Сверточная нейронная сеть
Эта статья нуждается в дополнительных цитатах для проверки . ( июнь 2019 г. ) |
| Часть серии о |
| Машинное обучение и интеллектуальный анализ данных |
|---|
Сверточная нейронная сеть ( CNN ) — это регуляризованный тип нейронной сети с прямой связью изучает разработку функций , которая самостоятельно посредством оптимизации фильтров (или ядра). Исчезающие и взрывные градиенты, наблюдаемые во время обратного распространения ошибки в более ранних нейронных сетях, предотвращаются за счет использования регуляризованных весов для меньшего количества соединений. [1] [2] Например, для каждого нейрона полносвязного слоя потребуется 10 000 весов для обработки изображения размером 100 × 100 пикселей. Однако, применяя ядра каскадной свертки (или взаимной корреляции), [3] [4] для обработки плиток размером 5x5 требуется всего 25 нейронов. [5] [6] Функции более высокого уровня извлекаются из более широких контекстных окон по сравнению с функциями более низкого уровня.
У них есть приложения:
- распознавание изображений и видео , [7]
- рекомендательные системы , [8]
- классификация изображений ,
- сегментация изображений ,
- анализ медицинских изображений ,
- обработка естественного языка , [9]
- интерфейсы мозг-компьютер , [10] и
- financial time series.[11]
CNNs are also known as shift invariant or space invariant artificial neural networks (SIANN), based on the shared-weight architecture of the convolution kernels or filters that slide along input features and provide translation-equivariant responses known as feature maps.[12][13] Counter-intuitively, most convolutional neural networks are not invariant to translation, due to the downsampling operation they apply to the input.[14]
Feed-forward neural networks are usually fully connected networks, that is, each neuron in one layer is connected to all neurons in the next layer. The "full connectivity" of these networks makes them prone to overfitting data. Typical ways of regularization, or preventing overfitting, include: penalizing parameters during training (such as weight decay) or trimming connectivity (skipped connections, dropout, etc.) Robust datasets also increase the probability that CNNs will learn the generalized principles that characterize a given dataset rather than the biases of a poorly-populated set.[15]
Convolutional networks were inspired by biological processes[16][17][18][19] in that the connectivity pattern between neurons resembles the organization of the animal visual cortex. Individual cortical neurons respond to stimuli only in a restricted region of the visual field known as the receptive field. The receptive fields of different neurons partially overlap such that they cover the entire visual field.
CNNs use relatively little pre-processing compared to other image classification algorithms. This means that the network learns to optimize the filters (or kernels) through automated learning, whereas in traditional algorithms these filters are hand-engineered. This independence from prior knowledge and human intervention in feature extraction is a major advantage.[to whom?]
Architecture[edit]
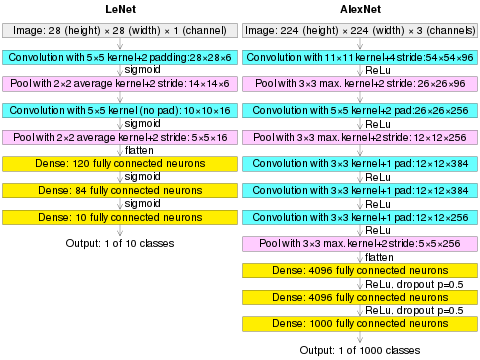
(AlexNet image size should be 227×227×3, instead of 224×224×3, so the math will come out right. The original paper said different numbers, but Andrej Karpathy, the head of computer vision at Tesla, said it should be 227×227×3 (he said Alex didn't describe why he put 224×224×3). The next convolution should be 11×11 with stride 4: 55×55×96 (instead of 54×54×96). It would be calculated, for example, as: [(input width 227 - kernel width 11) / stride 4] + 1 = [(227 - 11) / 4] + 1 = 55. Since the kernel output is the same length as width, its area is 55×55.)
A convolutional neural network consists of an input layer, hidden layers and an output layer. In a convolutional neural network, the hidden layers include one or more layers that perform convolutions. Typically this includes a layer that performs a dot product of the convolution kernel with the layer's input matrix. This product is usually the Frobenius inner product, and its activation function is commonly ReLU. As the convolution kernel slides along the input matrix for the layer, the convolution operation generates a feature map, which in turn contributes to the input of the next layer. This is followed by other layers such as pooling layers, fully connected layers, and normalization layers.Here it should be noted how close a convolutional neural network is to a matched filter.[20]
Convolutional layers[edit]
In a CNN, the input is a tensor with shape:
(number of inputs) × (input height) × (input width) × (input channels)
After passing through a convolutional layer, the image becomes abstracted to a feature map, also called an activation map, with shape:
(number of inputs) × (feature map height) × (feature map width) × (feature map channels).
Convolutional layers convolve the input and pass its result to the next layer. This is similar to the response of a neuron in the visual cortex to a specific stimulus.[21] Each convolutional neuron processes data only for its receptive field.

Although fully connected feedforward neural networks can be used to learn features and classify data, this architecture is generally impractical for larger inputs (e.g., high-resolution images), which would require massive numbers of neurons because each pixel is a relevant input feature. A fully connected layer for an image of size 100 × 100 has 10,000 weights for each neuron in the second layer. Convolution reduces the number of free parameters, allowing the network to be deeper.[5] For example, using a 5 × 5 tiling region, each with the same shared weights, requires only 25 neurons. Using regularized weights over fewer parameters avoids the vanishing gradients and exploding gradients problems seen during backpropagation in earlier neural networks.[1][2]
To speed processing, standard convolutional layers can be replaced by depthwise separable convolutional layers,[22] which are based on a depthwise convolution followed by a pointwise convolution. The depthwise convolution is a spatial convolution applied independently over each channel of the input tensor, while the pointwise convolution is a standard convolution restricted to the use of kernels.

Pooling layers[edit]
Convolutional networks may include local and/or global pooling layers along with traditional convolutional layers. Pooling layers reduce the dimensions of data by combining the outputs of neuron clusters at one layer into a single neuron in the next layer. Local pooling combines small clusters, tiling sizes such as 2 × 2 are commonly used. Global pooling acts on all the neurons of the feature map.[23][24] There are two common types of pooling in popular use: max and average. Max pooling uses the maximum value of each local cluster of neurons in the feature map,[25][26] while average pooling takes the average value.
Fully connected layers[edit]
Fully connected layers connect every neuron in one layer to every neuron in another layer. It is the same as a traditional multilayer perceptron neural network (MLP). The flattened matrix goes through a fully connected layer to classify the images.
Receptive field[edit]
In neural networks, each neuron receives input from some number of locations in the previous layer. In a convolutional layer, each neuron receives input from only a restricted area of the previous layer called the neuron's receptive field. Typically the area is a square (e.g. 5 by 5 neurons). Whereas, in a fully connected layer, the receptive field is the entire previous layer. Thus, in each convolutional layer, each neuron takes input from a larger area in the input than previous layers. This is due to applying the convolution over and over, which takes the value of a pixel into account, as well as its surrounding pixels. When using dilated layers, the number of pixels in the receptive field remains constant, but the field is more sparsely populated as its dimensions grow when combining the effect of several layers.
To manipulate the receptive field size as desired, there are some alternatives to the standard convolutional layer. For example, atrous or dilated convolution[27][28] expands the receptive field size without increasing the number of parameters by interleaving visible and blind regions. Moreover, a single dilated convolutional layer can comprise filters with multiple dilation ratios,[29] thus having a variable receptive field size.
Weights[edit]
Each neuron in a neural network computes an output value by applying a specific function to the input values received from the receptive field in the previous layer. The function that is applied to the input values is determined by a vector of weights and a bias (typically real numbers). Learning consists of iteratively adjusting these biases and weights.
The vectors of weights and biases are called filters and represent particular features of the input (e.g., a particular shape). A distinguishing feature of CNNs is that many neurons can share the same filter. This reduces the memory footprint because a single bias and a single vector of weights are used across all receptive fields that share that filter, as opposed to each receptive field having its own bias and vector weighting.[30]
History[edit]
CNN are often compared to the way the brain achieves vision processing in living organisms.[31]
Receptive fields in the visual cortex[edit]
Work by Hubel and Wiesel in the 1950s and 1960s showed that cat visual cortices contain neurons that individually respond to small regions of the visual field. Provided the eyes are not moving, the region of visual space within which visual stimuli affect the firing of a single neuron is known as its receptive field.[32] Neighboring cells have similar and overlapping receptive fields. Receptive field size and location varies systematically across the cortex to form a complete map of visual space.[citation needed] The cortex in each hemisphere represents the contralateral visual field.[citation needed]
Their 1968 paper identified two basic visual cell types in the brain:[17]
- simple cells, whose output is maximized by straight edges having particular orientations within their receptive field
- complex cells, which have larger receptive fields, whose output is insensitive to the exact position of the edges in the field.
Hubel and Wiesel also proposed a cascading model of these two types of cells for use in pattern recognition tasks.[33][32]
Neocognitron, origin of the CNN architecture[edit]
The "neocognitron"[16] was introduced by Kunihiko Fukushima in 1980.[18][26][34]It was inspired by the above-mentioned work of Hubel and Wiesel. The neocognitron introduced the two basic types of layers in CNNs:
- A convolutional layer which contains units whose receptive fields cover a patch of the previous layer. The weight vector (the set of adaptive parameters) of such a unit is often called a filter. Units can share filters.
- Downsampling layers which contain units whose receptive fields cover patches of previous convolutional layers. Such a unit typically computes the average of the activations of the units in its patch. This downsampling helps to correctly classify objects in visual scenes even when the objects are shifted.
In 1969, Kunihiko Fukushima also introduced the ReLU (rectified linear unit) activation function.[35][36] The rectifier has become the most popular activation function for CNNs and deep neural networks in general.[37]
In a variant of the neocognitron called the cresceptron, instead of using Fukushima's spatial averaging, J. Weng et al. in 1993 introduced a method called max-pooling where a downsampling unit computes the maximum of the activations of the units in its patch.[38] Max-pooling is often used in modern CNNs.[39]
Several supervised and unsupervised learning algorithms have been proposed over the decades to train the weights of a neocognitron.[16] Today, however, the CNN architecture is usually trained through backpropagation.
The neocognitron is the first CNN which requires units located at multiple network positions to have shared weights.
Convolutional neural networks were presented at the Neural Information Processing Workshop in 1987, automatically analyzing time-varying signals by replacing learned multiplication with convolution in time, and demonstrated for speech recognition.[6]
Time delay neural networks[edit]
The time delay neural network (TDNN) was introduced in 1987 by Alex Waibel et al. for phoneme recognition and was one of the first convolutional networks, as it achieved shift-invariance.[40] A TDNN is a 1-D convolutional neural net where the convolution is performed along the time axis of the data. It is the first CNN utilizing weight sharing in combination with a training by gradient descent, using backpropagation.[41] Thus, while also using a pyramidal structure as in the neocognitron, it performed a global optimization of the weights instead of a local one.[40]
TDNNs are convolutional networks that share weights along the temporal dimension.[42] They allow speech signals to be processed time-invariantly. In 1990 Hampshire and Waibel introduced a variant that performs a two-dimensional convolution.[43] Since these TDNNs operated on spectrograms, the resulting phoneme recognition system was invariant to both time and frequency shifts. This inspired translation invariance in image processing with CNNs.[41] The tiling of neuron outputs can cover timed stages.[44]
TDNNs now [when?] achieve the best performance in far-distance speech recognition.[45]
Max pooling[edit]
In 1990 Yamaguchi et al. introduced the concept of max pooling, a fixed filtering operation that calculates and propagates the maximum value of a given region. They did so by combining TDNNs with max pooling to realize a speaker-independent isolated word recognition system.[25] In their system they used several TDNNs per word, one for each syllable. The results of each TDNN over the input signal were combined using max pooling and the outputs of the pooling layers were then passed on to networks performing the actual word classification.
Image recognition with CNNs trained by gradient descent[edit]
Denker et al. (1989) designed a 2-D CNN system to recognize hand-written ZIP Code numbers.[46] However, the lack of an efficient training method to determine the kernel coefficients of the involved convolutions meant that all the coefficients had to be laboriously hand-designed.[47]
Following the advances in the training of 1-D CNNs by Waibel et al. (1987), Yann LeCun et al. (1989)[47] used back-propagation to learn the convolution kernel coefficients directly from images of hand-written numbers. Learning was thus fully automatic, performed better than manual coefficient design, and was suited to a broader range of image recognition problems and image types. Wei Zhang et al. (1988)[12][13] used back-propagation to train the convolution kernels of a CNN for alphabets recognition. The model was called Shift-Invariant Artificial Neural Network (SIANN) before the name CNN was coined later in the early 1990s. Wei Zhang et al. also applied the same CNN without the last fully connected layer for medical image object segmentation (1991)[48] and breast cancer detection in mammograms (1994).[49]
This approach became a foundation of modern computer vision.
LeNet-5[edit]
LeNet-5, a pioneering 7-level convolutional network by LeCun et al. in 1995,[50] classifies hand-written numbers on checks (British English: cheques) digitized in 32x32 pixel images. The ability to process higher-resolution images requires larger and more layers of convolutional neural networks, so this technique is constrained by the availability of computing resources.
It was superior than other commercial courtesy amount reading systems (as of 1995). The system was integrated in NCR's check reading systems, and fielded in several American banks since June 1996, reading millions of checks per day.[51]
Shift-invariant neural network[edit]
A shift-invariant neural network was proposed by Wei Zhang et al. for image character recognition in 1988.[12][13] It is a modified Neocognitron by keeping only the convolutional interconnections between the image feature layers and the last fully connected layer. The model was trained with back-propagation. The training algorithm was further improved in 1991[52] to improve its generalization ability. The model architecture was modified by removing the last fully connected layer and applied for medical image segmentation (1991)[48] and automatic detection of breast cancer in mammograms (1994).[49]
A different convolution-based design was proposed in 1988[53] for application to decomposition of one-dimensional electromyography convolved signals via de-convolution. This design was modified in 1989 to other de-convolution-based designs.[54][55]
Neural abstraction pyramid[edit]

