Кодирование двоичного кода в текст
В этой статье есть несколько проблем. Пожалуйста, помогите улучшить его или обсудите эти проблемы на странице обсуждения . ( Узнайте, как и когда удалять эти шаблонные сообщения )
|
Кодирование двоичного текста в текст это кодирование данных — в виде обычного текста . Точнее, это кодирование двоичных данных в последовательность печатных символов . Эти кодировки необходимы для передачи данных, когда канал связи не допускает двоичных данных (например, электронная почта или NNTP ) или не является 8-битным . Документация PGP ( RFC 4880 ) использует термин « броня ASCII » для кодирования двоичного кода в текст при ссылке на Base64 .
Обзор
[ редактировать ]Основная потребность в кодировании двоичного текста в текст возникает из-за необходимости передавать произвольные двоичные данные по ранее существовавшим протоколам связи , которые были разработаны для передачи только текста , читаемого человеком, на английском языке . Эти протоколы связи могут быть только 7-битными (и при этом избегать определенных управляющих кодов ASCII), могут требовать разрывов строк через определенные максимальные интервалы и не могут поддерживать пробелы . Таким образом, только 94 печатных символа ASCII «безопасны» для передачи данных.
Описание
[ редактировать ]Стандарт ASCII кодирования текста использует 7 бит для кодирования символов. При этом можно закодировать 128 (т.е. 2 7 ) уникальные значения (0–127) для представления буквенных, цифровых символов и символов пунктуации, обычно используемых в английском языке , а также набор управляющих символов , которые не представляют собой печатные символы. Например, заглавная буква A представлена в 7 битах как 100 0001 2 , 0x41 (101 8 ), цифра 2 — 011 0010 2 0x32 (62 8 ), символ } — 111 1101 2 0x7D (175 8 ), и Управляющий символ RETURN — 000 1101 2 0x0D (15 8 ).
Напротив, большинство компьютеров хранят данные в памяти, организованной в восьмибитные байты . Файлы, содержащие машинно-исполняемый код и нетекстовые данные, обычно содержат все 256 возможных восьмибитных байтовых значений. Многие компьютерные программы стали полагаться на это различие между семибитным текстом и восьмибитными двоичными данными и не работали должным образом, если символы, отличные от ASCII, появлялись в данных, которые, как ожидалось, должны были включать только текст ASCII. Например, если значение восьмого бита не сохраняется, программа может интерпретировать значение байта выше 127 как флаг, указывающий ей выполнить некоторую функцию.
Однако часто желательно иметь возможность отправлять нетекстовые данные через текстовые системы, например, когда можно прикрепить файл изображения к сообщению электронной почты. Для этого данные каким-либо образом кодируются, например, восьмибитные данные кодируются в семибитные символы ASCII (обычно с использованием только буквенно-цифровых символов и знаков препинания — печатных символов ASCII). После благополучного прибытия в пункт назначения он затем декодируется обратно в восьмибитную форму. Этот процесс называется кодированием двоичного текста в текст. Многие программы выполняют это преобразование для обеспечения транспортировки данных, например PGP и GNU Privacy Guard .
Кодирование обычного текста
[ редактировать ]Методы кодирования двоичного текста также используются в качестве механизма кодирования обычного текста . Например:
- Некоторые системы имеют более ограниченный набор символов, с которыми они могут работать; они не только не являются 8-битными , некоторые даже не могут обрабатывать все печатаемые символы ASCII.
- В других системах существуют ограничения на количество символов, которые могут появляться между разрывами строк, например ограничение «1000 символов в строке» некоторых программ Simple Mail Transfer Protocol , разрешенное РФК 2821 .
- Третьи добавляют заголовки или трейлеры . к тексту
- Несколько малоизвестных, но все еще используемых протоколов используют внутриполосную сигнализацию , что вызывает путаницу, если в сообщении появляются определенные шаблоны. Наиболее известной является строка «От» (включая пробел в конце) в начале строки, используемая для разделения почтовых сообщений в формате файла mbox .
Используя кодирование двоичного текста в сообщениях, которые уже являются обычным текстом, а затем декодируя на другом конце, можно сделать такие системы полностью прозрачными . Иногда это называют «бронированием ASCII». Например, компонент ViewState ASP.NET использует кодировку base64 для безопасной передачи текста через HTTP POST во избежание коллизии разделителей .
