Постоянная структура данных
При вычислениях постоянная структура данных или не эфемерная структура данных - это структура данных , которая всегда сохраняет предыдущую версию самого себя при изменении. Такие структуры данных эффективно неизменны , так как их операции не (заметно) обновляют структуру на месте, но вместо этого всегда дают новую обновленную структуру. Термин был введен в статье Дрисколла, Сарнака, Слэтора и Тарджана 1986 года. [ 1 ]
Структура данных частично устойчива , если все версии можно получить, но можно изменить только самую новую версию. Структура данных полностью устойчива, если каждая версия может быть как доступна и модифицирована. Если есть также операция MELD или MERGE, которая может создать новую версию из двух предыдущих версий, структура данных называется Commustly Persistent . Структуры, которые не стойкие, называются эфемерными . [ 2 ]
Эти типы структур данных особенно распространены в логическом и функциональном программировании , [ 2 ] Поскольку языки в этих парадигмах препятствуют (или полностью запрещают) использование изменяющихся данных.
Частичная и полная настойчивость
[ редактировать ]В модели частичной стойкости программист может запросить любую предыдущую версию структуры данных, но может обновить только последнюю версию. Это подразумевает линейный упорядочение среди каждой версии структуры данных. [ 3 ] В полностью постоянной модели как обновления, так и запросы разрешены в любой версии структуры данных. В некоторых случаях характеристики производительности запроса или обновления более старых версий структуры данных могут быть разрешены деградировать, как и в соответствии со структурой данных веревки . [ 4 ] Кроме того, структуру данных может быть названа как постоянно постоянная, если, помимо того, что они полностью стойкие, две версии одной и той же структуры данных могут быть объединены, чтобы сформировать новую версию, которая все еще полностью устойчива. [ 5 ]
Частично постоянная структура данных
[ редактировать ]Тип структуры данных, где пользователь может запросить любую версию структуры, но может обновить только последнюю версию.
Эфемерная структура данных может быть преобразована в частично постоянную структуру данных с использованием нескольких методов.
Один из техники - с использованием рандомизированной версии дерева Ван Эмде Боас, который создается с использованием динамического идеального хэширования. Эта структура данных создается следующим образом:
- Стратифицированное дерево с M -элементами реализовано с использованием динамического идеального хэширования.
- Дерево обрезано путем деления элементов М на ведра от размера log (log n), так что элементы ведра 1 меньше, чем элементы ведра 2 и так далее.
- Максимальный элемент в каждом ведре хранится в стратифицированном дереве, и каждое ведро хранится в структуре в виде неупорядоченного списка.
Размер этой структуры данных ограничен количеством элементов, хранящихся в структуре, которая является O (M). Вставка нового максимального элемента выполняется в постоянное время O (1) ожидаемое и амортизированное время. Наконец, запрос на поиск элемента может быть сделан в этой структуре в (log (log n)) наихудшее время. [ 6 ]
Методы сохранения предыдущих версий
[ редактировать ]Копия на записи
[ редактировать ]Одним из методов создания постоянной структуры данных является использование платформы, предоставленной эфемерной структурой данных, такой как массив для хранения данных в структуре данных, и копировать всю структуру данных с использованием семантики копирования на плате . структура Это неэффективная методика, потому что вся структура данных поддержки должна быть скопирована для каждой записи, что приводит к наихудшему случаю характеристик производительности O (N · M) для M модификаций массива размера n. [ Цитация необходима ]
Толстый узел
[ редактировать ]Метод жирового узла состоит в том, чтобы записать все изменения, внесенные в поля узлов в самих узлах, не стирая старые значения полей. Это требует, чтобы узлы были разрешены произвольно «толстыми». Другими словами, каждый жирный узел содержит одну и ту же информацию и поля указателя , что и эфемерный узел, а также пространство для произвольного числа дополнительных значений поля. Каждое дополнительное значение поля имеет соответствующее имя поля и штамп версий, которая указывает версию, в которой названное поле было изменено, чтобы иметь указанное значение. Кроме того, каждый жирный узел имеет свою собственную марку версии, указывающая версию, в которой был создан узел. Единственная цель узлов, имеющих марки версий, - убедиться, что каждый узел содержит только одно значение на имя поля на версию. Чтобы перемещаться по структуре, каждое исходное значение поля в узле имеет штамп с нулем версии.
Сложность жирного узла
[ редактировать ]При использовании метода Fat Node требуется пространство O (1) для каждой модификации: просто храните новые данные. Каждая модификация требует O (1) дополнительное время для хранения модификации в конце истории модификации. Это амортизированная временная граница, предполагая, что история модификации хранится в растущем массиве . Во время доступа правильная версия на каждом узле должна быть найдена по мере прохождения структуры. Если бы были внесены изменения "M", то каждая операция доступа будет иметь замедление O (log M), вызванное стоимостью поиска ближайшей модификации в массиве.