The feed-forward architecture of convolutional neural networks was extended in the neural abstraction pyramid[56] by lateral and feedback connections. The resulting recurrent convolutional network allows for the flexible incorporation of contextual information to iteratively resolve local ambiguities. In contrast to previous models, image-like outputs at the highest resolution were generated, e.g., for semantic segmentation, image reconstruction, and object localization tasks.
GPU implementations[edit]
Although CNNs were invented in the 1980s, their breakthrough in the 2000s required fast implementations on graphics processing units (GPUs).
In 2004, it was shown by K. S. Oh and K. Jung that standard neural networks can be greatly accelerated on GPUs. Their implementation was 20 times faster than an equivalent implementation on CPU.[57][39] In 2005, another paper also emphasised the value of GPGPU for machine learning.[58]
The first GPU-implementation of a CNN was described in 2006 by K. Chellapilla et al. Their implementation was 4 times faster than an equivalent implementation on CPU.[59] Subsequent work also used GPUs, initially for other types of neural networks (different from CNNs), especially unsupervised neural networks.[60][61][62][63]
In 2010, Dan Ciresan et al. at IDSIA showed that even deep standard neural networks with many layers can be quickly trained on GPU by supervised learning through the old method known as backpropagation. Their network outperformed previous machine learning methods on the MNIST handwritten digits benchmark.[64] In 2011, they extended this GPU approach to CNNs, achieving an acceleration factor of 60, with impressive results.[23] In 2011, they used such CNNs on GPU to win an image recognition contest where they achieved superhuman performance for the first time.[65] Between May 15, 2011, and September 30, 2012, their CNNs won no less than four image competitions.[66][39] In 2012, they also significantly improved on the best performance in the literature for multiple image databases, including the MNIST database, the NORB database, the HWDB1.0 dataset (Chinese characters) and the CIFAR10 dataset (dataset of 60000 32x32 labeled RGB images).[26]
Subsequently, a similar GPU-based CNN by Alex Krizhevsky et al. won the ImageNet Large Scale Visual Recognition Challenge 2012.[67] A very deep CNN with over 100 layers by Microsoft won the ImageNet 2015 contest.[68]
Intel Xeon Phi implementations[edit]
Compared to the training of CNNs using GPUs, not much attention was given to the Intel Xeon Phi coprocessor.[69]A notable development is a parallelization method for training convolutional neural networks on the Intel Xeon Phi, named Controlled Hogwild with Arbitrary Order of Synchronization (CHAOS).[70]CHAOS exploits both the thread- and SIMD-level parallelism that is available on the Intel Xeon Phi.
Distinguishing features[edit]
In the past, traditional multilayer perceptron (MLP) models were used for image recognition.[example needed] However, the full connectivity between nodes caused the curse of dimensionality, and was computationally intractable with higher-resolution images. A 1000×1000-pixel image with RGB color channels has 3 million weights per fully-connected neuron, which is too high to feasibly process efficiently at scale.

For example, in CIFAR-10, images are only of size 32×32×3 (32 wide, 32 high, 3 color channels), so a single fully connected neuron in the first hidden layer of a regular neural network would have 32*32*3 = 3,072 weights. A 200×200 image, however, would lead to neurons that have 200*200*3 = 120,000 weights.
Also, such network architecture does not take into account the spatial structure of data, treating input pixels which are far apart in the same way as pixels that are close together. This ignores locality of reference in data with a grid-topology (such as images), both computationally and semantically. Thus, full connectivity of neurons is wasteful for purposes such as image recognition that are dominated by spatially local input patterns.
Convolutional neural networks are variants of multilayer perceptrons, designed to emulate the behavior of a visual cortex. These models mitigate the challenges posed by the MLP architecture by exploiting the strong spatially local correlation present in natural images. As opposed to MLPs, CNNs have the following distinguishing features:
- 3D volumes of neurons. The layers of a CNN have neurons arranged in 3 dimensions: width, height and depth.[71] Where each neuron inside a convolutional layer is connected to only a small region of the layer before it, called a receptive field. Distinct types of layers, both locally and completely connected, are stacked to form a CNN architecture.
- Local connectivity: following the concept of receptive fields, CNNs exploit spatial locality by enforcing a local connectivity pattern between neurons of adjacent layers. The architecture thus ensures that the learned "filters" produce the strongest response to a spatially local input pattern. Stacking many such layers leads to nonlinear filters that become increasingly global (i.e. responsive to a larger region of pixel space) so that the network first creates representations of small parts of the input, then from them assembles representations of larger areas.
- Shared weights: In CNNs, each filter is replicated across the entire visual field. These replicated units share the same parameterization (weight vector and bias) and form a feature map. This means that all the neurons in a given convolutional layer respond to the same feature within their specific response field. Replicating units in this way allows for the resulting activation map to be equivariant under shifts of the locations of input features in the visual field, i.e. they grant translational equivariance - given that the layer has a stride of one.[72]
- Pooling: In a CNN's pooling layers, feature maps are divided into rectangular sub-regions, and the features in each rectangle are independently down-sampled to a single value, commonly by taking their average or maximum value. In addition to reducing the sizes of feature maps, the pooling operation grants a degree of local translational invariance to the features contained therein, allowing the CNN to be more robust to variations in their positions.[14]
Together, these properties allow CNNs to achieve better generalization on vision problems. Weight sharing dramatically reduces the number of free parameters learned, thus lowering the memory requirements for running the network and allowing the training of larger, more powerful networks.
Building blocks[edit]
This section needs additional citations for verification. (June 2017) |
A CNN architecture is formed by a stack of distinct layers that transform the input volume into an output volume (e.g. holding the class scores) through a differentiable function. A few distinct types of layers are commonly used. These are further discussed below.

Convolutional layer[edit]
The convolutional layer is the core building block of a CNN. The layer's parameters consist of a set of learnable filters (or kernels), which have a small receptive field, but extend through the full depth of the input volume. During the forward pass, each filter is convolved across the width and height of the input volume, computing the dot product between the filter entries and the input, producing a 2-dimensional activation map of that filter. As a result, the network learns filters that activate when it detects some specific type of feature at some spatial position in the input.[73][nb 1]
Stacking the activation maps for all filters along the depth dimension forms the full output volume of the convolution layer. Every entry in the output volume can thus also be interpreted as an output of a neuron that looks at a small region in the input. Each entry in an activation map use the same set of parameters that define the filter.
Self-supervised learning has been adapted for use in convolutional layers by using sparse patches with a high-mask ratio and a global response normalization layer.[citation needed]
Local connectivity[edit]
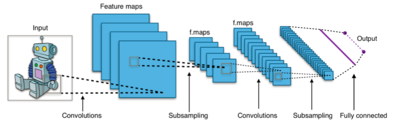
When dealing with high-dimensional inputs such as images, it is impractical to connect neurons to all neurons in the previous volume because such a network architecture does not take the spatial structure of the data into account. Convolutional networks exploit spatially local correlation by enforcing a sparse local connectivity pattern between neurons of adjacent layers: each neuron is connected to only a small region of the input volume.
The extent of this connectivity is a hyperparameter called the receptive field of the neuron. The connections are local in space (along width and height), but always extend along the entire depth of the input volume. Such an architecture ensures that the learned (British English: learnt) filters produce the strongest response to a spatially local input pattern.
Spatial arrangement[edit]
Three hyperparameters control the size of the output volume of the convolutional layer: the depth, stride, and padding size:
- The depth of the output volume controls the number of neurons in a layer that connect to the same region of the input volume. These neurons learn to activate for different features in the input. For example, if the first convolutional layer takes the raw image as input, then different neurons along the depth dimension may activate in the presence of various oriented edges, or blobs of color.
- Stride controls how depth columns around the width and height are allocated. If the stride is 1, then we move the filters one pixel at a time. This leads to heavily overlapping receptive fields between the columns, and to large output volumes. For any integer a stride S means that the filter is translated S units at a time per output. In practice, is rare. A greater stride means smaller overlap of receptive fields and smaller spatial dimensions of the output volume.[74]
- Sometimes, it is convenient to pad the input with zeros (or other values, such as the average of the region) on the border of the input volume. The size of this padding is a third hyperparameter. Padding provides control of the output volume's spatial size. In particular, sometimes it is desirable to exactly preserve the spatial size of the input volume, this is commonly referred to as "same" padding.


Пространственный размер выходного тома является функцией размера входного тома. , the kernel field size of the convolutional layer neurons, the stride и количество заполнения нулями на границе. Тогда количество нейронов, «помещающихся» в данном объеме, равно:





Если это число не является целым числом , то шаги неверны, и нейроны не могут быть выложены плиткой, чтобы симметрично разместиться во входном объеме . В общем, установка нулевого заполнения будет когда шаг гарантирует, что входной и выходной том будут иметь одинаковый пространственный размер. Однако не всегда полностью необходимо задействовать все нейроны предыдущего слоя. Например, разработчик нейронной сети может решить использовать только часть заполнения.


Совместное использование параметров [ править ]
Схема совместного использования параметров используется в сверточных слоях для управления количеством свободных параметров. Он основан на предположении, что если объект-заплатку полезно вычислить в какой-то пространственной позиции, то его также полезно вычислить и в других позициях. Обозначая одиночный двумерный срез глубины как срез глубины , нейроны в каждом срезе глубины ограничены использованием одних и тех же весов и смещений.
Поскольку все нейроны в одном срезе глубины имеют одни и те же параметры, прямой проход в каждом срезе глубины сверточного слоя можно вычислить как свертку весов нейронов с входным объемом. [номер 2] Поэтому наборы весов принято называть фильтром (или ядром ) , который свернут с входными данными. Результатом этой свертки является карта активации , а набор карт активации для каждого отдельного фильтра складываются вместе по измерению глубины для получения выходного объема. Совместное использование параметров способствует трансляционной инвариантности архитектуры CNN. [14]
Иногда предположение о совместном использовании параметров может не иметь смысла. Это особенно актуально, когда входные изображения в CNN имеют определенную центрированную структуру; для которого мы ожидаем, что в разных пространственных точках будут изучены совершенно разные функции. Одним из практических примеров является случай, когда входными данными являются лица, которые были центрированы на изображении: мы могли бы ожидать, что в разных частях изображения будут изучены разные особенности глаз или волос. В этом случае принято ослаблять схему совместного использования параметров и вместо этого просто называть уровень «локально подключенным уровнем».
Слой объединения [ править ]

Другая важная концепция CNN — это объединение, которое представляет собой форму нелинейной понижающей дискретизации . Существует несколько нелинейных функций для реализации пула, максимальный пул наиболее распространенной из которых является . Он разбивает входное изображение на набор прямоугольников и для каждой такой подобласти выводит максимум.
Интуитивно понятно, что точное местоположение объекта менее важно, чем его приблизительное расположение относительно других объектов. В этом заключается идея использования пула в сверточных нейронных сетях. Уровень объединения служит для постепенного уменьшения пространственного размера представления, уменьшения количества параметров, объема памяти и объема вычислений в сети и, следовательно, для контроля переобучения . Это известно как понижающая выборка. Обычно периодически вставляют слой объединения между последовательными сверточными уровнями (за каждым из которых обычно следует функция активации, такая как уровень ReLU ). в архитектуре CNN [73] : 460–461 Хотя уровни объединения способствуют локальной трансляционной инвариантности, они не обеспечивают глобальную трансляционную инвариантность в CNN, если не используется форма глобального пула. [14] [72] Слой объединения обычно работает независимо на каждой глубине или срезе входных данных и изменяет их пространственный размер. Очень распространенной формой максимального пула является слой с фильтрами размера 2×2, применяемыми с шагом 2, который субдискретизирует каждый срез глубины во входных данных на 2 как по ширине, так и по высоте, отбрасывая 75% активаций:

В дополнение к максимальному объединению, объединяющие единицы могут использовать другие функции, такие как среднее объединение или ℓ 2 -нормы объединение . Исторически часто использовалось среднее объединение, но в последнее время оно вышло из моды по сравнению с максимальным объединением, которое на практике обычно работает лучше. [75]
Из-за эффектов быстрого пространственного уменьшения размера представления, [ который? ] в последнее время наблюдается тенденция к использованию фильтров меньшего размера. [76] или вообще отказаться от слоев объединения. [77]

Объединение « области интереса » (также известное как объединение областей интереса) — это вариант максимального объединения, при котором выходной размер фиксирован, а входной прямоугольник является параметром. [ нужна ссылка ]
Пул — это метод понижающей дискретизации и важный компонент сверточных нейронных сетей для обнаружения объектов на основе Fast R-CNN. [78] архитектура.
Максимальное объединение каналов [ править ]
Уровень операции максимального объединения каналов (CMP) выполняет операцию MP вдоль стороны канала среди соответствующих позиций последовательных карт признаков с целью устранения избыточной информации. CMP позволяет собрать важные функции в меньшем количестве каналов, что важно для более детальной классификации изображений, требующей большего количества различающих функций. Между тем, еще одним преимуществом операции CMP является уменьшение количества каналов карт объектов перед их подключением к первому полносвязному (FC) уровню. Подобно операции MP, мы обозначаем входные карты признаков и выходные карты признаков слоя CMP как F ∈ R(C×M×N) и C ∈ R(c×M×N) соответственно, где C и c — это номера каналов входных и выходных карт объектов, M и N — это ширина и высота карт объектов соответственно. Обратите внимание, что операция CMP изменяет только номер канала карт объектов. Ширина и высота карт объектов не изменяются, в отличие от операции MP. [79]
Слой ReLU [ править ]
ReLU — это аббревиатура выпрямленной линейной единицы, введенная Кунихико Фукусимой в 1969 году. [35] [36] без насыщения ReLU применяет функцию активации . [67] Он эффективно удаляет отрицательные значения из карты активации, устанавливая их равными нулю. [80] Это вносит нелинейность в функцию принятия решения и в сеть в целом, не затрагивая рецептивные поля слоев свертки.В 2011 году Ксавье Глоро, Антуан Бордес и Йошуа Бенжио обнаружили, что ReLU позволяет лучше обучать более глубокие сети. [81] по сравнению с широко используемыми функциями активации до 2011 года.

