Апач Кафка
В этой статье есть несколько проблем. Пожалуйста, помогите улучшить его или обсудите эти проблемы на странице обсуждения . ( Узнайте, как и когда удалять эти шаблонные сообщения )
|
 | |
| Оригинальный автор(ы) | |
|---|---|
| Разработчик(и) | Фонд программного обеспечения Apache |
| Первоначальный выпуск | январь 2011 г [ 2 ] |
| Стабильная версия | 3.7.1 [ 3 ] |
| Репозиторий | |
| Написано в | Скала , Ява |
| Операционная система | Кросс-платформенный |
| Тип | Потоковая обработка , Брокер сообщений |
| Лицензия | Лицензия Апач 2.0 |
| Веб-сайт | Кафка |
Apache Kafka — это распределенное хранилище событий и платформа потоковой обработки . Это система с открытым исходным кодом , разработанная Apache Software Foundation и написанная на Java и Scala . Целью проекта является создание единой платформы с высокой пропускной способностью и низкой задержкой для обработки потоков данных в реальном времени. Kafka может подключаться к внешним системам (для импорта/экспорта данных) через Kafka Connect и предоставляет библиотеки Kafka Streams для приложений потоковой обработки. Kafka использует двоичный протокол на основе TCP , который оптимизирован для повышения эффективности и опирается на абстракцию «набора сообщений», которая естественным образом группирует сообщения вместе, чтобы уменьшить накладные расходы на передачу данных по сети. Это «приводит к более крупным сетевым пакетам, более крупным последовательным дисковым операциям, смежным блокам памяти [...], что позволяет Kafka превращать прерывистый поток случайных записей сообщений в линейные записи». [ 4 ]
История
[ редактировать ]Изначально Kafka была разработана в LinkedIn , а в начале 2011 года ее исходный код был открыт с открытым исходным кодом. Джей Крепс , Неха Наркхеде и Джун Рао участвовали в создании Kafka. [ 5 ] Выпуск инкубатора Apache произошел 23 октября 2012 года. [ 6 ] Джей Крепс решил назвать программу в честь автора Франца Кафки , потому что это «система, оптимизированная для написания», и ему нравились работы Кафки. [ 7 ]
Приложения
[ редактировать ]Apache Kafka основан на журнале коммитов и позволяет пользователям подписываться на него и публиковать данные в любом количестве систем или приложений реального времени. Примеры приложений включают в себя управление подбором пассажиров и водителей в Uber , предоставление аналитики в реальном времени и прогнозное обслуживание «умного дома» British Gas , а также выполнение многочисленных услуг в реальном времени по всей LinkedIn. [ 8 ]
Архитектура
[ редактировать ]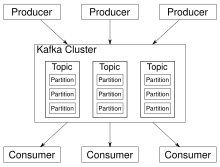
Kafka хранит сообщения «ключ-значение», поступающие от произвольного множества процессов, называемых производителями . Данные могут быть разделены на разные «разделы» в разных «темах». Внутри раздела сообщения строго упорядочены по смещениям (положению сообщения внутри раздела), индексируются и сохраняются вместе с отметкой времени. Другие процессы, называемые «потребителями», могут читать сообщения из разделов. Для потоковой обработки Kafka предлагает API Streams, который позволяет писать приложения Java, которые потребляют данные из Kafka и записывают результаты обратно в Kafka. Apache Kafka также работает с внешними системами потоковой обработки, такими как Apache Apex , Apache Beam , Apache Flink , Apache Spark , Apache Storm и Apache NiFi .
Kafka работает в кластере из одного или нескольких серверов (называемых брокерами), а разделы всех тем распределяются по узлам кластера. Кроме того, разделы реплицируются на несколько брокеров. Эта архитектура позволяет Kafka доставлять огромные потоки сообщений отказоустойчивым способом и позволяет ей заменить некоторые традиционные системы обмена сообщениями, такие как служба сообщений Java (JMS), расширенный протокол очереди сообщений (AMQP) и т. д. Начиная с версии 0.11. 0.0 Kafka предлагает транзакционные записи , которые обеспечивают однократную обработку потока с использованием Streams API.