Стандарты кодирования
[ редактировать ]В таблице ниже сравниваются наиболее используемые формы кодирования двоичного текста в текст. Указанная эффективность представляет собой соотношение между количеством бит на входе и количеством бит на закодированном выходе.
| Кодирование | Тип данных | Эффективность | Реализации языков программирования | Комментарии |
|---|---|---|---|---|
| Асия85 | Произвольный | 80% | awk. Архивировано 29 декабря 2014 г. на Wayback Machine , C , C (2) , C# , F# , Go , Java Perl , Python , Python (2). | Существует несколько вариантов этой кодировки: Base85 , btoa и т. д. |
| База32 | Произвольный | 62.5% | ANSI C , Delphi , Go , Java , C# F# , Python | |
| База36 | Целое число | ~64% | bash, C , C++ , C# , Java , Perl , PHP , Python , Visual Basic, Swift и многие другие. | Используются арабские цифры 0–9 и латинские буквы A–Z ( основной латинский алфавит ISO ). Обычно используется системами перенаправления URL-адресов , такими как TinyURL или SnipURL/Snipr, в качестве компактных буквенно-цифровых идентификаторов. |
| База45 | Произвольный | ~67% (97% [а] ) | Иди , Питон | Определено в спецификации IETF RFC 9285 для компактного включения двоичных данных в QR-код . [1] |
| База56 | Целое число | — | PHP , Python , Го | Вариант кодировки Base58, в котором дополнительно исключаются символы «1» и строчные буквы «o», чтобы минимизировать риск мошенничества и человеческих ошибок. [2] |
| База58 | Целое число | ~73% | C , C++ , Python , C# , Java | Похож на Base64, но изменен, чтобы избежать использования как небуквенно-цифровых символов (+ и /), так и букв, которые могут выглядеть неоднозначно при печати (0 – ноль, I – заглавная i, O – заглавная o и l – строчная буква L). Base58 используется для представления биткойн- адресов. [ нужна ссылка ] Некоторые системы обмена сообщениями и социальные сети разбивают строки на небуквенно-цифровые строки. Этого можно избежать, если не использовать зарезервированные символы URI, такие как +. Для SegWit его заменил Bech32, см. ниже. 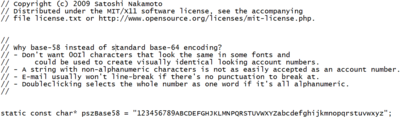 |
| База62 | Произвольный | ~74% | Ржавчина , Питон | Похож на Base64, но содержит только буквенно-цифровые символы. |
| База64 | Произвольный | 75% | awk. Архивировано 29 декабря 2014 г. на Wayback Machine , C , C (2) , Delphi , Go , Python и многих других. | Ранняя и до сих пор популярная кодировка, впервые указанная как часть RFC 989 в 1987 г. |
| База85 ( РФК 1924 ) | Произвольный | 80% | С , Питон , Питон (2) | Пересмотренная версия Ascii85 . |
| База91 [3] | Произвольный | 81% | С# Ф# | Вариант с постоянной шириной |
| базаE91 [4] | Произвольный | 81% | C, Java, PHP, сборка 8086, AWK C#, F# , Rust | Вариант с переменной шириной |
| База94 [5] | Произвольный | 82% | Питон , Си , Ржавчина | |
| База122 [6] | Произвольный | 87.5% | JavaScript , Python , Java , Base125 Python и Javascript , Go , C | |
| БазеXML [7] | Произвольный | 83.5% | C Python JavaScript | |
| Беч32 | Произвольный | 62,5% + не менее 8 символов (метка, разделитель, 6-значный код ECC ) | C, C++, JavaScript , Go , Python, Haskell , Ruby , Rust | Спецификация. [8] Используется в Биткойне и сети Lightning . [9] Часть данных кодируется по принципу Base32 с возможностью проверки и исправления до 6 неправильно набранных символов с использованием 6-значного кода BCH в конце, который также проверяет/исправляет удобочитаемую часть. Вариант Bech32m имеет небольшое изменение, которое делает его более устойчивым к изменениям длины. [10] |
| БинХекс | Произвольный | 75% | Перл , С , С (2) | MacOS Классик |
| десятичный | Целое число | ~42% | Большинство языков | Обычно представление по умолчанию для ввода/вывода от/к людям. |
| Шестнадцатеричный (Base16) | Произвольный | 50% | Большинство языков | Существует в с прописными и строчными буквами вариантах . |