Копирование пути
[ редактировать ]С помощью метода копирования пути копия всех узлов сделана на пути к любому узлу, который должен быть изменен. Эти изменения должны затем быть каскадированы обратно через структуру данных: все узлы, указывающие на старый узел, должны быть изменены, чтобы указать на новый узел. Эти модификации вызывают больше каскадных изменений и т. Д. До тех пор, пока не будет достигнут корневой узел.
Сложность копирования пути
[ редактировать ]С модификациями M это стоит время отдачи . Время и пространство модификации ограничены размером самого длинного пути в структуре данных и стоимостью обновления в структуре эфемерных данных. В сбалансированном бинарном дереве поиска без родителей указателям, сложность модификации наихудшего случая составляет O (Log n обновление стоимость). Тем не менее, в связанном списке сложность времени изменения случая наихудшего случая составляет O (стоимость обновления n +).
Комбинация
[ редактировать ]Driscoll, Sarnak, Slater , Tarjan Camera Up [ 1 ] С помощью способа объединить методы жирных узлов и копирование пути, достигнув замедления O (1) и (1) пространства модификации и сложности времени.
В каждом узле сохраняется одна коробка модификации. Эта коробка может содержать одну модификацию в узле-либо модификацию одного из указателей, либо к ключу узла, либо к какой-либо другой части данных, специфичных для узла-и временной меткой, когда была применена эта модификация. Первоначально поле модификации каждого узла пусто.
Всякий раз, когда доступ к узлу обращается, проверка модификации проверяется, и его временная метка сравнивается со временем доступа. (Время доступа указывает версию рассматриваемой структуры данных.) Если поле модификации пустое, или время доступа является до времени модификации, то окно модификации игнорируется, и рассматривается только нормальная часть узла. С другой стороны, если время доступа составляет после времени модификации, то используется значение в поле модификации, переоценивая это значение в узле.
Модификация узла работает так. (Предполагается, что каждая модификация касается одного указателя или аналогичного поля.) Если поле модификации узла пустое, то она заполнена модификацией. В противном случае ящик для модификации заполнен. Сделано копия узла, но использует только последние значения. Модификация выполняется непосредственно в новом узле, без использования блока модификации. (Одно из полей нового узла перезаписывается, и его модификационная коробка остается пустой.) Наконец, это изменение каскадируется для родителя узла, как и копирование пути. (Это может включать заполнение блока модификации родителя или рекурсивное копию родителя. Если у узла нет родителя - это корень - он добавляется новый корень в отсортированный массив корней.)
С помощью этого алгоритма , учитывая в любое время t, в структуре данных существует не более одного ящика для модификации со временем t. Таким образом, модификация в момент времени t разбивает дерево на три части: одна часть содержит данные с времени t, одна часть содержит данные от времени t, а одна часть не была затронута модификацией.
Сложность комбинации
[ редактировать ]Время и пространство для модификаций требуют амортизированного анализа. Модификация принимает O (1) амортизированное пространство и O (1) амортизированное время. Чтобы понять почему, используйте потенциальную функцию ϕ, где ϕ (t) - это количество полных живых узлов в t. Живые узлы T - это только узлы, которые доступны из текущего корня в текущее время (то есть после последней модификации). Полные живые узлы - это живые узлы, чьи модификационные коробки полны.
Каждая модификация включает в себя некоторое количество копий, скажем, k, за которым следует 1 изменение в поле модификации. Рассмотрим каждую из k копий. Каждый стоит o (1) пространство и время, но уменьшает потенциальную функцию на единицу. (Во -первых, узел, который необходимо скопировать, должен быть заполнен и жить, поэтому он способствует потенциальной функции. Потенциальная функция только упадет, однако, если старый узел не доступен в новом дереве. Но известно, что она Не достижимо в новом дереве. Следующий шаг в алгоритме состоит в том, чтобы изменить родителя узла, чтобы указать на копию. Заменяется пустым живым узлом, а ϕ спускается на один.) Последний шаг заполняет ящик модификации, который стоит o (1) времени и увеличивает ϕ на один.
Собрав все это вместе, изменение ϕ составляет Δϕ = 1- K. Таким образом, алгоритм принимает O (k +Δϕ) = O (1) пространство и O (k +Δϕ +1) = O (1) Время
Генерализованная форма настойчивости
[ редактировать ]Копирование пути является одним из простых методов достижения постоянства в определенной структуре данных, таких как двоичные поисковые деревья. Приятно иметь общую стратегию для реализации настойчивости, которая работает с любой данной структурой данных. Чтобы достичь этого, мы рассмотрим направленный график g . Мы предполагаем, что каждая вершина V в G имеет постоянное число C исходящих краев, которые представлены указателями. Каждая вершина имеет метку, представляющую данные. Мы считаем, что вершина имеет ограниченное число D краев, ведущих к нему, которое мы определяем как inedges ( v ). Мы разрешаем следующие различные операции на g .
