Внимание (машинное обучение)
| Часть серии о |
| Машинное обучение и интеллектуальный анализ данных |
|---|
машинном обучении, , основанный на Метод внимания имитирует работу человеческого внимания , присваивая разным уровням важности разные слова в предложении. Он присваивает важность каждому слову путем расчета «мягких» весов для числового представления слова, известного как его встраивание , в определенный раздел предложения, называемый контекстным окном, для определения его важности. Вычисление этих весов может происходить одновременно в моделях, называемых трансформаторами , или по одному в моделях, известных как рекуррентные нейронные сети . В отличие от «жестких» весов, которые заранее определяются и фиксируются во время тренировки, «мягкие» веса могут адаптироваться и меняться при каждом использовании модели.
Внимание было обращено на устранение недостатков использования информации со скрытых выходов рекуррентных нейронных сетей. Рекуррентные нейронные сети отдают предпочтение более свежей информации, содержащейся в словах в конце предложения, тогда как ожидается, что информация в начале предложения будет ослаблена . Внимание позволяет вычислить скрытое представление токена, равное доступу к любой части предложения напрямую, а не только через предыдущее скрытое состояние.
Ранее использование этого механизма прикрепляло этот механизм к системе языкового перевода последовательной рекуррентной нейронной сети (ниже), но более позднее использование в больших языковых моделях Transformers удалило рекуррентную нейронную сеть и в значительной степени полагалось на более быструю схему параллельного внимания.
Предшественники [ править ]
Предшественники механизма использовались в рекуррентных нейронных сетях , которые, однако, вычисляли «мягкие» веса последовательно и на каждом шаге учитывали текущее слово и другие слова в пределах контекстного окна. Они были известны как мультипликативные модули , сигма-пи . [1] и гиперсети . [2] Они использовались в сетях долговременной краткосрочной памяти (LSTM), мультисенсорной обработке данных (звука, изображений, видео и текста) в воспринимающих устройствах , быстрой памяти контроллера веса, [3] задачи рассуждения в дифференцируемых нейронных компьютерах и нейронных машинах Тьюринга . [4] [5] [6] [7] [8]
Основные расчеты [ править ]
Сеть внимания была разработана для выявления наиболее высоких корреляций между словами в предложении, при условии, что она усвоила эти шаблоны из обучающего корпуса. Эта корреляция фиксируется в весах нейронов посредством обратного распространения ошибки либо в результате предварительной тренировки с самоконтролем , либо в результате контролируемой точной настройки.
В приведенном ниже примере (вариант сети внимания QKV только для кодировщика) показано, как корреляции идентифицируются после того, как сеть обучена и имеет правильные веса. Глядя на слово «это» в предложении «вижу, как бежит девушка», сеть должна быть в состоянии идентифицировать «девушку» как сильно коррелированное слово. Для простоты в этом примере основное внимание уделяется слову «это», но на самом деле все слова обрабатываются параллельно, и полученные мягкие веса и векторы контекста складываются в матрицы для дальнейшего использования для конкретной задачи.

Предложение передается через три параллельных потока (слева), которые в конце появляются как вектор контекста (справа). Размер встраивания слова составляет 300, а количество нейронов — 100 в каждой подсети головы внимания.
- Заглавная буква X обозначает матрицу размером 4×300, состоящую из вложений всех четырех слов.
- Маленькая подчеркнутая буква x обозначает вектор внедрения (размером 300) слова «это».
- три (расположенные на рисунке вертикально) подсети, каждая из которых имеет 100 нейронов, имеющих Wq Голова внимания включает , Wk Wv и . 100 соответствующие весовые матрицы, все они имеют размер 300 ×
- q (от «запрос») — вектор размером 100, K («ключ») и V («значение») — матрицы 4x100.
- Звездочка в скобках « (*) » обозначает softmax( qW k / √ 100 ) . Результатом Softmax является вектор размером 4, который позже умножается на матрицу V=XW v для получения вектора контекста.
