Для деревьев регрессии мы имеем , где является ячейкой, содержащей , разработанный со случайностью и набор данных , и .

![{\displaystyle [0,1]^{p}\times \mathbb {R} }](https://wikimedia.org/api/rest_v1/media/math/render/svg/6724c5c806dd7cee08c1f2133fc89f94ed0c2e91)

![{\displaystyle \operatorname {E} [Y^{2}]<\infty }](https://wikimedia.org/api/rest_v1/media/math/render/svg/07a863a618762e9fecf30fadce90c3f6484db196)


![{\displaystyle м(\mathbf {x}) =\operatorname {E} [Y\mid \mathbf {X} =\mathbf {x}]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/0c097ce105048693746d5524ac0ef9fc514da53b)











Таким образом, случайные оценки леса удовлетворяют всем , . Случайный регрессионный лес имеет два уровня усреднения: сначала по выборкам в целевой ячейке дерева, затем по всем деревьям. Таким образом, вклад наблюдений, находящихся в ячейках с высокой плотностью точек данных, меньше, чем вклад наблюдений, принадлежащих менее населенным ячейкам. Чтобы улучшить методы случайного леса и компенсировать неправильную оценку, Скорнет [41] определил KeRF в
![{\displaystyle \mathbf {x} \in [0,1]^{d}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/691c9727c059400e1d15031c7e0e08fbd6774282)






Центрированный KeRF [ править ]
Построение Centered KeRF уровня то же самое, что и для центрированного леса, за исключением того, что прогнозы делаются , соответствующая функция ядра или функция соединения

![{\ displaystyle K_ {k} ^ {cc} (\ mathbf {x}, \ mathbf {z}) = \ sum _ {k_ {1}, \ ldots, k_ {d}, \ sum _ {j = 1} ^{d}k_{j}=k}{\frac {k!}{k_{1}!\cdots k_{d}!}}\left({\frac {1}{d}}\right)^ {k}\prod _{j=1}^{d}\mathbf {1} _{\lceil 2^{k_{j}}x_{j}\rceil =\lceil 2^{k_{j}}z_ {j}\rceil },\qquad {\text{ for all }}\mathbf {x} ,\mathbf {z} \in [0,1]^{d}.}](https://wikimedia.org/api/rest_v1/media/math/render/svg/b4b7a16a2bcfb63020d9081379559d5fcd82a7a5)
Униформа KeRF [ править ]
Однородный KeRF строится так же, как и однородный лес, за исключением того, что прогнозы делаются , соответствующая функция ядра или функция соединения
![{\displaystyle K_{k}^{uf}(\mathbf {0},\mathbf {x})=\sum _{k_{1},\ldots,k_{d},\sum _{j=1} ^{d}k_{j}=k}{\frac {k!}{k_{1}!\ldots k_{d}!}}\left({\frac {1}{d}}\right)^ {k}\prod _{m=1}^{d}\left(1-|x_{m}|\sum _{j=0}^{k_{m}-1}{\frac {\left( -\ln |x_{m}|\right)^{j}}{j!}}\right){\text{ for all }}\mathbf {x} \in [0,1]^{d}. }](https://wikimedia.org/api/rest_v1/media/math/render/svg/e06f4c0b6697dda0b20263456b511570143a7785)
Свойства [ править ]
KeRF и случайным Связь между лесом
Прогнозы, данные KeRF и случайными лесами, близки, если количество точек в каждой ячейке контролируется:
Предположим, что существуют последовательности такое, что почти наверняка
Тогда почти наверняка



бесконечным KeRF и бесконечным случайным лесом между Связь
Когда количество деревьев уходит в бесконечность, то мы имеем бесконечный случайный лес и бесконечный KeRF. Их оценки близки, если число наблюдений в каждой ячейке ограничено:
Предположим, что существуют последовательности такое, что почти наверняка
Тогда почти наверняка

![{\displaystyle \operatorname {E} [N_ {n}(\mathbf {x},\Theta)]\geq 1,}](https://wikimedia.org/api/rest_v1/media/math/render/svg/07f5beb5ef7860bc9f527fb5b01fbed3dc0fc716)
![{\displaystyle \operatorname {P} [a_{n}\leq N_{n}(\mathbf {x},\Theta)\leq b_{n}\mid {\mathcal {D}}_{n}]\ geq 1-\varepsilon _{n}/2,}](https://wikimedia.org/api/rest_v1/media/math/render/svg/4bad78155a4139322247009072e48d6b7bf8c5b9)
![{\displaystyle \operatorname {P} [a_{n}\leq \operatorname {E}_{\Theta }[N_{n}(\mathbf {x},\Theta)]\leq b_{n}\mid { \mathcal {D}}_{n}]\geq 1-\varepsilon _{n}/2,}](https://wikimedia.org/api/rest_v1/media/math/render/svg/71711062ff59f3d2075162074e8f94f917a0cdad)

Согласованность результатов [ править ]
Предположим, что , где представляет собой центрированный гауссов шум, не зависящий от , с конечной дисперсией . Более того, равномерно распределен по и является Липшиц . Скорнет [41] доказал верхние границы скорости согласованности для центрированного KeRF и однородного KeRF.