Для увеличения нелинейности также можно использовать другие функции, например насыщающий гиперболический тангенс. , и сигмовидная функция . ReLU часто предпочтительнее других функций, поскольку он обучает нейронную сеть в несколько раз быстрее без значительного снижения точности обобщения . [82]



Полностью связный слой [ править ]
После нескольких сверточных слоев и слоев максимального пула окончательная классификация выполняется через полностью связанные слои. Нейроны в полностью связном слое имеют связи со всеми активациями предыдущего слоя, как это видно в обычных (несверточных) искусственных нейронных сетях . Таким образом, их активации можно вычислить как аффинное преобразование с умножением матрицы , за которым следует смещение смещения ( векторное сложение изученного или фиксированного термина смещения).
Слой потерь [ править ]
«Уровень потерь» или « функция потерь » определяет, как обучение наказывает за отклонение между прогнозируемыми выходными данными сети и истинными метками данных (во время контролируемого обучения). различные функции потерь В зависимости от конкретной задачи могут использоваться .
Функция потерь Softmax используется для прогнозирования одного класса из K взаимоисключающих классов. [номер 3] Сигмовидная кросс-энтропийная потеря используется для прогнозирования K независимых значений вероятности в . Евклидова потеря используется для регрессии к с действительным значением. меткам .
![{\displaystyle [0,1]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/738f7d23bb2d9642bab520020873cccbef49768d)

Гиперпараметры [ править ]
Этот раздел нуждается в дополнительных цитатах для проверки . ( июнь 2017 г. ) |
Гиперпараметры — это различные настройки, которые используются для управления процессом обучения. CNN используют больше гиперпараметров , чем стандартный многослойный перцептрон (MLP).
Размер ядра [ править ]
Ядро — это количество пикселей, обработанных вместе. Обычно это выражается в размерах ядра, например, 2x2 или 3x3.
Заполнение [ править ]
Заполнение — это добавление (обычно) пикселей со значением 0 на границах изображения. Это делается для того, чтобы граничные пиксели не были занижены (не потеряны) в выходных данных, поскольку обычно они участвуют только в одном экземпляре рецептивного поля. Применяемое дополнение обычно на единицу меньше соответствующего размера ядра. Например, сверточный слой, использующий ядра 3x3, получит 2-пиксельную площадку, то есть по 1 пикселю с каждой стороны изображения. [ нужна ссылка ]
Страйд [ править ]
Шаг — это количество пикселей, на которое окно анализа перемещается на каждой итерации. Шаг 2 означает, что каждое ядро смещено на 2 пикселя относительно своего предшественника.
Количество фильтров [ править ]
Поскольку размер карты объектов уменьшается с глубиной, слои рядом с входным слоем, как правило, имеют меньше фильтров, а более высокие слои могут иметь больше. Чтобы уравнять вычисления на каждом слое, произведение значений признаков v a на положение пикселя поддерживается примерно постоянным на всех слоях. Для сохранения большего количества информации о входных данных потребуется, чтобы общее количество активаций (количество карт объектов, умноженное на количество позиций пикселей) не уменьшалось от одного слоя к другому.
Количество карт признаков напрямую влияет на емкость и зависит от количества доступных примеров и сложности задачи.
Размер фильтра [ изменить ]
Общие размеры фильтров, встречающиеся в литературе, сильно различаются и обычно выбираются на основе набора данных.
Задача состоит в том, чтобы найти правильный уровень детализации, чтобы создавать абстракции в нужном масштабе с учетом конкретного набора данных и без переобучения .
Тип и размер пула [ править ]
Обычно используется максимальное объединение , часто с размером 2x2. Это означает, что входные данные значительно уменьшаются , что снижает затраты на обработку.
Увеличение пула уменьшает размерность сигнала и может привести к неприемлемой потере информации . Зачастую лучше всего работают непересекающиеся окна пула. [75]
Дилатация [ править ]
Расширение предполагает игнорирование пикселей внутри ядра. Это потенциально уменьшает обработку/память без значительной потери сигнала. Расширение 2 в ядре 3x3 расширяет ядро до 5x5, при этом все еще обрабатывается 9 (равномерно расположенных) пикселей. Соответственно, расширение 4 расширяет ядро до 7x7. [ нужна ссылка ]
и псевдонимы Эквивариантность перевода
Обычно предполагается, что CNN инвариантны к сдвигам входных данных. Слои свертки или объединения внутри CNN, шаг которых не превышает единицы, действительно эквивалентны переводам входных данных. [72] Однако слои с шагом больше единицы игнорируют теорему выборки Найквиста-Шеннона и могут привести к искажению входного сигнала. [72] Хотя в принципе CNN способны реализовывать фильтры сглаживания, было замечено, что на практике этого не происходит. [83] и дают модели, которые не эквивариантны переводам.Более того, если CNN использует полносвязные слои, трансляционная эквивалентность не подразумевает трансляционную инвариантность, поскольку полносвязные слои не инвариантны к сдвигам входных данных. [84] [14] Одним из решений для полной инвариантности трансляции является отказ от понижающей выборки по всей сети и применение глобального среднего пула на последнем уровне. [72] Кроме того, было предложено несколько других частичных решений, таких как сглаживание перед операциями понижения разрешения. [85] пространственные трансформаторные сети, [86] увеличение данных , подвыборка в сочетании с объединением в пулы, [14] и капсульные нейронные сети . [87]
Оценка [ править ]
Точность окончательной модели основана на части набора данных, выделенной в начале и часто называемой тестовым набором. такие методы, как k -кратная перекрестная проверка В других случаях применяются . Другие стратегии включают использование конформного предсказания . [88] [89]
Методы регуляризации [ править ]
Этот раздел нуждается в дополнительных цитатах для проверки . ( июнь 2017 г. ) |
Регуляризация — это процесс введения дополнительной информации для решения некорректной задачи или предотвращения переобучения . CNN используют различные типы регуляризации.
Эмпирический [ править ]
Выбывание [ править ]
Поскольку полносвязный слой занимает большую часть параметров, он склонен к переобучению. Одним из методов уменьшения переобучения является дропаут , представленный в 2014 году. [90] На каждом этапе обучения отдельные узлы либо «выпадают» из сети (игнорируются) с вероятностью или сохраняется с вероятностью , так что остается уменьшенная сеть; входящие и исходящие ребра к выпавшему узлу также удаляются. На этом этапе на данных обучается только сокращенная сеть. Удаленные узлы затем повторно вставляются в сеть с их первоначальными весами.


На этапах обучения, обычно составляет 0,5; для входных узлов оно обычно намного выше, поскольку информация напрямую теряется, когда входные узлы игнорируются.
Во время тестирования после завершения обучения нам в идеале хотелось бы найти выборочное среднее всех возможных значений. выпавшие сети; к сожалению, это невозможно для больших значений . Однако мы можем найти приближение, используя полную сеть, в которой выход каждого узла взвешивается с коэффициентом , поэтому ожидаемое значение вывода любого узла такое же, как и на этапах обучения. Это самый большой вклад метода отсева: хотя он эффективно генерирует нейронных сетей и, как таковые, позволяют комбинировать модели, во время тестирования необходимо тестировать только одну сеть.


Избегая обучения всех узлов на всех обучающих данных, отсев уменьшает переобучение. Метод также значительно повышает скорость обучения. Это делает комбинацию моделей практичной даже для глубоких нейронных сетей . Кажется, что этот метод уменьшает взаимодействие узлов, что позволяет им изучать более надежные функции. [ нужны разъяснения ] лучше обобщить на новые данные.
ДропКоннект [ править ]
DropConnect — это обобщение исключения, при котором с вероятностью может быть отброшено каждое соединение, а не каждый выходной блок. . Таким образом, каждый блок получает входные данные от случайного подмножества блоков на предыдущем уровне. [91]
DropConnect аналогичен исключению, поскольку он вводит динамическую разреженность в модели, но отличается тем, что разреженность связана с весами, а не с выходными векторами слоя. Другими словами, полностью связанный уровень с DropConnect становится разреженным слоем, в котором соединения выбираются случайным образом на этапе обучения.
Стохастический пул [ править ]
Основным недостатком Dropout является то, что он не дает тех же преимуществ для сверточных слоев, где нейроны не полностью связаны.
Еще до Dropout, в 2013 году, была использована техника под названием стохастический пул. [92] обычные детерминированные операции объединения были заменены стохастической процедурой, в которой активация в каждой области объединения выбирается случайным образом в соответствии с полиномиальным распределением , заданным действиями в пределах региона объединения. Этот подход не содержит гиперпараметров и может сочетаться с другими подходами к регуляризации, такими как исключение и увеличение данных .
Альтернативный взгляд на стохастическое объединение состоит в том, что оно эквивалентно стандартному максимальному объединению, но со многими копиями входного изображения, каждая из которых имеет небольшие локальные деформации . Это похоже на явные упругие деформации входных изображений: [93] который обеспечивает превосходную производительность при работе с набором данных MNIST . [93] Использование стохастического объединения в многослойной модели приводит к экспоненциальному числу деформаций, поскольку выборка в более высоких слоях не зависит от выборки в нижних слоях.
Искусственные данные [ править ]
Поскольку степень переобучения модели определяется как ее мощностью, так и объемом обучения, которое она получает, предоставление сверточной сети большего количества обучающих примеров может уменьшить переобучение. Поскольку доступных данных для обучения зачастую недостаточно, особенно если учесть, что некоторую часть следует сохранить для последующего тестирования, есть два подхода: либо сгенерировать новые данные с нуля (если это возможно), либо изменить существующие данные для создания новых. Последний используется с середины 1990-х годов. [50] Например, входные изображения можно обрезать, вращать или масштабировать для создания новых примеров с теми же метками, что и исходный обучающий набор. [94]
Явное [ править ]
Ранняя остановка [ править ]
Один из самых простых способов предотвратить переобучение сети — просто остановить обучение до того, как произойдет переобучение. Недостатком этого является то, что процесс обучения останавливается.
Количество параметров [ править ]
Еще один простой способ предотвратить переоснащение — ограничить количество параметров, обычно путем ограничения количества скрытых модулей в каждом слое или ограничения глубины сети. Для сверточных сетей размер фильтра также влияет на количество параметров. Ограничение количества параметров напрямую ограничивает прогнозирующую способность сети, уменьшая сложность функции, которую она может выполнять с данными, и, таким образом, ограничивает количество переобучения. Это эквивалентно « нулевой норме ».
Снижение веса [ править ]
Простая форма добавленного регуляризатора — это затухание веса, которое просто добавляет дополнительную ошибку, пропорциональную сумме весов ( норма L1 ) или квадрату величины ( норма L2 ) весового вектора, к ошибке в каждом узле. Уровень приемлемой сложности модели можно снизить, увеличив константу пропорциональности (гиперпараметр «альфа»), тем самым увеличив штраф за большие весовые векторы.
Регуляризация L2 — наиболее распространенная форма регуляризации. Это можно реализовать путем штрафования квадратов всех параметров непосредственно в цели. Регуляризация L2 имеет интуитивную интерпретацию, заключающуюся в строгом наказании пиковых весовых векторов и предпочтении диффузных весовых векторов. Из-за мультипликативного взаимодействия между весами и входными данными это имеет полезное свойство, побуждающее сеть использовать все свои входные данные понемногу, а не часто использовать некоторые из своих входных данных.
Регуляризация L1 также распространена. Это делает весовые векторы разреженными во время оптимизации. Другими словами, нейроны с регуляризацией L1 в конечном итоге используют только редкое подмножество своих наиболее важных входных данных и становятся почти инвариантными к зашумленным входным сигналам. Регуляризацию L1 и L2 можно комбинировать; это называется эластичной сетевой регуляризацией .
Максимальные ограничения нормы [ править ]
Другая форма регуляризации — установить абсолютную верхнюю границу величины весового вектора для каждого нейрона и использовать прогнозируемый градиентный спуск для обеспечения соблюдения ограничения. На практике это соответствует обычному обновлению параметров, а затем обеспечению соблюдения ограничения путем фиксации весового вектора. каждого нейрона для удовлетворения . Типичные значения имеют порядок 3–4. В некоторых статьях сообщается об улучшениях [95] при использовании этой формы регуляризации.