- Create node (): создает новую вершину без входящих или исходящих краев.
- Переключение ( v , i , u ): меняет i тур Край v, чтобы указать на тебя
- Изменение-label ( v , x ): изменяет значение данных, хранящихся при V на x
Любая из вышеперечисленных операций выполняется в определенное время, и цель постоянного представления графика - иметь возможность получить доступ к любой версии G в любой момент времени. Для этой цели мы определяем таблицу для каждой вершины V в g . Таблица содержит C и столбцы ряды Каждая строка содержит в дополнение к указателям для исходящих краев, метку, которая представляет данные в вершине и время t , в котором была выполнена операция. В дополнение к этому существует массив инджес ( v который отслеживает все входящие края в V. ) , Когда таблица заполнена, новый стол с ряды могут быть созданы. Старая таблица становится неактивной, и новая таблица становится активной таблицей.

Создать узл
[ редактировать ]Призыв к созданию узла создает новую таблицу и устанавливает все ссылки на NULL
Смены
[ редактировать ]Если мы предположим, что изменение ( v , i , u ) называется, то есть два случая для рассмотрения.
- В таблице вершины V есть пустая строка вершины V : В этом случае мы копируем последнюю строку в таблице и изменяем край вершины V , чтобы указывать на новую вершину u
- Таблица вершины V заполнена: в этом случае нам нужно создать новую таблицу. Мы копируем последний ряд старой таблицы в новую таблицу. Нам нужно зацикливаться на массиве инджеса ( v ), чтобы позволить каждой вершине в точке массива к созданной новой таблице. В дополнение к этому нам необходимо изменить запись V в inedges (w) для каждой вершины w, такой что Edge V, w существует на графике g .
Изменение-маршрута
[ редактировать ]Он работает точно так же, как и смену, за исключением того, что вместо меня тур край вершины, мы меняем I тур этикетка.
Эффективность обобщенной постоянной структуры данных
[ редактировать ]Чтобы найти эффективность предложенной выше схемы, мы используем аргумент, определенный как кредитная схема. Кредит представляет валюту. Например, кредит может использоваться для оплаты таблицы. Аргумент гласит следующее:
- Создание одной таблицы требует одного кредита
- Каждый вызов для создания узла поставляется с двумя кредитами
- Каждый звонок к смене поставляется с одним кредитом
Схема кредита всегда должна удовлетворять следующим инвариантным: каждая строка каждой активной таблицы хранит один кредит, а таблица имеет одинаковое количество кредитов, что и количество строк. Давайте подтвердим, что инвариант применяется ко всем трем операциям создания узла, изменения изменения и изменений.
- CREATE NODE: он приобретает два кредита, один используется для создания таблицы, а другая придается одной строке, которая добавлена в таблицу. Таким образом, инвариант поддерживается.
- Изменение: есть два случая для рассмотрения. Первый случай возникает, когда в таблице еще есть хотя бы одна пустая строка. В этом случае один кредит используется для недавно вставленной строки. Второй случай происходит, когда таблица заполнена. В этом случае старая таблица становится неактивной и Кредиты трансформируются в новую таблицу в дополнение к одному кредиту, приобретенному при вызове смены. Так что в общей сложности у нас Кредиты. Один кредит будет использоваться для создания новой таблицы. Еще один кредит будет использоваться для новой строки, добавленной в таблицу, а оставшиеся кредиты D используются для обновления таблиц других вершин, которые должны указывать на новую таблицу. Мы заключаем, что инвариант поддерживается.
- Изменение-LABEL: он работает точно так же, как и смены.

В качестве резюме мы заключаем, что вызовы в create_node и вызовы в изменение_жа приведут к созданию столы. Поскольку каждая таблица имеет размер не принимая во внимание рекурсивные вызовы, тогда заполнение таблицы требует где дополнительный коэффициент D поступает от обновления инджеса на других узлах. Следовательно, объем работы, необходимой для завершения последовательности операций, ограничен количеством созданных таблиц, умноженных на Полем Каждая операция доступа может быть сделана в И есть Операции с краями и меткой, поэтому требуется Полем Мы заключаем, что существует структура данных, которая может завершить любое последовательность создания узла, изменения и изменений в .










Приложения постоянных структур данных
[ редактировать ]Следующий поиск элементов или местоположение точки
[ редактировать ]Одним из полезных приложений, которые можно эффективно решить с помощью постоянства, является следующее поиск элементов. Предположим, что есть Не пересекающиеся сегменты линий, которые не пересекают друг друга, которые параллельны оси X. Мы хотим построить структуру данных, которая может запросить точку зрения и вернуть сегмент выше (если есть). Мы начнем с решения следующего поиска элемента, используя наивный метод, тогда мы покажем, как его решить, используя метод постоянной структуры данных.