Kafka поддерживает два типа тем: обычные и сжатые. Обычные темы могут быть настроены с указанием времени хранения или ограничения пространства. Если существуют записи старше указанного срока хранения или если ограничение пространства для раздела превышено, Kafka может удалить старые данные, чтобы освободить место для хранения. По умолчанию для тем настроен срок хранения 7 дней, но также возможно хранить данные неограниченное время. Для сжатых тем срок действия записей не ограничен во времени или пространстве. Вместо этого Kafka рассматривает более поздние сообщения как обновления более ранних сообщений с тем же ключом и гарантирует никогда не удалять последнее сообщение для каждого ключа. Пользователи могут полностью удалять сообщения, записывая так называемое сообщение-захоронение с нулевым значением для определенного ключа.
В Kafka есть пять основных API:
- API-интерфейс производителя — позволяет приложению публиковать потоки записей.
- Consumer API — позволяет приложению подписываться на темы и обрабатывать потоки записей.
- Connect API — выполняет многократно используемые API-интерфейсы производителя и потребителя, которые могут связать темы с существующими приложениями.
- Streams API — этот API преобразует входные потоки в выходные и выдает результат.
- API администратора — используется для управления темами, брокерами и другими объектами Kafka.
API-интерфейсы потребителя и производителя отделены от основных функций Kafka посредством базового протокола обмена сообщениями . Это позволяет писать совместимые уровни API на любом языке программирования, которые будут столь же эффективны, как API Java, поставляемые в комплекте с Kafka. Проект Apache Kafka поддерживает список таких сторонних API.
API-интерфейсы Кафки
[ редактировать ]Подключить API
[ редактировать ]Kafka Connect (или Connect API) — это платформа для импорта/экспорта данных из/в другие системы. Он был добавлен в выпуске Kafka 0.9.0.0 и внутри использует API-интерфейсы производителя и потребителя. Сама платформа Connect выполняет так называемые «коннекторы», реализующие реальную логику чтения/записи данных из других систем. API Connect определяет программный интерфейс, который необходимо реализовать для создания специального соединителя. Многие коннекторы с открытым исходным кодом и коммерческие соединители для популярных систем данных уже доступны. Однако сам Apache Kafka не включает в себя готовые к использованию соединители.
API потоков
[ редактировать ]Kafka Streams (или Streams API) — это библиотека потоковой обработки, написанная на Java. Он был добавлен в выпуске Kafka 0.10.0.0. Библиотека позволяет разрабатывать масштабируемые, эластичные и полностью отказоустойчивые приложения потоковой обработки с отслеживанием состояния. Основной API — это доменно-ориентированный язык (DSL) потоковой обработки, который предлагает операторы высокого уровня, такие как фильтр, карта , группировка, обработка окон, агрегация, соединения и понятие таблиц. Кроме того, API процессора можно использовать для реализации пользовательских операторов для более низкоуровневого подхода к разработке. API DSL и процессора также можно смешивать. Для обработки потока с сохранением состояния Kafka Streams использует RocksDB для поддержания состояния локального оператора. Поскольку RocksDB может записывать на диск, поддерживаемое состояние может быть больше, чем доступная основная память. В целях отказоустойчивости все обновления локальных хранилищ состояний также записываются в тему в кластере Kafka. Это позволяет воссоздать состояние, прочитав эти темы, и передать все данные в RocksDB. Последняя версия Streams API — 2.8.0. [ 9 ] Ссылка также содержит информацию о том, как обновиться до последней версии. [ 10 ]
Совместимость версий
[ редактировать ]До версии 0.9.x брокеры Kafka обратно совместимы только со старыми клиентами. Начиная с Kafka 0.10.0.0, брокеры также совместимы с новыми клиентами. Если новый клиент подключается к старому брокеру, он может использовать только те функции, которые поддерживает брокер. Для Streams API полная совместимость начинается с версии 0.10.1.0: приложение Kafka Streams 0.10.1.0 несовместимо с брокерами 0.10.0 или более ранних версий.