Иерархические системы координат [ править ]
При объединении теряются точные пространственные отношения между частями высокого уровня (такими как нос и рот на изображении лица). Эти отношения необходимы для распознавания личности. Перекрытие пулов, так что каждый объект встречается в нескольких пулах, помогает сохранить информацию. Сам по себе перевод не может экстраполировать понимание геометрических отношений на радикально новую точку зрения, например, на другую ориентацию или масштаб. С другой стороны, люди очень хорошо умеют экстраполировать; увидев новую форму, они смогут распознать ее с другой точки зрения. [96]
Более ранний распространенный способ решения этой проблемы — обучение сети на преобразованных данных в разных ориентациях, масштабах, освещении и т. д., чтобы сеть могла справиться с этими изменениями. Это требует больших вычислительных ресурсов для больших наборов данных. Альтернативой является использование иерархии систем координат и использование группы нейронов для представления сочетания формы объекта и его положения относительно сетчатки . Поза относительно сетчатки — это взаимосвязь между системой координат сетчатки и системой координат внутренних особенностей. [97]
Таким образом, один из способов представить что-либо — это встроить в него систему координат. Это позволяет распознавать крупные черты лица, используя согласованность поз их частей (например, позы носа и рта позволяют последовательно прогнозировать позу всего лица). Этот подход гарантирует, что объект более высокого уровня (например, лицо) присутствует, когда объект более низкого уровня (например, нос и рот) соглашается с прогнозом позы. Векторы активности нейронов, представляющие позу («векторы позы»), позволяют осуществлять пространственные преобразования, смоделированные как линейные операции, которые облегчают сети изучение иерархии визуальных объектов и обобщение точек зрения. Это похоже на то, как зрительная система человека накладывает рамки координат для представления форм. [98]
Приложения [ править ]
Распознавание изображений [ править ]
CNN часто используются в системах распознавания изображений . В 2012 году о частоте ошибок 0,23% . в базе данных MNIST сообщалось [26] В другой статье об использовании CNN для классификации изображений сообщается, что процесс обучения был «на удивление быстрым»; в той же статье лучшие опубликованные результаты по состоянию на 2011 год были достигнуты в базе данных MNIST и базе данных NORB. [23] Впоследствии аналогичный CNN назвал АлексНет [99] выиграл конкурс ImageNet по крупномасштабному визуальному распознаванию 2012.
Применительно к распознаванию лиц CNN добились значительного снижения частоты ошибок. [100] В другой статье сообщалось о 97,6% распознавании «5600 неподвижных изображений более 10 предметов». [19] CNN использовались для оценки качества видео объективной после ручного обучения; полученная система имела очень низкую среднеквадратическую ошибку . [44]
— Масштабный конкурс визуального распознавания ImageNet это эталон в классификации и обнаружении объектов, в котором участвуют миллионы изображений и сотни классов объектов. На ILSVRC 2014 г. [101] В ходе масштабной задачи по визуальному распознаванию почти каждая команда с высоким рейтингом использовала CNN в качестве базовой структуры. Победитель ГуглЛеНет [102] (основа DeepDream ) увеличил среднюю точность обнаружения объектов до 0,439329 и снизил ошибку классификации до 0,06656, что является лучшим результатом на сегодняшний день. В его сети применено более 30 слоев. Производительность сверточных нейронных сетей в тестах ImageNet была близка к показателям людей. [103] Лучшие алгоритмы по-прежнему борются с маленькими или тонкими объектами, такими как маленький муравей на стебле цветка или человек, держащий в руке перо. У них также возникают проблемы с изображениями, искаженными фильтрами, что является все более распространенным явлением в современных цифровых камерах. Напротив, подобные изображения редко беспокоят людей. Однако у людей обычно возникают проблемы с другими проблемами. Например, они не умеют классифицировать объекты по детальным категориям, таким как конкретная порода собаки или вид птицы, тогда как сверточные нейронные сети справляются с этим. [ нужна ссылка ]
В 2015 году многослойная CNN продемонстрировала способность распознавать лица под разными углами, в том числе перевернутыми, даже при частичном закрытии, с конкурентоспособными характеристиками. Сеть была обучена на базе данных из 200 000 изображений, включающих лица под разными углами и ориентациями, а также еще 20 миллионов изображений без лиц. Они использовали пакеты по 128 изображений в течение 50 000 итераций. [104]
Видеоанализ [ править ]
По сравнению с доменами данных изображений, работы по применению CNN для классификации видео относительно мало. Видео сложнее изображений, поскольку оно имеет другое (временное) измерение. Тем не менее, были изучены некоторые расширения CNN в область видео. Один из подходов состоит в том, чтобы рассматривать пространство и время как эквивалентные измерения входных данных и выполнять свертки как во времени, так и в пространстве. [105] [106] Другой способ — объединить функции двух сверточных нейронных сетей: одной для пространственного, а другой для временного потока. [107] [108] [109] единицы долгосрочной краткосрочной памяти (LSTM) Рекуррентные обычно включаются после CNN для учета зависимостей между кадрами или между клипами. [110] [111] неконтролируемого обучения Были представлены схемы для обучения пространственно-временных функций, основанные на сверточных вентилируемых ограниченных машинах Больцмана. [112] и независимый анализ подпространства. [113] Его применение можно увидеть в модели преобразования текста в видео . [ нужна ссылка ]
Обработка естественного языка [ править ]
CNN также использовались для обработки естественного языка . Модели CNN эффективны для решения различных задач НЛП и достигли отличных результатов в семантическом анализе . [114] получение поисковых запросов, [115] моделирование предложений, [116] классификация, [117] прогноз [118] и другие традиционные задачи НЛП. [119] По сравнению с традиционными методами языковой обработки, такими как рекуррентные нейронные сети , CNN могут представлять различные контекстуальные реалии языка, которые не полагаются на предположение о последовательностях рядов, в то время как RNN лучше подходят, когда требуется классическое моделирование временных рядов. [120] [121] [122] [123]
Обнаружение аномалий [ править ]
CNN с одномерными свертками использовалась во временных рядах в частотной области (спектральный остаток) с помощью неконтролируемой модели для обнаружения аномалий во временной области. [124]
Открытие лекарств [ править ]
CNN использовались при открытии лекарств . Прогнозирование взаимодействия между молекулами и биологическими белками может определить потенциальные методы лечения. В 2015 году Atomwise представила AtomNet, первую нейронную сеть глубокого обучения для разработки лекарств на основе структуры . [125] Система обучается непосредственно на трехмерных представлениях химических взаимодействий. Подобно тому, как сети распознавания изображений учатся объединять меньшие, пространственно близкие объекты в более крупные и сложные структуры. [126] AtomNet обнаруживает химические свойства, такие как ароматичность , sp. 3 углерода и водородной связи . Впоследствии AtomNet использовалась для прогнозирования новых биомолекул- кандидатов для лечения множества заболеваний, в первую очередь для лечения вируса Эбола. [127] и рассеянный склероз . [128]
Игра в шашки [ править ]
CNN использовались в игре в шашки . С 1999 по 2001 год Фогель и Челлапилла опубликовали статьи, показывающие, как сверточная нейронная сеть может научиться играть в шашку, используя коэволюцию. В процессе обучения не использовались предыдущие человеческие профессиональные игры, а, скорее, основное внимание уделялось минимальному набору информации, содержащейся в шахматной доске: расположению и типу фигур, а также разнице в количестве фигур на двух сторонах. В конечном итоге программа ( Blondie24 ) была протестирована на 165 играх против игроков и заняла высшие 0,4%. [129] [130] Он также одержал победу над программой Chinook на ее «экспертном» уровне игры. [131]
Иди [ править ]
CNN использовались в компьютерном Go . В декабре 2014 года Кларк и Сторки опубликовали статью, показывающую, что CNN, обученная контролируемым обучением на основе базы данных профессиональных игр людей, может превзойти GNU Go и выиграть несколько игр против поиска по дереву Монте-Карло Fuego 1.1 за долю времени, которое потребовалось Fuego играть. [132] Позже было объявлено, что большая 12-слойная сверточная нейронная сеть правильно предсказала профессиональный ход в 55% позиций, что соответствует точности игрока-человека с 6 даном . Когда обученная сверточная сеть использовалась непосредственно для игр в Го, без какого-либо поиска, она превзошла традиционную программу поиска GNU Go в 97% игр и сравнялась по производительности с программой поиска по дереву Монте-Карло Fuego, имитирующей десять тысяч игр (около миллион позиций) за ход. [133]
использовала пару CNN для выбора ходов («политическая сеть») и оценки позиций («сеть ценности»), управляющих MCTS AlphaGo , которая первой обыграла лучшего игрока-человека того времени. [134]
временных Прогнозирование рядов
Рекуррентные нейронные сети обычно считаются лучшими архитектурами нейронных сетей для прогнозирования временных рядов (и моделирования последовательностей в целом), но недавние исследования показывают, что сверточные сети могут работать сопоставимо или даже лучше. [135] [11] Расширенные извилины [136] может позволить одномерным сверточным нейронным сетям эффективно изучать зависимости временных рядов. [137] Свертки могут быть реализованы более эффективно, чем решения на основе RNN, и они не страдают от исчезновения (или взрыва) градиентов. [138] Сверточные сети могут обеспечить повышенную эффективность прогнозирования, когда имеется несколько похожих временных рядов, на которых можно учиться. [139] CNN также можно применять для дальнейших задач анализа временных рядов (например, классификации временных рядов). [140] или квантильное прогнозирование [141] ).
Культурное наследие и наборы - данных 3D
Поскольку археологические находки, такие как глиняные таблички с клинописью, все чаще приобретаются с помощью 3D-сканеров , становятся доступными наборы эталонных данных, включая HeiCuBeDa. [142] предоставление почти 2000 нормализованных наборов 2-D и 3-D данных, подготовленных с помощью GigaMesh Software Framework . [143] Таким образом, измерения на основе кривизны используются в сочетании с геометрическими нейронными сетями (GNN), например, для классификации периода тех глиняных табличек, которые являются одними из древнейших документов истории человечества. [144] [145]
Тонкая настройка [ править ]
Для многих приложений данные обучения не очень доступны. Сверточные нейронные сети обычно требуют большого объема обучающих данных, чтобы избежать переобучения . Распространенным методом является обучение сети на большем наборе данных из связанной области. После того, как параметры сети сошлись, выполняется дополнительный этап обучения с использованием внутридоменных данных для точной настройки весов сети. Это называется трансферным обучением . Более того, этот метод позволяет успешно применять архитектуры сверточных сетей для решения задач с крошечными обучающими наборами. [146]
Объяснения понятные , человеку