Наивный метод
[ редактировать ]Мы начинаем с сегмента вертикальной линии, который начинается с бесконечности, и мы подчиняем сегменты линий слева направо. Мы принимаем паузу каждый раз, когда сталкиваемся с конечной точкой этих сегментов. Вертикальные линии разделяют плоскость на вертикальные полоски. Если есть линейные сегменты, тогда мы можем получить вертикальные полосы, так как каждый сегмент Конечные точки. Ни один сегмент не начинается и заканчивается в полосе. Каждый сегмент либо не касается полосы, либо полностью пересекает ее. Мы можем думать о сегментах как о некоторых объектах, которые находятся в каком -то отсортированном порядке сверху вниз. Что нас волнует, так это то, где точка, на которую мы смотрим, подходит в этом порядке. Мы сортируем конечные точки сегментов по их координировать. Для каждой полосы , мы храним сегменты подмножества, которые пересекают в словаре. Когда вертикальная линия подметает сегменты линии, всякий раз, когда она проходит по левой конечной точке сегмента, мы добавляем ее в словарь. Когда он проходит через правую конечную точку сегмента, мы удаляем его из словаря. В каждой конечной точке мы сохраняем копию словаря и храним все копии, отсортированные по координаты. Таким образом, у нас есть структура данных, которая может ответить на любой запрос. Чтобы найти сегмент выше точки , мы можем посмотреть на координата Чтобы знать, какую копию или полоску она принадлежит. Тогда мы можем посмотреть на Координируйте, чтобы найти сегмент над ним. Таким образом, нам нужны два двоичных поиска, один для координировать, чтобы найти полосу или копию, а другой для Координируйте, чтобы найти сегмент над ним. Таким образом, время запроса занимает Полем В этой структуре данных пространство является проблемой, поскольку, если мы предположим, что у нас есть сегменты, структурированные таким образом, чтобы каждый сегмент начинался до конца любого другого сегмента, то пространство, необходимое для строительства структуры с использованием наивного метода будет Полем Давайте посмотрим, как мы можем построить еще одну постоянную структуру данных с тем же временем запроса, но с лучшим пространством.







Постоянный метод структуры данных
[ редактировать ]Мы можем заметить, что то, что действительно требует времени в структуре данных, используемой в наивном методе, так это то, что всякий раз, когда мы переходим от полосы к другой, нам нужно сделать снимок из любой структуры данных, которые мы используем, чтобы сохранить вещи в отсортированном порядке. Мы можем заметить, что, как только мы получим сегменты, которые пересекаются , когда мы переходим к Либо одна вещь уходит, либо одна вещь входит. Если разница между тем, что находится в и что в это только одна вставка или удаление, тогда не очень хорошая идея, чтобы копировать все из к Полем Хитрость заключается в том, что, поскольку каждая копия отличается от предыдущей только одной вставкой или удалением, нам нужно скопировать только те части, которые изменяются. Предположим, что у нас есть дерево, укорененное в Полем Когда мы вставляем ключ В дерево мы создаем новый лист, содержащий Полем Выполнение вращения для перебаланса Дерево только изменяет узлы пути от к Полем Перед вставкой ключа В дерево мы копируем все узлы на пути от к Полем Теперь у нас есть 2 версии дерева, оригинальная, которая не содержит и новое дерево, которое содержит и чей корень является копией корня Полем С точки зрения копирования пути из к не увеличивает время вставки более чем постоянным фактором, чем вставка в постоянную структуру данных принимает время. Для удаления нам нужно найти, какие узлы будут влиять на удаление. Для каждого узла затронут удалением, мы копируем путь от корня в Полем Это обеспечит новое дерево, корень которого является копией корня исходного дерева. Затем мы выполняем удаление на новом дереве. В итоге мы получим 2 версии дерева. Оригинальный, который содержит И новый, который не содержит Полем Поскольку любое удаление только изменяет путь от корня к и любой соответствующий алгоритм удаления работает в , таким образом, удаление в постоянной структуре данных принимает Полем Каждая последовательность вставки и делеции вызовет создание последовательности словарей, версий или деревьев где каждый является результатом операций Полем Если каждый содержит элементы, затем поиск в каждом принимает Полем Используя эту постоянную структуру данных, мы можем решить следующую проблему поиска элемента в Время запроса и пространство вместо Полем Пожалуйста, найдите ниже исходный код для примера, связанного со следующей задачей поиска.








Примеры постоянных структур данных
[ редактировать ]Возможно, самой простой постоянной структурой данных является односложенный список списка или лист, основанный на минусах , простой список объектов, сформированных при каждом из ссылок на следующую в списке. Это постоянно, потому что хвост списка может быть взят, что означает последние k элементы для некоторых K , а перед ним можно добавить новые узлы. Хвост не будет дублироваться, вместо этого станет обмен как старый список, так и новый список. До тех пор, пока содержимое хвоста неизменно, этот обмен будет невидимым для программы.