![{\displaystyle [0,1]^{d}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/e13ae4917276744b214714a20b3cb8ee305e309d)

центрированного Согласованность KeRF
Предоставление и , существует константа такой, что для всех , .




![{\displaystyle \mathbb {E} [{\tilde {m}}_{n}^{cc}(\mathbf {X}) -m (\mathbf {X})]^{2}\leq C_{1 }n^{-1/(3+d\log 2)}(\log n)^{2}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/bbd76dd80031cfdb1b8042faeab38ecaafefa2e3)
Согласованность однородного KeRF [ править ]
Предоставление и , существует константа такой, что, .

![{\displaystyle \mathbb {E} [{\tilde {m}}_{n}^{uf}(\mathbf {X}) -m (\mathbf {X})]^{2}\leq Cn^{ -2/(6+3d\log 2)}(\log n)^{2}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/51b3c9f4980f936fc01a73621cc56e9857059da4)
Недостатки [ править ]
Хотя случайные леса часто достигают более высокой точности, чем одно дерево решений, они жертвуют внутренней интерпретируемостью, присущей деревьям решений. Деревья решений относятся к довольно небольшому семейству моделей машинного обучения, которые легко интерпретируются наряду с линейными моделями, моделями , основанными на правилах , и моделями, основанными на внимании . Эта интерпретируемость является одним из наиболее желательных качеств деревьев решений. Это позволяет разработчикам подтвердить, что модель извлекла из данных реалистичную информацию, а конечным пользователям доверять решениям, принятым моделью. [37] [3] Например, проследить путь, по которому дерево решений принимает свое решение, довольно тривиально, но проследить пути десятков или сотен деревьев гораздо сложнее. Чтобы добиться как производительности, так и интерпретируемости, некоторые методы сжатия модели позволяют преобразовать случайный лес в минимальное «возрожденное» дерево решений, которое точно воспроизводит одну и ту же функцию принятия решений. [37] [47] [48] Если установлено, что прогностические атрибуты линейно коррелируют с целевой переменной, использование случайного леса может не повысить точность базового обучаемого. [37] [40] Более того, в задачах с несколькими категориальными переменными случайный лес может не повысить точность базового обучаемого. [49]
См. также [ править ]
- Повышение — метод машинного обучения
- Обучение дереву решений – алгоритм машинного обучения
- Ансамблевое обучение – статистика и техника машинного обучения
- Повышение градиента — техника машинного обучения
- Непараметрическая статистика . Раздел статистики, основанный не только на параметризованных семействах вероятностных распределений.
- Рандомизированный алгоритм - алгоритм, который использует определенную степень случайности как часть своей логики или процедуры.
Ссылки [ править ]
- ^ Jump up to: Перейти обратно: а б с д Хо, Тин Кам (1995). Леса случайных решений (PDF) . Материалы 3-й Международной конференции по анализу и распознаванию документов, Монреаль, Квебек, 14–16 августа 1995 г., стр. 278–282. Архивировано из оригинала (PDF) 17 апреля 2016 года . Проверено 5 июня 2016 г.
- ^ Jump up to: Перейти обратно: а б с д Хо ТК (1998). «Метод случайного подпространства для построения лесов решений» (PDF) . Транзакции IEEE по анализу шаблонов и машинному интеллекту . 20 (8): 832–844. дои : 10.1109/34.709601 . S2CID 206420153 .
- ^ Jump up to: Перейти обратно: а б с д и ж г Хасти, Тревор ; Тибширани, Роберт ; Фридман, Джером (2008). Элементы статистического обучения (2-е изд.). Спрингер. ISBN 0-387-95284-5 .
- ^ Jump up to: Перейти обратно: а б Кляйнберг Э (1990). «Стохастическая дискриминация» (PDF) . Анналы математики и искусственного интеллекта . 1 (1–4): 207–239. CiteSeerX 10.1.1.25.6750 . дои : 10.1007/BF01531079 . S2CID 206795835 . Архивировано из оригинала (PDF) 18 января 2018 г.