Сквозное обучение и прогнозирование — обычная практика в компьютерном зрении . , требуются понятные человеку объяснения Однако для таких критически важных систем , как беспилотные автомобили . [147] Благодаря недавним достижениям в области визуальной значимости , пространственного и временного внимания , наиболее важные пространственные области/временные моменты могут быть визуализированы, чтобы оправдать предсказания CNN. [148] [149]
Связанные архитектуры [ править ]
Глубокие Q-сети [ править ]
Глубокая Q-сеть (DQN) — это тип модели глубокого обучения, которая сочетает в себе глубокую нейронную сеть с Q-обучением , формой обучения с подкреплением . В отличие от более ранних агентов обучения с подкреплением, DQN, использующие CNN, могут учиться непосредственно на многомерных сенсорных входных данных посредством обучения с подкреплением. [150]
Предварительные результаты были представлены в 2014 году, а сопроводительный документ — в феврале 2015 года. [151] В исследовании описано применение игр для Atari 2600 . Этому предшествовали другие модели глубокого обучения с подкреплением. [152]
Сети глубоких убеждений
Сверточные сети глубокого убеждения (CDBN) имеют структуру, очень похожую на сверточные нейронные сети, и обучаются аналогично сетям глубокого убеждения. Поэтому они используют двумерную структуру изображений, как это делают CNN, и используют предварительное обучение, например, сети глубокого убеждения . Они предоставляют общую структуру, которую можно использовать во многих задачах обработки изображений и сигналов. Результаты сравнительного анализа стандартных наборов данных изображений, таких как CIFAR. [153] были получены с использованием CDBN. [154]
Известные библиотеки [ править ]
- Caffe : библиотека для сверточных нейронных сетей. Создано Центром видения и обучения Беркли (BVLC). Он поддерживает как процессор, так и графический процессор. Разработан на C++ и имеет Python и MATLAB . оболочки
- Deeplearning4j : глубокое обучение Java и Scala с поддержкой нескольких графических процессоров в Spark . Библиотека глубокого обучения общего назначения для производственного стека JVM, работающая на движке научных вычислений C++. Позволяет создавать собственные слои. Интегрируется с Hadoop и Kafka.
- Dlib : набор инструментов для создания реальных приложений машинного обучения и анализа данных на C++.
- Microsoft Cognitive Toolkit : набор инструментов глубокого обучения, написанный Microsoft, с несколькими уникальными функциями, улучшающими масштабируемость на нескольких узлах. Он поддерживает полноценные интерфейсы для обучения C++ и Python, а также дополнительную поддержку вывода моделей на C# и Java.
- TensorFlow : Theano-подобная библиотека под лицензией Apache 2.0 Google с поддержкой CPU, GPU, собственного тензорного процессора (TPU), [155] и мобильные устройства.
- Theano : эталонная библиотека глубокого обучения для Python с API, в значительной степени совместимым с популярной библиотекой NumPy . Позволяет пользователю писать символические математические выражения, а затем автоматически генерирует их производные, избавляя пользователя от необходимости кодировать градиенты или обратное распространение ошибки. Эти символические выражения автоматически компилируются в код CUDA для быстрой реализации на графическом процессоре .
- Torch : среда научных вычислений с широкой поддержкой алгоритмов машинного обучения, написанная на C и Lua .
См. также [ править ]
- Внимание (машинное обучение)
- Свертка
- Глубокое обучение
- Обработка естественного языка
- Неокогнитрон
- Преобразование масштабно-инвариантного объекта
- Нейронная сеть с задержкой времени
- Блок обработки изображений
Примечания [ править ]
- ^ Применительно к другим типам данных, кроме данных изображения, например звуковым данным, «пространственное положение» может по-разному соответствовать различным точкам во временной области , частотной области или других математических пространствах .
- ^ отсюда и название «сверточный слой».
- ^ Так называемые категориальные данные .
Ссылки [ править ]
- ↑ Перейти обратно: Перейти обратно: а б Венкатесан, Рагав; Ли, Баоксин (23 октября 2017 г.). Сверточные нейронные сети в визуальных вычислениях: краткое руководство . ЦРК Пресс. ISBN 978-1-351-65032-8 . Архивировано из оригинала 16 октября 2023 г. Проверено 13 декабря 2020 г.
- ↑ Перейти обратно: Перейти обратно: а б Балас, Валентина Евгеньевна; Кумар, Рагвендра; Шривастава, Раджшри (19 ноября 2019 г.). Последние тенденции и достижения в области искусственного интеллекта и Интернета вещей . Спрингер Природа. ISBN 978-3-030-32644-9 . Архивировано из оригинала 16 октября 2023 г. Проверено 13 декабря 2020 г.
- ^ Чжан, Инцзе; Скоро, Хон Геок; Йе, Донсен; Фу, Джерри Ин Си; Чжу, Куньпэн (сентябрь 2020 г.). «Мониторинг процесса плавления в порошковом слое с помощью машинного зрения с помощью гибридных сверточных нейронных сетей» . Транзакции IEEE по промышленной информатике . 16 (9): 5769–5779. дои : 10.1109/TII.2019.2956078 . ISSN 1941-0050 . S2CID 213010088 . Архивировано из оригинала 31 июля 2023 г. Проверено 12 августа 2023 г.
- ^ Червяков Н.И.; Ляхов, П.А.; Дерябин, М.А.; Нагорнов Н.Н.; Валуева, М.В.; Валуев, Г.В. (сентябрь 2020 г.). «Решение на основе системы остаточных чисел для снижения стоимости оборудования сверточной нейронной сети» . Нейрокомпьютинг . 407 : 439–453. doi : 10.1016/j.neucom.2020.04.018 . S2CID 219470398 . Архивировано из оригинала 29 июня 2023 г. Проверено 12 августа 2023 г.
Сверточные нейронные сети представляют собой архитектуры глубокого обучения, которые в настоящее время используются в широком спектре приложений, включая компьютерное зрение, распознавание речи, обнаружение вредоносных программ, анализ временных рядов в финансах и многие другие.
- ↑ Перейти обратно: Перейти обратно: а б Хабиби, Агдам, Хамед (30 мая 2017 г.). Руководство по сверточным нейронным сетям: практическое применение для обнаружения и классификации дорожных знаков . Херави, Эльназ Джахани. Чам, Швейцария. ISBN 9783319575490 . OCLC 987790957 .
{{cite book}}: CS1 maint: отсутствует местоположение издателя ( ссылка ) CS1 maint: несколько имен: список авторов ( ссылка ) - ↑ Перейти обратно: Перейти обратно: а б Хомма, Тоситеру; Лес Атлас; Роберт Маркс II (1987). «Искусственная нейронная сеть для пространственно-временных биполярных паттернов: применение к классификации фонем» (PDF) . Достижения в области нейронных систем обработки информации . 1 : 31–40. Архивировано (PDF) из оригинала 31 марта 2022 г. Проверено 31 марта 2022 г.
- ^ Валуева, М.В.; Нагорнов Н.Н.; Ляхов, П.А.; Валуев Г.В.; Червяков Н.И. (2020). «Применение системы остаточных чисел для снижения затрат на оборудование при реализации сверточной нейронной сети». Математика и компьютеры в моделировании . 177 . Эльзевир Б.В.: 232–243. дои : 10.1016/j.matcom.2020.04.031 . ISSN 0378-4754 . S2CID 218955622 .
Сверточные нейронные сети являются перспективным инструментом решения задачи распознавания образов.
- ^ ван ден Оорд, Аарон; Дилеман, Сандер; Шраувен, Бенджамин (01 января 2013 г.). Берджес, CJC; Ботту, Л.; Веллинг, М.; Гахрамани, З.; Вайнбергер, KQ (ред.). Глубокие рекомендации по музыке на основе контента (PDF) . Curran Associates, Inc., стр. 2643–2651. Архивировано (PDF) из оригинала 7 марта 2022 г. Проверено 31 марта 2022 г.
- ^ Коллобер, Ронан; Уэстон, Джейсон (1 января 2008 г.). «Единая архитектура обработки естественного языка». Материалы 25-й международной конференции по машинному обучению ICML '08 . Нью-Йорк, штат Нью-Йорк, США: ACM. стр. 160–167. дои : 10.1145/1390156.1390177 . ISBN 978-1-60558-205-4 . S2CID 2617020 .
- ^ Авилов, Алексей; Римбер, Себастьен; Попов, Антон; Буген, Лоран (июль 2020 г.). «Методы глубокого обучения для улучшения интраоперационного обнаружения осведомленности по электроэнцефалографическим сигналам» . 42-я ежегодная международная конференция Общества инженерии в медицине и биологии IEEE (EMBC), 2020 г. (PDF) . Том. 2020. Монреаль, Квебек, Канада: IEEE. стр. 142–145. дои : 10.1109/EMBC44109.2020.9176228 . ISBN 978-1-7281-1990-8 . ПМИД 33017950 . S2CID 221386616 . Архивировано (PDF) из оригинала 19 мая 2022 г. Проверено 21 июля 2023 г.
- ↑ Перейти обратно: Перейти обратно: а б Цантекидис, Авраам; Пассалис, Николаос; Тефас, Анастасиос; Канниайнен, Юхо; Габбуж, Монсеф; Иосифидис, Александрос (июль 2017 г.). «Прогнозирование цен на акции из книги лимитных ордеров с использованием сверточных нейронных сетей». 19-я конференция IEEE по бизнес-информатике (CBI) , 2017 г. Салоники, Греция: IEEE. стр. 7–12. дои : 10.1109/CBI.2017.23 . ISBN 978-1-5386-3035-8 . S2CID 4950757 .
- ↑ Перейти обратно: Перейти обратно: а б с Чжан, Вэй (1988). «Сдвиг-инвариантная нейронная сеть распознавания образов и ее оптическая архитектура» . Материалы ежегодной конференции Японского общества прикладной физики . Архивировано из оригинала 23 июня 2020 г. Проверено 22 июня 2020 г.
- ↑ Перейти обратно: Перейти обратно: а б с Чжан, Вэй (1990). «Модель параллельной распределенной обработки с локальными пространственно-инвариантными соединениями и ее оптическая архитектура» . Прикладная оптика . 29 (32): 4790–7. Бибкод : 1990ApOpt..29.4790Z . дои : 10.1364/AO.29.004790 . ПМИД 20577468 . Архивировано из оригинала 6 февраля 2017 г. Проверено 22 сентября 2016 г.
- ↑ Перейти обратно: Перейти обратно: а б с д и ж Мутон, Коэнраад; Майбург, Йоханнес К.; Давел, Марели Х. (2020). «Шаг и инвариантность трансляции в CNN» . В Гербере, Аурона (ред.). Исследования искусственного интеллекта . Коммуникации в компьютерной и информатике. Том. 1342. Чам: Международное издательство Springer. стр. 267–281. arXiv : 2103.10097 . дои : 10.1007/978-3-030-66151-9_17 . ISBN 978-3-030-66151-9 . S2CID 232269854 . Архивировано из оригинала 27 июня 2021 г. Проверено 26 марта 2021 г.
- ^ Курцман, Томас (20 августа 2019 г.). «Скрытая предвзятость в наборе данных DUD-E приводит к вводящей в заблуждение эффективности глубокого обучения при виртуальном скрининге на основе структур» . ПЛОС ОДИН . 14 (8): e0220113. Бибкод : 2019PLoSO..1420113C . дои : 10.1371/journal.pone.0220113 . ПМК 6701836 . ПМИД 31430292 .
- ↑ Перейти обратно: Перейти обратно: а б с Фукусима, К. (2007). «Неокогнитрон» . Схоларпедия . 2 (1): 1717. Бибкод : 2007SchpJ...2.1717F . doi : 10.4249/scholarpedia.1717 .
- ↑ Перейти обратно: Перейти обратно: а б Хьюбель, Д.Х.; Визель, Теннесси (1 марта 1968 г.). «Рецептивные поля и функциональная архитектура полосатой коры обезьян» . Журнал физиологии . 195 (1): 215–243. doi : 10.1113/jphysicalol.1968.sp008455 . ISSN 0022-3751 . ПМЦ 1557912 . ПМИД 4966457 .
- ↑ Перейти обратно: Перейти обратно: а б Фукусима, Кунихико (1980). «Неокогнитрон: самоорганизующаяся модель нейронной сети для механизма распознавания образов, на который не влияет сдвиг положения» (PDF) . Биологическая кибернетика . 36 (4): 193–202. дои : 10.1007/BF00344251 . ПМИД 7370364 . S2CID 206775608 . Архивировано (PDF) из оригинала 3 июня 2014 года . Проверено 16 ноября 2013 г.
- ↑ Перейти обратно: Перейти обратно: а б Матусугу, Масакадзу; Кацухико Мори; Юсуке Митари; Юджи Канеда (2003). «Субъектное независимое распознавание выражения лица с надежным обнаружением лиц с использованием сверточной нейронной сети» (PDF) . Нейронные сети . 16 (5): 555–559. дои : 10.1016/S0893-6080(03)00115-1 . ПМИД 12850007 . Архивировано (PDF) из оригинала 13 декабря 2013 года . Проверено 17 ноября 2013 г.
- ^ Демистификация сверточных нейронных сетей: учебное пособие на основе перспективы согласованной фильтрации https://arxiv.org/abs/2108.11663v3
- ^ «Сверточные нейронные сети (LeNet) — документация DeepLearning 0.1» . Глубокое обучение 0.1 . ЛИЗА Лаборатория. Архивировано из оригинала 28 декабря 2017 года . Проверено 31 августа 2013 г.
- ^ Шолле, Франсуа (04 апреля 2017 г.). «Xception: глубокое обучение с глубоко разделяемыми извилинами». arXiv : 1610.02357 [ cs.CV ].