Многие общие справочные структуры данных, такие как деревья красных блок , [ 7 ] стеки , [ 8 ] и Treaps , [ 9 ] может быть легко адаптирован для создания постоянной версии. Некоторым другим нужно немного больше усилий, например: очереди , декеи и расширений, включая Deceves (которые имеют дополнительную операцию O (1) Min, возвращая минимальный элемент) и случайный доступ (которые имеют дополнительную операцию случайного доступа с Суб-линейный, чаще всего логарифмический, сложность).
Также существуют постоянные структуры данных, которые используют разрушительные [ нужно разъяснения ] Операции, делая их невозможными для эффективного реализации на чисто функциональных языках (например, Haskell за пределами специализированных монадов, таких как State или IO), но возможно на таких языках, как C или Java. Эти типы структур данных часто можно избежать с помощью другой конструкции. Одним из основных преимуществ использования чисто постоянных структур данных является то, что они часто ведут себя лучше в многопоточных средах.
Связанные списки
[ редактировать ]отдельности Списки по -это структура данных хлеба и масла на функциональных языках. [ 10 ] Некоторые ML -происходящие языки, такие как Haskell , являются чисто функциональными, потому что, как только узел в списке был выделен, его нельзя изменить, скопировать, ссылаться или уничтожить коллекционером мусора , когда ничто не относится к нему. (Обратите внимание, что сам ML не является чисто функциональным, но поддерживает подмножество неразрушающих операций списков, что также верно в LISP функциональных диалектах (обработка списка), таких как схема и ракетка .)
Рассмотрим два списка:
xs = [0, 1, 2] ys = [3, 4, 5]
Они будут представлены в памяти:
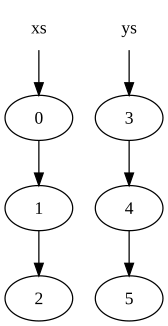
где круг указывает узел в списке (стрелка, представляющая второй элемент узла, который является указателем на другой узел).
Теперь объединяет два списка:
zs = xs ++ ys
приводит к следующей структуре памяти:

Обратите внимание, что узлы в списке xs были скопированы, но узлы в ys общие. В результате исходные списки ( xs и ys) сохраняется и не был изменен.
Причиной копии является то, что последний узел в xs (Узел, содержащий исходное значение 2) не может быть изменен, чтобы указать на начало ys, потому что это изменило бы значение xs.
Деревья
[ редактировать ]Рассмотрим бинарное дерево поиска , [ 10 ] где каждый узел в дереве имеет рекурсивный инвариант , который все подноды, содержащиеся в левом поддерево Значение хранится в узле.
Например, набор данных
xs = [a, b, c, d, f, g, h]
может быть представлено следующим бинарным деревом поиска:
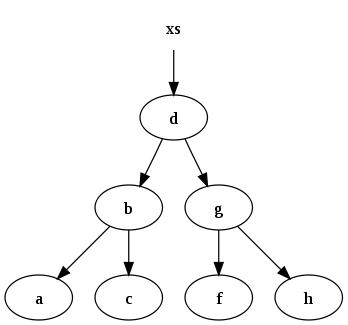
Функция, которая вставляет данные в двоичное дерево и поддерживает инвариант:
fun insert (x, E) = T (E, x, E)
| insert (x, s as T (a, y, b)) =
if x < y then T (insert (x, a), y, b)
else if x > y then T (a, y, insert (x, b))
else s
После выполнения
ys = insert ("e", xs)
Следующая конфигурация создается:
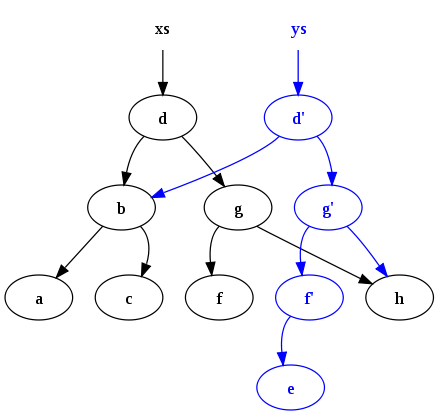
Обратите внимание на две точки: во -первых, исходное дерево ( xs) сохраняется. Во -вторых, многие общие узлы разделяются между старым деревом и новым деревом. Такой устойчивостью и обменом трудно управлять без какой -либо формы сбора мусора (GC) для автоматического освобождения узлов, которые не имеют живых ссылок, и именно поэтому GC является функцией, обычно встречающейся на языках функционального программирования .
Код
[ редактировать ]Github Repo, содержащая реализации постоянных BST, с использованием жирных узлов, копии на записи и методов копирования пути.
Чтобы использовать постоянные реализации BST, просто клонируйте репозиторий и следуйте инструкциям, представленным в файле README.