| Intel HEX | Произвольный | ≲50% | библиотека C , C++ | Обычно используется для программирования EPROM , флэш-памяти NOR. чипов |
| МИМ | Произвольный | См. Quoted-printable и Base64. | См. Quoted-printable и Base64. | Контейнер кодирования для форматирования, подобного электронной почте. |
| Процентное кодирование | Текст ( URI ), произвольный ( RFC1738 ). | ~40% [б] (33–70% [с] ) | C , Python , возможно, многие другие | |
| Цитируется-для печати | Текст | ~33–100% [д] | Вероятно, многие | Сохраняет разрывы строк; обрезает строки по 76 символов |
| S-запись (шестнадцатеричный Motorola) | Произвольный | 49.6% | библиотека C , C++ | Обычно используется для программирования EPROM и NOR микросхем флэш-памяти . 49,6% предполагает 255 двоичных байтов на запись. |
| Тектроникс шестигранный | Произвольный | Обычно используется для программирования EPROM и NOR микросхем флэш-памяти . | ||
| Uuкодирование | Произвольный | ~60% ( до 70% ) | Perl , C , Delphi , Java , Python и, возможно, многие другие. | Ранняя кодировка, разработанная в 1980 году для копирования Unix-to-Unix . В значительной степени заменен MIME и yEnc. |
| Xx-кодирование | Произвольный | ~75% (аналогично Uuencoding) | С , Дельфи | Предлагается (и иногда используется) в качестве замены кодировки Uu, чтобы избежать проблем с переводом набора символов между системами ASCII и EBCDIC, которые могут повредить данные, закодированные Uu. |
| z85 ( спецификация ZeroMQ: 32/Z85 ) | Двоичный и ASCII | 80% (аналогично Ascii85/Base85) | C (оригинал), C# , Dart , Erlang , Go , Lua , Ruby , Rust и другие. | Указывает подмножество ASCII, аналогичное Ascii85 , опуская несколько символов, которые могут вызвать ошибки программы ( ` \ " ' _ , ;). Формат соответствует спецификации ZeroMQ:32/Z85 . |
| RFC 1751 ( S/КЛЮЧ ) | Произвольный | 33% | С, [11] Питон | «Конвенция о 128-битных ключах , читаемых человеком ». Людям легче читать, запоминать и печатать ряд небольших английских слов, чем десятичные или другие системы кодирования двоичного текста. [12] Каждое 64-битное число отображается в шесть коротких слов длиной от одного до четырех символов каждое из общедоступного словаря из 2048 слов. [11] |
95 кодов isprint от 32 до 126 известны как печатные символы ASCII .
Некоторые старые и сегодня необычные форматы включают кодировку BOO, BTOA и USR.
Большинство этих кодировок генерируют текст, содержащий только подмножество всех печатаемых символов ASCII : например, кодировка base64 генерирует текст, который содержит только буквы верхнего и нижнего регистра (A–Z, a–z), цифры (0–9). и символы «+», «/» и «=".
Некоторые из этих кодировок (кодирование в кавычках и процентное кодирование) основаны на наборе разрешенных символов и одном escape-символе . Разрешенные символы остаются без изменений, а все остальные символы преобразуются в строку, начинающуюся с escape-символа. Этот вид преобразования позволяет полученному тексту быть почти читаемым, поскольку буквы и цифры являются частью разрешенных символов и поэтому остаются такими, какие они есть в закодированном тексте. Эти кодировки создают кратчайший простой вывод ASCII для ввода, который в основном представляет собой печатный ASCII.
Некоторые другие кодировки ( base64 , uuencoding ) основаны на преобразовании всех возможных последовательностей шести бит в различные печатные символы. Поскольку их больше 2 6 = 64 печатных символа, это возможно. Заданная последовательность байтов преобразуется, рассматривая ее как поток битов, разбивая этот поток на куски по шесть бит и генерируя последовательность соответствующих символов. Различные кодировки различаются отображением последовательностей битов и символов и форматированием результирующего текста.
