Апач Друид
| Оригинальный автор(ы) | Метарынки |
|---|---|
| Разработчик(и) | Фонд программного обеспечения Apache |
| Стабильная версия | 30.0.0 [2] |
| Репозиторий | github.com/apache/druid |
| Написано в | Ява |
| Операционная система | Кросс-платформенный |
| Тип | |
| Лицензия | Лицензия Апач 2.0 |
| Веб-сайт | друид |
Druid — это столбцово-ориентированное распределенное с открытым исходным кодом , хранилище данных написанное на Java . Druid предназначен для быстрого приема огромных объемов данных о событиях и выполнения запросов с малой задержкой поверх данных. [3] Название Druid происходит от изменяющего форму, класса Druid, во многих ролевых играх , чтобы отразить, что архитектура системы может меняться для решения различных типов проблем с данными.
Druid обычно используется в приложениях бизнес-аналитики — OLAP для анализа больших объемов данных в реальном времени и исторических данных. [4] Druid используется в производстве такими технологическими компаниями, как Alibaba , [4] Эйрбнб , [4] Циско , [5] [4] eBay , [6] Лифт , [7] Нетфликс , [8] PayPal , [4] Пинтерест , [9] Реддит , [10] Твиттер , [11] Уолмарт , [12] Фонд Викимедиа [13] и Яху . [14]
История
[ редактировать ]Компания Druid была основана в 2011 году Эриком Четтером, Фанджином Янгом, Джаном Мерлино и Вадимом Огиевецким. [15] для поддержки аналитического продукта Metamarkets. В октябре 2012 года проект был открыт под лицензией GPL. [16] [17] [18] и перешел на лицензию Apache в феврале 2015 года. [19] [20]
Архитектура
[ редактировать ]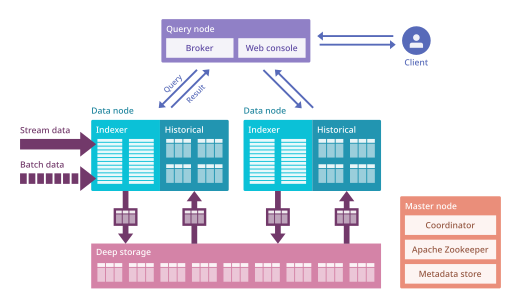
Полностью развернутый Druid работает как кластер специализированных процессов (в Druid называемых узлами) для поддержки отказоустойчивой архитектуры. [21] где данные хранятся избыточно и нет единой точки отказа. [22] Кластер включает в себя внешние зависимости для координации ( Apache ZooKeeper ), хранилище метаданных (например, MySQL , PostgreSQL или Derby ) и глубокое хранилище (например, HDFS или Amazon S3 ) для постоянного резервного копирования данных.
Управление запросами
[ редактировать ]Клиентские запросы сначала попадают к узлам-брокерам, которые перенаправляют их соответствующим узлам данных (как исторических, так и в реальном времени). Поскольку сегменты Druid могут быть секционированы, для входящего запроса могут потребоваться данные из нескольких сегментов и разделов (или осколков ), хранящихся на разных узлах кластера. Брокеры могут узнать, какие узлы содержат необходимые данные, а также объединить частичные результаты перед возвратом агрегированного результата.
Управление кластером
[ редактировать ]Операции, связанные с управлением данными в исторических узлах, контролируются узлами-координаторами. Apache ZooKeeper используется для регистрации всех узлов, управления определенными аспектами межузловой связи и обеспечения выборов лидера.
Функции
[ редактировать ]- Прием данных с низкой задержкой (потоковая передача).
- Исследование произвольных срезов и кубиков данных.
- Субсекундные аналитические запросы.
- Приблизительные и точные расчеты.
Производительность
[ редактировать ]В 2019 году исследователи сравнили производительность Hive , Presto и Druid с помощью денормализованного теста Star Schema Benchmark, основанного на стандарте TPC-H . Druid тестировался как с использованием конфигурации «Druid Best», использующей таблицы с хешированными разделами, так и с конфигурацией «Druid Suboptimal», которая не использует хешированные разделы. [23]
Тесты проводились путем выполнения 13 запросов TPC-H с использованием коэффициента масштабирования TPC-H 30 (база данных объемом 30 ГБ), коэффициента масштабирования 100 (база данных объемом 100 ГБ) и коэффициента масштабирования 300 (база данных объемом 300 ГБ).
| Масштабный коэффициент | Улей | Скоро | Друид Лучший | Друид Неоптимальный |
|---|---|---|---|---|
| 30 | 256 с | 33 с. | 2,09 с | 3,21 с |
| 100 | 424 с | 90-е | 6,12 с | 8.08с |
| 300 | 982-е | 452 с | 7.60с | 20.02с |
Производительность Druid была измерена как минимум на 98 % выше, чем у Hive, и как минимум на 90 % выше, чем у Presto в каждом сценарии, даже при использовании субоптимизированной конфигурации Druid.