Ссылка: https://github.com/desaultiermakk/persistentbst
Постоянный хэш -массив нанесен на карту Trie
[ редактировать ]Постоянный хеш -массив, нанесенный на карту Trie, представляет собой специализированный вариант хеш -массивы Trie , который сохранит предыдущие версии в любых обновлениях. Он часто используется для реализации постоянной структуры данных карты общего назначения. [ 11 ]
Хеш -массивные попытки были первоначально описаны в статье 2001 года Филом Багвеллом под названием «Идеальные хеш -деревья». В этой статье представлена изменяющаяся хэш-таблица , где «Включение, поиск и удаление времени невелики и постоянны, независимо от размера набора клавиш, операции являются o (1). Небольшое время для вставки, поиска и удаления может быть гарантировано и пропускает Стоимость меньше, чем успешные поиски ». [ 12 ] Эта структура данных была затем изменена Rich Hickey, чтобы быть полностью устойчивым для использования на языке программирования Clojure . [ 13 ]
Концептуально, хеш -массив, отображающие попытки, работают аналогично любому общему дереву , поскольку они хранят узлы иерархически и получают их, следуя по пути вниз к конкретному элементу. Ключевое отличие состоит в том, что хэш -массивные попытки сначала используют хэш -функцию , чтобы преобразовать их ключ поиска в целое число (обычно 32 или 64 бит). Путь вниз по дереву затем определяется с использованием срезов бинарного представления этого целого числа, чтобы индексировать в редкий массив на каждом уровне дерева. Листовые узлы дерева ведут себя похожими на ведра, используемые для построения хэш -таблиц , и могут или не могут содержать несколько кандидатов в зависимости от хэш -столкновений . [ 11 ]
Большинство реализаций постоянных хеш -массивов, отображаемых, используют фактор разветвления 32 в их реализации. что на практике, в то время как вставки, удаления и поиск в постоянную хеш -массив, нанесенные на карту Trie Это означает , Сделайте любую операцию, сделайте более десятка шагов. [ 14 ]
Использование на языках программирования
[ редактировать ]Хаскелл
[ редактировать ]Haskell - это чистый функциональный язык и, следовательно, не допускает мутации. Следовательно, все структуры данных на языке стойкие, поскольку невозможно не сохранять предыдущее состояние структуры данных с функциональной семантикой. [ 15 ] Это связано с тем, что любые изменения в структуре данных, которые могут сделать предыдущие версии структуры данных недействительными, нарушает референциальную прозрачность .
В своей стандартной библиотеке Haskell обладает эффективными постоянными реализациями для связанных списков, [ 16 ] Карты (реализованные как сбалансированные деревья размера), [ 17 ] и наборы [ 18 ] среди других. [ 19 ]
Клоджюр
[ редактировать ]Как и многие языки программирования в семье LISP , Clojure содержит реализацию связанного списка, но, в отличие от других диалектов, его реализация связанного списка обеспечила устойчивость вместо того, чтобы быть настойчивым соглашением. [ 20 ] Clojure также обладает эффективными реализациями постоянных векторов, карт и наборов, основанных на постоянных попытках сопоставления хеш -массивов. Эти структуры данных реализуют обязательные части для чтения рамки сбора Java . [ 21 ]
Дизайнеры языка Clojure выступают за использование стойких структур данных по сравнению с изменчивыми структурами данных, потому что они имеют семантику ценности , что дает пользу их свободно общаться между потоками с дешевыми псевдонимами, простыми в изготовлении и независимым от языка. [ 22 ]
Эти структуры данных составляют основу поддержки Clojure для параллельных вычислений , поскольку они позволяют легко повторно обработать операции для обоснования раций данных и атомного сравнения и семантики обмена . [ 23 ]
Вере
[ редактировать ]Язык программирования ELM является чисто функциональным, как Haskell, что делает все свои структуры данных стойкими по необходимости. Он содержит постоянные реализации связанных списков, а также постоянные массивы, словари и наборы. [ 24 ]
ELM использует пользовательскую виртуальную реализацию DOM , которая использует постоянный характер данных ELM. По состоянию на 2016 год разработчики ELM сообщили, что этот виртуальный DOM позволяет языку ELM делать HTML быстрее, чем популярные JavaScript рамки React , Ember и Angular . [ 25 ]
Ява
[ редактировать ]Язык программирования Java не особенно функционален. Несмотря на это, основной пакет JDK java.util.concurrent включает в себя copyonwritearraylist и copyonwritearrayset, которые являются постоянными структурами, реализованными с использованием методов копирования на Write. Однако обычная одновременная реализация карты в Java, concurrenthashmap, однако не является постоянной. Полностью постоянные коллекции доступны в сторонних библиотеках, [ 26 ] или другие языки JVM.