- ^ Jump up to: Перейти обратно: а б Кляйнберг Э (1996). «Метод стохастического моделирования для распознавания образов, устойчивый к перетренировке» . Анналы статистики . 24 (6): 2319–2349. дои : 10.1214/aos/1032181157 . МР 1425956 .
- ^ Jump up to: Перейти обратно: а б Кляйнберг Э (2000). «Об алгоритмической реализации стохастической дискриминации» (PDF) . Транзакции IEEE по анализу шаблонов и машинному интеллекту . 22 (5): 473–490. CiteSeerX 10.1.1.33.4131 . дои : 10.1109/34.857004 . S2CID 3563126 . Архивировано из оригинала (PDF) 18 января 2018 г.
- ^ Jump up to: Перейти обратно: а б с д Брейман Л. (2001). «Случайные леса» . Машинное обучение . 45 (1): 5–32. Бибкод : 2001MachL..45....5B . дои : 10.1023/А:1010933404324 .
- ^ Jump up to: Перейти обратно: а б Лиав А (16 октября 2012 г.). «Документация для пакета R RandomForest» (PDF) . Проверено 15 марта 2013 г.
- ^ Регистрационный номер товарного знака в США 3185828, зарегистрирован 19 декабря 2006 г.
- ^ «Торговая марка RANDOM FORESTS компании Health Care Productivity, Inc. — Регистрационный номер 3185828 — Серийный номер 78642027 :: Торговые марки Justia» .
- ^ Jump up to: Перейти обратно: а б Амит Ю, Геман Д (1997). «Квантование и распознавание формы с помощью рандомизированных деревьев» (PDF) . Нейронные вычисления . 9 (7): 1545–1588. CiteSeerX 10.1.1.57.6069 . дои : 10.1162/neco.1997.9.7.1545 . S2CID 12470146 . Архивировано из оригинала (PDF) 5 февраля 2018 г. Проверено 1 апреля 2008 г.
- ^ Хит Д., Касиф С. и Зальцберг С. (1993). k-DT: метод обучения с несколькими деревьями. В материалах второго международного заседания. Семинар по мультистратегическому обучению , стр. 138-149.
- ^ Диттерих, Томас (2000). «Экспериментальное сравнение трех методов построения ансамблей деревьев решений: пакетирование, повышение и рандомизация» . Машинное обучение . 40 (2): 139–157. дои : 10.1023/А:1007607513941 .
- ^ Гарет Джеймс; Даниэла Виттен; Тревор Хэсти; Роберт Тибширани (2013). Введение в статистическое обучение . Спрингер. стр. 316–321.
- ^ Хо, Тин Кам (2002). «Анализ сложности данных сравнительных преимуществ конструкторов леса решений» (PDF) . Анализ шаблонов и приложения . 5 (2): 102–112. дои : 10.1007/s100440200009 . S2CID 7415435 . Архивировано из оригинала (PDF) 17 апреля 2016 г. Проверено 13 ноября 2015 г.
- ^ Гертс П., Эрнст Д., Вехенкель Л. (2006). «Чрезвычайно рандомизированные деревья» (PDF) . Машинное обучение . 63 : 3–42. дои : 10.1007/s10994-006-6226-1 .
- ^ Десси, Н., Милия, Г. и Пес, Б. (2013). Повышение производительности случайных лесов при классификации данных микрочипов. Документ конференции, 99-103. 10.1007/978-3-642-38326-7_15.
- ^ Йе, Ю., Ли, Х., Денг, Х. и Хуанг, Дж. (2008) Случайный лес взвешивания функций для обнаружения скрытых интерфейсов веб-поиска. Журнал компьютерной лингвистики и обработки китайского языка, 13, 387–404.
- ^ Амаратунга, Д., Кабрера, Дж., Ли, Ю.С. (2008) Обогащенный случайный лес. Биоинформатика, 24, 2010-2014.
- ^ Гош Д., Кабрера Дж. (2022) Обогащенный случайный лес для многомерных геномных данных. IEEE/ACM Транскомпьютер Биол Биоинформ. 19(5):2817-2828. doi:10.1109/TCBB.2021.3089417.
- ^ Уинхэм, Стейси и Фреймут, Роберт и Бирнака, Джоанна. (2013). Подход с использованием взвешенных случайных лесов для повышения эффективности прогнозирования. Статистический анализ и интеллектуальный анализ данных. 6. 10.1002/сэм.11196.
