Погрешность
Эта статья включает список общих ссылок , но в ней отсутствуют достаточные соответствующие встроенные цитаты . ( Ноябрь 2021 г. ) |
Погрешность – это статистический показатель , выражающий величину ошибки случайной выборки в результатах опроса . Чем больше погрешность, тем меньше следует быть уверенности в том, что результат опроса будет отражать результат переписи всего населения . Предел погрешности будет положительным, если совокупность отобрана не полностью и показатель результата имеет положительную дисперсию , то есть всякий раз, когда показатель изменяется .
Термин «погрешность» часто используется в контексте, не связанном с обследованием, для обозначения ошибки наблюдения при сообщении измеренных величин.
Концепция
[ редактировать ]Рассмотрим простой «да/нет» опрос как образец респонденты, отобранные из населения сообщая о проценте ответов «да» . Мы хотели бы знать, насколько близко является истинным результатом опроса всего населения , без необходимости его проведения. Если бы, гипотетически, мы провели опрос над последующими образцами респонденты (недавно отобранные из ), мы ожидаем, что последующие результаты нормально распределяться по , истинный, но неизвестный процент населения. Погрешность описывает расстояние, в пределах которого ожидается , что указанный процент этих результатов будет отличаться от .







Согласно правилу 68-95-99,7 мы ожидаем, что 95% результатов будет находиться в пределах примерно двух стандартных отклонений ( ) по обе стороны от истинного среднего значения . Этот интервал называется доверительным интервалом , а радиус (половина интервала) называется пределом погрешности , что соответствует уровню достоверности 95% .

Как правило, на уровне доверия , размер выборки населения, ожидавшего стандартного отклонения имеет погрешность



где обозначает квантиль (также обычно z-показатель ), и это стандартная ошибка .


Стандартное отклонение и стандартная ошибка
[ редактировать ]Мы ожидаем, что среднее значение нормально распределенных значений иметь стандартное отклонение, которое каким-то образом меняется в зависимости от . Чем меньше , тем шире поле. Это называется стандартной ошибкой .

Для единственного результата нашего опроса мы предполагаем , что , и что все последующие результаты вместе будет иметь разницу .



Обратите внимание, что соответствует дисперсии распределения Бернулли .

Максимальная погрешность на разных уровнях достоверности
[ редактировать ]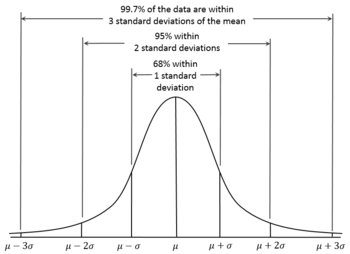
доверия Для уровня , существует соответствующий доверительный интервал относительно среднего значения , то есть интервал в пределах которых значения должно упасть с вероятностью . Точные значения определяются квантильной функцией нормального распределения (которую аппроксимирует правило 68-95-99,7).

![{\displaystyle [\mu -z_ {\gamma }\sigma,\mu +z_{\gamma }\sigma ]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/a4568060e0cffbc8dfb793aa2ef4617c89cb9e94)
Обратите внимание, что не определено для , то есть, не определено, как и .



| 0.84 | 0.994 457 883 210 | 0.9995 | 3.290 526 731 492 | |
| 0.95 | 1.644 853 626 951 | 0.99995 | 3.890 591 886 413 | |
| 0.975 | 1.959963984540 | 0.999995 | 4.417 173 413 469 | |
| 0.99 | 2.326 347 874 041 | 0.9999995 | 4.891 638 475 699 | |
| 0.995 | 2.575 829 303 549 | 0.99999995 | 5.326 723 886 384 | |
| 0.9975 | 2.807 033 768 344 | 0.999999995 | 5.730 728 868 236 | |
| 0.9985 | 2.967 737 925 342 | 0.9999999995 | 6.109 410 204 869 |
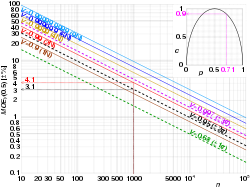

Врезная парабола иллюстрирует отношения между в и в . В примере МОЭ 95 (0,71) ≈ 0,9×±3,1% ≈ ±2,8%.