JavaScript
[ редактировать ]Этот раздел может быть запутанным или неясным для читателей . ( Май 2021 ) |
Популярная фронтальная структура JavaScript часто используется вместе с системой управления состоянием, которая реализует архитектуру потока , [ 27 ] [ 28 ] Популярной реализацией которого является Redux Bibrary JavaScript . Библиотека Redux вдохновлена схемой управления государством, используемой на языке программирования ELM, что означает, что она требует, чтобы пользователи рассматривали все данные как постоянные. [ 29 ] В результате проект Redux рекомендует, чтобы в некоторых случаях пользователи использовали библиотеки для соблюдения и эффективных постоянных структур данных. По сообщениям, это обеспечивает большую производительность, чем при сравнении или создании копий регулярных объектов JavaScript. [ 30 ]
Одна такая библиотека постоянных структур данных Immutable.js основана на структурах данных, предоставленных и популяризированной Clojure и Scala. [ 31 ] Это упоминается документацией Redux как одной из возможных библиотек, которые могут обеспечить принудительную неизменность. [ 30 ] Mori.js приносит структуры данных, аналогичные структурам в Clojure к JavaScript. [ 32 ] Immer.js приносит интересный подход, в котором «создает следующее неизменное состояние, мутируя текущее». [ 33 ] Immer.js использует собственные объекты JavaScript и не эффективные постоянные структуры данных, и это может вызвать проблемы с производительностью, когда размер данных большой.
Пролог
[ редактировать ]Термины пролога естественным образом неизменны, и, следовательно, структуры данных, как правило, являются постоянными структурами данных. Их производительность зависит от обмена и коллекции мусора, предлагаемой системой Prolog. [ 34 ] Расширение терминов пролога, не способных, не всегда осуществимы из-за взрыва пространства поиска. Задержанные цели могут смягчить проблему.
Некоторые системы Prolog, тем не менее, обеспечивают разрушительные операции, такие как SetArg/3, которые могут происходить в разных вкусах, с/без копирования и без/без возврата государственных изменений. Есть случаи, когда SetArg/3 используется для обеспечения нового декларативного слоя, например, решателя ограничений. [ 35 ]
Скала
[ редактировать ]Язык программирования Scala способствует использованию постоянных структур данных для реализации программ с использованием «объектно-функционального стиля». [ 36 ] Scala содержит реализации многих постоянных структур данных, включая связанные списки, деревья красных блюдо , а также постоянную хеш -массивную карту попытки, представленные в Clojure. [ 37 ]
Сбор мусора
[ редактировать ]Поскольку постоянные структуры данных часто реализуются таким образом, что последовательные версии структуры данных разделяют основную память [ 38 ] Эргономическое использование таких структур данных обычно требует некоторой формы автоматической системы сбора мусора , такой как отсчет справочника или отметка и развертка . [ 39 ] На некоторых платформах, где используются постоянные структуры данных, это возможность не использовать сбор мусора, который, хотя это может привести к утечкам памяти , в некоторых случаях может оказать положительное влияние на общую производительность приложения. [ 40 ]
Смотрите также
[ редактировать ]- Копия на записи
- Навигационная база данных
- Постоянные данные
- Ретроактивные структуры данных
- Чисто функциональная структура данных
Ссылки
[ редактировать ]- ^ Подпрыгнуть до: а беременный Driscoll JR, Sarnak N, Sleator DD, Tarjan Re (1986). «Создание структур данных настойчивым». Труды восемнадцатого ежегодного симпозиума ACM по теории вычислений - Stoc '86 . С. 109–121. Citeseerx 10.1.1.133.4630 . doi : 10.1145/12130.12142 . ISBN 978-0-89791-193-1 Полем S2CID 364871 .
- ^ Подпрыгнуть до: а беременный Каплан, Хаим (2001). «Постоянные структуры данных» . Справочник по структурам данных и приложениям .
- ^ Кончон, Сильвен; Filliâtre, Jean-Christophe (2008), «Полудистойкие структуры данных», языки и системы программирования , лекционные заметки в компьютерных науках, Vol. 4960, Springer Berlin Heidelberg, с. 322–336, doi : 10.1007/978-3-540-78739-6_25 , ISBN 9783540787389
- ^ Tiark, Bagwell, Philip Rompf (2011). RRB-деревья: эффективные неизменные векторы . OCLC 820379112 .
{{cite book}}: Cs1 maint: несколько имен: список авторов ( ссылка ) - ^ Бродал, Герт Столтинг; Макрис, Христос; Tsichlas, Kostas (2006), «Чисто функциональный худший постоянный случай, постоянный время, сортируемые списки, сортируемые списки», Алгоритмы - ESA 2006 , лекционные примечания в компьютерных науках, вып. 4168, Springer Berlin Heidelberg, с. 172–183, Citeseerx 10.1.1.70.1493 , doi : 10.1007/11841036_18 , ISBN 9783540388753
- ^ Ленхоф, Ганс-Петер; Smid, Michiel (1994). «Использование постоянных структур данных для добавления ограничений в диапазоне для поиска проблем» . RAIRO - Теоретическая информатика и приложения . 28 (1): 25–49. doi : 10.1051/ita/1994280100251 . HDL : 11858/00-001M-0000-0014-AD4F-B . ISSN 0988-3754 .