- ^ Ли, Х.Б., Ван, В., Дин, Х.В., и Донг, Дж. (2010, 10–12 ноября 2010 г.). Метод случайного леса с взвешиванием деревьев для классификации многомерных зашумленных данных. Доклад, представленный на 7-й Международной конференции IEEE по разработке электронного бизнеса в 2010 году.
- ^ Чжу Р., Цзэн Д., Косорок М.Р. (2015). «Деревья обучения с подкреплением» . Журнал Американской статистической ассоциации . 110 (512): 1770–1784. дои : 10.1080/01621459.2015.1036994 . ПМК 4760114 . ПМИД 26903687 .
- ^ Дэн, Х.; Рангер, Г.; Тув, Э. (2011). Смещение показателей важности для многозначных атрибутов и решений . Материалы 21-й Международной конференции по искусственным нейронным сетям (ICANN). стр. 293–300.
- ^ Альтманн А., Толоши Л., Сандер О., Ленгауэр Т. (май 2010 г.). «Важность перестановки: исправленная мера важности функции» . Биоинформатика . 26 (10): 1340–7. doi : 10.1093/биоинформатика/btq134 . ПМИД 20385727 .
- ^ Пирионеси С. Маде; Эль-Дираби Тамер Э. (01.06.2020). «Роль анализа данных в управлении инфраструктурными активами: преодоление проблем с размером и качеством данных». Журнал транспортной техники, Часть B: Тротуары . 146 (2): 04020022. doi : 10.1061/JPEODX.0000175 . S2CID 216485629 .
- ^ Штробль С., Булестейкс А.Л., Огюстен Т. (2007). «Непредвзятый разделенный выбор для деревьев классификации на основе индекса Джини» (PDF) . Вычислительная статистика и анализ данных . 52 : 483–501. CiteSeerX 10.1.1.525.3178 . дои : 10.1016/j.csda.2006.12.030 .
- ^ Паинский А., Россет С. (2017). «Выбор переменных с перекрестной проверкой в древовидных методах повышает эффективность прогнозирования». Транзакции IEEE по анализу шаблонов и машинному интеллекту . 39 (11): 2142–2153. arXiv : 1512.03444 . дои : 10.1109/tpami.2016.2636831 . ПМИД 28114007 . S2CID 5381516 .
- ^ Толоси Л., Ленгауэр Т. (июль 2011 г.). «Классификация с коррелирующими признаками: ненадежность ранжирования признаков и решений» . Биоинформатика . 27 (14): 1986–94. doi : 10.1093/биоинформатика/btr300 . ПМИД 21576180 .
- ^ Jump up to: Перейти обратно: а б «Остерегайтесь случайных значений леса по умолчанию» . объяснил.ai . Проверено 25 октября 2023 г.
- ^ Брейман, Лео (25 октября 2017 г.). Деревья классификации и регрессии . Нью-Йорк: Рутледж. дои : 10.1201/9781315139470 . ISBN 978-1-315-13947-0 .
- ^ Ортис-Посадас, Марта Рефухио (29 февраля 2020 г.). Методы распознавания образов, применяемые к биомедицинским проблемам . Спрингер Природа. ISBN 978-3-030-38021-2 .
- ^ https://scikit-learn.org/stable/auto_examples/inspection/plot_permutation_importance.html 31 августа 2023 г.
- ^ Jump up to: Перейти обратно: а б Лин, Йи; Чон, Ёнхо (2002). Случайные леса и адаптивные ближайшие соседи (Технический отчет). Технический отчет № 1055. Университет Висконсина. CiteSeerX 10.1.1.153.9168 .
- ^ Ши, Т.; Хорват, С. (2006). «Обучение без учителя со случайными лесными предикторами». Журнал вычислительной и графической статистики . 15 (1): 118–138. CiteSeerX 10.1.1.698.2365 . дои : 10.1198/106186006X94072 . JSTOR 27594168 . S2CID 245216 .
- ^ Ши Т., Селигсон Д., Белльдегрун А.С., Палоти А., Хорват С. (апрель 2005 г.). «Классификация опухолей с помощью профилирования тканевых микрочипов: случайная лесная кластеризация применительно к почечно-клеточному раку» . Современная патология . 18 (4): 547–57. doi : 10.1038/modpathol.3800322 . ПМИД 15529185 .
- ^ Jump up to: Перейти обратно: а б с д и Пирионеси, С. Маде; Эль-Дираби, Тамер Э. (01 февраля 2021 г.). «Использование машинного обучения для изучения влияния типа индикатора производительности на моделирование разрушения гибкого покрытия» . Журнал инфраструктурных систем . 27 (2): 04021005. doi : 10.1061/(ASCE)IS.1943-555X.0000602 . ISSN 1076-0342 . S2CID 233550030 .