Производительность
[ редактировать ]Мониторинг сквозной производительности требует отслеживания показателей брокеров, потребителей и производителей в дополнение к мониторингу ZooKeeper , который Kafka использует для координации между потребителями. [ 11 ] [ 12 ] В настоящее время существует несколько платформ мониторинга для отслеживания производительности Kafka. В дополнение к этим платформам сбор данных Kafka также можно выполнять с помощью инструментов, обычно входящих в состав Java, включая JConsole . [ 13 ]
См. также
[ редактировать ]- КроликMQ
- Апач Пульсар
- Редис
- НАТС
- Апач Флинк
- Апач Самза
- Потоковая передача Apache Spark
- Служба распространения данных
- Шаблоны корпоративной интеграции
- Корпоративная система обмена сообщениями
- Потоковая аналитика
- SOA, управляемая событиями
- Поток данных Хортонворкс
- Промежуточное программное обеспечение, ориентированное на сообщения
- Сервис-ориентированная архитектура
Ссылки
[ редактировать ]- ^ «Apache Kafka на GitHub» . github.com . Архивировано из оригинала 16 января 2023 года . Проверено 5 марта 2018 г.
- ^ «Kafka с открытым исходным кодом, распределенная очередь сообщений LinkedIn» . Архивировано из оригинала 26 декабря 2022 года . Проверено 27 октября 2016 г.
- ^ https://kafka.apache.org/blog#apache_kafka_371_release_announcement .
{{cite web}}: Отсутствует или пусто|title=( помощь ) - ^ "Эффективность" . kafka.apache.org . Проверено 19 сентября 2019 г.
- ^ Ли, С. (2020). Он оставил свою высокооплачиваемую работу в LinkedIn, а затем построил бизнес на 4,5 миллиарда долларов в нише, о которой вы никогда не слышали. Форбс. Получено 8 июня 2021 г. из Forbes_Kreps. Архивировано 31 января 2023 г. в Wayback Machine .
- ^ «Инкубатор Apache: статус инкубации Kafka» . Архивировано из оригинала 17 октября 2022 г. Проверено 17 октября 2022 г.
- ^ Наркхеде, Неха; Шапира, Гвен; Палино, Тодд (2017). «Глава 1». Кафка: Полное руководство . О'Рейли. ISBN 9781491936115 .
Люди часто спрашивают, как Kafka получила свое название и имеет ли оно какое-либо отношение к самому приложению. Джей Крепс высказал следующее мнение: «Я думал, что, поскольку Кафка — это система, оптимизированная для письма, имя писателя будет иметь смысл. В колледже я посещал много уроков литературы, и мне нравился Франц Кафка».
- ^ «Что такое Апач Кафка» . confluent.io . Архивировано из оригинала 17 августа 2020 г. Проверено 4 мая 2018 г.
- ^ «Апач Кафка» . Апач Кафка . Архивировано из оригинала 10 сентября 2021 г. Проверено 10 сентября 2021 г.
- ^ «Апач Кафка» . Апач Кафка . Проверено 10 сентября 2021 г.
- ^ «Мониторинг показателей производительности Kafka» . 06 апреля 2016 г. Архивировано из оригинала 08.11.2020 . Проверено 5 октября 2016 г.
- ^ Музакитис, Эван (6 апреля 2016 г.). «Мониторинг показателей производительности Kafka» . Датадог . Архивировано из оригинала 08.11.2020 . Проверено 5 октября 2016 г.
- ^ «Сбор метрик производительности Kafka — Datadog» . 06 апреля 2016 г. Архивировано из оригинала 27 ноября 2020 г. Проверено 5 октября 2016 г.
Внешние ссылки
[ редактировать ]| Базы данных органов управления : Национальные |
|---|
- Программное обеспечение LinkedIn
- Проекты Apache Software Foundation
- Интеграция корпоративных приложений
- Бесплатное программное обеспечение, написанное на Scala.
- Бесплатное программное обеспечение, написанное на Java (языке программирования).
- Промежуточное программное обеспечение, ориентированное на сообщения
- Продукты, связанные с сервис-ориентированной архитектурой
- программное обеспечение 2011 года
- Программное обеспечение, использующее лицензию Apache