- ^ Нил Сарнак; Роберт Э. Тарджан (1986). «Планарное местоположение точки с использованием постоянных поисковых деревьев» (PDF) . Коммуникации ACM . 29 (7): 669–679. doi : 10.1145/6138.6151 . S2CID 8745316 . Архивировано из оригинала (PDF) 2015-10-10 . Получено 2011-04-06 .
- ^ Крис Окасаки. «Чисто функциональные структуры данных (тезис)» (PDF) .
{{cite journal}}: CITE Journal требует|journal=( помощь ) - ^ Liljenzin, Olle (2013). «Сметно постоянные наборы и карты». Arxiv : 1301.3388 . BIBCODE : 2013ARXIV1301.3388L .
{{cite journal}}: CITE Journal требует|journal=( помощь ) - ^ Подпрыгнуть до: а беременный Этот пример взят из Окасаки. Смотрите библиографию.
- ^ Подпрыгнуть до: а беременный Boostcon (2017-06-13), C ++ Now 2017: Фил Нэш «Святой Грааль!? Постоянный тройник с хеш-арайлом для C ++» , архивированный из оригинала на 2021-12-21 , восстановлен 2018-10 -22
- ^ Фил, Багвелл (2001). «Идеальные хэш -деревья» .
{{cite journal}}: CITE Journal требует|journal=( помощь ) - ^ "Мы уже там?" Полем Infoq . Получено 2018-10-22 .
- ^ Steindorfer, Michael J.; Винджу, Юрген Дж. (2015-10-23). «Оптимизация хеш-аррея нанесена на карту попытки для быстрых и худых сборов JVM» . ACM Sigplan замечает . 50 (10): 783–800. doi : 10.1145/2814270.2814312 . ISSN 0362-1340 . S2CID 10317844 .
- ^ "Haskell Language" . www.haskell.org . Получено 2018-10-22 .
- ^ "Data.List" . chackage.haskell.org . Получено 2018-10-23 .
- ^ "Data.Map.Strict" . chackage.haskell.org . Получено 2018-10-23 .
- ^ "Data.Set" . chackage.haskell.org . Получено 2018-10-23 .
- ^ «Производительность/массивы - Хаскеллвики» . Wiki.haskell.org . Получено 2018-10-23 .
- ^ «Clojure - различия с другими лиспами» . clojure.org . Получено 2018-10-23 .
- ^ "Clojure - структуры данных" . clojure.org . Получено 2018-10-23 .
- ^ «Keynote: значение значений» . Infoq . Получено 2018-10-23 .
- ^ "Clojure - атомы" . clojure.org . Получено 2018-11-30 .
- ^ "Core 1.0.0" . package.elm-lang.org . Получено 2018-10-23 .
- ^ «Блог/проклятый-фаст-HTML-раунд-два» . ELM-lang.org . Получено 2018-10-23 .
- ^ «Постоянные (неизменные) коллекции для Java и Kotlin» . github.com . Получено 2023-12-13 .
- ^ «Flux | Архитектура приложения для создания пользовательских интерфейсов» . facebook.github.io . Получено 2018-10-23 .
- ^ Мора, Осмель (2016-07-18). «Как справиться с состоянием в React» . Реагировать экосистему . Получено 2018-10-23 .
- ^ «Прочтите меня - Redux» . Redux.js.org . Получено 2018-10-23 .
- ^ Подпрыгнуть до: а беременный «Необываемые данные - Redux» . Redux.js.org . Получено 2018-10-23 .
- ^ "Неизвестный.js" . facebook.github.io . Архивировано с оригинала 2015-08-09 . Получено 2018-10-23 .
- ^ "Мори" .
- ^ "Всегда" . GitHub . 26 октября 2021 года.
- ^ Джамбулиан, Ара М.; Boizumault, Patrice (1993), Внедрение Prolog - Patrice Boizumault , Princeton University Press, ISBN 9780691637709
- ^ Использование Mercury для реализации конечного домена Solver - Henk Vandecasteele, Bart Demoen, Joachim van der Auwera , 1999
- ^ «Суть объектно -функционального программирования и практический потенциал блога Scala - Codecentric AG» . Кодекентрический блог AG . 2015-08-31 . Получено 2018-10-23 .
- ^ Clojuretv (2013-01-07), Extreme Cleversity: функциональные структуры данных в Scala-Daniel Spiewak , полученные 2018-10-23 [ Dead YouTube ссылка ]
- ^ "Vladimir Kostyukov - Posts / Slides" . kostyukov.net . Retrieved 2018-11-30 .
- ^ «Необываемые предметы и коллекция мусора» . Wiki.c2.com . Получено 2018-11-30 .
- ^ «Последняя граница в Java Performance: Удалите коллектор мусора» . Infoq . Получено 2018-11-30 .