- ^ Принци, А.; Ван ден Поэль, Д. (2008). «Случайные леса для многоклассовой классификации: случайный многономиальный логит». Экспертные системы с приложениями . 34 (3): 1721–1732. дои : 10.1016/j.eswa.2007.01.029 .
- ^ Принци, Анита (2007). «Случайная мультиклассовая классификация: обобщение случайных лесов на случайные MNL и случайные NB». У Роланда Вагнера; Норман Ревелл; Гюнтер Пернул (ред.). Приложения баз данных и экспертных систем: 18-я Международная конференция, DEXA 2007, Регенсбург, Германия, 3-7 сентября 2007 г., Материалы . Конспекты лекций по информатике. Том. 4653. стр. 349–358. дои : 10.1007/978-3-540-74469-6_35 . ISBN 978-3-540-74467-2 .
- ^ Jump up to: Перейти обратно: а б Смит, Пол Ф.; Ганеша, Шива; Лю, Пин (01 октября 2013 г.). «Сравнение случайной лесной регрессии и множественной линейной регрессии для прогнозирования в нейробиологии» . Журнал методов нейробиологии . 220 (1): 85–91. doi : 10.1016/j.jneumeth.2013.08.024 . ПМИД 24012917 . S2CID 13195700 .
- ^ Jump up to: Перейти обратно: а б с д Скорнет, Эрван (2015). «Случайные леса и методы ядра». arXiv : 1502.03836 [ math.ST ].
- ^ Брейман, Лео (2000). «Немного теории бесконечности для ансамблей предикторов» . Технический отчет 579, Статистический отдел UCB.
{{cite journal}}: Для цитирования журнала требуется|journal=( помощь ) - ^ Лин, Йи; Чон, Ёнхо (2006). «Случайные леса и адаптивные ближайшие соседи». Журнал Американской статистической ассоциации . 101 (474): 578–590. CiteSeerX 10.1.1.153.9168 . дои : 10.1198/016214505000001230 . S2CID 2469856 .
- ^ Дэвис, Алекс; Гахрамани, Зубин (2014). «Ядро случайного леса и другие ядра для больших данных из случайных разделов». arXiv : 1402.4293 [ stat.ML ].
- ^ Jump up to: Перейти обратно: а б Брейман Л., Гахрамани З. (2004). «Согласованность простой модели случайных лесов». Статистический факультет Калифорнийского университета в Беркли. Технический отчет (670). CiteSeerX 10.1.1.618.90 .
- ^ Jump up to: Перейти обратно: а б Арлот С., Дженуер Р. (2014). «Анализ чисто случайной предвзятости лесов». arXiv : 1407.3939 [ math.ST ].
- ^ Саги, Омер; Рокач, Лиор (2020). «Объяснимый лес решений: Преобразование леса решений в интерпретируемое дерево» . Информационный синтез . 61 : 124–138. дои : 10.1016/j.inffus.2020.03.013 . S2CID 216444882 .
- ^ Видаль, Тибо; Шиффер, Максимилиан (2020). «Возрожденные древесные ансамбли» . Международная конференция по машинному обучению . 119 . ПМЛР: 9743–9753. arXiv : 2003.11132 .
- ^ Пирионеси, Сайед Маде (ноябрь 2019 г.). Применение анализа данных для управления активами: ухудшение состояния и адаптация к изменению климата на дорогах Онтарио (Докторская диссертация) (Диссертация).
Дальнейшее чтение [ править ]
- Принци А., Поэль Д. (2007). «Случайная мультиклассовая классификация: обобщение случайных лесов на случайные MNL и случайные NB» . Приложения баз данных и экспертных систем . Конспекты лекций по информатике . Том. 4653. с. 349. дои : 10.1007/978-3-540-74469-6_35 . ISBN 978-3-540-74467-2 .
- Дениско Д., Хоффман М.М. (февраль 2018 г.). «Классификация и взаимодействие в случайных лесах» . Труды Национальной академии наук Соединенных Штатов Америки . 115 (8): 1690–1692. Бибкод : 2018PNAS..115.1690D . дои : 10.1073/pnas.1800256115 . ПМЦ 5828645 . ПМИД 29440440 .
Внешние ссылки [ править ]
- Описание классификатора случайных лесов (сайт Лео Бреймана)
- Лио, Энди и Винер, Мэтью «Классификация и регрессия с помощью randomForest» R News (2002) Vol. 2/3 р. 18 (Обсуждение использования пакета случайного леса для R )