- Изменение масштаба на √ 100 предотвращает высокую дисперсию qW k. Т это позволило бы одному слову чрезмерно доминировать в мягком максимуме, что привело бы к вниманию только к одному слову, как это сделал бы дискретный жесткий максимум.
Обозначение для строк, : широко написанная формула softmax приведенная выше, предполагает, что векторы являются строками, что противоречит стандартным математическим обозначениям векторов-столбцов. Точнее, нам следует взять транспонирование вектора контекста и использовать softmax по столбцам , что приведет к более правильной форме.
запроса Вектор сравнивается (через скалярное произведение) с каждым словом в ключах. Это помогает модели обнаружить наиболее подходящее слово для слова запроса. В данном случае слово «девушка» было определено как наиболее подходящее слово для слова «это». Результат (в данном случае размер 4) обрабатывается функцией softmax , создавая вектор размера 4 с суммой вероятностей, равной 1. Умножение этого значения на матрицу значений эффективно усиливает сигнал для наиболее важных слов в предложении и уменьшает сигнал. для менее важных слов. [5]
Структура входных данных фиксируется весами W q и W k , а веса W v выражают эту структуру с точки зрения более значимых функций для задачи, для которой проводится обучение. По этой причине компоненты «головы внимания» называются «Запрос» ( W q ), «Ключ» ( W k ) и «Значение» ( W v ) — это неопределенная и, возможно, вводящая в заблуждение аналогия с системами реляционных баз данных .
Обратите внимание, что вектор контекста для слова «это» не зависит от векторов контекста для других слов; поэтому векторы контекста всех слов можно вычислить с использованием всей матрицы X , которая включает в себя все вложения слов, вместо вектора встраивания одного слова x в приведенной выше формуле, что позволяет распараллелить вычисления. Теперь softmax можно интерпретировать как softmax матрицы, действующей на отдельные строки. Это огромное преимущество перед рекуррентными сетями , которые должны работать последовательно.
Общая аналогия ключа запроса с запросами к базе данных предполагает асимметричную роль этих векторов, когда один интересующий элемент (запрос) сопоставляется со всеми возможными элементами (ключами). Однако параллельные вычисления сопоставляют все слова предложения сами с собой; поэтому роли этих векторов симметричны. Возможно, из-за того, что упрощенная аналогия с базой данных ошибочна, много усилий было потрачено на дальнейшее понимание внимания путем изучения его роли в целенаправленных условиях, таких как контекстное обучение, [9] языковые задания в масках, [10] разобранные трансформаторы, [11] статистика биграмм, [12] парные свертки, [13] и арифметический факторинг. [14]
Пример языкового перевода [ править ]
Чтобы построить машину, которая переводит с английского на французский, к базовому кодировщику-декодеру прикрепляют блок внимания (схема ниже). В простейшем случае единица внимания состоит из скалярных произведений рекуррентных состояний кодера и не нуждается в обучении. На практике блок внимания состоит из трех обученных, полностью связанных слоев нейронной сети, называемых запросом, ключом и значением.
![Кодер-декодер с вниманием.[15] Левая часть (черные линии) — это кодер-декодер, средняя часть (оранжевые линии) — единица внимания, а правая часть (серый и цветной) — вычисляемые данные. Серые области в матрице H и векторе w имеют нулевые значения. Числовые индексы указывают размеры векторов, а буквенные индексы i и i - 1 указывают временные шаги.](http://upload.wikimedia.org/wikipedia/commons/f/f7/Attention-1-sn.png)
Если рассматривать их в виде матрицы, веса внимания показывают, как сеть корректирует свой фокус в зависимости от контекста. [17]
| я | любовь | ты | |
| является | 0.94 | 0.02 | 0.04 |
| т' | 0.11 | 0.01 | 0.88 |
| любовь | 0.03 | 0.95 | 0.02 |
Этот взгляд на веса внимания решает проблему « объяснимости » нейронной сети. Сети, выполняющие дословный перевод без учета порядка слов, покажут самые высокие баллы по (доминирующей) диагонали матрицы. Недиагональное доминирование показывает, что механизм внимания более тонкий. При первом проходе через декодер 94% веса внимания приходится на первое английское слово «I», поэтому сеть предлагает слово «je». На втором проходе декодера 88% внимания приходится на третье английское слово «you», поэтому оно предлагает «t». На последнем проходе 95% внимания приходится на второе английское слово «love», поэтому оно предлагает «aime».