- ↑ Перейти обратно: Перейти обратно: а б с Чиресан, Дэн; Ули Мейер; Джонатан Маски; Лука М. Гамбарделла; Юрген Шмидхубер (2011). «Гибкие, высокопроизводительные сверточные нейронные сети для классификации изображений» (PDF) . Материалы двадцать второй Международной совместной конференции по искусственному интеллекту, том второй . 2 : 1237–1242. Архивировано (PDF) из оригинала 5 апреля 2022 года . Проверено 17 ноября 2013 г.
- ^ Крижевский , Алекс. «Классификация ImageNet с глубокими сверточными нейронными сетями» (PDF) . Архивировано (PDF) из оригинала 25 апреля 2021 года . Проверено 17 ноября 2013 г.
- ↑ Перейти обратно: Перейти обратно: а б Ямагути, Коичи; Сакамото, Кендзи; Акабане, Тосио; Фудзимото, Ёсидзи (ноябрь 1990 г.). Нейронная сеть для независимого от говорящего распознавания изолированных слов . Первая международная конференция по обработке разговорной речи (ICSLP 90). Кобе, Япония. Архивировано из оригинала 07 марта 2021 г. Проверено 4 сентября 2019 г.
- ↑ Перейти обратно: Перейти обратно: а б с д Чиресан, Дэн; Мейер, Ули; Шмидхубер, Юрген (июнь 2012 г.). «Многостолбцовые глубокие нейронные сети для классификации изображений». Конференция IEEE 2012 по компьютерному зрению и распознаванию образов . Нью-Йорк, штат Нью-Йорк: Институт инженеров по электротехнике и электронике (IEEE). стр. 3642–3649. arXiv : 1202.2745 . CiteSeerX 10.1.1.300.3283 . дои : 10.1109/CVPR.2012.6248110 . ISBN 978-1-4673-1226-4 . OCLC 812295155 . S2CID 2161592 .
- ^ Ю, Фишер; Колтун, Владлен (30 апреля 2016 г.). «Многомасштабная агрегация контекста с помощью расширенных сверток». arXiv : 1511.07122 [ cs.CV ].
- ^ Чен, Лян-Чье; Папандреу, Джордж; Шрофф, Флориан; Адам, Хартвиг (05 декабря 2017 г.). «Переосмысление агрессивной свертки для семантической сегментации изображений». arXiv : 1706.05587 [ cs.CV ].
- ^ Дута, Ионут Космин; Георгеску, Мариана Юлиана; Ионеску, Раду Тудор (16 августа 2021 г.). «Контекстные сверточные нейронные сети». arXiv : 2108.07387 [ cs.CV ].
- ^ ЛеКун, Янн. «LeNet-5, сверточные нейронные сети» . Архивировано из оригинала 24 февраля 2021 года . Проверено 16 ноября 2013 г.
- ^ ван Дейк, Леонард Элиа; Квитт, Роланд; Денцлер, Себастьян Йохен; Грубер, Вальтер Роланд (2021). «Сравнение распознавания объектов у людей и глубоких сверточных нейронных сетей — исследование слежения за взглядом» . Границы в неврологии . 15 : 750639. дои : 10.3389/fnins.2021.750639 . ISSN 1662-453X . ПМЦ 8526843 . ПМИД 34690686 .
- ↑ Перейти обратно: Перейти обратно: а б Хьюбель, Д.Х.; Визель, Теннесси (октябрь 1959 г.). «Рецептивные поля отдельных нейронов полосатой коры головного мозга кошки» . Дж. Физиол . 148 (3): 574–91. doi : 10.1113/jphysicalol.1959.sp006308 . ПМЦ 1363130 . ПМИД 14403679 .
- ^ Дэвид Х. Хьюбель и Торстен Н. Визель (2005). Мозг и зрительное восприятие: история 25-летнего сотрудничества . Издательство Оксфордского университета, США. п. 106. ИСБН 978-0-19-517618-6 . Архивировано из оригинала 16 октября 2023 г. Проверено 18 января 2019 г.
- ^ ЛеКун, Янн; Бенджио, Йошуа; Хинтон, Джеффри (2015). «Глубокое обучение» (PDF) . Природа . 521 (7553): 436–444. Бибкод : 2015Natur.521..436L . дои : 10.1038/nature14539 . ПМИД 26017442 . S2CID 3074096 .
- ↑ Перейти обратно: Перейти обратно: а б Фукусима, К. (1969). «Визуальное извлечение признаков с помощью многослойной сети аналоговых пороговых элементов». Транзакции IEEE по системным наукам и кибернетике . 5 (4): 322–333. дои : 10.1109/TSSC.1969.300225 .
- ↑ Перейти обратно: Перейти обратно: а б Шмидхубер, Юрген (2022). «Аннотированная история современного искусственного интеллекта и глубокого обучения». arXiv : 2212.11279 [ cs.NE ].
- ^ Рамачандран, Праджит; Баррет, Зоф; Куок, В. Ле (16 октября 2017 г.). «Поиск функций активации». arXiv : 1710.05941 [ cs.NE ].
- ^ Венг, Дж; Ахуджа, Н; Хуанг, Т.С. (1993). «Обучение распознаванию и сегментации трехмерных объектов из двухмерных изображений» . 1993 (4-я) Международная конференция по компьютерному зрению . IEEE. стр. 121–128. дои : 10.1109/ICCV.1993.378228 . ISBN 0-8186-3870-2 . S2CID 8619176 .
- ↑ Перейти обратно: Перейти обратно: а б с Шмидхубер, Юрген (2015). «Глубокое обучение» . Схоларпедия . 10 (11): 1527–54. CiteSeerX 10.1.1.76.1541 . дои : 10.1162/neco.2006.18.7.1527 . ПМИД 16764513 . S2CID 2309950 . Архивировано из оригинала 19 апреля 2016 г. Проверено 20 января 2019 г.
- ↑ Перейти обратно: Перейти обратно: а б Вайбель, Алекс (декабрь 1987 г.). Распознавание фонем с использованием нейронных сетей с задержкой . Заседание Института инженеров по электротехнике, информатике и связи (IEICE). Токио, Япония.
- ↑ Перейти обратно: Перейти обратно: а б Александр Вайбель и др., Распознавание фонем с использованием нейронных сетей с задержкой. Архивировано 25 февраля 2021 г. в Wayback Machine. Транзакции IEEE по акустике, речи и обработке сигналов, том 37, № 3, стр. 328. - 339, март 1989 г. .
- ^ ЛеКун, Янн; Бенджио, Йошуа (1995). «Сверточные сети для изображений, речи и временных рядов» . В Арбибе, Майкл А. (ред.). Справочник по теории мозга и нейронным сетям (второе изд.). Пресса МТИ. стр. 276–278. Архивировано из оригинала 28 июля 2020 г. Проверено 3 декабря 2019 г.
- ^ Джон Б. Хэмпшир и Александр Вайбель, Коннекционистские архитектуры для распознавания фонем нескольких говорящих. Архивировано 31 марта 2022 г. в Wayback Machine , Достижения в области нейронных систем обработки информации, 1990, Морган Кауфманн.
- ↑ Перейти обратно: Перейти обратно: а б Ле Калле, Патрик; Кристиан Виар-Годэн; Доминик Барба (2006). «Подход сверточных нейронных сетей для объективной оценки качества видео» (PDF) . Транзакции IEEE в нейронных сетях . 17 (5): 1316–1327. дои : 10.1109/ТНН.2006.879766 . ПМИД 17001990 . S2CID 221185563 . Архивировано (PDF) из оригинала 24 февраля 2021 года . Проверено 17 ноября 2013 г.
- ^ Ко, Том; Педдинти, Виджаядитья; Пови, Дэниел; Зельцер, Майкл Л.; Худанпур, Санджив (март 2018 г.). Исследование увеличения данных реверберирующей речи для надежного распознавания речи (PDF) . 42-я Международная конференция IEEE по акустике, речи и обработке сигналов (ICASSP 2017). Новый Орлеан, Лос-Анджелес, США. Архивировано (PDF) из оригинала 8 июля 2018 г. Проверено 4 сентября 2019 г.
- ^ Денкер, Дж.С., Гарднер, В.Р., Граф, Х.П., Хендерсон, Д., Ховард, Р.Э., Хаббард, В., Джекель, Л.Д., Бэйрд, Х.С. и Гайон (1989). Распознаватель нейронной сети для рукописных цифр почтового индекса . Архивировано 4 августа 2018 г. в Wayback Machine , AT&T Bell Laboratories.
- ↑ Перейти обратно: Перейти обратно: а б Ю. ЛеКан, Б. Бозер, Дж. С. Денкер, Д. Хендерсон, Р. Э. Ховард, В. Хаббард, Л. Д. Джекел, Обратное распространение ошибки, применяемое к распознаванию рукописного почтового индекса. Архивировано 10 января 2020 г. в Wayback Machine ; AT&T Bell Laboratories
- ↑ Перейти обратно: Перейти обратно: а б Чжан, Вэй (1991). «Обработка изображений эндотелия роговицы человека на основе обучающей сети» . Прикладная оптика . 30 (29): 4211–7. Бибкод : 1991ApOpt..30.4211Z . дои : 10.1364/AO.30.004211 . ПМИД 20706526 . Архивировано из оригинала 6 февраля 2017 г. Проверено 22 сентября 2016 г.
- ↑ Перейти обратно: Перейти обратно: а б Чжан, Вэй (1994). «Компьютерное обнаружение кластерных микрокальцинатов на цифровых маммограммах с использованием инвариантной к сдвигу искусственной нейронной сети» . Медицинская физика . 21 (4): 517–24. Бибкод : 1994MedPh..21..517Z . дои : 10.1118/1.597177 . ПМИД 8058017 . Архивировано из оригинала 6 февраля 2017 г. Проверено 22 сентября 2016 г.
- ↑ Перейти обратно: Перейти обратно: а б Лекун, Ю.; Джекель, LD; Ботту, Л.; Кортес, К.; Денкер, Дж. С.; Друкер, Х.; Гийон, И.; Мюллер, Украина; Сакингер, Э.; Симард, П.; Вапник, В. (август 1995 г.). Алгоритмы обучения классификации: сравнение распознавания рукописных цифр (PDF) . Всемирная научная. стр. 261–276. дои : 10.1142/2808 . ISBN 978-981-02-2324-3 . Архивировано (PDF) из оригинала 2 мая 2023 года.
- ^ Лекун, Ю.; Ботту, Л.; Бенджио, Ю.; Хаффнер, П. (ноябрь 1998 г.). «Градиентное обучение применительно к распознаванию документов» . Труды IEEE . 86 (11): 2278–2324. дои : 10.1109/5.726791 .
- ^ Чжан, Вэй (1991). «Обратное распространение ошибок с весами с минимальной энтропией: метод лучшего обобщения двумерных нейронных сетей, инвариантных к сдвигу» . Материалы Международной совместной конференции по нейронным сетям . Архивировано из оригинала 6 февраля 2017 г. Проверено 22 сентября 2016 г.
- ^ Дэниел Граупе, Руи Вэнь Лю, Джордж С. Мошиц. « Применение нейронных сетей для обработки медицинских сигналов. Архивировано 28 июля 2020 г. в Wayback Machine ». В Proc. 27-я конференция IEEE по принятию решений и управлению, стр. 343–347, 1988 г.
- ^ Дэниел Граупе, Борис Верн, Г. Грюнер, Аарон Филд и Цю Хуан. « Разложение поверхностных сигналов ЭМГ на потенциалы действия отдельных волокон с помощью нейронной сети . Архивировано 4 сентября 2019 г. в Wayback Machine ». Учеб. Международный симпозиум IEEE. по схемам и системам, стр. 1008–1011, 1989.
- ^ Цю Хуан, Даниэль Граупе, И Фан Хуан, Жюй Вэнь Лю». Идентификация паттернов возбуждения нейрональных сигналов [ мертвая ссылка ] В материалах 28-й конференции IEEE Decision and Control Conf., стр. 266–271, 1989. https://ieeexplore.ieee.org/document/70115. Архивировано 31 марта 2022 г. в Wayback Machine.
- ^ Бенке, Свен (2003). Иерархические нейронные сети для интерпретации изображений (PDF) . Конспекты лекций по информатике. Том. 2766. Спрингер. дои : 10.1007/b11963 . ISBN 978-3-540-40722-5 . S2CID 1304548 . Архивировано (PDF) из оригинала 10 августа 2017 г. Проверено 28 декабря 2016 г.
- ^ Ох, КС; Юнг, К. (2004). «ГПУ-реализация нейронных сетей». Распознавание образов . 37 (6): 1311–1314. Бибкод : 2004PatRe..37.1311O . дои : 10.1016/j.patcog.2004.01.013 .
- ^ Дэйв Стейнкраус; Патрис Симар; Ян Бак (2005). «Использование графических процессоров для алгоритмов машинного обучения» . 12-я Международная конференция по анализу и распознаванию документов (ICDAR 2005) . стр. 1115–1119. дои : 10.1109/ICDAR.2005.251 . Архивировано из оригинала 31 марта 2022 г. Проверено 31 марта 2022 г.
- ^ Кумар Челлапилья; Сид Пури; Патрис Симар (2006). «Высокопроизводительные сверточные нейронные сети для обработки документов» . В Лоретте, Гай (ред.). Десятый международный семинар «Границы в распознавании рукописного текста» . Сувисофт. Архивировано из оригинала 18 мая 2020 г. Проверено 14 марта 2016 г.
- ^ Хинтон, GE; Осиндеро, С; Тех, YW (июль 2006 г.). «Алгоритм быстрого обучения для глубоких сетей доверия». Нейронные вычисления . 18 (7): 1527–54. CiteSeerX 10.1.1.76.1541 . дои : 10.1162/neco.2006.18.7.1527 . ПМИД 16764513 . S2CID 2309950 .
- ^ Бенджио, Йошуа; Ламблин, Паскаль; Поповичи, Дэн; Ларошель, Хьюго (2007). «Жадное послойное обучение глубоких сетей» (PDF) . Достижения в области нейронных систем обработки информации : 153–160. Архивировано (PDF) из оригинала 02 июня 2022 г. Проверено 31 марта 2022 г.
- ^ Ранзато, Марк Аурелио; Поултни, Кристофер; Чопра, Сумит; ЛеКун, Янн (2007). «Эффективное изучение разреженных представлений с помощью энергетической модели» (PDF) . Достижения в области нейронных систем обработки информации . Архивировано (PDF) из оригинала 22 марта 2016 г. Проверено 26 июня 2014 г.
- ^ Райна, Р; Мадхаван, А; Нг, Эндрю (14 июня 2009 г.). «Крупномасштабное глубокое обучение без учителя с использованием графических процессоров» (PDF) . Материалы 26-й ежегодной международной конференции по машинному обучению . ICML '09: Материалы 26-й ежегодной международной конференции по машинному обучению. стр. 873–880. дои : 10.1145/1553374.1553486 . ISBN 9781605585161 . S2CID 392458 . Архивировано (PDF) из оригинала 8 декабря 2020 г. Проверено 22 декабря 2023 г.