С в , мы можем произвольно установить , рассчитать , , и чтобы получить максимальную погрешность для на заданном уровне доверия и размер выборки , даже до получения фактических результатов. С







Также, что полезно, для любых сообщаемых


Конкретные пределы погрешности
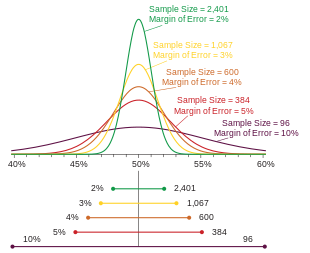
[ редактировать ]Если опрос имеет несколько процентных результатов (например, опрос, измеряющий одно предпочтение с несколькими вариантами ответов), результат, ближайший к 50%, будет иметь наибольшую погрешность. Обычно именно это число указывается как погрешность для всего опроса. Представьте себе опрос отчеты как


- (как на рисунке выше)



Когда данный процент приближается к крайним значениям 0% или 100%, его погрешность приближается к ±0%.
Сравнение процентов
[ редактировать ]Представьте себе опрос с несколькими вариантами ответов отчеты как . Как описано выше, погрешность, сообщаемая для опроса, обычно составляет , как ближе всего к 50%. Однако популярное понятие статистической ничьи или статистического ничьего касается не точности отдельных результатов, а точности ранжирования результатов . Что на первом месте?



Если бы, гипотетически, мы провели опрос над последующими образцами респонденты (недавно отобранные из ) и сообщить результат , мы могли бы использовать стандартную ошибку разницы, чтобы понять, как ожидается падение примерно . Для этого нам нужно применить сумму дисперсий , чтобы получить новую дисперсию: ,





где это ковариация и .



Таким образом (после упрощения)



Обратите внимание, что это предполагает, что близок к константе, то есть респонденты, выбравшие либо А, либо Б, почти никогда не выберут С (что делает и близка к совершенно отрицательной корреляции ). При наличии трех или более вариантов выбора в условиях более тесного конфликта выбор правильной формулы для становится сложнее.

Влияние конечной численности популяции
[ редактировать ]Приведенные выше формулы для погрешности предполагают, что население бесконечно велико и, следовательно, не зависит от размера населения. , но только от размера выборки . Согласно теории выборки , это предположение разумно, когда доля выборки мала. Предел погрешности для конкретного метода выборки по существу одинаков, независимо от того, является ли исследуемая совокупность размером со школу, город, штат или страну, при условии, что доля выборки невелика.
В тех случаях, когда доля выборки больше (на практике более 5%), аналитики могут скорректировать погрешность, используя конечную поправку на генеральную совокупность , чтобы учесть дополнительную точность, полученную за счет выборки гораздо большего процента генеральной совокупности. FPC можно рассчитать по формуле [1]

...и так, если опрос были проведены более 24%, скажем, электората в 300 000 избирателей,


Интуитивно, для достаточно больших ,


В первом случае настолько мал, что не требует коррекции. В последнем случае опрос фактически становится переписью, и ошибка выборки становится спорной.
См. также
[ редактировать ]Ссылки
[ редактировать ]- ^ Иссерлис, Л. (1918). «О значении среднего значения, рассчитанного по выборке» . Журнал Королевского статистического общества . 81 (1). Издательство Блэквелл: 75–81. дои : 10.2307/2340569 . JSTOR 2340569 . (Уравнение 1)
Источники
[ редактировать ]- Судман, Сеймур и Брэдберн, Норман (1982). Задавание вопросов: Практическое руководство по разработке анкет . Сан-Франциско: Джосси Басс. ISBN 0-87589-546-8
- Воннакотт, TH; Р. Дж. Воннакотт (1990). Вводная статистика (5-е изд.). Уайли. ISBN 0-471-61518-8 .
Внешние ссылки
[ редактировать ]- «Ошибки, теория» , Энциклопедия математики , EMS Press , 2001 [1994]
- Вайсштейн, Эрик В. «Погрешность» . Математический мир .