Варианты [ править ]
Многие варианты внимания реализуют мягкие веса, такие как
- «внутренние прожекторы внимания» [18] созданные быстрыми программистами веса или быстрыми контроллерами веса (1992) [3] (также известные как преобразователи с «линеаризованным самовниманием» [19] [20] ). Медленная нейронная сеть учится путем градиентного спуска программировать быстрые веса другой нейронной сети через внешние продукты самогенерируемых шаблонов активации, называемых «ОТ» и «ДО», которые в терминологии преобразователей называются «ключом» и «значением». Это быстрое «отображение внимания» применяется к запросам.
- По-Богданову будь осторожен, [17] также называемое аддитивным вниманием ,
- Внимание в стиле Луонг, [21] которое известно как мультипликативное внимание ,
- высокораспараллеливаемое внимание к себе, представленное в 2016 году как разлагаемое внимание [22] успешно использовался в трансформаторах . и год спустя
Для сверточных нейронных сетей механизмы внимания можно различать по измерению, в котором они работают, а именно: пространственное внимание, [23] канал внимания, [24] или комбинации. [25] [26]
Эти варианты рекомбинируют входные данные на стороне кодера для перераспределения этих эффектов на каждый целевой выход. Часто матрица скалярных произведений в стиле корреляции обеспечивает коэффициенты повторного взвешивания. На рисунках ниже W — это матрица весов контекстного внимания, аналогичная формуле, приведенной в разделе «Основные расчеты» выше.
| 1. скалярное произведение кодер-декодер | 2. кодер-декодер QKV | 3. скалярное произведение только для кодировщика | 4. QKV только для энкодера | 5. Учебное пособие по Pytorch |
|---|---|---|---|---|
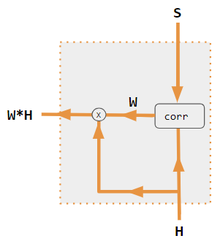 |  | 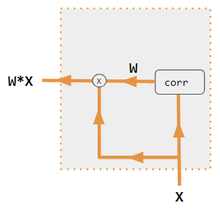 |  | 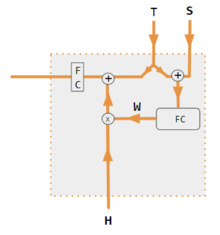 |
Математическое представление [ править ]
стандартное масштабированное скалярное Внимание , произведение




Многоголовое внимание [ править ]




Богданау (Присадка) Внимание [ править ]




Луонг Внимание (общее) [ править ]


См. также [ править ]
Ссылки [ править ]
- ^ Румельхарт, Дэвид Э.; Макклелланд, Джеймс Л.; Группа, PDP Research (29 июля 1987 г.). Параллельная распределенная обработка, Том 1: Исследования микроструктуры познания: Основы, Глава 2 (PDF) . Кембридж, Массачусетс: Bradford Books. ISBN 978-0-262-68053-0 .
- ^ Янн Лекун (2020). Курс глубокого обучения в Нью-Йоркском университете, весна 2020 г., видеолекции, 6-я неделя . Событие происходит в 53:00 . Проверено 8 марта 2022 г.
- ^ Jump up to: Перейти обратно: а б Шмидхубер, Юрген (1992). «Научимся контролировать быстрые воспоминания: альтернатива повторяющимся сетям». Нейронные вычисления . 4 (1): 131–139. дои : 10.1162/neco.1992.4.1.131 . S2CID 16683347 .