- ^ Чиресан, Дэн; Мейер, Ули; Гамбарделла, Лука; Шмидхубер, Юрген (2010). «Глубокие большие простые нейронные сети для распознавания рукописных цифр». Нейронные вычисления . 22 (12): 3207–3220. arXiv : 1003.0358 . дои : 10.1162/NECO_a_00052 . ПМИД 20858131 . S2CID 1918673 .
- ^ «Таблица результатов конкурса IJCNN 2011» . ОФИЦИАЛЬНЫЙ КОНКУРС IJCNN2011 . 2010. Архивировано из оригинала 17 января 2021 г. Проверено 14 января 2019 г.
- ^ Шмидхубер, Юрген (17 марта 2017 г.). «История конкурсов компьютерного зрения, выигранных глубокими CNN на GPU» . Архивировано из оригинала 19 декабря 2018 года . Проверено 14 января 2019 г.
- ↑ Перейти обратно: Перейти обратно: а б Крижевский, Алекс; Суцкевер, Илья; Хинтон, Джеффри Э. (24 мая 2017 г.). «Классификация ImageNet с глубокими сверточными нейронными сетями» (PDF) . Коммуникации АКМ . 60 (6): 84–90. дои : 10.1145/3065386 . ISSN 0001-0782 . S2CID 195908774 . Архивировано (PDF) из оригинала 16 мая 2017 г. Проверено 4 декабря 2018 г.
- ^ Он, Кайминг; Чжан, Сянъюй; Рен, Шаоцин; Сунь, Цзянь (2016). «Глубокое остаточное обучение для распознавания изображений» (PDF) . Конференция IEEE 2016 по компьютерному зрению и распознаванию образов (CVPR) . стр. 770–778. arXiv : 1512.03385 . дои : 10.1109/CVPR.2016.90 . ISBN 978-1-4673-8851-1 . S2CID 206594692 . Архивировано (PDF) из оригинала 5 апреля 2022 г. Проверено 31 марта 2022 г.
- ^ Вибке, Андре; Планана, Сабри (2015). «Потенциал Intel (R) Xeon Phi для контролируемого глубокого обучения» . 17-я Международная конференция IEEE по высокопроизводительным вычислениям и коммуникациям (2015 г.), 7-й Международный симпозиум IEEE по безопасности и защите киберпространства (2015 г.) и 12-я Международная конференция IEEE по встраиваемому программному обеспечению и системам (2015 г.) . IEEE Эксплор . IEEE 2015. стр. 758–765. doi : 10.1109/HPCC-CSS-ICES.2015.45 . ISBN 978-1-4799-8937-9 . S2CID 15411954 . Архивировано из оригинала 06 марта 2023 г. Проверено 31 марта 2022 г.
- ^ Вибке, Андре; Мемети, Суэйб; Планана, Сабри; Авраам, Аджит (2019). «ХАОС: схема распараллеливания для обучения сверточных нейронных сетей на Intel Xeon Phi». Журнал суперкомпьютеров . 75 (1): 197–227. arXiv : 1702.07908 . дои : 10.1007/s11227-017-1994-x . S2CID 14135321 .
- ^ Хинтон, Джеффри (2012). «Классификация ImageNet с глубокими сверточными нейронными сетями» . NIPS'12: Материалы 25-й Международной конференции по нейронным системам обработки информации — Том 1 . 1 : 1097–1105. Архивировано из оригинала 20 декабря 2019 г. Проверено 26 марта 2021 г. - через ACM.
- ↑ Перейти обратно: Перейти обратно: а б с д и Азулай, Аарон; Вайс, Яир (2019). «Почему глубокие сверточные сети так плохо обобщают небольшие преобразования изображений?» . Журнал исследований машинного обучения . 20 (184): 1–25. ISSN 1533-7928 . Архивировано из оригинала 31 марта 2022 г. Проверено 31 марта 2022 г.
- ↑ Перейти обратно: Перейти обратно: а б Жерон, Орельен (2019). Практическое машинное обучение с помощью Scikit-Learn, Keras и TensorFlow . Севастополь, Калифорния: O'Reilly Media. ISBN 978-1-492-03264-9 . , стр. 448
- ^ «Сверточные нейронные сети CS231n для визуального распознавания» . cs231n.github.io . Архивировано из оригинала 23 октября 2019 г. Проверено 25 апреля 2017 г.
- ↑ Перейти обратно: Перейти обратно: а б Шерер, Доминик; Мюллер, Андреас К.; Бенке, Свен (2010). «Оценка операций объединения в сверточных архитектурах для распознавания объектов» (PDF) . Искусственные нейронные сети (ICANN), 20-я Международная конференция по . Салоники, Греция: Springer. стр. 92–101. Архивировано (PDF) из оригинала 3 апреля 2018 г. Проверено 28 декабря 2016 г.
- ^ Грэм, Бенджамин (18 декабря 2014 г.). «Дробный максимальный пул». arXiv : 1412.6071 [ cs.CV ].
- ^ Спрингенберг, Йост Тобиас; Досовицкий, Алексей; Брокс, Томас; Ридмиллер, Мартин (21 декабря 2014 г.). «Стремление к простоте: вся сверточная сеть». arXiv : 1412.6806 [ cs.LG ].
- ^ Гиршик, Росс (27 сентября 2015 г.). «Быстрый R-CNN». arXiv : 1504.08083 [ cs.CV ].
- ^ Ма, Жаньюй; Чанг, Дунлян; Се, Цзиянь; Дин, Ифэн; Вэнь, Шаого; Ли, Сяосюй; Си, Чжунвэй; Го, Цзюнь (2019). «Детальная классификация транспортных средств с модифицированными CNN с максимальным объединением каналов». Транзакции IEEE по автомобильным технологиям . 68 (4). Институт инженеров по электротехнике и электронике (IEEE): 3224–3233. дои : 10.1109/tvt.2019.2899972 . ISSN 0018-9545 . S2CID 86674074 .
- ^ Романуке, Вадим (2017). «Подходящее количество и размещение ReLU в сверточных нейронных сетях» . Научно-исследовательский вестник НТУУ «Киевский политехнический институт» . 1 (1): 69–78. дои : 10.20535/1810-0546.2017.1.88156 .
- ^ Ксавье Глорот; Антуан Борд; Йошуа Бенджио (2011). Нейронные сети с глубоким разреженным выпрямителем (PDF) . АЙСТАТС. Архивировано из оригинала (PDF) 13 декабря 2016 г. Проверено 10 апреля 2023 г.
Функции активации выпрямителя и softplus. Второй вариант является более гладкой версией первого.
- ^ Крижевский А.; Суцкевер И.; Хинтон, GE (2012). «Классификация Imagenet с глубокими сверточными нейронными сетями» (PDF) . Достижения в области нейронных систем обработки информации . 1 : 1097–1105. Архивировано (PDF) из оригинала 31 марта 2022 г. Проверено 31 марта 2022 г.
- ^ Рибейро, Антонио Х.; Шен, Томас Б. (2021). «Как сверточные нейронные сети справляются с псевдонимами». ICASSP 2021–2021 Международная конференция IEEE по акустике, речи и обработке сигналов (ICASSP) . стр. 2755–2759. arXiv : 2102.07757 . дои : 10.1109/ICASSP39728.2021.9414627 . ISBN 978-1-7281-7605-5 . S2CID 231925012 .
- ^ Майбург, Йоханнес К.; Мутон, Коэнраад; Давел, Марели Х. (2020). «Отслеживание инвариантности трансляции в CNNS» . В Гербере, Аурона (ред.). Исследования искусственного интеллекта . Коммуникации в компьютерной и информатике. Том. 1342. Чам: Международное издательство Springer. стр. 282–295. arXiv : 2104.05997 . дои : 10.1007/978-3-030-66151-9_18 . ISBN 978-3-030-66151-9 . S2CID 233219976 . Архивировано из оригинала 22 января 2022 г. Проверено 26 марта 2021 г.
- ^ Ричард, Чжан (25 апреля 2019 г.). Снова делаем сверточные сети сдвигово-инвариантными . OCLC 1106340711 .
- ^ Ядеберг, Симонян, Зиссерман, Кавукчуоглу, Макс, Карен, Андрей, Корай (2015). «Пространственные трансформаторные сети» (PDF) . Достижения в области нейронных систем обработки информации . 28 . Архивировано (PDF) из оригинала 25 июля 2021 г. Проверено 26 марта 2021 г. - через NIPS.
{{cite journal}}: CS1 maint: несколько имен: список авторов ( ссылка ) - ^ Э, Сабур, Сара Фрост, Николас Хинтон, Джеффри (26 октября 2017 г.). Динамическая маршрутизация между капсулами . OCLC 1106278545 .
{{cite book}}: CS1 maint: несколько имен: список авторов ( ссылка ) - ^ Матиз, Серджио; Барнер, Кеннет Э. (01 июня 2019 г.). «Индуктивный конформный предиктор для сверточных нейронных сетей: приложения к активному обучению классификации изображений» . Распознавание образов . 90 : 172–182. Бибкод : 2019PatRe..90..172M . дои : 10.1016/j.patcog.2019.01.035 . ISSN 0031-3203 . S2CID 127253432 . Архивировано из оригинала 29 сентября 2021 г. Проверено 29 сентября 2021 г.
- ^ Вислендер, Хокан; Харрисон, Филип Дж.; Скогберг, Габриэль; Джексон, Соня; Фриден, Маркус; Карлссон, Йохан; Спьют, Ола; Уолби, Каролина (февраль 2021 г.). «Глубокое обучение с конформным прогнозированием для иерархического анализа крупномасштабных изображений тканей на целых предметных стеклах» . Журнал IEEE по биомедицинской и медицинской информатике . 25 (2): 371–380. дои : 10.1109/JBHI.2020.2996300 . ISSN 2168-2208 . ПМИД 32750907 . S2CID 219885788 .
- ^ Шривастава, Нитиш; К. Джеффри Хинтон; Алексей Крижевский; Илья Суцкевер; Руслан Салахутдинов (2014). «Отсев: простой способ предотвратить переобучение нейронных сетей» (PDF) . Журнал исследований машинного обучения . 15 (1): 1929–1958. Архивировано (PDF) из оригинала 19 января 2016 г. Проверено 3 января 2015 г.
- ^ «Регуляризация нейронных сетей с использованием DropConnect | ICML 2013 | JMLR W&CP» . jmlr.org : 1058–1066. 13 февраля 2013 г. Архивировано из оригинала 12 августа 2017 г. Проверено 17 декабря 2015 г.
- ^ Зейлер, Мэтью Д.; Фергус, Роб (15 января 2013 г.). «Стохастическое объединение для регуляризации глубоких сверточных нейронных сетей». arXiv : 1301.3557 [ cs.LG ].
- ↑ Перейти обратно: Перейти обратно: а б Платт, Джон; Стейнкраус, Дэйв; Симард, Патрис Ю. (август 2003 г.). «Лучшие практики использования сверточных нейронных сетей применительно к визуальному анализу документов – исследования Microsoft» . Исследования Майкрософт . Архивировано из оригинала 07.11.2017 . Проверено 17 декабря 2015 г.
- ^ Хинтон, Джеффри Э.; Шривастава, Нитиш; Крижевский, Алекс; Суцкевер, Илья; Салахутдинов, Руслан Р. (2012). «Улучшение нейронных сетей путем предотвращения совместной адаптации детекторов признаков». arXiv : 1207.0580 [ cs.NE ].
- ^ «Отсев: простой способ предотвратить переобучение нейронных сетей» . jmlr.org . Архивировано из оригинала 05 марта 2016 г. Проверено 17 декабря 2015 г.
- ^ Хинтон, Джеффри (1979). «Некоторые демонстрации эффектов структурных описаний в мысленных образах». Когнитивная наука . 3 (3): 231–250. дои : 10.1016/s0364-0213(79)80008-7 .
- ^ Рок, Ирвин. «Система отсчета». Наследие Соломона Аша: Очерки познания и социальной психологии (1990): 243–268.
- ^ Дж. Хинтон, Лекции Coursera по нейронным сетям, 2012 г., URL: https://www.coursera.org/learn/neural-networks. Архивировано 31 декабря 2016 г. в Wayback Machine.
- ^ Дэйв Гершгорн (18 июня 2018 г.). «Внутренняя история того, как искусственный интеллект стал достаточно хорош, чтобы доминировать в Кремниевой долине» . Кварц . Архивировано из оригинала 12 декабря 2019 года . Проверено 5 октября 2018 г.
- ^ Лоуренс, Стив; К. Ли Джайлз; А Чунг Цой; Эндрю Д. Бэк (1997). «Распознавание лиц: подход сверточной нейронной сети». Транзакции IEEE в нейронных сетях . 8 (1): 98–113. CiteSeerX 10.1.1.92.5813 . дои : 10.1109/72.554195 . ПМИД 18255614 . S2CID 2883848 .
- ^ «Масштабный конкурс визуального распознавания ImageNet 2014 (ILSVRC2014)» . Архивировано из оригинала 5 февраля 2016 года . Проверено 30 января 2016 г.
- ^ Сегеди, Кристиан; Лю, Вэй; Цзя, Янцин; Сермане, Пьер; Рид, Скотт Э.; Ангелов, Драгомир; Эрхан, Дмитрий; Ванхук, Винсент; Рабинович, Андрей (2015). «Углубляемся с извилинами». Конференция IEEE по компьютерному зрению и распознаванию образов, CVPR 2015, Бостон, Массачусетс, США, 7–12 июня 2015 г. Компьютерное общество IEEE. стр. 1–9. arXiv : 1409.4842 . дои : 10.1109/CVPR.2015.7298594 . ISBN 978-1-4673-6964-0 .
- ^ Русаковский, Ольга ; Дэн, Цзя; Су, Хао; Краузе, Джонатан; Сатиш, Санджив; Ма, Шон; Хуан, Чжихэн; Карпаты, Андрей ; Хосла, Адитья; Бернштейн, Майкл; Берг, Александр К.; Фей-Фей, Ли (2014). Image Net « Крупномасштабная задача визуального распознавания ». arXiv : 1409.0575 [ cs.CV ].
- ^ «Алгоритм распознавания лиц совершит революцию в поиске изображений» . Обзор технологий . 16 февраля 2015 г. Архивировано из оригинала 20 сентября 2020 г. Проверено 27 октября 2017 г.
- ^ Баккуш, Моэз; Мамалет, Франк; Вольф, Кристиан; Гарсия, Кристоф; Баскурт, Атилла (16 ноября 2011 г.). «Последовательное глубокое обучение для распознавания действий человека». В Салахе Альберт Али; Лепри, Бруно (ред.). Понимание человеческого поведения . Конспекты лекций по информатике. Том. 7065. Шпрингер Берлин Гейдельберг. стр. 29–39. CiteSeerX 10.1.1.385.4740 . дои : 10.1007/978-3-642-25446-8_4 . ISBN 978-3-642-25445-1 .
- ^ Цзи, Шуйван; Сюй, Вэй; Ян, Мин; Ю, Кай (01 января 2013 г.). «3D-сверточные нейронные сети для распознавания действий человека». Транзакции IEEE по анализу шаблонов и машинному интеллекту . 35 (1): 221–231. CiteSeerX 10.1.1.169.4046 . дои : 10.1109/TPAMI.2012.59 . ISSN 0162-8828 . ПМИД 22392705 . S2CID 1923924 .