Некоторые кодировки (исходная версия BinHex и рекомендуемая кодировка для CipherSaber ) используют четыре бита вместо шести, отображая все возможные последовательности из 4 битов в 16 стандартных шестнадцатеричных цифр. Использование 4 бит на закодированный символ приводит к увеличению длины вывода на 50% по сравнению с base64, но упрощает кодирование и декодирование — независимое расширение каждого байта в источнике до двух закодированных байтов проще, чем расширение 3 исходных байтов в Base64 до 4 закодированных байтов.
Из , первых 192 кодов PETSCII 164 имеют видимое представление в кавычках: 5 (белый), 17–20 и 28–31 (цвета и элементы управления курсором), 32–90 (эквивалент ascii), 91–127 (графика) 129 (оранжевый), 133–140 (функциональные клавиши), 144–159 (цвета и управление курсором) и 160–192 (графика). [13] Это теоретически допускает кодировку, например base128, между машинами, поддерживающими PETSCII.
См. также
[ редактировать ]- Буквенно-цифровой шеллкод
- Кодировка символов
- Компиляция
- Формат номера компьютера
- Геокодирование
- Системы счисления , перечисленные по типам обозначений
- Пуникод
Примечания
[ редактировать ]- ^ Кодировка для генерации QR-кода автоматически выбирает кодировку, соответствующую входному набору символов, кодируя 2 буквенно-цифровых символа в 11 бит, а Base45 кодирует 16 бит в 3 таких символа. Таким образом, эффективность составляет 32 бита двоичных данных, закодированных в 33 бита: 97%.
- ^ Для произвольных данных; кодирование всех 189 незарезервированных символов тремя байтами, а остальных 66 символов - одним.
- ^ Для текста; кодирует только каждый из 18 зарезервированных символов.
- ^ Один байт хранится как =XX. Кодирование всех символов, кроме 94, которые в этом не нуждаются (включая пробел и табуляцию).
Ссылки
[ редактировать ]- ^ Фельтстрем, Патрик; Юнггрен, Фрейк; Гулик, Дирк-Виллем ван (11 августа 2022 г.). «Кодирование данных Base45» .
Даже в байтовом режиме типичное устройство для чтения QR-кода пытается интерпретировать последовательность байтов как текст, закодированный в UTF-8 или ISO/IEC 8859-1. ... Такие данные необходимо преобразовать в соответствующий текст, прежде чем этот текст можно будет закодировать в виде QR-кода. ... Base45 ... предлагает более компактное кодирование QR-кода.
- ^ Дагган, Росс (18 августа 2009 г.). «Целочисленное кодирование Base-56 в PHP» .
- ^ Дэйк Хе; Ю Сун; Чжэнь Цзя; Сюин Юй; Вэй Го; Вэй Хэ; Чао Ци; Сяньхуэй Лу. «Предложение по замене Base85/64 – Base91» (PDF) . Международный институт информатики и системики .
- ^ «кодировка текста из двоичного кода ASCII» . базаE91 . СоурсФордж . Проверено 20 марта 2023 г.
- ^ «Преобразуйте двоичные данные в текст с наименьшими затратами» . Записки Воракла . 18 апреля 2020 г.
- ^ Альбертсон, Кевин (26 ноября 2016 г.). «Кодировка Base-122» .
- ^ «BaseXML — для XML1.0+» . Гитхаб . 16 марта 2019 г.
- ^ «биткойн/бипс» . Гитхаб . 8 декабря 2021 г.
- ^ Расти Рассел ; и др. (15 октября 2020 г.). « Кодирование платежей в репозитории Lightning RFC» . Гитхаб .
- ^ «Формат Bech32m для адресов-свидетелей v1+» . Гитхаб . 5 декабря 2021 г.
- ^ Jump up to: Перейти обратно: а б RFC 1760 «Система одноразовых паролей S/KEY».
- ^ РФК 1751 «Конвенция о 128-битных ключах, читаемых человеком»
- ^ «Коды Commodore 64 PETSCII» . sta.c64.org .