- ^ Грейвс, Алекс; Уэйн, Грег; Рейнольдс, Малькольм; Харли, Тим; Данигелька, Иво; Грабская-Барвинская, Агнешка; Кольменарехо, Серхио Гомес; Грефенштетт, Эдвард; Рамальо, Тьяго; Агапиу, Джон; Бадия, Адриа Пучдоменек; Герман, Карл Мориц; Зволс, Йори; Островский, Георг; Каин, Адам; Король, Хелен; Саммерфилд, Кристофер; Блансом, Фил; Кавукчуоглу, Корай; Хассабис, Демис (12 октября 2016 г.). «Гибридные вычисления с использованием нейронной сети с динамической внешней памятью» . Природа . 538 (7626): 471–476. Бибкод : 2016Natur.538..471G . дои : 10.1038/nature20101 . ISSN 1476-4687 . ПМИД 27732574 . S2CID 205251479 .
- ^ Jump up to: Перейти обратно: а б Васвани, Ашиш ; Шазир, Ноам; Пармар, Ники; Ушкорейт, Якоб; Джонс, Лион; Гомес, Эйдан Н ; Кайзер, Лукаш; Полосухин, Илья (2017). «Внимание — это все, что вам нужно» (PDF) . Достижения в области нейронных систем обработки информации . 30 . Карран Ассошиэйтс, Инк.
- ^ Рамачандран, Праджит; Пармар, Ники; Васвани, Ашиш; Белло, Ирван; Левская, Ансельм; Шленс, Джонатон (13 июня 2019 г.). «Автономное внимание к себе в моделях видения». arXiv : 1906.05909 [ cs.CV ].
- ^ Джегл, Эндрю; Гимено, Феликс; Брок, Эндрю; Зиссерман, Эндрю; Виньялс, Ориол; Каррейра, Жоау (22 июня 2021 г.). «Воспринимающий: общее восприятие с повторяющимся вниманием». arXiv : 2103.03206 [ cs.CV ].
- ^ Рэй, Тирнан. «Супермодель Google: DeepMind Perceiver — это шаг на пути к машине искусственного интеллекта, которая сможет обрабатывать всё и вся» . ЗДНет . Проверено 19 августа 2021 г.
- ^ Чжан, Жуйци (2024). «Обученные трансформаторы изучают линейные модели в контексте» (PDF) . Журнал исследований машинного обучения 1-55 . 25 . arXiv : 2306.09927 .
- ^ Ренде, Риккардо (2024). «Сопоставление механизмов внимания с обобщенной моделью Поттса». Обзор физических исследований . 6 (2): 023057. arXiv : 2304.07235 . Бибкод : 2024PhRvR...6b3057R . doi : 10.1103/PhysRevResearch.6.023057 .
- ^ Он, Бобби (2023). «Упрощение блоков-трансформеров». arXiv : 2311.01906 [ cs.LG ].
- ^ «Трансформаторные схемы» . Transformer-circuits.pub .
- ^ Нейронная сеть-трансформер, созданная с нуля . 2023 год. Событие происходит в 05:30 . Проверено 7 апреля 2024 г.
- ^ Чартон, Франсуа (2023). «Изучение наибольшего общего делителя: объяснение предсказаний трансформатора». arXiv : 2308.15594 [ cs.LG ].
- ^ Бритц, Денни; Голди, Анна; Луонг, Минь-Тхань; Ле, Куок (21 марта 2017 г.). «Массовое исследование архитектур нейронного машинного перевода». arXiv : 1703.03906 [ cs.CV ].
- ^ «Учебное пособие по seq2seq на Pytorch.org» . Проверено 2 декабря 2021 г.
- ^ Jump up to: Перейти обратно: а б с Богданов Дмитрий; Чо, Кёнхён; Бенджио, Йошуа (2014). «Нейронный машинный перевод путем совместного обучения выравниванию и переводу». arXiv : 1409.0473 [ cs.CL ].
- ^ Шмидхубер, Юрген (1993). «Уменьшение соотношения между сложностью обучения и количеством изменяющихся во времени переменных в полностью рекуррентных сетях». ИКАНН, 1993 год . Спрингер. стр. 460–463.