- ^ Ли, Вэйпин (2018). «Распознавание языка жестов без временной , Хуан, Цзе; Чжан . Цилинь ; » сегментации
- ^ Карпати, Андрей и др. « Крупномасштабная классификация видео с помощью сверточных нейронных сетей. Архивировано 6 августа 2019 г. в Wayback Machine ». Конференция IEEE по компьютерному зрению и распознаванию образов (CVPR). 2014.
- ^ Симонян, Карен; Зиссерман, Эндрю (2014). «Двухпотоковые сверточные сети для распознавания действий в видео». arXiv : 1406.2199 [ cs.CV ]. (2014).
- ^ Ван, Ле; Дуань, Сюйхуань; Чжан, Цилинь; Ню, Чжэньсин; Хуа, Банда; Чжэн, Наньнин (22 мая 2018 г.). «Segment-Tube: локализация пространственно-временных действий в необрезанных видео с покадровой сегментацией» (PDF) . Датчики . 18 (5): 1657. Бибкод : 2018Senso..18.1657W . дои : 10.3390/s18051657 . ISSN 1424-8220 . ПМЦ 5982167 . ПМИД 29789447 . Архивировано (PDF) из оригинала 1 марта 2021 г. Проверено 14 сентября 2018 г.
- ^ Дуань, Сюйхуань; Ван, Ле; Чжай, Чанбо; Чжэн, Наньнин; Чжан, Цилинь; Ню, Чжэньсин; Хуа, Банда (2018). «Совместная локализация пространственно-временных действий в необрезанных видео с покадровой сегментацией». 2018 25-я Международная конференция IEEE по обработке изображений (ICIP) . 25-я Международная конференция IEEE по обработке изображений (ICIP). стр. 918–922. дои : 10.1109/icip.2018.8451692 . ISBN 978-1-4799-7061-2 .
- ^ Тейлор, Грэм В.; Фергюс, Роб; ЛеКун, Янн; Бреглер, Кристоф (1 января 2010 г.). Сверточное обучение пространственно-временных характеристик . Материалы 11-й Европейской конференции по компьютерному зрению: Часть VI. ECCV'10. Берлин, Гейдельберг: Springer-Verlag. стр. 140–153. ISBN 978-3-642-15566-6 . Архивировано из оригинала 31 марта 2022 г. Проверено 31 марта 2022 г.
- ^ Ле, QV; Цзоу, Вайоминг; Юнг, С.Ю.; Нг, АЮ (01 января 2011 г.). «Изучение иерархических инвариантных пространственно-временных особенностей для распознавания действий с независимым анализом подпространства». ЦВПР 2011 . ЦВПР '11. Вашингтон, округ Колумбия, США: Компьютерное общество IEEE. стр. 3361–3368. CiteSeerX 10.1.1.294.5948 . дои : 10.1109/CVPR.2011.5995496 . ISBN 978-1-4577-0394-2 . S2CID 6006618 .
- ^ Грефенштетт, Эдвард; Блансом, Фил; де Фрейтас, Нандо; Герман, Карл Мориц (29 апреля 2014 г.). «Глубокая архитектура для семантического анализа». arXiv : 1404.7296 [ cs.CL ].
- ^ Мениль, Грегуар; Дэн, Ли; Гао, Цзяньфэн; Он, Сяодун; Шен, Йелун (апрель 2014 г.). «Изучение семантических представлений с использованием сверточных нейронных сетей для веб-поиска – исследования Microsoft» . Исследования Майкрософт . Архивировано из оригинала 15 сентября 2017 г. Проверено 17 декабря 2015 г.
- ^ Кальхбреннер, Нал; Грефенштетт, Эдвард; Блансом, Фил (08 апреля 2014 г.). «Сверточная нейронная сеть для моделирования предложений». arXiv : 1404.2188 [ cs.CL ].
- ^ Ким, Юн (25 августа 2014 г.). «Сверточные нейронные сети для классификации предложений». arXiv : 1408.5882 [ cs.CL ].
- ^ Коллоберт, Ронан и Джейсон Уэстон. « Единая архитектура для обработки естественного языка: глубокие нейронные сети с многозадачным обучением. Архивировано 4 сентября 2019 г. в Wayback Machine ». Материалы 25-й международной конференции по машинному обучению. АКМ, 2008.
- ^ Коллобер, Ронан; Уэстон, Джейсон; Ботту, Леон; Карлен, Майкл; Кавукчуоглу, Корай; Кукса, Павел (2 марта 2011 г.). «Обработка естественного языка (почти) с нуля». arXiv : 1103.0398 [ cs.LG ].
- ^ Инь, Вт; Канн, К; Ю, М; Шютце, Х (2 марта 2017 г.). «Сравнительное исследование CNN и RNN для обработки естественного языка». arXiv : 1702.01923 [ cs.LG ].
- ^ Бай, С.; Колтер, Дж.С.; Колтун, В. (2018). «Эмпирическая оценка общих сверточных и рекуррентных сетей для моделирования последовательностей». arXiv : 1803.01271 [ cs.LG ].
- ^ Грубер, Н. (2021). «Обнаружение динамики действия в тексте с помощью рекуррентной нейронной сети». Нейронные вычисления и их приложения . 33 (12): 15709–15718. дои : 10.1007/S00521-021-06190-5 . S2CID 236307579 .
- ^ Хаотянь, Дж.; Чжун, Ли; Цяньсяо, Ли (2021). «Теория аппроксимации сверточных архитектур для моделирования временных рядов». Международная конференция по машинному обучению . arXiv : 2107.09355 .
- ^ Рен, Ханьшэн; Сюй, Бисюн; Ван, Юйцзин; Йи, Чао; Хуан, Конгруй; Коу, Сяоюй; Син, Тони; Ян, Мао; Тонг, Цзе; Чжан, Ци (2019). Служба обнаружения аномалий временных рядов в Microsoft | Материалы 25-й Международной конференции ACM SIGKDD по обнаружению знаний и интеллектуальному анализу данных . arXiv : 1906.03821 . дои : 10.1145/3292500.3330680 . S2CID 182952311 .
- ^ Валлах, Ижар; Дзамба, Майкл; Хейфец, Авраам (9 октября 2015 г.). «AtomNet: глубокая сверточная нейронная сеть для прогнозирования биологической активности при открытии лекарств на основе структуры». arXiv : 1510.02855 [ cs.LG ].
- ^ Йосински, Джейсон; Клюн, Джефф; Нгуен, Ань; Фукс, Томас; Липсон, Ход (22 июня 2015 г.). «Понимание нейронных сетей посредством глубокой визуализации». arXiv : 1506.06579 [ cs.CV ].
- ^ «У стартапа из Торонто есть более быстрый способ найти эффективные лекарства» . Глобус и почта . Архивировано из оригинала 20 октября 2015 г. Проверено 9 ноября 2015 г.
- ^ «Стартап использует суперкомпьютеры для поиска лекарств» . KQED Ваше будущее . 27 мая 2015 г. Архивировано из оригинала 6 декабря 2018 г. Проверено 9 ноября 2015 г.
- ^ Челлапилла, К; Фогель, Д.Б. (1999). «Развитие нейронных сетей для игры в шашки, не полагаясь на экспертные знания». IEEE Транснейронная сеть . 10 (6): 1382–91. дои : 10.1109/72.809083 . ПМИД 18252639 .
- ^ Челлапилла, К.; Фогель, Д.Б. (2001). «Развитие экспертной программы игры в шашки без использования человеческого опыта». Транзакции IEEE в эволюционных вычислениях . 5 (4): 422–428. дои : 10.1109/4235.942536 .
- ^ Фогель, Дэвид (2001). Blondie24: Игра на грани искусственного интеллекта . Сан-Франциско, Калифорния: Морган Кауфманн. ISBN 978-1558607835 .
- ^ Кларк, Кристофер; Сторки, Амос (2014). «Обучение глубоких сверточных нейронных сетей игре в го». arXiv : 1412.3409 [ cs.AI ].
- ^ Мэддисон, Крис Дж.; Хуанг, Аджа; Суцкевер, Илья; Сильвер, Дэвид (2014). «Перемещение оценки в Go с использованием глубоких сверточных нейронных сетей». arXiv : 1412.6564 [ cs.LG ].
- ^ «АльфаГо – Google DeepMind» . Архивировано из оригинала 30 января 2016 года . Проверено 30 января 2016 г.
- ^ Бай, Шаоцзе; Колтер, Дж. Зико; Колтун, Владлен (19 апреля 2018 г.). «Эмпирическая оценка общих сверточных и рекуррентных сетей для моделирования последовательностей». arXiv : 1803.01271 [ cs.LG ].
- ^ Ю, Фишер; Колтун, Владлен (30 апреля 2016 г.). «Многомасштабная агрегация контекста с помощью расширенных сверток». arXiv : 1511.07122 [ cs.CV ].
- ^ Боровых, Анастасия; Бохте, Сандер; Остерли, Корнелис В. (17 сентября 2018 г.). «Условное прогнозирование временных рядов с помощью сверточных нейронных сетей». arXiv : 1703.04691 [ stat.ML ].
- ^ Миттельман, Рони (3 августа 2015 г.). «Моделирование временных рядов с помощью непрореженных полностью сверточных нейронных сетей». arXiv : 1508.00317 [ stat.ML ].
- ^ Чен, Итянь; Канг, Янфэй; Чен, Исюн; Ван, Цзычжоу (11 июня 2019 г.). «Вероятностное прогнозирование с помощью временной сверточной нейронной сети». arXiv : 1906.04397 [ stat.ML ].
- ^ Чжао, Бендонг; Лу, Хуаньчжан; Чен, Шанфэн; Лю, Цзюньлян; У, Донгья (01 февраля 2017 г.). «Сверточные нейронные сети для классов временных рядов». Журнал системной инженерии и электроники . 28 (1): 162–169. дои : 10.21629/JSEE.2017.01.18 .
- ^ Петнехази, Габор (21 августа 2019 г.). «QCNN: Квантильная сверточная нейронная сеть». arXiv : 1908.07978 [ cs.LG ].
- ^ Хуберт Мара (07.06.2019), HeiCuBeDa Hilprecht - Набор эталонных данных Heidelberg Cuneiform для коллекции Hilprecht (на немецком языке), heiDATA - институциональный репозиторий исследовательских данных Гейдельбергского университета, doi : 10.11588/data/IE8CCN
- ^ Хуберт Мара и Бартош Богач (2019), «Взлом кода сломанных планшетов: задача обучения аннотированному клинописному письму в нормализованных наборах 2D и 3D данных», Материалы 15-й Международной конференции по анализу и распознаванию документов (ICDAR) (на немецком языке) , Сидней, Австралия, стр. 148–153, номер документа : 10.1109/ICDAR.2019.00032 , ISBN. 978-1-7281-3014-9 , S2CID 211026941
- ^ Богач, Бартош; Мара, Хуберт (2020), «Периодическая классификация трехмерных клинописных табличек с геометрическими нейронными сетями», Материалы 17-й Международной конференции по границам распознавания рукописного текста (ICFHR) , Дортмунд, Германия
- ^ Презентация документа ICFHR о периодической классификации трехмерных клинописных табличек с геометрическими нейронными сетями на YouTube
- ^ Дурджой Сен Майтра; Уджвал Бхаттачарья; С.К. Паруи, «Общий подход к распознаванию рукописных символов в нескольких сценариях на основе CNN». Архивировано 16 октября 2023 г. в Wayback Machine , в «Анализ и распознавание документов» (ICDAR), 13-я Международная конференция 2015 г., том, №, стр. 1021–1025, 23–26 августа 2015 г.
- ^ «НИПС 2017» . Симпозиум по интерпретируемому машинному обучению . 20 октября 2017 г. Архивировано из оригинала 07 сентября 2019 г. Проверено 12 сентября 2018 г.
- ^ Цзан, Цзиньлян; Ван, Ле; Лю, Цзыи; Чжан, Цилинь; Хуа, Банда; Чжэн, Наньнин (2018). «Временно-взвешенная сверточная нейронная сеть, основанная на внимании, для распознавания действий». Приложения и инновации искусственного интеллекта . ИФИП: Достижения в области информационных и коммуникационных технологий. Том. 519. Чам: Springer International Publishing. стр. 97–108. arXiv : 1803.07179 . дои : 10.1007/978-3-319-92007-8_9 . ISBN 978-3-319-92006-1 . ISSN 1868-4238 . S2CID 4058889 .
- ^ Ван, Ле; Цзан, Цзиньлян; Чжан, Цилинь; Ню, Чжэньсин; Хуа, Банда; Чжэн, Наньнин (21 июня 2018 г.). «Распознавание действий с помощью временной взвешенной сверточной нейронной сети, учитывающей внимание» (PDF) . Датчики . 18 (7): 1979. Бибкод : 2018Senso..18.1979W . дои : 10.3390/s18071979 . ISSN 1424-8220 . ПМК 6069475 . ПМИД 29933555 . Архивировано (PDF) из оригинала 13 сентября 2018 г. Проверено 14 сентября 2018 г.
- ^ Онг, Хао И; Чавес, Кевин; Хонг, Август (18 августа 2015 г.). «Распределенное глубокое Q-обучение». arXiv : 1508.04186v2 [ cs.LG ].
- ^ Мних, Владимир; и др. (2015). «Контроль на человеческом уровне посредством глубокого обучения с подкреплением». Природа . 518 (7540): 529–533. Бибкод : 2015Natur.518..529M . дои : 10.1038/nature14236 . ПМИД 25719670 . S2CID 205242740 .
- ^ Сан, Р.; Сешнс, К. (июнь 2000 г.). «Самосегментация последовательностей: автоматическое формирование иерархий последовательного поведения». Транзакции IEEE о системах, человеке и кибернетике. Часть B: Кибернетика . 30 (3): 403–418. CiteSeerX 10.1.1.11.226 . дои : 10.1109/3477.846230 . ISSN 1083-4419 . ПМИД 18252373 .
- ^ «Сверточные сети глубоких убеждений на CIFAR-10» (PDF) . Архивировано (PDF) из оригинала 30 августа 2017 г. Проверено 18 августа 2017 г.
- ^ Ли, Хонглак; Гросс, Роджер; Ранганатх, Раджеш; Нг, Эндрю Ю. (1 января 2009 г.). «Сверточные сети глубокого убеждения для масштабируемого неконтролируемого обучения иерархических представлений». Материалы 26-й ежегодной международной конференции по машинному обучению . АКМ. стр. 609–616. CiteSeerX 10.1.1.149.6800 . дои : 10.1145/1553374.1553453 . ISBN 9781605585161 . S2CID 12008458 .
- ^ Кейд Мец (18 мая 2016 г.). «Google создала собственные чипы для работы своих ботов с искусственным интеллектом» . Проводной . Архивировано из оригинала 13 января 2018 года . Проверено 6 марта 2017 г.
Внешние ссылки [ править ]
- CS231n: Сверточные нейронные сети для визуального распознавания — зрении Стэнфордский компьютерном курс информатики Андрея Карпати по CNN в
Дифференцируемые вычисления |
|---|