См. также
[ редактировать ]Ссылки
[ редактировать ]- ^ «Apache Druid на GitHub» . github.com . Проверено 4 мая 2021 г.
- ^ . 17 июня 2024 г. https://github.com/apache/druid/releases/tag/druid-30.0.0 .
{{cite web}}: Отсутствует или пусто|title=( помощь ) - ^ Хемсот, Николь. « Друид призывает силу в реальном времени» « . Архивировано из оригинала 27 февраля 2013 г. Проверено 7 февраля 2014 г. , Датанами , 8 ноября 2012 г.
- ^ Перейти обратно: а б с д и друид. «Друид | Создано Друидом» . druid.apache.org . Проверено 29 июня 2016 г.
- ^ Батлер, Брэндон (20 июня 2016 г.). «Под капотом платформы Cisco Tetration Analytics» . Архивировано из оригинала 26 апреля 2024 г. Проверено 23 июня 2016 г.
- ^ «Друид в Pulsar — колонка на ebay — канал блога — CSDN.NET» Проверено . 23 июня 2016 г. .
- ^ Потоковая передача SQL и Druid от Arup Malakar , получено 29 января 2020 г.
- ^ «Технический блог Netflix: анонс Suro: основа конвейера данных Netflix» . techblog.netflix.com . Проверено 23 июня 2016 г.
- ^ Pinterest: Использование рекламной аналитики с помощью Apache Druid , получено 29 января 2020 г.
- ^ «Масштабирование отчетности на Reddit — проголосовали за» . www.redditinc.com . 26 февраля 2021 г. Проверено 13 сентября 2022 г.
- ^ «Интерактивная аналитика в MoPub: запрос терабайтов данных за секунды» . блог.twitter.com . Проверено 29 января 2020 г.
- ^ Наяк, Амареш (23 февраля 2018 г.). «Аналитика потока событий в Walmart с помощью Druid» . Середина . Проверено 29 января 2020 г.
- ^ «Конференции — О’Рейли Медиа» .
- ^ «Дополнение Hadoop в Yahoo: интерактивная аналитика с Druid» . Проверено 23 июня 2016 г.
- ^ «Druid: хранилище аналитических данных в реальном времени» (PDF) .
- ^ Четтер, Эрик. « Знакомство с Друидом » . Архивировано из оригинала 08 февраля 2022 г. Проверено 12 июня 2019 г. , druid.apache.org , 24 октября 2012 г.
- ^ Хиггинботэм, Стейси. " "Метамаркеты с открытым исходным кодом Druid, его базой данных в памяти" " . Архивировано из оригинала 18 сентября 2021 г. Проверено 7 февраля 2014 г. , ГигаОМ , 24 октября 2012 г.
- ^ «Metamarkets Open Sources Druid, хранилище потоковых данных в реальном времени» . Yahoo Новости . 24 октября 2012 г. Проверено 24 июля 2023 г.
- ^ Харрис, Деррик (20 февраля 2015 г.). «База данных реального времени Druid переходит на лицензию Apache» . Архивировано из оригинала 22 августа 2015 г. Проверено 4 августа 2015 г.
- ^ «Druid получает версию с открытым исходным кодом под лицензией Apache» . Проверено 4 августа 2015 г.
- ^ «Документация проекта Друид» .
- ^ Ян, Слух; Четтер, Эрик; Леоте, Ксавье; Рэй, Нельсон; Мерлино, Джиан; Гангули, Дип. « Druid: хранилище аналитических данных в реальном времени» ( PDF) . , Метамаркеты , дата обращения 6 февраля 2014 г.
- ^ Коррейя, Хосе; Коста, Карлос; Сантос, Марибель Ясмина (2019). «Вызов производительности SQL-on-Hadoop с помощью Apache Druid» . В Абрамовиче, Витольд; Корчуэло, Рафаэль (ред.). Бизнес-информационные системы . Конспекты лекций по обработке деловой информации. Том. 353. Чам: Международное издательство Springer. стр. 149–161. дои : 10.1007/978-3-030-20485-3_12 . hdl : 1822/66785 . ISBN 978-3-030-20485-3 . S2CID 190005302 .