- ^ Шлаг, Иманол ; Ириэ, Кадзуки; Шмидхубер, Юрген (2021). «Линейные трансформаторы — тайно быстрые программисты веса». ICML 2021 . Спрингер. стр. 9355–9366.
- ^ Хороманский, Кшиштоф; Лихошерстов Валерий; Дохан, Дэвид; Сун, Синъю; Гейн, Андреа; Сарлос, Тамас; Хокинс, Питер; Дэвис, Джаред; Мохиуддин, Афроз; Кайзер, Лукаш; Беланджер, Дэвид; Колвелл, Люси; Веллер, Адриан (2020). «Переосмысление внимания с исполнителями». arXiv : 2009.14794 [ cs.CL ].
- ^ Jump up to: Перейти обратно: а б с Луонг, Минь-Тхан (20 сентября 2015 г.). «Эффективные подходы к нейронному машинному переводу, основанному на внимании». arXiv : 1508.04025v5 [ cs.CL ].
- ^ «Документы с кодом — разложимая модель внимания для вывода на естественном языке» . paperswithcode.com .
- ^ Чжу, Сичжоу; Ченг, Дажи; Чжан, Чжэн; Лин, Стивен; Дай, Цзифэн (2019). «Эмпирическое исследование механизмов пространственного внимания в глубоких сетях» . Международная конференция IEEE/CVF по компьютерному зрению (ICCV) 2019 . стр. 6687–6696. arXiv : 1904.05873 . дои : 10.1109/ICCV.2019.00679 . ISBN 978-1-7281-4803-8 . S2CID 118673006 .
- ^ Ху, Цзе; Шен, Ли; Солнце, Банда (2018). «Сети сжатия и возбуждения» . Конференция IEEE/CVF 2018 по компьютерному зрению и распознаванию образов . стр. 7132–7141. arXiv : 1709.01507 . дои : 10.1109/CVPR.2018.00745 . ISBN 978-1-5386-6420-9 . S2CID 206597034 .
- ^ Уу, Санхён; Пак, Чончан; Ли, Джун-Ён; Квеон, Ин Со (18 июля 2018 г.). «CBAM: Модуль внимания сверточного блока». arXiv : 1807.06521 [ cs.CV ].
- ^ Георгеску, Мариана-Юлиана; Ионеску, Раду Тудор; Мирон, Андреа-Юлиана; Савенку, Оливиан; Ристеа, Николае-Каталин; Верга, Николае; Хан, Фахад Шахбаз (12 октября 2022 г.). «Мультимодальное многоголовое сверточное внимание с различными размерами ядер для сверхразрешения медицинских изображений». arXiv : 2204.04218 [ eess.IV ].
- ^ Нил Роудс (2021). CS 152 NN-27: Внимание: ключи, запросы и значения . Событие происходит в 06:30 . Проверено 22 декабря 2021 г.
- ^ Альфредо Канциани и Янн Лекун (2021). Курс глубокого обучения Нью-Йоркского университета, весна 2020 г. Событие происходит в 05:30 . Проверено 22 декабря 2021 г.
- ^ Альфредо Канциани и Янн Лекун (2021). Курс глубокого обучения Нью-Йоркского университета, весна 2020 г. Событие происходит в 20:15 . Проверено 22 декабря 2021 г.
- ^ Робертсон, Шон. «НЛП с нуля: перевод с помощью сети последовательностей и внимания» . pytorch.org . Проверено 22 декабря 2021 г.
Внешние ссылки [ править ]
- Дэн Джурафски и Джеймс Х. Мартин (2022 г.) Обработка речи и языка (проект 3-го изд., январь 2022 г.) , гл. 10.4 Внимание и гл. 9.7 Сети самообслуживания: преобразователи
- Алекс Грейвс (4 мая 2020 г.), Внимание и память в глубоком обучении (видеолекция), DeepMind / UCL , через YouTube
Дифференцируемые вычисления |
|---|